Python数据分析高薪实战第六天 数据过滤与数据清洗
13 高级索引:过滤与查看表格中的局部数据
上一节课中,我们学习了 pandas 中两个核心的数据结构:Series 和 DataFrame,之后还学习了 DataFrame 的常见操作,比如对列、行的增删查改。
但 DataFrame 的能力远不止于此,今天我们会围绕数据分析中各种各样的查询需求,来系统性介绍 DataFrame 强大的数据查询与过滤能力。
使用 [] 查询元素
中括号[], 是 pandas 中最基础的索引器。索引器是指我们提供索引,然后索引器就返回索引对应的内容。其实我们早在变量与数据类型一讲中已经打过交道。
比如一个列表 a, 我们想要访问第三个元素则可以写 a[2] , 这里的 2 就是索引,[] 就是索引器。a[2] 就能为我们访问列表 a 中索引 2 对应的元素,也就是列表的第三个元素。
以字典为例的话,如果我们有如下字典: b = {"name":"小亮", "age": 24}。我们希望访问字典 b 的 age 字段,则可以写 b["age"],字符串 "age" 是索引,[]是索引器,最终 b["age"] 返回了索引对应的内容:24。
DataFrame 和 Series 同样支持 []. 具体的行为是:
对 Series 使用[],返回索引对应的元素;
对 DataFrame 使用[],返回列名等于索引的那一列,以 Series 的形式。
准备数据
我们通过例子来加深一下印象。在课程目录新建文件夹 chapter13。 之后在 VSCode 中打开该文件夹,并新建一个 Notebook,保存在该文件夹中并命名为 chapter13.ipynb.
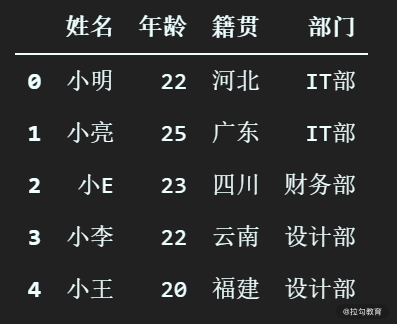
我们还是以 chapter12 中用到的部门信息为例,首先将创建部门信息 DataFrame 拷贝过来。如下所示。
import pandas as pd
# 将列索引保存在 index_arr 变量中
index_arr = ["姓名", "年龄", "籍贯", "部门"]
# 构建小明、小亮、小E的行 Series,并使用我们创建好的 index_arr 作为 Series 的index
ser_xiaoming = pd.Series(["小明", 22, "河北","IT部"], index= index_arr)
ser_xiaoliang = pd.Series(["小亮", 25, "广东","IT部"], index = index_arr)
ser_xiaoe = pd.Series(["小E", 23, "四川","财务部"], index= index_arr)
# 直接将三个 Series 以列表的形式作为 DataFrame 的参数,创建 DataFrame
df_info = pd.DataFrame([ser_xiaoming, ser_xiaoliang, ser_xiaoe])
# 使用 notebook 打印 DataFrame
df_info
执行之后输出:

这样,我们实验的数据就准备好了。
简单索引
接下来,我们通过实验来加深一下 [] 选择器的理解。
首先是对 DataFrame 使用 [] 索引器。
# 对 DataFrame 使用 [] ,返回列名= 传入的索引值的 Series
ser_name = df_info["姓名"]
# 打印 ser_name 变量的类型
print(type(ser_name))
# 打印 ser_name 的内容
print(ser_name)
输出为:
<class 'pandas.core.series.Series'>
0 小明
1 小亮
2 小E
Name: 姓名, dtype: object
从输出的结果可以看出。通过 [] 索引器和"姓名"这个索引,拿到的是一个 Series 类型。并且内容就是上一步构造的 DataFrame 中,姓名那一列对应的 Series。
对一个 Series 对象使用 [] 索引器,则会返回索引对应的具体数据。比如当我们希望拿索引 1 对应的数据,从上面的例子中可以看到,索引 1 对应的数据是“小亮”这个名字。我们通过代码来验证一下。
# 对上一步获取的 Series 对象:ser_name 使用 [] 索引器
# 传入索引 1
result = ser_name[1]
# 打印拿到的结果
print(result)
输出:
小亮
代码的运行结果和我们预期的结果一致。
多重索引
[]除了可以传入单一索引实现数据选择,还支持传入一个索引列表来获得原始数据集的一个子集。规则如下:
当对 DataFrame 的 [] 索引器传入一个索引列表时,返回一个新的 DataFrame,这个 DataFrame 只包含索引列表中的列,相当于是原 DataFrame 的子 DataFrame;
同理对于 Series,传入索引列表时,返回一个子 Series,包含索引列表对应的数据。
我们继续通过代码来加深理解:
# 传入一个索引列表,包含两个索引项:“姓名”,“年龄”
sub_df_info = df_info[["姓名", "年龄"]]
# 打印获取到的 sub_df_info 的类型
print(type(sub_df_info))
# 打印获取到的 sub_df_info 的数据
print(sub_df_info)
输出为:
<class 'pandas.core.frame.DataFrame'>姓名 年龄
0 小明 22
1 小亮 25
2 小E 23
传入索引列表之后,结果仍然是一个 DataFrame,并且这个 DataFrame 只包含了姓名、年龄这两列。
对于 Series 而言也是类似,比如我们希望同时挑选索引为 0 和 2 的两条记录,可以用如下方式实现。
# 传入索引列表 [0, 2] 给 Series,并将结果保存在变量 sub_ser_name 中
sub_ser_name = ser_name[[0,2]]
# 打印出 sub_ser_name 的类型
print(type(sub_ser_name))
# 打印出 sub_ser_name 中的内容
print(sub_ser_name)
输出为:
<class 'pandas.core.series.Series'>
0 小明
2 小E
Name: 姓名, dtype: object
可以看到,结果仍然是一个 Series 类型,但只包含了两条记录,分别是索引 0 对应的小明和索引 2 对应的小 E。从另一个角度看,Series 的数字索引是可以不连续的,这个也是和列表的一个重要区别。
范围选择
在学习如何使用 [] 进行范围选择之前,我们先给我们的 DataFrame 添加新的两条记录,方便演示功能效果。代码如下:
# 创建小王和小李的 Series
ser_xiaoli = pd.Series(["小李", 22, "云南","设计部"], index= index_arr)
ser_xiaowang = pd.Series(["小王", 20, "福建","设计部"], index= index_arr)
# 将 Series 添加到 DataFrame 中
df_info = df_info.append(ser_xiaoli, ignore_index= True)
df_info = df_info.append(ser_xiaowang, ignore_index= True)
# 查看添加之后的 DataFrame
df_info
输出如下所示,可以看到新的记录已经添加成功了,并且被分配了默认的索引。

现在进入正题,[] 索引器支持常见的范围选择有以下几种:
(1)df[n:m], 选择第 n 条到第 m 条之间的记录。示例代码:
# 取第 2 到 4 条,不包含4,也就是第 2、第 3 条记录
df_info[2:4]
输出为:

(2)df[:m], 选择前 m 条记录。示例代码:
# 取前 2条记录
df_info[:2]
输出为:

如果不写 m , 直接写 df[:] 的话,代表返回所有的记录。
(3)df[::n], 间隔 n 条选择。示例代码:
# 每取一次跳过 2 个
df_info[::2]
输出为:

# 每取一次跳过1个(也就是默认的选择方式)
df_info[::1]
输出
(4)df[::-1], 从最后一条开始逐一选择。
# 从后往前取,每取一次跳过1个
df_info[::-1]
输出为:

在范围选择的应用中,Series 的用法和 DataFrame 是一致的。
至此,我们就学习完了 [] 选择器的常见用法。
loc 与 iloc
在学习 [] 选择器的过程中,如果我们想查询 DataFrame 中某个单元格的数据,那往往都需要分三步走:
查看单元格所在行的索引;
拿到单元格所在列的列 Series;
用 1 拿到的索引去 2 拿到的 Series 中查询出具体的数据。
比如我们希望打印小亮的部门,可能就需要这样做:
# 查看数据表
df_info
输出为:

可以看到,小亮的行索引是 1,然后我们获取部门的列 Series 并进行查询:
# 获得部门的列 Series
dep_series = df_info["部门"]
# 打印部门 Series 中,索引为 1 的值
print("小亮的部门:" + dep_series[1])
输出如下。
小亮的部门:IT部
整个过程还是比较麻烦的,并且需要人肉记得我们要查询的数据所在行的索引,非常容易出错。有没有更好的方式呢?答案是肯定的。
pandas 除了 [] 索引器之外,还提供了一套非常强大的数据查询方式:loc 和 iloc。
loc 基础用法
loc 和 iloc 是 pandas 的一种特殊的对象,专门用于查询 DataFrame 中的数据。
首先是 loc,基本用法如下:
df.loc[行索引名称, 列索引名称]
看了以上的形式,相信聪明的你已经发现了,使用 loc 对象我们可以一次性执行行索引+列索引,这样就使得定位单元格的内容可以直接一行代码就搞定。
拿上面的例子来说,如果要查询小亮的部门,用 loc 直接这么写即可:
# 小亮的行索引是1,查询部门,则列索引是 '部门'
print("小亮的部门:" + df_info.loc[1, "部门"])
输出为:
小亮的部门:IT部
可以看到,通过 loc, 我们将之前的三步缩短成了两步,省去了先取 Series 出来的环节。
loc 对象的 [] 索引器支持所有 DataFrame 的 [] 索引器的能力。具体来说就是 loc 对象的行索引部分和列索引部分都可以分别使用我们第一部分介绍的多种索引、范围选择的语法。
举个例子来说明一下,比如我们任务是在上面的 df_info 表中,从后往前选择每个同事的姓名和年龄两列。
上述任务规定了两个条件:一个是需要从后往前,即我们取行的时候,需要使用范围选择中学到的技术;另一个是只取姓名和年龄两列,需要用到我们之前在多重索引中学到的技术。
具体的代码如下:
# 使用 loc,行索引处使用 ::-1 来指定从后往前选取,列索引部分传入列名列表来实现取两列
df_info.loc[::-1, ["姓名", "年龄"]]
输出为:

