21分钟教会你分析MaxCompute账单
为什么80%的码农都做不了架构师?>>> 
21分钟教会你分析MaxCompute账单
背景
阿里云大计算服务MaxCompute是一款商业化的大数据分析平台,其计算资源有预付费和后付费两种计费方式。并且产品每天按照project为维度进行计量计费(账单基本情况下会第二天6点前产出)。本文使用的为云上客户真实数据,故在下文中的截图都mask掉了。
关于MaxCompute计量计费说明,详见官方文档:

但是通常情况下,我们在数据开发阶段或者在上线前夕会发下账单有波动(通常情况下为增大), 其实用户首先可以通过自助的方式来分析账单波动情况,再倒逼自己的作业进行优化。阿里云费用中心就是一个很好的通道,阿里云所有商业化收费的产品都可以在其中下载费用明细。
获取账单信息
通常您需要使用主账号查看账单详情。如果您需要使用子账号查看账单信息,请首先参考费用中心RAM配置策略行子账号授权。
step1:使用主账号或者被授权的RAM子账号来登录阿里云管控台。
step2:右上角进入费用中心。

step3:在费用中心-消费记录-消费明细中,选择产品和账单日期。
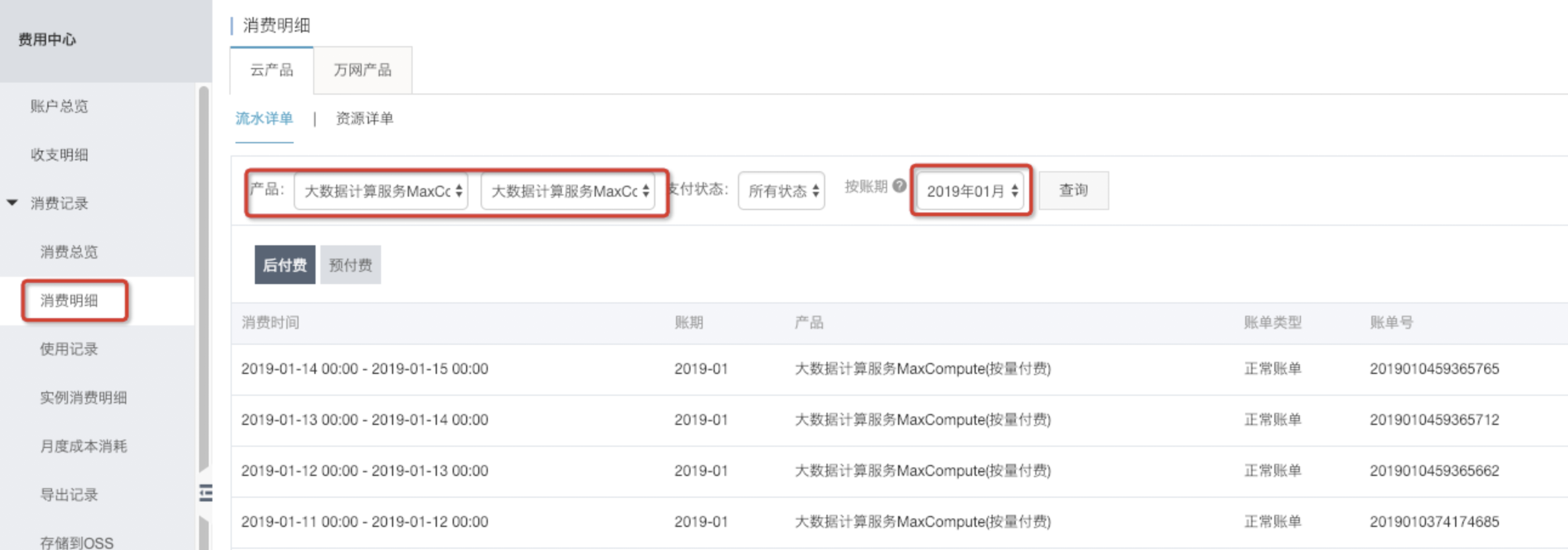
包年包月中的 后付费是指项目开通包年包月计算计费模式后,还产生的存储、下载对应的费用(存储、下载费用只有后付费)。
step4:为了方便批量分析数据,我们选择下载使用记录csv文件在本地分析。
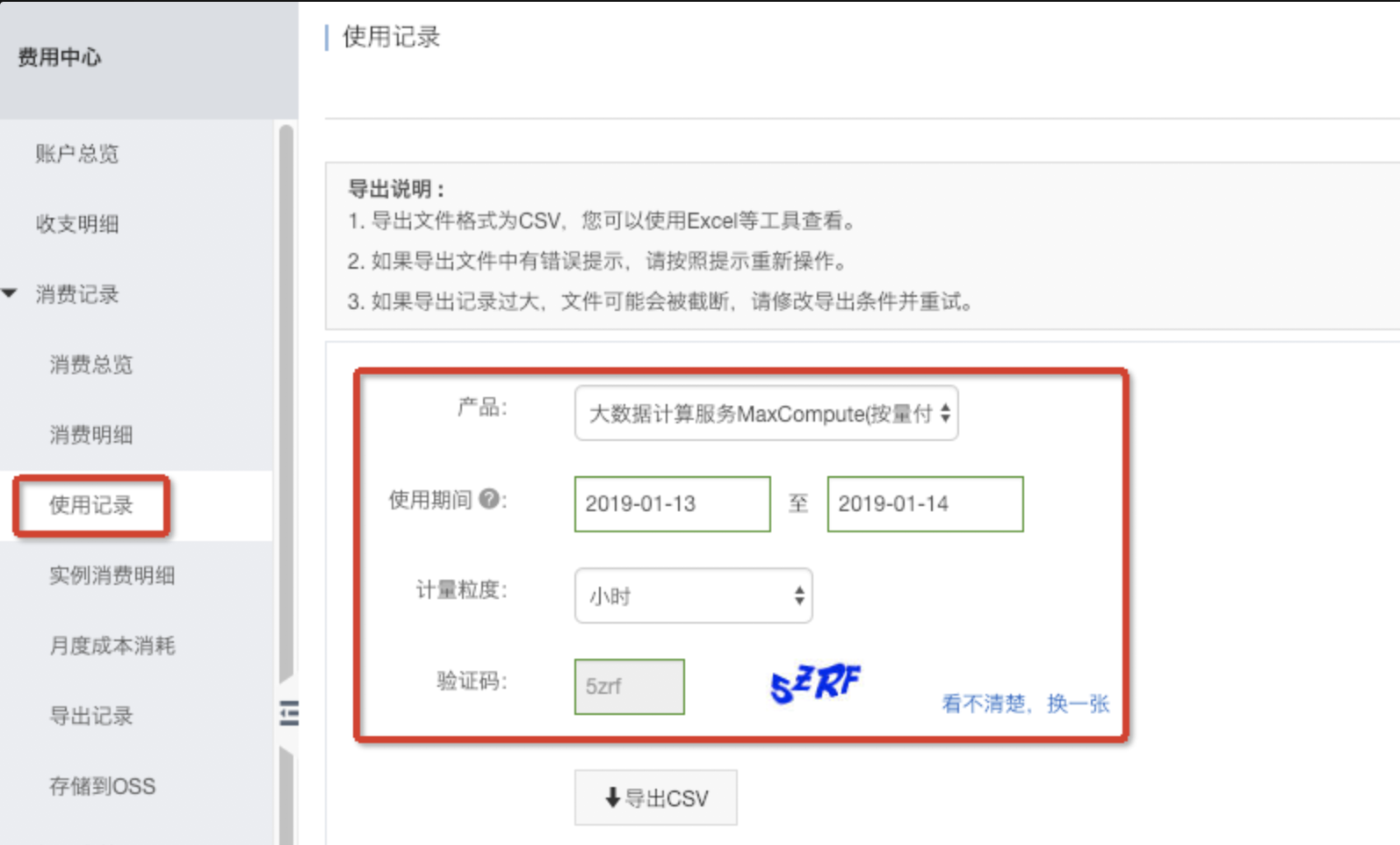
下载csv文件如下,可以在本地打开进行分析。

--csv的表头
项目编号,计量信息编号,数据分类,存储(Byte),SQL 读取量(Byte),SQL 复杂度(Byte),公网上行流量(Byte),公网下行流量(Byte),MR 作业计算,开始时间,结束时间,SQL读取量_访问OTS(Byte),SQL读取量_访问OSS(Byte)上传账单明细至MaxCompute
使用记录明细字段解释:
- 项目编号:当前账号下或子账号对应的主账号的MaxCompute project列表。
- 计量信息编号:其中会包含存储、计算、上传和下载的计费信息编号,SQL为instanceid,上传和下载为Tunnel sessionid。
