4.1 - 《机器学习基石》Home Work 1 Q.15-17
2019独角兽企业重金招聘Python工程师标准>>> 
二话不说先上题目:

训练数据格式如下:

输入有4个维度,输出为{-1,+1}。共有400条数据。
题目要求将权向量元素初始化为0,然后使用“Naive Cycle”遍历训练集,求停止迭代时共对权向量更新了几次。
所谓“Naive Cycle”指的是在某数据条目x(i)上发现错误并更新权向量后,下次从x(i+1)继续读数据,而不是回到第一条数据x(0)从头开始。
#include <fstream>
#include <iostream>
#include <vector>using namespace std;#define DEMENSION 5 //数据维度double weights[DEMENSION]; //权重向量
int step= 0; //迭代次数
int length = 0; //数据条目个数
int index = 0; //当前数据条目索引
bool isFinished = false; //迭代终止状态
char *file = "training_data.txt";struct record {double input[DEMENSION]; //输入int output; //输出
};
vector<record> trainingSet; //训练数据int sign(double x)
{if(x<0) return -1;else if(x>0) return 1;else return -1;
}//两个向量相加,更新第一个向量
void add(double *v1, double *v2, int demension)
{for(int i=0;i<demension;++i){ v1[i] = v1[i] + v2[i]; }
}//两个向量相乘,返回内积
double multiply(double *v1, double *v2, int demension)
{double innerProd = 0.0;for(int i=0;i<demension;++i){innerProd += v1[i] * v2[i];}return innerProd;
}//向量与实数相乘,结果通过*result返回,不改变参与计算的向量
void multiply(double *result, double *v, double num, int demension)
{for(int i=0;i<demension;++i){ result[i] = v[i] * num; }
}//读取所有训练数据
void getData(ifstream & dataFile)
{while(!dataFile.eof()){record curRecord;curRecord.input[0] = 1; for(int i=1;i<DEMENSION;++i){ dataFile>>curRecord.input[i]; }dataFile>>curRecord.output;trainingSet.push_back(curRecord);}dataFile.close();length = trainingSet.size();
}void PLA()
{int start = index;double curInput[DEMENSION];//找到下一个错误记录的indexwhile( trainingSet[index].output == sign(multiply(weights,trainingSet[index].input,DEMENSION)) ){ if(index==length-1) {index = 0;}else {index++;}if(index==start) {isFinished = true; break;} //没发现错误,迭代结束}if(isFinished){cout<<"计算结果:step = "<<step<<", weights = \n";for(int i=0;i<DEMENSION;++i){ cout<<weights[i]<<endl; } return;}else{step++;//更新: weights = weights + curOutput * curInputmultiply( curInput, trainingSet[index].input, trainingSet[index].output, DEMENSION ); add( weights, curInput, DEMENSION ); if(index==length-1) {index = 0;}else {index++;}PLA(); }return;
}void main()
{ ifstream dataFile(file);if(dataFile.is_open()){getData(dataFile); }else{cerr<<"ERROR ---> 文件打开失败"<<endl;exit(1);}for(int i=0;i<DEMENSION;++i){ weights[i] = 0.0; }PLA();
}
多次运行程序,迭代次数均为45次。
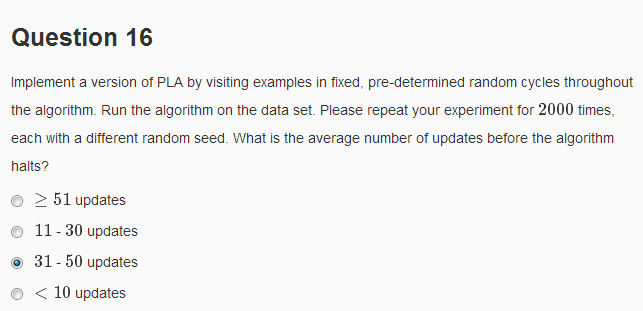
该题要求使用“fixed,pre-determined random cycle”对数据进行遍历,即对400条数据进行随机排序,然后在这轮计算中始终使用这一排序,直到下一轮计算开始再重新排序,重复2000次,求对权向量的平均修正次数。
#include <fstream>
#include <iostream>
#include <vector>
#include <ctime>using namespace std;#define DEMENSION 5 //数据维度int step= 0; //迭代次数
int index = 0; //当前数据条目索引
bool isFinished = false; //迭代终止状态
char *file = "training_data.txt";struct record {double input[DEMENSION]; //输入int output; //输出
};int sign(double x)
{//同Q15
