为什么需要稀疏编码及解释
参考:(1) UFLDL
(2) Why sparse coding works
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。稀疏编码算法的目的就是找到一组基向量 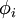 ,使得我们能将输入向量
,使得我们能将输入向量 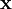 表示为这些基向量的线性组合:
表示为这些基向量的线性组合:
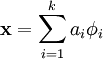
虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组“超完备”基向量来表示输入向量 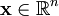 (也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。要求系数 ai 是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。
(也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。要求系数 ai 是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。
确切地说,在稀疏编码算法中,有样本数据 x 供我们进行特征学习。特别是,学习一个用于表示样本数据的稀疏特征集 s, 和一个将特征集从特征空间转换到样本数据空间的基向量 A, 我们可以构建如下目标函数:
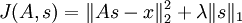
(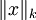 是x的Lk范数,等价于
是x的Lk范数,等价于 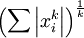 。L2 范数即大家熟知的欧几里得范数,L1 范数是向量元素的绝对值之和)
。L2 范数即大家熟知的欧几里得范数,L1 范数是向量元素的绝对值之和)
上式前第一部分是利用基向量将特征集重构为样本数据所产生的误差,第二部分为稀疏性惩罚项(sparsity penalty term),用于保证特征集的稀疏性。
但是,如目标函数所示,它的约束性并不强――按常数比例缩放A的同时再按这个常数的倒数缩放 s,结果不会改变误差大小,却会减少稀疏代价(表达式第二项)的值。因此,需要为 A 中每项 Aj 增加额外约束 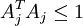 。问题变为:
。问题变为:
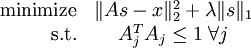
遗憾的是,因为目标函数并不是一个凸函数,所以不能用梯度方法解决这个优化问题。但是,在给定 A 的情况下,最小化 J(A,s) 求解 s 是凸的。同理,给定 s最小化 J(A,s) 求解 A 也是凸的。这表明,可以通过交替固定 s和 A 分别求解 A和s。实践表明,这一策略取得的效果非常好。
但是,以上表达式带来了另一个难题:不能用简单的梯度方法来实现约束条件 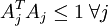 。因此在实际问题中,此约束条件还不足以成为“权重衰变”("weight decay")项以保证 A 的每一项值够小。这样我们就得到一个新的目标函数:
。因此在实际问题中,此约束条件还不足以成为“权重衰变”("weight decay")项以保证 A 的每一项值够小。这样我们就得到一个新的目标函数:
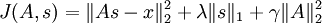
(注意上式中第三项, 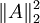 等价于
等价于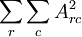 ,是A各项的平方和)
,是A各项的平方和)
这一目标函数带来了最后一个问题,即 L1 范数在 0 点处不可微影响了梯度方法的应用。尽管可以通过其他非梯度下降方法避开这一问题,但是本文通过使用近似值“平滑” L1 范数的方法解决此难题。使用 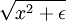 代替
代替 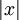 , 对 L1 范数进行平滑,其中 ε 是“平滑参数”("smoothing parameter")或者“稀疏参数”("sparsity parameter") (如果 ε远大于x, 则 x + ε 的值由 ε 主导,其平方根近似于ε)。在下文提及拓扑稀疏编码时,“平滑”会派上用场。
, 对 L1 范数进行平滑,其中 ε 是“平滑参数”("smoothing parameter")或者“稀疏参数”("sparsity parameter") (如果 ε远大于x, 则 x + ε 的值由 ε 主导,其平方根近似于ε)。在下文提及拓扑稀疏编码时,“平滑”会派上用场。
因此,最终的目标函数是:
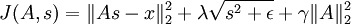
( 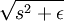 是
是 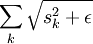 的简写)
的简写)
