T7-Dropout 解决 overfitting 过拟合
Dropout 解决 overfitting
相对于过拟合(overfitting,或称:过度学习)是指,使用过多参数,以致太适应训练数据而非一般情况;另一种常见的现象是使用太少参数,以致于不适应当前的训练数据,这则称为欠拟合(underfitting,或称:拟合不足)现象。[2]
防止过拟合,我们需要用到一些方法,如:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)、Dropout等。[3]
本次数据来自 sklearn, 首先导入模块
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer在之前代码的基础上修改, 增加 keep_prob 占位符保留数据的概率
# k = 1, 保留 100%, 即没有 dropout 任何数据.
keep_prob = tf.placeholder(tf.float32)准备训练数据(train)测试数据(test)
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)在训练过程中,overfitting 的问题与 keep_prob 相关,keep_prob = 1 没有dropout 任何数据, keep_prob = 0.5 则能明显看出 dropout 的效果。
keep_prob = 1

keep_prob = 0.5
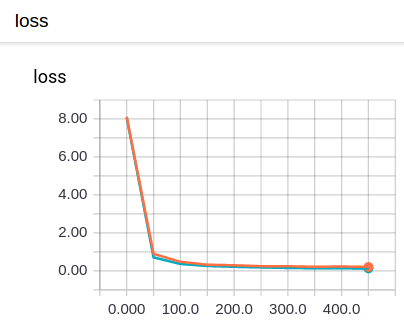
完整代码
# !/usr/bin/python3
# -*- coding: utf-8 -*-from __future__ import print_function
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer# load data
digits = load_digits()
X = digits.data # img data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):# add one more layer and return the output of this layerWeights = tf.Variable(tf.random_normal([in_size, out_size]))biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )Wx_plus_b = tf.matmul(inputs, Weights) + biases# here to dropoutWx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob) # +++if activation_function is None:outputs = Wx_plus_belse:outputs = activation_function(Wx_plus_b, )tf.summary.histogram(layer_name + '/outputs', outputs)return outputs# define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32) # +++
xs = tf.placeholder(tf.float32, [None, 64]) # 8x8
ys = tf.placeholder(tf.float32, [None, 10])# add output layer
l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax)# the loss between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),reduction_indices=[1])) # loss
tf.summary.scalar('loss', cross_entropy) # +++
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)sess = tf.Session()
merged = tf.summary.merge_all()
# summary writer goes in here
train_writer = tf.summary.FileWriter("logs/train", sess.graph) # +++
test_writer = tf.summary.FileWriter("logs/test", sess.graph)# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:init = tf.initialize_all_variables()
else:init = tf.global_variables_initializer()
sess.run(init)for i in range(500):# here to determine the keeping probabilitysess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) # +++if i % 50 == 0:# record losstrain_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})train_writer.add_summary(train_result, i)test_writer.add_summary(test_result, i) # +++
Reference
[1] 莫烦Python: Dropout 解决 overfitting
[2] 拾毅者: 机器学习—过拟合overfitting
[3] 一只鸟的天空: 机器学习中防止过拟合的处理方法
转载于:https://www.cnblogs.com/TaylorBoy/p/6814664.html
T7-Dropout 解决 overfitting 过拟合相关推荐
- TF之CNN:利用sklearn(自带手写数字图片识别数据集)使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线
TF之CNN:利用sklearn(自带手写数字图片识别数据集)使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线 目录 输出结果 设计代码 输出结果 设计代码 ...
- 解决神经网络过拟合问题—Dropout方法、python实现
解决神经网络过拟合问题-Dropout方法 一.what is Dropout?如何实现? 二.使用和不使用Dropout的训练结果对比 一.what is Dropout?如何实现? 如果网络模型复 ...
- Dropout解决过拟合问题
Dropout解决过拟合问题 晓雷 6 个月前 这篇也属于 <神经网络与深度学习总结系列>,最近看论文对Dropout这个知识点有点疑惑,就先总结以下.(没有一些基础可能看不懂,以后还会继 ...
- 解决overfitting的方法
解决overfitting的方法 Dropout, regularization, batch normalizatin. 但是要注意dropout只在训练的时候用,让一部分神经元随机失活. Batc ...
- keras添加正则化全连接_第16章 Keras使用Dropout正则化防止过拟合
Dropout虽然简单,但可以有效防止过拟合.本章关于如何在Keras中使用Dropout.本章包括: dropout的原理 dropout的使用 在隐层上使用dropout 我们开始吧. 16.1 ...
- 使用权值衰减算法解决神经网络过拟合问题、python实现
使用权值衰减算法解决神经网络过拟合问题.python实现 一.what is 过拟合 二.过拟合原因 三.权值衰减 四.实验验证 4.1制造过拟合现象 4.2使用权值衰减抑制过拟合 一.what is ...
- Tensorflow——Dropout(解决过拟合问题)
1.前言 Overfitting 也被称为过度学习,过度拟合.我们总是希望在机器学习训练时,机器学习模型能在新样本上很好的表现.过拟合时,通常是因为模型过于复杂,学习器把训练样本学得"太好了 ...
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
从本专栏开始,作者正式开始研究Python深度学习.神经网络及人工智能相关知识.前一篇文章通过TensorFlow实现分类学习,以MNIST数字图片为例进行讲解:本文将介绍什么是过拟合,并采用drop ...
- 深度学习Deep Learning: dropout策略防止过拟合
本文参考 hogo在youtube上的视频 :https://www.youtube.com/watch?v=UcKPdAM8cnI 一.理论基础 dropout的提出是为了防止在训练过程中的过拟合现 ...
最新文章
- 六、springboot整合swagger
- DotNetCore跨平台~EFCore数据上下文的创建方式
- monocross 环境搭建:MonoTouch Mono for Android
- aosp 为什么某些目录没有编译_编译Android AOSP代码
- uva 1617——Laptop
- 【bzoj1911-[Apio2010]特别行动队】斜率优化
- Bootstrap表格样式
- openGauss的开源数据库之路
- linux android开发环境搭建
- 判断IE版本的HTML语句详解,如:!--[if IE 9] 仅IE9可识别 ![endif]--
- BP神经网络整定PID
- eclipse中修改xml文件的默认编辑器
- java强制删文件夹_Java 删除文件夹 和 文件 集合
- 读书笔记:自动控制原理
- 阿里云服务器怎么配置安全组?
- linux的XDG(X Desktop Group)基本目录规范
- ibm tivoli_IBM Tivoli Directory Server中的安全复制
- 回头看一看我的2018年
- 5v2.1a给5v2a充电行吗
- 高德API 经纬度转换地市区县(含读取文件)
热门文章
- html5 支持音频格式,html5中audio支持音频格式
- (HDU)1019 --Least Common Multiple(最小公倍数)
- java中的动态绑定与静态绑定
- WPF中打印问题的探讨[转]
- javascript 栈 Stack
- 穷人最缺少的是什么?
- Vista SP1、IIS7,安装ASP.Net 1.1、VS2003、NetAdvantage 2004vol、Sql Server2000全攻略
- 湖南大学计算机与通信学院研究生,湖南大学计算机与通信学院2010年硕士研究生招生学科...
- 是先设计mysql表再进行php代码_PHP与RBAC设计思路,数据表设计与源码讲解
- 创建线程都有哪些方式?— Callable篇