iloc 基础用法
iloc 的用法和 loc 非常类似,区别是 iloc 仅支持传入整数索引。简单来说,loc 是需要传入行索引和列索引的名称,而 iloc 则需要传入第几行、第几列这样的数字。基本用法如下:
df.iloc[第几行, 第几列]
拿上面的例子来说,假设我们要用 iloc 对象来打印小亮的部门,可以这么做。
# 从数据表中可以看到,小亮的部门这个数据在第一行,第三列。所以可以将 1 3 传入 iloc 即可
print("小亮的部门:" + df_info.iloc[1, 3])
输出为:
小亮的部门:IT部
从输出来看,效果和使用 loc 对象是一样的。但是从易用性的层面,loc 显然比 iloc 更加容易使用且不容易出错。使用 iloc 每次都需要去数我们所要的数据在第几行、第几列,非常容易出错。所以一般情况下,我们都推荐直接使用 loc。但也有一些场景,不知道行索引,但明确要拿第一个元素的场合就需要使用 iloc。
总体来说 iloc 是和 loc 打配合使用的, loc 最常用。
条件查询
我们回过头去看单元格查询的三个步骤,虽然通过 loc 对象,我们省去了先取 Series 再取数据的冗余步骤,但是第一步:查看小亮所在的行的索引。这一步对于我们的例子来说是很简单的,毕竟一共也就这么几行。但如果我们的表里面数据有几十万、上百万,我们不可能逐一去看小亮所在的行的索引到底是什么。
这个时候就需要用到 loc 对象的一个重要特性:条件索引。
loc 的条件索引的具体用法如下所示,它和普通的 loc 用法区别最大的就是将行索引部分替换为条件表达式。
df.loc[条件表达式, 列索引名称]
比如,我们希望获得年龄大于等于 23 岁的员工的信息。使用条件查询,我们可以这样写:
# 条件表达式:df_info["年龄"] >= 23, 然后因为我们希望获得所有列,所以列索引直接写 :
df_info.loc[df_info["年龄"] >= 23, :]
输出为:

条件表达式往往是判断 DataFrame 的某个列满足某个条件,比如是否大于或等于,等等。这样我们就不用每次都要看我们想要数据的行索引是什么,而是直接通过写合适的条件表达式就可以筛选出我们想要的数据。
拿我们最开始的任务来说,我们要查询小亮的部门,有了条件表达式,我们不再需要关心小亮所在行的行索引。而是可以这么写:
# 使用条件表达式: df["姓名"] == "小亮", 并取 部门 这个列
df_info.loc[df_info["姓名"] == "小亮", "部门"]
输出:
1 IT部
Name: 部门, dtype: object
可以看到,小亮的部门被成功查询出来了,而且还是在我们完全不知道他行索引的前提下。不过,我们希望查询的是一个值,但这里的结果似乎是一个 Series,这是因为一旦在 loc 中使用了条件表达式,它返回的结果就会是 Series,因为会存在满足条件的行有多个的情况。
在这个例子里,我们知道表中只有一个小亮,所以直接从结果 Series 取第一个就可以。这里我们不关心结果中的行索引,所以可以直接使用 iloc 取第一个即可。(Series 的 iloc 和 DataFrame 的 iloc 作用类似,即不关心索引,而是按照第几个这样的排序来取)
综上所述,我们通过条件查询来打印小亮的部门,代码如下:
print("小亮的部门:" + df_info.loc[df_info["姓名"] == "小亮", "部门"].iloc[0])
输出为:
小亮的部门:IT部
高级条件查询
当我们筛选数据的时候,一个条件不能满足要求,就需要组合多个条件来筛选出我们想要的数据。组合多个条件时,最常见的两个逻辑关系就是:逻辑与和逻辑或。
(1)逻辑与
假设有两个条件:A 和 B,A & B 代表逻辑与,逻辑与的意思是 A 和 B 两个条件需要同时满足,则 A & B 才算满足。
举个例子,我们希望查询 IT 部中 25 岁以下的员工信息。这里就有两个条件,一个是部分是 IT部,另一个是年龄小于 25,这两个条件需要同时满足。
# loc 条件表达式的逻辑与操作。每个子条件都需要用括号括起来
df_info.loc[(df_info["部门"] == "IT部") & (df_info["年龄"] <25), :]
输出

(2)逻辑或
假设有两个条件,A 和 B,A | B 代表逻辑或,意思是 A 和 B 只需要有一个条件满足,则 A | B 就满足。
举个例子,我们希望查询出所有财务部和设计部的员工。这里有两个条件,一个是部门等于财务部,一个是部门等于设计部,只需要满足其中一个条件就需要打印出来。代码如下:
df_info.loc[(df_info["部门"] == "财务部") | (df_info["部门"] == "设计部"), :]
输出为:

小结
至此,关于 DataFrame 和 Series 的数据查询技术就已经全部讲完了,我们在这里简单地回顾一下。
首先,我们学习了使用 [] 来查询 DataFrame 的 Series 的内容,关键点如下。
针对 Series 使用 [], 返回传入的索引对应的元素;针对 DataFrame 使用 [] ,返回传入的索引对应的列 Series。
当传给 [] 索引器的索引是多个索引,即一个索引列表时,DataFrame 会返回包含索引列表中指定的列的子 DataFrame,而 Series 则会返回索引列表中索引对应的元素组成的子 Series。
[n:m],代表查询从 n 到 m 中间的这一段记录,不写 n 时,代表查询前 m 条数据,n 和 m 都不写时,返回查询全部数据。
[::n],代表每隔 n 条返回一条,一般用于基于固定的频率采样数据集;[::-1] 代表从后向前逐一返回。
之后,我们学习了查询数据更强大的 loc 和 iloc,关键点如下。
loc 后接[] ,可以一次性传入行索引和列索引,使用逗号隔开,实现了直接取单元格的数据;行索引和列索引都遵循第一部分介绍的各种规则,如多重索引、范围选择等。
iloc 和 loc 类似,只是传入的不是索引,而是第几行、第几列这样的整数。
loc 的行索引部分可以替换为条件表达式,来实现通过条件来选择行,而不是通过固定的行索引。
条件表达式可以组合,& 代表逻辑与,| 代表逻辑或。
学完了数据查询,相信你目前在拿到超大 DataFrame 的时候,也有足够的技巧去进行初步的分析。在接下来的章节我会将你更多的进阶分析,来更好地应对工作中的实际项目。
课后习题:
筛选出年龄在 22~23 的员工的姓名和籍贯,不包含设计部的员工。
答案:
df_info.loc[(df_info["年龄"] >= 22) & (df_info["年龄"] <= 23) & (df_info["部门"] != "设计部"), ["姓名", "籍贯"]]
输出

