语义分割论文-DeepLab系列
语义分割论文-DeepLab系列
DeepLabv1
收录:ICLR 2015 (International Conference on Learning Representations)
代码:github-Caffe
Semantic image segmentation with deep convolutional nets and fully connected CRFs
Abstract
DeepLab是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。在实验中发现DCNNs做语义分割时精准度不够的问题, 根本原因 是DCNNs的高级特征的平移不变性(即高层次特征映射)。DeepLab解决这一问题的 方法 是通过将DCNNs层的响应和完全连接的条件随机场(CRF)结合。同时模型创新性的将hole(即空洞卷积)算法应用到DCNNs模型上,在现代GPU上运行速度达到了8FPS。
1. Introduction
相比于传统的视觉算法(SIFT或HOG),DCNN以其end-to-end方式获得了很好的效果。这样的成功部分可以归功于DCNN对图像转换的平移不变性(invariance),这根本是源于重复的池化和下采样组合层。平移不变性增强了对数据分层抽象的能力,但同时可能会阻碍低级(low-level)视觉任务,例如姿态估计、语义分割等,在这些任务中我们倾向于精确的定位而不是抽象的空间关系。
DCNN在图像标记任务中存在两个技术障碍:
- 信号下采样
- 空间不敏感(invariance)
第一个问题涉及到 :在DCNN中重复最大池化和下采样带来的分辨率下降问题,分辨率的下降会丢失细节。DeepLab是采用的atrous(带孔)算法扩展感受野,获取更多的上下文信息。
第二个问题涉及到 :分类器获取以对象中心的决策是需要空间变换的不变性,这天然的限制了DCNN的定位精度,DeepLab采用完全连接的条件随机场(DenseCRF)提高模型捕获细节的能力。
论文的 主要贡献 在于:
速度 :带atrous算法的DCNN可以保持8FPS的速度,全连接CRF平均推断需要0.5s
准确 :在PASCAL语义分割挑战中获得了第二的成绩
简单 :DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成
2. Related Work
DeepLab系统应用在语义分割任务上,目的是做逐像素分类的,这与使用两阶段的DCNN方法形成鲜明对比(指R-CNN等系列的目标检测工作),R-CNN系列的做法是原先图片上获取候选区域,再送到DCNN中获取分割建议,重新排列取结果。虽然这种方法明确地尝试处理前段分割算法的本质,但在仍没有明确的利用DCNN的预测图。
我们的系统与其他先进模型的主要区别在于DenseCRFs和DCNN的结合。 是将每个像素视为CRF节点,利用远程依赖关系,并使用CRF推理直接优化DCNN的损失函数。Koltun(2011)的工作表明完全连接的CRF在语义分割下非常有效。
也有其他组采取非常相似的方向,将DCNN和密集的CRF结合起来,我们已经更新提出了DeepLab系统(指的是DeepLabV2)。
3. 研究方法与内容
3.1 使用空洞算法做密集滑动窗口特征提取
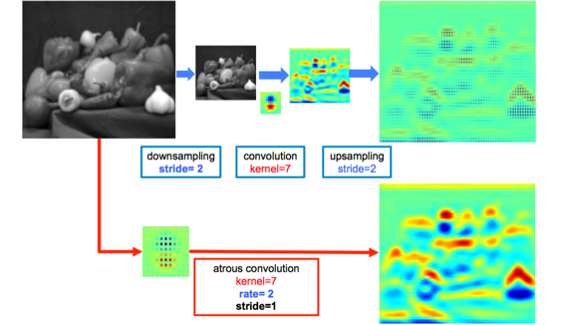
密集的空间分数评估有助于提取密集的CNN特征。首先将VGG16的全连接层改为卷积层,再使用采样率rate=2或4的空洞卷积方法对特征图采样,这种方法不仅可以保持完好的滤波器还能扩大感受野,并且不增加计算量和参数。算法里加入了im2col函数,将多通道的特征图转化成向量块,可以在不引入任何近似值的情况下,用各种采样率高效计算密集CNN特征图。损失函数是计算CNN输出图与原始图像(8倍采样)每个位置像素点交叉熵总和。
