如何降低疾病监测的漏诊比率?一种新的分类学习算法...
小叽导读:在高风险分类(例如:高死亡率疾病监测、自动驾驶等场景)中控制假阳性率是非常重要的,由算法得出的结果将对个人产生巨大的影响。遗漏一名潜在病人的风险,远远高于误诊一名正常人。因此,我们希望在保证分类器假阳性率(即错误地将负样本分类为正样本的概率) 低于某个阈值 τ 的前提下,最小化其误分正样本的概率。下面,我们就一起来看看阿里工程师如何实现这个目标。
作者:张翱,李楠,浦剑,王骏,严骏驰,查宏远
摘要
许多实际应用需要在满足假阳性率上限约束的前提下学习一个二分类器。对于该问题,现存方法往往通过调整标准分类器的参数,或者引入基于领域知识的不平衡分类损失来达到目的。由于没有显式地将假阳性率上限融合到模型训练中,这类方法的精度往往受到制约。
本文提出了一个新的排序——阈值方法τ-FPL 解决这个问题。首先,我们设计了一个新的排序学习方法,其显式地将假阳性率上限值纳入考虑,并且展示了如何高效地在线性时间内求得该排序问题的全局最优解;而后将学到的排序函数转化为一个低假阳性率的分类器。通过理论误差分析以及实验,我们验证了τ-FPL对比传统方法在性能及精度上的优越性。
研究背景
在疾病监测,风险决策控制,自动驾驶等高风险的分类任务中,误报正样本与负样本所造成的损失往往是不同的。例如,在高死亡率疾病检测的场景下,遗漏一名潜在病人的风险,要远高于误诊一名正常人。另一方面,两类错误的损失比也很难量化估计。在这种情况下,一个更加合理的学习目标是:我们希望可以在保证分类器假阳性率(即错误地将负样本分类为正样本的概率) 低于某个阈值 τ 的前提下,最小化其误分正样本的概率。可以看到,由于问题的转换,传统的基于精度(Accuracy),曲线下面积(AUC) 等目标的学习算法将不再适用。
假阳性率约束下的分类学习,在文献中被称为Neyman-Pearson 分类问题。现存的代表性方法主要有代价敏感学习(Cost-sensitive learning),拉格朗日交替优化(LagragianMethod), 排序——阈值法(Ranking-Thresholding)等。然而,这些方法通常面临一些问题,限制了其在实际中的使用:
需要额外的超参数选择过程,难以较好地匹配指定的假阳性率;
排序学习或者交替优化的训练复杂度较高,难以大规模扩展;
通过代理函数或者罚函数来近似约束条件,可能导致其无法被满足。
因此,如何针对现有方法存在的问题,给出新的解决方案,是本文的研究目标。
动机:从约束分类到排序学习
考虑经验版本的Neyman-Pearson分类问题,其寻找最优的打分函数f与阈值b,使得在满足假阳性率约束的前提下,最小化正样本的误分概率:
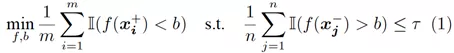
我们尝试消除该问题中的约束。首先,我们阐述一个关键的结论:经验Neyman-Pearson分类与如下的排序学习问题是等价的,即它们有相同的最优解f以及最优目标函数值:
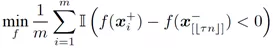
这里, f(x[j]^-)表示取负样本中第j大的元素。直观上讲,该问题本身是一个pairwise ranking问题,其将所有的正样本与负样本中第τn大的元素相比较。从优化AUC的角度,该问题也可看作一个部分AUC优化问题,如图1所示,其尝试最大化假阳性率τ附近的曲线下面积。
