python模型预测_【超级干货!】教你用Python做回归模型预测房价
原标题:【超级干货!】教你用Python做回归模型预测房价
欢迎关注天善智能 hellobi.com,我们是专注于商业智能BI,大数据,数据分析领域的垂直社区,学习、问答、求职,一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。

用先进的回归技术做房价数据预测竞赛。
按照以下步骤取得成功的Kaggle参赛作品:
· 获得数据
· 探索数据
· 特性的创建和工程化(engineering features)以及目标变量
· 建立模型
· 制作并提交预测

我们需要为此次竞争找到数据。对特性和一些其他有用信息的描述包含在一个名称为data_deion.txt的文件中。(附后)
下载数据并将其保存到一个文件夹中,在这个文件夹中,保存所有你需要的文件。
我们先来看看train.csv 数据文件。在我们训练了模型之后,我们将预测结果存入test . csv 数据文件。
首先,import Pandas,一个很好的用Python语言函数库。接下来, import numpy。

我们可以用Pandas读入csv文件。用pd.read_csv()方法从csv文件中创建DataFrame。

让我们看看数据的大小。

Test 文件有80列,train 文件有 81列。当然,这是由于前者测试数据不包括最终的销售价格信息。
接下来,我们将使用theDataFrame.head()方法查看。

我们应该在我们的比赛文件夹中为比赛提供数据字典。你也可以在这里找到。
下面是在数据描述文件中的一些字段:
· SalesPrice——以美元计算的房地产的售价。这是你要预测的目标变量。
· MSSubClass——房地产建筑类别
· MSZoning ——一般的地区区分类
· LotFrontage——与房地产相距的街道英尺距离(?)
· LotArea -用平方英尺表示的大小
· Stret——所在道路的类型
· Alley-所在巷通道的类型
· LotShape -----房地产形状的分类
· LandContour-----土地的平整性
· Utilities-----可用的实用工具类型
· LotConfig——大小配置
等等。
比赛要求你预测每个家庭的最终价格。在这一点上,我们应该开始考虑我们对艾姆斯、爱荷华州(Ames, Iowa,)住房价格的了解,以及我们在这个数据集中可能看到的东西。
从这些数据,我们看到了我们所期望的特性,YrSold(房子的最后出售时间)和SalePrice。还有一些我们可能没有预料到的,比如,LandSlope(建造在屋顶上的房屋的坡度), RoofMatl(用来建造屋顶的材料)。稍后,我们将不得不决定如何处理这些字段和其他特性字段。
可以在项目的探索阶段进行一些可视化预览工作,也需要将这些功能导入到我们的环境中。预览允许我们可视化数据的分布,检查离群值,查看可能忽略的其他模式。我们将使用一个流行的可视化库Matplotlib来做这件事。

步骤二:挖掘数据,特征工程化
挑战在于预测最终的房屋出售价格,房屋出售价格信息存在SalePrice列中。通常将要预测的值称为目标变量(target variable)。
可以应用Series.describe()获取更多的信息。

Series.describe()提供了系列(series)的信息,count:系列(series)包含的行数,mean:均值,std:标准差,min:最小值,max:最大值。
在我们的数据集中房屋售价均值接近$180,000,大部分房屋价格分布在$130,000~$215,000范围内。
接下来,检查数据偏斜度(skewness),并以此来衡量数据分布的形状。
当使用回归方法时,如果目标变量出现偏斜,则有必要对目标变量进行对数变换(log-transform)。通过对数变换,可以改善数据的线性度。判断何时进行对数变换超出了本文的范围
重要的是,由最终模型生成的预测数据也要经过对数变换,这样便可将预测结果转换为原始形式。np.log()对数据进行变换,np.exp()进行逆变换。
plt.hist()可画出SalePrice的直方图,值得注意的是在分布右侧有较长的尾部。这个分布是正向偏差。