原因: FCN的粗糙之处:为了保证之后输出的尺寸不至于太小,FCN的作者在第一层直接对原图加了100的padding,可想而知,这会引入噪声。
而怎样才能保证输出的尺寸不会太小而又不会产生加100 padding这样的做法呢?可能有人会说减少池化层不就行了,这样理论上是可以的,但是这样直接就改变了原先可用的结构了,而且最重要的一点是就不能用以前的结构参数进行fine-tune了。所以,Deeplab这里使用了一个非常优雅的做法:将pooling的stride改为1,再加上 1 padding。这样池化后的图片尺寸并未减小,并且依然保留了池化整合特征的特性。
但是,事情还没完。因为池化层变了,后面的卷积的感受野也对应的改变了,这样也不能进行fine-tune了。所以,Deeplab提出了一种新的卷积,带孔的卷积:Atrous Convolution.即:
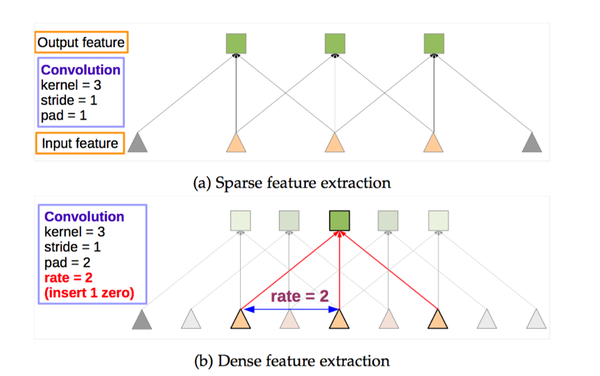
而具体的感受野变化如下:
a为普通的池化的结果,b为“优雅”池化的结果。我们设想在a上进行卷积核尺寸为3的普通卷积,则对应的感受野大小为7.而在b上进行同样的操作,对应的感受野变为了5.感受野减小了。但是如果使用hole为1的Atrous Convolution则感受野依然为7.
所以,Atrous Convolution能够保证这样的池化后的感受野不变,从而可以fine tune,同时也能保证输出的结果更加精细。即:
Note hole algorithm:
这里补充一下,VGG中卷积层的参数:stride=1,kernel_size = 3, padding =1,
所以进行卷积操作后:(H – 3 + 2 x 1)/1 + 1 = H,即卷积没有缩小图像的分辨率;
而VGG16Layer中有5个Maxpooling层,参数为:stride = 2, kernel_size = 2, padding =0;
所以:池化操作后:(H – 2)/2 + 1 = H/2,即图像分辨率减小一半,5个pooling层就是一共缩小了 2^5=32 倍
他们把VGG16模型中的全连接层全部转换成卷积层,然后运行这个网络。
其实得到的特征map还是很稀疏,而本论文作者的目标是只让它缩小8倍就好,于是想了个办法:
①他们想 skip the subsampling , 但是他们不是把pooling层直接去掉,而是把stride改成了1.然后还加上了padding = 1. 这个操作我在论文上似乎是没有看见详细说明,但是它的代码上是这么写的。这样的效果就是( H – 2 + 2 x 1) / 1 + 1 = H + 1,多了一个像素应该不影响把,它也没有详细解释这个问题,但是总之它把分辨率现在改回到基本不变了,所以就相当于少了两次缩小,就总共只缩小了8倍。
②分辨率是改大了,但是就因此出现了一个问题,就是后面卷积层卷积核的感受野变了,因此想要利用原先的VGG16的weights进行微调就有问题。
所以他们想的idea 对原卷积核填充0,也就是hole,把kernel试着变大 。
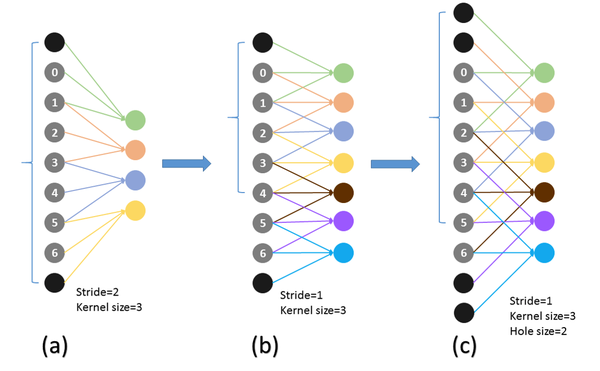
pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。接着pool5由2变为1, 则后面的fc6中hole size为4。
简单介绍下空洞卷积在卷积神经网络的使用(这在DeepLabv3中有更详细的讨论)。
在1-D的情况下,我们扩大输入核元素之间的步长,如下图Input stride:

如果不是很直观,看下面的在二维图像上应用空洞卷积:

蓝色部分是输入:7×7的图像
青色部分是输出:3×3的图像
空洞卷积核:3x3 采样率(扩展率)为2 无padding