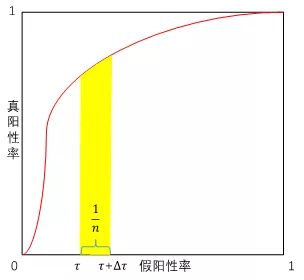
图1: Neyman-Pearson分类等价于一个部分AUC优化问题
然而,由于引入了取序操作符[.],可以证明,即使将0-1损失用连续函数替换,该优化问题本身也是NP-hard的。因此,我们考虑优化该问题的一个凸上界:
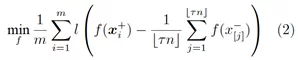
这里l是任意0-1损失的凸代理函数(convex surrogate function)。(2)仍然是一个排序问题,其尝试最大化负样本中得分最高的那部分的“质心”与正样本之间的距离。这个新问题有一些良好的性质:
通过设计高效的学习算法,我们可以在线性时间内求得该问题的全局最优解,这使其非常适合于大规模数据下的场景;
形式上显式地包含τ,无需引入额外的损失超参数(cost-free);
最优解f有可理论保证的泛化误差界。
我们也可以从对抗学习(Adversarial learning)的角度,给出排序问题(2) 的一个直观解释。读者可以验证,(2)与如下的对抗学习问题是等价的:
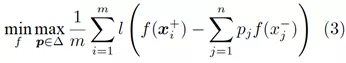
其中k = τn,且
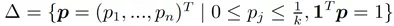
换句话说,排序学习问题(2)可以看作是在两个玩家——打分函数A与样本分布B间进行的一个min-max游戏。对于A给出的每个f,B尝试从负样本分布的集合△中给出一个最坏的分布p,以最小化A的期望收益。该游戏达到纳什均衡(Nash equilibrium)时的稳点,也就是我们要求的最优解。
τ-FPL算法总览
如上所述,τ-FPL的训练分为两个部分,排序(scoring)与阈值(thresholding)。在排序阶段,算法学习一个排序函数,其尝试将正样本排在负样本中得分最高的那部分的“质心”之前。阈值阶段则选取合适的阈值,将学到的排序函数转化为二分类器。
排序学习优化算法
考虑与(2)等价的对抗学习问题(3),其对偶问题如下:
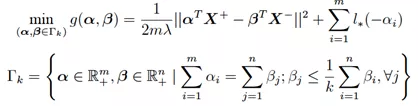
这个新问题不含任何不可导项,并且目标函数g是光滑的(Smooth)。因此,我们可以使用投影梯度下降算法求解该问题,并利用加速梯度方法(Nesterov)获得最优的收敛率。

线性时间的变上界欧式投影
排序学习算法的一个关键步骤,是将梯度下降的解投影到可行集Gamma_k上。我们注意到,这个投影问题是一大类被广泛研究的欧式投影问题的推广。然而传统方法仅对一些特例可以高效求解,即便对于该问题的一个简化版本,也仅能达到O(nlogn +τn^2) 的超线性复杂度。
本文中,我们提出了一个算法,能够在O(n) 的线性时间内高效地求解该投影问题,且其性能不受τ增长所带来的影响。该算法的核心是二分求根法与分治法的有效结合。根据KKT最优条件,我们将投影问题转换为一个求解分段线性方程组的问题,该方程组仅包含三个未知的对偶变量,且可以通过二分求根法获得指定精度的解。进一步地,利用方程组分段线性的特殊结构,以及对偶变量间“同变”的单调性质,我们可以在二分过程中逐步减少每次迭代的计算消耗,最终显著减少总的算法运行时间。实验中,我们观察到随着n与τ的增长,我们的算法较现有的求解该类问题的方法有一至三个数量级的性能提升,见图2。
