机器学习爬大树之决策树(CART与剪枝)
分类与回归树(classification and regression tree,CART)是应用广泛的决策树学习方法,同样由特征选择,树的生成以及剪枝组成,既可以用于分类也可以用于回归。CART假设假设决策树是二叉树,内部结点特征的取值为“是”或‘否’,左分支是取值为‘是’的分支,右分支是取值为“否”的分支,例如有个特征为‘年龄’,它的特征值为{‘年龄’:[‘小孩’,‘成年’,‘老人’]};那么左分支为去{‘年龄’ = ‘小孩’}的情况下为{{‘小孩’},{‘成年’,‘老人’}};这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布!
CART算法有以下两步组成:
i)决策树的生成:基于训练数据集生成决策树,生成的决策树要尽量大:而在递归地构建二叉决策树时,对生成回归树用平方误差最小化准则,对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。
ii)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
一、CART之回归树
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分的单元上的输出值;当输入空间的划分确定时,可以用平方误差在表示回归树对于训练数据 的预测误差,用平方误差最小的准则求解每个单元上的最优输出值。
问题是怎样对输入空间进行划分呢?、这里采用启发式的方法,这里我们假设有个特征,每个特征都有
取值,那么我们遍历所有的特征,尝试该特征下的所有取值,直到我们取得了最小的特征
的特征值
,使得损失函数最小,这样就得到一个划分点,即:
接着,对每个区域重复上述划分过程, 假设 将输入空间划分为M个单元,则每个划分空间的输出值为
直到满足停止条件为止,这样就生成一颗回归树。这样的回归树通常称为最小二乘回归树(least squares regression tree)
具体算法步骤参考李航(统计学习方法):
![]()
为了便于理解,我们以一个简单的例子来生成一个回归树(最小二乘回归树):
|
|
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|
|
4.50 | 4.75 | 4.91 | 5.34 | 5.80 | 7.05 | 7.90 | 8.23 | 8.70 | 9.00 |
首先我们的划分点集合为:
|
|
1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
来寻找最优划分点(因为我们的例子只有一个特征,所以无需考虑
)
当s=1.5时,,
,由划分后的输入空间的输出值公式:
得
同理得到如下表:
|
|
1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|
|
4.50 | 4.62 | 4.72 | 4.87 | 5.06 | 5.39 | 5.75 | 6.06 | 6.35 |
|
|
6.85 | 7.11 | 7.43 | 7.78 | 8.17 | 8.45 | 8.64 | 8.85 | 9.0 |
将,
,
带入公式
得
|
|
1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|
|
22.64 | 17.70 | 12.19 | 7.38 | 3.36 | 5.07 | 10.05 | 15.18 | 21.33 |
由上表可以很清楚的知道当s=5.5时,损失函数最小,故将训练集划分为:
,
;
,
;
那么此时的回归树可以表示为:
然后分别对,
重复上面的步骤:
当划分时 ,有
,有
|
|
1 | 2 | 3 | 4 | 5 |
|
|
4.50 | 4.75 | 4.91 | 5.34 | 5.80 |
此时的划分点为:
|
|
1.5 | 2.5 | 3.5 | 4.5 |
同理计算每个划分下的,然后找到最小的划分点作为最后的划分点,如下表:
|
|
1.5 | 2.5 | 3.5 | 4.5 |
|
|
4.50 | 4.63 | 4.72 | 4.88 |
|
|
5.20 | 5.35 | 5.57 | 5.80 |
将,
,
带入公式
,得到下表:
|
|
1.5 | 2.5 | 3.5 | 4.5 |
|
|
0.67 | 0.43 | 0.191 | 0.37 |
因此最小划分点为时,故将
,分为
, 其输出值
;
,其 输出值
.
当划分时 ,有
,有
|
|
6 | 7 | 8 | 9 | 10 |
|
|
7.05 | 7.90 | 8.23 | 8.70 | 9.00 |
此时的划分点为:
|
|
6.5 | 7.5 | 8.5 | 9.5 |
同理计算每个划分下的,然后找到最小的划分点作为最后的划分点,如下表:
|
|
6.5 | 7.5 | 8.5 | 9.5 |
|
|
7.05 | 7.48 | 7.73 | 7.97 |
|
|
8.46 | 8.64 | 8.85 | 9.0 |
将,
,
带入公式
,得到下表:
|
|
6.5 | 7.5 | 8.5 | 9.5 |
|
|
0.72 | 0.66 | 0.79 | 1.45 |
因此最小划分点为时,故将
,分为
, 其输出值
;
,其 输出值
.