- 数据分类:Storage(存储)、ComputationSql(计算)、UploadIn(内网上传)、UploadEx(外网上传)、DownloadIn(内网下载)、DownloadEx(外网下载)。按照计费规则其中只有红色为实际计费项目。
- 开始时间/结束时间:按照实际作业执行时间进行计量,只有Storage是按照每个小时取一次数据。
- 存储(Byte):每小时读取的存储量单位为Byte。
- SQL 读取量(Byte):SQL计算项,每一次SQL执行时SQL的input数据量,单位为Byte。
- SQL 复杂度(Byte):每次执行SQL的复杂度,为SQL计费因子之一。
- 公网上行流量(Byte),公网下行流量(Byte):分别为公网上传和下载的数据量,单位Byte。
- MR作业计算(CoreSecond):MR作业的计算时单位为coresecond,需要转换为计算时hour。
- SQL读取量_访问OTS(Byte),SQL读取量_访问OSS(Byte):外部表实施收费后的读取数据量,单位Byte。
① 确认CSV文件数据,尤其是列分隔符等(推荐使用UE)。

数据以逗号分隔,且单元格值都带有双引号。
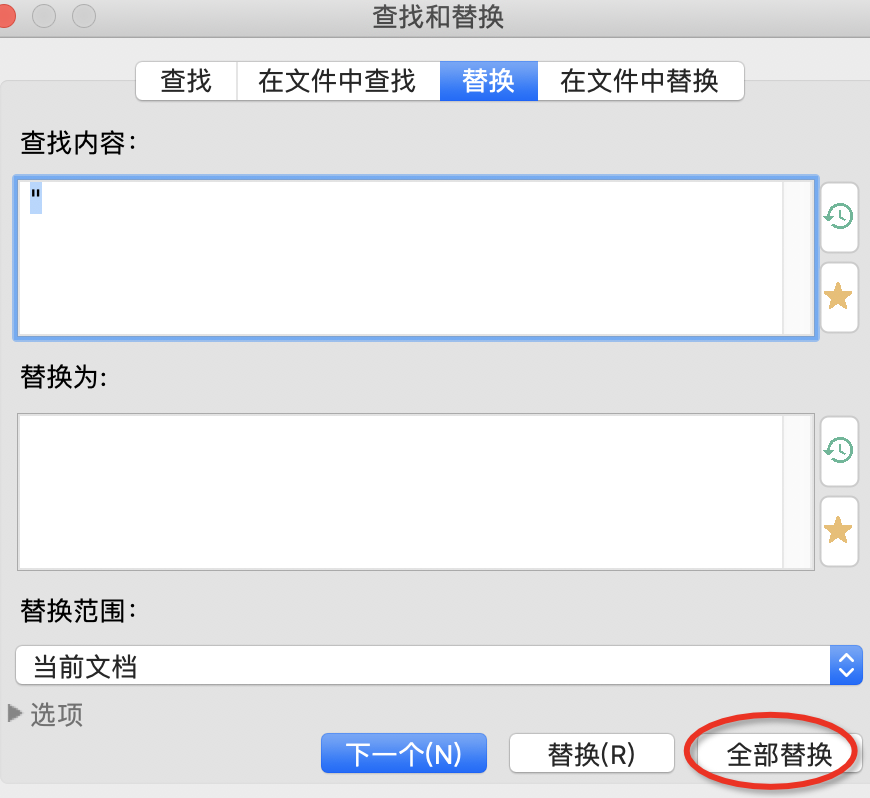
② 数据预处理:替换掉文档所有双引号,以方便使用Tunnel等上传工具。
替换为不用填写。直接点击全部替换。
③ 创建MaxCompute表,存储下载的消费明细。
DROP TABLE IF EXISTS maxcomputefee ;CREATE TABLE IF NOT EXISTS maxcomputefee
(projectid STRING COMMENT '项目编号',feeid STRING COMMENT '计费信息编号',type STRING COMMENT '数据分类,包括Storage、ComputationSQL、DownloadEx等',starttime DATETIME COMMENT '开始时间',storage BIGINT COMMENT '存储量',endtime DATETIME COMMENT '结束时间',computationsqlinput