该目标函数可以通过以下过程迭代优化:
- 随机初始化A
- 重复以下步骤直至收敛:
- 根据上一步给定的A,求解能够最小化J(A,s)的s
- 根据上一步得到的s,,求解能够最小化J(A,s)的A
观察修改后的目标函数 J(A,s),给定 s 的条件下,目标函数可以简化为 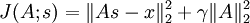 (因为 s 的 L1 范式不是 A 的函数,所以可以忽略)。简化后的目标函数是一个关于 A 的简单二次项式,因此对 A 求导是很容易的。这种求导的一种快捷方法是矩阵微积分( 相关链接部分列出了跟矩阵演算有关的内容)。遗憾的是,在给定 A 的条件下,目标函数却不具备这样的求导方法,因此目标函数的最小化步骤只能用梯度下降或其他类似的最优化方法。
(因为 s 的 L1 范式不是 A 的函数,所以可以忽略)。简化后的目标函数是一个关于 A 的简单二次项式,因此对 A 求导是很容易的。这种求导的一种快捷方法是矩阵微积分( 相关链接部分列出了跟矩阵演算有关的内容)。遗憾的是,在给定 A 的条件下,目标函数却不具备这样的求导方法,因此目标函数的最小化步骤只能用梯度下降或其他类似的最优化方法。
理论上,通过上述迭代方法求解目标函数的最优化问题最终得到的特征集(A 的基向量)与通过稀疏自编码学习得到的特征集是差不多的。但是实际上,为了获得更好的算法收敛性需要使用一些小技巧,后面的 稀疏编码实践 稀疏编码实践章节会详细介绍这些技巧。用梯度下降方法求解目标函数也略需技巧,另外使用矩阵演算或 反向传播算法则有助于解决此类问题。
稀疏编码实践
如上所述,虽然稀疏编码背后的理论十分简单,但是要写出准确无误的实现代码并能快速又恰到好处地收敛到最优值,则需要一定的技巧。
回顾一下之前提到的简单迭代算法:
- 随机初始化A
- 重复以下步骤直至收敛到最优值:
- 根据上一步给定的A,求解能够最小化J(A,s)的s
- 根据上一步得到的s,求解能够最小化J(A,s)的A
这样信手拈来地执行这个算法,结果并不会令人满意,即使确实得到了某些结果。以下是两种更快更优化的收敛技巧:
- 将样本分批为“迷你块”
- 良好的s初始值
将样本分批为“迷你块”
如果你一次性在大规模数据集(比如,有10000 个patch)上执行简单的迭代算法,你会发现每次迭代都要花很长时间,也因此这算法要花好长时间才能达到收敛结果。为了提高收敛速度,可以选择在迷你块上运行该算法。每次迭代的时候,不是在所有的 10000 个 patchs 上执行该算法,而是使用迷你块,即从 10000 个 patch 中随机选出 2000 个 patch,再在这个迷你块上执行这个算法。这样就可以做到一石二鸟――第一,提高了每次迭代的速度,因为现在每次迭代只在 2000 个 patch 上执行而不是 10000个;第二,也是更重要的,它提高了收敛的速度(原因见TODO)。
良好的s初始值
另一个能获得更快速更优化收敛的重要技巧是:在给定 A 的条件下,根据目标函数使用梯度下降(或其他方法)求解 s 之前找到良好的特征矩阵 s 的初始值。实际上,除非在优化 A 的最优值前已找到一个最佳矩阵 s,不然每次迭代过程中随机初始化 s 值会导致很差的收敛效果。下面给出一个初始化 s 的较好方法:
- 令
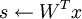 (x 是迷你块中patches的矩阵表示)
(x 是迷你块中patches的矩阵表示) - s中的每个特征(s的每一列),除以其在A中对应基向量的范数。即,如果sr,c表示第c个样本的第r个特征,则Ac表示A中的第c个基向量,则令
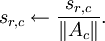
无疑,这样的初始化有助于算法的改进,因为上述的第一步希望找到满足 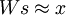 的矩阵 s;第二步对 s 作规范化处理是为了保持较小的稀疏惩罚值。这也表明,只采用上述步骤的某一步而不是两步对 s 做初始化处理将严重影响算法性能。(TODO: 此链接将会对为什么这样的初始化能改进算法作出更详细的解释)
的矩阵 s;第二步对 s 作规范化处理是为了保持较小的稀疏惩罚值。这也表明,只采用上述步骤的某一步而不是两步对 s 做初始化处理将严重影响算法性能。(TODO: 此链接将会对为什么这样的初始化能改进算法作出更详细的解释)
可运行算法
有了以上两种技巧,稀疏编码算法修改如下:
- 随机初始化A
- 重复以下步骤直至收敛
- 随机选取一个有2000个patches的迷你块
- 如上所述,初始化s
- 根据上一步给定的A,求解能够最小化J(A,s)的s
- 根据上一步得到的s,求解能够最小化J(A,s)的A
通过上述方法,可以相对快速的得到局部最优解。
稀疏编码概率解释 [基于1996年Olshausen与Field的理论]
到目前为止,我们所考虑的稀疏编码,是为了寻找到一个稀疏的、超完备基向量集,来覆盖我们的输入数据空间。现在换一种方式,我们可以从概率的角度出发,将稀疏编码算法当作一种“生成模型”。
我们将自然图像建模问题看成是一种线性叠加,叠加元素包括 k 个独立的源特征 以及加性噪声 ν :
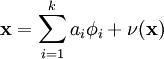
我们的目标是找到一组特征基向量 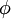 ,它使得图像的分布函数
,它使得图像的分布函数 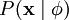 尽可能地近似于输入数据的经验分布函数
