热度php代码,爬取知乎热度搜索标题并数据分析及可视化(示例代码)
一、主题式网络爬虫设计方案
1、主题式网络爬虫名称:爬取知乎热度数据并数据分析及可视化
2、爬取的内容:知乎热搜的标题、排行、热度
数据特征:随机、以文字和数字为主
3、实现思路:首先查看所要爬取页面的源代码,找到所需要爬取的数据在源代码中的位置,接下来进行数据爬取,并将爬取的数据持久化,保存在excel表格中用于使用,接下来对数据进行清洗处理,并进行数据分析额可视化
技术难点:正则表达式、回归方程
二、主题页面的结构特征分析
1、主题页面的结构和特征分析:所要爬取的热度数据在标签‘td’里面,标题在标签‘ .... ’里面
2、页面解析:


三、
1、数据爬取与采集
importrequestsimportreimportpandas as pdimportopenpyxlimportmatplotlibimportmatplotlib.pyplot as pltimportnumpy as npimportseaborn as snsfrom sklearn.linear_model importLinearRegression
url= ‘https://tophub.today/n/mproPpoq6O‘header= {‘user-agent‘:‘Mozilla/5.0‘}
r= requests.get(url, headers=header)
r.raise_for_status()
r.encoding=r.apparent_encoding
r.text
html=r.text
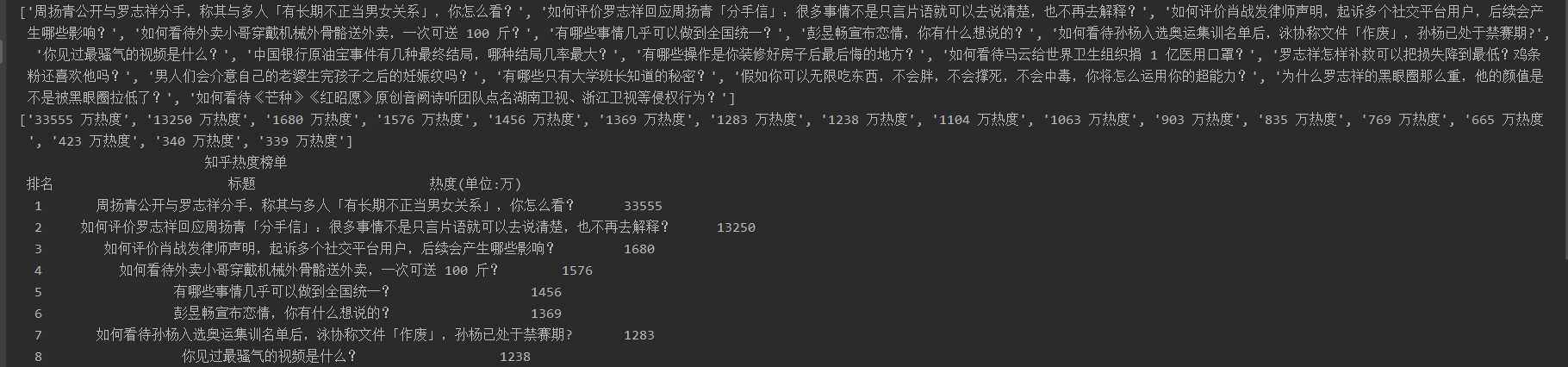
title= re.findall(‘(.*?)‘,html)[3:20]
redu= re.findall(‘
(.*?)‘,html)[0:17]print(title)print(redu)print(‘{:^55}‘.format(‘知乎热度榜单‘))print(‘{:^5}{:^40}{:^10}‘.format(‘排名‘,‘标题‘,‘热度(单位:万)‘))
num= 8lst=[]for i inrange(num):print(‘{:^5}{:^40}{:^10}‘.format(i+1, title[i], redu[i][:-3]))
lst.append([i+1, title[i], redu[i][:-3]])
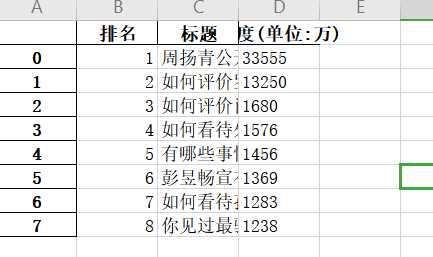
df= pd.DataFrame(lst, columns=[‘排名‘,‘标题‘,‘热度(单位:万)‘])
df.to_excel(‘知乎热度榜.xlsx‘)
2、对数据进行清洗和处理
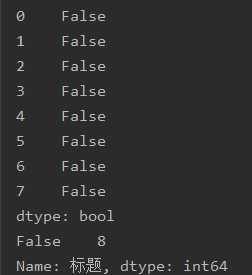
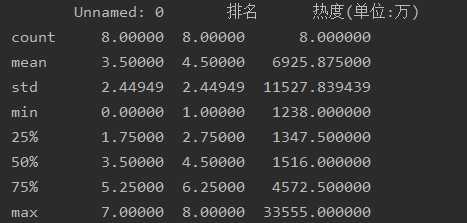