BIGINT COMMENT '输入数据量',computationsqlcomplexity DOUBLE COMMENT 'sql复杂度',uploadex BIGINT COMMENT '公网上行流量Byte',download BIGINT COMMENT '公网下行流量Byte',cu_usage DOUBLE COMMENT 'MR计算时*second',input_ots BIGINT COMMENT '访问OTS的数据输入量',input_oss BIGINT COMMENT '访问OSS的数据输入量'
)
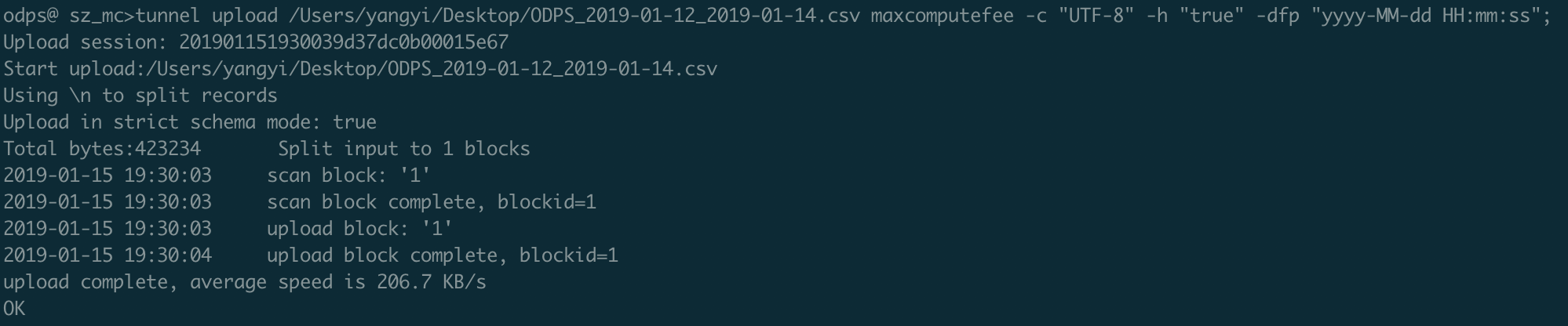
;④ Tunnel上传数据,具体Tunnel的配置详见官方文档。
odps@ sz_mc>tunnel upload /Users/yangyi/Desktop/ODPS_2019-01-12_2019-01-14.csv maxcomputefee -c "UTF-8" -h "true" -dfp "yyyy-MM-dd HH:mm:ss";
当然用户也可以通过DataWorks数据导入的功能来进行,具体详见操作步骤。
⑤ 验证数据。

通过SQL分析账单数据
1、分析SQL费用
云上客户使用MaxCompute,95%的用户通过SQL即可满足需求,SQL也在消费成长中占据了绝大部分。
SQL费用=一次SQL计算费用 = 计算输入数据量 SQL复杂度 0.3元/GB
--分析SQL消费,按照SQL进行排行
SELECT to_char(endtime,'yyyymmdd') as ds,feeid as instanceid,projectid,computationsqlcomplexity --复杂度,SUM((computationsqlinput / 1024 / 1024 / 1024)) as computationsqlinput --数据输入量GB,SUM((computationsqlinput / 1024 / 1024 / 1024)) * computationsqlcomplexity * 0.3 AS sqlmoney
FROM maxcomputefee
