Alexnet结构及代码
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet。其官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%. 这项对于传统的机器学习分类算法而言,已经相当的出色。
![]()
上图所示是caffe中alexnet的网络结构,上图采用是两台GPU服务器,所有会看到两个流程图。下边把AlexNet的网络结构示意一下:
![]()
简化的结构为:
![]()
AlexNet为啥取得比较好的结果呢?
1. 使用了Relu激活函数。
Relu函数:f(x)=max(0,x)
![]()
基于ReLU的深度卷积网络比基于tanh和sigmoid的网络训练快数倍,下图是一个基于CIFAR-10的四层卷积网络在tanh和ReLU达到25%的training error的迭代次数:
![]()
2. 标准化(Local Response Normalization)
使用ReLU f(x)=max(0,x)后,你会发现激活函数之后的值没有了tanh、sigmoid函数那样有一个值域区间,所以一般在ReLU之后会做一个normalization,LRU就是稳重提出(这里不确定,应该是提出?)一种方法,在神经科学中有个概念叫“Lateral inhibition”,讲的是活跃的神经元对它周边神经元的影响。
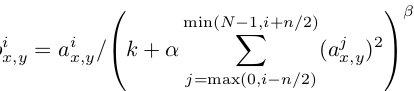
3. Dropout
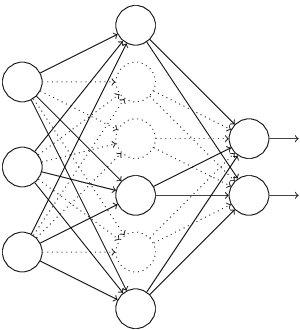
Dropout也是经常说的一个概念,能够比较有效地防止神经网络的过拟合。 相对于一般如线性模型使用正则的方法来防止模型过拟合,而在神经网络中Dropout通过修改神经网络本身结构来实现。对于某一层神经元,通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个人不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束。
4. 数据增强(data augmentation)
在深度学习中,当数据量不够大时候,一般有4解决方法:
>> data augmentation——人工增加训练集的大小——通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据
>> Regularization——数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter。
>> Dropout——也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现
>> Unsupervised Pre-training——用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning
AlexNet的TensorFlow实现(仅参考):
# -*- coding=UTF-8 -*-import sysimport osimport randomimport cv2import mathimport timeimport numpy as npimport tensorflow as tfimport linecacheimport stringimport skimageimport imageio# 输入数据import input_datamnist = input_data.read_data_sets("/tmp/data/", one_hot=True)# 定义网络超参数learning_rate = 0.001training_iters = 200000batch_size = 64display_step = 20# 定义网络参数n_input = 784 # 输入的维度n_classes = 10 # 标签的维度dropout = 0.8 # Dropout 的概率# 占位符输入x = tf.placeholder(tf.types.float32, [None, n_input])y = tf.placeholder(tf.types.float32, [None, n_classes])keep_prob = tf.placeholder(tf.types.float32)# 卷积操作def conv2d(name, l_input, w, b):return tf.nn.relu(tf.nn.bias_add( \tf.nn.conv2d(l_input, w, strides=[1, 1, 1, 1], padding='SAME'),b) \, name=name)# 最大下采样操作def max_pool(name, l_input, k):return tf.nn.max_pool(l_input, ksize=[1, k, k, 1], \strides=[1, k, k, 1], padding='SAME', name=name)# 归一化操作def norm(name, l_input, lsize=4):return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)# 定义整个网络 def alex_net(_X, _weights, _biases, _dropout):_X = tf.reshape(_X, shape=[-1, 28, 28, 1]) # 向量转为矩阵# 卷积层conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1'])# 下采样层pool1 = max_pool('pool1', conv1, k=2)# 归一化层norm1 = norm('norm1', pool1, lsize=4)# Dropoutnorm1 = tf.nn.dropout(norm1, _dropout)# 卷积conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2'])# 下采样pool2 = max_pool('pool2', conv2, k=2)# 归一化norm2 = norm('norm2', pool2, lsize=4)# Dropoutnorm2 = tf.nn.dropout(norm2, _dropout)# 卷积conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3'])# 下采样pool3 = max_pool('pool3', conv3, k=2)# 归一化norm3 = norm('norm3', pool3, lsize=4)# Dropoutnorm3 = tf.nn.dropout(norm3, _dropout)# 全连接层,先把特征图转为向量dense1 = tf.reshape(norm3, [-1, _weights['wd1'].get_shape().as_list()[0]]) dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1') # 全连接层dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation# 网络输出层out = tf.matmul(dense2, _weights['out']) + _biases['out']return out# 存储所有的网络参数weights = {'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])),'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])),'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])),'wd1': tf.Variable(tf.random_normal([4*4*256, 1024])),'wd2': tf.Variable(tf.random_normal([1024, 1024])),'out': tf.Variable(tf.random_normal([1024, 10]))}biases = {'bc1': tf.Variable(tf.random_normal([64])),'bc2': tf.Variable(tf.random_normal([128])),'bc3': tf.Variable(tf.random_normal([256])),'bd1': tf.Variable(tf.random_normal([1024])),'bd2': tf.Variable(tf.random_normal([1024])),'out': tf.Variable(tf.random_normal([n_classes]))}# 构建模型pred = alex_net(x, weights, biases, keep_prob)# 定义损失函数和学习步骤cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)# 测试网络correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))# 初始化所有的共享变量init = tf.initialize_all_variables()# 开启一个训练with tf.Session() as sess:sess.run(init)step = 1# Keep training until reach max iterationswhile step * batch_size < training_iters:batch_xs, batch_ys = mnist.train.next_batch(batch_size)# 获取批数据sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout})if step % display_step == 0:# 计算精度acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})# 计算损失值loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc)step += 1print "Optimization Finished!"# 计算测试精度print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.})
Alexnet结构及代码相关推荐
- alexnet 结构_AlexNet的体系结构和实现
alexnet 结构 In my last blog, I gave a detailed explanation of the LeNet-5 architecture. In this blog, ...
