台大机器学习基石学习笔记
台大机器学习基石学习笔记
标签(空格分隔): 机器学习
目录
- 台大机器学习基石学习笔记
- 目录
- Lecture 1 The Learning Problem
- Course Introduction
- What is Machine Learning
- Applications of Machine Learning
- Components of Machine Learning
- Machine Learning and Other Fields
- Lecture 2 Learning to Answer YesNo
- Perceptron Hypothesis Set
- Perceptron Learning Algorithm PLA
- Guarantee of PLA
- Non-Separable Data
- Lecture 3 Types of Learning
- Learning with Different Output Space mathcalY
- Learning with Different Data Label y_n
- Learning with Different Protocol f Rightarrow textbfx_n y_n
- Learning with Different Input Space mathcalX
- Lecture 4 Feasibility of Learning
- Learning is Impossible
- Probability to the Rescue
- Connection to Learning
- Connection to Real Learning
- Lecture 5 Training versus Testing
- Recap and Preview
- Effective Number of Lines
- Effective Number of Hypotheses
- Break Point
- Lecture 6 Theory of Generalization
- Restriction of Break Point
- Bounding Function Basic Cases
- Bounding Function Inductive Cases
- A Pictorial Proof
- Lecture 7 The VC Dimension
- Definition of VC Dimension
- VC Dimension of Perceptrons
- Physical Intuition of VC Dimension
- Lecture 8 Noise and Error
- Noise and Probabilistic Target
- Error Measure
- Algorithmic Error Measure
- Weighted Classification
- Lecture 9 Linear Regression
- Linear Regression Problem
- Linear Regression Algorithm
- Generalization Issue
- Linear Regression for Binary Classification
- Lecture 10 Logistic Regression
- 背景
- 最大似然估计
- 梯度下降法最小化错误
- 梯度下降法的具体过程
- Lecture 11 Linear Models for Classification
- Linear Models for Binary Classification
- Stochastic Gradient Descent
- Multiclass via Logistic Regression
- Multiclass via Binary Classification
- Lecture 12 Nonlinear Transformation
- 背景
- 找到一个好的转换函数
- 要付出的代价
- Lecture 13 Hazard of Overfitting
- What is Overfitting
- The Role of Noise and Data Size
- Deterministic Noise
- Dealing with Overfitting
- Lecture 14 Regularization
- 背景
- 正则化的优化问题
- 正则化的VC bound
- Lecture 15 Validation
- 背景
- Validation的过程
- Leave-One-Out Cross Validation
- V-Fold Cross Validation
- Lecture 16 Three Learning Principles
- 背景
- Principle
Lecture 1: The Learning Problem
1.Course Introduction
主要是介绍课程的一些相关情况。
2.What is Machine Learning
如果一个系统能够通过执行某个进程改善它的性能,这就是学习。赫尔伯特·西蒙
- Machine Learning
- Improving some performance measure with experience computed from data.
何时适用ML:
- 存在某种可以被学习的规律
- 规律难以以编程实现
- 拥有和特征有关的数据可供学习
3.Applications of Machine Learning
机器学习的应用极广:已经出现在人们生活(衣食住行)的各个角落。
4.Components of Machine Learning
- input: \textbf{x}\textbf{x} \in\in \mathcal{X}\mathcal{X} (customer application)
- output: yy \in\in \mathcal{Y}\mathcal{Y} (good/bad after approving credit card)
- \color{#A05}{unknown\ pattern\ to\ be\ learned \Leftrightarrow target function:}\color{#A05}{unknown\ pattern\ to\ be\ learned \Leftrightarrow target function:}
ff : \mathcal{X}\mathcal{X} \rightarrow\rightarrow \mathcal{Y}\mathcal{Y} (ideal credit approval formula) - \color{blue}{data \Leftrightarrow training\ examples}\color{blue}{data \Leftrightarrow training\ examples}: \mathcal{D}\mathcal{D} = {(\textbf{x}_1\textbf{x}_1, y_1), (\textbf{x}_2\textbf{x}_2, y_2y_2), \ldots \ldots , (\textbf{x}_N\textbf{x}_N, y_Ny_N)}
(historical records in bank) - \color{#0F0}{hypothesis \Leftrightarrow skill}\color{#0F0}{hypothesis \Leftrightarrow skill} with hopefully \color{#F05}{good\ performance}\color{#F05}{good\ performance}:
gg : \mathcal{X}\mathcal{X} \rightarrow\rightarrow \mathcal{Y}\mathcal{Y} (‘learned’ formula to be used)
5.Machine Learning and Other Fields
- Machine Learning and Data Mining
ML和DM的区别很小 - Machine Learning and Artificial Intelligence
ML被认为是一种实现人工智能的方式(在这里我认为可能是深度学习)。 - Machine Learning and Data Mining
统计与ML紧密相关,ML领域大量使用统计学的模型和知识,例如目前在看的一本《统计学习方法》(里面介绍的若干种机器学习算法),作者李航就把统计学习认为是最有效的机器学习方法。
Lecture 2: Learning to Answer Yes/No
1.Perceptron Hypothesis Set
X= \begin{bmatrix} 1 & x_1^1 & x_2^1 &\cdots&x_d^1 \\ 1 & x_1^2 & x_2^2 &\cdots&x_d^2 \\ \vdots&\vdots&\vdots&\ddots&\vdots \\ 1 & x_1^j & x_2^j &\cdots&x_d^j \\ \end{bmatrix} \ \ \ \ \ \mathcal{Y} : \{+1(good), -1(bad)\}\\ X= \begin{bmatrix}1 & x_1^1 & x_2^1 &\cdots&x_d^1 \\1 & x_1^2 & x_2^2 &\cdots&x_d^2 \\\vdots&\vdots&\vdots&\ddots&\vdots \\1 & x_1^j & x_2^j &\cdots&x_d^j \\\end{bmatrix} \ \ \ \ \ \mathcal{Y} : \{+1(good), -1(bad)\}\\
\begin{split} h(\textbf{x}) &= sign\Bigg(\Big(\sum_{i=1}^dW_iX_i\Big) - threshold\Bigg) \ \ \ \ h\in \mathcal{H} \\ &= sign\Big(W^TX\Big) \end{split}\begin{split}h(\textbf{x}) &= sign\Bigg(\Big(\sum_{i=1}^dW_iX_i\Big) - threshold\Bigg) \ \ \ \ h\in \mathcal{H} \\&= sign\Big(W^TX\Big) \end{split}
2.Perceptron Learning Algorithm (PLA)
1.逐个遍历各个point(随机或者按序列),直到找到错误:
sign\Big(W_t^TX_{n(t)}\Big)\neqsign\Big(W_t^TX_{n(t)}\Big)\neqy_{n(t)}y_{n(t)}
2.correct W_tW_t:
W_{t+1}\leftarrowW_{t+1}\leftarrowW_t+W_t+y_{n(t)}X_{n(t)}y_{n(t)}X_{n(t)}
3.遍历完毕所有样本点,没有发现错误:
return last WW(called W_{PLA}W_{PLA}) as gg
3.Guarantee of PLA
证明PLA在线性可分额样本里训练,更新过程一定收敛:
1.wf一定完美区分所有的点(所有的点的向量与之内积为正):
y_{n(t)}W_f^TX_{n(t)}\ge\mathop {\min }\limits_n y_{n}W_f^TX_{n}\gt0y_{n(t)}W_f^TX_{n(t)}\ge\mathop {\min }\limits_n y_{n}W_f^TX_{n}\gt0
2.每次找到错误才更新:
\begin{split} W_{t+1}&=W_t+y_{n(t)}X_{n(t)}\\ \end{split}\begin{split} W_{t+1}&=W_t+y_{n(t)}X_{n(t)}\\ \end{split}
3.什么是错误的点:
y_{n(t)}W_f^TX_{n(t)}\le0y_{n(t)}W_f^TX_{n(t)}\le0
根据以上三个结论我们可以通过计算W_fW_f和W_TW_T的夹角余弦以得到TT(更新次数)收敛的结论。
4.Non-Separable Data
对于样本有噪声,线性不可分的情况,若直接通过计算所有的W_fW_f取错误率最小的那个的方法是可以证明是非常困难的,所以对PLA算法进行加入比较步骤的口袋算法(贪心算法),即每次存储W_TW_T,对于下一次额更新,比较存储的W_TW_T和当前的W_TW_T,取错误更少的保存,继续迭代,直到无法再找到错误更少的W_TW_T,即作为W_fW_f。
Lecture 3: Types of Learning
1.Learning with Different Output Space \mathcal{Y}\mathcal{Y}
按照不同的输出我们可以把ML分为以下几类:
- 二元分类: 如之前的信用卡申请,门禁权限识别
- 多元分类: 如硬币的分类,手写字母、数字的识别
- 回归: 如预测价格走势
- 结构学习: 输出预测句子或者段落(更为复杂的s结构)
- 更多。。。
2.Learning with Different Data Label y_ny_n
按照数据的不同的标签不同,可以把ML分为以下几类:
- supervised: 所有data都具有 y_ny_n
- unsupervised: 所有data都没有 y_ny_n
- semi-supervised: 一些data具有 y_ny_n
- reinforcement: 所有data都没有 y_ny_n,但是某些data具有某些有暗示意味的\hat{y_n}\hat{y_n}
- and more!!
3.Learning with Different Protocol f \Rightarrow\Rightarrow (\textbf{x}_n\textbf{x}_n, y_ny_n)
按照数据的传输方式,可以把ML分为以下几类:
- batch: all known data(填鸭式,一次性把所有的data给算法)
- online: sequential (passive) data(连续的数据,如同接收一封一封邮件)
- active: strategically-observed data(机器通过主动询问某些问题来学习)
- and more!!
4.Learning with Different Input Space \mathcal{X}\mathcal{X}
按照输入空间\mathcal{X}\mathcal{X}的不同,可以把ML分为以下几类:
- concrete: sophisticated (and related)(精细的、复杂的、有序的,已经完成预处理的数据)
- physical meaning
- raw: simple physical meaning(原始的,未经处理或者经过很少处理的数据)
- abstract: no (or little) physical meaning(抽象的,无法轻易表明含义的数据)
- and more!!
Lecture 4: Feasibility of Learning
1.Learning is Impossible?
机器学习的大多数情况下是让机器通过现有的训练集(D)的学习以获得预测未知数据的能力,即选择一个最佳的h做为学习结果,那么这种预测是可能的么?为什么在采样数据上得到的h可以认为适用于全局,也就是说其泛化性的本质是什么?通过两个简单的小题目引出这个问题。
2.Probability to the Rescue
课程首先引入一个情景:
如果有一个装有很多(数量很大以至于无法通过数数解决)橙色球和绿色球的罐子,我们能不能推断橙色球的比例?很明显的思路是利用统计中抽样的方法,既然我们无法穷尽数遍所有罐子中的球,不如随机取出几个球,算出其中两种颜色球的比例去近似得到我们要的答案,这样真的可以么?
