sql cte递归_准备好,开始吧– SQL Server如何处理递归CTE
sql cte递归
First of all, a quick recap on what a recursive query is.
首先,快速回顾一下递归查询是什么。
Recursive queries are useful when building hierarchies, traverse datasets and generate arbitrary rowsets etc. The recursive part (simply) means joining a rowset with itself an arbitrary number of times.
递归查询在构建层次结构,遍历数据集并生成任意行集等时很有用。递归部分(简单地)意味着将行集与自身连接任意次。
A recursive query is defined by an anchor set (the base rowset of the recursion) and a recursive part (the operation that should be done over the previous rowset).
递归查询由锚集(递归的基本行集)和递归部分(应在前一个行集上执行的操作)定义。
This blogpost will cover some of the basics in recursive CTE’s and explain the approach done by the SQL Server engine.
该博文将介绍递归CTE的一些基础知识,并说明SQL Server引擎完成的方法。
基础 (The basics)
A recursive query helps in a lot of scenarios. For instance, where a dataset is built as a parent-child relationship and the requirement is to “unfold” this dataset and show the hierarchy in a ragged format.
递归查询在很多情况下都有帮助。 例如,在将数据集构建为父子关系的情况下,要求“展开”该数据集并以不整齐的格式显示层次结构。
A recursive CTE has a defined syntax and can be written in general terms like this …but don’t run way because of the general syntax. A lot of examples (in real code) will come:
递归CTE具有已定义的语法,可以用这样的通用术语来编写……但是由于通用语法而无法运行。 许多示例(以实际代码)将出现:
select result_from_previous.*
from result_from_previous
union all
select result_from_current.*
from set_operation(result_from_previous, mytable) as result_from_currentOr rewritten in another way:
或以另一种方式重写:
select result_from_previous.*
from result_from_previous
union all
select result_from_current.*
from result_from_previous.*
join mytable
on condition(result_from_previous)Another way to write the query (using cross apply):
编写查询的另一种方式(使用交叉应用):
select result_from_current.*
from result_from_previous
cross apply (
select result_from_previous.*
union all
select *
from mytable
where condition(result_from_previous.*)
) as result_from_currentThe last one, with the cross apply, is row based and a lot slower than the other two. It iterates over every row from the previous result and computes the scalar condition (which returns true or false). The same row then gets compared to each row in mytable and the current row of result_from_previous. When these conditions are real – the query can be rewritten as a join. Why you should not use the cross apply for recursive queries.
最后一个带有交叉标记,基于行,并且比其他两个慢很多。 它从先前的结果遍历每一行,并计算标量条件(返回true或false)。 然后将同一行与mytable中的每一行以及result_from_previous的当前行进行比较。 当这些条件成立时,可以将查询重写为联接。 为什么不应该使用叉号来申请递归查询。
The reverse – from join to cross apply – is not always true. To know this, we need to look at the algebra of distributivity.
从联接到交叉应用的相反情况并不总是正确的。 要知道这一点,我们需要看一下分布代数。
分布代数 (Distributivity algebra)
Most of us have already learned that below mathematics is true:
我们大多数人已经了解到以下数学是正确的:
X x (Y + Z) = (X x Y) + (X x Z)
X x(Y + Z)=(X x Y)+(X x Z)
But below is not always true:
但是以下情况并非总是如此:
X ^ (Y x Z) = (X ^ Z) x (X ^ Y)
X ^(Y x Z)=(X ^ Z)x(X ^ Y)
Or said with words, distributivity means that the order of operations is not important. The multiplication can be done after the addition and the addition can be done after the multiplication. The result will be the same no matter what.
或用言语来说,分布意味着操作顺序并不重要。 乘法可以在加法之后完成,加法可以在乘法之后完成。 无论如何,结果都是一样的。
This arithmetic can be used to generate the relational algebra. It’s pretty straight forward:
该算法可用于生成关系代数。 这很简单:
set_operation(A union all B, C) = set_operation(A, C) union all set_operation(B, C)
set_operation(A合并所有B,C)= set_operation(A,C)合并所有set_operation(B,C)
The condition above is true as with the first condition in the arithmetic.
上面的条件与算术中的第一个条件一样成立。
So the union all over the operations is the same as the operations over the union all. This also implies that you cannot use operators like top, distinct, outer join (more exceptions here). The distribution is not the same between top over union all and union all over top. Microsoft has done a lot of good thinking in the recursive approach to reach one ultimate goal – forbid operators that do not distribute over union all.