14 数据清洗:表格数据缺失值与异常值的处理
上一讲中,我们学习了 DataFrame 常见的数据查询技巧。有了这些技巧,我们已经可以通过各种角度来分析 DataFrame, 即便 DataFrame 包含非常多的数据。
但是在现实情况中,我们往往还会面临一个棘手的问题:现实工作中,因为在数据记录和数据存储环节偶尔会出现问题,比如互联网公司后端的行为日志记录系统时不时就会出现问题,导致部分数据的丢失。所以数据分析师拿到的原始数据中会存在很多字段或者记录是丢失的。为了不让这些缺失的数据影响数据分析的结果,在分析之前往往就需要进行数据清洗,对这些缺失的数据进行预处理。
本讲我们就来学习常见的数据清洗的技巧。
什么是缺失值
当我们从 CSV 文件或者其他数据源加载到 DataFrame 中时,往往会遇到某些单元格的数据是缺失的。当我们打印出 DataFrame 时,缺失的部分会显示为 NaN, 或者 None,或者 NaT(取决于单元格的数据类型),这样的值我们就称之为缺失值。
我们通过一个具体的例子来学习缺失值。按照之前每次课程的试验准备步骤,我们新建文件夹:chapter14,打开该文件夹,然后新建一个新的 Notebook,命名为 chapter14.ipynb 并保存在该文件夹中。
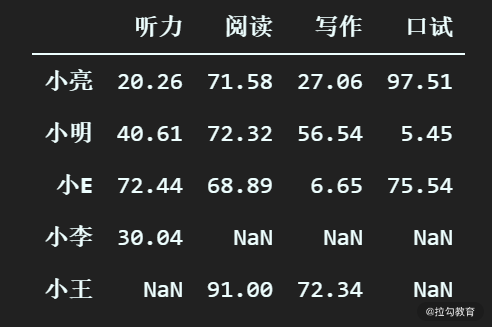
假设阿普闪购举办了一次全员英语能力考试,每个员工最后都有听力、阅读、写作、口试四个成绩。这里我们抽样了三个同事的分数数据,打算对其做一些简单的分析。如下所示
scores = [[20.26, 71.58, 27.06, 97.51],[40.61, 72.32, 56.54, 5.45],[72.44, 68.89, 6.65, 75.54]]
执行上述代码,接下来我们需要将分数数据导入到 DataFrame 中。代码如下:
import pandas as pd
# DataFrame 的列名
index_arr = ["听力", "阅读", "写作", "口试"]
# 从 scores 列表中创建 DataFrame
# index 参数代表行索引
# columns 参数代表列索引
df_scores = pd.DataFrame(scores,index = ["小亮", "小明", "小E"],columns= index_arr)
# 打印 DataFrame
df_scores
输出为:
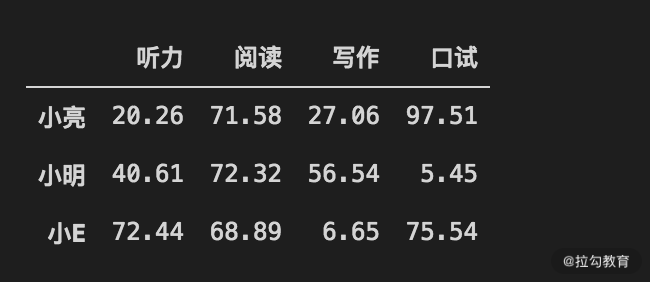
现在,三位同事的分数已经被录入了,但这会儿你的 Mentor 希望你把小李的成绩纳入一起分析。但小李的我们只有听力成绩,不知道另外三项的成绩。
代码如下:
# 生成小李的 Series,没有的成绩用 None 取代
ser_xiaol = pd.Series([30.04,None,None,None], index=index_arr,name="小李")
# 将小李的 Series 添加到 df_scores 中
df_scores = df_scores.append(ser_xiaol)
# 查看 df_scores
df_scores
执行代码后,输出如下:
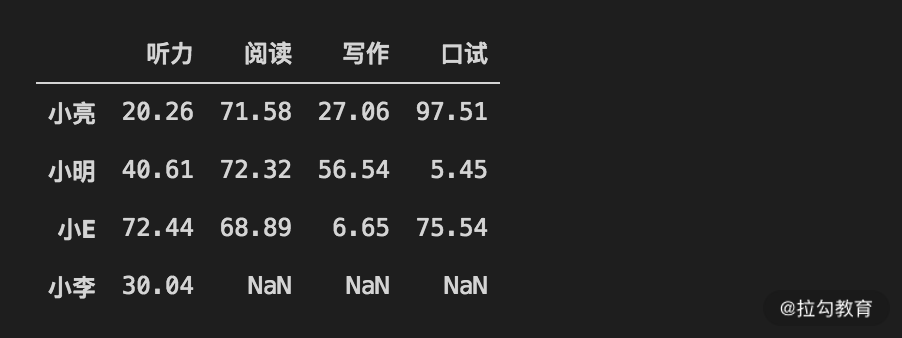
可以看到,小李的阅读、写作和口试显示了 NaN,代表数字类型的缺失值。时间类型的缺失值一般显示为 NaT,而字符串类型的则显示为 None。
在实际项目中,缺失值可以说一直存在于原始的数据源中。如果我们在数据分析时不把它处理掉,很可能会得到错误的结果。
以这个例子来说:如果要计算写作科目的平均分,小李的 NaN 到底是当作 0,还是当作平均数,还是干脆就不把小李纳入计算,都需要根据情况进行决策,来最大化降低缺失值对于分析结果的影响。
接下来我们会介绍对于缺失值不同策略的实现方式。
查询缺失值
要处理缺失值,首先第一步是查询缺失值是否存在,以及数量情况如何。与上述例子不同,现实项目中我们是不知道 DataFrame 中是不是有缺失值以及到底有多少缺失值。
接下来,我们会学习如何查询 DataFrame 中的缺失值情况。为了更好地演示如何查看缺失值,我们再添加一条记录到 DataFrame。
# 生成小王的 Series,没有的成绩用 None 取代
ser_xiaowang = pd.Series([None, 91.00, 72.34, None], index = index_arr, name="小王")
# 将小王的 Series 添加到 df_scores 中
df_scores = df_scores.append(ser_xiaowang)
# 查看 df_scores
df_scores
执行之后,最新的 DataFrame 如下图所示。
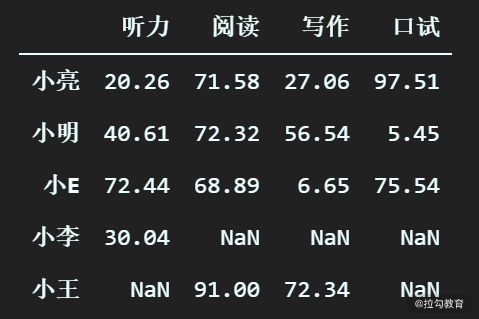
接下来我们开始分析缺失值的情况
1. 按单元格查看缺失值情况
DataFrame 提供了 isna 函数,isna 函数返回一个新的 DataFrame, 行数和列数和原 DataFrame 相同,新的 DataFrame 全部由布尔型数据组成,原 DataFrame 的单元格的数据是缺失值的话,在新的 DataFrame 对应位置的单元格就是 True,否则为 False。
# 调用 isna 函数,并查看结果
df_scores.isna()
输出:

可以看到,小李的 阅读、写作、口试,以及小王的 听力、口试是 True,代表在原来的 DataFrame 中这些数据是缺失值。
2. 按列查看缺失值
由于现实项目中的 DataFrame 往往很大,我们不可能逐一去看 DataFrame 每个单元格是 True 还是 False,所以更常见的查看手段就是按列聚合缺失值的数量。
我们只需要在 isna 函数的基础上再调用一次 sum 函数,即可实现按列聚合。
# 按列聚合缺失值并查看
df_scores.isna().sum()
输出为:

代表听力、阅读、写作三列都有一个缺失值,而口试一列有两个。
3. 按行查看缺失值
既然可以按列查看,自然也是可以按行查看的。按行查看可以帮助我们了解某个同事的缺失值情况。按行查看的实现方式和按列类似,只需要在 sum 函数的参数中传入 1 即可。
# 按行聚合缺失值并查看
df_scores.isna().sum(1)
输出为:

4. 过滤出有缺失值的列
有时候,我们希望单独将有缺失值的列过滤出来,查看大概情况,这时候配合使用 isna 函数和上一讲学习的 loc 函数就可以实现。
# 行索引部分,取所有的行
# 列索引部分,取所有包含缺失值的列
# any 函数类似 sum 函数,但any 函数做的是布尔聚合,当列有一个或以上的 True 时,结果就是 True, 否则为 False
df_scores.loc[:, df_scores.isna().any()]
输出为:
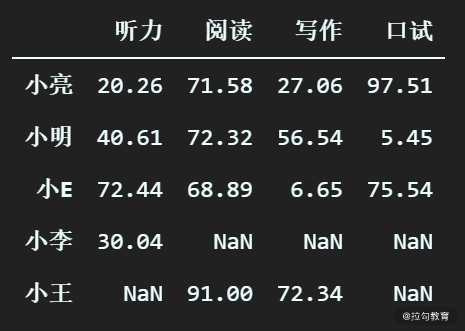
因为目前我们的 DataFrame 每一列都至少包含一个缺失值,所以过滤列之后输出了所有记录。
5. 过滤出有缺失值的行
对应的,如果我们想过滤出有缺失值的行,同样也可以通过 loc 配合 isna 实现。
# 行索引部分,通过 any(1) 来聚合行维度的结果
# 列索引部分,取所有的列
df_scores.loc[df_scores.isna().any(1),:]
输出为:

可以看到,包含缺失值的小李和小王的记录被过滤了出来。
6. 缺失值的总个数
对 isna 返回的布尔 DataFrame 做 sum,则可以得到各列各行有多少个缺失值,如果再对这个结果再做一次 sum,则可以得到整个 DataFrame 包含多少个缺失值。
df_scores.isna().sum().sum()
输出为:
5
这代表整个 DataFrame 一共包含五个缺失值。
处理缺失值
在查询出缺失值后,接下来就是根据分析的场景和缺失值的情况,来决定怎么处理这些缺失值。
常见的缺失值处理方法有以下三种。
1. 缺失值删除
顾名思义,删除代表的就是我们直接将缺失值从 DataFrame 中删除,一般在缺失值比较少的情况下可以用删除来简单处理。
pandas 的 DataFrame 提供了一个强大的删除缺失值的方法:dropna, 通过传入恰当的参数,我们可以灵活地删除部分或者全部的缺失值。
(1)删除所有缺失值所在的行
df_scores.dropna()
输出为:

(2)删除所有缺失值所在的列
df_scores.dropna(axis = 1)
输出为:

因为我们的 DataFrame 每一列都至少有一个缺失值,所以删除后 DataFrame 只剩下行索引。
(3)删除少于 X 个正常值的行
有时候,我们希望删除缺失值较多的行,保留有缺失值但数量比较少的行,可以通过指定 thresh 参数来实现。
# 删除正常值小于 2 个的行
df_scores.dropna(thresh=2)
输出为:
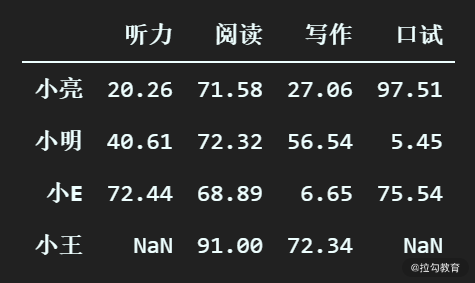
可以看到,小李的正常值只有 1 个,所以被删除。而小王的正常值有两个,所以被保留。
(4)参考某几列作为删除依据
有的时候,我们的数据表中不同的列权重(重要性)是不一样的。比如这次职工英语考试,最关键的是听力,所以我们希望只看听力这一列,如果听力是缺失值,则删除,其他列有缺失值则不删除。可以通过 subset 参数实现。
# 删除写作一列是缺失值的所有行
df_scores.dropna(subset=["听力"])
输出为:
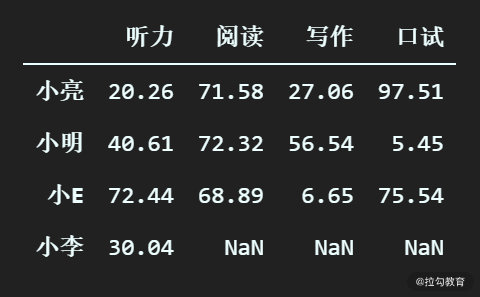
可以看到,小王的记录被删除,而小李的被保留,原因就是小李的听力成绩是在的,而我们通过 subset 参数指定了只看听力这一列的缺失值情况。
另外,需要注意一点的是,dropna 方法默认不会改变调用它的 DataFrame,而是会将删除缺失值后的 DataFrame 作为函数的返回值返回。所以上面的代码并没有实际修改到 df_scores。如果需要实际修改 df_scores ,则需要做一次赋值,比如: df_scores = df_scores.dropna()
2. 缺失值替换
除了删除之外,另一个主流的缺失值处理方式就是替换。简单来说就是将缺失值的部分替换为一个固定的值,来减少缺失值带来的对于分析结果的不确定性。当数据量大且缺失值的数量也不小的时候,使用填充策略相比删除策略能显著提升分析结果的准确性。
常见的缺失值替换策略有以下几种。
(1)全表固定值替换
最简单的缺失值替换方式,就是使用一个默认值来替换 DataFrame 中所有的缺失值。首先我们先看一下目前 DataFrame的缺失值情况
df_scores
输出为:
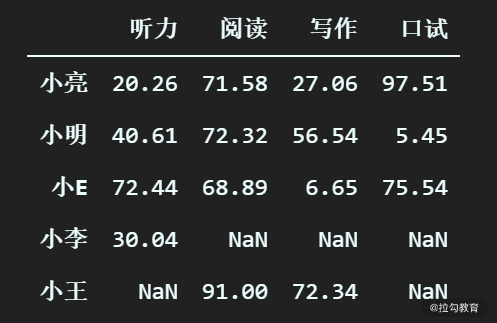
现在,我们用 33.0 这个数字来替换掉全部的缺失值。代码如下:
df_scores.fillna(33.0)
输出为:

可以看到,所有的缺失值已经被替换为了 33.0。
(2)按列固定值替换
除了全局替换,我们也可以实现按列来替换缺失值,为了不影响 df_scores 的值,这里我们用一个新的 DataFame 来测试。
# 复制一个 DataFrame, 命名为 df_scores_test
df_scores_test = df_scores.copy(deep=True)
# 将听力一列的缺失值填充为 60
df_scores_test["听力"] = df_scores_test["听力"].fillna(60.0)
# 查看
df_scores_test
执行之后,输出为:
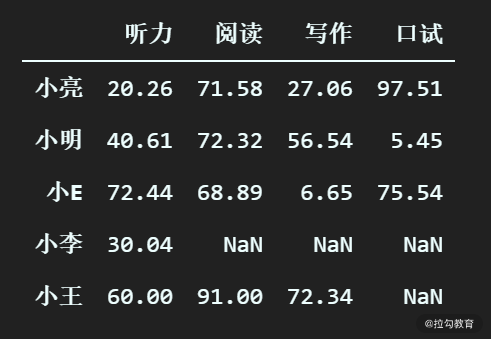
小王的听力成绩被填充为了 60分。
(3)按行固定值替换
按行填充和按列填充类似,只是索引单行就需要借助 loc 对象,因为按行列填充都会修改到原始 DataFrame,所以这里我们仍然使用 df_scores_test 来进行测试。
# 将 小李 一行的缺失值统一填充为 50.0
df_scores_test.loc["小李", :] = df_scores_test.loc["小李",:].fillna("50.0")
# 查看
df_scores_test
输出为:
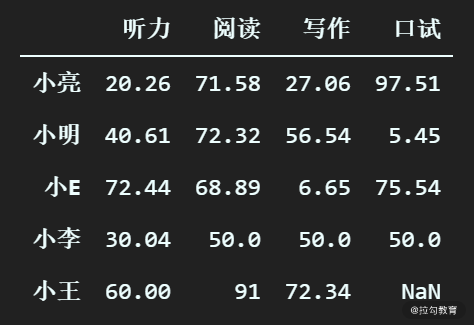
可以看到,小李的阅读、写作、口试成绩都被填充为了50.0。
(4)最近有效值替换
在实际的项目中,除了使用固定值之外,还有一个常见的策略就是使用最近有效值来做替换。
什么叫最近有效值呢?就是在列的维度,当某一个单元格的数据是缺失值时,在该列往上搜索,碰到第一个有效值(非缺失值),就是最近有效值。
听起来比较绕,我们举例来说明一下,还是以 df_scores 这个 DataFrame 为例,数据如下。
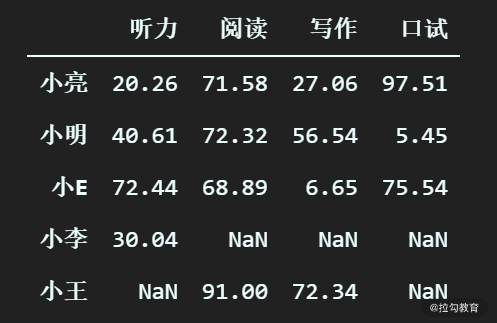
小王的听力是缺失值,那在该列往上找,第一个有效值就是小李的听力成绩:30.04 ,所以 30.04 就是小王的听力的最近有效值。
同理可得小李的阅读的最近有效值是 68.89,以此类推。
pandas 中要实现最近有效值填充,给 fillna 函数传入 method 参数即可。代码如下:
df_scores.fillna(method="ffill")
输出为:
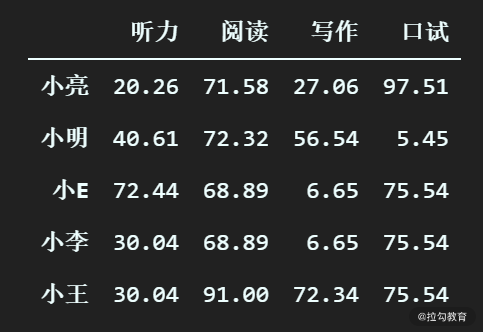
可以看到,几个缺失值的位置都被对应的最近有效值替换了。最近有效值灵活利用了列的数据特性,比起全局统一值的替换往往能达到更好的效果。
当我们设置 method="bfill" 的时候,pandas 就会用缺失值对应列,往下搜索的第一个有效值来填充。
3. 缺失值插值
在有的场景下,只使用最近有效值依然不能很好地满足分析的诉求。比如一些时间序列分析的场景,缺失值可能和前面或者后面的数据都有一定的关系。
如果可以结合缺失值前后的有效值的信息来推测缺失值,那准确性相比直接用最近有效值要高很多。pandas 提供了插值方法来实现这一目的。
插值简单来说就是通过已经有的点来拟合出一个函数关系(f),然后根据缺失值的位置(x)来去拟合出来的函数中拿到对应的 f(x) 值,然后用这个值去替换掉缺失值。这样我们认为这个 f(x) 是最有可能贴近真实的值的。
插值的方法有很多,最简单的有线性插值、临近点插值、立方插值等。这里以简单的线性插值为例来介绍 pandas 插值的用法。
假设我们有如下 Series:
ser_test = pd.Series([100,3, None, None, 9])
ser_test
执行之后输出:
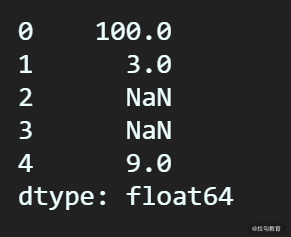
目前 ser_test 中有两个缺失值,想要通过线性插值来计算出这两个缺失值的话,我们可以拿到缺失值前后的两个数据点(1,3.0), (4, 9.0),根据两点直线方程有:
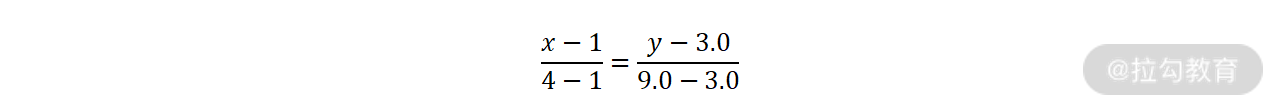
化简可得:y = 2x + 1, 将缺失值的行索引 2 和 3代入该函数,可以得到插值分别为 5 和 7。
以上是线上插值的原理,实际我们在写代码中并不需要手算,pandas 提供了 interpolate 函数可以帮助我们直接搞定。
现在我们来计算 ser_test 的插值情况。
# 调用 interpolate 对 Series 进行插值,默认为线性插值
ser_test.interpolate()
输出为:

可以看到,填充的结果和我们手算的结果是一样的。
现在,我们使用插值的方法来填充 df_scores 这个 DataFrame。当对 DataFrame 使用 interpolate时,实际上是每个列 Series 分别计算并插值的。代码如下:
df_scores.interpolate()
输出为:
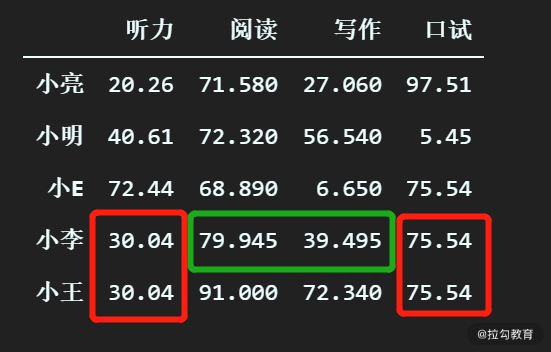
从结果上,可以看到绿框的两个缺失值成功替换为了线性插值的版本,而红框部分却仍然是用的最近有效值,这是为何呢?其实很简单,线性插值需要缺失值前后有效值的信息来拟合方程,而红框部分都缺少后面的有效值,所以无法拟合。当线性插值无法拟合的时候,会默认采用最近有效值来填充。
4. 处理重复值
除了常见的缺失值之外,实际项目中还经常遇到的异常数据问题就是重复值。企业的数据日志记录系统出现问题时,有时候会导致丢失数据,这就产生了缺失值的问题。有的时候会重复写入数据,这也产生了重复值的问题。
重复值指的是 DataFrame 中的两行全部或部分一样。
为了更好地演示如何处理重复值,我们先模拟一下重复值的场景,额外添加两条小王的记录进 DataFrame。
# 生成一条一模一样的小王的记录
ser_xiaowang = pd.Series([None, 91.00, 72.34, None], index = index_arr, name="小王")
# 将新增加的两 Series 添加到 df_scores 中
df_scores = df_scores.append(ser_xiaowang)
# 查看 df_scores
df_scores
输出为:
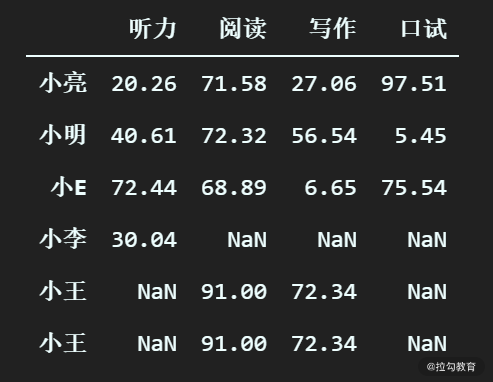
pandas 提供了 duplicated 函数来识别 DataFrame 中是否存在重复的行,执行 duplicated 后返回一个布尔类型的 Series,并将重复的行标记为 True, 其他为 False。用法如下:
df_scores.duplicated()
输出:

从结果中可以看到,第一个小王的记录,因为是第一次出现,不算重复,所以标记为 False,而第二个小王的记录因为是第二次出现了,所以标记为 True,也就是重复。
确认有重复的数据后,我们只需要调用 pandas 提供的 drop_duplicates 方法即可删除这些重复值。
# 我们需要修改 df_scores ,所以需要将 drop_duplicates 的结果赋值回 df_scores
df_scores = df_scores.drop_duplicates()
df_scores
输出为:
小结
到此,我们对于缺失值和重复值的处理就讲解完了。相信现在你拿到一个不完美的数据集,已经知道如何下手进行初步的分析和数据清洗了。
回顾一下,今天我们主要学习了如下关键点。
缺失值的概念:DataFrame 中缺少的部分数据,数字的显示为 NaN,字符串显示为 None,时间类型则显示为 NaT。
查看缺失值:
按单元格查看:df.isna()
按列查看:df.isna().sum()
按行查看:df.isna().sum(1)
有缺失值的列:df.loc[:, df.isna().any()]
有缺失值的行:df_scores.loc[df_scores.isna().any(1),:]
缺失值总个数:df.isna().sum().sum()
处理缺失值:
删除缺失值:df.dropna()
缺失值替换:df.fillna()
缺失值插值:df.interpolate()
处理重复值:
查看重复行:df.duplicated()
删除重复行:df.drop_duplicates()
到现在,pandas 的学习已经结束了大半儿。下一讲我们会专门学习数据分析领域常见的挑战:时间序列数据的分析与处理。
15 时间序列:时间数据的解析与应用
在很多数据分析任务中,经常会遇到处理时间相关的数据。比如电商网站经常需要根据下单记录来分析不同时间段的商品偏好,以此来决定网站不同时间段的促销信息;又或者是通过对过去十年的金融市场的数据进行分析,来预测某个细分版本的未来走势。在这些任务中,时间信息的处理都是重中之重。
时间数据的处理不同于对常见的数字、字符串等数据的处理方式,时间数据处理起来往往会比较复杂。
比如数据表中有一个表示时间的字符串:"2018/02/01",我们希望提取其年、月、日,就需要去解析,分割该字符串。而往往我们会遇到各种不同格式的表示,比如"01/02/2018",或者 "2018-2-1", 等等。如果要完全实现针对不同格式的兼容,往往需要书写大量琐碎的代码。而这还只是最简单的提取年月日。其他比如时间的加减,都不是简单就能够完成的。
pandas 作为数据分析最强大的工具集,自然也提供了一套非常强大的处理时间数据的工具,本讲我们就来具体介绍。
核心概念:时间和时间序列
pandas 提供了丰富的处理时间的工具和类,其中最常用的有以下几种。
Timestamp:代表某一个时间点。比如用户某个购物订单下单的时间,或者某次网页点击的时间。
DatetimeIndex:代表一个时间点的序列,换句话说就是多个 Timestamp 构成的列表。DatetimeIndex 可以作为 Series 和 DataFrame 的索引。
Timedelta:单个时长。比如 2 个小时,4 分钟等都算时长,时长具有不同的单位,常见的单位有天、时、分、秒等等。本质上,时长代表两点时间点(Timestamp)的距离。
TimedeltaIndex:多个时长数据的序列。类似 DatetimeIndex 和 Timestamp 的关系。TimedeltaIndex 就是多个 Timedelat 组成的列表,也可以作为 Series 和 DataFrame 的索引。
DataOffset:时间在日历维度的偏移。比如 2018 年 2 月 1 日早上 6 点,在日历上偏移一点就是 2018 年 1 月 31 日早上 6 点。DataOffset 提供了各种方便的偏移方式,比如按照工作日偏移。星期五早上 10 点,偏移一个工作日,可以自动返回下周一早上 10 点。
在使用 pandas 做时间处理的时候,最常见的场景就是:
将来自数据源的时间描述(比如字符串或者整型)等表示,转化为 Timestamp类型;
使用 Timestamp 类型来访问时间的各种属性,比如年月日、星期几等;
使用 Timestamp 配合 Timedelta 来做时间相关的计算和加减等,如果是在日历维度的计算,则配合 DataOffset 一起使用;
如果需要从时间的维度来筛选 DataFrame 里的记录,则需要先将时间列设置为 DatetimeIndex, 然后按照普通索引的用法通过时间来筛选。
接下来,我来逐一介绍下这 4 种场景的实现方式。
首先我们创建 chapter15 的文件夹,用 VS code 打开,并新建 chapter15.ipynb,保存到该文件夹中。
时间数据的解析
时间数据的解析本质就是将各种不同类型的时间表示都统一转换为 pandas 的 Timestamp 类型。因为只有转换为 Timestamp 之后才能进行后续的操作。
pandas 提供了 to_datetime 方法,来将各种不同类型的时间数据转换为 Timestamp 类型。
(1)解析字符串
字符串是最常见的数据源中存储时间的方式,to_datetime 函数近乎支持所有主流的时间字符串标记法,比如:
import pandas as pd
# 常见的日期+时间的表示方法
pd_time = pd.to_datetime("2018-08-29 17:17:22")
print(type(pd_time),pd_time)
# 时间简写,并用12小时制的表示方法
pd_time1 = pd.to_datetime("2018-08-29 5:17pm")
print(type(pd_time1), pd_time1)
# / 表示法
pd_time2 = pd.to_datetime("08/29/2018")
print(type(pd_time2), pd_time2)
# 结合英文月份的表示方法
pd_time3 = pd.to_datetime("Aug 29, 2018")
print(type(pd_time3), pd_time3)
执行之后,输出:
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2018-08-29 2018-08-29 17:17:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2018-08-29 00:00:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2018-08-29 00:00:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2018-08-29 00:00:00
从上面输出的结果可以看到,to_datetime 函数返回的是 Timestamp 类型。并且该函数默认就支持从常见的用字符串表示的时间格式中解析出 Timestamp 结构。
如果我们想解析的时间字符串不是常见的类型呢?比如中文环境中,类似“2018 年 8 月 29 日”这样的表示方法还是会经常遇到的。答案是可以的。
to_datetime 支持我们自定义时间格式字符串来进行解析。在时间格式字符串中,%Y 表示年份,%m 代表月,%d 代表日。
比如要解析刚才的中文时间,对应的格式字符串就是: "%Y年%月%日"。代码如下:
# 使用自定义格式字符串解析任意时间字符串
pd_time4 = pd.to_datetime("2018年8月29日", format="%Y年%m月%d日")