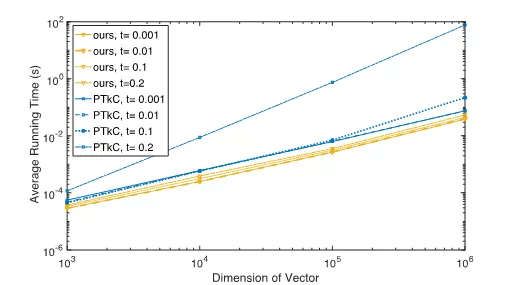
图2:我们的方法与现存算法(PTkC)在求解简化版问题时的性能对比(log-log曲线)
阈值选择
阈值选择阶段,算法每次将训练集分为两份,一份训练排序函数, 另一份用来选取阈值。该过程可以进行多次,以充分利用所有样本,最终的阈值则是多轮阈值的平均。该方法结合了out-of-bootstrap与软阈值技术分别控制偏差及方差的优点,也适于并行。
理论结果
收敛率与时间复杂度
通过结合加速梯度方法与线性时间投影算法,τ-FPL可以确保每次迭代的线性时间消耗以及最优的收敛率。图3将τ-FPL 与一些经典方法进行了对比,可以看到其同时具备最优的训练及验证复杂度。
泛化性能保证
我们也从理论上给出了τ-FPL学得模型的泛化误差界,证明了泛化误差以很高的概率被经验误差所上界约束。这给予了我们设法求解排序问题(2)的理论支持。

图3:不同算法的训练复杂度比较
实验结果

图4报告了不同算法优化部分AUC的效果,'N/A'代表该模型的训练无法在一周内完成。可以看到,τ-FPL对于不同τ值,在大部分实验中都具有较好的表现。另外,其相比二分排序算法有明显的性能优势。
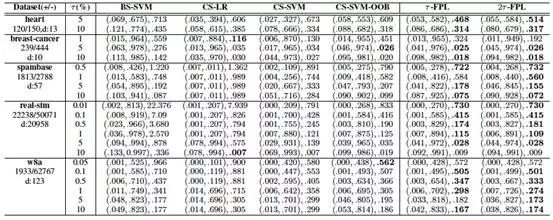
图5比较了不同算法输出的分类器的分类性能。这里选取NP-score 作为评价标准,其综合考虑了分类器间的精度差异与违背假阳性率约束的惩罚。可以看到,采用OOB 阈值的算法在大部分情况下均可有效地抑制假阳性率在允许范围内。另外,即使采用同样的阈值选择方法,τ-FPL 也可以获得较代价敏感学习(CS-SVM-OOB) 更好的精度。
总结
在高风险分类任务中控制假阳性率是重要的。本文中,我们主要研究在指定的假阳性率容忍度τ下学习二分类器。为此,我们提出了一个新的排序学习问题,其显式地最大化将正样本排在前 τ% 负样本的质心之上的概率。通过结合加速梯度方法与线性时间投影,该排序问题可以在线性时间内被高效地解决。我们通过选取合适的阈值将学到的排序函数转换为低假阳性率的分类器,并从理论和实验两个角度验证了所提出方法的有效性。
原文发布时间为:2018-08-15
本文作者: 热爱论文的
本文来自云栖社区合作伙伴“ 阿里巴巴机器智能”,了解相关信息可以关注“ 阿里巴巴机器智能”。
如何降低疾病监测的漏诊比率?一种新的分类学习算法...相关推荐
- 谷歌实现2种新的强化学习算法,“比肩”DQN,泛化性能更佳!|ICLR 2021
丰色 发自 凹非寺 量子位 报道 | 公众号 QbitAI 强化学习(RL)算法持续"进化"中-- 来自Google Research的研究人员,证明可以使用图表示 (graph ...
- 提出了一种新的基于一致性算法的直流微电网均流和均压二级控制方案 关键词:一致性算法;直流微电网;下垂控制;分布式二次控制
关键词:一致性算法;直流微电网;下垂控制;分布式二次控制;电压电流恢复与均分;非线性负载;MATLAB/Simulink;顶刊复现, 主题:提出了一种新的基于一致性算法的直流微电网均流和均压二级控制方 ...
- 介绍一种新的群智能算法---黏菌算法
一种新的群智能算法-黏菌算法 介绍一种新的群智能算法-黏菌算法 近些年群智能算法由于其效率较高,使用方便的优点引起了广大科研者的关注与兴趣.最近看文献,温州大学的李世民(现在去复旦读研究生了)提出了一 ...