WHERE TYPE = 'ComputationSql'
AND to_char(endtime,'yyyymmdd') >= '20190112'
GROUP BY to_char(endtime,'yyyymmdd'),feeid,projectid,computationsqlcomplexity
ORDER BY sqlmoney DESC
LIMIT 10000
;--查询结果--
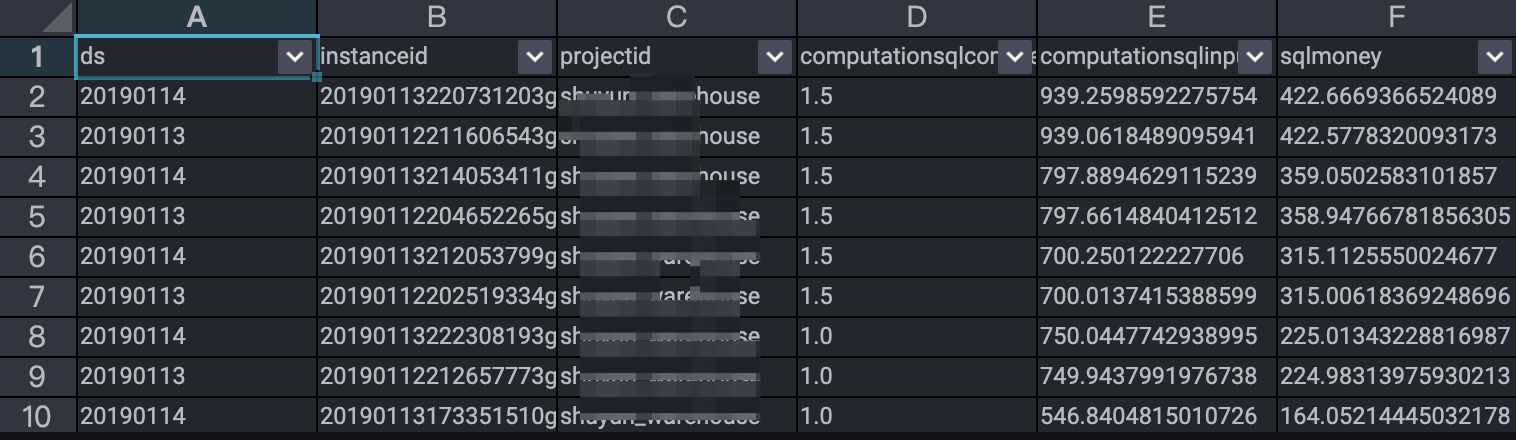
根据此段SQL执行结果可以得到如下结论:
- 大作业可以优化的点:**是否可以减小数据读取量、降低复杂度来优化费用成本。
- 也可以按照ds字段(按照天)进行汇总,分析某个时间段内的SQL消费金额走势。比如利用本地excle或云上QuickBI等工具绘制折线图等方式,更直观的反应作业的趋势。
- 拿到具体的instanceid,在console或者DataWorks脚本中进行
wait instanceid;查看具体作业和SQL。

随即在浏览器中打开logview的url地址(关于logview的介绍详见官方文档):
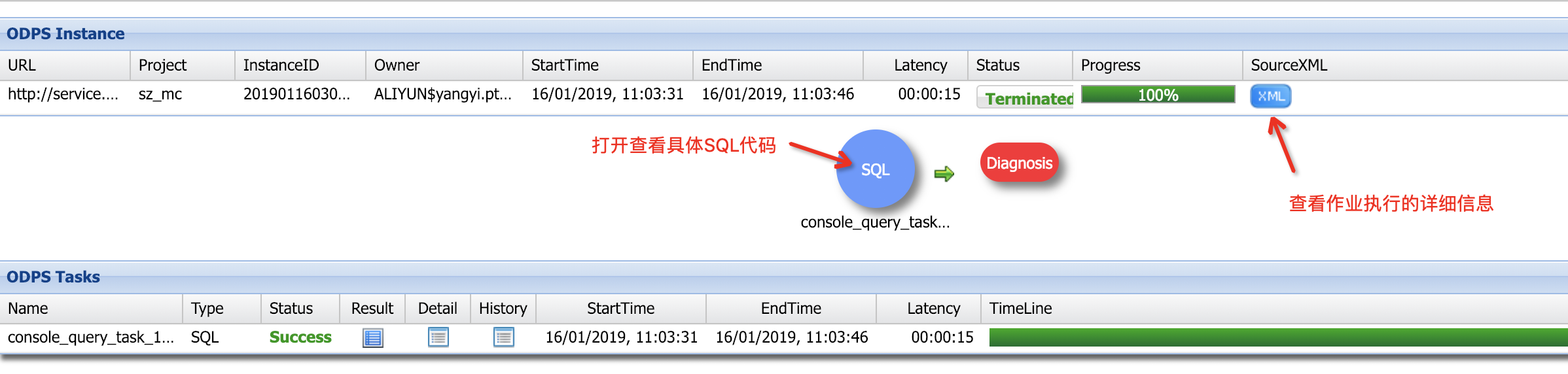
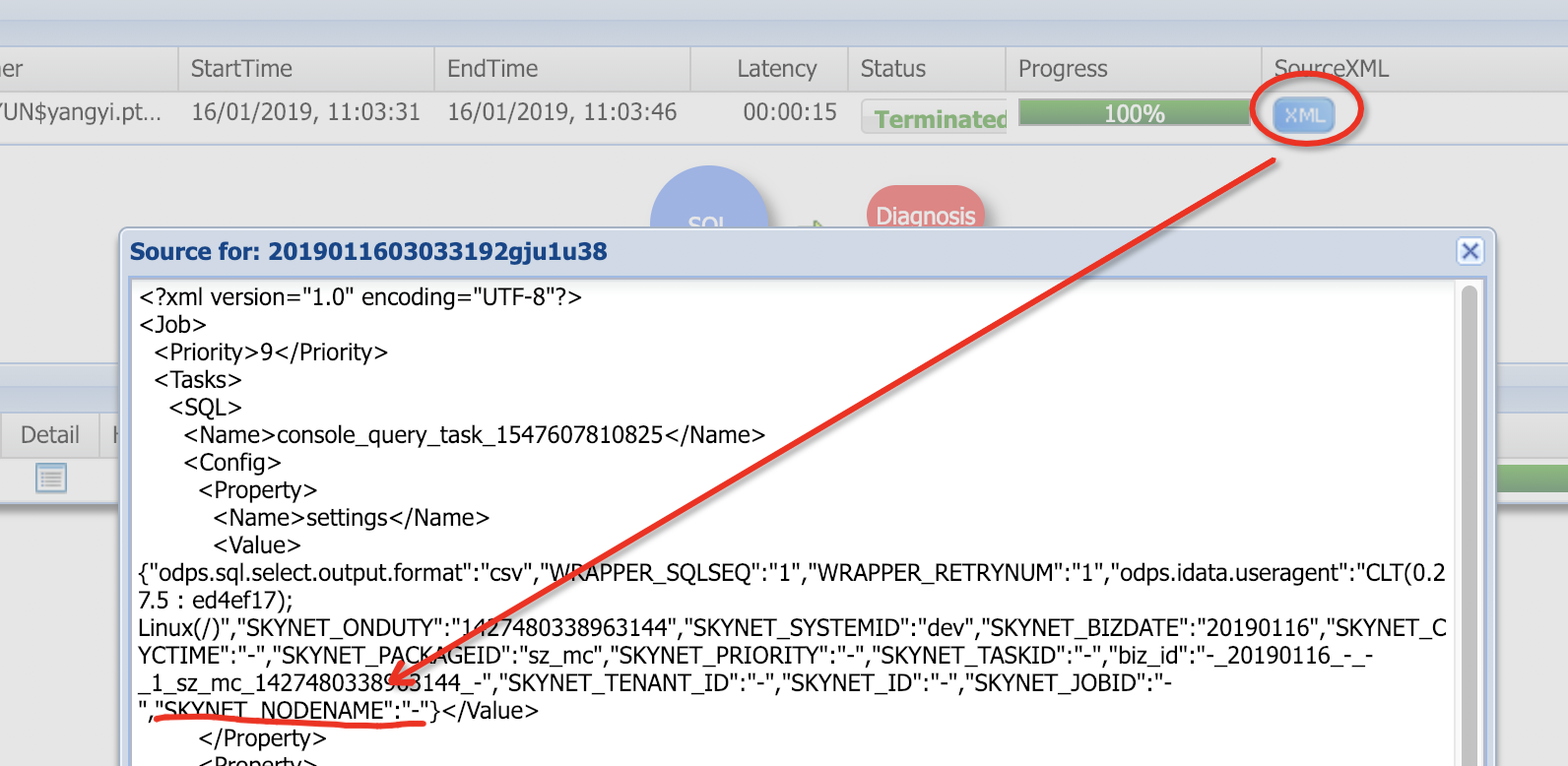
从logview中获取DataWorks节点名称:
在logview中打开SourceXML可以查看到具体执行信息,如SKYNET_NODENAME表示DataWorks的节点名称(当然只有被调度系统执行的作业才有值,临时查询为空,如下图所示)。拿到节点名称可以快速的在DataWorks找到该节点进行优化或查看责任人。
2、分析作业增长趋势
一般情况下费用的增长背后其实是作业量的暴涨,可能是重复执行,也可能是调度属性配置的不是很合理。
--分析作业增长趋势
SELECT TO_CHAR(endtime,'yyyymmdd') AS ds,projectid,COUNT(*) AS tasknum
FROM maxcomputefee
WHERE TYPE = 'ComputationSql'
AND TO_CHAR(endtime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(endtime,'yyyymmdd'),projectid
