TableStore: 海量结构化数据分层存储方案
2019独角兽企业重金招聘Python工程师标准>>> 
前言
表格存储是阿里云自研分布式存储系统,可以用来存储海量结构化、半结构化的数据。表格存储支持高性能和容量型两种实例类型。高性能使用SSD的存储介质,针对读多写多的场景都有较好的访问延时。容量型使用的是SSD和SATA混合的存储介质。对写多的场景,性能接近高性能,读方面,如果遇到冷数据产生读SATA盘的话,延时会比高性能上涨一个量级。在海量数据存储场景下,例如时序场景,我们会希望最新的数据可以支持高性能查询,较早的数据的读写频次都会低很多。这时候一个基于表格存储高性能和容量型存储分层的需求就产生了。
方案细节
表格存储近期对外正式发布的全增量一体的通道服务,通道服务基于表格存储数据接口之上的全增量一体化服务。通道服务为用户提供了增量、全量、增量加全量三种类型的分布式数据实时消费通道。有了通道服务,我们可以很方便的构建从高性能实例下的表到容量型表之间的实时数据同步,进而可以在高性能表上使用表格存储的特性数据生命周期,根据业务需求设置一个合理的TTL。
总体来说就可以构建一个如下图所示的架构:
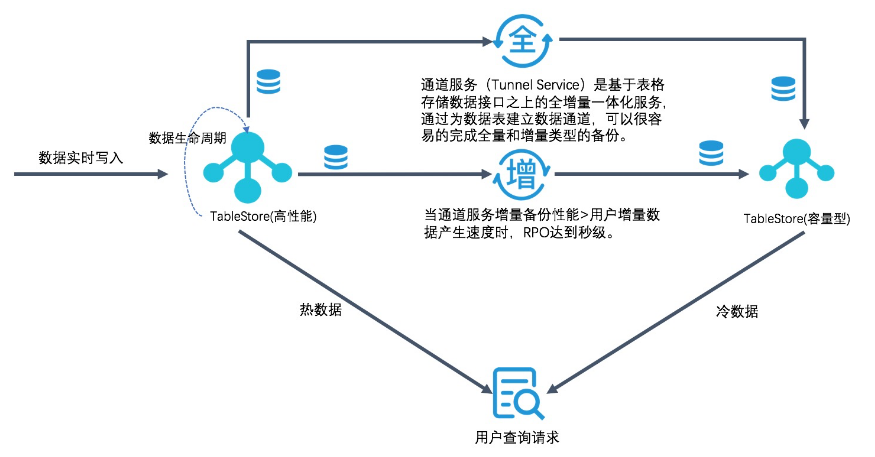
整个数据的流动过程如下:
- 业务写入端直接写入高性能实例
- 高性能实例中的数据通过通道服务同步至容量型
- 高性能实例中的老数据自动过期,减少存储量占用
用户查询请求根据时序查询条件,判断是否是近期数据
- 近期数据查询进入高性能,毫秒级别返回
- 较早数据查询进入容量型,几十毫秒后返回
代码和操作流程:
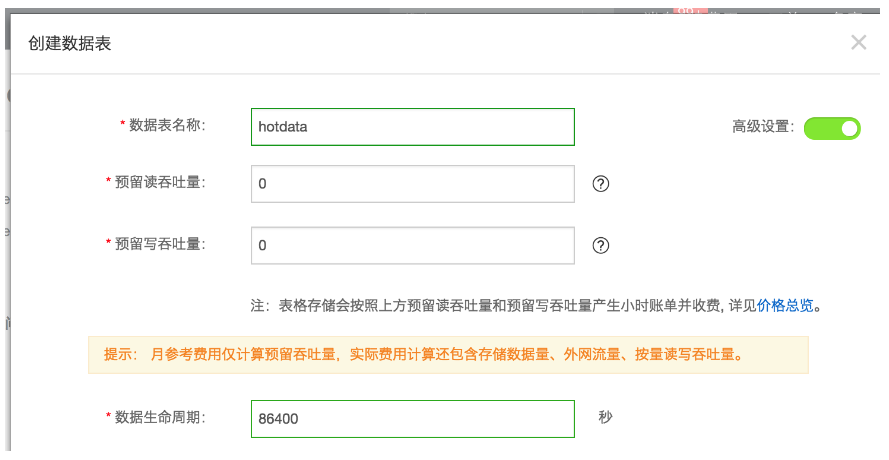
在高性能实例上根据业务主键需求创建数据表,并设置合理的数据TTL,然后在容量型下创建相同的schema的表用来持久化存储所有数据。
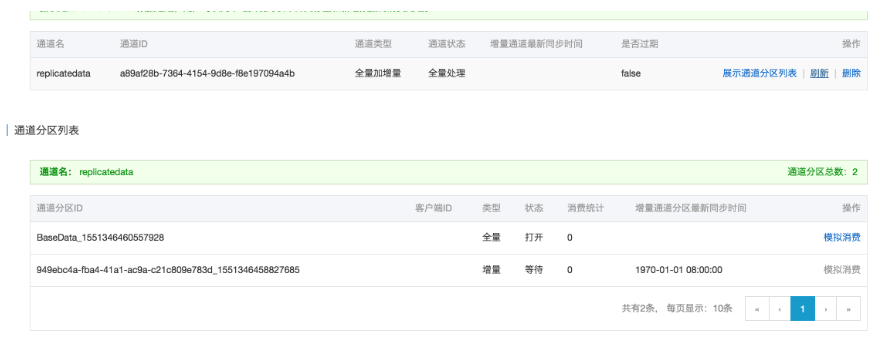
然后在通道页面创建一个全增量类型的通道:

通过控制台可以简单清晰的查看到同步的状态,并发,进度等信息:
下面贴一下通过Tunnel进行复制同样schema表TableStore表的Sample代码:
func main () {//高性能实例的信息tunnelClient := tunnel.NewTunnelClient("", "", "", "")//容量型实例的信息client := tablestore.NewClient("", "", "", "")//配置callback到SimpleProcessFactory,配置消费端TunnelWorkerConfigworkConfig := &tunnel.TunnelWorkerConfig{ProcessorFactory: &tunnel.SimpleProcessFactory{ProcessFunc: replicateDataFunc,CustomValue: client,},}//使用TunnelDaemon持续消费指定tunneldaemon := tunnel.NewTunnelDaemon(tunnelClient, "", workConfig)err := daemon.Run()if err != nil {fmt.Println("failed to start tunnel daemon with error:", err)}