print(type(pd_time4), pd_time4)
执行之后,输出如下。因为我们没有指定时分秒,所以这个部分默认为 0 。
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2018-08-29 00:00:00
(2)解析整型/浮点型时间戳
在很多数据系统中,时间也经常以时间戳的形式存在。时间戳一般指的是 1970 年 1 月 1 日到某个时间点的秒数。比如一个特定的时间点:北京时间的 2021-05-09 21:06:44, 对应的时间戳就是:1620565604,代表从 1970 年 1 月 1 日零时零分零秒到 2021 年 5 月 29 日下午 9 点 6 分 44 秒一共有 1620565604 秒。
to_datetime 同样支持直接将时间戳转换为 Timestamp 类型,用法如下:
time_value = 1620565604
# 将数字时间戳转换为 Timestamp 类型,并指定单位为秒
pd_time5 = pd.to_datetime(time_value, unit="s")
print(type(pd_time5), pd_time5)
输出:
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2021-05-09 13:06:44
Timestamp 对象已经正确构建,但是为什么是 13 点 06 分,而不是刚才的 21 点 06 分? 原因是通过 to_datetime 默认是格林威治时间,也就是零时区,落后北京时间 8 小时。如果算上 8 小时的偏移,13+8 就正好是 21 点 06 分了。如果我们希望在构造 Timestamp 对象时就指定时区,可以调用 tz_localize 指定。
# 转换时间戳并指定时区
pd_time6 = pd.to_datetime(time_value, unit="s").tz_localize("Asia/Shanghai")
print(type(pd_time6), pd_time6)
输出:
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2021-05-09 13:06:44+08:00
可以看到,这次输出的内容多了一个 +08:00 代表已经带上了时区。
(3)直接构造 Timestamp 对象
除了上述两种方式外,我们可以直接构建 Timestamp 对象。比如通过指定年月日,或者直接获取程序运行的时间。主要包括以下用法:
# 通过单独指定年月日等信息来创建 Timestamp 对象
pd_time7 = pd.Timestamp(year=2018, month=8, day=29, hour= 21)
print(type(pd_time7), pd_time7)
# 获取当前的时间
pd_time8 = pd.Timestamp("now")
print(type(pd_time8), pd_time8)
输出:
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2018-08-29 21:00:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 2021-05-09 21:54:38.064474
时间属性的提取
当我们获取到 Timestamp 对象之后,就可以通过 Timestamp 对象提供的方法来轻松获取各种时间的属性了。常见的属性获取方法如下所示:
print("当前时间对象:", pd_time8)
print("星期几,星期一为0:", pd_time8.dayofweek)
print("星期几,字符串表示:", pd_time8.day_name())
print("一年中的第几天:", pd_time8.dayofyear)
print("这个月的有几天:",pd_time8.daysinmonth)
print("今年是否是闰年", pd_time8.is_leap_year)
print("当前日期是否是本月最后一天", pd_time8.is_month_end)
print("当前日期是否是本月第一天", pd_time8.is_month_start)
print("当前日期是否是本季度最后一天", pd_time8.is_quarter_end)
print("当前日期是否是本季第一天", pd_time8.is_quarter_start)
print("当前日期是否是本年度最后一天", pd_time8.is_year_end)
print("当前日期是否是本年度第一天", pd_time8.is_year_start)
print("当前第几季度:", pd_time8.quarter)
print("当前的时区:", pd_time8.tz)
print("本年第几周:", pd_time8.week)
print("年:", pd_time8.year)
print("月:", pd_time8.month)
print("日:",pd_time8.day)
print("小时:", pd_time8.hour)
print("分钟:", pd_time8.minute)
print("秒:", pd_time8.second)
输出:
当前时间对象: 2021-05-09 21:54:38.064474
星期几,星期一为0: 6
星期几,字符串表示: Sunday
一年中的第几天: 129
这个月的有几天: 31
今年是否是闰年 False
当前日期是否是本月最后一天 False
当前日期是否是本月第一天 False
当前日期是否是本季度最后一天 False
当前日期是否是本季第一天 False
当前日期是否是本年度最后一天 False
当前日期是否是本年度第一天 False
当前第几季度: 2
当前的时区: None
本年第几周: 18
年: 2021
月: 5
日: 9
小时: 21
分钟: 54
秒: 38
使用方法比较直观,这里就不展开解释。
时间数据的计算
pandas 中,时间数据的计算值的是时间数据的加减,比如在一个时间点上增加几小时、几分钟、或者几天,几个月来得到加了之后的时间。因为时间并不像数字运算一样简单,而是有很多潜在的规则在里面,比如一分钟 60 秒,一小时 60 分钟,一天 24 小时,一个月可能有 28 天,也可能有 30、31 天,等等,如果我们手写计算逻辑将会非常复杂。
pandas 提供了一套强大的时间计算机制来让我们不用关系背后的规则就能完成时间的计算。pandas 的时间计算是通过 Timestamp 对象和 Timedelta 对象混合运算来实现。Timedelta 可以理解成一个时间段,或者说,时间长度。最常见的运算有以下两种类型:
两个 Timestamp 对象相减,可以得到一个 Timedetla 对象;
一个 Timestamp 对象 加上或者减去一个 Timedelta 对象,可以获得一个新的 Timestamp 对象。
所以要实现时间的运算,我们首先要创建 Timedelta 对象。
Timedelta 对象的创建
Timedelta 对象和 Timestamp 对象类似,也支持多种形式的创建。
(1) 从字符串来创建
Timedelta 对象支持解析多种描述时长的格式。我们通过代码来展示:
delta1 = pd.Timedelta('0.5 days')
print("半天:", delta1)
delta2 = pd.Timedelta("2 days 3 hour 20 minutes")
print("2天零3小时20分钟", delta2)