尽可能地近似于输入数据的经验分布函数 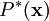 。一种实现方式是,最小化 与 之间的 KL 散度,此 KL 散度表示如下:
。一种实现方式是,最小化 与 之间的 KL 散度,此 KL 散度表示如下:
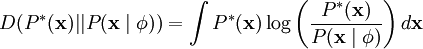
因为无论我们如何选择 ,经验分布函数 都是常量,也就是说我们只需要最大化对数似然函数 。 假设 ν 是具有方差 σ2 的高斯白噪音,则有下式:
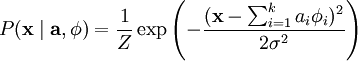
为了确定分布 ,我们需要指定先验分布 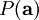 。假定我们的特征变量是独立的,我们就可以将先验概率分解为:
。假定我们的特征变量是独立的,我们就可以将先验概率分解为:
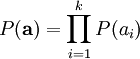
此时,我们将“稀疏”假设加入进来——假设任何一幅图像都是由相对较少的一些源特征组合起来的。因此,我们希望 ai 的概率分布在零值附近是凸起的,而且峰值很高。一个方便的参数化先验分布就是:
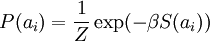
这里 S(ai) 是决定先验分布的形状的函数。
当定义了 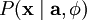 和 后,我们就可以写出在由 定义的模型之下的数据 的概率分布:
和 后,我们就可以写出在由 定义的模型之下的数据 的概率分布:
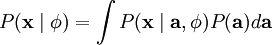
那么,我们的问题就简化为寻找:
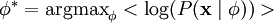
这里 < . > 表示的是输入数据的期望值。
不幸的是,通过对 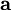 的积分计算 通常是难以实现的。虽然如此,我们注意到如果 的分布(对于相应的 )足够陡峭的话,我们就可以用 的最大值来估算以上积分。估算方法如下:
的积分计算 通常是难以实现的。虽然如此,我们注意到如果 的分布(对于相应的 )足够陡峭的话,我们就可以用 的最大值来估算以上积分。估算方法如下:
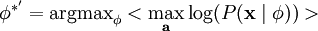
跟之前一样,我们可以通过减小 ai 或增大 来增加概率的估算值(因为 P(ai) 在零值附近陡升)。因此我们要对特征向量 加一个限制以防止这种情况发生。
最后,我们可以定义一种线性生成模型的能量函数,从而将原先的代价函数重新表述为:
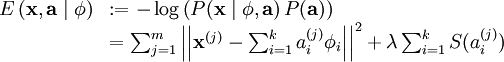
其中 λ = 2σ2β ,并且关系不大的常量已被隐藏起来。因为最大化对数似然函数等同于最小化能量函数,我们就可以将原先的优化问题重新表述为:
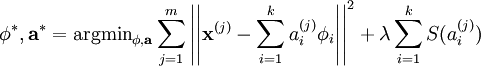
使用概率理论来分析,我们可以发现,选择 L1 惩罚和 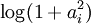 惩罚作为函数 S(.) ,分别对应于使用了拉普拉斯概率
惩罚作为函数 S(.) ,分别对应于使用了拉普拉斯概率 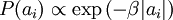 和柯西先验概率
和柯西先验概率 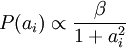 。
。
学习算法
使用稀疏编码算法学习基向量集的方法,是由两个独立的优化过程组合起来的。第一个是逐个使用训练样本 来优化系数 ai ,第二个是一次性处理多个样本对基向量 进行优化。
如果使用 L1 范式作为稀疏惩罚函数,对 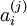 的学习过程就简化为求解 由 L1 范式正则化的最小二乘法问题,这个问题函数在域 内为凸,已经有很多技术方法来解决这个问题(诸如CVX之类的凸优化软件可以用来解决L1正则化的最小二乘法问题)。如果 S(.) 是可微的,比如是对数惩罚函数,则可以采用基于梯度算法的方法,如共轭梯度法。
的学习过程就简化为求解 由 L1 范式正则化的最小二乘法问题,这个问题函数在域 内为凸,已经有很多技术方法来解决这个问题(诸如CVX之类的凸优化软件可以用来解决L1正则化的最小二乘法问题)。如果 S(.) 是可微的,比如是对数惩罚函数,则可以采用基于梯度算法的方法,如共轭梯度法。
用 L2 范式约束来学习基向量,同样可以简化为一个带有二次约束的最小二乘问题,其问题函数在域 内也为凸。标准的凸优化软件(如CVX)或其它迭代方法就可以用来求解 ,虽然已经有了更有效的方法,比如求解拉格朗日对偶函数(Lagrange dual)。
根据前面的的描述,稀疏编码是有一个明显的局限性的,这就是即使已经学习得到一组基向量,如果为了对新的数据样本进行“编码”,我们必须再次执行优化过程来得到所需的系数。这个显著的“实时”消耗意味着,即使是在测试中,实现稀疏编码也需要高昂的计算成本,尤其是与典型的前馈结构算法相比。
为什么需要稀疏编码及解释相关推荐
- Sparsity稀疏编码(三)
稀疏编码(sparse coding)和低秩矩阵(low rank)的区别 上两个小结介绍了稀疏编码的生命科学解释,也给出一些稀疏编码模型的原型(比如LASSO),稀疏编码之前的探讨文章就不说了,今天 ...