}func replicateDataFunc(ctx *tunnel.ChannelContext, records []*tunnel.Record) error {client := ctx.CustomValue.(*tablestore.TableStoreClient)fmt.Println(client)for _, rec := range records {fmt.Println("tunnel record detail:", rec.String())updateRowRequest := new(tablestore.UpdateRowRequest)updateRowRequest.UpdateRowChange = new(tablestore.UpdateRowChange)updateRowRequest.UpdateRowChange.TableName = "coldtable"updateRowRequest.UpdateRowChange.PrimaryKey = new(tablestore.PrimaryKey)updateRowRequest.UpdateRowChange.SetCondition(tablestore.RowExistenceExpectation_IGNORE)for _, pk := range rec.PrimaryKey.PrimaryKeys {updateRowRequest.UpdateRowChange.PrimaryKey.AddPrimaryKeyColumn(pk.ColumnName, pk.Value)}for _, col := range rec.Columns {if col.Type == tunnel.RCT_Put {updateRowRequest.UpdateRowChange.PutColumn(*col.Name, col.Value)} else if col.Type == tunnel.RCT_DeleteOneVersion {updateRowRequest.UpdateRowChange.DeleteColumnWithTimestamp(*col.Name, *col.Timestamp)} else {updateRowRequest.UpdateRowChange.DeleteColumn(*col.Name)}}_, err := client.UpdateRow(updateRowRequest)if err != nil {fmt.Println("hit error when put record to cold data", err)}}fmt.Println("a round of records consumption finished")return nil
}总结
通过通道服务,存储在表格存储中的结构化,半结构化数据可以实时流出,进行加工,萃取,计算或进行同步。如果是想进一步降低冷数据的存储成本,可以参考这篇文章把表格存储的数据备份到OSS归档存储。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
转载于:https://my.oschina.net/u/1464083/blog/3058678
TableStore: 海量结构化数据分层存储方案相关推荐
- 海量结构化数据存储技术揭秘:Tablestore存储和索引引擎详解
前言 表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless NoSQL多模型数据库.Tablestore在阿里云官网上有各种文档介绍,也发布了很多场景案例文章,这些文 ...