我们的终止条件是最小损失函数小于某个阈值,或者是规定树的深度,亦或者是样本个数小于预定阈值
所以假设我们规定树的深度为3,那么以上划分将终止,最后的回归树为:
在GBDT中无论是回归还是分类问题,都是使用CART回归树,那么如何用CART的回归树解决CBDT的分类,我将在后续的博客中论述。
二、CART之分类树
CART决策树使用“基尼指数”(Gini index)来选择划分特征,其定义如下:
给定一个样本集合,假设有
个类,第
类的样本集合为
,其概率为
,则样本集合
的基尼指数定义为:
直观来说,反映了从数据集
中随机抽取两个样本,其类别标记不一致的概率。因此,
越小,则数据集
的纯度越高。
如果样本集合根据特征
是否取某一可能属性值
被分割成
和
两部分,即:
,
则在特征的条件下,集合
的基尼指数定义为:
基尼指数表示
的不确定性,基尼指数
表示经
分割后集合
的不确定性。基尼指数值越大,样本集合的不确定性也就越大,这一点与熵相似。
算法停止计算的条件一般为:
(1)结点中的样本个数小于预定的阈值;
(2)样本集的基尼指数小于预定阈值(样本基本属于同一类)
(3)没有更多特征
由于这边的知识点较为简单,并且例子很多,比如李航的书就有,所以就不再举例说明了!
三、决策树的剪枝
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好了”,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
当前存在许多种不同的剪枝方法,分为预剪枝(preprunning)和后剪枝(postpruning),后者应用较为广泛,后剪枝又可以分为两类,一类是把训练数据集分为树生成集与树剪枝集,一类是在树的生长与剪枝过程中都使用同一训练数据集,预剪枝的缺点是使树的生长可能过早停止,因此应用较少,因此我们主要讲讲后剪枝的知识点。
1、ID3与C4.5的剪枝
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)或代价函数(cost function)来实现。设树的叶节点的个数为
,
是树
的叶节点,该叶节点有
个样本点,其中
类的样本点有
个,
,
为叶结点
上的经验熵,
为参数,则决策树学习的损失函数为:
其中经验熵为:
既然损失函数这么定义(虽然我也不知道是怎么来的),我们就好好分析一下这个函数,我们不难发现,决定损失函数的只与叶结点有关,而跟内部节点一点关系都没有,在损失函数中,若有如下定义:
这时有:
表示模型对训练数据的预测误差,即模型与训练数据的拟合程度;
表示模型复杂度;
我的理解是相当于领回归中的正则化参数,首先我们想要最小化的损失函数,那么当
很小的时候,对
的惩罚也就很小,因此
就会很大,这样得到的决策树因为叶结点多所以较为复杂,当
时,整棵树就是最好的;同理当
很大的时候,对
的惩罚也就很大,因此
就会很小,这样得到的决策树因为叶结点少所以较为简单。
剪枝就是当确定时,选择损失函数最小的模型;因此我们可以这么理解,
表示剪枝前的树,
表示剪枝后的树,看下表:
| 剪枝前损失函数 |
|
| 剪枝后损失函数 |
|
如果剪枝前的损失函数大于剪枝后的损失函数(我们想要损失函数越小越好)即,那么一定要剪枝的啊,好处多多,比如说剪枝后损失函数小;剪枝后因为少了
个叶子结点所以树的模型也变得简单,因此算法如下:
![]()
其实这种剪枝方法类似于REP(reduced error pruning)方法,它需要一个分离数据集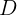 用于剪枝,对于决策树
用于剪枝,对于决策树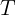 的每颗非叶子树
的每颗非叶子树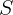 ,用叶结点代替这颗子树。如果被叶结点替代后形成的新树关于的误差等于或者小于关于所产生的误差,则用叶子结点替代!
,用叶结点代替这颗子树。如果被叶结点替代后形成的新树关于的误差等于或者小于关于所产生的误差,则用叶子结点替代!