ORDER BY tasknum DESC
LIMIT 10000
;--执行结果--
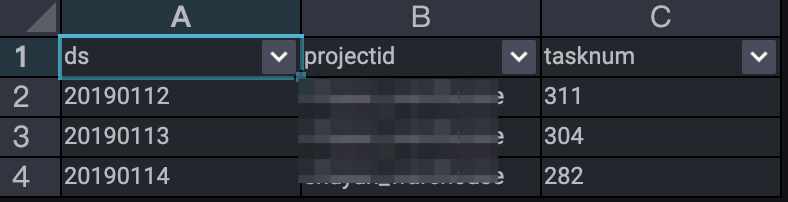
从执行结果可以看出来12-14日提交到MaxCompute且执行成功的作业数的波动趋势。
3、分析存储费用
存储费用的计费规则相对来说比较复杂,因为下载到的明细是每个小时取一次数据。按照MaxCompute存储计费规则,会整体24小时求和然后平均之后的值再阶梯收费。具体详见官网。
--分析存储费用
SELECT t.ds,t.projectid,t.storage,CASE WHEN t.storage < 0.5 THEN 0.01WHEN t.storage >= 0.5 AND t.storage <= 100 THEN t.storage*0.0192WHEN t.storage > 100 AND t.storage <= 1024 THEN (100*0.0192+(t.storage-100)*0.0096)WHEN t.storage > 1024 AND t.storage <= 10240 THEN (100*0.0192+(1024-100)*0.0096+(t.storage-1024)*0.0084)WHEN t.storage > 10240 AND t.storage <= 102400 THEN (100*0.0192+(1024-100)*0.0096+(10240-1024)*0.0084+(t.storage-10240)*0.0072)WHEN t.storage > 102400 AND t.storage <= 1048576 THEN (100*0.0192+(1024-100)*0.0096+(10240-1024)*0.0084+(102400-10240)*0.0072+(t.storage-102400)*0.006) END storage_fee