我们都知道小概率事件也会发生,假如罐子里面大部分都是橙色球,而我们恰巧取出的都是绿色,这样我们就判断错了,那么到底通过抽样得出的比例能够说明什么呢?似乎两者不能直接划等号。
由此,课程中引入了一个非常重要的概念,PAC,要理解这个,先得理解一个超级重要的不等式:Hoeffding’s inequality
\Bbb{P}[\left|\nu-\mu\right|\gt\epsilon]\le2\exp\big(-2\epsilon^2N\big) \Bbb{P}[\left|\nu-\mu\right|\gt\epsilon]\le2\exp\big(-2\epsilon^2N\big)
这个不等书说明了对于未知的那个概率,我们的抽样概率可以根它足够接近只要抽样的样本够大或者容忍的限制变松,这个和我们的直觉是相符的。式子最后给出了probably approximately correct (PAC)的概念,即概率上几乎正确。所以,我们通过采用算出的橙球的概率和全局橙球的概率相等是PAC的。
3.Connection to Learning
这些和机器学习有什么关系?其实前文中提到的例子可以和机器学习问题一一对应。
映射中最关键的点是讲抽样中橙球的概率理解为样本数据集D上h(x)错误的概率,以此推算出在所有数据上h(x)错误的概率,这也是机器学习能够工作的本质,即我们为什么在采样数据上得到了一个假设,就可以推到全局呢?因为两者的错误率是PAC的,只要我们保证前者小,后者也就小了。
4.Connection to Real Learning
请注意,以上都是对某个特定的假设,其在全局的表现可以和其在DataSet的表现PAC,保证DataSet表现好,就能够推断其能泛化。可是我们往往有很多假设,我们实际上是从很多假设中挑一个表现最好(Ein最小)的作为最终的假设,那么这样挑的过程中,最小的Ein其泛化能力一定是最好么?肯定不是。
继续用抛硬币的例子说明,很形象,每一个罐子都是一个假设集合,我们默认是挑表现最好的,也就是全绿色(错误率为0)的那个假设。
但是当从众多假设选择时,得到全对的概率也在增加,就像丢硬币一样,当有个150个童鞋同时丢硬币5次,那么这些人中出现5面同时朝上的概率为99%,所以表现好的有可能是小概率事件发生(毕竟对于每个假设其泛化能力是PAC),其不一定就有好的泛化能力(Ein和Eout相同),我们称这次数据是坏数据(可以理解为选到了泛化能力差的假设),在坏数据上,Ein和Eout的表现是差别很大的,这就是那个小概率事件。
Hoeffding’s inequality告诉我们,每个h在采样数据上Ein和Eout差别很大的概率很低(坏数据):
\begin{split} \Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}]&=\Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_1\ or\ BAD\ \mathcal{D}\ for\ h_2\ or\ ...\ or\ BAD\ \mathcal{D}\ for\ h_M]\\&\le\Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_1]+ \Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_2]+ ...+\Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_M] \\&\le2\exp\big(-2\epsilon^2N\big)+\exp\big(-2\epsilon^2N\big)+\exp\big(-2\epsilon^2N\big)+...+\exp\big(-2\epsilon^2N\big)\\&=2M\exp\big(-2\epsilon^2N\big) \end{split} \begin{split} \Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}]&=\Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_1\ or\ BAD\ \mathcal{D}\ for\ h_2\ or\ ...\ or\ BAD\ \mathcal{D}\ for\ h_M]\\&\le\Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_1]+ \Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_2]+ ...+\Bbb{P}_{\mathcal{D}}[BAD\ \mathcal{D}\ for\ h_M] \\&\le2\exp\big(-2\epsilon^2N\big)+\exp\big(-2\epsilon^2N\big)+\exp\big(-2\epsilon^2N\big)+...+\exp\big(-2\epsilon^2N\big)\\&=2M\exp\big(-2\epsilon^2N\big) \end{split}
由于有这个bound,那么我们每次选取Ein最小的h就是合理的,因为如果M小N大,出现表现好的坏数据的假设几率降低了,我们选择表现后就有信心认为其有良好的泛化能力。
Lecture 5: Training versus Testing
1.Recap and Preview
复习一下我们机器学习的流程图,我们有两个问题
1. E_{in}\text{是否等于}E_{out}E_{in}\text{是否等于}E_{out}
2. E_{in}E_{in}是否足够小
而M(hypothesis的数目)在其中这两个问题中扮演的角色有:
- M比较小,由于\Bbb{P}[BAD]\le2M\exp\big(-2\epsilon^2N\big)\Bbb{P}[BAD]\le2M\exp\big(-2\epsilon^2N\big),坏事情(选到不好的hypothesis)的几率也会比较小:比较能确保E_{in}\text{等于}E_{out}E_{in}\text{等于}E_{out}(问题一);但是,我们的选择比较小,不容易选到使E_{in}E_{in}足够小的hypothesis(问题二)。
- M比较大,我们的选择比较大,更容易选到使E_{in}E_{in}足够小的hypothesis(问题二);但坏事情发生的几率也会增大:更不能确保E_{in}\text{等于}E_{out}E_{in}\text{等于}E_{out}(问题一);。
2.Effective Number of Lines
\Bbb{P}\left[\left|E_{in}(g)-E_{out}(g)\right|\gt\epsilon\right]\le2\color{red}{M}\exp\big(-2\epsilon^2N\big) \Bbb{P}\left[\left|E_{in}(g)-E_{out}(g)\right|\gt\epsilon\right]\le2\color{red}{M}\exp\big(-2\epsilon^2N\big)
上式展示了总体上坏事情发生的概率,我们可以观察到,这个概率以一个\color{orange}{union\ bound}\color{orange}{union\ bound}作为上限,但是当M是一个发散的值(PLA算法)的时候,这个不等式并没有意义。
事实上M往往是over estimated的(各个hypothesis有重叠,union没那么大)。那么怎么解决这个问题呢?
我们以二元分类来阐述怎么解决(当然最后是可以推广到其他学习问题的):
对于一个training example{ x1 }。虽然看起来我们的hypothesis set有无数条线。但实际上这些hypothesis只有两类罢了—-把x1分为叉叉的一类和把x1分为圈圈的一类。
这样问题便转化为:
\Bbb{P}\left[\left|E_{in}(g)-E_{out}(g)\right|\gt\epsilon\right]\le2\ \color{red}{effective(N)}\exp\big(-2\epsilon^2N\big) \Bbb{P}\left[\left|E_{in}(g)-E_{out}(g)\right|\gt\epsilon\right]\le2\ \color{red}{effective(N)}\exp\big(-2\epsilon^2N\big)
也就是把无数的线划分成等价类。我们可以发现,线的划分同时也取决于点的个数。一个二维点有两种类型的线(也就有两种类型的hypothesis),二个二维的点就有四种类型的线了(也就有四种类型的hypothesis)。
3.Effective Number of Hypotheses
- Dichotomy
- Mini-hypotheses,可产生的有效的分类
- growth function
- m_{\mathcal{H}}(N)=\mathop {\max }\limits_{\textbf{x}_1,\textbf{x}_2,...,\textbf{x}_N}\left|\mathcal{H}(\textbf{x}_1,\textbf{x}_2,...,\textbf{x}_N)\right| m_{\mathcal{H}}(N)=\mathop {\max }\limits_{\textbf{x}_1,\textbf{x}_2,...,\textbf{x}_N}\left|\mathcal{H}(\textbf{x}_1,\textbf{x}_2,...,\textbf{x}_N)\right|
于是我们用dichotomy的\color{orange}{2^N}\color{orange}{2^N}的bound取代了\color{red}{M}\color{red}{M}的无限bound。但是\color{orange}{2^N}\color{orange}{2^N}仍然是一个较大的值,我们继续希望用一个更小的bound取代它。
显然,如果growth function是一个关于N的多形式函数,那么利用之前的hoeffding不等式,我们会得到一个不错的结果。
下面是几个实际的例子:
- Positive Rays:
- 易得其m_{\mathcal{H}}(N) = N+1m_{\mathcal{H}}(N) = N+1
- Positive Intervals:
- 易得其m_{\mathcal{H}}(N) ={N+1 \choose 2}+1=\frac{1}{2}N^2+\frac{1}{2}N+1m_{\mathcal{H}}(N) ={N+1 \choose 2}+1=\frac{1}{2}N^2+\frac{1}{2}N+1
- Convex Sets:
- 虽不好直接考虑,但是可以想象一种极端的情况:所有的点都排列在圆的周长上,其m_{\mathcal{H}}(N) = 2^Nm_{\mathcal{H}}(N) = 2^N
4.Break Point
- 引入shatter的概念:shatter
- 对于N个点,能用线把2^N种点的情况,也就是2元分类下N个点可能出现的所有情况都作出正确的分割。
对于K个输入(K个点),我们知道break point是不能作出shatter的那个最小的K。一旦K是break point,那么大于K的输入也无法shatter(这是显然的,我只要把多出点重叠,就可以reduce到K个点情况了)。
现在假设break point为2,再我们假设4个输入点,显然4个输入点里任意两个点无法被shatter(也就是无法做出一条线使任意的两个点能被分为oo,xx,ox,xo这四种情况)。这样我们这四个点可能出现的组合就被break point大大的限制住了。
Lecture 6: Theory of Generalization
1.Restriction of Break Point
总结归纳之前结论:
- Positive Rays的m_{\mathcal{H}}(N) = N+1m_{\mathcal{H}}(N) = N+1,m_{\mathcal{H}}(2) = 3\le2^2m_{\mathcal{H}}(2) = 3\le2^2: break point at 2;
- Positive Intervals的m_{\mathcal{H}}(N) ={N+1 \choose 2}+1=\frac{1}{2}N^2+\frac{1}{2}N+1m_{\mathcal{H}}(N) ={N+1 \choose 2}+1=\frac{1}{2}N^2+\frac{1}{2}N+1,m_{\mathcal{H}}(3) = 7\le2^3m_{\mathcal{H}}(3) = 7\le2^3: break point at 3;
- Convex Sets的m_{\mathcal{H}}(N) = 2^Nm_{\mathcal{H}}(N) = 2^Nalways: no break point;
- 2D preceptrons的m_{\mathcal{H}}(4) = 14\le2^4m_{\mathcal{H}}(4) = 14\le2^4: break point at 4
2.Bounding Function: Basic Cases
- 于是我们引入函数bounding function B(N; k)B(N; k):
- maximum possiblem_{\mathcal{H}}(N)m_{\mathcal{H}}(N) when break point = k
接下来根据已知的和显而易见的关系来画Table of Bounding Function:
\begin{array}{c|lcr}&&&&k\\ B(N,k) &1&2&3&4&5&6&\cdots \\ \hline 1 & 1 & 2 & 2&2&2&2 &\cdots\\ 2 & 1 & 3 & 4&4&4&4 &\cdots\\ 3 & 1 & 4 & 7&8&8&8&\cdots\\ 4&1&&&15&16&16&\cdots\\ 5&1&&&&31&32&\cdots\\ 6&1&&&&&63&\cdots\\ \vdots&\vdots&&&&&&\ddots \end{array} \begin{array}{c|lcr}&&&&k\\ B(N,k) &1&2&3&4&5&6&\cdots \\ \hline 1 & 1 & 2 & 2&2&2&2 &\cdots\\ 2 & 1 & 3 & 4&4&4&4 &\cdots\\ 3 & 1 & 4 & 7&8&8&8&\cdots\\ 4&1&&&15&16&16&\cdots\\ 5&1&&&&31&32&\cdots\\ 6&1&&&&&63&\cdots\\ \vdots&\vdots&&&&&&\ddots \end{array}
3.Bounding Function: Inductive Cases
接下来如何呢?我们分析B(4,3)B(4,3)可能会与上表之中的它的上一排有关,所以用计算机计算出了B(4,3)B(4,3)的所有的11种可能情况,再把这十一种情况按照x_1,x_2,x_3x_1,x_2,x_3的是否成对出现分为\alpha,\beta\alpha,\beta两组一共有2\alpha+\beta2\alpha+\beta个,因为B(4,3)B(4,3)表示的是4个点中不能出现任何三个点shatter的情况,故只考虑x_1,x_2,x_3x_1,x_2,x_3的情况下,把\alpha+\beta\alpha+\beta(2\alpha\alpha重复出现只算一半)单独留下来,必然也不会shatter三个点故有
\alpha+\beta\le B(3,3)\alpha+\beta\le B(3,3)