我们以下图为例说明REP的剪枝过程,图(a)为剪枝数据集,图(b)和图(c)显示的是基于REP的方法:
![]()
我们看图(b)中根结点,
表示这个结点分类为
时的误差为3,即括号里的数是分类误差;在遍历树过程中,采用自底向上的方式,该方式可以保证剪枝后的结果是关于剪枝数据集的具有最小误差的最小剪枝树。
我们以图(b)为例,结点有两个叶子结点(
),那么
结点到底需不需要剪枝呢 ?我们看下剪枝前与剪枝后的误差的大小关系来决定:
剪枝前:的误差之和为1
剪枝后:(
作为叶子结点被剪掉)
作为叶子结点误差为0
所以我们决定剪枝(之前2个叶子结点,现在变成了一个,使模型边的简单)得到图(c),余下的过程类似。
2.CART剪枝
CART剪枝算法从“完全生长”的决策树的底端剪去一些子树,使决策树变小(模型变简单),从而能够对未知数据有更准确的预测常用CCP(cost-complexity pruning)。
CART剪枝算法由两步组成:
(1):从生成算法产生的决策树底端开始不断剪枝,直到
的根结点,形成一个子树序列
;
(2):然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。
在步骤(1)中,生成子树序列的基本思想是从
开始,裁剪
中关于训练数据集误差增加最小的分枝来得到
,实际上,当一棵树
在结点
处剪枝时,它的误差增加直观上认为是
,其中,
为在结点
的子树被裁剪后的结点
的误差(其实就是内部结点t经过裁剪后变成叶子结点t),
为在结点
的子树没被裁剪时的子树
误差;然而,剪枝后,
的叶子数减少了
,其中,
为子树
的叶结点数,也就是说,
的复杂性减少了因此,考虑树的复杂性因素,树分支被裁剪后误差增加率由下式决定:
其中 ,
是结点
的误差率;
是结点
的样本个数与训练集样本个数的比值!
等于子树
所有叶子结点的误差之和!
那么问题是上式是怎么来的?
首先我们看下在剪枝过程中,计算子树的损失函数:
与上面的一样是不是,我们知道为参数为
时的子树
的整体损失,对于固定的
,一定存在使损失函数
最小的子树,将其表示为
。
在损失函数
最小的意义下是最优的。并且Breiman已经证明这样的最优子树是唯一的。
具体的,从整体树开始剪枝。对
的任意内部结点
,,若将
进行剪枝,即以
为单结点的损失函数为:
(对剪枝后,由于叶结点变成它自己,所以
)
以为根节点的子树
的损失函数为:
(没有对剪枝,所以它还有叶结点
)
|
对 |
|
|
|
对 |
|
|
当或
充分小时,有不等式
(前面讲过叶结点很是多的,所以复杂度高,分的细,精度高,所以损失函数小;那么剪枝后,由于剪去了
个叶结点,所以精度变得低了一些,自然损失函数就大了一些,所以有了这个不等式)
当增大时,在某一
有
(因为无论怎么变化,剪枝后的树就是客观存在的,所以
都是不变的,那么当
变大之后,剪枝前叶子结点就越少,所以分的没以前细,精度就变得低了一些,直到剪枝前的误差等于剪枝后的误差)
当再增大时,不等式反向,所以只要
解得:
与
有相同的损失函数值,而
的结点少了
(剪枝前与剪枝后的损失函数一样,并且剪枝后的叶节点也少了,当然要剪枝啦),对
进行剪枝!
就是
中具有最小
值对应的剪枝树。
接下来我们就一个例子来简单的描述一个剪枝的过程:
![]()
如图所示为一个有80个样本的决策树,分类分别为,
,其中对于结点
(
类样本有46个,
类样本有4个),根据多数分类原则结点
应该分为
类,所以:
结点的叶结点(
)被裁剪之后的误差为
,
结点被裁剪之前的误差为
,
带入,
得,其他过程类似得到:
![]()
从上表可以看出,原始树中最小的
为 结点
,将其剪掉之后为树
,它的最小
为结点
或
,从图中可以看出剪掉结点
能使树的模型更加简单,裁剪后得到
!
最后利用独立的验证集,测试子树序列中各颗子树的平方误差或基尼指数。平方误差或基尼指数最小的决策树被认为是最优的决策树!具体算法参考李航的统计学习方法!
