优化算法之——最速下降法
引言:在解决无约束问题时,经常用到的一类算法是最速下降法,在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。本节主要介绍一下最速下降法。
1.原理
本篇主要讨论如下的优化模型:
其中是
的实值连续函数,通常假定其具有二阶连续偏导数,对于
可以等价的转化为
,所以下面仅讨论极小化问题。
最速下降法由于只考虑当前下降最快而不是全局下降最快,在求解非线性无约束问题时,最重要的是得到每一步迭代的方向和每一步下降的长度
。考虑到函数
在点
处沿着方向
的方向导数
,其意义是
在点
处沿
的变化率。当
连续可微时,方向导数为负,说明函数值沿着该方向下降;方向导数越小(负值),表明下降的越快,因此确定搜索方向
的一个想法就是以
在点
方向导数最小的方向作为搜索方向。
1.1 搜索方向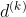 的确定
的确定
设方向为单位向量,
,从点
按方向
,步长
进行搜索得到下一点
,对该式进行泰勒展开得到:
可以得到处的变化率:
容易看出来在下降最快就是要在
出的变化率最大,所以就是要使
最小(
),而对于
,要使其最小就是当
时,
,即可以确定最速下降方向为
,这也是最速下降法名字的由来。
1.2 步长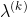 的确定
的确定
最速下降法采用的搜索步长通常采取的策略是精确步长搜索法,即:,通过求该式子的最小值点来求取步长,一般有:
,该式表明
和
是正交的。在这里我没有用该方法,而是用一维搜索方法(黄金分割法<0.618法>)来近似找到最小值点,通过自己编程实现一维搜索更好的理解这个过程,最终的结果与精确搜索几乎一致。
2. 算法过程
求解问题:
最速下降法的具体步骤为:
1. 选定初始点,
,给定精度要求
。
2.计算,若
,则停止,否则令
;
3. 在处沿方向
作线搜索得
,
,返回2.
3.例子
用最速下降法求解无约束非线性问题的最小值点:
其中。
在这里为了直观的理解问题,我们对该问题进行可视化,分别取
步长为0.2。绘制图像如下:
![]()
解:在这里先用精确搜索求出最小值点,其后再用一维搜索进行验证。
(1)
(2)
(3)
(4)运用精确搜索求步长
,可得
,
(5)
同理转回(2)可以一直迭代回去一直到满足条件为止,得到最优解为,
4.优缺点
优点:
(1)每一步迭代简单,对初始点要求少
缺点:
(1)由于是对每一步进行最优迭代,但是整体的收敛下降速度不一定最快。
(2)用最速下降法求最优问题,迭代路径呈直角锯齿形如下图,开始的几步迭代很快,但越接近最优点收敛速度越慢
![]()
用matlab编程来求解,由于我在这里运用平分法确定极小值区间,然后用黄金分割法求的极小值,代码比较仔细,最终结果如下:
![]()
clear;
xk=[0,0]';
t=0.01;
syms x1;
syms x2;
while (1)[dfx1_value,dfx2_value]=steepest_gradient(xk);deltafx=[dfx1_value,dfx2_value]';gredfxabs=sqrt(dfx1_value.^2+dfx2_value.^2);if (gredfxabs<t)x_best=xk%f=x1-x2+2*x1.^2+2*x1*x2+x2.^2;f=x1.^2+2.*x2.^2-2.*x1.*x2-2.*x2;m=matlabFunction(f);y_best=m(xk(1),xk(2))break;else dk=-deltafx;fx=lamdafunction(dk,xk);lamda=goldensfenge(fx);xk=xk-lamda*deltafx;continue;end
endfunction [dfx1_value,dfx2_value]=steepest_gradient(xk)
syms x1;
syms x2;
%fx=x1.^2-2*x1*x2+4*x2.^2+x1-3*x2;
%fx=x1-x2+2*x1.^2+2*x1*x2+x2.^2;
fx=x1.^2+2.*x2.^2-2.*x1.*x2-2.*x2;
dfx_1=diff(fx,x1);
dfx_2=diff(fx,x2);
dfx1=matlabFunction(dfx_1);
dfx2=matlabFunction(dfx_2);
dfx1_value=dfx1(xk(1),xk(2));
dfx2_value=dfx2(xk(1),xk(2));function [a,b]=region(fx,x0)
dx=0.1;
P=fdx(fx,x0);
if (P==0)x_best=x0;
elseif (P>0)while (1)x1=x0-dx;dx=dx+dx;P=fdx(fx,x1);if(P==0)x_best=x1;break;elseif (P<0)a=x1;b=x0;break;else x0=x1;endend
elsewhile (1)x1=x0+dx;dx=dx+dx;P=fdx(fx,x1);if(P==0)x_best=x1;break;elseif(P>0)a=x0;b=x1;break;elsex0=x1;endend
end
function fx=lamdafunction(dk,x_k)
syms lamda;
syms x1;
syms x2;
x1=x_k(1)+lamda*dk(1);
x2=x_k(2)+lamda*dk(2);
%fx=x1.^2-2*x1*x2+4*x2.^2+x1-3*x2;
%fx=x1-x2+2*x1.^2+2*x1*x2+x2.^2;
fx=x1.^2+2.*x2.^2-2.*x1.*x2-2.*x2;function x_best=goldensfenge(fx)
x0=10*rand;
e=0.005;
[a,b]=region(fx,x0);
%x0=a+rand*(b-a);x1=a+0.382*(b-a);x2=a+0.618*(b-a);f1=fvalue(fx,x1);f2=fvalue(fx,x2);
while(1)if (f1>f2)a=x1;x1=x2;f1=f2;x2=a+0.618*(b-a);f2=fvalue(fx,x2);if(abs(b-a)<=e)x_best=(a+b)/2;break;elsecontinue;endelseif(f1<f2)b=x2;x2=x1;f2=f1;x1=a+0.382*(b-a);f1=fvalue(fx,x1);if(abs(b-a)<=e)x_best=(a+b)/2;break;elsecontinue;endelsea=x1;b=x2;if(abs(b-a)<=e)x_best=(a+b)/2;break;elsex1=a+0.382*(b-a);x2=a+0.618*(b-a);f1=fvalue(fx,x1);f2=fvalue(fx,x2);continue;endend
endfunction y_value=fvalue(fx,a)
syms x;
%y=2*x.^2-x-1;
f=matlabFunction(fx);
y_value=f(a);function dy_value=fdx(fx,a)
syms x;
%y=2*x.^2-x-1;
dy=diff(fx);
sign2fun=matlabFunction(dy);
dy_value=sign2fun(a);编辑:高宇航
优化算法之——最速下降法相关推荐
- matlab共轭梯度法_优化算法之牛顿法
牛顿法(Newton's method)是一种在实数域和复数域上近似求解方程的方法,,它使用函数f(x)的泰勒级数的前面几项来寻找方程f(y)=0的根. 牛顿法最初由艾萨克·牛顿在<Method ...