FROM (SELECT to_char(starttime,'yyyymmdd') as ds,projectid,SUM(storage/1024/1024/1024)/24 AS storageFROM maxcomputefeeWHERE TYPE = 'Storage'and to_char(starttime,'yyyymmdd') >= '20190112'GROUP BY to_char(starttime,'yyyymmdd'),projectid) t
ORDER BY storage_fee DESC
;--执行结果--

根据计算结果可以分析得出结论:
- 存储在13日为最高有一个增长的过程,但是在14日是有降低。
- 存储优化,建议表设置生命周期,删除长期不使用的临时表等。
4、分析下载费用
对于公网或者跨Region的数据下载,MaxCompute将按照下载的数据大小进行计费。计费公式为:一次下载费用=下载数据量*0.8元/GB。
--分析下载消费明细
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,projectid,SUM((download/1024/1024/1024)*0.8) AS download_fee
FROM maxcomputefee
WHERE type = 'DownloadEx'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd'),projectid
ORDER BY download_fee DESC
;按照执行结果也可以分析出某个时间段内的下载费用走势。另外可以通过tunnel show history查看具体历史信息,具体命令详见官方文档。

以下几种计算作业与SQL类似,按照官方计费文档编写SQL即可。
5、分析MapReduce作业消费
MR任务当日计算费用=当日总计算时*0.46元
--分析MR作业消费
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,projectid,(cu_usage/3600)*0.46 AS mr_fee
FROM maxcomputefee
WHERE type = 'MapReduce'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd'),projectid,cu_usage