而单独考虑\alpha\alpha组的情况,必然其不会shatter2个点(因为\alpha\alpha组中的每个点都对应x_4x_4的两种情况,\alpha\alpha组如果shatter2个点,加上x_4x_4必然shatter3个点),于是有:
\alpha\le B(3,2)\alpha\le B(3,2)
又B(4,3)=2\alpha+\betaB(4,3)=2\alpha+\beta
于是:
B(4,3)\le B(3,3)+B(3,2)B(4,3)\le B(3,3)+B(3,2)
推广到其他:
B(N,k)\le B(N-1,k)+B(N-1,k-1)B(N,k)\le B(N-1,k)+B(N-1,k-1)
用数学归纳法可以证明:
B(N,k) \le\sum_{i=0}^{k-1}{N \choose i}B(N,k) \le\sum_{i=0}^{k-1}{N \choose i}
当k=1时不等式恒成立,因此只要讨论k≥2的情形。N=1时,不等式成立,假设N≤No时对于所有的k不等式都成立,则我们需要证明当N=No+1时,不等式也成立。根据前面得到的结论,有:
\begin{aligned} B(N_{o}+1,k) &\leq B(N_{o},k) + B(N_{o},k-1) \\\ &\leq \sum_{i=0}^{k-1}\binom{N_{o}}{i}+\sum_{i=0}^{k-2}\binom{N_{o}}{i} \\\ &=1+\sum_{i=1}^{k-1}\binom{N_{o}}{i}+\sum_{i=1}^{k-1}\binom{N_{o}}{i-1} \\\ &=1+\sum_{i=1}^{k-1}[\binom{N_{o}}{i}+\binom{N_{o}}{i-1}] \\\ &=1+\sum_{i=1}^{k-1}\binom{N_{o}+1}{i}=\sum_{i=0}^{k-1}\binom{N_{o}+1}{i} \end{aligned}\begin{aligned} B(N_{o}+1,k) &\leq B(N_{o},k) + B(N_{o},k-1) \\\ &\leq \sum_{i=0}^{k-1}\binom{N_{o}}{i}+\sum_{i=0}^{k-2}\binom{N_{o}}{i} \\\ &=1+\sum_{i=1}^{k-1}\binom{N_{o}}{i}+\sum_{i=1}^{k-1}\binom{N_{o}}{i-1} \\\ &=1+\sum_{i=1}^{k-1}[\binom{N_{o}}{i}+\binom{N_{o}}{i-1}] \\\ &=1+\sum_{i=1}^{k-1}\binom{N_{o}+1}{i}=\sum_{i=0}^{k-1}\binom{N_{o}+1}{i} \end{aligned}
因此当N=N_0+1N=N_0+1时,不等式也成立。
4.A Pictorial Proof
成长函数的上界B(N,k)B(N,k)都被bound住了,那我们的成长函数同样也可以被这个bound住,因此对于存在break point k的成长函数而言,有:
m_{\mathcal{H}}\leq \sum_{i=0}^{k-1}\binom {N}{i}m_{\mathcal{H}}\leq \sum_{i=0}^{k-1}\binom {N}{i}
而右手边(RHS)实际上是一个最高次项为k-1次的多项式。以2D Perceptrons为例,它的break point k=4,则它的成长函数会被B(N,4)给bound住
m_{\mathcal{H}}\leq \sum_{i=0}^{4-1}\binom {N}{i}=\frac{1}{6}N^3+\frac{5}{6}N+1m_{\mathcal{H}}\leq \sum_{i=0}^{4-1}\binom {N}{i}=\frac{1}{6}N^3+\frac{5}{6}N+1
故利用有限的m_{\mathcal{H}}(N)m_{\mathcal{H}}(N)来替换无限的大MM,得到\mathcal{H}\mathcal{H}遇到Bad Sample的概率上界:
\mathbb{P}_\mathcal{D}[BAD\ D]\leq 2m_{\mathcal{H}}(N)\cdot exp(-2\epsilon ^2N)\mathbb{P}_\mathcal{D}[BAD\ D]\leq 2m_{\mathcal{H}}(N)\cdot exp(-2\epsilon ^2N)
其中\mathbb{P}_\mathcal{D}[BAD\ D]\mathbb{P}_\mathcal{D}[BAD\ D]是\mathcal{H}\mathcal{H}中所有有效的方程(Effective Hypotheses)遇到Bad Sample的联合概率,即\mathcal{H}\mathcal{H}中存在一个方程遇上bad sample,则说\mathcal{H}\mathcal{H}遇上bad sample。用更加精准的数学符号来表示上面的不等式:
\mathbb{P}[\exists h \in \mathcal{H}\text{ s.t. } |E_{in}(h)-E_{out}(h)|\gt \epsilon]\leq 2m_{\mathcal{H}}(N)\cdot exp(-2\epsilon ^2N)\mathbb{P}[\exists h \in \mathcal{H}\text{ s.t. } |E_{in}(h)-E_{out}(h)|\gt \epsilon]\leq 2m_{\mathcal{H}}(N)\cdot exp(-2\epsilon ^2N)
注:\exists h \in \mathcal{H}\text{ s.t. }\exists h \in \mathcal{H}\text{ s.t. } - \mathcal{H}\mathcal{H}中存在(\exists\exists)满足(\text{ s.t }\text{ s.t })…的hh
但事实上上面的不等式是不严谨的,为什么呢?m_{\mathcal{H}}(N)m_{\mathcal{H}}(N)描述的是\mathcal{H}\mathcal{H}作用于数据量为NN的资料\mathcal{D}\mathcal{D},有效的方程数,因此\mathcal{H}\mathcal{H}当中每一个hh作用于\mathcal{D}\mathcal{D}都能算出一个E_{in}E_{in}来,一共能有m_{\mathcal{H}}(N)m_{\mathcal{H}}(N)个不同的E_{in}E_{in},是一个有限的数。但在out of sample的世界里(总体),往往存在无限多个点,平面中任意一条直线,随便转一转动一动,就能产生一个不同的E_{out}E_{out}来。E_{in}E_{in}的可能取值是有限个的,而E_{out}E_{out}的可能取值是无限的,无法直接套用union bound,我们得先把上面那个无限多种可能的E_{out}E_{out}换掉。那么如何把E_{out}E_{out}变成有限个呢?
假设我们能从总体当中再获得一份NN笔的验证资料(verification set)\mathcal{D}’\mathcal{D}’,对于任何一个hh我们可以算出它作用于\mathcal{D}’\mathcal{D}’上的E_{in}^{‘}E_{in}^{‘},由于\mathcal{D}’\mathcal{D}’也是总体的一个样本,因此如果E_{in}E_{in}和E_{out}E_{out}离很远,有非常大的可能E_{in}E_{in}和E_{in}^{‘}E_{in}^{‘}也会离得比较远。

事实上当N很大的时候,E_{in}E_{in}和E_{in}^{‘}E_{in}^{‘}可以看做服从以E_{out}E_{out}为中心的近似正态分布(Gaussian),如上图。[|E_{in}-E_{out}|\text{ is large}][|E_{in}-E_{out}|\text{ is large}]这个事件取决于\mathcal{D}\mathcal{D},如果[|E_{in}-E_{out}|\text{ is large}][|E_{in}-E_{out}|\text{ is large}],则如果我们从总体中再抽一份\mathcal{D}^{‘}\mathcal{D}^{‘}出来,有50%左右的可能性会发生[|E_{in}-E_{in}^{‘}|\text{ is large}][|E_{in}-E_{in}^{‘}|\text{ is large}],还有大约50%的可能[|E_{in}-E_{in}^{‘}|\text{ is not large}][|E_{in}-E_{in}^{‘}|\text{ is not large}]。
因此,我们可以得到\mathbb{P}[|E_{in}-E_{out}|\text{ is large}]\mathbb{P}[|E_{in}-E_{out}|\text{ is large}]的一个大概的上界可以是2\mathbb{P}[|E_{in}-E_{in}^{‘}|\text{ is large}]2\mathbb{P}[|E_{in}-E_{in}^{‘}|\text{ is large}],以此为启发去寻找二者之间的关系。
引理:
(1-2e^{-\frac{1}{2}\epsilon^2N})\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon]\leq \mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{‘}(h)| \gt \frac{\epsilon}{2}](1-2e^{-\frac{1}{2}\epsilon^2N})\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon]\leq \mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{‘}(h)| \gt \frac{\epsilon}{2}]
上面的不等式是从何而来的呢?我们先从RHS出发:
\begin{aligned} &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &\geq \mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2} \mathbf{\;and\;} \underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &=\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \;\times \\\ &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\;\;\;\,\text{(注:sup - 上确界,最小上界。)} \end{aligned}\begin{aligned} &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &\geq \mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2} \mathbf{\;and\;} \underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &=\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \;\times \\\ &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\;\;\;\,\text{(注:sup - 上确界,最小上界。)} \end{aligned}
上式第二行的不等号可以由\mathbb{P}[\mathcal{B}_1]\geq \mathbb{P}[\mathcal{B}_1 \textbf{ and } \mathcal{B}_2]\mathbb{P}[\mathcal{B}_1]\geq \mathbb{P}[\mathcal{B}_1 \textbf{ and } \mathcal{B}_2]得到,第三、四行则是贝叶斯公式,联合概率等于先验概率与条件概率之积。
下面来看看不等式的最后一项:
\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{‘}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon]\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{‘}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon]。对于一个固定的data set \mathcal{D}\mathcal{D}来说,我们任选一个h^{*}h^{*}使得|E_{in}(h^{*})-E_{out}(h^{*})|\gt \epsilon|E_{in}(h^{*})-E_{out}(h^{*})|\gt \epsilon,注意到这个h^{*}h^{*}只依赖于\mathcal{D}\mathcal{D}而不依赖于\mathcal{D}^{‘}\mathcal{D}^{‘}噢,对于\mathcal{D}^{‘}\mathcal{D}^{‘}来说可以认为这个h^{*}h^{*} is forced to pick out。
由于h^{*}h^{*}是对于\mathcal{D}\mathcal{D}来说满足|E_{in}-E_{out}|\gt \epsilon|E_{in}-E_{out}|\gt \epsilon的任意一个hypothesis,因此可以把式子中的上确界(sup)先去掉。
\begin{aligned} &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq \mathbb{P}[|E_{in}(h^{*})-E_{in}^{'}(h^{*})| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \end{aligned}\begin{aligned} &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq \mathbb{P}[|E_{in}(h^{*})-E_{in}^{'}(h^{*})| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \end{aligned}
这里就要稍微出动一下前人的智慧了:
\left.\begin{matrix} |E_{in}^{'} - E_{out}|\leq \frac{\epsilon}{2}\\\ |E_{in}-E_{out}| \gt \epsilon \end{matrix}\right\} \Rightarrow |E_{in}-E_{in}^{'}| \gt \frac{\epsilon}{2}\left.\begin{matrix} |E_{in}^{'} - E_{out}|\leq \frac{\epsilon}{2}\\\ |E_{in}-E_{out}| \gt \epsilon \end{matrix}\right\} \Rightarrow |E_{in}-E_{in}^{'}| \gt \frac{\epsilon}{2}
为了直观一点h^{*}h^{*}就不写了。经过各种去掉绝对值符号又加上绝对值符号的运算,可以发现LHS的两个不等式是RHS那个不等式的充分非必要条件。而LHS第二个不等式是已知的,对于h^{*}h^{*}必成立的。因此我们拿LHS这个充分非必要条件去替换RHS这个不等式,继续前面的不等式:
\begin{aligned} &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq \mathbb{P}[|E_{in}(h^{*})-E_{in}^{'}(h^{*})| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq \mathbb{P}[|E_{in}^{'}(h^{*})-E_{out}(h^{*})| \leq \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq 1-2e^{-\frac{1}{2}\epsilon^2N} \end{aligned} \begin{aligned} &\;\;\;\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq \mathbb{P}[|E_{in}(h^{*})-E_{in}^{'}(h^{*})| \gt \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq \mathbb{P}[|E_{in}^{'}(h^{*})-E_{out}(h^{*})| \leq \frac{\epsilon}{2}\;\;|\;\;\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon] \\\ &\geq 1-2e^{-\frac{1}{2}\epsilon^2N} \end{aligned}
最后一个不等号动用了Hoeffding Inequality:
\begin{aligned} &\;\;\;\,\mathbb{P}[|...|\gt \epsilon]\leq 2Mexp(-2\epsilon^2N) \\\ &\Leftrightarrow 1-\mathbb{P}[|...|\gt \epsilon]\geq 1-2Mexp(-2\epsilon^2N) \\\ &\Leftrightarrow \mathbb{P}[|...|\leq \epsilon]\geq 1-2Mexp(-2\epsilon^2N) \end{aligned} \begin{aligned} &\;\;\;\,\mathbb{P}[|...|\gt \epsilon]\leq 2Mexp(-2\epsilon^2N) \\\ &\Leftrightarrow 1-\mathbb{P}[|...|\gt \epsilon]\geq 1-2Mexp(-2\epsilon^2N) \\\ &\Leftrightarrow \mathbb{P}[|...|\leq \epsilon]\geq 1-2Mexp(-2\epsilon^2N) \end{aligned}
之前说过对于\mathcal{D}^{‘}\mathcal{D}^{‘}来说,h^{*}h^{*} is forced to pick out,因此M=1M=1。接着把\epsilon\epsilon替换为\frac{\epsilon}{2}\frac{\epsilon}{2},就成了\mathbb{P}[|…|\lt \frac{\epsilon}{2}]\geq 2exp(-\frac{1}{2}\epsilon^2N)\mathbb{P}[|…|\lt \frac{\epsilon}{2}]\geq 2exp(-\frac{1}{2}\epsilon^2N)。则我们可以得到引理中的不等式。
对于e^{-\frac{1}{2}e^2N}e^{-\frac{1}{2}e^2N},一个比较合理的要求是e^{-\frac{1}{2}\epsilon^2N}\lt \frac{1}{4}e^{-\frac{1}{2}\epsilon^2N}\lt \frac{1}{4},譬如我们有400笔资料,想要E_{in}E_{in}和E_{out}E_{out}相差不超过0.1。注意到这只是一个bound,只要要求不太过分,也不能太宽松即可,适当的宽松一点是OK的。当然这里也是想跟之前所说的 “\mathbb{P}[|E_{in}-E_{out}|\text{ is large}]\mathbb{P}[|E_{in}-E_{out}|\text{ is large}]的一个大概的上界可以是2\mathbb{P}[|E_{in}-E_{in}^{‘}|\text{ is large}]2\mathbb{P}[|E_{in}-E_{in}^{‘}|\text{ is large}]” 当中的2倍有所结合。
所以就有1-2e^{-\frac{1}{2}e^2N}\gt \frac{1}{2}1-2e^{-\frac{1}{2}e^2N}\gt \frac{1}{2}。带回引理,可得:
\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon]\leq 2\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{‘}(h)| \gt \frac{\epsilon}{2}]\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{out}(h)| \gt \epsilon]\leq 2\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{‘}(h)| \gt \frac{\epsilon}{2}]
这样一来我们就把无限多种的E_{out}E_{out}换成了有限多种的E_{in}E_{in},因为\mathcal{D}\mathcal{D}与\mathcal{D}^{‘}\mathcal{D}^{‘}的大小相等,都为NN,因此我们手中一共有2N2N笔数据,这样\mathcal{H}\mathcal{H}作用于\mathcal{D}+\mathcal{D}^{‘}\mathcal{D}+\mathcal{D}^{‘}最多能产生m_{\mathcal{H}}(2N)m_{\mathcal{H}}(2N)种dichotomies。此时我们针对上面的不等式,就又可以使用union bound了。
\begin{aligned} \mathbb{P}[BAD] &\leq 2\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &\leq 2\,m_{\mathcal{H}}(2N)\,\mathbb{P}[\text{fixed } \textit{h} \text{ s.t. } |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &\text{(用固定的hypothesis去看$E_{in}$与$E_{in}^{'}$的差别。)} \end{aligned}\begin{aligned} \mathbb{P}[BAD] &\leq 2\,\mathbb{P}[\underset{h\in \mathcal{H}}{sup}\ |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &\leq 2\,m_{\mathcal{H}}(2N)\,\mathbb{P}[\text{fixed } \textit{h} \text{ s.t. } |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &\text{(用固定的hypothesis去看$E_{in}$与$E_{in}^{'}$的差别。)} \end{aligned}
前面的动作相当于先从总体中抽出2N2N笔数据,把这2N2N笔数据当成一个比较小的bin,然后在这个bin中抽取N<script type="math/tex">N</script>笔作为\mathcal{D}\mathcal{D},剩下的NN笔作为\mathcal{D}^{‘}\mathcal{D}^{‘},\mathcal{D}\mathcal{D}和\mathcal{D}^{‘}\mathcal{D}^{‘}之间是没有交集的。在我们想象出来的这个small bin当中,整个bin的错误率为\frac{E_{in}+E_{out}}{2}\frac{E_{in}+E_{out}}{2},又因为:
|E_{in}-E_{in}^{‘}|\gt \frac{\epsilon}{2} \Leftrightarrow |E_{in} - \frac{E_{in}+E_{in}^{‘}}{2}|\gt \frac{\epsilon}{4}|E_{in}-E_{in}^{‘}|\gt \frac{\epsilon}{2} \Leftrightarrow |E_{in} - \frac{E_{in}+E_{in}^{‘}}{2}|\gt \frac{\epsilon}{4}
所以用RHS替换LHS之后,前面不等式就又可以使用Hoeffding inequality了:
\begin{aligned} \mathbb{P}[BAD] &\leq 2\,m_{\mathcal{H}}(2N)\,\mathbb{P}[\text{fixed } \textit{h} \text{ s.t. } |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &=2\,m_{\mathcal{H}}(2N)\,\mathbb{P}[\text{fixed } \textit{h} \text{ s.t. } |E_{in}(h)-\frac{E_{in}(h)+E_{in}^{'}(h)}{2}| \gt \frac{\epsilon}{4}]\\\ &\;\;\;\text{(Hoeffding without replacement)} \\\ &\leq 2\,m_{\mathcal{H}}(2N)\cdot 2\,exp(-2(\frac{\epsilon}{4})^2N) \end{aligned} \begin{aligned} \mathbb{P}[BAD] &\leq 2\,m_{\mathcal{H}}(2N)\,\mathbb{P}[\text{fixed } \textit{h} \text{ s.t. } |E_{in}(h)-E_{in}^{'}(h)| \gt \frac{\epsilon}{2}] \\\ &=2\,m_{\mathcal{H}}(2N)\,\mathbb{P}[\text{fixed } \textit{h} \text{ s.t. } |E_{in}(h)-\frac{E_{in}(h)+E_{in}^{'}(h)}{2}| \gt \frac{\epsilon}{4}]\\\ &\;\;\;\text{(Hoeffding without replacement)} \\\ &\leq 2\,m_{\mathcal{H}}(2N)\cdot 2\,exp(-2(\frac{\epsilon}{4})^2N) \end{aligned}
这上面千辛万苦得出来的这个bound就叫做Vapnik-Chervonenkis (VC) bound:
\begin{aligned} \mathbb{P}[BAD] &= \mathbb{P}[\exists h \in \mathcal{H}\text{ s.t. } |E_{in}(h)-E_{out}(h)|\gt \epsilon] \\\ &\leq 4m_{\mathcal{H}}(2N)exp(-\frac{1}{8}\epsilon^2N) \end{aligned}\begin{aligned} \mathbb{P}[BAD] &= \mathbb{P}[\exists h \in \mathcal{H}\text{ s.t. } |E_{in}(h)-E_{out}(h)|\gt \epsilon] \\\ &\leq 4m_{\mathcal{H}}(2N)exp(-\frac{1}{8}\epsilon^2N) \end{aligned}
Lecture 7: The VC Dimension
1.Definition of VC Dimension
上节课讲到了VC Dimension以及VC Bound。VC Bound所描述的是在给定数据量N以及给定的Hypothesis Set的条件下,遇到坏事情的概率的上界,即E_{in}E_{in}与E_{out}E_{out}差很远的概率,最多是多少。VC Bound用公式表示就是:
\begin{aligned} \mathbb{P}[BAD] &= \mathbb{P}[\exists h \in \mathcal{H}\text{ s.t. } |E_{in}(h)-E_{out}(h)|\gt \epsilon] \\\ &\leq 4m_{\mathcal{H}}(2N)exp(-\frac{1}{8}\epsilon^2N) \end{aligned} \begin{aligned} \mathbb{P}[BAD] &= \mathbb{P}[\exists h \in \mathcal{H}\text{ s.t. } |E_{in}(h)-E_{out}(h)|\gt \epsilon] \\\ &\leq 4m_{\mathcal{H}}(2N)exp(-\frac{1}{8}\epsilon^2N) \end{aligned}
其中m_{\mathcal{H}}(N)m_{\mathcal{H}}(N)为Hypothesis Set的成长函数,有:
2.VC Dimension of Perceptrons
对于以下几个\mathcal{H}\mathcal{H},由于之前我们已经知道了他们的成长函数(见机器学习笔记-VC Dimension, Part I),因此可以根据m_{\mathcal{H}}(N)\leq N^{d_{vc}}m_{\mathcal{H}}(N)\leq N^{d_{vc}},直接得到他们的VC Dimension:
- positive rays: m_{\mathcal{H}}(N)=N+1m_{\mathcal{H}}(N)=N+1,看N的最高次项的次数,知道d_{vc}=1d_{vc}=1
- positive intervals: m_{\mathcal{H}}(N)=\frac{1}{2}N^2+\frac{1}{2}N+1m_{\mathcal{H}}(N)=\frac{1}{2}N^2+\frac{1}{2}N+1,d_{vc}=2d_{vc}=2
- convex sets: m_{\mathcal{H}}(N)=2^Nm_{\mathcal{H}}(N)=2^N,d_{vc}=\inftyd_{vc}=\infty
- 2D Perceptrons: m_{\mathcal{H}}(N)\leq N^3\;for\;N\geq 2m_{\mathcal{H}}(N)\leq N^3\;for\;N\geq 2,所以d_{vc}=3d_{vc}=3
由于convex sets的d_{vc}=\inftyd_{vc}=\infty,不满足上面所说的第1个条件,因此不能用convex sets这个\mathcal{H}\mathcal{H}来学习。
但这里要回归本意,通过成长函数来求得d_{vc}d_{vc}没有太大的意义,引入d_{vc}d_{vc}很大的一部分原因是,我们想要得到某个Hypothesis Set的成长函数是困难的,希望用N^{d_{vc}}N^{d_{vc}}来bound住对应的m_{\mathcal{H}}(N)m_{\mathcal{H}}(N)。对于陌生的\mathcal{H}\mathcal{H},如何求解它的d_{vc}d_{vc}呢?