现在应用np.log()对train.SalePric进行变换,然后重新计算偏斜率,并重新画图。通过变换,斜率更靠近0值,分布更接近正态分布。


已经对目标变量进行了对数变换,现在我们再考虑下数据特征。首先,选择出数值特征并进行绘图。select_dtypes()方法返回与给定数据类型匹配的列的集合
对数字特征操作(Working with Numeric Features)
Id int64
MSSubClass int64
LotFrontage float64
LotArea int64
OverallQual int64
OverallCond int64
YearBuilt int64
YearRemodAdd int64
MasVnrArea float64
BsmtFinSF1 int64
BsmtFinSF2 int64
BsmtUnfSF int64
TotalBsmtSF int64
1stFlrSF int64
2ndFlrSF int64
LowQualFinSF int64
GrLivArea int64
BsmtFullBath int64
BsmtHalfBath int64
FullBath int64
HalfBath int64
BedroomAbvGr int64
KitchenAbvGr int64
TotRmsAbvGrd int64
Fireplaces int64
GarageYrBlt float64
GarageCars int64
GarageArea int64
WoodDeckSF int64
OpenPorchSF int64
EnclosedPorch int64
3SsnPorch int64
ScreenPorch int64
PoolArea int64
MiscVal int64
MoSold int64
YrSold int64
SalePrice int64
dtype: object
DataFrame.corr()方法可以给出两个列之间的相关性,我们利用该方法用于检测特征和目标变量之间的相关性。

前5个特征与SalePrice正相关,后5个特征与SalePrice负相关。为了进一步了解Over11Qual,可以利用unique()方法获取唯一值(unique values)。

Over11Qual数据是1~10的整数。建立一个数据透视表(pivot table,https://en.wikipedia.org/wiki/Pivot_table),以便深入分析Over11Qual和SalePrice之间的关系。Pandas文档(Pandas docshttp://pandas.pydata.org/pandas-docs/stable/reshaping.html)演示了如何完成分析工作。先设定“index='OverallQual'”、“values='SalePrice'”,进而查看median的值。

为了更容易地可视化这个数据透视表(pivot table),可以使用Series.plot()方法创建一个条形图。

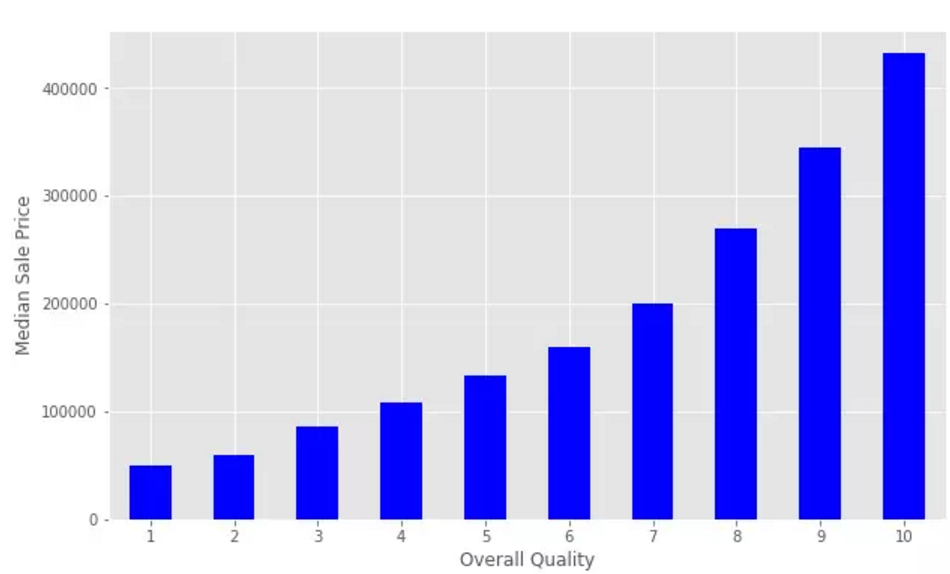
透过上图可以看出销售价格的中位数随着数量的增加而增加。接下来应用plt.scatter()生成散点图,对居住面积GrLivArea和SalePrice的关系进行可视化分析。


通过上图可以看出居住面积与价格呈现正相关关系。接下来对GarageArea进行同样的分析。

通过上图,可以看出许多房屋的Garage Area是0,表明这些房屋没有配备车库,稍后我们会利用其他特征反映这个猜测。图中显示存在一些奇异值(outliners, https://en.wikipedia.org/wiki/Outlier),这些奇异值会使预测回归线远离真实的回归线,进而影响回归模型。为保证回归模型的准确性,我们需要剔除这些奇异值。剔除野值既是技巧也是科学,有很多技术可以处理野值。
将剔除野值后的数据重新组合成新的数据帧(dataframe)。
利用剔除离群值后的数据进行画图。