ORDER BY mr_fee DESC
;6、分析外部表作业(OTS和OSS)
SQL外部表功能计费规则:一次SQL计算费用=计算输入数据量SQL复杂度0.03元/GB
--分析OTS外部表SQL作业消费
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,projectid,(input_ots/1024/1024/1024)*1*0.03 AS ots_fee
FROM maxcomputefee
WHERE type = 'ComputationSql'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd'),projectid,input_ots
ORDER BY ots_fee DESC
;--分析OSS外部表SQL作业消费
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,projectid,(input_oss/1024/1024/1024)*1*0.03 AS ots_fee
FROM maxcomputefee
WHERE type = 'ComputationSql'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd'),projectid,input_oss
ORDER BY ots_fee DESC
;总结
MaxCompute产品消费的增长(暴涨)往往背后都是由于作业量的大幅度提升,要优化自己的费用成本,首选要知道自己SQL等作业中存在什么问题,要优化具体哪一个SQL。本文期望能够给予大家一些帮助。更多关于费用成本优化的文章可以详见,云栖社区《帮助企业做好MaxCompute大数据平台成本优化的最佳实践》和《众安保险如果优化自己的MaxCompute费用成本实践》。
作者: 祎休
原文链接
本文为云栖社区原创内容,未经允许不得转载。
转载于:https://my.oschina.net/yunqi/blog/3005076
21分钟教会你分析MaxCompute账单相关推荐
- 授之以鱼不如授之以渔!五分钟教会您手工查杀***!