3. Physical Intuition of VC Dimension
对于d_{vc}d_{vc}较小的\mathcal{H}\mathcal{H},可以从它最多能够shatter的点的数量,得到d_{vc}d_{vc},但对于一些较为复杂的模型,寻找能够shatter掉的点的数量,就不太容易了。此时我们可以通过模型的自由度,来近似的得到模型的d_{vc}d_{vc}。
维基百科上有不止一个关于自由度的定义,每种定义站在的角度不同。在这里,我们定义自由度是,模型当中可以自由变动的参数的个数,即我们的机器需要通过学习来决定模型参数的个数。
譬如:
- Positive Rays,需要确定1个threshold,这个threshold就是机器需要根据\mathcal{D}\mathcal{D}来确定的一个参数,则Positive Rays中自由的参数个数为1,
- Positive Intervals,需要确定左右2个thresholds,则可以由机器自由决定的参数的个数为2,d_{vc}=2d_{vc}=2
- d-D Perceptrons,dd维的感知机,可以由机器通过学习自由决定的参数的个数为d+1d+1(别忘了还有个w_0w_0),d_{vc}=d+1d_{vc}=d+1
###4. Interpreting VC Dimension
我们一开始就提到,learning的问题应该关注的两个最重要的问题是:1.能不能使E_{in}E_{in}与E_{out}E_{out}很接近,2.能不能使E_{in}E_{in}足够小。
- 对于相同的\mathcal{D}\mathcal{D}而言,d_{vc}d_{vc}小的模型,其VC Bound比较小,比较容易保证E_{in}E_{in}与E_{out}E_{out}很接近,但较难做到小的E_{in}E_{in},试想,对于2D Perceptron,如果规定它一定要过原点(d_{vc}=2d_{vc}=2),则它就比没有规定要过原点(d_{vc}=3d_{vc}=3)的直线更难实现小的E_{in}E_{in},因为可选的方程更少。2维平面的直线,就比双曲线(d_{vc}=6d_{vc}=6),更难实现小的E_{in}E_{in}。
- 对于相同的\mathcal{D}\mathcal{D}而言,d_{vc}d_{vc}大的模型,比较容易实现小的E_{in}E_{in},但是其VC Bound就会很大,很难保证模型对\mathcal{D}\mathcal{D}之外的世界也能有同样强的预测能力。
令之前得到的VC Bound为\delta\delta,坏事情[|E_{in}(g)-E_{out}(g)|\gt \epsilon][|E_{in}(g)-E_{out}(g)|\gt \epsilon]发生的概率小于\delta\delta,则好事情[|E_{in}(g)-E_{out}(g)|\leq \epsilon][|E_{in}(g)-E_{out}(g)|\leq \epsilon]发生的概率就大于1-\delta1-\delta,这个1-\delta1-\delta在统计学中又被称为置信度,或信心水准。
\begin{aligned} \text{set}\;\;\;\;\delta &= 4(2N)^{d_{vc}}exp(-\frac{1}{8}\epsilon^2N)\\\ \sqrt{\frac{8}{N}ln(\frac{4(2N)^{d_{vc}}}{\delta})} &= \epsilon \end{aligned} \begin{aligned} \text{set}\;\;\;\;\delta &= 4(2N)^{d_{vc}}exp(-\frac{1}{8}\epsilon^2N)\\\ \sqrt{\frac{8}{N}ln(\frac{4(2N)^{d_{vc}}}{\delta})} &= \epsilon \end{aligned}
因此E_{in}E_{in}、E_{out}E_{out}又有下面的关系:
mode=display">E_{in}(g)-\sqrt{\frac{8}{N}ln(\frac{4(2N)^{d_{vc}}}{\delta})} \leq E_{out}(g) \leq E_{in}(g)+\sqrt{\frac{8}{N}ln(\frac{4(2N)^{d_{vc}}}{\delta})} mode=display">E_{in}(g)-\sqrt{\frac{8}{N}ln(\frac{4(2N)^{d_{vc}}}{\delta})} \leq E_{out}(g) \leq E_{in}(g)+\sqrt{\frac{8}{N}ln(\frac{4(2N)^{d_{vc}}}{\delta})}
令\Omega (N,\mathcal{H},\delta)=\sqrt{…}\Omega (N,\mathcal{H},\delta)=\sqrt{…},即上式的根号项为来自模型复杂度的,模型越复杂,E_{in}E_{in}与E_{out}E_{out}离得越远。
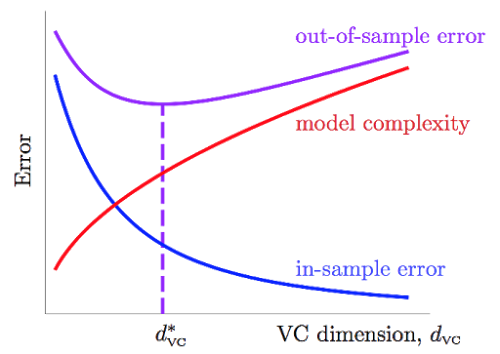
随着d_{vc}d_{vc}的上升,E_{in}E_{in}不断降低,而\Omega\Omega项不断上升,他们的上升与下降的速度在每个阶段都是不同的,因此我们能够寻找一个二者兼顾的,比较合适的d_{vc}^{*}d_{vc}^{*},用来决定应该使用多复杂的模型。
反过来,如果我们需要使用d_{vc}=3d_{vc}=3这种复杂程度的模型,并且想保证\epsilon = 0.1\epsilon = 0.1,置信度1-\delta =90\%1-\delta =90\%,我们也可以通过VC Bound来求得大致需要的数据量NN。通过简单的计算可以得到理论上,我们需要N\approx 10,000d_{vc}N\approx 10,000d_{vc}笔数据,但VC Bound事实上是一个极为宽松的bound,因为它对于任何演算法\mathcal{A}\mathcal{A},任何分布的数据,任何目标函数ff都成立,所以经验上,常常认为N\approx 10d_{vc}N\approx 10d_{vc}就可以有不错的结果。
Lecture 8: Noise and Error
1.Noise and Probabilistic Target
我们机器学习的基本过程是,首先,我们认为有一个未知的关系ff存在于DD中,而DD中的yy就是作用于xx产生的,虽然我们并不知道ff,但是我们可以找到一个和ff差不多的g函数,我们就算学到东西了。但是在现实世界中,我们所观察到的DDDDD并不是它原本的样子,都会有noise的存在,在learning中,noise主要表现为以下三种形式:
- noise in y: 例如被标记成圈圈的叉叉
- noise in y: 相同的xx,却有不同的yy
- noise in x: xx之中本就含有错误
ff本是一个确定性的模型,但是加上随机的noise,它们共同作用,就是一个概率性的结果:
\left.\begin{array}{1} \text{idea mina-target$f(x)=1$}\\ \text{"flipping" noise $level = 0.3$} \end{array} \right\}\Rightarrow \begin{array}{1} P(+1|x)=0.7 P(-1|x)=0.3 \end{array} \left.\begin{array}{1} \text{idea mina-target$f(x)=1$}\\ \text{"flipping" noise $level = 0.3$} \end{array} \right\}\Rightarrow \begin{array}{1} P(+1|x)=0.7 P(-1|x)=0.3 \end{array}
对于某个样本xx,理想状态下,应该有y=f(x)=+1y=f(x)=+1,但是由于noise的存在,该noise有30%的可能性转换f(x)f(x)的结果。因此在mathcal{D}mathcal{D}中,该样本有70%的几率表现出y=+1y=+1,有30%的几率表现出y=-1y=-1。
再举个例子来对比不考虑noise的情况和考虑noise的情况的区别。假设不存在noisede情况下某个h<script type="math/tex">h</script>在mathcal{D}mathcal{D}中的错误率E_{in}=\muE_{in}=\mu。再加上一个\text{‘flipping’ noise level} =1−λ\text{‘flipping’ noise level} =1−λ的noise,即:
P(y|x)= \left\{\begin{matrix} \lambda & y=f(x)\\\ 1-\lambda & y\neq f(x) \end{matrix}\right. P(y|x)= \left\{\begin{matrix} \lambda & y=f(x)\\\ 1-\lambda & y\neq f(x) \end{matrix}\right.
假设\mathcal{D}\mathcal{D}中的noise样本有NN个:
\begin{matrix}& \text{no noise} & \text{noise}\\\ h\text{ on }\mathcal{D} & \left\{\begin{matrix} (1-\mu)N & right\\ \\ \\ \mu N& wrong \end{matrix}\right. & \begin{matrix} \left\{\begin{matrix} \lambda(1-\mu)N & \text{true right}\\ (1-\lambda)(1-\mu)N & \text{false right} \end{matrix}\right.\\ \\ \left\{\begin{matrix} \lambda \mu N & \text{true wrong}\\ (1-\lambda)\mu N & \text{false wrong} \end{matrix}\right. \end{matrix} \end{matrix}\begin{matrix}& \text{no noise} & \text{noise}\\\ h\text{ on }\mathcal{D} & \left\{\begin{matrix} (1-\mu)N & right\\ \\ \\ \mu N& wrong \end{matrix}\right. & \begin{matrix} \left\{\begin{matrix} \lambda(1-\mu)N & \text{true right}\\ (1-\lambda)(1-\mu)N & \text{false right} \end{matrix}\right.\\ \\ \left\{\begin{matrix} \lambda \mu N & \text{true wrong}\\ (1-\lambda)\mu N & \text{false wrong} \end{matrix}\right. \end{matrix} \end{matrix}
因此,如果存在noise,则hh判断错误的概率是:
E_{in }= \lambda\mu+(1-\lambda)(1-\mu)=(2\lambda-1)\mu+(1-\lambda) E_{in }= \lambda\mu+(1-\lambda)(1-\mu)=(2\lambda-1)\mu+(1-\lambda)
由此可见noise对于E_(in)E_(in)是有影响的,在noise存在且较大的情况下,算出的E_(in)E_(in)会与实际的E_(in)E_(in)有较大差别,故\mathcal{D}\mathcal{D}的质量也会影响ML的效果。
2.Error Measure
我们在把learning的工作交给机器的时候,必须让机器明白你学习的目标,比如你想让什么什么最大化,或者什么什么最小化。通常的做法是把每一个预测值与真实值之间的误差(error)看成一种成本,机器要做的,就是在HH中,挑选一个能使总成本最低的函数(cost function)。
之前提到的二元分类就是对判断错误的点,记误差为1,判断正确的点,记误差为0:
\text{error of h on }x_n \left\{\begin{matrix} 1 & h(x_n)\neq y_n\\\ 0 & h(x_n) = y_n \end{matrix}\right. \text{error of h on }x_n \left\{\begin{matrix} 1 & h(x_n)\neq y_n\\\ 0 & h(x_n) = y_n \end{matrix}\right.
不管是把y=+1的猜错成−1,或是把y=−1的猜错成+1,其产生的误差都为1。
在实际应用中,这个误差的定义可以很灵活,例如下面两个指纹验证的例子:
1.超市利用指纹识别判断某个人是否是他们的会员,若是会员会给相应的折扣。这种情形下,可能做出两种不同的错误判断,把非会员错认为是会员,把会员错认为是非会员。但对于超市来说,这两种错误的成本应该是不同的。把非会员错认为是会员,无非损失些许的折扣;但若是把会员识别为非会员从而不给折扣,就会导致顾客的不满,从而损失掉了未来的生意。针对这种需求,或许下面这个error的衡量办法会更加合理一些。把+1(会员)错判为-1(非会员)的error为10,把-1错判为+1的error为1。
2.中情局的门禁系统,利用指纹判断是内部工作人员,才允许进入。这种情形下,若是把好人当坏人,代价并不高,无非就是请工作人员多按一次指纹的功夫,但如果把坏人当好人,损失可就大了。针对这种需求,下面这个error的衡量办法可能更加合理。
之前一直说的Ein(h),就是h作用于D中每一笔数据,所产生的成本之和:
E_{in}(h)=\frac{1}{N}\sum_{n=1}^{N}err(h,x_n,y_n)E_{in}(h)=\frac{1}{N}\sum_{n=1}^{N}err(h,x_n,y_n)
对于上面中情局的例子,err(h,xn,yn)err(h,xn,yn)的定义如下:
err(h,x_n,y_n)=\left\{\begin{matrix} 1 & h(x_n)\neq y_n,y_n=+1 \\\ 1000 & h(x_n)\neq y_n,y_n=-1 \end{matrix}\right.err(h,x_n,y_n)=\left\{\begin{matrix} 1 & h(x_n)\neq y_n,y_n=+1 \\\ 1000 & h(x_n)\neq y_n,y_n=-1 \end{matrix}\right.