df = pd.DataFrame(pd.read_excel(‘知乎热度榜.xlsx‘))print(df.head())print(df.duplicated())print(df[‘标题‘].isnull().value_counts())print(df[‘热度(单位:万)‘].isnull().value_counts())print(df.describe())


3、数据分析与可视化
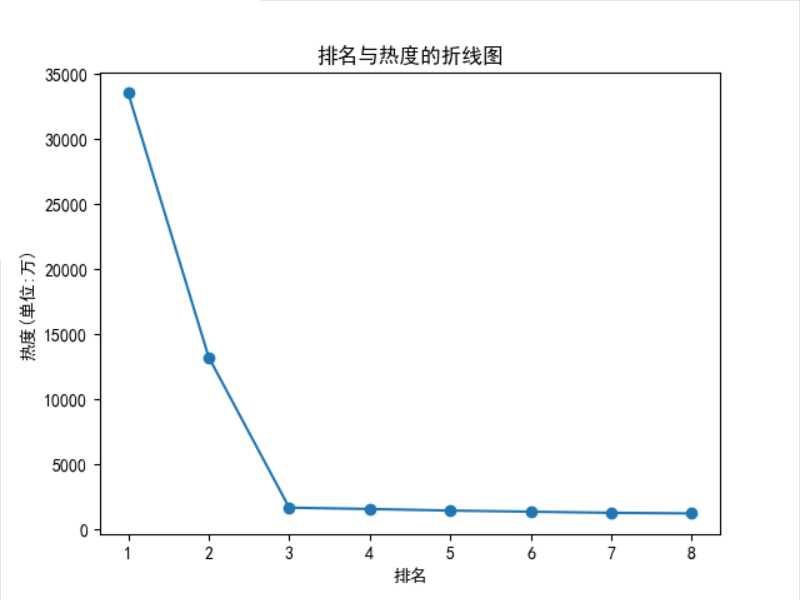
defzhexian():
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
x= df[‘排名‘]
y= df[‘热度(单位:万)‘]
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.plot(x,y)
plt.scatter(x,y)
plt.title(‘排名与热度的折线图‘)
plt.show()
zhexian()
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
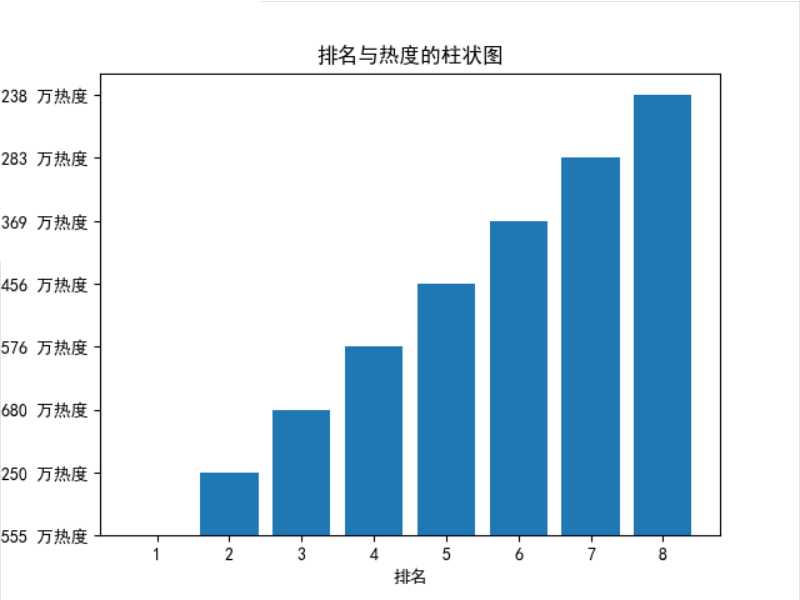
plt.bar(range(1,9),redu[:8])
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.title(‘排名与热度的柱状图‘)
plt.show()
4、回归方程
df = pd.read_excel(‘知乎热度榜.xlsx‘)
df.head(8)
X= df.drop(‘标题‘,axis=1)
predict_model=LinearRegression()
predict_model.fit(X, df[‘热度(单位:万)‘])print(‘回归系数:‘,predict_model.coef_)

5、数据持久化
df = pd.DataFrame(lst, columns=[‘排名‘,‘标题‘,‘热度(单位:万)‘])
df.to_excel(‘知乎热度榜.xlsx‘)
6、代码汇总
importrequestsimportreimportpandas as pdimportopenpyxlimportmatplotlibimportmatplotlib.pyplot as pltimportnumpy as npimportseaborn as snsfrom sklearn.linear_model importLinearRegression
url= ‘https://tophub.today/n/mproPpoq6O‘header= {‘user-agent‘:‘Mozilla/5.0‘}
r= requests.get(url, headers=header)
r.raise_for_status()
r.encoding=r.apparent_encoding
r.text
html=r.text
title= re.findall(‘(.*?)‘,html)[3:20]
redu= re.findall(‘
(.*?)‘,html)[0:17]print(title)print(redu)print(‘{:^55}‘.format(‘知乎热度榜单‘))print(‘{:^5}{:^40}{:^10}‘.format(‘排名‘,‘标题‘,‘热度(单位:万)‘))
