Python数据分析高薪实战第十二天 网络服务用户流失预测分析和国产电视剧评分预测分析
29 综合实战:网络服务用户流失预测与分析
绝大多数互联网公司都面临一个非常重要的问题:用户流失问题。随着互联网和移动互联网的充分发展,发展新用户(也就是一般所说的拉新)的成本越来越高,往往要几块或者几十块的成本才能发展出一个新用户。
但如果用户在使用服务的时候觉得不开心就不用了,那就算流失用户。流失用户对公司会带来非常直接的损失,所以最大可能地减少用户流失就成为互联网公司的重要命题。常规的提升产品的使用体验,提供更多用户喜欢的功能是一个方向。
另一方向就是识别出潜在的流失用户,发放一定的权益或者红包让他们留下来。目前,潜在流失用户预测逐渐成为互联网公司数据分析的工作热点,今天我们就一起来做一个这方面的实战。
准备数据
今天我们使用的是 IBM 公布的一份电信公司用户流失的数据集。
下载地址是:链接:https://pan.baidu.com/s/1BIhV7iSPUaeDK3S4HGa6aw提取码: xwsv
数据集的字段释义如下:

在课程目录新建 chapter29 文件夹,然后将下载的文件放到该文件夹中,这次的项目不再有 train 和 test 两个分开的数据集,只有一个总的数据集。
之后,我们用 VS code 打开上述文件夹,并新建 notebook,同时保存为 chapter29.ipynb。
接下来,导入必要的工具包(直接从上一讲中拷贝过来即可):
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import numpy as np
import random
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from plotly import tools
import plotly.express as px
from plotly.offline import init_notebook_mode, iplot, plot
import plotly.figure_factory as ff
import plotly.graph_objs as go
import ast
然后我们将数据集导入到 notebook 中。
df = pd.read_csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
df
输出之后发现列太多,无法完整显示,所以我们还是用上一讲学习的方法,来打印第一行的转置来查看所有的列。
df.head(1).transpose()
输出如下:

任务目标
今天我们的任务和之前有点不太一样。之前我们面对的主要都是回归问题,简单来说就是通过一系列特征来预测出一个具体的数值,比如上一讲的电影票房,上上讲的确诊病例数。而我们今天要使用模型计算的则是一个用户是否会流失,Yes or No。
所以今天我们要处理的实际上是一个分类的问题。还有一些不一样的是,这次我们数据集中的特征有很多是布尔类型的值。
任务目标已经很清楚了:通过选择与构造合适的特征,建立分类模型,来预测用户是否会流失。
数据清洗
第一步,仍然是数据清洗环节。
缺失值处理
我们首先查看是否存在缺失值:
df.isna().sum()
输出如下:
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
dtype: int64
从统计结果上来看,该数据集不存在缺失值,所以暂时不需要进一步处理。
数据类型处理
接下来,我们进一步看下数据集的数据类型。
df.info()
输出如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):# Column Non-Null Count Dtype
--- ------ -------------- -----0 customerID 7043 non-null object 1 gender 7043 non-null object 2 SeniorCitizen 7043 non-null int643 Partner 7043 non-null object 4 Dependents 7043 non-null object 5 tenure 7043 non-null int646 PhoneService 7043 non-null object 7 MultipleLines 7043 non-null object 8 InternetService 7043 non-null object 9 OnlineSecurity 7043 non-null object 10 OnlineBackup 7043 non-null object 11 DeviceProtection 7043 non-null object 12 TechSupport 7043 non-null object 13 StreamingTV 7043 non-null object 14 StreamingMovies 7043 non-null object 15 Contract 7043 non-null object 16 PaperlessBilling 7043 non-null object 17 PaymentMethod 7043 non-null object 18 MonthlyCharges 7043 non-null float6419 TotalCharges 7043 non-null object 20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
从上述结果中,可以看到存在一处问题, MonthlyCharges 是 float类型,但是 TotalCharges 却是 object 类型。考虑到后续我们需要计算 TotalCharges 和是否流失的相关性,所以这里我们将其转换为 float。
df["TotalCharges"] = pd.to_numeric(df["TotalCharges"])
执行上述代码,发现报错,错误提示为 “无法被转换为 float“。 说明 TotalCharges 字段虽然没有缺失值,但有部分值是空格,这导致我们无法直接将其转换为 float 类型。
为了解决上述问题,我们首先将 TotalCharges 字段中的空格,统一替换为数字 0,然后再进行转换:
df["TotalCharges"] = df["TotalCharges"].replace(' ', 0)
df["TotalCharges"] = pd.to_numeric(df["TotalCharges"])
df.info()
输出如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):# Column Non-Null Count Dtype
--- ------ -------------- -----0 customerID 7043 non-null object 1 gender 7043 non-null object 2 SeniorCitizen 7043 non-null int643 Partner 7043 non-null object 4 Dependents 7043 non-null object 5 tenure 7043 non-null int646 PhoneService 7043 non-null object 7 MultipleLines 7043 non-null object 8 InternetService 7043 non-null object 9 OnlineSecurity 7043 non-null object 10 OnlineBackup 7043 non-null object 11 DeviceProtection 7043 non-null object 12 TechSupport 7043 non-null object 13 StreamingTV 7043 non-null object 14 StreamingMovies 7043 non-null object 15 Contract 7043 non-null object 16 PaperlessBilling 7043 non-null object 17 PaymentMethod 7043 non-null object 18 MonthlyCharges 7043 non-null float6419 TotalCharges 7043 non-null float6420 Churn 7043 non-null object
dtypes: float64(2), int64(2), object(17)
memory usage: 1.1+ MB
可以看到,现在 TotalCharges 已经变为 float 类型了。
可视化分析
数据基本的清洗完之后,我们通过可视化的手段,来分析数据集的各种特征和最终的用户流失与否的关系。
流失比例分析
首先,我们来看一下总的用户里面流失用户和没流失用户占比。
sns.catplot(data=df, y="Churn", kind="count")
输出如下:

