新浪微博百万用户分布式压测实践手记
作者:聂永,新浪微博技术专家。负责移动端消息应用架构底层基础设施维护和优化等,目前致力于推广性能驱动模式推动系统健康发展的理念。
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅《程序员》
微博产品后端服务团队在资源受限情况下基于Tsung提供了一套开箱即用的100万用户性能压测工具套件,推动两名能力和经验都欠缺的中初级工程师,不但顺利完成支持海量用户的在线聊天室项目任务,同时保证了该业务系统整体处理性能可控并按照预期方式向前推进。
需求 & 背景
前段时间我们为微博App增加一个视频直播聊天室功能,这是一个需要支持海量级手机终端用户一起参与、实时互动的强交互系统,建立在私有协议之上、有状态的长连接TCP应用。和其他项目一样,在立项之初,就已确定所构建系统至少能够承载100万用户容量,以及业务处理性能最低标准。
当时研发力量投入有限,一名中级工程师 + 一名初级工程师,两人研发经验和实践能力的欠缺不足以完成系统容量和处理性能的考核目标,这是摆在眼前最为头疼问题。聊天室业务逻辑清晰并已文档化,倒不用太担心功能运行正确,除了自我验证外,还会有QA部门帮忙校验。这驱使我们在软件工程角度去思考,如何通过行之有效的手段或工具去推动研发同学项目顺利完成项目性能考核目标。
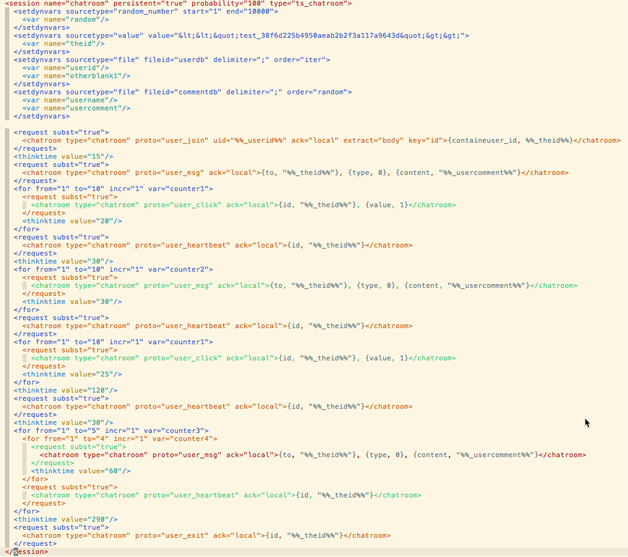
聊天室会话实例
延伸一下,新项目构建之初,自然要关注总体处理性能目标的。但从软件生命周期角度考虑,还应该考虑到系统后续维护和迭代。所谓工欲善其事,必先利其器,因此我们需要提供一个完善的开箱即用、支持海量用户的性能压测基础工具套件,既要能够保证系统处理性能是可测量的,又要能够为每一次版本发布时、常规迭代后再次验证系统性能目标。带着这一目标,下面将逐一展开我们如何构建百万用户性能压测工具套件的过程以及注意事项。

性能贯穿于软件生命周期
性能压测工具选择
团队所能够支配的空闲服务器数量几乎为零,这是现状。所负责业务线的大部分服务器配置为16GB内存、24个CPU核心左右,每时每刻都在跑着具体的业务。若留心观察,一般晚上九、十点之后资源利用率高,而白天时间CPU、内存、网络等资源大概会剩余30%-60%左右,颇为浪费,如何将这部分资源充分利用起来,是一个需要思索的问题。
针对100万用户这样超大容量压测需求,要求每台压测机要能够负载尽可能多的用户量。试想,若一台压测机器承载1万用户,那么就会需要使用到100台,单纯所需数量就是一件让人很恐怖的事情。
若是单独为性能压测申请服务器资源,一是流程审批流程较为繁冗,二是因为压测行为不是每时每刻都会执行高频事件,会造成计算资源极大浪费。本着节约资源理想方式就是充分利用现有的空闲计算资源用于执行性能压力测试任务。
【众多选择】
当前市面上能够提供性能压测的工具很多,选择面也能很广泛,下面我将结合实际具体业务逐一分析和筛选。
TcpCopy
线上引流模式,针对新项目或全新功能就不太合适了,业务层面若需要一定量的业务逻辑支持,很难做得到。
JMeter
Java编写,在执行1万个压测用户线程时,CPU上下文切换频繁,大量并发时会有内存溢出问题,很显然也不是理想的选择。
nGrinder
图表丰富,架构很强大,堆栈依赖项太多,学习成本很高。