处理空白值(Handling Null Values)
在这部分,检查空白值或者缺失值。
我们将创建一个数据帧DataFrame来查看顶部的空列(top null columns)。 将train.isnull().sum()方法链接在一起,我们返回一系列每列中的空值的计数。

该文档可以帮助我们了解缺少的值。 PoolQC表示泳池质量(Pool Quality)。当PoolArea为0时,泳池质量是NaN,或者是没有泳池。
我们可以在与车库相关的列之间找到相似的关系。
看看其他列,比如对MiscFeature列进行分析,利用Series.unique()方法给出唯一值列表。
我们可以使用文档来了解这些值是什么意思:

这些值描述了房屋是否有超过100平方英尺的棚子、第二个车库等设施,稍后我们会利用这些信息。在处理缺失值时,需要更多的专业知识才能做出最好的决定。
处理非数字特征(Wrangling the non-numeric Features)
下面我们考虑非数字特征。

Count:非空观测值的计数,
Unique:唯一值的计数
Top:出现次数最多的值,
Freq:出现次数最多值的频率。
对于这些特征,我们希望用one-hot encoding(https://www.quora.com/What-is-one-hot-encoding-and-when-is-it-used-in-data-science)法建模。one-hot encoding可以将分类数据(categorical data)转化为数值。通过这种转化,模型可以理解特定观测属于哪一类别。
转换和工程化特征(transforming and engineering features)
在转换特征时,需要记住在适应模型前对训练数据进行的变换,并对测试数据进行同样的变换。
我们的模型预期train数据集的特征形状与test数据集相匹配,即在train数据集工程化的特征也可以应用在test数据集。下面将以Street数据集为例来演示这个过程,Street表示到达房屋的路是Gravel还是Paved。

Street列的唯一值(unique values)是Pave和Grvl,用来描述到房屋道路的类型。在训练集中,5所房屋有碎石路。我们的模型需要数字数据,因此应用one-hot encoding法将Street数据转化为布尔列。创建一个新的列enc_street,pd.get_dummies()方法可以完成将数据转换成布尔量的工作。如前文所述,需要对train数据和test数据进行同样的处理。

处理之后的值可以用来训练、测试模型,这是工程化的第一个特征。特征工程化是对数据特征进行处理,使其成为适合于机器学习和建立模型。将Street特征转变为布尔列,这就是工程化了一个特征。
让我们试着对其他特征工程化。下面将对SaleCondition进行处理,就像刚刚对OverallQual所做的一样。


值得注意的是Partial的价格中位数要比其他量高,因此将Partial作为新的特征。当SaleCondition等于Patrial时,赋值1,否则赋值0。采用处理Street的方法,完成赋值操作。
下面利用图像来分析新的特征。


你可以继续对更多的特征进行处理,来改善你建立的模型。
在建模前,需要处理缺失值。我们用均值对缺失值赋值,并用data保存,这个过程称为插值。DataFrame.interpolate()方法可以简单方便的实现这个过程。但是应用此方法建立的模型,可能在处理新数据时达不到最优性能。处理缺失值是建模过程中重要的一步,创造性和洞察力在这个操作中大有裨益。这是本教材中另一个可以拓展的领域。
确认data所有列值均为0。
步骤三:构建线性模型
让我们来完成建模前数据准备的最后步骤:分离建模的特征变量和目标变量。将特征变量分配给x,将目标变量分配给y,如上所述,使用np.log()来改变模型的y变量。
使用 data.drop([features], axis=1这个语句来告诉pandas想要排除的列。很明显SalePrice不会包含在变量内,同样id只是SalePrice并没有关联关系的一个索引。 y = np.log(train.SalePrice)X = data.drop(['SalePrice', 'Id'], axis=1)