这种误差衡量方式称为”pointwise measure”,即对每个点记录误差,总误差为所有点产生的误差之和。在Ng那门课上,这个Ein(h)Ein(h)被称为cost function,通过cost function可以计算出当前h<script type="math/tex">h</script>作用于\mathcal{D}\mathcal{D}所造成的总成本,通过learning找到一个能够使总成本最小的hh,就完成了学习的过程。
3.Algorithmic Error Measure
针对不同的问题与不同的使用环境,我们可以设计不同的误差衡量方法,下面是集中常见的误差的定义:
- 0/1 error ,通常用于分类问题:
err(\widetilde{y},y)=[\widetilde{y}\neq y]err(\widetilde{y},y)=[\widetilde{y}\neq y] - squared error,通常用于回归问题:
err(\widetilde{y},y)=[\widetilde{y}- y]^2err(\widetilde{y},y)=[\widetilde{y}- y]^2 - absolute error:
err(\widetilde{y},y)=abs[\widetilde{y}- y]err(\widetilde{y},y)=abs[\widetilde{y}- y]
4.Weighted Classification
总结一下,先根据问题的不同选择合适的误差衡量方式,0/1 error还是squared error或者是其他针对某一场景特殊设计的error?把h<script type="math/tex">h</script>作用于\mathcal{D}\mathcal{D}中所有点的error加总起来就成了一个cost function,也就是E_{in}(h)E_{in}(h),接着要设计一个最优化算法\mathcal{A}\mathcal{A},它能够从h<script type="math/tex">h</script>中挑选出能够使E_{in}E_{in}最小的方程g,learning就完成了。对于不同类型的cost function,通常会使用不同的最优化算法。对于某些cost function,很容易实现E_{in}E_{in}最小,比如之后会说的线性回归。对于某些cost function,寻找最小的E_{in}E_{in}是困难的,回忆之前说的PLA,用0/1 error来衡量误差,要minimize E_{in}E_{in}就是个NP Hard问题。
当然除此之外,cost function中还可以增加一些来自于error之外的成本,以达到限制模型复杂度方面的目的,如ridge regression、lasso等,这些以后有机会都会提到。
Lecture 9: Linear Regression
1.Linear Regression Problem
之前我们利用银行审核顾客信用卡申请的案例引出机器学习的整个框架图,当时我们涉及的是二元分类(是否给予信用卡),也即是输出空间
\mathcal{Y} = \{+1, -1\}\mathcal{Y} = \{+1, -1\}
接着上面,当现在我们讨论给予顾客多少信用额度的的时候,也即是输出空间为
\mathcal{Y} = \Bbb{R}\mathcal{Y} = \Bbb{R}
时,,该怎么做呢?一个简单的想法则是:将Linear Classification的决策函数中的sign函数去掉,直接用顾客的特征的加权分数作为输出
y \approx \sum_{i = 0}^{d} W_i X_iy \approx \sum_{i = 0}^{d} W_i X_i
从这里我们引申出我们这次要讲的线性回归的hypothesis
h(X) = W^TXh(X) = W^TX
而线性回归的目标则是学习拥有最小误差的一条直线或者一个平面,以便我们未来的预测。
对于线性回归的误差函数我们通常用均方误差
E_{in}(hW) = \frac{1}{N} \sum_{n = 1}^{N} \left(h(X_n) - y_n\right)^2E_{in}(hW) = \frac{1}{N} \sum_{n = 1}^{N} \left(h(X_n) - y_n\right)^2
2.Linear Regression Algorithm
接下来我们讨论线性回归算法,也即是如何最小化E_{in}E_{in}。
对E_{in}E_{in}进行展开
\begin{split} E_{in}(W) &= \frac{1}{N} \sum_{n = 1}^{N} \left(h(X_n) - y_n\right)^2 \\ &= \frac{1}{N} \Bigg\Vert \begin{matrix} X_1^TW - y_1 \\ X_2^TW - y_2 \\ \cdot \cdot \cdot \\ X_N^TW - y_N \\ \end{matrix} \Bigg\Vert^2 \\ &= \frac{1}{N} \Vert X W - y \Vert^2 \end{split} \begin{split} E_{in}(W) &= \frac{1}{N} \sum_{n = 1}^{N} \left(h(X_n) - y_n\right)^2 \\ &= \frac{1}{N} \Bigg\Vert \begin{matrix} X_1^TW - y_1 \\ X_2^TW - y_2 \\ \cdot \cdot \cdot \\ X_N^TW - y_N \\ \end{matrix} \Bigg\Vert^2 \\ &= \frac{1}{N} \Vert X W - y \Vert^2 \end{split}
学习的目标则是
\mathop{min}\limits_{W} E_{in}(W) = \frac{1}{N} \Vert X W - y \Vert^2 \mathop{min}\limits_{W} E_{in}(W) = \frac{1}{N} \Vert X W - y \Vert^2
E_{in}(W)E_{in}(W)是一个连续、可微的凸函数。于是WW的最优化问题可转化为:找到一个W_{LIN}W_{LIN}使得\nabla E_{in} (W_{LIN}) = 0\nabla E_{in} (W_{LIN}) = 0。而
\nabla E_{in} (W) = \frac{2}{N} (X^TXW - X^Ty)\nabla E_{in} (W) = \frac{2}{N} (X^TXW - X^Ty)
当X^TXX^TX可逆的时候,易得
W_{LIN} = \left( X^TX \right) ^ {-1} X^T yW_{LIN} = \left( X^TX \right) ^ {-1} X^T y
其中
\left( X^TX \right) ^ {-1} X^T = X^{\dagger}\left( X^TX \right) ^ {-1} X^T = X^{\dagger}
当X^TXX^TX不可逆的时候,我们也有其他的最优化方法,其中一种则是用一些特定的方法定义X^\daggerX^\dagger
至此,我们可以定义线性回归算法如下
1.从数据集\mathcal{D}\mathcal{D}中构造输入矩阵 XX 和输出向量 yy
2.计算伪逆矩阵 X^\daggerX^\dagger
3.返回 W_{LIN} = X^{\dagger} yW_{LIN} = X^{\dagger} y
3.Generalization Issue
乍一看,线性回归“不算是”机器学习算法,更像是分析型方法,而且我们有确定的公式来求解W<script type="math/tex">W</script>。
实际上,线性回归属于机器学习算法:
1.对 E_{in}E_{in} 进行优化。
2.得到 E_{out}E_{out} 约等于 E_{in}E_{in}。
3.本质上还是迭代提高的:pseudo-inverse 内部实际是迭代进行的。
得到了 W_{LIN}W_{LIN},用于未知数据的预测时,
\hat{y} = X W_{LIN} = X X^\dagger y\hat{y} = X W_{LIN} = X X^\dagger y
这里又称X X^\dagger=HX X^\dagger=H为hat matrix。
\hat{y}={X}{w_{LIN}}\hat{y}={X}{w_{LIN}}是XX的一个线性组合,即\hat{y}\hat{y}在XX中的d + 1d + 1个向量构成的一个d + 1d + 1维的span上。而hat matrixHH即是把yy投影到span上的\hat{y}\hat{y}。易得HH有如下性质
1.对称性 H = H^TH = H^T
2.幂等性 H^2 = HH^2 = H
3.半正定性 \lambda_i \ge 0\lambda_i \ge 0
且对于HH有
trace(I-{H}) = N-(d+1)trace(I-{H}) = N-(d+1)
假设
y = noise + \mathcal{f}(x)\ , \mathcal{f}(x) \in spany = noise + \mathcal{f}(x)\ , \mathcal{f}(x) \in span
之前讲到HH作用于某个向量,会得到此向量在span上的投影,则I - HI - H作用于某个向量,则会得到与span垂直的向量。即
(I-{H})noise={y-\hat{y}}(I-{H})noise={y-\hat{y}}
其中,{y-\hat{y}}{y-\hat{y}}是真实值与预测值的差,其长度就是就是所有点的平方误差之和。于是就有
\begin{aligned} E_{in}({w_{LIN}})&=\frac{1}{N}||{y-\hat{y}}||^2\\\ &=\frac{1}{N}||(I-{H})noise||^2 \\\ &=\frac{1}{N}trace(I-{H})||noise||^2 \\\ &=\frac{1}{N}(N-(d+1))||noise||^2 \end{aligned}\begin{aligned} E_{in}({w_{LIN}})&=\frac{1}{N}||{y-\hat{y}}||^2\\\ &=\frac{1}{N}||(I-{H})noise||^2 \\\ &=\frac{1}{N}trace(I-{H})||noise||^2 \\\ &=\frac{1}{N}(N-(d+1))||noise||^2 \end{aligned}
因此,就平均而言,有
\begin{aligned} {\overline{E_{in}}}&=\text{noise level}\cdot(1-\frac{d+1}{N})\\\ {\overline{E_{out}}}&=\text{noise level}\cdot(1+\frac{d+1}{N}) \;\;\; \end{aligned}\begin{aligned} {\overline{E_{in}}}&=\text{noise level}\cdot(1-\frac{d+1}{N})\\\ {\overline{E_{out}}}&=\text{noise level}\cdot(1+\frac{d+1}{N}) \;\;\; \end{aligned}
至此,我们从与VC bound不同的一个角度证明了线性回归学习的可行性,即\overline{E_{in}}\overline{E_{in}}和\overline{E_{out}}\overline{E_{out}}都向\sigma^2\sigma^2(noise level)收敛,并且他们之间的差异被\frac{2(d+1)}{N}\frac{2(d+1)}{N}给bound住了,这种要比VC bound来的更严格一些。
4.Linear Regression for Binary Classification
最后我们讨论线性回归用于线性分类的可行性。上面我们讨论到线性回归的最优化问题是相对容易求解的,而通常来讲直接求解线性分类的最优化问题是很难的,那我们可不可以把线性回归的结果套用sign函数作为线性分类的解呢?答案是肯定的。但是这样做是有一些问题的,我们从图像上比较两者的error function可以看出,均方误差是0/1误差的上限,于是, 通常来讲我们可以把线性回归的解W_{LIN}W_{LIN}作为线性分类的初始值来求解。
Lecture 10: Logistic Regression
1.背景
–
当已知病人的体重,血压,胆固醇等等,从这些指标或者说这些特征预测病人心脏病发生的概率是多少;这里就引出了逻辑回归这个话题。其中体重,血压,胆固醇这些因素就是所谓的 xx ,也就是特征,我们分别赋予这些特征权重 ww ,wxwx 就是每个特征的分数,分数越大,心脏病发生的概率就越大。s=\sum_{i=0}^{d}w_ix_is=\sum_{i=0}^{d}w_ix_i \text{logistic hypothesis:}h(x)=\theta \left({w^Tx}\right) \text{logistic hypothesis:}h(x)=\theta \left({w^Tx}\right)
然后把这些权重归一化到0和1之间:\theta (s)=\frac{e^s}{1+e^s}=\frac{1}{1+e^{-s}}\theta (s)=\frac{e^s}{1+e^s}=\frac{1}{1+e^{-s}} 所以根据以上的式子我们可以得到:
h(x)=\frac{1}{1+exp\left( -w^Tx \right)} h(x)=\frac{1}{1+exp\left( -w^Tx \right)}
2.最大似然估计
已知资料 D=(x_1,x_2,...,x_n)D=(x_1,x_2,...,x_n) 的分布,求它们对应的 yy 的概率分布,我们可以用 h(x)h(x) 的最大似然来估计 yy 或者 gg :g= \mathop{argmax}_{h}\text{likelihood}(h)g= \mathop{argmax}_{h}\text{likelihood}(h)\text{likelihood}(h)=P(x_1)h(x_1)\cdot P(x_2)h(x_2)...P(x_N)h(x_N)\text{likelihood}(h)=P(x_1)h(x_1)\cdot P(x_2)h(x_2)...P(x_N)h(x_N)所以有:
\text{likelihood}(h) \propto\prod\limits_{i=1}^nh(y_nx_n)\text{likelihood}(h) \propto\prod\limits_{i=1}^nh(y_nx_n)所以有:
\max_h \text{likelihood}(h) \propto\prod\limits_{i=1}^nh(y_nx_n)\max_h \text{likelihood}(h) \propto\prod\limits_{i=1}^nh(y_nx_n)所以有:
\max_w \text{likelihood}(h) \propto\prod\limits_{i=1}^n\theta(y_nw^Tx_n)\max_w \text{likelihood}(h) \propto\prod\limits_{i=1}^n\theta(y_nw^Tx_n)我们需要把连乘化为连加,所以可以取对数:
\max_w \ln \prod\limits_{i=1}^n\theta(y_nw^Tx_n)\max_w \ln \prod\limits_{i=1}^n\theta(y_nw^Tx_n)所以有:
\min_w \frac{1}{N} \sum_{n=1}^{N}-\ln \theta(y_nw^Tx_n)\min_w \frac{1}{N} \sum_{n=1}^{N}-\ln \theta(y_nw^Tx_n)即:
\min_w \frac{1}{N} \sum_{n=1}^{N}\ln \left(1+exp\left( -y_nw^Tx_n \right) \right)\min_w \frac{1}{N} \sum_{n=1}^{N}\ln \left(1+exp\left( -y_nw^Tx_n \right) \right)我们称:
\text{err(w,x,y)}=\ln \left(1+exp\left( -y_nw^Tx_n \right) \right)\text{err(w,x,y)}=\ln \left(1+exp\left( -y_nw^Tx_n \right) \right)为cross-entropy error
3.梯度下降法最小化错误
我们需要让错误最小化:E_{in}(w)=\frac{1}{N} \sum_{n=1}^{N}\ln \left(1+exp\left( -y_nw^Tx_n \right) \right)E_{in}(w)=\frac{1}{N} \sum_{n=1}^{N}\ln \left(1+exp\left( -y_nw^Tx_n \right) \right)
对上式求导,我们可以得到它的梯度:\bigtriangledown E_{in}(w)=\frac{1}{N} \sum_{n=1}^{N}\theta(-y_nw^Tx_n)(-y_nx_n)\bigtriangledown E_{in}(w)=\frac{1}{N} \sum_{n=1}^{N}\theta(-y_nw^Tx_n)(-y_nx_n)当梯度为0的时候,我们可以得到错误的最小值。
4.梯度下降法的具体过程
每一轮更新迭代的过程为: w_{t+1}\leftarrow w_t+\eta v w_{t+1}\leftarrow w_t+\eta v 这个式子中的 \eta\eta 是步长,就是下降的过程走多大一步,vv 是梯度下降的方向,就是往哪个方向迭代。
标量场中某一点上的梯度指向标量场增长最快的方向,梯度的长度是这个最大的变化率。基于这一点,函数沿着梯度相反的方向下降最快。所以有:
w_{t+1}\leftarrow w_t-\eta \bigtriangledown E_{in}(w)w_{t+1}\leftarrow w_t-\eta \bigtriangledown E_{in}(w)
Lecture 11: Linear Models for Classification
1.Linear Models for Binary Classification
通过对比我们目前学过的三种线性模型
- linear classification
- linear regression
- logistics regress
如果将三者的分类正确性分数命名为
s = W^T Xs = W^T X则三者的error function可以分别写成如下的形式
\begin{split} err_{0/1} (s, y) &= \{ \begin{matrix} 1 & sign(ys) \ne 1\\ 0 & sign(ys) = 1 \end{matrix}\\ err_{SQR}(s,y) &= (ys - 1)^2\\ err_{SE}(s,y) &= \ln(1 + \exp(-ys)) \end{split}\begin{split} err_{0/1} (s, y) &= \{ \begin{matrix} 1 & sign(ys) \ne 1\\ 0 & sign(ys) = 1 \end{matrix}\\ err_{SQR}(s,y) &= (ys - 1)^2\\ err_{SE}(s,y) &= \ln(1 + \exp(-ys)) \end{split}
将err_{SE}err_{SE}做一个换底的动作,即:
{\text{scaled}}\text{ ce : err}_{{s}ce}({s},{y})={log_2}(1+exp(-{ys})){\text{scaled}}\text{ ce : err}_{{s}ce}({s},{y})={log_2}(1+exp(-{ys}))
我们的问题是能否拿Linear Regression或Logistic Regression来替代Linear Classification?