- 七分结构三分代码-直立车想节能
沉睡的小灰 2021-01-27 Wednesday ⊙ 原文链接: 直立车想节能--2020全国大学生智能车车竞赛经验记录之梦的开始 ▌黄粱一梦 如今回首,我不懂我一个通信工程的为什么要去做这个 ...
- python实现struct_Python实现结构体代码实例
这篇文章主要介绍了python实现结构体代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 # python 使用类创建结构体 class My ...
- java 树状数据算法_使用递归算法结合数据库解析成Java树形结构的代码解析
这篇文章主要介绍了使用递归算法结合数据库解析成Java树形结构的代码解析的相关资料,需要的朋友可以参考下 1.准备表结构及对应的表数据 a.表结构:create table TB_TREE ( CID ...
- InnoDB事务结构体代码变量列表
事务结构 struct trx_t 写在前面 InnoDB是MySQL的一个存储引擎,支持事务,支持非堵塞的一致性读,物理存储结构是Page,每个事务都有回滚日志,重做日志,事务还会有死锁检测,各种各 ...
- html页面结构代码,pjblog模板结构HTML代码网页展示
pjblog模板结构HTML代码网页展示: New Document body{ background-color:#FFFAFA; border:1px solid #7D7D7D; color: ...
- MySQL InnoDB事务结构体代码变量全攻略(附源码)
写在前面 InnoDB是MySQL的一个存储引擎,支持事务,支持非堵塞的一致性读,物理存储结构是Page,每个事务都有回滚日志,重做日志,事务还会有死锁检测,各种各样不同的锁等等. 翻看InnoD ...
- [EMQX-V3.4.6源码解析系列]-2-项目结构与代码入口
目录 2-项目结构与代码入口 2.1 项目结构 2.2 emqx应用程序的配置 2.3 依赖的一些应用 kernel Stdlib Jsx Gproc gen_rpc esockd Cowboy re ...
- python结构体_Python实现结构体代码实例
Python实现结构体代码实例 这篇文章主要介绍了Python实现结构体代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 # python 使 ...
最新文章
- python opencv local_threshold_Python-OpenCV中的cv2.threshold
- Angular里如何测试一个具有外部依赖的Component
- SAP CRM Fiori busy dialog的工作原理
- 进程状态转换(了解)
- 黑盒攻击的分类_「图像分类」图像分类中的对抗攻击是怎么回事?
- SpringMVC介绍之约定优于配置
- AGP与PCI-E的区别和PCI-E接口与PCI接口的区别
- 虚幻UE4的后处理特效介绍 http://www.52vr.com/thread-31215-1-1.html
- 图论算法——无向图的邻接链表实现
- 软件开发过程中的一些感悟
- 水管工游戏(啊哈算法)
- Copy and Paste GAN: Face Hallucination from Shaded Thumbnails
- 线性方法求欧拉数-POJ2478
- java集成阿里大于第三方平台发送短信验证码
- envoy做集中式egress sidecar
- python爬虫批量下载图片
- HDU6411 带劲的and和
- 网站服务器选择什么操作系统,网站服务器选择哪种操作系统比较好
- windows搭建hadoop环境(解决HADOOP_HOME and hadoop.home.dir are unset)
- Linux I/O原理和零拷贝Zero-copy技术全面揭秘