让我们来将数据进行划分并开始建模。使用scikit-learn里的train_test_split()函数生成一份训练集和一份测试集。
使用这种方式划分数据,使我们能评估当模型面对以前从未遇到的数据时,它的执行情况会怎样。如果将测试数据都用来训练模型,那将会很难判断模型是不是过度拟合了。
train_test_split() 会返回4个对象
X_train:用作训练数据的一个子集
X_test: 用作测试数据的一个子集--会被用来测试训练好的模型
y_train:与 X_train对应的目标变量SalesPrice
y_test: 与 X_test对应的目标变量SalesPrice
第一个参数值X表示一组预测数据集,y是目标变量。接下来设置random_state=42,它提供了可重复的结果,因为sci-kit learn的train_test_split函数会随机的划分数据。test_size参数告诉函数样本的占比。在这个例子中,约33%的数据被用作测试集。
开始建模
我们先创建一个线性回归模型。首先实例化模型
接下来,训练这个模型。模型拟合是一个针对不同类型模型而变化的过程。简而言之,评估预测因子和目标变量之间的关联程度,以便对新的数据集做出准确的预测。
用X_train 和 y_train训练模型,用X_test和 y_test 衡量模型,lr.fit()方法会对指定的特征变量和目标变量进行线性回归训练。
model = lr.fit(X_train, y_train)
评估模型的表现并展示结果
现在,我们要评估模型的表现。 每个比赛可能会对提交作品有不同的评估方式。 在这场比赛中,Kaggle将使用均方根误差(RMSE)评估我们的提交作品。
我们还会考虑r平方的值, r平方值是数据与拟合回归线的接近程度的一种度量,它的取值在0到1之间,1意味着目标中的所有方差都由数据解释。 一般来说,较高的r平方值意味着更好的拟合。
model.score()方法默认会返回r平方值

这标志着我们的特征变量能解释目标变量中约89%的差异(todo?是否意译为准确度89%) 。 点击上面的链接可以了解更多。
接下来,我们来关注下RMSE。 为此,我们用建立好的模型对测试数据集进行预测。 predictions=model.predict(X_test)
model.predict()在训练模型之后使用这个方法,它会返回给定一组预测变量的预测列表。
函数mean_squared_error需要两个数组来计算RMSE。
fromsklearn.metricsimportmean_squared_errorprint('RMSE is:\n',mean_squared_error(y_test,predictions))
RMSE is: 0.0178417945196
RMSE这个值比r平方值更直观,它表示我们的预测值和实际值之间的距离。
我们可以用散点图来查看这种关系。
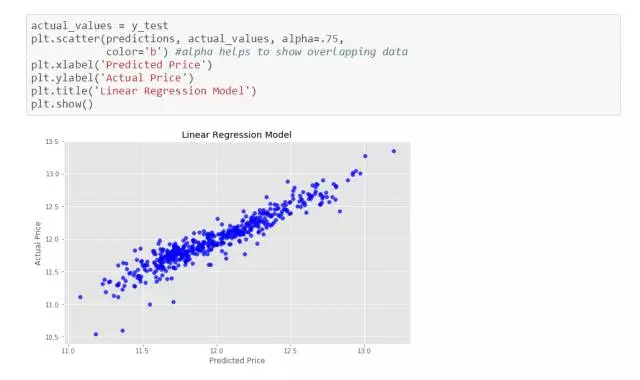
如果预测值与实际值相同,则该图将为直线y = x,因为每个预测值x将等于每个实际值y。
尝试改进模型
接下来我们尝试使用岭正则化(Ridge Regularization)来减少非关键特征变量的影响, 岭正则化(Ridge Regularization)是收缩非关键特征的回归系数的过程。
现在再次实例化模型,岭正则化(Ridge Regularization)模型使用一个参数α,用来控制正则化的强度。
我们将通过循环赋于几个不同的 α值来进行实验,并观察它们如何改变我们的结果。






这些模型与第一个模型几乎相同,如此看来,调整alpha并没有显著提升我们的模型。当添加更多特征时,正则化可能会有所帮助,您可以添加更多功能后重复此步骤。
步骤四:提交
创建一个csv文件,其中包含测试文件test.csv中每个需要观察预测的SalePrice字段
登录到Kaggle帐户,然后到提交页面进行提交。我们将使用DataFrame.to_csv()创建一个csv来提交。第一列必须包含来自测试数据的ID。
现在,根据上面所做的模型,从测试数据中选择特性。

接下来,生成预测。
在把预测转换成正确的形式。记住,要反向使用log(),执行exp()。因此,用np.exp()来做预测,因为之前已经取了对数。
看有什么不同。
初的预测:
[ 11.76725362 11.71929504 12.07656074 12.20632678 12.11217655]
最后的预测:
[ 128959.49172586 122920.74024358 175704.82598102 200050.83263756
182075.46986405]
让我们来分配这些预测,并检查一下结果。