需要额外掌握Python等脚本语言,虽针对程序员友好,不是所有人都可以马上修改。
数十个线程至少占用4GB内存,一台机器上要模拟5万个用户,不但CPU上下文切换恐怖,16GB小内存机器更是远远满足不了。
针对服务器资源充足的团队,可以考虑单独机器部署或Docker部署组成集群,针对我们团队情况就不合适了,想免费做到是不可能的。
Tsung
完成同样性能压测功能,却没有第三方库依赖,独立一套应用程序。
虽然所测试服务是I/O密集型,但所占用内存不会成为瓶颈。
可能会触及到Erlang语言,但我们现在工作用的语言就是Erlang,也就不存在什么问题了。
其他
综合所述,Tsung默认情况下消耗低,可充分利用现有服务器空闲计算资源,线上多次实践也证实资源占用始终在一个理想可控的范围内,具有可让百万用户压测执行的费用成本降低为0的能力,这也是我们选择Tsung的目的所在。
【为什么是Tsung?】
Tsung是一个有着超过15年历史积累的性能压测工具,本身受益于Erlang天生支持并发和分布式以及实时性的特性,其进程的创建和运行非常廉价,一台机器上轻轻松松创建上百万个进程。其提供一个用户对应一个进程的隔离处理机制,单机支持虚拟用户的用户数量可支持若十万、百万级别,只要机器资源充足(但总体来讲受制于受制于网络、内存等资源,后面会具体解释)。单机计算能力总是有限的,Tsung的目的就是要把多台服务器横向扩展成分布式集群,从而可以对外提供一致的海量性能压力测试服务。
协议层,Tsung不但支持TCP/UDP/SSL传输层协议等,而且应用层协议,已支持诸如WebDAV/WebScoket/MQTT/MySQL/PGSQL/AQMP/Jabber/XMPP/LDAP等。默认情况下,开箱即用,凭借着社区的支持,市面上能够找到的公开通用协议,都有相应官方或第三方插件支持。
和nGrinder相比,Tsung定位于提供一个强大的性能测试工具,在易用性和强大可扩展方面保持了一个平衡点。基于XML + DSL提供可配置、可编程的能力。比如我们可设置上一次的响应结果作为下一次请求内容,我们可配置多种业务协议、多个业务场景作为一个整体压测等。尽力抽象所要压测的情景吧,你不会失望的。
服务资源占用方面,以单机模拟5万长连接用户为例,有数据正常交互情况下,内存占用不到3GB,CPU占用不到两核,十分经济。

单机5万长连接资源消耗
【Tsung的集群架构 & 流程】
知其然知其所以然,还是需要掌握Tsung集群大致流程的。这是一种强主从模型,简单流程梳理如下:

Tsung主从架构图
- 主节点(tsung_controller)通过SSH通道连接到从服务器启动从节点运行时环境;
- 主节点通过RPC方式批量启动从节点实例(tsung client);
- 主节点为每一个从节点启动会话监控,控制会话速度,控制每一个压测用户进程ts_client生成速度;
- 从节点请求主节点具体业务进程,获取会话指令以及会话具体内容;
- 从节点建立到目标压测服务器的SOCKET网络连接,开始会话;
- 主节点可以通过SSH通道连接到目标压测服务器,启动从节点,收集数据(可选)。
- 再深入一些,以MQTT协议为例,每一种具体协议的支持可分为文件解析和会话动作的执行,运作机制不复杂,当我们在需要时可以遵循接口约定实现私有协议支持,也不是难事。
100万用户压测需要多少台机器?