- 稀疏编码(Sparse Coding)(二)
为了更进一步的清晰理解大脑皮层对信号编码的工作机制(策略),需要把他们转成数学语言,因为数学语言作为一种严谨的语言,可以利用它推导出期望和要寻找的程式.本节就使用概率推理(bayes views)的方 ...
- Stanford UFLDL教程 稀疏编码自编码表达
稀疏编码自编码表达 Contents [hide] 1稀疏编码 2拓扑稀疏编码 3稀疏编码实践 3.1将样本分批为"迷你块" 3.2良好的s初始值 3.3可运行算法 4中英文对照 ...
- Stanford UFLDL教程 稀疏编码
稀疏编码 Contents [hide] 1稀疏编码 2概率解释 [基于1996年Olshausen与Field的理论] 3学习算法 4中英文对照 5中文译者 稀疏编码 稀疏编码算法是一种无监督学习方 ...
- 为什么要做稀疏编码_为什么我每天都要编码一年,所以我也学到了什么,以及如何做。...
为什么要做稀疏编码 by Paul Rail 由Paul Rail 为什么我每天都要编码一年,所以我也学到了什么,以及如何做. (Why I coded every day for a year, w ...
- 深度学习基础(九)—— 稀疏编码(sparse coding)
稀疏编码算法是一种无监督学习方法,它用来寻找一组"超完备"基向量来更高效地表示样本数据.稀疏编码算法的目的就是找到一组基向量 (自然图像的小波基?) ϕi \mathbf{\phi ...
- 深度学习之五:稀疏编码
9.2.Sparse Coding稀疏编码 如果我们把输出必须和输入相等的限制放松,同时利用线性代数中基的概念,即O = a1*Φ1 + a2*Φ2+-.+ an*Φn, Φi是基,ai是系数, ...
- 稀疏编码(sparsecode)简单理解
Sparse coding: 本节将简单介绍下sparse coding(稀疏编码),因为sparse coding也是deep learning中一个重要的分支,同样能够提取出数据集很好的特征.本文 ...
- [转]字典学习/稀疏编码
本文转自https://zhuanlan.zhihu.com/p/26015351 机器学习--字典学习/稀疏编码学习笔记 Esquirrel 2 个月前 以下资料是小编学习字典学习/稀疏编码时,整理 ...
最新文章
- ORB-SLAM3 论文笔记
- Mysql 安全加固
- java process started_Java HistoricProcessInstanceQuery.startedBy方法代碼示例
- wxWidgets:操作档案manipulate archives的示例应用程序
- C++技术在哪些领域中最为适用?
- Selenium爬虫 -- 使用Selenium爬取数据时,网页切换之后原先获取的元素变量失效的问题
- 信号公式汇总之拉普拉斯变换
- 《微信小程序-进阶篇》组件封装-Icon组件的实现(二)
- uniapp H5 扫码 扫一扫 功能
- uniapp app运行到手机模拟器
- Android Tombstone/Crash的log分析和定位(墓碑文件)
- Beginning Lua with World of Warcraft Add-ons第三章翻译总结及一些工具
- 学习Python编程看哪些书比较好?推荐这10本
- java excel 超链接_Java 添加超链接至Excel文档
- openlayers学习——3、openlayers加点加圆加图标图片
- 2022冬-DownKyi 辅助使用的小插件源码分享
- 3D建模入门学习方法,制作过程的六个主要阶段讲解 小白教程
- 关于使用腾讯云HiFlow场景连接器每天提醒签到打卡
- PhotoShop 之设置选区的羽化
- [luogu2294] [HNOI2005]狡猾的商人