因此,整个操作的联合与整个联合的操作相同。 这也意味着您不能使用诸如top,distinct,external join之类的运算符( 此处有更多例外 )。 最高工会超过所有工会和最高工会之间的分配是不同的。 微软在递归方法中做出了很多很好的思考,以实现一个最终目标–禁止没有在所有工会上进行分配的运营商。
With this information and knowledge our baseline for building a recursive CTE is now in place.
有了这些信息和知识,我们就可以建立递归CTE的基准。
第一个递归查询 (The first recursive query)
Based on the intro and the above algebra we can now begin to build our first recursive CTE.
基于介绍和上述代数,我们现在可以开始构建第一个递归CTE。
Consider a sample rowset (sampletree):
考虑一个样本行集(sampletree):
|
id |
parentId |
name |
|
1 |
NULL |
Ditlev |
|
2 |
NULL |
Claus |
|
3 |
1 |
Jane |
|
4 |
2 |
John |
|
5 |
3 |
Brian |
|
ID |
parentId |
名称 |
|
1个 |
空值 |
迪特列夫 |
|
2 |
空值 |
克劳斯 |
|
3 |
1个 |
简 |
|
4 |
2 |
约翰 |
|
5 |
3 |
布赖恩 |
From above we can see that Brian refers to Jane who refers to Ditlev. And John refers to Claus. This is fairly easy to read from this rowset – but what if the hierarchy is more complex and unreadable?
从上面我们可以看到,布莱恩(Brian)指简(Jane),后者指Ditlev。 约翰指的是克劳斯。 从该行集中可以很容易地读取它-但是如果层次结构更复杂且不可读怎么办?
A sample requirement could be to “unfold” the hierarchy in a ragged hierarchy so it is directly readable.
一个示例需求可能是在一个粗糙的层次结构中“展开”该层次结构,以便可以直接阅读。
The anchor
锚点
We start with the anchor set (Ditlev and Claus). In this dataset the anchor is defined by parentId is null.
我们从锚点集(Ditlev和Claus)开始。 在此数据集中,由parentId定义的锚为null。
This gives us an anchor-query like below:
这为我们提供了一个锚查询,如下所示:
Now on to the next part.
现在继续下一部分。
The recursive
递归
After the anchor part, we are ready to build the recursive part of the query.
在锚定部分之后,我们准备构建查询的递归部分。
The recursive part is actually the same query with small differences. The main select is the same as the anchor part. We need to make a self join in the select statement for the recursive part.
递归部分实际上是相同的查询,但差异很小。 主要选择与锚定部分相同。 我们需要在递归部分的select语句中进行自我联接。
Before we dive more into the total statement – I’ll show the statement below. Then I’ll run through the details.
在深入探讨总声明之前,我将在下面显示该声明。 然后,我将详细介绍。
Back to the self-reference. Notice the two red underlines in the code. The top one indicates the CTE’s name and the second line indicates the self-reference. This is joined directly in the recursive part in order to do the arithmetic logic in the statement. The join is done between the recursive results parentId and the id in the anchor result. This gives us the possibility to get the name column from the anchor statement.
回到自我参考。 请注意代码中的两个红色下划线。 最上面的一个表示CTE的名称,第二行表示自引用。 为了执行语句中的算术逻辑,将其直接连接到递归部分中。 连接是在递归结果parentId和锚结果中的id之间完成的。 这使我们有可能从anchor语句中获取名称列。
Notice that I’ve also put in another blank field in the anchor statement and added the parentName field in the recursive statement. This gives us the “human readable” output where I can find the hierarchy directly by reading from left to right.
注意,我还在锚语句中添加了另一个空白字段,并在递归语句中添加了parentName字段。 这为我们提供了“人类可读”的输出,在这里我可以通过从左到右阅读直接找到层次结构。
To get data from the above CTE I just have to make a select statement from this:
要从上述CTE获取数据,我只需要从中做出选择语句:
And the results:
结果:
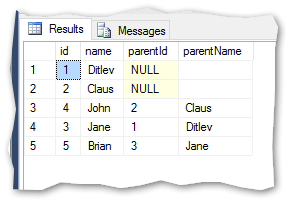
I can now directly read that Jane refers to Ditlev and Brian refers to Jane.
我现在可以直接读到Jane指Ditlev,而Brian指Jane。
But how is this done when the SQL engine executes the query – the next part tries to explain that.
但是,当SQL引擎执行查询时,该如何完成–下一部分将对此进行说明。
SQL引擎处理 (The SQL engines handling)
Given the full CTE statement above I’ll try to explain what the SQL engine does to handle this.