旦认为已经把数据按正确的格式安排好了,可以导出到a.csv文件,这是Kaggle所要求的那样。我们设置index= False,否则Pandas会为我们再创建一个新的索引。
提交我们的结果
我们创建了一个名为submission1.csv的文件。我们工作目录中的csv符合正确的格式。进入提交页面提交。
转载请保留以下内容:
本文来源自天善社区datakong老师的博客(公众号)。
原文链接: https://ask.hellobi.com/blog/datakong/8134返回搜狐,查看更多
责任编辑:
python模型预测_【超级干货!】教你用Python做回归模型预测房价相关推荐
- python灰色预测模型步骤人口预测_超级干货:一文读懂灰色预测模型
灰色预测模型可针对数量非常少(比如仅4个),数据完整性和可靠性较低的数据序列进行有效预测,其利用微分方程来充分挖掘数据的本质,建模所需信息少,精度较高,运算简便,易于检验,也不用考虑分布规律或变化趋势 ...
- logit回归模型假设_一文让你搞懂Logistic回归模型
注:本文是我和夏文俊同学共同撰写的 现考虑二值响应变量 ,比如是否购车,是否点击,是否患病等等,而 是相应的自变量或者称特征.现希望构建一个模型用于描述 和 的关系,并对 进行预测. 线性模型可以吗? ...
- python 开发工具_「干货」推荐一整套 Python 开发工具
文 | Brendan Maginnis 译 | EarlGrey 在开始一个新的Python项目时,很容易不做规划直接进入编码环节.花费少量时间,用最好的工具设置项目,将节省大量时间并带来更快乐的编 ...
- python做空矩阵_【手把手教你】Python实现基于隐马尔科夫的多空策略
前言 我们通常使用股市的一手数据来创建一个策略模型,预测下一时刻价格的多少.走势的判断或其他. 今天,我们想结合多样的市场条件(波动性,交易量,价格变化等等)和结合隐马尔科夫(HMM)来构建我们的交易 ...
- 一步步教你轻松学逻辑回归模型算法
一步步教你轻松学逻辑回归模型算法 ( 白宁超2018年9月6日15: 01:20) 导读:逻辑回归(Logistic regression)即逻辑模型,属于常见的一种分类算法.本文将从理论介绍开始,搞 ...
- python小技巧:一步步教你用Python实现
python小技巧:一步步教你用Python实现2048小游戏 https://www.meipian.cn/2xywlpbv https://www.meipian.cn/2xywhexo http ...
- Python灰帽子_黑客与逆向工程师的Python编程之道
收藏自用 链接:Python灰帽子_黑客与逆向工程师的Python编程之道
- 大模型落地实践系列一、公司为什么要做大模型?
为什么公司要做大模型? 近年来,随着人工智能技术的飞速发展,大模型在各行各业中被越来越多地应用.尤其是在企业中,大模型被视为提高生产力.优化运营和增加收益的利器,越来越多的公司开始着手部署大模型.本文 ...
- python预测未来数据步骤_大神教你用Python预测未来:一文看懂时间序列(值得收藏)...
所有代码都是用 Python 编写的,并且在 GitHub 上可以看到所有的信息. https://nbviewer.jupyter.org/github/leandrovrabelo/tsmodel ...
最新文章
- 用Python写出Gameboy模拟器,还能训练AI模型:丹麦小哥的大学项目火了
- word的小操作--页码的编辑
- qpython怎么用matplotlib_将matplotlib绘图嵌入pyqt的方法示例
- Python 把较长的一行代码分成多行的技巧
- [Web 前端] 解决因inline-block元素导致的空白间距和元素下沉
- Fleury算法 求欧拉回路
- 命令唤醒计算机,电脑Win10怎么使用命令查看唤醒系统设备和任务的软件的方法...
- 应用id_科普贴:什么是OpenID、AppID 、用户ID等各种ID?
- JavaScript数组的高级用法-reduce和reduceRight详解
- 消息中间件Notify和MetaQ-阿里中间件
- css 修改占位符(placeholder)默认颜色、字体
- python gui控件案例_python基础教程python GUI库图形界面开发之PyQt5布局控件QHBoxLayout详细使用方法与实例...
- IPO | 经纬恒润登科创板,好赛道下隐患依然很突出
- winrar5.31 专用激活key
- springboot mime类型处理
- php的seeder是什么,使用Laravel框架的Seeder实现自动填充数据功能
- wps怎么画网络图_wps 流程图怎么画 WPS流程图绘制图解教程
- 内存数据网格IMDG简介
- 20系列显卡服务器,关于20系列的DLSS
- 点对点加密文件传输工具Filegogo