为什么会想做这样的替代?Linear Classification,在分类这件事上,它做的很好,但在最优化这件事上,由于是NP-hard问题,不大好做,而Linear Regression与Logistic Regression在最优化上比较容易。因此,如果他们在分类能力上的表现能够接近Linear Classification,用他们来替代Linear Classification来处理分类的问题,就是件皆大欢喜的事。这时候就可以想想刚刚为何要把err_{se}err_{se} scale 成err_{0/1}err_{0/1}的upper bound,目的就是为了让这几个模型的观点在某个方向上是一致的,即
err_{sqr}err_{sqr}/err_{sce}err_{sce}低的时候,err_{0/1}err_{0/1}也低
也即是
如果使用err_{sqr}err_{sqr}/err_{sce}err_{sce}来衡量一个模型分类分得好不好的时候,如果它们认为分得好,那么如果使用err_{0/1}err_{0/1},它也会认为分得好。
对比下在处理分类问题时,使用PLA,Linear Regression以及Logistic Regression的优缺点。
PLA:
优点:数据是线性可分时,err_{0/1}err_{0/1}保证可以降到最低
缺点:数据不是线性可分时,要额外使用pocket技巧,较难做最优化
Linear Regression:
优点:在这三个模型中最容易做最优化
缺点:在ys很大或很小时,这个bound是很宽松的,意思就是没有办法保证err_{0/1}err_{0/1}能够很小
Logistic Regression:
优点:较容易最优化
缺点:当ys是很小的负数时,bound很宽松
所以我们常常可以使用Linear Regresion跑出的w作为(PLA/Pocket/Logistic Regression)的W_0W_0,然后再使用W_0W_0来跑其他模型,这样可以加快其他模型的最优化速度。同时,由于拿到的数据常常是线性不可分的,我们常常会去使用Logistic Regression而不是PLA+pocket。
2.Stochastic Gradient Descent
我们知道PLA与Logistic Regression都是通过迭代的方式来实现最优化的,即:
w_{t+1}\leftarrow w_t + \eta v\quad \text{when stop, return last w as g}w_{t+1}\leftarrow w_t + \eta v\quad \text{when stop, return last w as g}
区别在于,PLA每次迭代只需要针对一个点进行错误修正,而Logistic Regression每一次迭代都需要计算每一个点对于梯度的贡献,再把他们平均起来。这样一来,数据量大的时候,由于需要计算每一个点,Logistic Regerssion就会很慢了。
那么我可以不可以每次只看一个点,即不要公式中先求和再取平均数的那个部分呢?随机取一个点n,它对梯度的贡献为{\triangledown _w err(w,x_n,y_n)}{\triangledown _w err(w,x_n,y_n)},我们把它称为随机梯度,stochastic gradient。而真实的梯度,可以认为是随机抽出一个点的梯度值的期望
\triangledown_w E_{in}(w) = {\underset{random\,n}{\epsilon}}\triangledown_w {err(w,x_n,y_n)}\triangledown_w E_{in}(w) = {\underset{random\,n}{\epsilon}}\triangledown_w {err(w,x_n,y_n)}
因此我们可以把随机梯度当成是在真实梯度上增加一个均值为0的noise:
{\text{stochastic gradient}} = {\text{true gradient}} + {\text{zero-mean 'noise' directions}}{\text{stochastic gradient}} = {\text{true gradient}} + {\text{zero-mean 'noise' directions}}
虽然和true gradient存在一定的误差,但是可以认为在足够多的迭代次数之后,也能达到差不多好的结果。我们把这种方法成为随机梯度下降,Stochastic Gradient Descent (SGD)
w_{t+1} \leftarrow w_t + \eta \underbrace{{\theta(\color{black}{-y_nw_t^Tx_n})}{(y_nx_n)}}_{-{\triangledown_{err}(w_t,x_n,y_n)}}w_{t+1} \leftarrow w_t + \eta \underbrace{{\theta(\color{black}{-y_nw_t^Tx_n})}{(y_nx_n)}}_{-{\triangledown_{err}(w_t,x_n,y_n)}}
3.Multiclass via Logistic Regression
我们现在已经有办法使用线性分类器解决二元分类问题,但有的时候,我们需要对多个类别进行分类,即模型的输出不再是0和1两种,而会是多个不同的类别。那么如何套用二元分类的方法来解决多类别分类的问题呢?
利用二元分类器来解决多类别分类问题主要有两种策略,OVA(One vs. ALL)和OVO(One vs. One)。
先来看看OVA,假设原问题有四个类别,那么每次我把其中一个类别当成圈圈,其他所有类别当成叉叉,建立二元分类器,循环下去,最终我们会得到4个分类器。做预测的时候,分别使用这四个分类器进行预测,预测为圈圈的那个模型所代表的类别,即为最终的输出。譬如正方形的那个分类器输出圈圈,菱形、三角形、星型这三个分类器都说是叉叉,则我们认为它是正方形。当然这里可能遇到一个问题,就是所有模型都说不是自己的时候(都输出叉叉),怎么办? 只要让各个分类器都输出是否为自己类别的概率值,即可,然后选择概率值最高的那个分类器所对应的类别,作为最终的输出。
4.Multiclass via Binary Classification
在类别较多的时候,如果使用OVA方法,则又会遇到数据不平衡(unbalance)的问题,拿一个类别作为圈圈,其他所有类别作为叉叉,那么圈圈的比例就会非常小,而叉叉的比例非常高。为了解决这个不平衡的问题,我们可以利用另外一个策略,OVO,即每次只拿两个类别的数据出来建建立分类器。
这个想法类似在打比赛,一笔新数据进来之后,分别使用这六个模型进行预测,得票数最多的那个类别,作为最终的输出。这样做的好处是,有效率,每次只拿两个类别的数据进行训练,每个模型训练数据量要少很多。但是缺点是,由于模型的数量增加了,将消耗更多的存储空间,会减慢预测的速度。
Lecture 12: Nonlinear Transformation
1.背景
对于线性可分的hypothesis,我们可以用线性分类器来分开,但是当hypothesis比较复杂,不是线性可分的时候,我们就要把非线性空间转换到线性空间,这里需要用到转换函数,然后在线性空间进行分类,具体过程如下:x\in\mathcal{X}\mathop{\rightarrow}^{\Phi}z\in \mathcal{Z}x\in\mathcal{X}\mathop{\rightarrow}^{\Phi}z\in \mathcal{Z}例如下面这个例子,把X空间中的圆这个曲线转换到Z空间,使得在Z空间线性可分,那转换函数是:
(z_0,z_1,z_2)=z=\Phi(x)=(1,x_1^2,x_2^2)(z_0,z_1,z_2)=z=\Phi(x)=(1,x_1^2,x_2^2)
从而有:h(x)=sign\left(w^T\Phi(x) \right)=sign\left(w_0,w_1x_1^2,w_2x_2^2 \right)h(x)=sign\left(w^T\Phi(x) \right)=sign\left(w_0,w_1x_1^2,w_2x_2^2 \right)那 xx 前面的系数 ww 变化的话,X 空间中的曲线也会相应的变化,对应到 Z 空间也就不同,比如说有椭圆,双曲线等等。比如说一个二次变换函数中包含常数项,一次项,二次项,如下:\Phi_2(x)=(1,x_1,x_2,x_1^2,x_1x_2,x_2^2)\Phi_2(x)=(1,x_1,x_2,x_1^2,x_1x_2,x_2^2)
2.找到一个好的转换函数
简单来说,一个好的转换函数对应的hypothesis,是能够把X空间中的圈圈叉叉分开,对应到Z空间就是能够把它们线性分开就是一个好的转换函数。
3.要付出的代价
当转换函数是高次项的时候,对应到X空间就是高维度的空间,曲线就会很复杂,那就会产生计算和存储的代价,最主要的是可能会overfit,得不到我们想要的理想的结果。那回到我们最初的问题:
- can we make sure that E_{out}(g)E_{out}(g) is close enough to E_{in}(g)E_{in}(g) ?
- can we make E_{in}(g)E_{in}(g) small enough?
所以正确选择转换函数以及转换函数的复杂度是非常重要的,既要保证不会overfit,也要使得能够得到良好的效果。
Lecture 13: Hazard of Overfitting
1.What is Overfitting?
什么是过拟合(overfitting)简单的说就是这样一种学习现象:E_{in}E_{in} 很小,E_{out}E_{out} 却很大。而E_{in}E_{in}和E_{out}E_{out} 都很大的情况叫做 underfitting。
发生overfitting 的主要原因是:
1.使用过于复杂的模型(d_{vc} d_{vc} 很大);
2.数据噪音;
3.有限的训练数据。
这是机器学习中两种常见的问题。
2.The Role of Noise and Data Size
我们可以理解地简单些:有噪音时,更复杂的模型会尽量去覆盖噪音点,即对数据过拟合,这样,即使训练误差E_{in}E_{in}很小(接近于零),由于没有描绘真实的数据趋势,E_{out}E_{out}反而会更大。即噪音严重误导了我们的假设。
还有一种情况,如果数据是由我们不知道的某个非常非常复杂的模型产生的,实际上有限的数据很难去“代表”这个复杂模型曲线。我们采用不恰当的假设去尽量拟合这些数据,效果一样会很差,因为部分数据对于我们不恰当的复杂假设就像是“噪音”,误导我们进行过拟合。
假设数据是由50次幂的曲线产生的,与其通过10次幂的假设曲线去拟合它们,还不如采用简单的2次幂曲线来描绘它的趋势。
3.Deterministic Noise
之前说的噪音一般指随机噪音(stochastic noise),服从高斯分布;还有另一种“噪音”,就是前面提到的由未知的复杂函数f(x)f(x) 产生的数据,对于我们的假设也是噪音,这种是确定性噪音。
可见,数据规模一定时,随机噪音越大,或者确定性噪音越大(即目标函数越复杂),越容易发生overfitting。总之,容易导致overfitting 的因素是:数据过少;随机噪音过多;确定性噪音过多;假设过于复杂(excessive power)。
如果我们的假设空间不包含真正的目标函数f(X)(未知的),那么无论如何H 无法描述f(X) 的全部特征。这时就会发生确定性噪音。它与随机噪音是不同的。
我们可以类比的理解它:在计算机中随机数实际上是“伪随机数”,是通过某个复杂的伪随机数算法产生的,因为它对于一般的程序都是杂乱无章的,我们可以把伪随机数当做随机数来使用。确定性噪音的哲学思想与之类似。
4.Dealing with Overfitting
对应导致过拟合发生的几种条件,我们可以想办法来避免过拟合。
- 假设过于复杂(excessive d_{vc} d_{vc} ) => start from simple model
- 随机噪音 => 数据清洗
- 数据规模太小 => 收集更多数据,或根据某种规律“伪造”更多数据
正规化(regularization) 也是限制模型复杂度的,在下一讲介绍。
数据清洗(data ckeaning/Pruning):
将错误的label 纠正或者删除错误的数据。
Data Hinting: “伪造”更多数据, add “virtual examples”
例如,在数字识别的学习中,将已有的数字通过平移、旋转等,变换出更多的数据。
其他解决过拟合的方法在后面几讲介绍。
Lecture 14: Regularization
1.背景
因为我们在实际操作过程当中经常出现overfit的情况,为了避免或者减小这种情况的发生,我们需要Regularization,通过正则化,相当于踩刹车,就可以减小overfit。
下面举例:同时用二次式和十次式去拟合一条低次的曲线,十次式很容易overfit,它们对应的hypothesis为:\begin{array}{c} \text{hypothesis in }\mathcal{H_{10}}:w_0+w_1x+w_2x^2+...+w_{10}x^{10}\\ \text{hypothesis in }\mathcal{H_{2}}:w_0+w_1x+w_2x^2\\ \end{array}\begin{array}{c} \text{hypothesis in }\mathcal{H_{10}}:w_0+w_1x+w_2x^2+...+w_{10}x^{10}\\ \text{hypothesis in }\mathcal{H_{2}}:w_0+w_1x+w_2x^2\\ \end{array}
我们会发现10次多项式比2次多项式只是多了后面的8项。那我们可能会想如果给10次多项式一个限制条件:
w_3=w_4=...=w_{10}=0w_3=w_4=...=w_{10}=0
10次多项式就变成了2次多项式,这就是一个正则化的过程。那如果对w_3,w_4...,w_{10}w_3,w_4...,w_{10}一个更为宽松的限制呢?\min_{w\in R^{10+1}}E_{in}(w) s.t.\sum_{q=0}^{10}w_q^2\leq C\min_{w\in R^{10+1}}E_{in}(w) s.t.\sum_{q=0}^{10}w_q^2\leq C
2.正则化的优化问题
\min_{w\in R^{10+1}}E_{in}(w)=\frac{1}{N}\sum_{n=1}^{N}\left(w^Tz_n-y_n \right)^2\min_{w\in R^{10+1}}E_{in}(w)=\frac{1}{N}\sum_{n=1}^{N}\left(w^Tz_n-y_n \right)^2 \text{s.t.}\sum_{q=0}^{Q}w_q^2\leq C \text{s.t.}\sum_{q=0}^{Q}w_q^2\leq C 对于上面的式子,我们很容易会想到可以引进拉格朗日乘子进行求解或者优化。再结合梯度下降法最小化E_{in}(w)E_{in}(w).当梯度的反方向和w_{reg}w_{reg}平行的时候,能够得到最优解,并且不会破坏上面的约束条件。即:
-\bigtriangledown E_{in} (w_{reg})\propto w_{reg} -\bigtriangledown E_{in} (w_{reg})\propto w_{reg}引进拉格朗日乘子:\bigtriangledown E_{in} (w_{reg})+\frac{2\lambda }{N}w_{reg}=0\bigtriangledown E_{in} (w_{reg})+\frac{2\lambda }{N}w_{reg}=0对上式积分,相当于解决:
E_{in} (w)+\frac{\lambda }{N}w^TwE_{in} (w)+\frac{\lambda }{N}w^Tw根据上面的式子我们可以得到:E_{aug}=E_{in} (w)+\frac{\lambda }{N}w^TwE_{aug}=E_{in} (w)+\frac{\lambda }{N}w^Tw我们称这个为augmented error,而称后面一项为regularizer.