- AI领域3种典型的深度学习算法
2019-11-23 10:38:48 深度学习(Deep Learning)是机器学习(Machine Learning)领域中一个新的研究方向,引领了第三次人工智能的浪潮. 本文整理了深度学习领 ...
- Facebook人工智能的一种新的自我监督学习算法:Barlow Twins
首先 近年来,在ImageNet等大规模计算机视觉基准中,自我监督学习已经开始与监督学习竞争.在计算机视觉中,已经引入了很多数据增强的自监督学习方式.目标是学习一个不受输入变化影响的通用表示.对于一个 ...
- 2018-3-23论文一种新的群智能算法--狼群算法(框架结构+感想一点点)
一.文章的总体的结构 中文摘要: 总体的说提出了一种算法,并应用与15个基准函数---得出结论 英文摘要: 0 引言------ 各个群智能算法的列举+解释群智能算法的好处,本质 1 ...
- 一种新的在线学习的方法:能够克服单人多任务学习的困难!
就是和几个好朋友一起看视频 假装直播 pretending to be streaming! teams screening sharing!!!
- 同伦算法matlab程序,一种新的基于Matlab环境的同伦路径跟踪算法
MATLAB 第28卷第5期2007年5月 东北大学学报(自然科学版) V01.28.No.5 JournalofNortheasternUniversity(NaturalScience) May ...
- ISPRS2021/遥感影像云检测:一种地理信息驱动的方法和一种新的大规模遥感云/雪检测数据集
ISPRS2021/云检测:A geographic information-driven method and a new large scale dataset for remote sensin ...
- ehd边缘直方图描述子 matlab,一种新的图像空间特征提取方法
计 算 机 工 程第卷 第3期 38 Computer EngineeringV ol.38 No.3 文章编号:1000-3428(2012)03-0218-03·图形图像处理· 2012年2月 F ...
最新文章
- Lambda 表达式(=):网络摘抄,自学用,侵删。
- 启动进程 问号_有两个这样的进程:僵尸进程amp;孤儿进程,蓝瘦香菇
- 利用MatConvNet进行孪生多分支网络设计
- TCP连接中的异常情况
- js array 的理解
- 前端路由实现原理(history)
- 6-7Pytorch搭建cifar10训练脚本(下)
- 若依单体项目定时任务模块使用教程
- 空间中的语义直线检测_基于语义分割的车道线检测算法研究
- DenseNet稠密连接层
- phpcms v9 index.php,Phpcms V9后台登录地址修改方法
- 《软件工程(第4版?修订版)》—第1章1.10节实时系统的例子
- 计算机信息技术行业代码,行业代码 是什么呢
- UE5导入MetaHuman虚拟头像后,连接live link face,面部表情捕捉出错修正
- 安卓手机root是什么意思
- 夜神模拟器怎么安装使用教程!
- 构造者模式与Lombok的邂逅
- 用大白话聊聊JavaSE
- NAND Flash(spi nand flash和nand flash)和emmc以及ufs通过uboot烧写固件的一些差异
- 20190605学习日记
热门文章
- python天天向上的力量实验报告_Python练习11:天天向上的力量
- 自动驾驶技术-环境感知篇:V2X技术的介绍
- (10)图像增强- -- 图像对比度和亮度调整方法与实现
- 复兴号为什么不能超载?_接下来:什么都没有? 信息超载如何影响我们的大脑。...
- 樊登读书会2016年推荐书目汇总
- 沧桑,何尝不是一种美丽 ----红尘一笑
- PHP用什么标签方便,PHP_用途相似的标签:acronym与abbr,有的时候为了方便传阅或者记 - phpStudy...
- css特殊符号代码以及用过使用方式。
- css 动画 抖动,css3动画之上下抖动
- 20172328 2018-2019《Java软件结构与数据结构》第七周学习总结