[转]字典学习/稀疏编码
本文转自https://zhuanlan.zhihu.com/p/26015351
机器学习——字典学习/稀疏编码学习笔记
 Esquirrel
Esquirrel
以下资料是小编学习字典学习/稀疏编码时,整理的高质量的网络博客,供大家参考。欢迎留言交流,批评指正理解不足。
最Highlight的地方
基于数据驱动,可以自适应的去学习基(字典),而不需要预先假设,在处理model free的任务上很有优势;
字典D是自己预先设定的大小;字典的系数X是尽可能让D稀疏且表达目标Y的时候自身稀疏(自己的理解)
研究历史
字典学习(Dictionary Learning)和稀疏表示(Sparse Representation)在学术界的正式称谓应该是稀疏字典学习(Sparse Dictionary Learning)。该算法理论包含两个阶段:字典构建阶段(Dictionary Generate)和利用字典(稀疏的)表示样本阶段(Sparse coding with a precomputed dictionary)。  参考资料:
参考资料:
Mallat, S.G. & Zhang, Z. 1993.Matching pursuit in a time-frequency dictionary. IEEE Transactions on Signal Processing 41(12): 3397–3415
Aharon M, Elad M, Bruckstein A. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation[J]. IEEE Transactions on Signal Processing, 2006, 54(11):4311-4322.
问题1:我们为什么需要字典学习?
无论人类的知识有多么浩繁,也无论人类的科技有多么发达,一本新华字典或牛津字典足以表达人类从古至今乃至未来的所有知识,那些知识只不过是字典中字的排列组合罢了!直到这里,我相信相当一部分读者或许在心中已经明白了字典学习的第一个好处(1)它实质上是对于庞大数据集的一种降维表示,或者说是信息的压缩(2)正如同字是句子最质朴的特征一样,字典学习总是尝试学习蕴藏在样本背后最质朴的特征(假如样本最质朴的特征就是样本最好的特征)。
这两条原因同时也是这两年深度学习之风日盛的情况下字典学习也开始随之升温的原因。
问题2:我们为什么需要稀疏表示?
[脑功能研究的启发]意大利罗马大学的Fabio Babiloni教授
回答这个问题毫无疑问就是要回答“稀疏字典学习”中稀疏两字的来历。不妨再举一个例子。相信大部分人都有这样一种感觉,当我们在解涉及到新的知识点的数学题时总有一种累心(累脑)的感觉。但是当我们通过艰苦卓绝的训练将新的知识点牢牢掌握时,再解决与这个知识点相关的问题时就不觉得很累了。这是为什么呢?意大利罗马大学的Fabio Babiloni教授曾经做过一项实验,他们让新飞行员驾驶一架飞机并采集了他们驾驶状态下的脑电,同时又让老飞行员驾驶飞机并也采集了他们驾驶状态下的脑电。
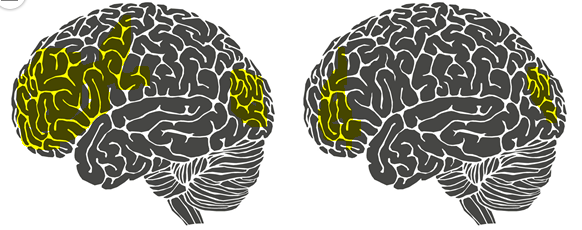 结论是熟练者的大脑(右图)可以调动尽可能少的脑区消耗尽可能少的能量进行同样有效的计算(所以熟悉知识点的你,大脑不会再容易觉得累了),并且由于调动的脑区很少,大脑计算速度也会变快,这就是我们称熟练者为熟练者的原理所在。站在我们所要理解的稀疏字典学习的角度上来讲就是大脑学会了知识的稀疏表示。
结论是熟练者的大脑(右图)可以调动尽可能少的脑区消耗尽可能少的能量进行同样有效的计算(所以熟悉知识点的你,大脑不会再容易觉得累了),并且由于调动的脑区很少,大脑计算速度也会变快,这就是我们称熟练者为熟练者的原理所在。站在我们所要理解的稀疏字典学习的角度上来讲就是大脑学会了知识的稀疏表示。
稀疏表示的本质:用尽可能少的资源表示尽可能多的知识,这种表示还能带来一个附加的好处,即计算速度快。
适应性(泛化能力)和稀疏性之间找平衡,最优取决于代价函数。
这里再扯两点:
1)特征选择(Feature Selection)
大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
2)可解释性(Interpretability)
另一个青睐于稀疏的理由是,模型更容易解释。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:y=w1*x1+w2*x2+…+w1000*x1000+b(当然了,为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的w*就只有很少的非零元素,例如只有5个非零的wi,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。但如果1000个wi都非0,医生面对这1000种因素,累觉不爱。
参考Deep Learning(深度学习)学习笔记整理系列之(二)(四、关于特征)
----------------------------
稀疏字典学习在计算机视觉领域的发展
1995 年前后,Bruno Olshausen和 David Field 两位学者任职 Cornell University,他们试图同时用生理学和计算机的手段,双管齐下,研究视觉问题。
他们收集了很多黑白风景照片,从这些照片中,提取出400个小碎片,每个照片碎片的尺寸均为 16x16 像素,不妨把这400个碎片标记为 S[i], i = 0,.. 399。接下来,再从这些黑白风景照片中,随机提取另一个碎片,尺寸也是 16x16 像素(思考:为什么定为16*16呢?64*64行吗?,相信原文有解答),不妨把这个碎片标记为 T。
我的理解:很多张图片的压缩才可能用到稀疏。表达最好的应该是1*1的基,最稀疏的矩阵应该是图像本身;大小为5*5还是50*50是一种权衡,取决于具体的任务。
原文:Olshausen, Bruno A., and David J. Field. "Emergence of simple-cell receptive field properties by learning a sparse code for natural images." Nature 381.6583 (1996): 607.