num= 8lst=[]for i inrange(num):print(‘{:^5}{:^40}{:^10}‘.format(i+1, title[i], redu[i][:-3]))
lst.append([i+1, title[i], redu[i][:-3]])
df= pd.DataFrame(lst, columns=[‘排名‘,‘标题‘,‘热度(单位:万)‘])
df.to_excel(‘知乎热度榜.xlsx‘)
df= pd.DataFrame(pd.read_excel(‘知乎热度榜.xlsx‘))print(df.head())print(df.duplicated())print(df[‘标题‘].isnull().value_counts())print(df[‘热度(单位:万)‘].isnull().value_counts())print(df.describe())defzhexian():
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
x= df[‘排名‘]
y= df[‘热度(单位:万)‘]
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.plot(x,y)
plt.scatter(x,y)
plt.title(‘排名与热度的折线图‘)
plt.show()
zhexian()
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
plt.bar(range(1,9),redu[:8])
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.title(‘排名与热度的柱状图‘)
plt.show()
df= pd.read_excel(‘知乎热度榜.xlsx‘)
df.head(8)
X= df.drop(‘标题‘,axis=1)
predict_model=LinearRegression()
predict_model.fit(X, df[‘热度(单位:万)‘])print(‘回归系数:‘,predict_model.coef_)
四、结论
1、经过对知乎今日的热度标题进行爬取,今日第一和第二名的标题较为受关注,后面的标题较为平稳,相差不大
2、本次的程序设计的任务我完成的时间花了较长,遇到了挺多问题,但是经过百度搜索等等,最后将问题一步步解决,使得我对python更加的感兴趣了,完成任务之后非常的有成就感,正则表达式还不是很会,回归方程也遇到了问题,接下来的学习里,我会更加努力学习计算机这门课程。
热度php代码,爬取知乎热度搜索标题并数据分析及可视化(示例代码)相关推荐
- 60行代码爬取知乎“神回复”,句句戳中泪点
作者 | shenzhongqiang 转载自Python与数据分析(ID:PythonML) 之前的一篇文章<爬了下知乎神回复,笑死人了~>发布后,引发了大家热烈的反响.很多朋友觉得很神 ...