这种带孔的采样又称atrous算法,可以稀疏的采样底层特征映射,该方法具有通常性,并且可以使用任何采样率计算密集的特征映射。在VGG16中使用不同采样率的空洞卷积,可以让模型再密集的计算时,明确控制网络的感受野。保证DCNN的预测图可靠的预测图像中物体的位置。
训练时将预训练的VGG16的权重做fine-tune,损失函数是取输出的特征图与ground truth下采样8倍做交叉熵和;测试时取输出图双线性上采样8倍得到结果。但DCNN的预测物体的位置是粗略的,没有确切的轮廓。在卷积网络中,因为有多个最大池化层和下采样的重复组合层使得模型的具有平移不变性,我们在其输出的high-level的基础上做定位是比较难的。这需要做分类精度和定位精度之间是有一个自然的折中。
解决这个问题的工作,主要分为两个方向:
- 第一种是利用卷积网络中多个层次的信息
- 第二种是采样超像素表示,实质上是将定位任务交给低级的分割方法
DeepLab是结合了DCNNs的识别能力和全连接的CRF的细粒度定位精度,寻求一个结合的方法,结果证明能够产生准确的语义分割结果。
3.2 用卷积网络控制接受域的大小加速密集计算
文章设置不同的感受野大小实验,发现由77变为44之后,训练速度提高,加速密集计算,还尝试了将完全连接层的通道数量从4096减少到1024,这进一步减少了计算时间和内存占用,同时不会影响性能。
note: 在把VGG的后面的全连接层转换为卷积层之后,比如说第一个全连接层(即原来的FC6)现在的卷积filter的size就是7x7大小的了,这个计算量就有些,
所以他们的思路是:直接从7x7的范围中抽取一个4x4 (or 3x3)的范围以此来减小计算量、计算时间比原来减少了2-3倍。
4. 细节边界恢复:完全连接的条件随机场(CRF)和多尺寸预测
4.1 深层卷积网络和本地化挑战
传统上,CRF已被用于平滑噪声分割图。通常,这些模型包含耦合相邻节点的能量项,有利于相同标签分配空间近端像素。定性的说,这些短程的CRF主要功能是清除在手工特征基础上建立的弱分类器的虚假预测。
与这些弱分类器相比,现代的DCNN体系产生质量不同的预测图,通常是比较平滑且均匀的分类结果(即以前是弱分类器预测的结果,不是很靠谱,现在DCNN的预测结果靠谱多了)。在这种情况下,使用短程的CRF可能是不利的,因为我们的目标是恢复详细的局部结构,而不是进一步平滑。而有工作证明可用全连接的CRF来提升分割精度。
译者注: 得分图可以可靠地预测图像中对象的存在和粗略位置,但不太适合用于刻画精准的轮廓。而DCNN用于分类确实很成功,但是它们的不变性和很大的感受野对于从得分图中精确定位还是有些难度。所以作者提出来他们的想法:
4.2 基于完全连接的条件随机域的准确定位
附:CRF示意图:
对于每个像素位置ii具有隐变量xi(这里隐变量就是像素的真实类别标签,如果预测结果有21类,则(i∈1,2,…,21),还有对应的观测值yi(即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构成了一个条件随机场(CRF)。通过观测变量yi来推测像素位置i对应的类别标签xi。条件随机场示意图如下:
![]()
CRF简单来说,能做到的就是在决定一个位置的像素值时(在这个paper里是label),会考虑周围邻居的像素值(label),这样能抹除一些噪音。但是通过CNN得到的feature map在一定程度上已经足够平滑了,所以short range的CRF没什么意义。于是作者采用了fully connected CRF,这样考虑的就是全局的信息了。
![]()
在全连接的CRF模型中,标签x 的能量可以表示为:
![]()
其中, θi(xi) 是一元能量项,代表着将像素 i分成label xi 的能量,二元能量项φp(xi,xj)是对像素点 i、j同时分割成xi、xj的能量。 二元能量项描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签,而这个“距离”的定义与颜色值和实际相对距离有关。所以这样CRF能够使图片尽量在边界处分割。最小化上面的能量就可以找到最有可能的分割。而全连接条件随机场的不同就在于,二元势函数描述的是每一个像素与其他所有像素的关系,所以叫“全连接”。