}void add(double *v1, double *v2, int demension)
{//同Q15
}//两个向量相乘,返回内积
double multiply(double *v1, double *v2, int demension)
{//同Q15
}//向量与实数相乘,结果通过*result返回,不改变参与计算的向量
void multiply(double *result, double *v, double num, int demension)
{//同Q15
}//对 traininig set 创建一个随机排序
void setRandomOrder(vector<record> &trainingSet, vector<int> &randIndexes)
{srand((unsigned)time(NULL)); int length = trainingSet.size(); vector<bool> assignedIndexes(length,false); for(int i=0;i<length;++i){int randIndex = rand()%length;while(assignedIndexes[randIndex]==true){randIndex = rand()%length; }randIndexes.push_back(randIndex); assignedIndexes[randIndex] = true; }
}//读取所有训练数据
void getData(ifstream & dataFile, vector<record> &trainingSet)
{while(!dataFile.eof()){record curRecord;curRecord.input[0] = 1; for(int i=1;i<DEMENSION;++i){ dataFile>>curRecord.input[i]; }dataFile>>curRecord.output;trainingSet.push_back(curRecord);}dataFile.close();
}void PLA(vector<record> &trainingSet, vector<int> &randIndexes, double *weights)
{int length = trainingSet.size();int start = index; double curInput[DEMENSION];//找到下一个错误记录的indexwhile( trainingSet[randIndexes[index]].output == sign(multiply(weights,trainingSet[randIndexes[index]].input,DEMENSION)) ){ if(index==length-1) {index = 0;}else {index++;}if(index==start) {isFinished = true; break;} //没发现错误,迭代结束}if(isFinished){return;}else{step++;//更新: weights = weights + curOutput * curInputmultiply( curInput, trainingSet[randIndexes[index]].input, trainingSet[randIndexes[index]].output, DEMENSION ); add( weights, curInput, DEMENSION ); if(index==length-1) {index = 0;}else {index++;}PLA(trainingSet, randIndexes, weights); }return;
}void main()
{int totalSteps = 0;for(int i=0;i<2000;++i){double weights[DEMENSION]; //权重向量vector<record> trainingSet; //训练数据vector<int> randIndexes; //访问数据的随机索引列表ifstream dataFile(file);step = 0; index = 0; isFinished = false; if(dataFile.is_open()){getData(dataFile,trainingSet); setRandomOrder(trainingSet,randIndexes);}else{cerr<<"ERROR ---> 文件打开失败"<<endl;exit(1);}for(int i=0;i<DEMENSION;++i){ weights[i] = 0.0; }PLA(trainingSet, randIndexes, weights);totalSteps += step;}cout<<"Average Step = "<<totalSteps/2000<<endl;
}

本题要求在更新权向量时乘以一个0.5的系数,代码变动很少。

转载于:https://my.oschina.net/findbill/blog/208917
4.1 - 《机器学习基石》Home Work 1 Q.15-17相关推荐
- 太赞了!NumPy 手写所有主流 ML 模型,由普林斯顿博士后 David Bourgin打造的史上最强机器学习基石项目!...
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! 用 NumPy 手写所有主流 ML 模型,普林斯顿博士后 David Bourgi ...
- NumPy 手写所有主流 ML 模型,由普林斯顿博士后 David Bourgin打造的史上最强机器学习基石项目!...
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! 用 NumPy 手写所有主流 ML 模型,普林斯顿博士后 David Bourgi ...
- 台湾大学林轩田机器学习基石课程学习笔记14 -- Regularization
红色石头的个人网站:redstonewill.com 上节课我们介绍了过拟合发生的原因:excessive power, stochastic/deterministic noise 和limited ...
