TensorFlow HOWTO 4.2 多层感知机回归(时间序列)
4.2 多层感知机回归(时间序列)
这篇教程中,我们使用多层感知机来预测时间序列,这是回归问题。
操作步骤
导入所需的包。
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
导入数据,并进行预处理。我们使用国际航班乘客数据集,由于它不存在于任何现有库中,我们需要先下载它。
ts = pd.read_csv('international-airline-passengers.csv', usecols=[1], header=0).dropna().values.ravel()
之后,我们需要将其转换为结构化数据集。我知道时间序列有很多实用的特征,但是这篇教程中,为了展示 MLP 的强大,我仅仅使用最简单的特征,也就是乘客数的历史值,并根据历史值来预测当前值。为此,我们需要一个窗口大小,也就是几个历史值与当前值有关。
wnd_sz = 5
ds = []
for i in range(0, len(ts) - wnd_sz + 1):ds.append(ts[i:i + wnd_sz])
ds = np.asarray(ds)x_ = ds[:, 0:wnd_sz - 1]
y_ = ds[:, [wnd_sz - 1]]
之后是训练集和测试集的划分。为时间序列划分训练集和测试集的时候,绝对不能打乱,而是应该把前一部分当做训练集,后一部分当做测试集。因为在时间序列中,未来值依赖历史值,而历史值不依赖未来值,这样可以尽可能避免在训练中使用测试集的信息。
train_size = int(len(x_) * 0.7)
x_train = x_[:train_size]
y_train = y_[:train_size]
x_test = x_[train_size:]
y_test = y_[train_size:]
定义超参数。时间序列很容易过拟合,为了避免过拟合,建议不要将迭代数设置太大。
| 变量 | 含义 |
|---|---|
n_input
|
样本特征数 |
n_epoch
|
迭代数 |
n_hidden1
|
隐层 1 的单元数 |
n_hidden2
|
隐层 2 的单元数 |
lr
|
学习率 |
n_input = wnd_sz - 1
n_hidden1 = 8
n_hidden2 = 8
n_epoch = 10000
lr = 0.05
搭建模型。要注意隐层的激活函数使用了目前暂时最优的 ELU。由于这个是回归问题,并且标签的取值是正数,输出层激活函数最好是 ReLU,不过我这里用了f(x)=x。
| 变量 | 含义 |
|---|---|
x
|
输入 |
y
|
真实标签 |
w_l{1,2,3}
|
第{1,2,3}层的权重
|
b_l{1,2,3}
|
第{1,2,3}层的偏置
|
z_l{1,2,3}
|
第{1,2,3}层的中间变量,前一层输出的线性变换
|
a_l{1,2,3}
|
第{1,2,3}层的输出,其中a_l3是模型输出
|
x = tf.placeholder(tf.float64, [None, n_input])
y = tf.placeholder(tf.float64, [None, 1])
w_l1 = tf.Variable(np.random.rand(n_input, n_hidden1))
b_l1 = tf.Variable(np.random.rand(1, n_hidden1))
w_l2 = tf.Variable(np.random.rand(n_hidden1, n_hidden2))
b_l2 = tf.Variable(np.random.rand(1, n_hidden2))
w_l3 = tf.Variable(np.random.rand(n_hidden2, 1))
b_l3 = tf.Variable(np.random.rand(1, 1))
z_l1 = x @ w_l1 + b_l1
a_l1 = tf.nn.elu(z_l1)
z_l2 = a_l1 @ w_l2 + b_l2
a_l2 = tf.nn.elu(z_l2)
z_l3 = a_l2 @ w_l3 + b_l3
a_l3 = z_l3
定义 MSE 损失、优化操作、和 R 方度量指标。
| 变量 | 含义 |
|---|---|
loss
|
损失 |
op
|
优化操作 |
r_sqr
|
R 方 |
loss = tf.reduce_mean((a_l3 - y) ** 2)
op = tf.train.AdamOptimizer(lr).minimize(loss)y_mean = tf.reduce_mean(y)
r_sqr = 1 - tf.reduce_sum((y - z_l3) ** 2) / tf.reduce_sum((y - y_mean) ** 2)
使用训练集训练模型。
losses = []
r_sqrs = []with tf.Session() as sess:sess.run(tf.global_variables_initializer())for e in range(n_epoch):_, loss_ = sess.run([op, loss], feed_dict={x: x_train, y: y_train})losses.append(loss_)
使用测试集计算 R 方。
r_sqr_ = sess.run(r_sqr, feed_dict={x: x_test, y: y_test})r_sqrs.append(r_sqr_)
每一百步打印损失和度量值。
if e % 100 == 0:print(f'epoch: {e}, loss: {loss_}, r_sqr: {r_sqr_}')