要执行100万用户的性能压测,首先预估需要多少台压测服务器才能够满足要求。在Tsung中,一个压测用户对应于一个进程,一个进程默认会打开一条连接到服务器的TCP网络连接。只要内存够用(I/O密集型的应用一般吃内存),基于Erlang开发的应用程序,轻轻松松应对几十万、上百万的进程不是问题。那么我们需要把注意力转移到Linux网络资源上。一台服务器所能够提供网络IP地址数量和内存大小等主要因素,直接决定了能够承载的对外建立的网络连接数,下面我们把主要的影响因素一一列出并分析。

Tsung通用插件调用流程
【网络四元组和总连接数】
说到网络连接抽象层面构成元素,针对本机对外建立的一个TCP连接而言,需要使用到本机的IP地址(localip)和端口(localport),以及远程的主机的IP地址(targetip)和端口(targetport),可以使用网络四元组进行呈现一个连接的最小构成:
{local_ip,local_port,target_ip,target_port}我司目前所使用的服务器操作系统大多为Centos 6.x版,受制于Linux内核限制,无论目标服务器连接地址如何变化,单机对外建立的连接数量是有限的:总连接数=本机可用IP地址数量×本机可用端口的数量。
明白了总连接数的计算方式,那么可以按图索骥,从每一个计算因子上去考虑如何扩大其连接数。
注:若要调试TCP网络四元组,诸位可使用bindp这个小工具:https://github.com/yongboy/bindp,十分方便。
【Linux内核端口数量的限制】
众所周知,在Linxu系统中,端口的数值范围为无符号short类型,值范围为1 ~ 65535。一般来讲1 ~ 1023范围默认只有Root用户有权限使用,普通用户可以使用区间范围1025 ~ 65535,约6万。
但你要考虑这中间很多的端口可能被已运行的程序占用,不妨打个折降低预期范围,留有5万左右的可用数值,以作缓冲。
我们可通过sysctl命令确认当前可用的端口范围,以作参考:
bash sysctl -a | grep net.ipv4.ip_local_port_range若范围空间太小,比如1024 ~ 35525,那就需要主动扩大一下:
bash sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -p【扩展阅读:IP可用数量的延伸】
有三种比较经济方式可扩展IP地址可用数量。
第一种,针对Linux内核 >= 3.9的Linux服务器而言,可设置SO_REUSEPORT内核参数进行支持;对外一个连接的四元组,将不再仅局限于本机IP地址和端口两个元素,整个网络四元组任何一个元素若有变化,都可以认为是一个全新的TCP连接,那么针对单机而言可用总连接数上限可以这样计算:
总连接数 = 本机可用IP地址数量×本机可用端口的数量×远程服务器可访问IP地址数量×远程服务器可访问端口数量。
注:
- 远程服务器指的是要压测的业务服务器提供了多个访问地址(IP地址:端口)访问,但都指向同一个业务服务接口;
- 一般而言,一个业务服务只会开放一个IP地址和端口。
第二种方式,使用IP地址别名的方式,为本机绑定额外的可用的IP地址:
bash ifconfig eth0:1 10.10.10.101 netmask 255.255.255.0注:所绑定的IP地址一定是可用的,否则会导致压测机和被压测的服务器之间无法成功建立连接。