他们提出的问题是,如何从这400个碎片中,选取一组碎片,S[k], 通过叠加的办法,合成出一个新的碎片,而这个新的碎片,应当与随机选择的目标碎片 T,尽可能相似,同时,S[k] 的数量尽可能少。用数学的语言来描述,就是:
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在叠加碎片 S[k] 时的权重系数。
为解决这个问题,Bruno Olshausen和 David Field 发明了一个算法,稀疏编码(Sparse Coding)。(此处衍生了好几种算法?有何异同呢?)
稀疏编码是一个重复迭代的过程,每次迭代分两步:
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
Bruno Olshausen和 David Field 的算法结果,与 David Hubel 和Torsten Wiesel 的生理发现,不谋而合!
也就是说,复杂图形,往往由一些基本结构组成。比如下图:一个图可以通过用64种正交的edges(可以理解成正交的基本结构)来线性表示。比如样例的x可以用1-64个edges中的三个按照0.8,0.3,0.5的权重调和而成。而其他基本edge没有贡献,因此均为0。
-----------------------------
K-SVD简述--字典学习,稀疏编码 - Rachel Zhang的专栏 - 博客频道 - CSDN.NET
K-SVD算法简介
K-SVD中每个信号是用多个原子的线性组合来表示的。K-SVD通过构建字典来对数据进行稀疏表示,经常用于图像压缩、编码、分类等应用。
主要问题
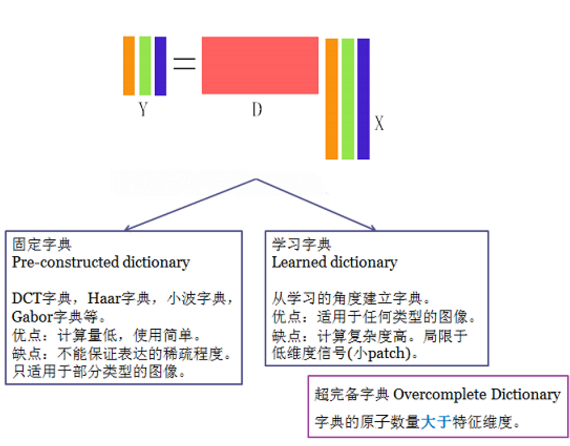 Y为要表示的信号,D为超完备矩阵(列数大于行数), X为系数矩阵,X与Y按列对应,表示D中元素按照Xi为系数线性组合为Y,我们的目的是找到让X尽量稀疏的D。
Y为要表示的信号,D为超完备矩阵(列数大于行数), X为系数矩阵,X与Y按列对应,表示D中元素按照Xi为系数线性组合为Y,我们的目的是找到让X尽量稀疏的D。
参考:Dictionary Learning(字典学习、稀疏表示以及其他)这篇博客从视觉生理角度给予解释
(什么叫完备?)完备性_百度百科
在希尔伯特空间(Hilbert space))中(或者略一般地,在线性内积空间(inner product space)中),一组标准正交基(orthonormal basis)就是一个完全而且正交的集合。
简单说:Hilbert空间就是定义了完备的内积空间。简单理解:不可能再多添加一个元素,基是独立的,所以叫完备。
(为什么要过完备?)
字典矩阵中所谓过完备性,指的是字典元素的个数远远大于信号y的长度(其长度很是n),即n<<k(D矩阵的列数)。(这个表述理解怪怪的?简单理解:基是不独立的,不正交(为了更好的简洁,稀疏的表示信号),过完备)
----------------------
我们的目的是找到让X尽量稀疏的D。
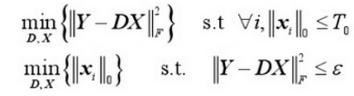
上面的式子本质上是相通的,只是表述形式不一样罢了。
寻找最优解(X最稀疏)是NP-Hard问题。
用追踪算法(Pursuit Algorithm)得到的次优解代替。
MatchingPursuit (MP)
OrthogonalMatching Pursuit (OMP)
BasisPursuit (BP)
FocalUnderdetermined System Solver (FOCUSS)
参考MP算法和OMP算法及其思想 - 逍遥剑客的专栏 - 博客频道 - CSDN.NET(对算法解释的很详细)
[转]字典学习/稀疏编码相关推荐
- 字典学习/稀疏表示学习笔记
首先向大家安利一下南大周志华老师写的<机器学习>这本书,作为一个对此一窍不通的人看了都觉得很有意思,受益匪浅.语言平实却又干货十足,比某些故弄玄虚泛泛而谈的其它国内教材高到不知哪里去了. ...