得到模型对训练特征和测试特征的预测值。
y_train_pred = sess.run(a_l3, feed_dict={x: x_train})y_test_pred = sess.run(a_l3, feed_dict={x: x_test})
输出:
epoch: 0, loss: 59209399.053257026, r_sqr: -17520.903006130215
epoch: 100, loss: 54125.98862726741, r_sqr: -28.30371839204463
epoch: 200, loss: 48165.48221823986, r_sqr: -25.13646606476775
epoch: 300, loss: 25826.1223418781, r_sqr: -12.89535810028511
epoch: 400, loss: 1596.701326728818, r_sqr: -0.2350739792412242
epoch: 500, loss: 1396.8836047513207, r_sqr: -0.19979831972491247
epoch: 600, loss: 1386.2307618333675, r_sqr: -0.18952804825771152
epoch: 700, loss: 1374.6194509485028, r_sqr: -0.17864308160044695
epoch: 800, loss: 1362.1306530753875, r_sqr: -0.1669310907644168
epoch: 900, loss: 1348.837516403113, r_sqr: -0.15445861855695942
epoch: 1000, loss: 1334.8048545363076, r_sqr: -0.14128485137041857
epoch: 1100, loss: 1320.0909505177317, r_sqr: -0.1274628487494167
epoch: 1200, loss: 1304.7487050247062, r_sqr: -0.11304061847816937
epoch: 1300, loss: 1288.8264056578596, r_sqr: -0.09806183013209635
epoch: 1400, loss: 1272.368278888685, r_sqr: -0.08256632457099822
epoch: 1500, loss: 1255.4149176209135, r_sqr: -0.06659050598517702
epoch: 1600, loss: 1238.0036386736738, r_sqr: -0.05016766677562812
epoch: 1700, loss: 1220.1688168734415, r_sqr: -0.033328289031115066
epoch: 1800, loss: 1201.942219268364, r_sqr: -0.016100344309701198
epoch: 1900, loss: 1183.3533635535823, r_sqr: 0.001490385551745188
epoch: 2000, loss: 1164.4299150007857, r_sqr: 0.019419953232036713
epoch: 2100, loss: 1145.1981380968932, r_sqr: 0.037665840800028216
epoch: 2200, loss: 1125.683416643312, r_sqr: 0.056206491416253
epoch: 2300, loss: 1105.9108537794123, r_sqr: 0.07502076650340628
epoch: 2400, loss: 1085.9059630721106, r_sqr: 0.0940873169623373
epoch: 2500, loss: 1065.6954608224203, r_sqr: 0.11338385761808756
epoch: 2600, loss: 1045.3081603639205, r_sqr: 0.13288634237228225
epoch: 2700, loss: 1024.7759657787278, r_sqr: 0.15256803995690105
epoch: 2800, loss: 1004.1349451931811, r_sqr: 0.172398525823234
epoch: 2900, loss: 983.4264457196117, r_sqr: 0.1923426217757903
epoch: 3000, loss: 962.6981814611527, r_sqr: 0.2123593431286731
epoch: 3100, loss: 942.0051856419402, r_sqr: 0.23240095064001043
epoch: 3200, loss: 921.4104707924716, r_sqr: 0.25241224904623527
epoch: 3300, loss: 900.9855546712687, r_sqr: 0.2723303372744077
epoch: 3400, loss: 880.8157626399897, r_sqr: 0.2920819860142483
epoch: 3500, loss: 860.9797390814788, r_sqr: 0.3115862647284954