![]()
4.3 多尺度预测
我们在input image后面和 前面的4个maxpooling层的输出后面都紧接一个2层的MLP(Multi-layer Perceptron,多层感知器)。这个两层的MLP的构造为:第一层:128个3x3大小的卷积核,第二层:128个1xx大小的卷积核。然后把这写MLP得出的feature map 和主网络最后一层得出的feature map 排在一起。
所以最后送入到softmax layer的feature map 就得到了增强,也就是多了这5 *128个channels的值(我个人感觉这个操作有点FCN中skip layer的意思, 实验表示多尺度有助于提升预测结果,但是效果不如CRF明显。
5. 实验和评估
数据集:PASCAL VOC 2012 ,包含1464(train),1449(validation)和1456(test)数据集;10582张额外的训练数据,测试在21个分类上的IOU结果。
训练:DCNN和CRF分开进行(DCNN是训练,CRF是交叉验证从而找到最佳参数)
在验证集上的表现:
| 项目 | 设置 |
|---|---|
| 数据集 | PASCAL VOC 2012 segmentation benchmark |
| 网络结构 | VGG16 |
| DCNN模型 | 权重采用预训练的VGG16 |
| DCNN损失函数 | 上文提到的交叉熵之和 |
| 训练器 | SGD,batch=20 |
| 学习率 | 初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1 |
| 权重 | 0.9的动量, 0.0005的衰减 |
DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,对CRF做交叉验证。给定参数初始搜索范围,采用从粗糙到精细的搜索方案,找到最优参数值,所有实验报告的平均场迭代次数为10。这里使用ω2=3和σγ=3在小的交叉验证集上寻找最佳的ω1,σα,σβ,采用从粗到细的寻找策略。
CRF和多尺度的表现
在验证集上的表现:

可以看到带CRF和多尺度的(MSc)的DeepLab模型效果明显上升了。并且可以看出DeepLab-MSc-CRF-LargeFOV效果最好。
多尺度的视觉表现:

第一行是普通输出,第二行是带多尺度的输出,可以看出多尺度输出细节部分要好点:在模型中加入多尺度特征,性能约提高1.5%,连接CRF可提高4%。
离散卷积的表现
在使用离散卷积的过程中,可控制离散卷积的采样率(步幅)来扩展特征感受野的范围,不同配置的参数如下:

同样的实验结果:

带FOV的即不同离散卷积的配置.可以看到大的离散卷积效果会好一点。
与其他模型相比

与其他先进模型相比,DeepLab捕获到了更细节的边界。
6. Conclusion
DeepLab创造性的结合了DCNN和CRF产生一种新的语义分割模型,模型有准确的预测结果同时计算效率高。在PASCAL VOC 2012上展现了先进的水平。DeepLab是卷积神经网络和概率图模型的交集,后续可考虑将CNN和CRF结合到一起做end-to-end训练。
后续的DeepLabv2,3是DeepLabv1的升级版,进一步讨论空洞卷积和CRF的使用
语义分割论文-DeepLab系列相关推荐
- 语义分割丨DeepLab系列总结「v1、v2、v3、v3+」
花了点时间梳理了一下DeepLab系列的工作,主要关注每篇工作的背景和贡献,理清它们之间的联系,而实验和部分细节并没有过多介绍,请见谅. DeepLabv1 Semantic image segmen ...
