#数据技术选型#即席查询Shib+Presto,集群任务调度HUE+Oozie
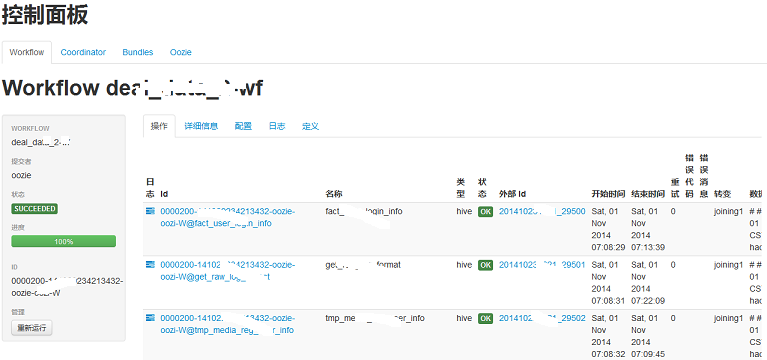
使用者是产品/运营/销售运营的数据分析师;要求数据分析师掌握查询SQL查询脚本编写技巧,掌握不同业务的数据存储在不同的数据集市里;不管他们的计算任务是提交给 数据库 还是 Hadoop,计算时间都可能会很长,不可能在线等待;所以,使用者提交了一个计算任务(PIG/SQL/Hive SQL),控制台告知任务已排队,给出大致的计算时间等友情提示, 这些作业的权重较低,使用者和管理员可以查看排队中的计算任务,包括已执行任务的执行时间、运行时长和运行结果;当计算任务有结果后,控制台界面有通知提示,或者发邮件提示,使用者可以在线查看和下载数据。
Presto 简化的架构如下图1所示,客户端将 SQL 查询发送到 Presto 的协调器。协调器会进行语法检查、分析和规划查询计划。调度器将执行的管道组合在一起,将任务分配给那些离数据最近的节点,然后监控执行过程。客户端从输 出段中将数据取出,这些数据是从更底层的处理段中依次取出的。
Presto 的运行模型与 Hive 有着本质的区别。Hive 将查询翻译成多阶段的 Map-Reduce 任务,一个接着一个地运行。 每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然 而 Presto 引擎没有使用 Map-Reduce。它使用了一个定制的查询执行引擎和响应操作符来支持SQL的语法。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不 同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的 时候就会将数据从一个处理段传入到下一个处理段。
这样的方式会大大的减少各种查询的端到端响应时间。
同时,Presto 设计了一个简单的数据存储抽象层,来满足在不同数据存储系统之上都可以使用 SQL 进行查询。存储连接器目前支持除 Hive/HDFS 外,还支持 HBase、Scribe 和定制开发的系统。

图1. Presto架构
- Oozie允许失败的工作流从任意点重新运行,这对于处理工作流中由于前一个耗时活动而出现瞬态错误的情况非常有用。
- 工作流执行过程可视化。
- 工作流的每一步的日志、错误信息都可以点击查看,并实时滚动,便于排查问题。

转载于:https://my.oschina.net/zhengyun/blog/359171
#数据技术选型#即席查询Shib+Presto,集群任务调度HUE+Oozie相关推荐
- 大数据江湖之即席查询与分析(上篇)--即席查询与分析的前世今生
如今,大数据领域新技术层出不穷,可谓百家争鸣,甚是红火.不乏有些玩家动辄搞出个大数据平台,可谓包罗万象,号称无所不能.小弟则以为在大数据江湖中如能修炼好独门绝技,有能拿得出手的看家本领已然实属不易.小 ...
- 大数据江湖之即席查询与分析(下篇)--手把手教你搭建即席查询与分析Demo
上篇小弟分享了几个"即席查询与分析"的典型案例,引起了不少共鸣,好多小伙伴迫不及待地追问我们:说好的"手把手教你搭建即席查询与分析Demo"啥时候能出?说到就得 ...