epoch: 3600, loss: 841.5508166258288, r_sqr: 0.3307714419429332
epoch: 3700, loss: 822.65464452708, r_sqr: 0.34954174287751905
epoch: 3800, loss: 804.3510636509582, r_sqr: 0.36784090179299245
epoch: 3900, loss: 786.698489755282, r_sqr: 0.385608999078319
epoch: 4000, loss: 769.742814493071, r_sqr: 0.4028012203684326
epoch: 4100, loss: 753.5066274222577, r_sqr: 0.41939554512386545
epoch: 4200, loss: 737.987317032155, r_sqr: 0.435393667355777
epoch: 4300, loss: 723.1589061501688, r_sqr: 0.450820383097843
epoch: 4400, loss: 708.9775872199175, r_sqr: 0.4657183502307326
epoch: 4500, loss: 695.3902622132391, r_sqr: 0.48014080374835966
epoch: 4600, loss: 682.3445164530003, r_sqr: 0.49414259666687754
epoch: 4700, loss: 669.7979767738486, r_sqr: 0.5077712354635172
epoch: 4800, loss: 657.7254031658086, r_sqr: 0.5210596011864659
epoch: 4900, loss: 646.1225385082785, r_sqr: 0.5340213253103482
epoch: 5000, loss: 635.0063312881094, r_sqr: 0.5466495174400207
epoch: 5100, loss: 624.413372450103, r_sqr: 0.5589148722286865
epoch: 5200, loss: 614.3949181844811, r_sqr: 0.5707707632698614
epoch: 5300, loss: 605.0111648523978, r_sqr: 0.5821553829261457
epoch: 5400, loss: 596.3251407668536, r_sqr: 0.5929950345771348
epoch: 5500, loss: 588.394934666788, r_sqr: 0.6032110372771016
epoch: 5600, loss: 581.2665165995329, r_sqr: 0.6127246745768582
epoch: 5700, loss: 574.966974465473, r_sqr: 0.6214638760543536
epoch: 5800, loss: 569.4991301790525, r_sqr: 0.6293697644027529
epoch: 5900, loss: 564.8386101443393, r_sqr: 0.6364025085215417
epoch: 6000, loss: 560.9342529396988, r_sqr: 0.6425455981413335
epoch: 6100, loss: 557.7121333454768, r_sqr: 0.6478080528894717
epoch: 6200, loss: 555.082871816442, r_sqr: 0.6522228049088226
epoch: 6300, loss: 552.9504878905169, r_sqr: 0.655844018250897
epoch: 6400, loss: 551.2218559344465, r_sqr: 0.6587415604098865
epoch: 6500, loss: 549.8130443197065, r_sqr: 0.6609962191562182
epoch: 6600, loss: 548.6541928338876, r_sqr: 0.6626926870925417
epoch: 6700, loss: 547.6907665851817, r_sqr: 0.6639154520465458
epoch: 6800, loss: 546.8824436922644, r_sqr: 0.6647451519232287
epoch: 6900, loss: 546.2005216521292, r_sqr: 0.6652561458635722
epoch: 7000, loss: 545.624816174369, r_sqr: 0.6655151008532998
epoch: 7100, loss: 545.1407754175443, r_sqr: 0.6655803536739032
epoch: 7200, loss: 544.737161207175, r_sqr: 0.6655015768007708
epoch: 7300, loss: 544.4043734455902, r_sqr: 0.6653207475362519
epoch: 7400, loss: 544.1341742901118, r_sqr: 0.6650726389557293
