使用spark计算文档相似度
2019独角兽企业重金招聘Python工程师标准>>> 
1、TF-IDF文档转换为向量
以下边三个句子为例
罗湖发布大梧桐新兴产业带整体规划
深化伙伴关系,增强发展动力
为世界经济发展贡献中国智慧经过分词后变为
[罗湖, 发布, 大梧桐, 新兴产业, 带, 整体, 规划]|
[深化, 伙伴, 关系, 增强, 发展, 动力]
[为, 世界, 经济发展, 贡献, 中国, 智慧]经过词频(TF)计算后,词频=某个词在文章中出现的次数
(262144,[10607,18037,52497,53469,105320,122761,220591],[1.0,1.0,1.0,1.0,1.0,1.0,1.0])
(262144,[8684,20809,154835,191088,208112,213540],[1.0,1.0,1.0,1.0,1.0,1.0])
(262144,[21159,30073,53529,60542,148594,197957],[1.0,1.0,1.0,1.0,1.0,1.0]) 262144为总词数,这个值越大,不同的词被计算为一个Hash值的概率就越小,数据也更准确。
[10607,18037,52497,53469,105320,122761,220591]分别代表罗湖, 发布, 大梧桐, 新兴产业, 带, 整体, 规划的向量值
[1.0,1.0,1.0,1.0,1.0,1.0,1.0]分别代表罗湖, 发布, 大梧桐, 新兴产业, 带, 整体, 规划在句子中出现的次数
经过逆文档频率(IDF),逆文档频率=log(总文章数/包含该词的文章数)
[6.062092444847088,7.766840537085513,7.073693356525568,5.201891179623976,7.073693356525568,5.3689452642871425,6.514077568590145]
[3.8750202389748862,5.464255444091467,6.062092444847088,7.3613754289773485,6.668228248417403,5.975081067857458]
[6.2627631403092385,4.822401557919072,6.2627631403092385,6.2627631403092385,3.547332831909406,4.065538562973019]其中[6.062092444847088,7.766840537085513,7.073693356525568,5.201891179623976,7.073693356525568,5.3689452642871425,6.514077568590145]分别代表罗湖, 发布, 大梧桐, 新兴产业, 带, 整体, 规划的逆文档频率
2、相似度计算方法
在之前学习《Mahout实战》书中聚类算法中,知道几种相似性度量方法
欧氏距离测度
给定平面上的两个点,通过一个标尺来计算出它们之间的距离
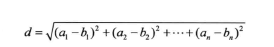
平方欧氏距离测度
这种距离测度的值是欧氏距离的平方。
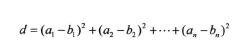
曼哈顿距离测度
两个点之间的距离是它们坐标差的绝对值
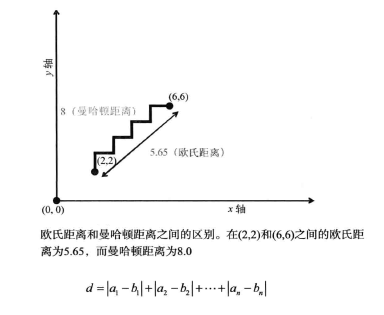
余弦距离测度
余弦距离测度需要我们将这些点视为人原点指向它们的向量,向量之间形成一个夹角,当夹角较小时,这些向量都会指向大致相同方向,因此这些点非常接近,当夹角非常小时,这个夹角的余弦接近于1,而随着角度变大,余弦值递减。
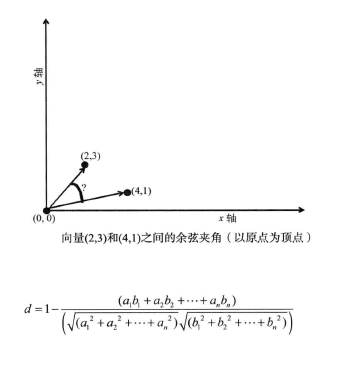
两个n维向量之间的余弦距离公式
谷本距离测度
余弦距离测度忽略向量的长度,这适用于某些数据集,但是在其它情况下可能会导致糟糕的聚类结果,谷本距离表现点与点之间的夹角和相对距离信息。
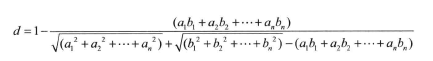
加权距离测度
允许对不同的维度加权从而提高或减小某些维度对距离测度值的影响。
3、代码实现
spark ml有TF_IDF的算法实现,spark sql也能实现数据结果的轻松读取和排序,也自带有相关余弦值计算方法。本文将使用余弦相似度计算文档相似度,计算公式为
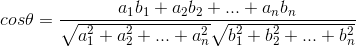
测试数据来源于12月07日-12月12日之间网上抓取,样本测试数据量为16632条,
数据格式为:Id@==@发布时间@==@标题@==@内容@==@来源。penngo_07_12.txt文件内容如下:

第一条新闻是这段时间的一个新闻热点,本文例子是计算所有新闻与第一条新闻的相似度,计算结果按相似度从高到低排序,最终结果保存在文本文件中。
使用maven创建项目spark项目
pom.xml配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.spark.penngo</groupId><artifactId>spark_test</artifactId><packaging>jar</packaging><version>1.0-SNAPSHOT</version><name>spark_test</name><url>http://maven.apache.org</url><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.0.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.0.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.11</artifactId><version>2.0.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.2.0</version></dependency><dependency><groupId>org.lionsoul</groupId><artifactId>jcseg-core</artifactId><version>2.0.0</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.5</version></dependency><!--<dependency><groupId>org.mongodb</groupId><artifactId>mongodb-driver</artifactId><version>3.3.0</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.1</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.21</version></dependency>--></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin></plugins></build>
</project>
SimilarityTest.java
package com.spark.penngo.tfidf;import com.spark.test.tfidf.util.SimilartyData;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.ml.feature.HashingTF;