可以看到,最终整体的用户还是未流失的更多,大概是流失用户的 3 倍。这说明业务状态大概还算正常。但从另一个方面,将近 1/4 的用户流失了,也应该引起警觉。
数值类型特征分析
这次的数据集只包含三个数值类型的特征:tenure、MonthlyCharges、TotalCharges。
因为今天我们分析的是一个分类问题(是否流失),所以这里我们分析的重点就应该围绕流失用户和非流失用户,在这三个特征上是否展示出一定的差异。
首先从 tenure 开始,因为数据量偏少,我们使用核密度图进行分析。
fig1 = plt.figure(figsize=(10,5))
plt.rcParams["font.sans-serif"] = "SimHei"
sns.kdeplot(df[df["Churn"] == "Yes"]["tenure"], label = "流失用户")
sns.kdeplot(df[df["Churn"] == "No"]["tenure"], label = "未流失用户")
plt.legend()
输出如下:

可以看到,对于流失用户而言,绝大多数用户的 tenure 值都集中在 0 的附近。因为 tenure 代表的是用户使用服务的月份数,所以我们可以看出流失用户绝大多数都是新用户,对于使用了一段时间的用户反倒流失的比较少。
因为对于 MonthlyCharges 和 TotalCharges 都需要核密度图来分析,为了节省代码,我们首先将刚才画核密度图曲线的代码封装成一个函数, 然后把特征的名称作为参数。
def show_kde_for_feature(feat):fig1 = plt.figure(figsize=(10,5))plt.rcParams["font.sans-serif"] = "SimHei"sns.kdeplot(df[df["Churn"] == "Yes"][feat], label = "流失用户")sns.kdeplot(df[df["Churn"] == "No"][feat], label = "未流失用户")plt.legend()
接下来,我们分析 MonthlyCharges 字段:
show_kde_for_feature("MonthlyCharges")
输出如下:

从上图中可以看出,流失用户的月缴费普遍比较高,而非流失用户普遍集中在月费 20 元这个区间,可以看出来有很多用户可能是因为月费太高而直接流失了。说明 MonthlyCharges 应该是我们来判断用户是否会流失的主要指标之一。
接下来分析 TotalCharges 。
show_kde_for_feature("TotalCharges")
输出如下:

从 TotalCharges 上来看,流失用户和非流失用户的分布并不是很大,所以这个字段的信息量应该比较小。
用户维度的类别特征
接下来我们分析一下用户维度的类别特征,主要是 gender、SeniorCitizen、Partner 以及 Dependents。为了分析方便,我们直接将它们以子图的形式画在同一张大图里。代码如下:
fig = plt.figure(figsize=(10, 10))
fig.add_subplot(2,2,1)
sns.countplot(data=df, x="gender", hue="Churn")
fig.add_subplot(2,2,2)
sns.countplot(data=df, x="SeniorCitizen", hue="Churn")
fig.add_subplot(2,2,3)
sns.countplot(data=df, x="Partner", hue="Churn")
fig.add_subplot(2,2,4)
sns.countplot(data=df, x="Dependents", hue="Churn")
输出如下:

从图中可以看出,对于性别而言,流失用户和非流失用户的特征基本一致,说明用户是否流失和用户的性别基本无关,我们在建立模型的时候基本可以排除 gender 这个特征。
对于老年人来说,流失的比例也比非老年人要高,说明老年人可能对这类服务的依赖并不强。比较有趣的是 partner,没有配偶的流失用户的比例远高于有配偶的,这个情况也和第四个图匹配,有家人的流失比例远低于没有家人的。说明有家人和配偶,对于该电影公司的服务更依赖。而对于单身汉,可能偏向于其他公司提供的服务。
除了用户维度的类别特征,其他都是用户是否使用了某项服务的类别值。这里不进行进一步的分析,有兴趣的话你可以参考上面的方法做一些可视化的分析。
特征工程
通过可视化分析,我们判断除了 gender 之外的字段对于结果或多或少有一些影响。所以我们将有可能使用到的特征都单独提出来。另外, CustomerID 也是不需要的。
df_feature = df[["SeniorCitizen", "Partner", "Dependents", "tenure", "PhoneService","MultipleLines","InternetService", "OnlineSecurity","OnlineBackup","DeviceProtection","TechSupport","StreamingTV","StreamingMovies","PaperlessBilling","PaymentMethod","Churn"]]
df_feature
输出如下:

可以看到,我们一共选出了 16 列作为我们后续建立模型的特征备选值。 其中除了数据特征外,还有非常多的 Yes/No 或者字符串的列。这些列我们以前也处理过了,可以用 LabelEncoder 将其转换为 0 和 1 的值。所以第一步,我们要将所有需要编码的列找出来。代码如下:
object_columns = df_feature.select_dtypes(['object'])
下一步就是遍历这个 object_columns 的列名,来将其转化为编码后的值。
encoder = LabelEncoder()
for item in object_columns.columns:df_feature[item] = encoder.fit_transform(df_feature[item])
之后,我们查看 df_features。
df_feature
输出如下:

可以看到,现在 DataFrame 的值都已经被转换成对应的数字了。
建立模型
现在我们来建立模型,这次我们要进行的是分类任务,所以以往的回归模型是不太实用的。分类任务常见的模型有逻辑回归、随机森林等。具体理论部分就不在本课程展开,我们直接学习使用方法即可。这些模型的使用方法和之前我们使用的 XGBoost 和 LinearRegression 等都没特别的区别。
在训练模型之前,第一步首先就是将数据集拆分为训练集和测试集,直接使用我们之前使用的 train_test_split 函数即可。代码如下:
classifier = RandomForestClassifier(n_estimators=30 , oob_score = True, n_jobs = -1,random_state =50, max_features = "auto", min_samples_leaf = 50)
classifier.fit(df_train.drop(columns="Churn"), df_train["Churn"])
score = classifier.score(df_train.drop(columns="Churn"), df_train["Churn"])
score
输出如下:
0.8002650511170011
输出的分数代表模型拟合效果,0.8 算一个还不错的结果。
获取预测结果
在模型训练完成之后,我们就可以对之前拆分出来的测试集进行预测了。
prediction = classifier.predict(df_train_validator.drop(columns="Churn"))
prediction
输出如下:
array([0, 0, 0, ..., 0, 0, 0])
prediction 存储了我们模型针对测试集合特征预测的结果,是一个NumPy 的数组。我们可以将其转化成 pandas 的 Series ,来看下在我们预测的结果中,流失与非流失的比例。
pd.Series(prediction).value_counts()
输出如下:
0 1494
1 267
dtype: int64
可以看到,我们预测出来的流失与非流失的比例,和我们之前数据集中的情况基本是差不多的。
衡量分类模型的结果
我们之前在回归模型的评估上,往往使用预测结果和真实结果的均方误差来衡量,但对于分类问题并不合适。对于分类问题,最常用来衡量模型效果的指标有三个:准确率、召回率和查准率。
对于分类问题,我们针对某条数据的预测的结果会有以下四种情况:
TruePosition(TP), 本来是真,我们的预测结果也为真;
TrueNegtive(TN),本来是假,我们的预测结果也是假;
FalsePosition(FP), 本来是假,我们预测的结果为真;
FalseNegtive(FN), 本来是真,我们预测的结果为假。
不难看出,如果我们的结果是 TP 和 TN 都代表是对的,FP 和 FN 都代表是错的。但是不同的场景关注的终点也不同。
(1)准确率
准确率衡量的就是我们预测结果总的正确个数处于总预测的数量,公式为:

(2)召回率
召回率衡量的是我们找到了多少正样本。换句话说,对于本来是真的样本,我们找到了多少个。比如本来有 100 个用户会流失,而我们预测为真的结果中有 40 个人在这 100 个人里面,那我们的召回率就是 40%。 公式为:

(3)查准率
查准率衡量的是我们预测为真的所有样本中,真的为真的比例是多少。比如我们认为有 100 个用户会流失,然后有 80 个用户真的流失了,那说明我们的查准率为 80%。 公式为:

在不同的业务场景,会使用不同的指标来衡量我们分类模型的好坏。sklearn 提供了现成的函数可以直接计算这三个数值,代码如下:
accuracy = accuracy_score(df_train_validator.Churn.values, prediction)
recall = recall_score(df_train_validator.Churn.values, prediction)
precision = precision_score(df_train_validator.Churn.values, prediction)
print("准确率:", accuracy)
print("召回率:", recall)
print("查准率:", precision)
输出如下:
准确率: 0.7978421351504826
召回率: 0.401330376940133
查准率: 0.6779026217228464
可以看到,我们的准确率和查准率还是相当不错的。但召回率不算高,但这也算一个不错的平衡。一般来说召回率都是比较难提升的,毕竟如果盲目提升召回率,则可能会导致查准率下降,这样可能也会导致一个不太置信预测结果。
小结
至此,网络服务流失用户预测的实战案例就结束了。伴随着这几次的案例,相信你对于数据分析的几大核心步骤也有了基本的认识,了解如何进行数据清洗和特征工程以及根据任务的类型来选择合适的模型。
今天我们第一次接触分类问题,首先分类问题使用的模型和回归问题一般是不一样的,其次评价模型好坏的指标也不太一样,对于分类问题的三个指标应用也是非常广泛的。
回顾一下今天学习的内容,新的知识主要有:
使用 Series 的replace方法来批量替换 Series 中的字符串的值;
使用 pd_tonumeric 来将 object 类型的字段转换为数值型;
使用 sns.catlot 来查看布尔值的分布比例;
使用 sns.kdeplot 配合 dataframe 的条件选择,来查看流失与不流失用户在其他字段上的分布特征;
使用 df.select_dtypes 来选择出某个数据类型的字段;
使用 RandomForestClassifier 来建立分类模型。
30 综合实战:国产电视剧评分预测与分析
时间过得很快,转眼间就来到了课程的最后一讲。我可以很负责地说,坚持学习到了这里。你已经踏入了数据分析师的大门,先为自己鼓个掌。
今天依然是实战的环节,与之前稍微不同的是,今天我们尝试分析的并不是围绕专门用来做分析的数据集。因为用来做分析的数据集多多少少都包含了一些设定好的潜在规律等着我们去探索,缺少了一丝真实的味道。
今天我们尝试分析我们之前通过爬虫技术收集的国产电视剧的评分数据集,难度比之前会变大,但也更贴近真实世界收集到的数据的特点:信息量有限,但需要尽量挖掘出有用的信息。
准备数据
首先在工作目录创建 chapter30 文件夹,并将 chapter21 中使用过的 tv_rating.csv 拷贝到 chapter30 文件夹中。
用 VS code 打开 chapter30 文件夹。并新建 notebook 保存为 chapter30.ipynb。导入必要的工具包:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import numpy as np
import random
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LinearRegression
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from plotly import tools
import plotly.express as px
from plotly.offline import init_notebook_mode, iplot, plot
import plotly.figure_factory as ff
import plotly.graph_objs as go
import ast
之后,我们加载并打印我们抓取到的电视剧的数据集。
df = pd.read_csv("tv_rating.csv")
df
输出如下:

相信大家对这个数据集应该不陌生了。一共包含 3600 条记录,并且有三列:分别是 电视剧的标题、评分和演员表。
任务目标
尝试基于目前手上已经有的数据,建立模型,来预测一个电视剧可能的评分。简单的说,需要我们基于一个电视剧标题和演员表的信息来预估它的评分。
由于我们只有一个数据集,所以我们从原始数据集中拆 80% 出来训练模型,然后用剩下的 20% 的数据来测试我们模型的效果。
问题分析
第一印象来说,从标题和演员表来预测电视剧的评分,多少是有点不够的。信息比较有限。但如果我们充分发挥我们想象力的话,标题和演员表也不是完全没用,比如是否存在以下可能。
标题长的电视剧是否会评分更高?
电影标题中包含数字的是否会评分更高? 比如 2、第二部。 毕竟烂片一般就不会拍第二部了。
演员表中包含流量明星是否会评分更高? 比如鹿晗、关晓彤。
另一方面,如果一个演员演的电视剧评分都很低,如果他也是待预测电视剧的演员,是否可以认为可能这部电视剧的评分也不高?
虽然乍看之下棘手。但我们仔细分析过后,还是可以从标题和演员表中挖掘出一些和评分有关的信息,这就是数据分析师最关键的工作,从一堆看似关联性很弱的数据中挖掘出有用的信息。理论上只要特征变量和目标变量存在相关性,那就肯定存在一个可用的模型,能比随机猜有更好的表现。今天我们的任务就是找到这个模型。
数据清洗
缺失值处理
接下来进行数据清洗,我们依然是从缺失值检测开始。
df.isna().sum()
输出如下:
title 0
rating 0
stars 0
dtype: int64
可以看出,我们的数据表是不存在缺失值。
处理评分数据
下一步我们要处理的是评分数据,评分数据目前还是字符串,因为数据中还包含了分数的“分”字。为了方便后续的处理,我们首先将其转换为数字。转换为数字有两个步骤:
移除“分”字;
把剩下的数字字符串转换为数字。
代码如下:
df.rating = df.rating.apply(lambda x: x.replace("分", ""))
df.rating = pd.to_numeric(df.rating)
df
输出如下:

可以看到,分数已经被我们转换为数字了。
处理演员表
接下来就是演员表的处理,从我们之前粗略的分析中,演员表是我们今天分析的重点。所以我们首先将其处理成列表。
由于现在是用逗号链接的字符串,所以我们可以用 split 函数将其拆为列表。另外,通过观察数据我们可以发现演员表开头都有“主演”这两个字,同样需要去除。代码如下:
def handleStars(stars):stars = stars.replace("主演", "")result_arr = []base_arr = stars.split(",")return base_arr
df.stars = df.stars.apply(handleStars)
df
输出如下:

可以看到,我们的演员表字段已经被处理成列表了。细心的你可能已经发现,有记录的演员表字段没有被分割成功。比如【实习女捕快】 这个电视剧,演员之间用空格隔开。所以当我们尝试用逗号分割时,这个列表还是被当成整个字符串处理了。本质就是很多演员表的格式可能是不标准的。
为了找出没有被成功分割的记录,我们可以创建一个新的列:star_count 来记录每一行记录 stars 字段的长度。
df["star_count"] = df.stars.apply(len)
df
之后,我们筛选长度为 1 的记录查看:
df[df.star_count==1].stars
输出如下:

一共有 348 条长度为 1 的列表,当然这个列表页不全是异常值,比如有的电视剧确实就只有一个演员。由于 pandas 输出太多数据时会被截断,我们可以用 [] 索引器来输出某一段的记录,比如第 100 条到第 150 条。
df[df.star_count==1][100:150]
输出如下(未完整截取):

通过分析,我们可以发现未能被成功分割的主要有以下几种情况:
使用空格( )分割;
使用/斜杠(/)分割;
使用中文逗号(,)分割;
使用顿号(、)分割。
基于此,我们可以编写代码,对目前已经是列表类型 stars 列进行二次处理,将那些没有被成功分割的字段分割开。代码如下:
def handleStarStep2(stars):spliters = [' ', '/',',','、']result_arr = []for item in stars:for spliter in spliters:temp_arr = item.split(spliter)for sub_item in temp_arr:temp_item = sub_item.strip()if temp_item not in result_arr:result_arr.append(temp_item)return result_arr
df.stars = df.stars.apply(handleStarStep2)
df
输出如下:

之后,我们再次刷新 star_count 字段的值并查看。
df["star_count"] = df.stars.apply(len)
df[df.star_count ==1]
输出如下:

可以看到,演员个数为 1 的记录从 348 减少为 81。从结果中看,绝大多数都确实只有一个演员的电视剧,而也存在着极少数仍未被分开的记录,因为中间完全没有分隔符。由于个数较少,我们不做进一步的处理。
可视化分析
基本的数据处理完毕后,我们尝试可视化分析,目前我们的数据表中仅有一个数值字段:star_count, 以及按照我们之前说的,标题的长度也应该是一个值得参考的值。
数据分布分析
首先我们看一下目标变量的分布:
df.rating.hist()
输出如下:
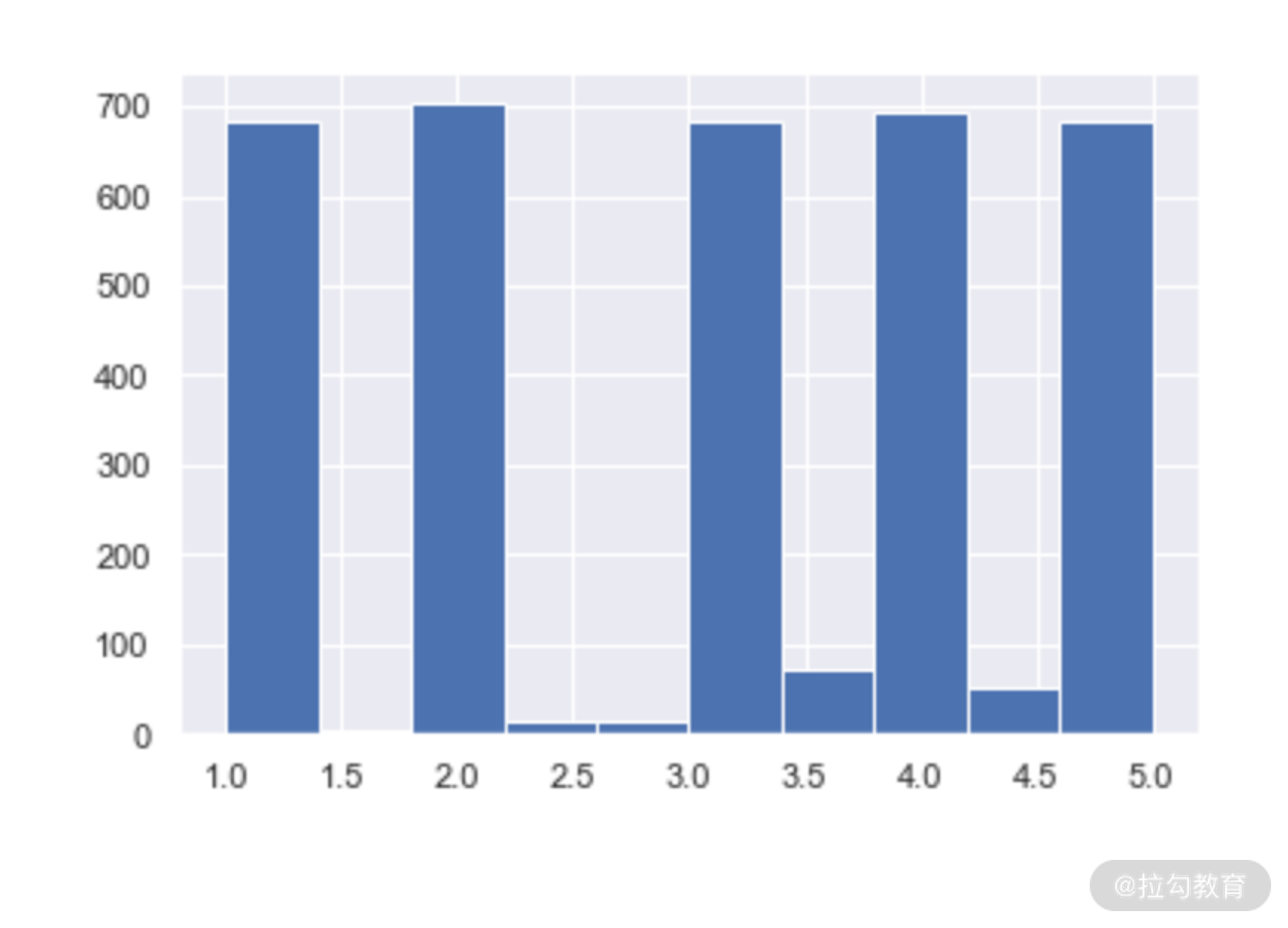
数据集中的评分分布还是比较平均的。
接下来看一下 title_len 字段。
df.title_len.hist()
输出如下:

可以看到,绝大多数电影的标题都是 4~5 个字。由于数据太过集中,所以 title_len 可能并不是一个特别好的特征。
最后,我们来看一下 star_count。
df.star_count.hist()
输出如下:

可以看到类似 title_len、star_count 的数量都集中到 0~5 的范围内。
相关性分析
接下来我们分析一下这两个字段与 rating 字段的相关性,首先是标题长度。
df["title_len"] = df.title.apply(len)
px.scatter(df, x="title_len", y = "rating")
输出如下:
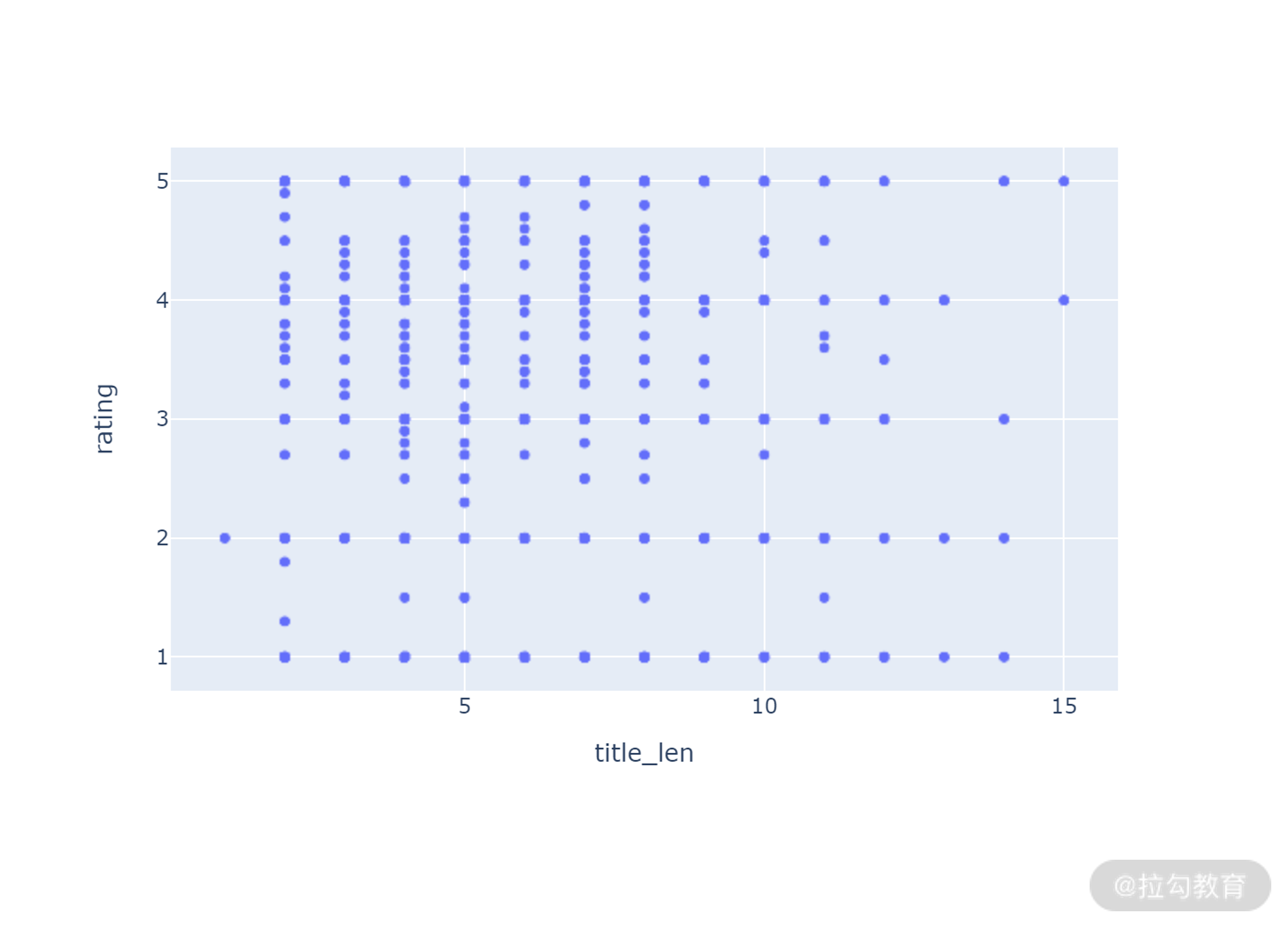
从上图中可以看到,我们这次的数据量比较小。这也导致我们做分析可能很难得出一个比较完美的结果,另一方面,title_len 和 rating 从图中反映的相关性也比较弱。
我们再来看一下 star_count 。
px.scatter(df, x="star_count", y="rating")
输出如下:

从上图中可以看到,数据尤其是高分的数据都集中在 star_count 3 到 10 这个区间。虽然也反映不出 star_count 与 rating 存在明显的关系,但至少从概率来看,不在这个区间的评分不高的概率就偏大了,可以说存在一定的弱相关性。
特征工程与模型
因为这次我们的任务并没有特别明显的特征,所以我们将特征功能和模型放到一起来讲,因为需要一边测试模型的表现一边筛选特征。
基准结果
在本讲的开头我们就描述了这次任务的性质:
数据量少,稀疏;
收集自现实世界,数据中不一定隐含有意义的结论。
对于这类不确定性高的数据分析任务,最重要就需要设定一个评价是否有用的基准。比如我们建立的模型比随便猜的错误率还高,那就没有任何意义了。结合本案例来说,我们 80% 用于训练,20% 的数据集用于测试,对于 20% 的测试集合,我们用随机的方式计算电视剧的评分,随机评分和测试集中的真实评分做均方误差。
这个均方误差就是我们的基准结果,换句话来说,我们的模型对于测试集中电视剧评分的预测需要超过这个基准结果,模型才能算是有用的。
首先第一步,拆分训练和测试集。
df_train,df_test = train_test_split(df, test_size=0.2)
df_test
输出如下:

现在测试集中包含 720 行记录。接下来我们随机出 720 个 [0,5] 的评分,计算随机结果与测试集评分的 MSE。
random_result = np.random.uniform(0.0,5.0, 720)
mean_squared_error(random_result, df_test["rating"])
输出如下:
4.260423686305926
初版模型
接下来进入模型的训练,目前我们有两个特征 title_len 和 star_count,相关性都不是很强。但我们仍然可以先试试用它们训练一版模型。代码如下:
from xgboost import XGBRegressor
features = ["title_len","star_count"]
target = "rating"
xgb = XGBRegressor(n_estimators = 2000 , random_state = 0 , max_depth = 27)
df_train_features = df_train[features]
df_train_target = df_train[target]
xgb.fit(df_train_features, df_train_target)
df_test_feat = df_test[features]
df_test_result = xgb.predict(df_test_feat)
mean_squared_error(df_test_result, df_test[target])
输出如下:
2.2631812293604723
通过 title_len 和 star_count 训练的 XGBoost 模型,在测试集上获得了 MSE 2.26 的成绩,已经大幅超过了我们之前准备的基准结果。这说明虽然这两个特征并不是非常的强,但也足够做出比乱猜靠谱得多的预测。
模型优化
虽然我们第一版的模型就能够得出不错的结果,但仍然有优化的空间。比如我们都知道,优秀的演员对于评分的帮助显然比标题长度,或者演员个数来的直接。我们可以定义两个维度。
优秀演员:参演过 4 分及以上电视剧的演员;
资深演员:参与过 3 部以上电视剧的演员(数据集中为准)。
基于此,我们可以制定出三个新的特征。
电视剧包含优秀演员的个数:top_stars_count;
电视剧包含资深演员的个人:sr_stars_count;
电视剧包含的优秀演员共演过几部4分以上电视剧:top_stars_movie_count。
要实现上述三个特征,我们首先需要遍历数据表,筛选出普通演员、优秀演员和电视剧个数的对应关系。代码如下,我们用 all_stars 存储普通演员,all_top_stars 存储优秀演员。
all_stars={}
all_top_stars = {}
i = 0
for item in df.stars.values:rating = df.loc[i, "rating"]for sub_item in item:if sub_item in all_stars:all_stars[sub_item] = all_stars[sub_item] + 1
else:
all_stars[sub_item] = 1
if rating >=4:
if sub_item in all_top_stars:
all_top_stars[sub_item] = all_top_stars[sub_item] + 1
else:
all_top_stars[sub_item] = 1
i = i+1
print(“普通演员个数:”, len(all_stars))
print(“优秀演员个数:”,len(all_top_stars))
执行之后输出如下:
普通演员个数: 8808
优秀演员个数: 1237
可以看到,数据集中一共有 8800 多个演员,其中有 1200+ 个优秀演员。
之后,我们基于这两个字典,来生成我们三个新的特征,代码如下:
def get_sr_stars_count(c,l):result = 0for item in l:if all_stars[item] > c:result = result+1return result
def get_top_stars_count(l):result = 0 for item in l:if item in all_top_stars:result = result + 1return result
def get_top_stars_movie_count(l):result = 0 for item in l:if item in all_top_stars:result = result + all_top_stars[item]return result
df["sr_stars_count"] = df.stars.apply(lambda x:get_sr_stars_count(3,x))
df["top_stars_count"] = df.stars.apply(get_top_stars_count)
df["top_stars_movie_count"] = df.stars.apply(get_top_stars_movie_count)
df
输出如下:

一切准备妥当,现在用我们三个新特征来训练模型。代码如下:
from xgboost import XGBRegressor
features = ["top_stars_count", "top_stars_movie_count","sr_stars_count"]
target = "rating"
df_train,df_test = train_test_split(df, test_size=0.2)
xgb = XGBRegressor(n_estimators = 2000 , random_state = 0 , max_depth = 27)
df_train_features = df_train[features]
df_train_target = df_train[target]
xgb.fit(df_train_features, df_train_target)
df_test_feat = df_test[features]
df_test_result = xgb.predict(df_test_feat)
mean_squared_error(df_test_result, df_test[target])
输出如下:
1.8756039712703974
可以看到,在我们使用三个新的特征后,模型的准确率相比初版模型提升了 17%,相比基准结果提升了 55.9%。
为什么第二次训练我们没有包含第一次的 title_len、star_count 这两个特征?
原因是数据集本身比较少,特征太多很容易导致模型无法收敛,进而出现更差的结果。
小结
至此,今天的数据分析案例实战就讲完了。回顾一下今天所涉及的内容:
现实世界的数据往往不存在明显的特征,需要我们基于现有特征不断挖掘出潜在的相关性,找出隐藏在数据背后的特征;
使用 replace 函数替换字符串中的任意字符,使用 pd.to_numeric 将某一列转换为数字;
使用 split 函数将字符串以某个分隔符为准拆成一个字符串数组;
结合经验与现有的数据,用不同的特征尝试模型的训练,最终找到最好的特征集合。
本讲也是课程的最后一讲,学到这里你已经完全证明了你的能力与觉悟,是时候在数据分析的道路上扬帆起航了。
加餐 VS Code 新版 Notebook 使用指南
在课前准备课时,有同学反映下载的版本和我们“课前准备”课时的版本不一样,导致界面和我们的截图也不一致,为了让大家用新版的版本也可以正常使用。现做加餐特以说明。
近期,VS Code 团队计划推出新版的 Notebook 插件,提供了相比之前的版本更简洁的 UI 和更好的体验,功能基本上是一致的。由于改版较大,所以这里针对性地说一下新版的用法。
新版界面,如下所示。

主操作区从左到右的功能依次是:
执行全部
清空输出
重启 Jupyter 内核
查看当前变量
导出
分栏
当我们的鼠标浮动在 Cell 之上时,便会出现 Cell 操作的相关按钮,如下图所示。

Cell 操作区的功能,从左到右依次是:
执行上一个 Cell
执行下一个 Cell
拆分 Cell
更多菜单
删除 Cell
有了执行上一个和下一个 Cell 的功能,那执行当前 Cell 呢?就是 Cell 左边的三角形按钮,如下图所示(默认快捷键变为 CTRL + Enter)。