第三种,可用考虑使用IP_TRANSPARENT(Linux kernel 2.6.28添加支持)特性支持。在你内存足够大的情况下(比如拥有64GB ~ 128GB内存),假如压测机A的IP地址为10.10.9.100,公司内网有一个IP段10.10.10.0暂时没有被使用,你可以通过ip route工具设置一台机器占用完整一个IP地址段支持。
压测机需要为物理网卡eth1添加路由规则,以便能够正常处理来自新增IP段的往返数据包:
bash ip rule add iif eth1 tab 100 ip route add local 0.0.0.0/0 dev lo tab 100同时需要在被压测的服务器上添加路由规则,方便在发送响应数据包时候能够找到被路由的接口地址:
bash route add -net 10.10.10.0 netmask 255.255.255.0 gw 10.10.9.100这样一折腾,压测机A的可用IP地址就多出来250多个全新的IP地址了。
注:其实,还可以虚拟若干个Docker实例达到这个目的。 有兴趣的同学,可以进一步参考:Tsung笔记之IP地址和端口限制突破篇,以便获得更多资料支持。
【内存因素】
针对大部分应用而言,Tsung默认网络堆栈发送和接收缓冲区都是16KB,完全够用了。一个网络连接 = 一个用户 = 一个进程,每进程业务占用约10KB,粗略算下来,一个不太复杂用户逻辑上内存占用不到50KB内存。
按照这个方式计算,1万用户可占用500M内存,单机要支持6W用户,再加上程序自身占用内存,整个Tsung实例大约会占用4GB内存。实际上测试中,在每台压测机分配5万用户情况下内存使用情况,可以见图2。
【注意文件句柄】
一个网络连接占用一个文件句柄,可用文件句柄数一定要大于对外建立的连接数。可使用ulimit查看限制的数量:
bash ulimit -Sn ulimit -Hn若此值太小,根据实际情况调整,设置大一些,比如下面设置的30万连接句柄限制,大于当前服务器日常对外提供的连接数峰值 + 压测从机对外建立的连接数,有缓冲余地,可轻松应对大部分任务:
bash echo "* soft nofile 300000" >> /etc/security/limits.conf echo "* hard nofile 300000" >> /etc/security/limits.conf还需要关注一下当前服务器总的文件句柄最大打开数量限制:
bash cat /proc/sys/fs/file-max此值不能够小于上面所设置的nofile的值,否则需要大一些:
bash sysctl -w fs.file-max=300000 sysctl -p【百万用户压测机组成】
说完影响因素,现在我们可计算一下,要压测100万用户,理论上需要多少台服务器支持:
- 每一个IP地址可以支持6万个TCP连接同时打开,那么100万个呢,100万/6万 ≈ 17个IP地址就够了;
- 1万用户大约占用500MB内存,100万用户大概将占用500MB×100万 / 1000MB ≈ 50GB内存。
总之理论上,一台64GB内存服务器 + 17个可用IP地址,可以单独完成100万用户的压测任务。
注:我们忽略了CPU资源的需求,一般压测是I/O密集型,所耗费CPU资源不是很多,但也要小心,有时需要降低或关闭掉在压测端进行一些高频的数据校验行为。
理论和现实总是有差距存在,要做100万用户的压测,如上所述,我们没有大量空闲服务器,有的是若干16GB小内存、单一内网IP地址的线上服务器,需要因地制宜:
- 留有缓冲余地,每一台压测机平均分配5万个用户;
- 1台服务器用作压测主机;
- 20台线上服务器作为压测机。
提前计算和准备好压测使用的服务器,下面该进入设计业务压测会话内容环节了。
设计业务压测会话内容