- 机器学习萌新必备的三种优化算法 | 选型指南
作者 | Nasir Hemed 编译 | Rachel 出品 | AI科技大本营(id:rgznai100) [导读]在本文中,作者对常用的三种机器学习优化算法(牛顿法.梯度下降法.最速下降法)进行 ...
- 机器学习中的优化算法!
↑↑↑关注后"星标"Datawhale 每日干货 & 每月组队学习,不错过 Datawhale干货 作者:李祖贤,Datawhale高校群成员,深圳大学 在机器学习中,有很 ...
- 优化算法-共轭梯度法
优化算法-共轭梯度法 (2012-04-20 08:57:05) 转载▼ 标签: 杂谈 最速下降法 1.最速下降方向 函数f(x)在点x处沿方向d的变化率可用方向导数来表示.对于可微函数,方 ...
- MATLAB优化算法(一)
1.线性规划 [x,fval]=linprog(c,A,b,Aeq,Beq,VLB,VUB) 用于解决 min(z)=cX%%求满足条件的X与已定系数c乘积之和的最小值 s.t. AX<=b ...
- 加速收敛_引入Powerball 与动量技术,新SGD优化算法收敛速度与泛化效果双提升 | IJCAI...
本文介绍的是 IJCAI-2020论文<pbSGD: Powered Stochastic Gradient Descent Methods for Accelerated Non-Convex ...
- 机器学习、深度学习中常用的优化算法详解——梯度下降法、牛顿法、共轭梯度法
一.梯度下降法 1.总述: 在机器学习中,基于基本的梯度下降法发展了三种梯度下降方法,分别为随机梯度下降法,批量梯度下降法以及小批量梯度下降法. (1)批量梯度下降法(Batch Gradient D ...
- 机器学习--梯度-牛顿-拟牛顿优化算法和实现
版权声明:作者:Jinliang's Hill(金良山庄),欲联系请评论博客或私信,CSDN博客: http://blog.csdn.net/u012176591 目录(?)[+] 要求解的问题 线搜 ...
- 数值优化:一阶和二阶优化算法(Pytorch实现)
1 最优化概论 (1) 最优化的目标 最优化问题指的是找出实数函数的极大值或极小值,该函数称为目标函数.由于定位\(f(x)\)的极大值与找出\(-f(x)\)的极小值等价,在推导计算方式时仅考虑最小 ...
- 优化算法之梯度下降法、牛顿法、拟牛顿法和拉格朗日乘数法
在机器学习中,优化方法是其中一个非常重要的话题,最常见的情形就是利用目标函数的导数通过多次迭代来求解最优化问题. - 无约束最优化问题:梯度下降法.牛顿法.拟牛顿法: - 有约束最优化问题:拉格朗 ...
最新文章
- mysql 5.7 缺点_MySQL · 特性分析 · MySQL 5.7 外部XA Replication实现及缺陷分析
- 记录memcache分布式策略及算法
- python算法与程序设计基础第二版-算法与程序设计基础(Python版) - 吴萍
- AI顶会,正在使用AI来审阅AI论文
- 用Android Sutdio调试NDK
- 如果你每次面试前都要去背一篇Spring中Bean的生命周期,请看完这篇文章
- Silverlight 自定义表格 转
- 互联网金融又任性撒钱了
- services.xml应该放在项目的哪里_新轮胎应该放在前轮还是后轮?
- 【C++】内存4区---代码区、全局区、栈区、堆区
- 关于键盘事件对象code值
- Pyspark:电影推荐
- 手机处理器排名2019_2019手机处理器性能排行,第一实至名归,第二太冷门
- whisper客服源码_以太坊源码分析—Whisper
- [转载] 胡锡进:5000亿买一包爆米花 我不想让我的国家这样
- DSP CCS12.00 芯片:TMS320F28335 结课设计 频率测量系统设计
- Centos7 安装VLC播放器
- 夏目漱石《我是猫》读后感
- 每个人心中都有一艘小白船
- 《健康地奋斗着——程序员自己的养生书》作者:中医程序猿