新版本的介绍就到这里了,相信同学们现在可以用新版本继续往下学习了!
结束语 构建数据分析的技能树
转眼之间,我们的课程就要结束了。如果你坚持学到了这里,充分证明了你已经学习到了基础的 Python 编程技术以及常见的 Python数据分析工具包。
不过现在的数据分析技术日新月异,使得这本身也是一个需要终身学习,不断积累经验的行业。但它又蕴含了许多经典的、亘古不变的道理,所以经验越多也就越吃香。
那之后怎么做到终身学习呢?最好的方法还是围绕着数据分析师所需要的关键技能展开学习,来一步步地构建自己体系化的技能树。随着技能树的逐渐完善,你在数据分析领域能处理的任务也就越来越复杂,也就越来越能从数据分析的角度为企业创造价值。
要构建技能树,首先我们要知道构成这棵树有那些主要的枝干。整体来说数据分析师核心技能应具备以下六大技能。
1. 编程能力
排第一的,首先就是编程能力。目前数据分析面临的海量数据,复杂的数据源,已不是单一数据处理工具(Excel、SQL)能解决的了。通过编程,不仅可以让我们通过各种手段拿到足够的数据,也能够展示多样化的图标,比如可交互图表等。
可以说在数据分析的每一个环节都离不开编程。对于数据分析的领域而言,最流行的语言就是 Python。近些年 R语言也逐渐被应用在数据分析领域,不过距离取代Python老大哥的位置还是很远的。
2. 数据清洗能力
数据预处理大家应该都不陌生了,贯穿了整个课程的始终。数据预处理在互联网行业重要的根本原因是软件系统不可靠。上游系统软件不可靠,造就了我们能拿到的数据源多多少少都是有一些问题数据的。如果不对问题数据的范围、类型等直接作出处理,很可能会影响最后分析的结果。而常见的数据预处理技巧有:
缺失值处理;
数据插补;
处理类别、类型的值;
将类别类型的值转换为数字形式(Label Encoder);
数据降维(主成分分析法等)。
3. 数据可视化的能力
数据可视化不仅仅是结果的一个更好的呈现方式,甚至在分析的过程中,通过可视化的形式都能够更好地帮助我们发现数据的规律,特征的分布以及特征与特征之间的关联。目前数据可视化比较成熟的解决方案有 matplotlib、seaborn和 plotly。
4. 数学和统计学基础
除了编程技巧和 Python的知识之外,从我们之前做过的各种实战经验来看。数学和统计学的知识出现频率非常高。当我们和数值类型的特征打交道的时候,我们首先需要看特征的概率分布情况。
概率分布情况能够直观地告诉我们这个特征是不是值得被分析。比如一个特征 99% 的取值都是一样的。那这个特征大概率无法提供更多的信息量。另一方面,特征的相关性分析,背后也是统计学的知识。另外在很多数据拟合、预测任务中,高等数学中的导数与梯度,矩阵计算都是核心的核心。
5. 基础的机器学习能力
在如今的绝大多数的数据分析任务里,数据分析的任务不是简单写一个数据分析报告,输出一些结论就完事儿了。在大多数互联网公司中,数据分析的目的更多是从海量数据中进行分析并建立模型,并且通过这个模型来对业务产生正向的****效果。
比如建立识别用户是否可能流失的模型,通过不断地使用模型来预测用户是否会丢失,公司就能针对性地做一些运营手段来改善。所以对当今的数据分析师而言,知道什么是机器学习、机器学习的常见框架和工具,以及如何建立模型都是必备技能。这个在我们的课程中也有体现,在最后几章的案例中,几乎每个都能看到机器学习的影子。
6. 沟通能力
数据分析师需要较强的沟通能力,一方面是你的上游,比如你要去拿各种各样的数据源,就需要和各种系统打交道,和系统打交道本质也是和人打交道。比如你需要和负责对应系统的产品经理或者程序员沟通你的需求,理解他们的数据特征等。另一方面也需要和你的下游,比如需要你去分析数据的老板,当你完成分析之后,你需要让老板理解你整个分析的过程和逻辑,这样才能显得你的结论比较可信。
同时,当你开发出了模型需要部署到线上,也需要和各类工程团队的同事们沟通,比如你模型的输入是什么,性能如何,等等。最后,复杂的数据分析任务都不是单打独斗,都是需要一个团队才能完成的,所以和同事们保持沟通同样也非常重要。
以上,就是数据分析师六大核心技能。
希望你之后能以终身学习的心态不断围绕着六大能力来构建技能树,你也必定在数据分析领域有明显质的提升与飞跃。
最后,感谢你坚持学完本课程。同时我邀请你为本专栏课程进行结课评价,因为你的每一个观点都是我和拉勾教育最关注的点。
Python数据分析高薪实战第十二天 网络服务用户流失预测分析和国产电视剧评分预测分析相关推荐
- Python数据分析高薪实战第四天 构建国产电视剧评分数据集
10 实战:手把手教你构建国产电视剧评分数据集 在前面几讲,我们已经学习完了爬虫技术的三个基础环节:下载数据.提取数据以及保存数据. 今天我们将通过一个综合的实战案例来将之前的内容都串联起来,帮你加深 ...
- Python数据分析高薪实战第一天 python基础与项目环境搭建
开篇词 数据赋能未来,Python 势不可挡 你好,我是千帆. 互联网公司从红利下的爆发期,进入新的精细化发展阶段,亟须深入分析与挖掘业务与数据价值,从而找到新的增长点突破现有增长瓶颈.各行各业的数据 ...
- Python数据分析高薪实战第十天 EDA实战-全球新冠肺炎确诊病例趋势分析
27 初识 EDA:全球新冠肺炎确诊病例趋势分析 从本讲开始,我们会通过四个具体的案例来将我们之前学习的 Python 数据分析方面的知识全都串起来.一方面能够融会贯通,另一方面也能帮你掌握数据分析基 ...
- Python数据分析高薪实战第八天 数据计算统计与分析
17 如何快速实现数据的批量计算? 接下来我们会进入一个全新的模块:数值类数据分析.在这个部分,我们会学习数据分析中常用的数学方法以及 Python 中处理数值数据的神器:NumPy. 在完成了本部分 ...
- Python数据分析高薪实战第十天 数据绘图进阶与实战
24 图像的脊柱.注解和图例:如何画出更专业的图表? 前面两节课,我们学习了主流的几种 matplotlib 的图形形式,主要包括折线图.散点图.直方图.条形图和饼图.现在我们已经可以画出样式比较多的 ...
- Python数据分析高薪实战第七天 数据解析和电商行为分析案例
15 时间序列:时间数据的解析与应用 在很多数据分析任务中,经常会遇到处理时间相关的数据.比如电商网站经常需要根据下单记录来分析不同时间段的商品偏好,以此来决定网站不同时间段的促销信息:又或者是通过对 ...
- Python数据分析高薪实战第四天 python数据采集下载和提取保存
06 获取数据:公开数据集与 DIY 数据集 首先恭喜你完成了第一部分的学习.现在你已经基本掌握了 Python 的基础并能够使用 Python 完成一些相对完整的功能的开发,是时候开始进入数据分析的 ...
- Python数据分析高薪实战第六天 数据过滤与数据清洗
13 高级索引:过滤与查看表格中的局部数据 上一节课中,我们学习了 pandas 中两个核心的数据结构:Series 和 DataFrame,之后还学习了 DataFrame 的常见操作,比如对列.行 ...
- python数据分析实战案例-Python数据分析案例实战
原标题:Python数据分析案例实战 至今我们网站已经开设了多个数据分析系列的课程,大部分都是基于算法思路来开展的,课程中着重点在于算法的讲授.软件的使用,案例只是辅助学习.然而很多学员反映,希望可以 ...
最新文章
- TSQL 聚合函数忽略NULL值
- OSChina 周四乱弹 —— 春天在哪里,春天在哪里?
- id设置为10000开始
- 手机上可以学python吗_Python爬虫也能用手机进行抓包?没错!这个技巧我只告诉你...
- RStudio(You‘re using a non-UTF8 locale, therefore only ASCII characters will work)
- 【转】ubuntu 11.10(32位系统)下编译android源码
- boost之lexical_cast
- [Silverlight入门系列]使用MVVM模式(3):Model的INotifyPropertyChanged接口实现
- gta5显示nat较为严格_为何严格治理下雾霾天仍频发?哈尔滨市环保局解答重污染天3大疑问...
- linux内核功能关闭透明大页 功能,redhat linux 7.4关闭透明大页
- 求一个任意实数c的算术平方根g的算法设计思想_算法复习第四篇——贪心法
- java 与sas交互_SAS与MACRO的交互使用
- Linux操作系统PS命令详细解析
- java获取网卡正真的mac_java获取网卡的mac地址
- 用matlab做bp神经网络预测,神经网络预测matlab代码
- xUtils框架的介绍
- 3种竞争力分析的简单途径
- C++ -- STL文件解析
- 软件架构模式 mark Richards - 读后总结 5 - 基于空间的架构
- RB女歌手宇西个人单曲《盛宴》上线 诠释独自疗伤的故事