紧密贴合业务设计压测,会话内容将是需要考虑的重心。
【压测连接信息】
怎么填写压测连接服务器地址、压测从机,根据Tsung手册操作即可。篇幅所限,不再赘述。
若是压测单台业务服务器,用户每秒生成速率需要避免设置过大。因为业务型服务,一般以处理具体自身业务为先,在用户每秒产生速率过快情况下,针对新建网络连接的处理速度就不会太快。
比如我们实践中设置每秒产生500个用户对线上若干台服务器压测,可避免因为产生过快影响到线上其他具体业务。
实践压测环节中,可能需要考虑很多的事情:
- 会不会突然之间对LVS网络通道产生影响,需要和网络组同事进行协调;
- 会不会因为突然之间的压力导致影响到其他现有服务;
- 一般建议,非封闭的网络环境下将用户每秒压力产生速度设置小一点,保险一些。
【设计压测会话内容】
压力测试会话内容的编写,有三个原则需要注意:模拟、全面和强度。
我们在设计压测会话时,一定要清楚所开发系统最终面向的用户是谁,其使用习惯和特征分别是什么,一定要尽可能的去复现其使用场景。其次,需要模拟的用户会话内容要全面覆盖用户交互的各个方面,比如聊天室项目中,一个用户从加入房间,中间流程包括点赞、打赏、光柱、发言等行为,中间间隔的心跳等,最后可选择的退出行为,其业务场景,完整的体现在编写的压测场景中了。另外,针对业务场景特点,还针对每一个具体的行为,还要考虑其执行次数等,简简单单走一遍流程,也就失去了性能压力测试的意义了。
下表是在压测聊天室这个业务时压测会话,包含了一个终端用户的完整交互。

安装和部署
Tsung安装部署要求简单:
- 所有压测服务器上安装有同样版本的Erlang和Tsung
- 服务器之间SSH通道需要设置成免密钥自动登录形式
这针对一般的机房环境是没有什么问题,但网络环境是很复杂的,问题总是会多过设想。
【SSH不可用时的替代方案】
但SSH通道会被系统管理员出于安全考虑禁用,导致Tsung主节点无法启动从节点,无法建立压测集群。我司机房网络环境就是如此,既然SSH不可使用,那么需要寻找/编写一个替代者。
一般情况下,Tsung主节点启动之后,从tsung.xml文件中读取从机列表,进而启动:
erlang slave:start(node_slave, bar, "-setcookie mycookie")然后被翻译为类似于ssh HOSTNAME/IP Command命令:
bash ssh node_slave erl -detached -noinput -master foo@node_master -sname bar@node_slave -s slave slave_start foo@node_master slave_waiter_0 -setcookie mycookie这很好解释了为什么压测节点之间需要提前设置SSH免密钥登录了。
SSH为C/S模式,SSH Server是默认监听22端口的一个守护进程,等待客户端发送命令,解析执行,然后返回结果。明白了这个道理,我们可利用反向Shell机制打造一个SSH替代品。
首先我们需要在一个从节点上启动一个守护进程:
bash ncat -4 -k -l 39999 -e /bin/bash &主节点作为客户端,比如我们想查询远程服务器主机名:
bash echo hostname | ncat 10.77.128.21 39999一点都不复杂吧,但实际上还有很多的工作要做,比如自动断开机制等,我已封装了rsh_client.sh和rsh_daemon.sh两个文件,可参考https://github.com/weibomobile/tsung_rsh,不再累述。
问题来了,如何结合Tsung使用呢?