- 【语义分割】DeepLab系列
目录 DeepLab V1 概述 细节 网络结构 空洞卷积 全连接CRF 多尺度预测 DeepLab V2 概述 细节 ASPP DeepLab V1 概述 我们之前有提到FCN将分类网络的全连接操作 ...
- 多篇开源CVPR 2020 语义分割论文
多篇开源CVPR 2020 语义分割论文 前言 DynamicRouting:针对语义分割的动态路径选择网络 Learning Dynamic Routing for Semantic Segment ...
- 综述笔记 | 一些弱监督语义分割论文
点击上方"AI算法修炼营",选择加星标或"置顶" 标题以下,全是干货 这里的弱监督信息为image-level的类别信息,即没有像素级的语义分割标签,而仅有图像 ...
- ECCV 2020 语义分割论文大盘点(38篇论文)
作者:CV Daily | 编辑:Amusi Date:2020-09-25 来源:计算机视觉Daily微信公众号(系投稿) 原文:ECCV 2020 语义分割论文大盘点(38篇论文) 前言 距离EC ...
- 图像语义分割python_图像语义分割 —利用Deeplab v3+训练VOC2012数据集
原标题:图像语义分割 -利用Deeplab v3+训练VOC2012数据集 前言: 配置:windows10 + Tensorflow1.6.0 + Python3.6.4(笔记本无GPU) 源码: ...
- 不良光线下的语义分割论文调研
不良光线下的语义分割论文调研 文章目录 不良光线下的语义分割论文调研 Multitask AET with Orthogonal Tangent Regularity for Dark Object ...
- 弱监督的语义分割论文汇总
弱监督的语义分割论文汇总 弱监督语义分割导读 弱监督语义分割论文整理 基于Bounding box的弱监督语义分割 基于Image-level labels的弱监督语义分割 基于Scribbles的弱 ...
- 深度学习语义分割论文笔记(待完善)
在深度学习这一块儿,我最开始使用Unet进行了冠状动脉血管的分割 再后来,我尝试改进Unet,改进损失函数,让网络能有不错的效果 再后来,看到了注意力机制,读了attention unet, 于是,我 ...
最新文章
- ajax调用接口很慢,nodejs 请求接口在高并发下耗时很大,而单个请求非常快
- Delegate和Command Pattern
- kali工具中文手册_Kali Linux 2019.4发布了!解决Kali Linux 2019.4中文乱码问题
- Blackey win10 + python3.6 + VSCode + tensorflow-gpu + keras + cuda8 + cuDN6N环境配置(转载)
- 让Windows控制台应用程序支持VT100---原理篇
- dm365 resize
- 招贤纳士|360WEB平台云平台部招人啦
- UITextView
- linux打开mysql某张表_Linux——MySQL多表连接
- Google 程序员消灭 Bug 的 5 大法宝!
- vb精简版12M大小含msinet.ocx控件
- 强化学习平台安装 Mujoco、mujoco-py、gym、baseline
- 电脑编辑安卓分区_20分钟轻松解决安卓手机分区问题 干货篇
- 中望cad文字显示问号怎么办_CAD文件打开后有很多问号怎么办
- Robocup 仿真2D 学习笔记(一) ubuntu16.04 搭建 robocup 仿真2D环境
- win2008服务器系统玩红警,win10系统玩红警卡死的两种方法
- 微信小程序-Testerhome
- 如何将Google表格电子表格插入Google文档
- 让技术Leader狂点赞的Linux速成手册,到底有多强悍?
- Java 第9天 面向对象(中) 理解有参构造器和无参构造器的作用