delta3 = pd.Timedelta("1 days 20:36:00")
print("1天零8小时36分钟:", delta3)
执行之后输出:
半天: 0 days 12:00:00
2天零3小时20分钟 2 days 03:20:00
1天零8小时36分钟: 1 days 20:36:00
(2)从单元时间创建
除了通过一定格式的字符串来创建 Timedelta 对象之外,我们还可以通过设置函数的参数来创建 Timedelta 对象,比如这样表示:
delta4 = pd.Timedelta(days = 1.5)
print("1天半:", delta4)
delta5 = pd.Timedelta(days = 10, hours= 9)
print("十天零九小时:", delta5)
输出:
1天半: 1 days 12:00:00
十天零九小时: 10 days 09:00:00
(3)从时间缩写创建
还有一种简洁的形式来创建 Timedelta,就是通过数字+缩写的形式。缩写主要有以下几种:
W:代表周、星期
D:代表天
H:代表小时
M:代表分钟
S:代表秒
具体使用方法如下:
delta6 = pd.Timedelta("2W3D")
print("两周零三天:", delta6)
delta7 = pd.Timedelta("6H30M12S")
print("6小时30分钟12秒:", delta7)
输出
两周零三天: 17 days 00:00:00
6小时30分钟12秒: 0 days 06:30:12
执行时间的计算
在学会如何创建 Timedelta 对象之后,要做时间的计算就非常简单了。我们直接上代码:
# 获得当前的时间
current_time = pd.Timestamp("now")
print("当前时间:", current_time)
# 获得当前时间减去两周的时间
two_week_ago = current_time - pd.Timedelta("2W")
print("两周前:", two_week_ago)
# 获得当前时间30天零7小时之后的时间
future_time = current_time + pd.Timedelta("30D7H")
print("30天零7小时之后的时间:",future_time)
执行之后,输出:
当前时间: 2021-05-09 23:46:09.346063
两周前: 2021-04-25 23:46:09.346063
30天零7小时之后的时间: 2021-06-09 06:46:09.346063
除了计算 Timedelta 和 Timestamp 外,两个 Timestamp 也能相减,得出一个时长(也就是 Timedelta)。
# 创建去年国庆节上午八点的时间
national_day = pd.to_datetime("2020-10-01 08:00:00")
# 计算当前时间和国庆时间的 Timedelta
delta8 = current_time - national_day
print("距离去年国庆已经过了:", delta8)
执行之后,输出:
距离去年国庆已经过了: 220 days 15:46:09.346063
时间数据作为索引
除了两个时间点的各种操作之外, pandas 还支持将时间数据作为索引,这样就能够支持各种时间维度的选择。为什么这个特性非常重要,我们以一个例子来说明。
首先从课程的 Github 仓库的 chapter15 目录中,下载 order_record.csv 文件,并将其保存在你 chapter15 的工作目录中。
我们首先先将数据集加载出来,看看里面有什么:
# 加载 order_record.csv 文件
df_log = pd.read_csv("order_record.csv")
# 查看 DataFrame
df_log
输出:
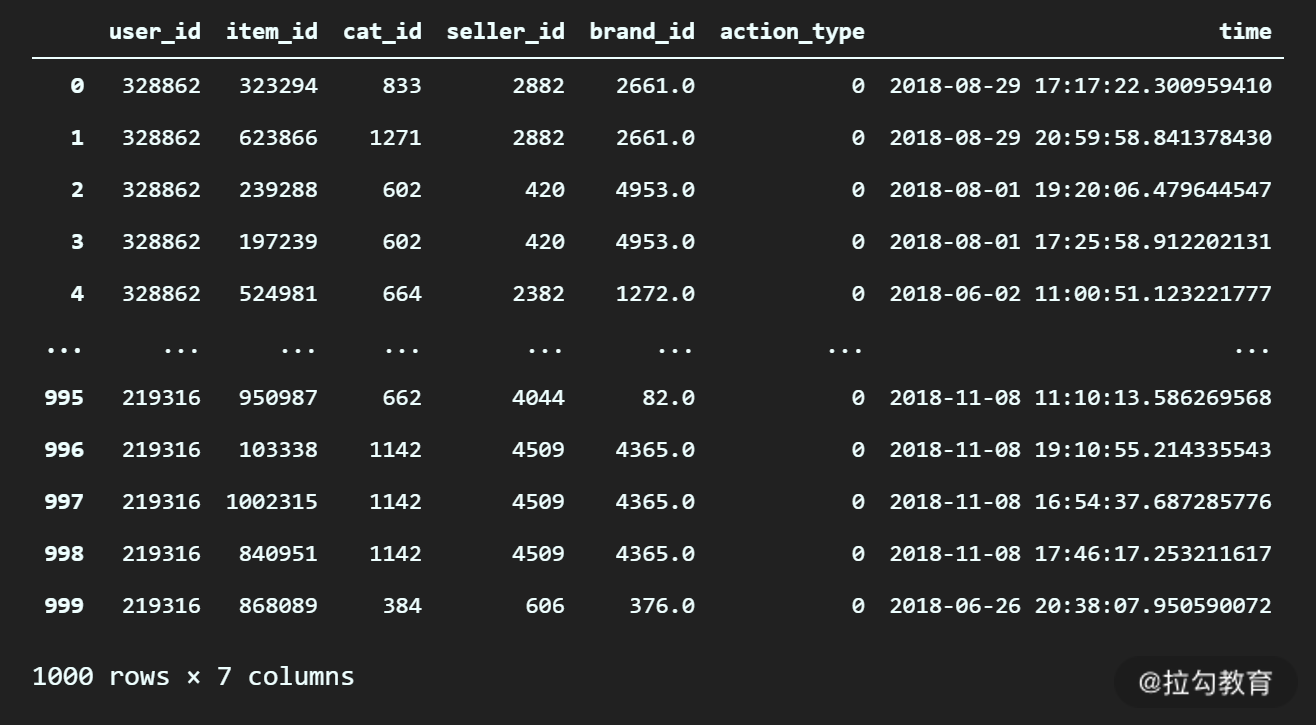
这是一个电商网站用户购买的记录数据,一共有一千条内容。从最后一列时间列来看,时间跨度在 2018 年 6 月到 11 月都有。
如果我们希望能够方便地进行时间维度的分析,比如查看 9 月 1 日到 9 月 15 日的记录,或者 8 月到 9 月的记录。那可以考虑将 time 一列转化为 DatetimeIndex。这样我们就能够直接对时间进行索引。
设置 DatetimeIndex
将字符串的时间一列转化为 DatetimeIndex, 一般分为两步:第一步首先将时间一列转化为 Timestamp 对象。
# 将 time 列转化为 Timestamp对象
df_log["time"] = pd.to_datetime(df_log["time"])
# 查看 time 列
df_log["time"]
执行之后输出:
0 2018-08-29 17:17:22.300959410
1 2018-08-29 20:59:58.841378430
2 2018-08-01 19:20:06.479644547
3 2018-08-01 17:25:58.912202131
4 2018-06-02 11:00:51.123221777...
995 2018-11-08 11:10:13.586269568
996 2018-11-08 19:10:55.214335543
997 2018-11-08 16:54:37.687285776
998 2018-11-08 17:46:17.253211617
999 2018-06-26 20:38:07.950590072
Name: time, Length: 1000, dtype: datetime64[ns]
可以看到,目前 time 列的数据类型已经转换为 Timestamp。
第二步就是将新的 time 这一列设置成索引。
# 设置 time 一列为 df_log 的索引
df_log.set_index("time", inplace=True)
# 查看最新的 DataFrame
df_log
执行之后,输出:
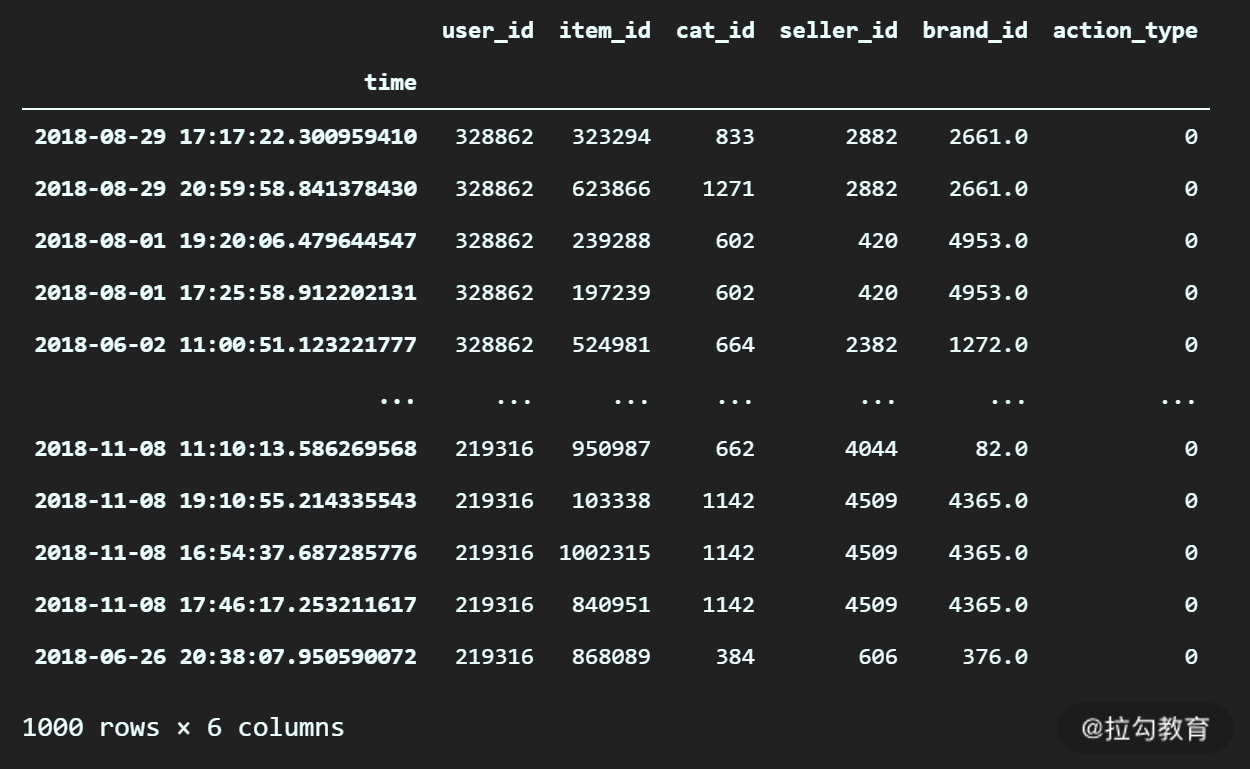
可以看到,现在时间列已经替代了之前默认的数字序号,成为 DataFrame 新的行索引。
现在我们可以查看一下 DataFrame 的索引类型。
df_log.index
输出:
DatetimeIndex(['2018-08-29 17:17:22.300959410','2018-08-29 20:59:58.841378430','2018-08-01 19:20:06.479644547','2018-08-01 17:25:58.912202131',...'2018-11-08 16:54:37.687285776','2018-11-08 17:46:17.253211617','2018-06-26 20:38:07.950590072'],dtype='datetime64[ns]', name='time', length=1000, freq=None)
可以看到,目前 df_log 表的索引就是我们开头介绍的 DatetimeIndex 类型。
基于时间筛选和过滤数据
在设置完 DatetimeIndex 之后,我们在之前提到的根据时间维度筛选就小菜一碟了。我们直接可以使用之前学习的 loc 索引器, 然后在行索引部分以字符串的形式写时间范围(开始时间和结束时间之间以冒号链接),具体用法见代码:
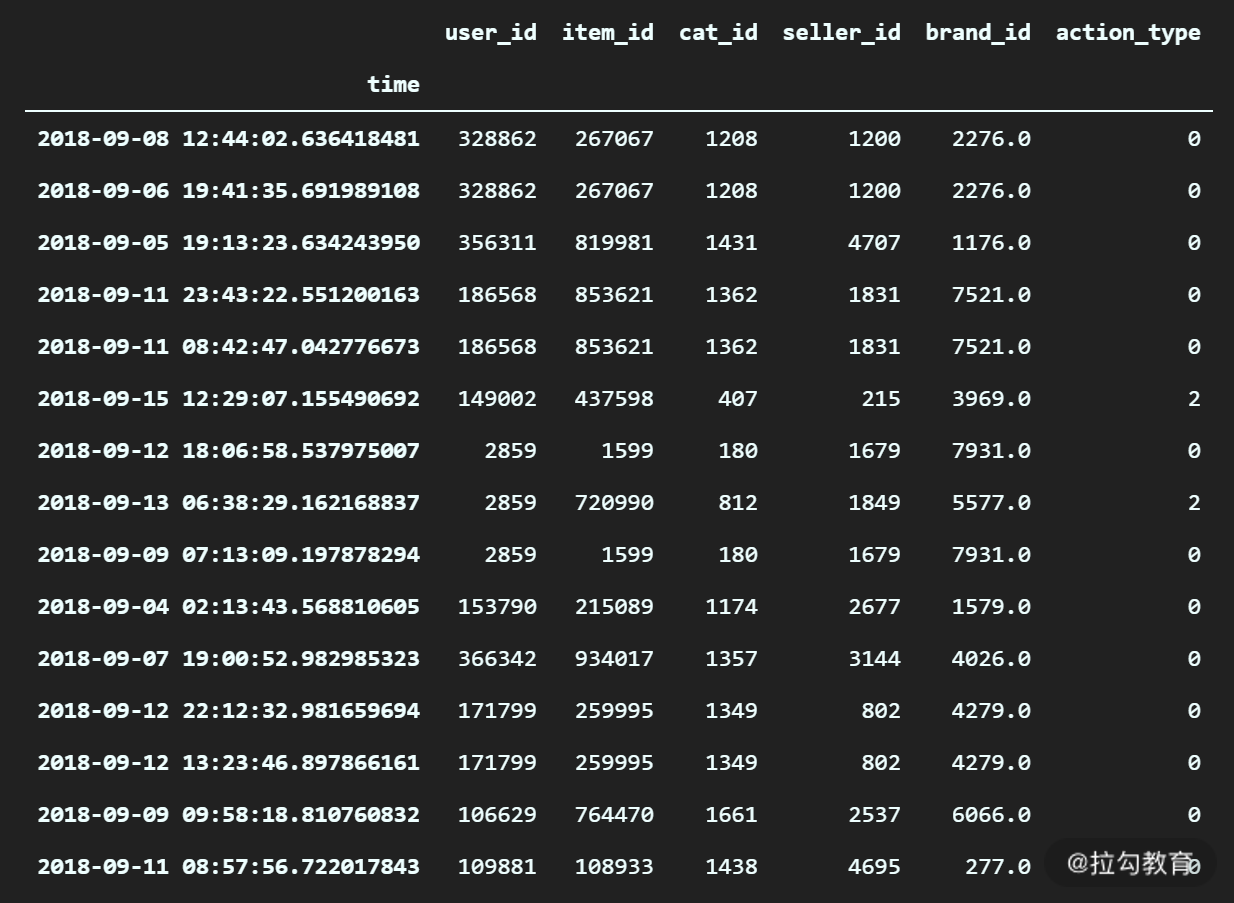
(1)选择从 9 月 1 日到 9 月 15 日的数据
df_log.loc["2018-09-01" : "2018-09-15",:]
输出(只截取了部分):