第一步,在所有从机启动守护进程:
bash sh rsh_daemon.sh start第二步,需要在Tsung启动时使用-r参数指定自定义的远程终端:
bash tsung -r rsh_client.sh -f tsung.xml start总之,这个SSH终端替代方案,已经在良好的运行在线上实际压测中了,图6为其部署结构。

注:其实不仅仅是替代,还可以在其上增加一些资源监控功能,我们已经这样干了。
【IP直连特性支持】
Tsung还有一个使用不便的地方,从机必须配置主机名,用于主机启动从机实例:
代码17
在主机名没有内网DNS解析支持情况下,需要在/etc/hosts文件中手动配置主机名和IP地址映射关系,若是集群很大,维护成本高。如何办呢,我增加了IP直连特性支持:https://github.com/weibomobile/tsung/ ,需要时检出编译即可使用。
这样压测从机可以直接填写IP地址:
xml <client weight="1" maxusers="50000" host="client20"> <ip value="10.10.10.20"></ip> </client>其次,在Tsung启动时需要指定-I参数,并填写压测主机IP地址(可以通过Linux代码自动获取):
bash tsung -I 压测主机IP地址 -r rsh_client.sh -f tsung.xml start这样改造之后,让Tsung分布式集群在复杂网络机房内网环境下适应性向前迈了一大步。
性能压测流程驱动
压测之前,我们一般需要关注哪些东西呢,其实大家做法差不多,可以列一个清单:
- 添加计数器,可以发送到计数收集服务器,报表显示等;
- 核心逻辑做好日志记录,但日志记录过多时,可能也会成为瓶颈,需要取舍日志等级等;
- 区分核心模块和非核心模块的在资源紧张时是否需要区别对待等。
压测中,大家一般都是紧密盯着各项报表,查看服务器各项资源开销等。有一点需要强调的是,尽量作为终端用户一员,亲身参与进去,这样才能够切身体验并切切实实感受到此时服务的质量。
压测后,复查各项报表,查看错误日志,结合刚才自身的体验等,认真思考修改问题,然后继续下一轮压力测试啦。
小结
如上所述,我们在没有空闲服务器情况下因地制宜,充分利用服务器空闲计算资源运行Tsung(有所增强、修改)分布式压测集群,让整体费用成本接近于零,同时也使之成为一项基础工具套件,为研发的同学提供足够多的支持。
在这一利器推动下,保证了我们整个聊天室项目的处理性能能够按照预期方式向前推进,有时还会有一点小惊喜:
系统处理性能,由项目之初单机服务1万用户,优化到单机处理50万用户的飞跃;
- 从上线之初服务支持50万用户,到后面支持1000万;
- 项目日常迭代,及时避免并修正了因额外功能引入的系统崩溃隐患;
- 激发了技术创新,期间收获了3项技术创新专利;
- 勤奋有心的同学,虽然经验欠缺,但被推着不停的发现问题、思考、解决问题,你可以看到他们成长的轨迹。
虽然看上去这一利器功不可没,但工具就是工具,关键还要看使用的人,是否能够一直坚持进行下去,是否可以贯穿于整个研发周期;但知易行难,需去除惰性,坚持下去,形成一种习惯,成为日常的业务流程(如图7)的一个组成部分,否则只能是摆设。

性能压测驱动
另外,希望能够给同样境遇的同学提供一种思路,或受限于SSH不可用而放弃搭建Tsung集群,或因地制宜需要稍作定制满足特殊业务,或直接使用我们开源增强版Tsung避免走弯路,或者直接使用Docker等。总之使用Tsung做海量用户的压测,它不会让你失望的。
订阅程序员(含iOS、Android及印刷版)请访问 http://dingyue.programmer.com.cn
![]()
订阅咨询:
- 在线咨询(QQ):2251809102
- 电话咨询:010-64351436
- 更多消息,欢迎关注“程序员编辑部”
新浪微博百万用户分布式压测实践手记相关推荐
- 性能测试搭建Jmeter分布式压测与监控
对于运维工程师来说,需要对自己维护的服务器性能瓶颈了如指掌,比如我当前的架构每秒并发是多少,我服务器最大能接受的并发是多少,是什么导致我的性能有问题:如果当前架构快达到性能瓶颈了,是横向扩容性能提升大 ...
- 搭建 Apache Jmeter 分布式压测与监控
1.前言 对于运维工程师来说,需要对自己维护的服务器性能瓶颈了如指掌,比如我当前的架构每秒并发是多少,我服务器最大能接受的并发是多少,是什么导致我的性能有问题:如果当前架构快达到性能瓶颈了,是横向扩容 ...
- Jmeter分布式压测介绍、原理及实操(一台master-windows控制机,三台slaves-linux负载机)
前言:大家在使用jmeter压测过程中,可能会度遇到内存溢出的错误,这是为什么呢? 因为jmeter是java写的应用,java应用jvm堆内存heap受负载机硬件限制,虽然我们可以调整堆内存大小,但 ...