参考:
周志华 西瓜树
李航 统计学习方法
魏红宁. 决策树剪枝方法的比较[J]. 西南交通大学学报, 2005, 40(1):44-48
https://blog.csdn.net/u014688145/article/details/53326910
https://blog.csdn.net/zhihua_oba/article/details/72230427
机器学习爬大树之决策树(CART与剪枝)相关推荐
- 机器学习爬大树之决策树(ID3,C4.5)
自己自学机器学习的相关知识,过了一遍西瓜书后准备再刷一遍,后来在看别人打比赛的代码时多次用到XGBoost,lightGBM,遂痛下决心认真学习机器学习关于树的知识,自己学习的初步流程图为: 决策树( ...
- 机器学习爬大树之(GBDT原理)--回归篇
集成学习(ensemble learning)想必应该是最为火爆的机器学习算法了,它通过构建并结合多个学习器来完成学习任务:类似于我们长说的"采百家之长",目前的集成学习方法大致 ...
- 机器学习爬大树之(GBDT原理)--二分类篇
上一篇文章讲了GBDT的回归篇,其实这一篇文章的原理的思想基本与回归相同,不同之处在于分类任务需用的损失函数一般为logloss.指数损失函数. 回顾下logistic regression有助于我们 ...
- 机器学习算法 04 —— 决策树(ID3、C4.5、CART,剪枝,特征提取,回归决策树)
文章目录 系列文章 决策树 1 决策树算法简介 2 决策树分类的原理 2.1 信息熵 2.2 决策树划分依据-信息增益(ID3) 2.3 决策树划分依据-信息增益率(C4.5) 2.4 决策树划分依据 ...
- 【机器学习基础】数学推导+纯Python实现机器学习算法5:决策树之CART算法
目录 CART概述 回归树 分类树 剪枝 Python实现示例:分类树 在数学推导+纯Python实现机器学习算法4:决策树之ID3算法中笔者已经对决策树的基本原理进行了大概的论述.本节将在上一讲的基 ...
- cart算法_机器学习十大算法之一——决策树CART算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第23篇文章,我们今天分享的内容是十大数据挖掘算法之一的CART算法. CART算法全称是Classification ...
- 机器学习十大算法之-CART分类决策树、回归树和模型树
转载(http://blog.163.com/zhoulili1987619@126/blog/static/35308201201542731455261/) Classification And ...
- 决策树ID3、决策树C4.5、决策树CART、CART树的生成、树的剪枝、从ID3到CART、从决策树生成规则、决策树优缺点
决策树ID3.决策树C4.5.决策树CART.CART树的生成.树的剪枝.从ID3到CART.从决策树生成规则.决策树优缺点 目录
- 【机器学习】 ID3,C4.5,CART决策树
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是&q ...
最新文章
- 装配式建筑连入自动驾驶技术,未来城市的房子居然是这个样子......
- Access-Control-Allow-Origin跨域问题的报错以及解决
- 30个类仿真手写spring框架V2.0版本
- COM学习(四)——COM中的数据类型
- sql server系统表详细说明(2)
- 安全控件开发原理分析 支付宝安全控件开发 网银密码控件 C++
- kitserver 6.33 完全简体中文版补丁
- Word参考文献交叉引用——连续多项引用
- iphone换android手机铃声,为什么大多数苹果手机用户只使用默认铃声,从不更换?原因很现实...
- bmp图片批量转为jpg格式文件?
- uni-app 页面中的背景图片高度和宽度自适应
- Maven基础-认识Maven
- 大数据学长面试之boss直聘面试题
- PHP图片压缩到指定的大小
- myeclipse 6 注册码生成
- 计算机组成原理 课程设计存档
- Solr Replication
- 相对论通俗演义(1-10) 第十章
- 我们对汽车黑客,CIA和维基解密声称的了解
- LTE射频拉远单元数字中频方案(六)
热门文章
- 容器编排技术 -- Kubernetes kubectl replace 命令详解
- 跨平台SSH客户端/Linux VNC客户端/Windows RDP客户端/FTP客户端 推荐 Royal TSX
- 基于Spring安全角色的访问授权示例
- ZooKeeper:协调分布式系统入门指南
- java反射随意值_Java反射总结
- 使用Swagger服务搭建.Net Core API
- linux系统wget、curl终端命令行获取公网ip地址及其他网络信息
- C 语言实例 - 斐波那契数列
- C#LeetCode刷题之#112-路径总和(Path Sum)
- JavaScript中有关数据结构和算法的最佳书籍