(2)选择从 8月到9月的数据
df_log.loc["2018-08" : "2018-09", :]
输出:
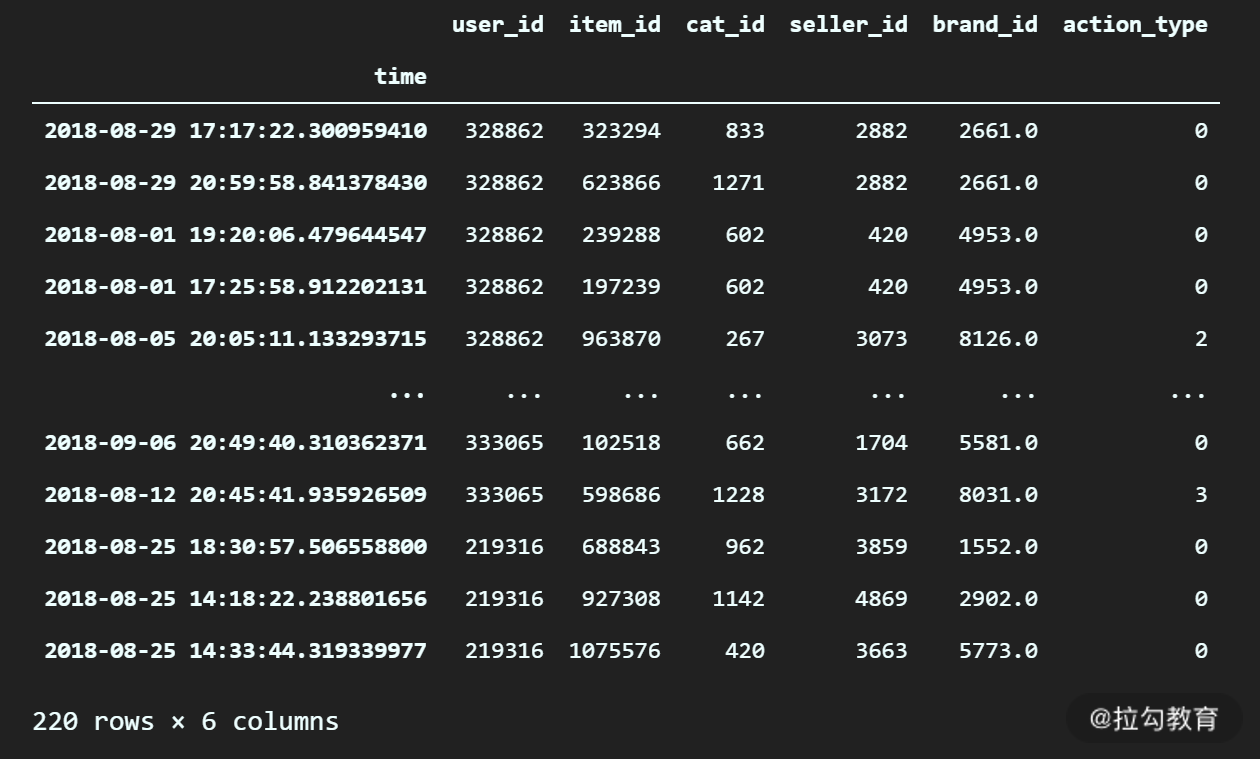
(3)选择从 8 月 1 日到 9 月 2 日下午两点之前的数据
df_log.loc["2018-08-01" : "2018-09-02 14:00:00", :]
输出:
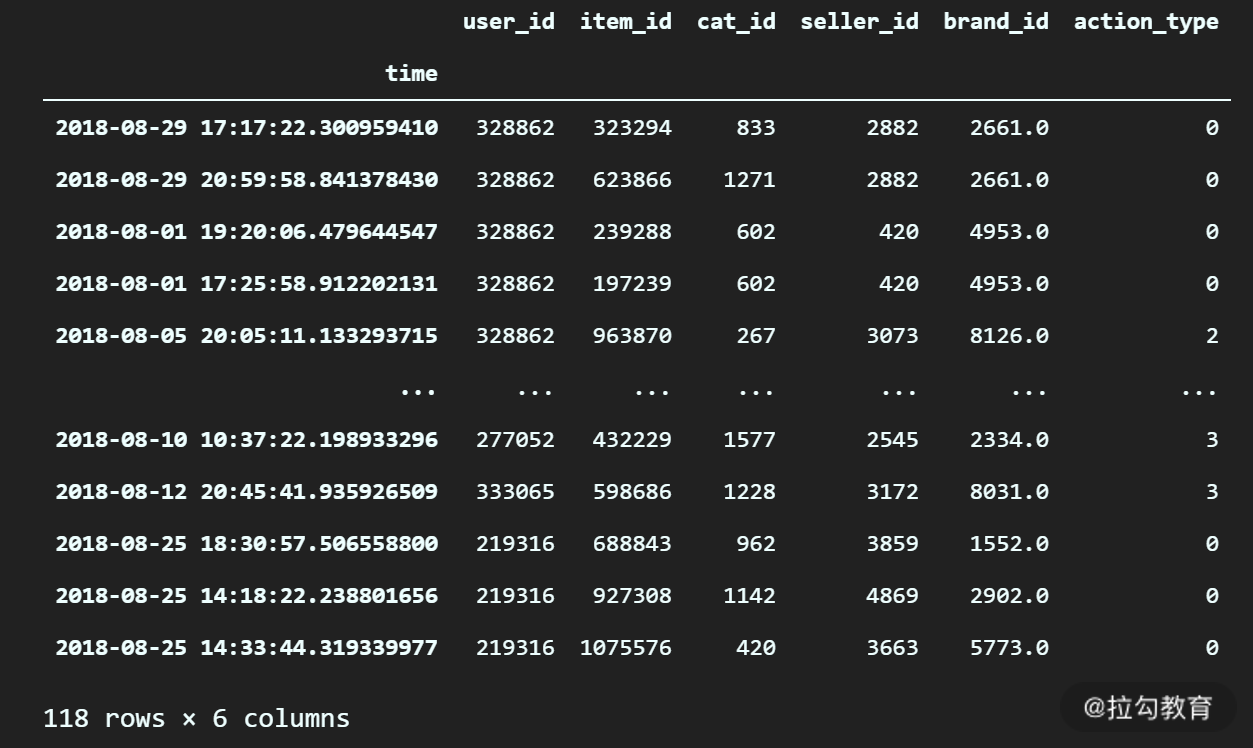
可以看到,当我们把 Timestamp 作为索引时,就可以非常简单地实现各种不同时间范围的筛选,并且时间范围的写法也非常自由。
小结
关于时间常用的处理技术至此就学习完毕了,我们来复习一下今天学习的内容。
1. 基本概念:
pandas 的时间处理体系主要包含这几个类。
Timestamp 代表时间点。
DatetimeIndex 代表多个 Timestamp构成的索引列表。
Timedelta 代表时间长度,用于做时间的计算
TimedeltaIndex 用于将 Timedelta做索引,但不常用。
2. 数据的解析:
通过 to_datetime 函数,可以将各类时间字符串、时间戳等表示形式转换为Timestamp 对象。同时也可以自定义时间格式字符串,用%Y、%m、%d 等格式字符来自定义解析。
3. 时间属性的提取:
Timestamp 对象提供了丰富的访问时间各种维度信息的能力,比如当前时间是星期几、在一年中是第几天,等等,具体见上面的示例代码。
4. 时间数据的计算:
在某个时间点上加减时间,需要用 Timedelta 对象来描述时间的长度。同样,Timedelta 对象也能从各种不同的数据生成,比如字符串、单位时间等。Timedelta 同时也可以表示两个 Timestamp 相减后的差。
5. 时间数据作为索引:
当我们希望从时间维度去筛选数据表中的数据的时候,可以将时间相关的列转换成 DatetimeIndex, 这样可以在行索引中直接写时间范围来筛选数据,非常方便。
学完了本讲,我们 pandas 相关的学习已经进入了尾声,是不是已经迫不及待想要用 pandas 做一个略微复杂的练习了呢? 下一讲我们将会融合最近几讲学习的内容,完成一个较为完整的数据分析。
思考题
思考一下,Timedelta 为什么不能按月创建?
答案:
Timedelta 代表一个绝对的时间长度,而一个月的天数是不固定的。
Python数据分析高薪实战第六天 数据过滤与数据清洗相关推荐
- Python数据分析高薪实战第十天 数据绘图进阶与实战
24 图像的脊柱.注解和图例:如何画出更专业的图表? 前面两节课,我们学习了主流的几种 matplotlib 的图形形式,主要包括折线图.散点图.直方图.条形图和饼图.现在我们已经可以画出样式比较多的 ...
- Python数据分析高薪实战第四天 python数据采集下载和提取保存
06 获取数据:公开数据集与 DIY 数据集 首先恭喜你完成了第一部分的学习.现在你已经基本掌握了 Python 的基础并能够使用 Python 完成一些相对完整的功能的开发,是时候开始进入数据分析的 ...
- Python数据分析高薪实战第四天 构建国产电视剧评分数据集
10 实战:手把手教你构建国产电视剧评分数据集 在前面几讲,我们已经学习完了爬虫技术的三个基础环节:下载数据.提取数据以及保存数据. 今天我们将通过一个综合的实战案例来将之前的内容都串联起来,帮你加深 ...
- Python数据分析高薪实战第十天 EDA实战-全球新冠肺炎确诊病例趋势分析
27 初识 EDA:全球新冠肺炎确诊病例趋势分析 从本讲开始,我们会通过四个具体的案例来将我们之前学习的 Python 数据分析方面的知识全都串起来.一方面能够融会贯通,另一方面也能帮你掌握数据分析基 ...
- Python数据分析高薪实战第一天 python基础与项目环境搭建
开篇词 数据赋能未来,Python 势不可挡 你好,我是千帆. 互联网公司从红利下的爆发期,进入新的精细化发展阶段,亟须深入分析与挖掘业务与数据价值,从而找到新的增长点突破现有增长瓶颈.各行各业的数据 ...
- Python数据分析高薪实战第十二天 网络服务用户流失预测分析和国产电视剧评分预测分析
29 综合实战:网络服务用户流失预测与分析 绝大多数互联网公司都面临一个非常重要的问题:用户流失问题.随着互联网和移动互联网的充分发展,发展新用户(也就是一般所说的拉新)的成本越来越高,往往要几块或者 ...
- Python数据分析高薪实战第七天 数据解析和电商行为分析案例
15 时间序列:时间数据的解析与应用 在很多数据分析任务中,经常会遇到处理时间相关的数据.比如电商网站经常需要根据下单记录来分析不同时间段的商品偏好,以此来决定网站不同时间段的促销信息:又或者是通过对 ...
- Python数据分析高薪实战第八天 数据计算统计与分析
17 如何快速实现数据的批量计算? 接下来我们会进入一个全新的模块:数值类数据分析.在这个部分,我们会学习数据分析中常用的数学方法以及 Python 中处理数值数据的神器:NumPy. 在完成了本部分 ...
- python数据分析实战案例-Python数据分析案例实战
原标题:Python数据分析案例实战 至今我们网站已经开设了多个数据分析系列的课程,大部分都是基于算法思路来开展的,课程中着重点在于算法的讲授.软件的使用,案例只是辅助学习.然而很多学员反映,希望可以 ...
最新文章
- 【硬核技能】舒工自创bind绑定数据方法,类似angular和vue绑定数据原理
- Bzoj4561 [JLoi2016]圆的异或并
- 【POJ - 3273 】Monthly Expense (二分,最小最大值)
- 字符的用意_北辰的符号意义 阅读答案
- 2021厦大计算机考研炸了,厦门大学2021年硕士研究生复试名单
- 从汇编的角度理解什么是引用
- 如何写一份优秀的投资计划书
- 【Axure高保真原型】用户详细画像可视化原型模板
- 【php】PHP数据库访问
- 如何确定自己测试结束?
- lumen报错Class redis does not exist
- 关于《算法(第四版 谢路云译)》标准库In、Out、StdOut和StdIn的正确配置和调用经验分享(以BinarySearch二分查找算法为例)
- html表格文字方向改变,excel表格怎么改变文字方向
- Transformer+目标检测,这一篇入门就够了
- 万维考试系统python_万维考试学生客户端
- 计算机主机接电视机,液晶电视机怎样才能连接电脑主机?
- TextToSpeech文字转语音、文字转音频文件并播放
- vanilla-tilt.js: 一个平滑的3D倾斜javascript库。
- kotlin中标准函数的使用(with、also、aply、let、run)
- 你还在用格式工厂转音频?
热门文章
- 中国乳腺X机市场研究与未来预测报告(2022版)
- 2021年茶艺师(中级)考试内容及茶艺师(中级)最新解析
- 改变-影响他人决策-引导他人思考的六种策略
- java拖拽选区_matplotlib之多边形选区(PolygonSelector)的使用
- linux反tp补丁,lol反tp补丁
- 安装双系统ubuntu18.04后,不能进入ubuntu界面的解决办法
- Jquery插件导出word之---html-docx.js
- CAD数据相互转换注意事项(一)
- 已解决:LNK2001 无法解析的外部符号 public: virtual void __cdecl CDigitalEarthView::OnInitialUpdate(void)
- vs2010、vs2013、vs2015、vs2017查看OF、ZF、SF标志位