- Table Store: 海量结构化数据实时备份实战
Table Store: 海量结构化数据实时备份实战 数据备份简介 在信息技术与数据管理领域,备份是指将文件系统或数据库系统中的数据加以复制,一旦发生灾难或者错误操作时,得以方便而及时地恢复系统的有效 ...
- 非结构化数据的存储与查询
当今信息化时代充斥着大量的数据.海量数据存储是一个必然的趋势.然而数据如何的存储和查询,尤其是当今非结构化数据的快速增长,对其数据的存储,处理,查询.使得如今的 关系数据库存储带来了巨大的挑战.分布存 ...
- 海量结构化数据解决方案-表格存储场景解读
简介: 数据是驱动业务创新的最核心的资产.不同类型的数据如非结构化数据(视频.图片等).结构化数据(订单.轨迹),面向不同业务的使用要求需要选择适合的存储引擎,能够真正发挥数据的价值.针对于海量的非强 ...
- 结构化数据存储,如何设计才能满足需求?
阿里妹导读:任何应用系统都离不开对数据的处理,数据也是驱动业务创新以及向智能化发展最核心的东西.数据处理的技术已经是核心竞争力.在一个完备的技术架构中,通常也会由应用系统以及数据系统构成.应用系统负责 ...
- 海量非结构化数据副本难保护,焱融科技携手英方推出联合解决方案
近日,北京焱融科技有限公司(简称"焱融科技")携手上海英方软件股份有限公司 (简称"英方软件")共同实现海量非结构化数据副本保护方案.这是双方针对海量非结构化数 ...
- 海量数据持久层解决方案_爱数AnyBackup重磅发布海量非结构化数据超可用解决方案...
海量非结构化数据有三大备份恢复问题一直没有得到有效解决:备份慢.恢复慢.备份数据不可查询.这三大问题已经对行业数字化转型造成了重大阻碍. 今天,AnyBackup Family 7线上发布会--重磅发 ...
- 如何使用 SQL Server FILESTREAM 存储非结构化数据?这篇文章告诉你!
作者 | ALEN İBRIÇ 译者 | 火火酱,责编 | Carol 封图 | CSDN 付费下载于视觉中国 在本文中,我将解释如何使用SQL Server FILESTREAM来存储非结构化数据. ...
- 如何使用 SQL Server FILESTREAM 存储非结构化数据?
作者 | ALEN İBRIÇ 译者 | 火火酱,责编 | Carol 封图 | CSDN 付费下载于视觉中国 在本文中,我将解释如何使用SQL Server FILESTREAM来存储非结构化数据. ...
最新文章
- jQuery与其它库冲突的解决方法(转)
- operator、explicit与implicit
- 使用javascript打开模态对话框
- nodejs中path的用法
- 《互联网+流通——F2R助力传统产业创新与转型》一一第1章 “互联网+”的新时代...
- 存储mysql数据存在特殊字符时处理_SQL数据库对于保存特殊字符的解决办法
- 跳房子(ybtoj-单调队列)
- 机器学习笔记(了解)
- 深度揭秘:腾讯存储技术发展史
- [转载] Java8-Stream API 详解
- [原创]完美开启Win8中管理员Administrator帐户
- 最好用的五大服装进销存管理软件,强推第一个
- 给大家推荐一款冰点文档下载器(免登陆,免积分)下载百度,豆丁,畅享网,mbalib,hp009,mab.book118文库文档
- 英语4级的分数如何计算机,英语四级分数怎么计算
- 关于NS3中各个WifiRemoteStationManager(二)
- RISCV学习笔记5.3--ubuntu18.04芯片设计软件(vcs、verdi)的简单使用
- [基础]-向量点乘和叉乘
- Java如何获取token
- VaR方法(Value at Risk,简称VaR)[风险价值模型]
- JK触发器计算机符号,JK触发器