- 大数据的分布式SQL查询引擎 -- Presto的详细使用
Presto – Distributed SQL Query Engine for Big Data 官网 项目源码 官方文档 目录 1 Presto 概述 2 概念 2.1 服务进程 2.2 数据源 ...
- presto集群安装
presto集群安装 整合hive 张映 发表于 2019-11-07 分类目录: hadoop/spark/scala 标签:hive, presto Presto是一个运行在多台服务器上的分布式系 ...
- 大数据系列(一)之hadoop介绍及集群搭建
大数据系列(一)之hadoop介绍及集群搭建 文章最早发布来源,来源本人原创初版,同一个作者: https://mp.weixin.qq.com/s/fKuKRrpmHrKtxlCPY9rEYg 系列 ...
- 2021年大数据HBase(二):HBase集群安装操作
全网最详细的大数据HBase文章系列,强烈建议收藏加关注! 新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点. 目录 系列历史文章 前言 HBase集群安装操作 一.上传解压HBase安装包 ...
- 如何在本地数据中心安装Service Fabric for Windows集群
概述 首先本文只是对官方文档(中文,英文)的一个提炼,详细的安装说明还请仔细阅读官方文档. 虽然Service Fabric的官方名称往往被加上Azure,但是实际上(估计很多人不知道)Service ...
- java访问oracle集群,JAVA查询Oracle数据库集群连接字符串
下载必备最新排行装机分类.游戏手机驱动源码LinuxMac小游戏.商城招聘百科知道软件盒子论坛3G版 本站搜索 新闻资讯 软件下载 当前位置: 网站首页 > 编程开发 > 编程语言 > ...
- 【MySQL5.7版本单节点大数据量迁移到PXC8.0版本集群全记】
MySQL5.7版本单节点大数据量迁移到PXC8.0版本集群全记录-1 - likingzi - 博客园 MySQL5.7版本单节点大数据量迁移到PXC8.0版本集群全记录-2 - likingzi ...
最新文章
- 邮箱的创建及配置:Exchange2003系列之二
- 【小米校招笔试】一个数组是由有序数组经过n次循环移动后所得,请你用最快速度查找某个元素位置
- 寺庙的纪律性也让我颇有感触
- python测网络连通性_网络工程师如何在ensp模拟器上玩python自动化配置交换机。...
- MySql的备份与恢复
- python后台架构Django教程——templates模板
- python人口普查数据数据分析_Python:第六次全国人口普查数据分析及可视化(pandas、matplotlib)...
- 世界杯为战斗民族的历史再添荣耀与光辉_数字体验_新浪博客
- 百度与谷歌地图坐标转换
- 电脑计算机无法搜索文件,电脑中的文件搜索功能出错怎么办?电脑无法搜索出实际存在的文件如何解决...
- EChart案例-折线面积渐变色
- 农夫山泉病毒性营销方案策划
- gromacs ngmx_GROMACS使用教程要点
- 传销?花生日记罚款7456万元这个微信社群营销分钱模式要知道
- 20220905 buffer overflow detected
- [Unity3D]Unity3D游戏开发之鼠标旋转、缩放实现3D物品展示
- html5 横向溢出隐藏,溢出:隐藏的HTML5视频
- corsswalk的研究和使用(一)
- 【 MATLAB 】poly 函数介绍
- FND_GLOBAL.CONC_REQUEST_ID = -1
热门文章
- 唤起手机qq、微信方法
- 亲子拍拍v1.2.1官方iPhone版
- 百度云管家下载大文件速度慢的解决办法
- 【郝斌老师数据结构学习笔记 day 3】
- html5网页中加入播放器,10款jquery+html5实现的网页播放器
- 【智能优化算法】基于自适应策略的混合鲸鱼优化算法求解单目标优化问题附matlab代码
- 女生节中奖名单~快来写地址
- GNSS数据下载网站整理,包括gamit、bernese更新文件地址[2021.08更新]
- arduino架子鼓_极客DIY:利用Arduino制作电子鼓
- 求知讲堂python+人工智能 99天完整版 学完可就业+某某教程Python 100例————作业(持续更新)