epoch: 7500, loss: 543.9183617756419, r_sqr: 0.6647841774748728
epoch: 7600, loss: 543.7491045438804, r_sqr: 0.6644772215677328
epoch: 7700, loss: 543.6189281327097, r_sqr: 0.664168178900878
epoch: 7800, loss: 543.5208538865398, r_sqr: 0.6638692273468367
epoch: 7900, loss: 543.448546441615, r_sqr: 0.6635888904468247
epoch: 8000, loss: 543.3964235871173, r_sqr: 0.6633326568412115
epoch: 8100, loss: 543.3597144375057, r_sqr: 0.6631036869053042
epoch: 8200, loss: 543.334470694699, r_sqr: 0.6629032437625964
epoch: 8300, loss: 543.3175272915516, r_sqr: 0.6627311295544881
epoch: 8400, loss: 543.3064268470205, r_sqr: 0.6625860646477272
epoch: 8500, loss: 543.2993218444616, r_sqr: 0.6624660124009056
epoch: 8600, loss: 543.2948676666707, r_sqr: 0.6623684566822827
epoch: 8700, loss: 543.2921173712779, r_sqr: 0.66229063392118
epoch: 8800, loss: 543.2904259948474, r_sqr: 0.6622297208034926
epoch: 8900, loss: 543.2893689519885, r_sqr: 0.6621829791500562
epoch: 9000, loss: 543.2886762658412, r_sqr: 0.6621478605931548
epoch: 9100, loss: 543.2881822202421, r_sqr: 0.6621220749401975
epoch: 9200, loss: 543.2877886467712, r_sqr: 0.6621036272136598
epoch: 9300, loss: 543.2874393833906, r_sqr: 0.6620908290593257
epoch: 9400, loss: 543.2871033165793, r_sqr: 0.662082291939509
epoch: 9500, loss: 543.2867636136157, r_sqr: 0.6620769002407012
epoch: 9600, loss: 543.2864111990842, r_sqr: 0.6620737858271186
epoch: 9700, loss: 543.2860410035256, r_sqr: 0.6620722889010859
epoch: 9800, loss: 543.285649892272, r_sqr: 0.6620719225552976
epoch: 9900, loss: 543.2852355789513, r_sqr: 0.662072338159642
绘制时间序列及其预测值。
plt.figure()
plt.plot(ts, label='Original')
y_train_pred = np.concatenate([[np.nan] * n_input, y_train_pred.ravel()
])
y_test_pred = np.concatenate([[np.nan] * (n_input + train_size),y_test_pred.ravel()
])
plt.plot(y_train_pred, label='y_train_pred')
plt.plot(y_test_pred, label='y_test_pred')
plt.legend()
plt.show()
![]()
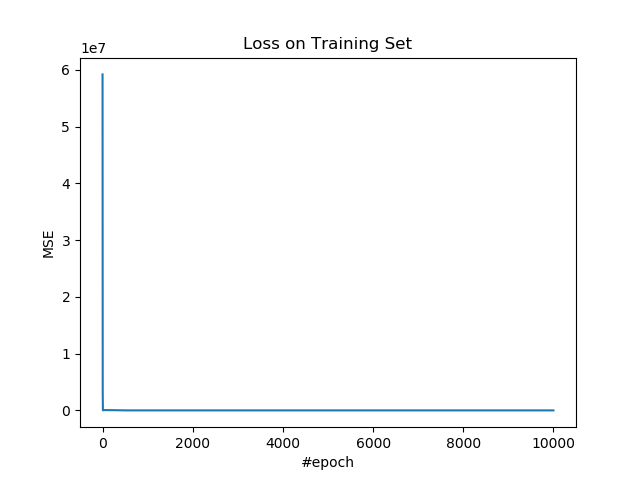
绘制训练集上的损失。
plt.figure()
plt.plot(losses)
plt.title('Loss on Training Set')
plt.xlabel('#epoch')
plt.ylabel('MSE')
plt.show()
绘制测试集上的 R 方。
plt.figure()
plt.plot(r_sqrs)
plt.title('$R^2$ on Testing Set')
plt.xlabel('#epoch')
plt.ylabel('$R^2$')
plt.show()
![]()
扩展阅读
- DeepLearningAI 笔记:浅层神经网络
- DeepLearningAI 笔记:深层神经网络
- 如何将时间序列问题转化为监督学习问题
TensorFlow HOWTO 4.2 多层感知机回归(时间序列)相关推荐
- TensorFlow HOWTO 4.1 多层感知机(分类)
4.1 多层感知机(分类) 这篇文章开始就是深度学习了.多层感知机的架构是这样: 输入层除了提供数据之外,不干任何事情.隐层和输出层的每个节点都计算一次线性变换,并应用非线性激活函数.隐层的激活函数是 ...