- 案例 | 荔枝微课基于 kubernetes 搭建分布式压测系统
王诚强,荔枝微课基础架构负责人.热衷于基础技术研发推广,致力于提供稳定高效的基础架构,推进了荔枝微课集群化从0到1的发展,云原生架构持续演进的实践者. 本文根据2021年4月10日深圳站举办的[腾讯云 ...
- 接口测试学习——jmeter分布式压测
分布式压测我理解的就是有一台主控机和几台压力机.主控机通过远程控制压力机启动测试,来实现系统不同级别访问量情况下的性能验证.操作步骤如下: 1.启动jmeter自动化工具,界面显示如下图所示. 2.在 ...
- jmeter分布式压测原理简介1
1.什么叫分布式压测? 分布式压测:模拟多台机器向目标机器产生压力,模拟几万用户并发访问 2.分布式压测原理:如下 3.更多补充.....待添加 转载于:https://www.cnblogs.com ...
- 分布式压测系列之Jmeter4.0第一季
1)Jmeter4.0介绍 jmeter是个纯java编写的开源压测工具,apache旗下的开源软件,一开始是设计为web测试的软件,由于发展迅猛,现在可以压测许多协议比如:http.https.so ...
- 分布式压测系列之Jmeter4.0
1)Jmeter4.0介绍 jmeter是个纯java编写的开源压测工具,apache旗下的开源软件,一开始是设计为web测试的软件,由于发展迅猛,现在可以压测许多协议比如:http.https.so ...
- Jeecgboot Feign、分布式压测、分布式任务调度
分布式压测 需求场景 一些关键接口需要压测到很高的QPS需要设置更多的线程去模拟虚拟用户去请求接口假如需要模拟2万个用户因为jemeter使用java语言开发每创建一个线程jvm默认会为每个线程分配1 ...
最新文章
- 【Flutter】顶部导航栏实现 ( Scaffold | DefaultTabController | TabBar | Tab | TabBarView )
- Codeforces Hello 2018!C
- 有三AI一周年了,说说我们的初衷,生态和愿景
- thymeleaf 获取yml中的值_SpringBoot引入Thymeleaf
- Python中__new__和__init__的区别与联系
- XorPay.com 支付平台介绍【支持个人申请】
- Pandas图表自定义数据格式
- 限制ul显示高度_HP Envy 34寸超宽曲屏 显示器评测
- 实现分页的通用存储过程
- 用gRPC建设微服务,Proto 怎么管理更合适
- bfs-poj-Bloxorz I
- Node安装模块命令
- 全国草地资源类型分布数据/植被类型分布数据/土地利用类型分布数据
- 原创拟态UI3.0-一款完全开源的个人主页源码
- MATLAB 自带RS编码函数中 gf 数据转化为 double 数组的方法
- js把txt转为html,js格式化文本为html标签
- windows系统重装步骤
- 面部关键特征点(Landmark)的定位
- MAC安装unrar
- 模拟复杂红绿灯交通指示程序编程显示黄灯闪烁箭头指示
热门文章
- HTTPS协议是如何实现“秘密交互”的?
- 自媒体形式下的个人设计(面向用户)—博客,QQ空间等个人主页的设计
- weboffice批注 java_Java开发调用PageOffice提供的Word手写批注接口
- 全球+中国+各省市自治区高清矢量地图汇总
- 在windoes系统中github访问出现的问题及解决办法
- 抖音实战~发布短视频流程梳理
- 磁通 磁通量 磁链 磁通密度 磁场强度 交流磁通密度 直流磁通密度 最大磁通密度 ... .. ...
- python西游之路
- 【已解决】在react+ts中 atnd 用 upload 组件报错Failed to execute ‘readAsArrayBuffer,param 1 is notof type Blob
- 【构建ML驱动的应用程序】第 6 章 :调试 ML 问题