给定以上完整的CTE语句,我将尝试解释SQL引擎如何处理此问题。
The documented semantics is as follows:
所记录的语义如下:
Split the CTE into anchor and recursive parts
将CTE分为锚点和递归部分
Run the anchor member creating the first base result set (T0)
运行锚成员以创建第一个基本结果集(T 0 )
Run the recursive member with Ti as an input and Ti+1 as an output
以T i作为输入并以T i + 1作为输出运行递归成员
Repeat step 3 until an empty result set is returned
重复步骤3,直到返回空结果集
Return the result set. This is a union all set of T0 to Tn
返回结果集。 这是T 0至T n的所有并集
So let me try to rewrite the above query to match this sequence.
因此,让我尝试重写上面的查询以匹配此顺序。
The anchor statement we already know:
我们已经知道的锚语句:
First recursive query:
第一个递归查询:
Second recursive query:
第二个递归查询:
The n recursive query:
n递归查询:
The union all statement:
工会所有声明:
This gives us the exactly same result as we saw before with the rewrite:
这给了我们与重写之前完全相同的结果:
Notice that the statement that I’ve put in above named Tn is actually empty. This to give the example of the empty statement that makes the SQL engine stop its execution in the recursive CTE.
注意,我在上面命名为Tn的语句实际上是空的。 这给出了空语句的示例,该语句使SQL引擎在递归CTE中停止其执行。
This is how I would describe the SQL engines handling of a recursive CTE.
这就是我描述递归CTESQL引擎处理方式。
Based on this very simple example, I guess you already can think of ways to use this in your projects and daily tasks.
基于这个非常简单的示例,我想您已经可以想到在项目和日常任务中使用此方法的方式。
But what about the performance and execution plan?
但是性能和执行计划呢?
Performance
性能
The execution plan for the original recursive CTE looks like this:
原始递归CTE的执行计划如下所示:
The top part of this execution plan is the anchor statement and the bottom part is the recursive statement.
该执行计划的顶部是anchor语句,底部是递归语句。
Notice that I haven’t made any indexes in the table, so we are reading on heaps here.
注意,我没有在表中建立任何索引,因此我们在这里阅读堆。
But what if the data is more complex in structure and depth. Let’s try to base the answer on an example:
但是,如果数据的结构和深度更加复杂,该怎么办? 让我们尝试以示例为基础得出答案:
From the attached sql code you’ll find a script to generate +20.000 rows in a new table called complextree. This data is from a live solution and contains medical procedure names in a hierarchy. The data is used to show the relationships in medical procedures done by the Danish hospital system. It is both deep and complex in structure. (Sorry for the Danish letters in the data…).
从附带的sql代码中,您将找到一个脚本,用于在名为complextree的新表中生成+20.000行。 此数据来自实时解决方案,并按层次结构包含医疗程序名称。 数据用于显示丹麦医院系统在医疗程序中的关系。 它的结构既深又复杂。 (很抱歉数据中的丹麦字母…)。
When we run a recursive CTE on this data – we get the exactly same execution plan:
当我们对这些数据运行递归CTE时,我们将获得完全相同的执行计划:
This is also what I would expect as the amount of data when read from heaps very seldom impact on the generated execution plan.
这也是我所期望的,因为从堆读取数据的数量很少会对生成的执行计划产生影响。
The query runs on my PC for 25 seconds.
该查询在我的PC上运行25秒钟。
Now let me put an index in the table and let’s see the performance and execution plan.
现在,让我在表中添加一个索引,然后看看性能和执行计划。
The index is only put on the parentDwId as, according to our knowledge from this article is the recursive parts join column.
根据本文的知识,该索引仅放在parentDwId上,这是递归部件连接列。
The query now runs 1 second to completion and generates this execution plan:
查询现在运行1秒钟,直到完成并生成以下执行计划:
The top line is still the anchor and the bottom part is the recursive part. Notice now the SQL engine uses the non-clustered index to perform the execution and the performance gain is noticeable.
最上面的行仍然是锚点,最下面的部分是递归部分。 现在注意,SQL引擎使用非聚集索引执行执行,并且性能明显提高。
结论 (Conclusion)
I hope that you’ve now become more familiar with the recursive CTE statement and are willing to try it on your own projects and tasks.
我希望您现在对递归CTE语句更加熟悉,并愿意在您自己的项目和任务上尝试它。
The basics is somewhat straight forward – but beware that the query can become complex and hard to debug as the demand for data and output becomes stronger. But don’t be scared. As I always say – “Don’t do a complex query all at once, start small and build it up as you go along”.
基础知识有些直截了当,但是请注意,随着对数据和输出的需求越来越强,查询可能变得复杂且难以调试。 但是不要害怕。 就像我一直说的那样-“不要一次做一个复杂的查询,要从小处着手,并在进行时逐步建立它”。
Happy coding.
快乐的编码。
Complete script can be downloaded here.
