Spark ALS应用BLAS加速
文章目录
- Spark ALS应用BLAS加速
- 1. 环境
- 2. 问题引入
- 3. 参考:
- 4. 思路:
- 4.1 简单测试:
- 4.2 使用Native BLAS需要添加的Jar包
- 方式1:在Intellij IDEA 中添加依赖找到
- 方式2: 自行指定参数编译Spark源码
- 4.3 使用新编译的Spark测试是否加载Native BLAS
- 5. 修改官网提供的安装包,使其加载BLAS
- 5.1 使用 --jars 参数
- 5.2 直接拷贝相关Jar包到$SPARK_HOME/jars路径中;
- 6. 测试ALS是否有加速
- 6.1 测试数据
- 6.2 使用集群配置
- 6.3 测试是否有BLAS的加速
- 7. 总结
Spark ALS应用BLAS加速
1. 环境
| 软件 | 说明 | 版本 |
|---|---|---|
| Win10 | 宿主机 | 8G内存,179G SSD |
| VMware Workstation | 虚拟化软件 | V11 |
| Spark | 2.2.2 | |
| Hadoop | 2.6.5 | |
| Maven | windows 上maven用于编译Spark2.2.2 | 3.3.9 |
| Intellij IDEA | Windows上编译测试包 | 2016.3 |
| ubuntu | WMware 虚拟机系统 | Ubuntu 16.04.5 LTS |
| 集群 | 一主三从,node200(主), node201~node203 |
2. 问题引入
- 在使用Spark1.6集群,进行Spark ALS算法测试时,发现其推荐运行的很慢;
- 同时在推荐或建模时,出现如下的提示:
Feb 25, 2019 10:07:05 PM com.github.fommil.netlib.BLAS <clinit>
WARNING: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
Feb 25, 2019 10:07:05 PM com.github.fommil.netlib.BLAS <clinit>
WARNING: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
com.github.fommil.netlib.F2jBLAS
3. 参考:
此篇博客参考如下链接:
- Use Native BLAS/LAPACK in Apache Spark
- How to configure high performance BLAS/LAPACK for Breeze on Amazon EMR, EC2
- netlib-java#linux
- building spark
- spark mllib guide
4. 思路:
4.1 简单测试:
参考 2 中的代码,并添加可以打印当前使用的Classpath路径功能的代码,全部代码可以 fansy1990/als_blas 中进行checkout。
下载完代码后,直接导入到IntelliJ IDEA中,并编译打包,得到als_blas-1.0-SNAPSHOT.jar,然后即可执行:
./spark-submit --class demo.TestBLAS --master local[1] /root/als_blas-1.0-SNAPSHOT.jar 3000
执行命令后,得到如下所示信息。
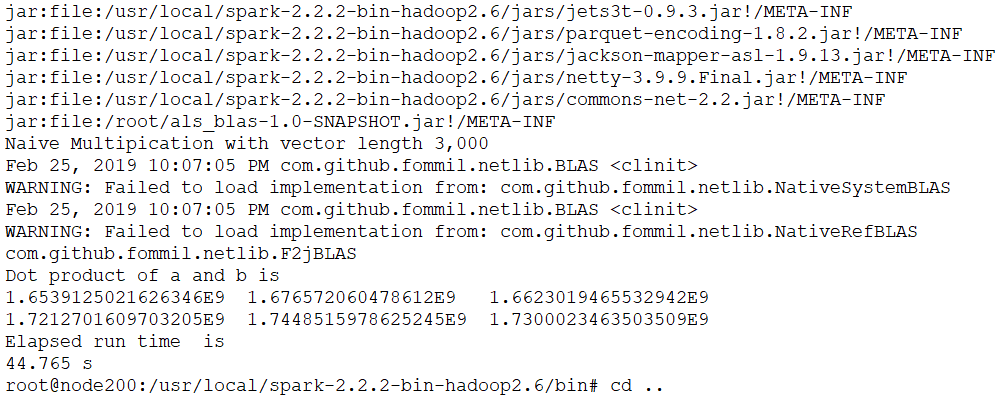
在图中可以看到:
- 其使用的Classpath是Spark安装目录下的jars路径下面的jar包;
- 代码并没有使用NativeSystemBLAS或NativeRefBLAS;
- 代码测试耗时44.765秒。
4.2 使用Native BLAS需要添加的Jar包
方式1:在Intellij IDEA 中添加依赖找到
- 在IDEA工程中直接运行demo.TestBLAS object,即可看到当前使用的Classpath;
- 通过在IDEA工程的pom.xml文件中加入
<dependency><groupId>com.github.fommil.netlib</groupId><artifactId>all</artifactId><version>1.1.2</version><type>pom</type>
</dependency>
依赖后,重新运行,可以发现其加载多了几个Jar包,如下:
jniloader-1.1.jarnetlib-native_ref-win-i686-1.1-natives.jar
netlib-native_system-win-i686-1.1-natives.jarnative_system-java-1.1.jar
native_ref-java-1.1.jarnetlib-native_ref-linux-armhf-1.1-natives.jar
netlib-native_system-linux-armhf-1.1-natives.jarnetlib-native_ref-linux-i686-1.1-natives.jar
netlib-native_system-linux-i686-1.1-natives.jarnetlib-native_ref-osx-x86_64-1.1-natives.jar
netlib-native_system-osx-x86_64-1.1-natives.jarnetlib-native_ref-win-x86_64-1.1-natives.jar
netlib-native_system-win-x86_64-1.1-natives.jarnetlib-native_ref-linux-x86_64-1.1-natives.jar
netlib-native_system-linux-x86_64-1.1-natives.jar
此Jar包即是所需的Jar包。
方式2: 自行指定参数编译Spark源码
下载Spark源码,并编译,编译时使用如下命令及参数:
C:\"Program Files"\apache-maven-3.6.0-bin\apache-maven-3.3.9\bin\mvn \
-Pnetlib-lgpl \
-Pyarn \
-Phive\
-Phive-thriftserver \
-DskipTests \
clean package
其中,-netlib-lgpl就是使用Native BLAS必须加入的参数。
如下所示,即为编译完成后结果。