3.正则化的VC bound
我们在前面学过的VC bound 的通用表达式为:E_{out}(w)\leq E_{in}(w)+\Omega \mathcal{(H)}E_{out}(w)\leq E_{in}(w)+\Omega \mathcal{(H)}而我们的regularizer在做的事情就是:E_{aug}=E_{in} (w)+\frac{\lambda }{N}w^TwE_{aug}=E_{in} (w)+\frac{\lambda }{N}w^Tw上面的两个式子都在算复杂度,只是第二个式子算的是单一的ww的复杂度,即:E_{aug}=E_{in} (w)+\frac{\lambda }{N}\Omega (w)E_{aug}=E_{in} (w)+\frac{\lambda }{N}\Omega (w) 它不是算所有的复杂度,而是算符合条件的 ww 的复杂度,即有效的VC维度,原理和我们前面学过的二维平面上有效的线的数量类似。
在这里,我们的regularizer是 ww 的平方,也就是我们加上的条件,但是我们可能也有别的Regularizers,所以我们需要根据目标函数找到一个合适的regularizer,但是即使没有找到好的regularizer,当 \lambda =0\lambda =0的时候,就相当于没有加regularizer,所以我们可以保证不会比没加regularizer做得更差。
Lecture 15: Validation
1.背景
我们在做二元分类的时候,我们总是要做很多选择,如选择哪一个算法,选择哪个模型等等,那我们根据什么来选择呢?
如果我们根据 E_{in}E_{in} 来做选择的话,根据我们前面学过的内容,我们会知道很容易产生ovefit 的情况,所以我们应该让一部分资料用来做验证,我们就可以用 E_{val}E_{val} 来做选择。
2.Validation的过程
validation的大致思路是:给定一部分资料,一部分用来做训练资料,一部分用来做测试资料,经过训练得到的hypothesis,拿去做测试,看效果如何。下面是具体过程: \begin{array}{ccccccccc} D& &\rightarrow &&D_{train}&&\cup &&D_{val} \end{array} \begin{array}{ccccccccc} D& &\rightarrow &&D_{train}&&\cup &&D_{val} \end{array} g_m=\mathcal{A_m}(D) g_m=\mathcal{A_m}(D) g_m^-=\mathcal{A_m}(D_{train}) g_m^-=\mathcal{A_m}(D_{train})这是资料经过算法之后得到的hypothesis。E_{out}(g_m^-)\leq E_{val}(g_m^-)+O\left( \sqrt{\frac{\log M}{K}}\right)E_{out}(g_m^-)\leq E_{val}(g_m^-)+O\left( \sqrt{\frac{\log M}{K}}\right) 这样我们就在理论上保证了validation的可行性以及有效性。当我们在训练资料上做完训练之后,拿去做测试。测试完之后选择一个最好的 g^-g^- ,错误最小的 g^-g^- 。
但是我们要选择多大的资料去进行验证呢?当下面这个式子成立的时候:
E_{out}(g_m^-)\approx E_{val}(g_m^-)E_{out}(g_m^-)\approx E_{val}(g_m^-)
我们希望验证的资料 KK 越多越好,资料越多才会越接近。
当下面这个式子成立的时候:E_{out}(g)\approx E_{out}(g^-)E_{out}(g)\approx E_{out}(g^-)
我们希望验证的资料 KK 越少越好,资料越少才会越接近。那我们应当怎么取舍,实践证明:大概用五分之一的资料来进行验证。
3.Leave-One-Out Cross Validation
我们考虑一个极端的情形,就是当验证的资料 K=1K=1 的时候,我们怎么算 E_{val}(g_m)E_{val}(g_m) ,并接近 E_{out}(g)E_{out}(g)。
E_{val}(g_n^-)=\text{err}\left( g_n^-(x_n),y_n\right)=e_nE_{val}(g_n^-)=\text{err}\left( g_n^-(x_n),y_n\right)=e_n
E_{loocv}\mathcal{(H,A)}=\frac{1}{N}\sum_{n=1}^{N}e_n=\frac{1}{N}\sum_{n=1}^{N}\text{err}\left( g_n^-(x_n),y_n\right)E_{loocv}\mathcal{(H,A)}=\frac{1}{N}\sum_{n=1}^{N}e_n=\frac{1}{N}\sum_{n=1}^{N}\text{err}\left( g_n^-(x_n),y_n\right)经过证明:E_{out}(g)\approx E_{loocv}\mathcal{(H,A)}E_{out}(g)\approx E_{loocv}\mathcal{(H,A)}
以上三个式子给出了 Leave-One-Out Cross Validation 的具体过程,其实就是一堆资料当中只拿一个资料出来做验证,每次只拿一个,NN 个资料每个资料都有且仅有一次做验证资料的机会,算错误的时候,把它们加起来再做平均。
4.V-Fold Cross Validation
但是其实我们在实际过程当中很少用Leave-One-Out Cross Validation,因为稳定性的原因,我们画出用Leave-One-Out Cross Validation做过的错误函数的图,我们就会发现其实不太稳定。所以下面介绍V-Fold Cross Validation。
E_{cv}\mathcal{(H,A)}=\frac{1}{V}\sum_{V=1}^{V}E_{val}^{(v)}(g_v^-)E_{cv}\mathcal{(H,A)}=\frac{1}{V}\sum_{V=1}^{V}E_{val}^{(v)}(g_v^-)
其实方法和Leave-One-Out Cross Validation 类似,比如给1000个资料,你把这些资料分成10份,一次验证一份,其他九份做训练资料,而不是一次验证一个,这样做出来的效果就更平滑一些。
Lecture 16: Three Learning Principles
1.背景
本讲主要讲了三个主要的学习原则,林轩田老师主要是通过讲了三个故事来讲这三个机器学习应该要注意的问题。
2.Principle
- The simplest model that fits the data is also the most plausible.
如果简单的模型能够完成我们的目标,那我们为什么还要用更复杂的模型呢?复杂的模型更可能产生overfit。所以我们在选择模型的时候要特别注意这个问题。
- If the data is sampled in a biased way, learning will produce a similarly biased outcome.
我们在对资料进行抽样的过程当中,尽可能的全面,尽可能包括所有的情况,这样才更真实,才能反映客观实际,在预测或推断的过程中才能更准确。
- If a data set has affected any step in the learning process,its ability to assess the outcome has been compromised
我们不能偷看资料,或者说不能拿测试资料当成验证资料,因为这样做毫无意义,这样得到 的hypothesis 拿去预测的话就达不到好的效果。
台大机器学习基石学习笔记相关推荐
- 台大林轩田机器学习基石学习笔记(一):The Learning Problem
这里写自定义目录标题 写在前面 一.What is Machine Learning 二.Applications of Machine Learning 三.Components of Machin ...
- 机器学习基石--学习笔记01--linear hard SVM
背景 支持向量机(SVM)背后的数学知识比较复杂,之前尝试过在网上搜索一些资料自学,但是效果不佳.所以,在我的数据挖掘工具箱中,一直不会使用SVM这个利器.最近,台大林轩田老师在Coursera上的机 ...
- 台大-林轩田老师-机器学习基石学习笔记6
这一讲数学的成份非常浓,但是中心思想还是为了希望证明机器学习的可行性条件.其中第五讲中提出的2D perceptrons的成长函数mH(N)是多项式级别的猜想,就是本次课的重点内容. break po ...
- 机器学习基石--学习笔记02--Hard Dual SVM
背景 上一篇文章总结了linear hard SVM,解法很直观,直接从SVM的定义出发,经过等价变换,转成QP问题求解.这一讲,从另一个角度描述hard SVM的解法,不那么直观,但是可以避免fea ...
- 台大机器学习基石上_lesson 2
Machine Learning Foundations –lesson 2 Perceptron definiton Perceptron Hypothesis 下面是的对上面h(x) 向量表示,且 ...
- Coursera台大机器学习技法课程笔记04-Soft-Margin Support Vector Machine
之前的SVM非常的hard,要求每个点都要被正确的划分,这就有可能overfit,为此引入了Soft SVM,即允许存在被错分的点,将犯的错放在目 标函数中进行优化,非常类似于正则化. 将Soft S ...
- 机器学习入门学习笔记:(3.2)ID3决策树程序实现
前言 之前的博客中介绍了决策树算法的原理并进行了数学推导(机器学习入门学习笔记:(3.1)决策树算法).决策树的原理相对简单,决策树算法有:ID3,C4.5,CART等算法.接下来将对ID3决策树算法 ...
- 机器学习入门学习笔记:(2.2)线性回归python程序实现
上一篇博客中,推导了线性回归的公式,这次试着编程来实现它.(机器学习入门学习笔记:(2.1)线性回归理论推导 ) 我们求解线性回归的思路有两个:一个是直接套用上一篇博客最后推导出来的公式:另一 ...
- 大数据业务学习笔记_学习业务成为一名出色的数据科学家
大数据业务学习笔记 意见 (Opinion) A lot of aspiring Data Scientists think what they need to become a Data Scien ...
最新文章
- iOS下拉tableView实现上面的图片放大效果
- [转]C# 2.0新特性与C# 3.5新特性
- Linux上程序调试的基石(1)--ptrace
- 慕课堂签到迟到怎么办_线上教学第一周:长安大学精品课程助力“云端课堂”...
- python爬虫可以爬取哪些有用的东西_Python爬虫系列(十三) 用selenium爬取京东商品...
- php foreach创建文件,php – mkdir()在foreach函数中跳过第一个文件
- mysql中in的问题
- Qt For Android 获取手机屏幕大小
- 海阔天空 在勇敢以后 --我的求职路
- 2011年-2019年华东地区产业发展、人口以及平均工资简析
- TMS VCL UI Pack Crack,完整源代码
- 常用室内定位技术总结
- 热门计算机软件学校,热门专科专业排行榜-热门大专专业排名前十名
- python实现食品推荐_通过Python语言实现美团美食商家数据抓取
- 一个与小球碰撞有关的有趣问题
- LeetCode#546. 移除盒子 (Python解法+详细分析)
- VC开发环境 路径宏
- 中断系统的相关知识(五)(外部中断)
- Running flutter pub get in flutter_app...卡死
- apktool高版本产生compileSdkVersion等错误