完整的脚本可以在这里下载。
翻译自: https://www.sqlshack.com/ready-set-go-sql-server-handle-recursive-ctes/
sql cte递归
sql cte递归_准备好,开始吧– SQL Server如何处理递归CTE相关推荐
- mysql 递归_「MySQL」 - SQL Cheat Sheet - 未完成
近几个月的心情真是安排的妥妥的,呈现W状.多的不说了,这里对SQL的测试进行简单梳理,制作一份SQL Cheat Sheet. 0x01.数据库基本架构 Clinet层 Server层 连接器 网络连 ...
- python中引入sql的优点_引用sql-和引用sql相关的内容-阿里云开发者社区
bboss持久层改进支持模块sql配置文件引用其它模块sql配置文件中sql语句 bboss持久层改进支持模块sql配置文件引用其它模块sql配置文件中sql语句. 具体使用方法如下: <pro ...
- sql azure 语法_什么是Azure SQL Cosmos DB?
sql azure 语法 介绍 (Introduction) In the Azure Portal, you will find the option to install Azure SQL Co ...
- java中sql模糊查询_模糊查询的sql语句(java模糊查询sql语句)
模糊查询的sql语句(java模糊查询sql语句) 2020-07-24 11:06:02 共10个回答 假设表名为product,商品名为name,简界为remark.则可如下写:select[na ...
- sql delete删除列_现有表操作中SQL DELETE列概述
sql delete删除列 In this article, we will explore the process of SQL Delete column from an existing tab ...
- 二叉树层序遍历递归与非递归_总结归纳:二叉树遍历【递归 amp;amp; 非递归】...
今天为大家总结了二叉树前中后序遍历的递归与迭代解法: 1. 前序遍历 递归 List list=new ArrayList<>();public ListpreOrder(TreeNode ...
- foreach jdk8 递归_[Java 8] (8) Lambda表达式对递归的优化(上) - 使用尾递归 .
递归优化 很多算法都依赖于递归,典型的比如分治法(Divide-and-Conquer).但是普通的递归算法在处理规模较大的问题时,常常会出现StackOverflowError.处理这个问题,我们可 ...
- mysql 部门名称递归_部门子部门表结构,递归指定部门的所有子部门SQL函数
C/C++面试题总结 腾讯阿里面试题总结:1. 多态机制2. 排序算法(快排.堆排)3. 程序内存分配4. unix多线程5. 哈希查找6. oop特点7. 素数(优化)8. 字符串掩膜操作(内存紧凑 ...
- java.sql.date格式化_如何将java.sql.date格式化为这种格式:“MM-dd-yyyy”?
我需要以下面的格式"MM-dd-yyyy"获取 java.sql.date,但是我需要它来保留java.sql.date所以我可以将它作为日期字段放入表中.因此,格式化后它不能是S ...
最新文章
- 为何说“内容+社交”是奥运发展化趋势?
- 不重启iis的情况下切换iis的.net版本
- 【摘录】Ics4.0如何去除系统的状态栏
- Spring PropertyPlaceholderConfigurer Usage - 使用系统变量替换spring配置文件中的变量
- 连微信红包都在催我们长大:90后首次成为红包主力军
- 在.NET Core日志记录中使用Trace和TraceSource
- Qt同时加载多个项目
- getSupportFragmentManager要用在FragmentActivity及其子类中
- 用Matlab求解高等数学中的问题(求极限,求导)
- CCNA3.0中文版教材
- 阿里云怎么启动mysql_阿里云启动mysql
- 智能驾驶ADAS算法设计及Prescan仿真(2): 自适应巡航ACC控制策略设计与simulink仿真
- Wordpress世界最牛?做网站用国内cms建站系统才是正道
- PHP连接mysql原生代码
- 一文读懂五险一金,离职空窗期五险一金又该怎么办
- angular 脏值检测基础流程
- python 条形图显示数值_如何在条形图的条形图中显示数值?
- 夜间环境人脸识别_基于人脸识别的夜间疲劳驾驶判断方法与流程
- Jmeter-BeanShell后置处理器
- 电脑关闭休眠模式清理 C盘内存
热门文章
- 安卓获取浏览器上网记录_在android中获取浏览器历史记录和搜索结果
- unity 加载完场景继续加载场景中的物体_Unity光照渲染原理
- A. Raising Bacteria
- jsp页面struts2标签展示clob类型的数据
- PHP递归删除目录及目录下的文件
- 多个集合计算笛卡尔积-Python
- Java web servers 间是如何实现 session 同步的
- Codeforces Round #382 (Div. 2) D. Taxes 歌德巴赫猜想
- Fragment的生命周期同一Activity下不同Fragment之间的通信
- SMTP Error: Could not connect to SMTP host.