4.3 使用新编译的Spark测试是否加载Native BLAS
- 确认node201上是否有blas库,如下:
root@node201:~# update-alternatives --config libblas.so
update-alternatives: error: no alternatives for libblas.so
root@node201:~# update-alternatives --config libblas.so.3
There is only one alternative in link group libblas.so.3 (providing /usr/lib/libblas.so.3): /usr/lib/libblas/libblas.so.3
Nothing to configure.
可以看到有一个系统默认的库。
- 拷贝编译好的安装包到node201,并在其下运行:
./spark-submit --class demo.TestBLAS \
--master local[1] \
/root/als_blas-1.0-SNAPSHOT.jar \
3000
运行后,可以看到如下信息:

从上面的信息可以看出:
- 其加载了本地的BLAS库
- 虽然加载了本地的BLAS库,但是还是很慢
- 尝试安装openblas
apt-get install libatlas3-base libopenblas-base
安装完成后,进行验证,如下:
root@node201:/opt/spark-2.2.2/bin# update-alternatives --config libblas.so
update-alternatives: error: no alternatives for libblas.so
root@node201:/opt/spark-2.2.2/bin# update-alternatives --config libblas.so.3
There are 3 choices for the alternative libblas.so.3 (providing /usr/lib/libblas.so.3).Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/lib/openblas-base/libblas.so.3 40 auto mode1 /usr/lib/atlas-base/atlas/libblas.so.3 35 manual mode2 /usr/lib/libblas/libblas.so.3 10 manual mode3 /usr/lib/openblas-base/libblas.so.3 40 manual modePress <enter> to keep the current choice[*], or type selection number:
出现如上所示信息,即说明安装成功。
- 再次运行测试,如下:

说明:
- 使用自行编译的Spark能加载安装的openblas;
- 同时效率有了10x的提升!
5. 修改官网提供的安装包,使其加载BLAS
5.1 使用 --jars 参数
既然对比发现官网和自己编译打包的Spark安装包里面的Classpath只有几个不同的jar包,可以考虑把这些jar包加入到执行参数中,如下:
./spark-submit --class demo.TestBLAS \
--master local[1] \
--jars /root/jars/jniloader-1.1.jar,/root/jars/netlib-native_ref-win-x86_64-1.1-natives.jar,/root/jars/native_ref-java-1.1.jar,/root/jars/netlib-native_system-linux-armhf-1.1-natives.jar,/root/jars/native_system-java-1.1.jar,/root/jars/netlib-native_system-linux-i686-1.1-natives.jar,/root/jars/netlib-native_ref-linux-armhf-1.1-natives.jar,/root/jars/netlib-native_system-linux-x86_64-1.1-natives.jar,/root/jars/netlib-native_ref-linux-i686-1.1-natives.jar,/root/jars/netlib-native_system-osx-x86_64-1.1-natives.jar,/root/jars/netlib-native_ref-linux-x86_64-1.1-natives.jar,/root/jars/netlib-native_system-win-i686-1.1-natives.jar,/root/jars/netlib-native_ref-osx-x86_64-1.1-natives.jar,/root/jars/netlib-native_system-win-x86_64-1.1-natives.jar,/root/jars/netlib-native_ref-win-i686-1.1-natives.jar \
/root/als_blas-1.0-SNAPSHOT.jar \
3000
但是,经测试此方法失败,[此方法的失败在 1 中有提及]。
5.2 直接拷贝相关Jar包到$SPARK_HOME/jars路径中;
拷贝相关包到官网安装包的jars路径下:
cp /root/jars/* $SPARK_HOME/jars
测试通过,说明:拷贝相关包到$SPARK_HOME/jars的方式可行 !
6. 测试ALS是否有加速
本文问题的引入是因为使用Spark1.6版本,但是测试环境使用的是Spark2.2.2版本,故此测试环境可能也会有影响,例如Spark2.2.2是有对ALS做了优化的,下面也有提及此点。
6.1 测试数据
测试数据使用 MovieLens 1m dataset, 该数据集有6000用户,4000电影。
6.2 使用集群配置
集群使用本机虚拟机,1主3从的配置,其集群具体配置如下:

6.3 测试是否有BLAS的加速
- 直接运行测试类,命令如下:
spark-submit --class demo.AlsTest \
--deploy-mode cluster \
/root/als_blas-1.1-SNAPSHOT.jar 3000
经过多次测试,发现:
- 耗时平均在1.2mins;

- 子节点出现没有使用Native BLAS的提示;

- 使用BLAS再次测试
(1)拷贝相关Jar包到所有集群节点的$SPARK_HOME/jars;
(2)在集群各个子节点安装openblas,参考上面的命令;
(3)再次运行,发现其耗时仍是1.2mins,同时也仍有没有使用Native BLAS的提示;
- 使用编译的Spark 进行测试;
- 耗时1.4mins,程序变得更慢;