授之以鱼不如授之以渔!五分钟教会您手工查杀***! 经常看到有人求助- 为什么我的主页被改了,死活改不回来呀? 这个进程是不是正常进程呀? 这个程序是什么程序呀?为什么死活杀不掉呢? ....... ...
- 10分钟教会你看眼图,太有用了!!
10分钟教会你看眼图,太有用了!!-面包板社区 ●搜寻了不少资料,如果追溯历史,大约47年前,眼图就已经开始广泛应用.在1962年-2002的40年间,眼图的测量方法是基于采样示波器的传统方法,200 ...
- iOS--3分钟教会你用mathjax显示数学公式
iOS–3分钟教会你用mathjax显示数学公式 最近开发数学教程,需要显示数学公式和图形,找了很多资料,找到2种方法,1.服务器返回Latex的字符串 我在客户端用webView来展示与交互,但是有 ...
- 怎样在表格中选出同一类_3分钟教会你如何将不同表格中的数据关联在一起
原标题: 3分钟教会你如何将不同表格中的数据关联在一起 版权声明:本文为博主原创文章,未经博主允许不得转载. 智能输入 超级表格 微视频 关键词: 智能输入 关联不同表格 逻辑输入 「超级表格微视频」 ...
- Mysql学习总结(12)——21分钟Mysql入门教程
21分钟 MySQL 入门教程 目录 一.MySQL的相关概念介绍 二.Windows下MySQL的配置 配置步骤 MySQL服务的启动.停止与卸载 三.MySQL脚本的基本组成 四.MySQL中的数 ...
- 华为手机充满有提醒吗_2020手机充电速度排名:最快21分钟充满,华为第15名
5G手机扎堆出现,中国5G基站数量也是不断增多,中国移动曾经表态,2020年底将会在全国地级市覆盖5G网络,全民5G时代终于到来!从目前国内手机出货量数据来看,5G手机占比已经达到了六成以上,国产5G ...
- 十分钟教会你原生JS压缩图片,极其精简版
十分钟教会你原生JS压缩图片,极其精简版 原文链接:https://blog.csdn.net/yasha97/article/details/83629510 (一)实现思路 先通过input标签获 ...
- 10分钟教会你Apache Shiro
前言 欢迎来到Apache Shiro 10分钟之旅! 希望通过这个简单.快速的示例,可以让你对应用程序中使用Shiro有个深入的了解.嗯,10分钟你应该可以搞定它. 概述 Apache Shiro是 ...
- 计算机系统如何重置,如何重置电脑系统?看这里1分钟教会你!
原标题:如何重置电脑系统?看这里1分钟教会你! 哈喽,大家好我是小黑~最近后台有小伙伴留言咨询#如何重置Windows 10系统?#. 重置系统是Windows系统自带的功能,此功能会将错误的系统文件 ...
最新文章
- win10系统 ubuntu子系统 进行ndk编译笔记
- 初识mysql学习笔记
- 【iOS开发】跳转到『设置App』的任意条目
- 基于指数平滑对心电信号进行PQRST模拟(第二种方案)
- 论调用约定__stdcall,__cdecl,__fastcall,thiscall,naked call
- Mybatis(19)注解实现多表查询
- 多态(Polymoph)
- python12306买票_Python 使用 selenium 实现半自动购买12306火车票
- Caused by: org.elasticsearch.action.search.SearchPhaseExecutionException报错解决
- MongoDB SpringDataMongoDB 查询指南简介
- 挂载并修改img镜像的分区文件
- python中得到26个字母
- 计算机网络- Internet是如何工作的
- JATG篇(1)——FT2232H入门
- 2022-2027年中国海洋油气开采行业市场全景评估及发展战略规划报告
- 现有4个列表,分别存放着学生的学号、语文 成绩、数学成绩、英语成绩。内容分别为:list1=[1.2.3,4],list2=[98,67.89.80],list3=[100.90.83]输入学号取值
- 【数据结构】无向图(构造+遍历)
- 自适应控制——仿真实验二 用Narendra方案设计模型参考自适应系统
- 数学会对计算机编程的关系
- 解决Navicat连接mysql闪退问题