- 如何用 60 行代码爬取知乎神回复?
作者 | 强哥 责编 | 郭芮 知乎上经常会有很多令人忍俊不禁的神回复,初看之下拍案叫绝,细思之下更是回味无穷.本文就来介绍下如何爬取知乎的神回复,揭晓其背后的原理. 知乎神回复都有些什么特点呢?我们 ...
- 60行代码爬取知乎神回复
之前的一篇文章 爬了下知乎神回复,笑死人了~ 发布后,引发了大家热烈的反响.很多朋友觉得很神奇,在后台问是怎么做到的,有的朋友还表示不太相信.其实爬取知乎神回复很简单,这篇文章我们就来揭晓一下背后的原 ...
- 60行代码爬取知乎神回复,笑到停不下来
前言:本人加入了一个不错的企鹅群,文章灵感来源也是那里,883872094群资料可以自取 爬取知乎回答 第一步我们爬取知乎上的回答.知乎上的回答太多了,一下子爬取所有的回答会很费时,我们可以选定几个话 ...
- 60 行代码爬取知乎神回复,笑的停不下来
(给程序员的那些事加星标) 转自:Python与数据分析,作者:shenzhongqiang 爬取知乎神回复很简单,这篇文章我们就来揭晓一下背后的原理. 知乎神回复都有些什么特点呢?我们先来观察一下 ...
- python xpath爬取新闻标题_爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接. 环境和方法:ubantu16.04.python3.requests.xpath 1.用浏览器打开知乎,并登录 2.获取cookie和User-Agen ...
- 【没落的985/211】Python爬取知乎8万字回答进行高校分析
↑ 点击上方 "一行数据" 关注 + 星标 ~ 每周送书,绝不错过 最近知乎一个"有哪些较原来没落的985/211院校?"的问题引起了很多人的关注,回答者各种分 ...
- Python爬虫利用18行代码爬取虎牙上百张小姐姐图片
Python爬虫利用18行代码爬取虎牙上百张小姐姐图片 下面开始上代码 需要用到的库 import request #页面请求 import time #用于时间延迟 import re #正则表达式 ...
- Python爬取知乎“神回复”,笑得根本停不下来(附代码)
来源:Python与数据分析 本文约4600字,建议阅读10+分钟. 本文介绍如何爬取知乎的神回复,为你揭晓其背后的原理. 知乎上经常会有很多令人忍俊不禁的神回复,初看之下拍案叫绝,细思之下更是回味无 ...
- 爬取知网博硕士文献及中国专利存到mysql数据库中的代码及其注意事项
今天因为需要做了一个爬取知网博硕士论文及中国专利的爬虫,在制作的过程中遇到了不少坑,在网上查资料时都是很老的资源,在现在知网的反爬虫下不起作用,所以我来写这篇文章来供大家参考.(这篇文章主要介绍通过改 ...
最新文章
- JupyterNotebook随记(part2)--更改JupyterNotebook主题
- micropython web ws2812_MicroPython实例之TPYBoard v102炫彩跑马灯WS2812B
- Go 语言里怎么正确实现枚举?答案藏着官方的源码里
- 前后端交互之封装Ajax+SpringMVC源码分析
- HDU2089 不要62【数位DP+记忆化搜索】
- qt 进度栏_HTML5进度栏
- 【生活智慧】001.追求实在的东西
- 优云automation实践技巧:简单4步完成自动化构建与发布
- 服务认证的介绍-实施依据及作用
- win10系统许可证即将过期的解决方法
- 苹果笔记本如何安装windows系统
- 面试官:说说你对双向绑定的理解?
- Gitlab+Docker构建流水线部署
- 【优化】--Squid优化汇总
- Android混淆——混淆代码总结
- 【Latex】Jupyter/Markdown/Latex快速编辑高大上数学公式/常见希腊字母
- Linux哪个命令显示文件内容,显示文件内容的Linux命令有哪些?Linux培训
- python气泡图画_Python使用Plotly绘图工具,绘制气泡图
- java微信模板消息接口的使用
- Vcenter Server 7 分配许可证