- 台湾大学林轩田机器学习基石课程学习笔记12 -- Nonlinear Transformation
红色石头的个人网站:redstonewill.com 上一节课,我们介绍了分类问题的三种线性模型,可以用来解决binary classification和multiclass classificati ...
- 机器学习基石12-Nonlinear Transformation
注: 文章中所有的图片均来自台湾大学林轩田<机器学习基石>课程. 笔记原作者:红色石头 微信公众号:AI有道 上一节课介绍了分类问题的三种线性模型,可以用来解决binary classif ...
- 台大机器学习基石学习笔记
台大机器学习基石学习笔记 标签(空格分隔): 机器学习 目录 台大机器学习基石学习笔记 目录 Lecture 1 The Learning Problem Course Introduction Wh ...
- 机器学习基石12:非线性变换(Nonlinear Transformation)
本文介绍了非线性变换的整体流程:通过非线性变换,将非线性模型映射到另一个空间,转换为线性模型,再来进行线性分类. 之后介绍了非线性变换存在的问题:时间复杂度和空间复杂度的增加. 最后证明了非线性变换的 ...
- 台湾大学林轩田机器学习基石课程学习笔记1 -- The Learning Problem
红色石头的个人网站:redstonewill.com 最近在看NTU林轩田的<机器学习基石>课程,个人感觉讲的非常好.整个基石课程分成四个部分: When Can Machine Lear ...
- 台湾大学林轩田机器学习基石课程学习笔记15 -- Validation
红色石头的个人网站:redstonewill.com 上节课我们主要讲了为了避免overfitting,可以使用regularization方法来解决.在之前的EinEinE_{in}上加上一个reg ...
- 台湾大学林轩田机器学习基石课程学习笔记13 -- Hazard of Overfitting
红色石头的个人网站:redstonewill.com 上节课我们主要介绍了非线性分类模型,通过非线性变换,将非线性模型映射到另一个空间,转换为线性模型,再来进行分类,分析了非线性变换可能会使计算复杂度 ...
最新文章
- 信息熵及其相关概念--数学
- 循环: 打印1~10
- Java中String、StringBuffer、StringBuilder的区别
- SAP S/4HANA装到Docker里的镜像有多大
- Python小数据保存,有多少中分类?不妨看看他们的类比与推荐方案...
- Linux系统管理第七周作业【Linux微职位】
- SVN Error: Unreadable path encountered; access denied;
- 推荐几个最好用的CRM软件,本人亲测
- 试用officescan 10.5
- 使用vue-pdf-signature实现pdf预览
- 不骗你,全网首创的超硬核的万字SQL题
- Stream系列(六)Match方法使用
- 【评测】MP SARS-CoV-2单抗、重组蛋白
- Pycharm一键选中多个东西(数据、函数等)进行修改、删除、替换等
- 俄罗斯天才少女也选华为,22岁拿下世界编程冠军,同天队友也宣布加盟
- 批处理bat实现常用软件一键开启
- 导出音乐软件歌单为txt文本
- 计算机上的查找替换功能快速格式化,Excel 2016中使用查找替换功能应用技巧
- 畅游Python 二十一:Web框架 - Tornado
- Leetcode(4)寻找两个有序数组的中位数
热门文章
- python求高阶导数_Pythorch中的高阶梯度
- Git报错解决:OpenSSL SSL_read: Connection was reset, errno 10054 错误解决
- java final 详解_java中Final详解
- oracle如何设置权限,Oracle创建用户并设置权限
- python控制窗口_Python : Turtle窗口控制
- linux关机_LINUX快速入门第二章:Linux 系统启动过程
- python导入requests库_windows环境中python导入requests
- mysql词法分析antlr4_词法分析器和语法分析器的界线 - ANTLR 4 简明教程
- python 代码行数统计工具_使用Python设计一个代码统计工具
- 南京师范大学与南京林业大学计算机,这8所高校“同宗同源”但不同命!有些是“985”,有些却是“双非”?...