- TensorFlow HOWTO 5.1 循环神经网络(时间序列)
5.1 循环神经网络(时间序列) 循环神经网络(RNN)用于建模带有时间关系的数据.它的架构是这样的. 在最基本的 RNN 中,单元(方框)中的操作和全连接层没什么区别,都是线性变换和激活.它完全可以 ...
- TensorFlow HOWTO 2.2 支持向量回归(软间隔)
将上一节的假设改一改,模型就可以用于回归问题. 操作步骤 导入所需的包. import tensorflow as tf import numpy as np import matplotlib.py ...
- 深度学习框架 TensorFlow:张量、自动求导机制、tf.keras模块(Model、layers、losses、optimizer、metrics)、多层感知机(即多层全连接神经网络 MLP)
日萌社 人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) 安装 TensorFlow2.CUDA10.cuDNN7.6. ...
- TensorFlow实现多层感知机函数逼近
TensorFlow实现多层感知机函数逼近 准备工作 对于函数逼近,这里的损失函数是 MSE.输入应该归一化,隐藏层是 ReLU,输出层最好是 Sigmoid. 下面是如何使用 MLP 进行函数逼近的 ...
- TensorFlow实现多层感知机MINIST分类
TensorFlow实现多层感知机MINIST分类 TensorFlow 支持自动求导,可以使用 TensorFlow 优化器来计算和使用梯度.使用梯度自动更新用变量定义的张量.本文将使用 Tenso ...
- TensorFlow多层感知机实现MINIST分类
import tensorflow as tf import tensorflow.contrib.layers as layers from tensorflow.python import deb ...
- 基于Tensorflow实现多层感知机网络MLPs
正文共1232张图,1张图,预计阅读时间7分钟. github:https://github.com/sladesha/deep_learning 之前在基于Tensorflow的神经网络解决用户流失 ...
- TensorFlow实现多层感知机
一.感知机的简介 在前面我们实现了一个softmax regression,也可以说是一个多分类问题的logistic regression.它和传统意义上的神经网络最大的区别就是没有隐藏层.在一个神 ...
最新文章
- 最牛逼的阿里巴巴内部Java调优方案,没有之一!
- android sdk投屏,海豚星空扫码投屏 Android 接收端 SDK 集成 六步骤
- Sql Server 查询语句
- 五分钟快速搭建Serverless免费邮件服务
- android init.d脚本,◇添加init.d脚本支持教程贴◇
- “3D几何与视觉技术”全球在线研讨会第五期~隐式3D形状表示学习
- 【英语学习】【English L06】U07 Jobs L2 I have my own bakery now
- TensorFlow 2.0 发布以来,又有哪些最新进展?| AI ProCon 2020
- 代号红狗:那些站在微软云起点的中国创业者
- Android pda出入库管理,仓库PDA扫描出入库管理系统
- 硬币找钱问题(最小硬币和问题)详解与代码实现
- Android11裁剪,Andorid 11调用系统裁剪
- STM32 CAN通信之二:正常模式
- 使用 Amazon Personalize 快速搭建推荐服务
- 云上领跑 智慧贵州 中软国际与云上贵州深度合作助力政府数字化转型
- yarn打包报错:error during build: Error: Assigning to rvalue (Note that you need plugins to import files
- ~1前端开发是干什么的?
- 讯飞语音转写.NET版本
- 别让假装努力毁了你,最强的68道软件测试基础问答题你能答的溜嘛?
- 英勇地死去 VS 卑贱地活着