- 深度学习之五:稀疏编码
9.2.Sparse Coding稀疏编码 如果我们把输出必须和输入相等的限制放松,同时利用线性代数中基的概念,即O = a1*Φ1 + a2*Φ2+-.+ an*Φn, Φi是基,ai是系数, ...
- sklearn自学指南(part49)--字典学习
学习笔记,仅供参考,有错必纠 文章目录 分解信号的分量(矩阵分解问题) 字典学习 用预先计算的字典进行稀疏编码 通用词典学习 Mini-batch字典学习 分解信号的分量(矩阵分解问题) 字典学习 用 ...
- 语音增强———字典学习介绍
语音增强--------------字典学习 字典学习就是用较少的特征(原子)来表示信号,那么信号的多个特征组合就相当于多个原子组成的字典,那么信号就可以用字典中少量的原子进行表示.信号在字典下的表示 ...
- 判别性的低秩字典学习代码matlab,基于分类的判别性字典学习的稀疏编码算法研究...
第1章绪论1.1课题研究的背景及意义计算机视觉一直是人类视觉研究中的一项非常热门的领域.计算机视觉研究的目的是为了让计算机能够利用图像和图像序列来识别和感知周围的世界,以帮助人们在复杂的情况下解决未知 ...
- 稀疏学习、稀疏表示、稀疏自编码神经网络、字典学习、主成分分析PCA、奇异值分解SVD 等概念的梳理,以及常用的特征降维方法
稀疏学习.稀疏表示.稀疏自编码神经网络.字典学习.主成分分析PCA.奇异值分解SVD 等概念的梳理,以及常用的特征降维方法 关于稀疏 稀疏编码 Sparse Coding 与字典学习 神经网络的正则化 ...
- 稀疏编码(sparse code)与字典学习(dictionary learning)
Dictionary Learning Tools for Matlab. 1. 简介 字典 D∈RN×KD\in \mathbb R^{N\times K}(其中 K>NK>N),共有 ...
- 卷积学习与传统稀疏编码、ICA模型学习区别(逐步补充)
逐步总结(有待补充) 无监督学习知识框架: 这种分类不合适,稀疏编码等也可以从统计学角度看做模型学习与参数选择.实际上,稀疏编码是从1维信号发展起来的表示方法. 近年来,稀疏编码逐渐引入信号的先验信息 ...
- 稀疏表示和字典学习的简单理解
稀疏表示和字典学习的简单理解 特征分类 稀疏表示 字典学习 特征分类 相关特征:对当前有用的属性 冗余特征:所包含的信息有时能从其他特征中推演出来.如若某个冗余特征恰好对应了学习任务所需"中 ...
最新文章
- 如何更好的格式化Objective-C代码
- git bash解决中文乱码问题
- Java集合之ArrayList
- HDU 1492 The number of divisors(约数) about Humble Numbers
- windows media player upnp
- 数字PCR(DPCR)和QPCR行业调研报告 - 市场现状分析与发展前景预测
- 矫情的C++——不明确行为(undefined behavior)
- c#图像处理、图片拼接、图片裁剪、图片缩放、图上添加形状、屏幕截图、图片反色、改变图片色彩度全解
- 百度竞价排名曝光_企业入驻百度爱采购必须选好本地运营服务商
- C#获取 Flv视频文件播放时间长度等信息
- 【JAVA】-- 坦克大战全部代码
- NovacoBridge 软件在电子海图更新中的应用
- 软件测试培训班出来好找工作么
- js正则判断域名和IP的端口路径是否正确
- 漏洞工具包2015年态势回顾:规模与分布
- 博弈论学习(二)——完全信息静态博弈
- 奥运会数据可视化展示
- P2690 [USACO04NOV]Apple Catching G 题解
- 超级微商系统开发,社交电商3.0时代的概念
- php 九宫格验证码,PHP九宫格抽奖源码示例
热门文章
- 【kafka专栏】使用shell脚本快速搭建kafka单机版(含视频)
- SSM实训:11、页面插件集成
- 中国设计在重庆丨5G+VR直播直击秋冬风尚大秀
- 在虚拟机里配置mysql环境
- Linux 查看tomcat占用的端口号
- [LaTex]小白----英文论文排版--缩进注意!!!
- UI库你应该知道的基础(超实用)
- oracle12c ora 12560,oracle11g报ora-12560:tns连接异常的解决方法
- extjs调试错误 TypeError:p is null 或 TypeError: el is null
- hbuilder前端需要的插件_这两款HTML5开发工具,前端开发工程师用了直呼内行