import org.apache.spark.ml.feature.IDF;
import org.apache.spark.ml.feature.IDFModel;
import org.apache.spark.ml.feature.Tokenizer;
import org.apache.spark.ml.linalg.BLAS;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.sql.*;
import org.lionsoul.jcseg.tokenizer.core.*;import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.StringReader;
import java.util.*;/*** 计算文档相似度https://my.oschina.net/penngo/blog*/
public class SimilarityTest {private static SparkSession spark = null;private static String splitTag = "@==@";public static Dataset<Row> tfidf(Dataset<Row> dataset) {Tokenizer tokenizer = new Tokenizer().setInputCol("segment").setOutputCol("words");Dataset<Row> wordsData = tokenizer.transform(dataset);HashingTF hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures");Dataset<Row> featurizedData = hashingTF.transform(wordsData);IDF idf = new IDF().setInputCol("rawFeatures").setOutputCol("features");IDFModel idfModel = idf.fit(featurizedData);Dataset<Row> rescaledData = idfModel.transform(featurizedData);return rescaledData;}public static Dataset<Row> readTxt(String dataPath) {JavaRDD<TfIdfData> newsInfoRDD = spark.read().textFile(dataPath).javaRDD().map(new Function<String, TfIdfData>() {private ISegment seg = null;private void initSegment() throws Exception {if (seg == null) {JcsegTaskConfig config = new JcsegTaskConfig();config.setLoadCJKPos(true);String path = new File("").getAbsolutePath() + "/data/lexicon";System.out.println(new File("").getAbsolutePath());ADictionary dic = DictionaryFactory.createDefaultDictionary(config);dic.loadDirectory(path);seg = SegmentFactory.createJcseg(JcsegTaskConfig.COMPLEX_MODE, config, dic);}}public TfIdfData call(String line) throws Exception {initSegment();TfIdfData newsInfo = new TfIdfData();String[] lines = line.split(splitTag);if(lines.length < 5){System.out.println("error==" + lines[0] + " " + lines[1]);}String id = lines[0];String publish_timestamp = lines[1];String title = lines[2];String content = lines[3];String source = lines.length >4 ? lines[4] : "" ;seg.reset(new StringReader(content));StringBuffer sff = new StringBuffer();IWord word = seg.next();while (word != null) {sff.append(word.getValue()).append(" ");word = seg.next();}newsInfo.setId(id);newsInfo.setTitle(title);newsInfo.setSegment(sff.toString());return newsInfo;}});Dataset<Row> dataset = spark.createDataFrame(newsInfoRDD,TfIdfData.class);return dataset;}public static SparkSession initSpark() {if (spark == null) {spark = SparkSession.builder().appName("SimilarityPenngoTest").master("local[3]").getOrCreate();}return spark;}public static void similarDataset(String id, Dataset<Row> dataSet, String datePath) throws Exception{Row firstRow = dataSet.select("id", "title", "features").where("id ='" + id + "'").first();Vector firstFeatures = firstRow.getAs(2);Dataset<SimilartyData> similarDataset = dataSet.select("id", "title", "features").map(new MapFunction<Row, SimilartyData>(){public SimilartyData call(Row row) {String id = row.getString(0);String title = row.getString(1);Vector features = row.getAs(2);double dot = BLAS.dot(firstFeatures.toSparse(), features.toSparse());double v1 = Vectors.norm(firstFeatures.toSparse(), 2.0);double v2 = Vectors.norm(features.toSparse(), 2.0);double similarty = dot / (v1 * v2);SimilartyData similartyData = new SimilartyData();similartyData.setId(id);similartyData.setTitle(title);similartyData.setSimilarty(similarty);return similartyData;}}, Encoders.bean(SimilartyData.class));Dataset<Row> similarDataset2 = spark.createDataFrame(similarDataset.toJavaRDD(),SimilartyData.class);FileOutputStream out = new FileOutputStream(datePath);OutputStreamWriter osw = new OutputStreamWriter(out, "UTF-8");similarDataset2.select("id", "title", "similarty").sort(functions.desc("similarty")).collectAsList().forEach(row->{try{StringBuffer sff = new StringBuffer();String sid = row.getAs(0);String title = row.getAs(1);double similarty = row.getAs(2);sff.append(sid).append(" ").append(similarty).append(" ").append(title).append("\n");osw.write(sff.toString());}catch(Exception e){e.printStackTrace();}});osw.close();out.close();}public static void run() throws Exception{initSpark();String dataPath = new File("").getAbsolutePath() + "/data/penngo_07_12.txt";Dataset<Row> dataSet = readTxt(dataPath);dataSet.show();Dataset<Row> tfidfDataSet = tfidf(dataSet);String id = "58528946cc9434e17d8b4593";String similarFile = new File("").getAbsolutePath() + "/data/penngo_07_12_similar.txt";similarDataset(id, tfidfDataSet, similarFile);}public static void main(String[] args) throws Exception{//window上运行//System.setProperty("hadoop.home.dir", "D:/penngo/hadoop-2.6.4");//System.setProperty("HADOOP_USER_NAME", "root");run();}}
运行结果,相似度越高的,新闻排在越前边,样例数据的测试结果基本满足要求。data_07_12_similar.txt文件内容如下:

参考资料
《Mahout实战》
转载于:https://my.oschina.net/dreamerliujack/blog/809387
使用spark计算文档相似度相关推荐
- java文档相似度计算,计算文档与文档的相似度
最近帮很多本科毕业生做文本数据分析,经常遇到的一个需求是计算文档相似度. 思路: 抽取语料(所有文档)中的词语,构建词典(词语与数字对应起来). 根据构建的词典对每个文档进行重新编码(将文档转化为向量 ...
- 文档相似度的比较tf-idf lda lsi
from gensim.models import doc2vec from gensim import corpora,models import jieba,os from gensim.simi ...
- 文档相似度之词条相似度word2vec、及基于词袋模型计算sklearn实现和gensim
文档相似度之词条相似度word2vec.及基于词袋模型计算sklearn实现和gensim 示例代码: import jieba import pandas as pd from gensim.mod ...
- 向量空间模型(VSM)在文档相似度计算上的简单介绍
向量空间模型(VSM:Vector space model)是最常用的相似度计算模型,在自然语言处理中有着广泛的应用,这里简单介绍一下其在进行文档间相似度计算时的原理. 假设共有十个词:w1,w2 ...
- word2vec相似度计算_文档相似度助力搜索引擎
几种简单相似度算法: 1.简单共有词判断 假设现有文本A和B,将A.B经过分词.去停用词之后形成集合A={a1,a2,...,an}和集合B={b1,b2,...,bn}.用NUM(A∩B)表示集合A ...
- WMD:基于词向量的文档相似度计算
EMD算法简介 该部分引用自[1] Earth Mover's Distance (EMD),和欧氏距离一样,他们都是一种距离度量的定义,可以用来测量某分布之间的距离.EMD主要应用在图像处理和语音信 ...
- Python自然语言处理:文档相似度计算(gensim.models)
目录 1. tf-idf(每个文档形成一个tfidf向量) 2. 仅频率(每个文档形成一个频率值向量) 3. 仅出现与否(每个文档形成一个出现与否的二元向量) 4. Word2vec模型(每个词形成一 ...
- vsm java_向量空间模型(VSM)在文档相似度计算上的简单介绍
C#实现在: 向量空间模型(VSM:Vector space model)是最常用的相似度计算模型,在自然语言处理中有着广泛的应用,这里简单介绍一下其在进行文档间相似度计算时的原理. 假设共有十个词: ...
- 文档相似度之doc2vec、文档聚类
文档相似度之doc2vec.文档聚类 示例代码: import jieba import pandas as pd from gensim import corpora, models from ge ...
最新文章
- 如何成为一名对话系统工程师
- 从源码分析DEARGUI之add_menu_items
- 自用Java爬虫工具JAVA-CURL已开源
- 窗口属性 客户矩形_航空公司客户价值分析
- 欢迎使用CSDN-markdown编辑器(此为使用指南,自己还不熟练有些功能的使用)
- 转载:缓存 Cache
- Tomcat服务器目录结构
- kafka分布式_带有Kafka和ZeroMQ的分布式类星体演员
- 全球首例无人车撞人致死事故判决:Uber无罪,安全员要进一步调查
- jQuery判断页面是电脑端还是手机端
- 洛谷 P1840 【Color the Axis_NOI导刊2011提高(05)】 题解
- PDF编辑器中文版怎么插入PDF空白页面
- vue json对象转数组_年薪百万之路--第六十七天 Vue入门
- APPLE 知识模块初步设计
- windows10 安装 choco
- 微信小程序:二开版优化新紫色UI云开发新款壁纸小程序源码
- AD中T型节点添加泪滴失败,原因是T型走线有问题
- 高效线性氮化镓射频功放芯片模组研究
- 使用python爬取网站数据并写入到excel中
- HTML5菜单栏特效