- 在子节点没有出现未使用Native BLAS的提示,说明已经使用了BLAS库;
7. 总结
- 如果要使用Spark ALS算法,建议使用Spark2.x以上,效率更快;
- 如果只能使用Spark1.x,建议使用自行编译的Spark安装包,可以应用Native BLAS进行加速([有待验证!])
- 如果使用Spark2.x的自行编译的安装包,那么针对Spark中ALS算法,其推荐效率更低。这点其实在其源码中也有说明,如下所示。
private def recommendForAll(rank: Int,srcFeatures: RDD[(Int, Array[Double])],dstFeatures: RDD[(Int, Array[Double])],num: Int): RDD[(Int, Array[(Int, Double)])] = {val srcBlocks = blockify(srcFeatures)val dstBlocks = blockify(dstFeatures)val ratings = srcBlocks.cartesian(dstBlocks).flatMap { case (srcIter, dstIter) =>val m = srcIter.sizeval n = math.min(dstIter.size, num)val output = new Array[(Int, (Int, Double))](m * n)var i = 0val pq = new BoundedPriorityQueue[(Int, Double)](n)(Ordering.by(_._2))srcIter.foreach { case (srcId, srcFactor) =>dstIter.foreach { case (dstId, dstFactor) =>// We use F2jBLAS which is faster than a call to native BLAS for vector dot productval score = BLAS.f2jBLAS.ddot(rank, srcFactor, 1, dstFactor, 1)pq += dstId -> score}pq.foreach { case (dstId, score) =>output(i) = (srcId, (dstId, score))i += 1}pq.clear()}output.toSeq}ratings.topByKey(num)(Ordering.by(_._2))
}
Spark ALS应用BLAS加速相关推荐
- Spark ALS recommendForAll源码解析实战之Spark1.x vs Spark2.x
文章目录 Spark ALS recommendForAll源码解析实战 1. 软件版本: 2. 本文要解决的问题 3. 源码分析实战 3.1 Spark2.2.2 ALS recommendForA ...
- 基于Spark ALS算法的个性化推荐
今天来使用spark中的ALS算法做一个小推荐.需要数据的话可以点击查看初识sparklyr-电影数据分析,在文末点击阅读原文即可获取. 其实在R中还有一个包可以做推荐,那就是recommenderl ...
- spark als推荐算法笔记
转自: https://www.cnblogs.com/mstk/p/7208674.html --上面的测试集实际用的训练集 参考: https://blog.csdn.net/delltower/ ...
- 推荐系统算法--ItemCF--MF(ALS)--FF
1.ItemCF: 协同过滤是什么? 协同过滤 (Collaborative filtering),指的是,通过收集群体用户的偏好信息,自动化预测(过滤)个体用户可能感兴趣的内容.协同(collabo ...
- 使用spark计算文档相似度
2019独角兽企业重金招聘Python工程师标准>>> 1.TF-IDF文档转换为向量 以下边三个句子为例 罗湖发布大梧桐新兴产业带整体规划 深化伙伴关系,增强发展动力 为世界经济发 ...
- 协同过滤算法 R/mapreduce/spark mllib多语言实现
用户电影评分数据集下载 http://grouplens.org/datasets/movielens/ 1) Item-Based,非个性化的,每个人看到的都一样 2) User-Based,个性化 ...
- spark 把一列数据合并_Spark Java-合并同一列多行 - java
我正在使用Java Spark,并且有1个这样的数据框 +---+-----+------+ |id |color|datas | +----------------+ |1 |blue |data1 ...
- spark 2.x ML概念与应用
# spark 2.x ML概念与应用 @(SPARK)[spark] 一基础 1核心概念 2Transformer 3Estimator 4Pileline 5同一实例 6保存模型 二基本数据结构 ...
- Spark NaiveBayes Demo 朴素贝叶斯分类算法
模型sql文件 :https://pan.baidu.com/s/1hugrI9e 使用数据链接 https://pan.baidu.com/s/1kWz8fNh NaiveBayes Spark M ...
最新文章
- 这些神经网络,还可信吗?
- 业务系统性能问题分析和诊断
- UI自动化测试工具White简介以及使用经验总结(一)
- 安装node-sass时出现的错误解决方案(Mac自用,也可以借鉴)
- CCIE-LAB-第十五篇-IPV6-BGP+VPN6+RT
- FreeSql (三)实体特性
- mysql explain 派生表_MySQL的Explain命令
- 堆的应用--并查集解决“擒贼先擒王”问题(JAVA)
- Java构造方法与析构方法实例剖析
- 《跟波利亚学解题》思维笔记
- 英文聊天常用缩写单词
- 我的计算机用户账户logo,UserAccountControl
- em算法详细例子及推导_EM算法入门教程
- linux shell grep 多个文件
- 华为鲲鹏HCIA认证 常考题
- EPLAN2.9程序安装及注意事项
- iOS 模拟器 获取位置 设置自定义位置
- 【Joy of Cryptography 读书笔记】Chapter 5 伪随机数生成器(Pseudorandom Generator)
- x264 2pass编码说明
- 卸载 npm 软件包