【一文带你读懂机器学习】线性回归原理
一.什么是线性回归
在讲解线性回归之前,我们来看一组数据
| 姓名 | 房屋单价(元/平方米) | 房屋面积(平方米) | 房屋总价(元) |
|---|---|---|---|
| 张三 | 6000 | 58 | 30000 |
| 李四 | 9000 | 77 | 55010 |
| 王五 | 11000 | 89 | 73542 |
| 赵六 | 15000 | 54 | 63201 |
以上例子是关于房屋价格的数据。
这个表格表包含了 房屋总价 与 房屋单价 和 房屋面积 等数据。
特征:其中 x1x_1x1为 房屋单价 ,x2x_2x2为 房屋面积 ,两者即为 特征。
标签:y为 房屋总价 ,我们称作为标签
我们可以利用一个线性函数来拟合给定的 房屋总价 与 房屋单价 和 房屋面积 数据,训练出模型hθh_\thetahθ
如果给定我们一组新的数据,只包含 房屋单价 和 房屋面积 ,而不包含 房屋总价 的话,我们就能根据训练出来的模型hθh_\thetahθ来预测新的 房屋总价
hθ(x)=θ0+θ1x1+θ2x2h_\theta(x) =\theta_0+\theta_1x_1+\theta_2x_2hθ(x)=θ0+θ1x1+θ2x2
参数:θ1\theta_1θ1和θ2\theta_2θ2我们称作为参数,表示的是x1x_1x1和x2x_2x2两个特征对于目标函数的重要度
偏置项:θ0\theta_0θ0表示的是偏置项
目标函数值:hθh_\thetahθ是我们通过模型预测出来的房屋总价,即目标函数值。
上面的这个式子是当一个模型只有两个特征(x1x_1x1,x2x_2x2)的时候的线性回归式子。
正常情况下,房屋总价和很多特征相关联,并不只是简单的这两个特征。所以我们需要把这个式子进行通用化。
假如有n个特征的话,那么式子就会变成下面的样子
hθ(x)=θ0+θ1x1+θ2x2+...+θnxn=θ0+∑i=1nθixih_\theta(x) =\theta_0+ \theta_1x_1+\theta_2x_2+...+\theta_nx_n=\theta_0+\sum_{i=1}^{n}\theta_ix_ihθ(x)=θ0+θ1x1+θ2x2+...+θnxn=θ0+∑i=1nθixi 式①
上面的式子是一个多项求和的式子,我们将其向量化表示如下:
我们令θ=[θ1θ2θ3...θn]\theta=\begin{bmatrix}\theta_1\\\\ \theta_2\\\\ \theta_3\\\\ ...\\\\ \theta_n\end{bmatrix}θ=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡θ1θ2θ3...θn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤,x=[x1x2x3...xn]x=\begin{bmatrix}x_1\\\\ x_2\\\\ x_3\\\\ ...\\\\ x_n\end{bmatrix}x=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x1x2x3...xn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤,
则式①表示为:
hθ(x)=θ0+[θ1,θ2,θ3,...θn][x1x2x3...xn]=∑i=1nθixi=θ0+θTXh_\theta(x) =\theta_0+\begin{bmatrix}\theta_1,& \theta_2,&\theta_3,&...&\theta_n\end{bmatrix} \begin{bmatrix}x_1\\\\ x_2\\\\ x_3\\\\ ...\\\\ x_n\end{bmatrix}=\sum_{i=1}^{n}\theta_ix_i=\theta_0+\theta^TXhθ(x)=θ0+[θ1,θ2,θ3,...θn]⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x1x2x3...xn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=i=1∑nθixi=θ0+θTX
通常情况下,我们为了消除偏置项的显示,使得方程更为简洁,我们单独增加一个为1的特征,则我们重新令
θ=[θ0θ1θ2θ3...θn]\theta=\begin{bmatrix}\theta_0\\\\\theta_1\\\\ \theta_2\\\\ \theta_3\\\\ ...\\\\ \theta_n\end{bmatrix}θ=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡θ0θ1θ2θ3...θn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤,x=[1x1x2x3...xn]x=\begin{bmatrix}1\\\\x_1\\\\ x_2\\\\ x_3\\\\ ...\\\\ x_n\end{bmatrix}x=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡1x1x2x3...xn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤,则hθh_\thetahθ则简化为hθ(x)=θTXh_\theta(x) =\theta^TXhθ(x)=θTX 式②
因此,我们称式②为线性回归的假设函数,即线性回归模型。
二.线性回归的损失函数
2.1损失函数的定义
我们通常需要一个机制去评估我们训练出来的模型hθh_\thetahθ的好坏,我对模型hθh_\thetahθ进行评估,一般这个机制称之为损失函数(loss function或者错误函数(error function),用来描述h函数不好的程度,我们通常用JθJ_\thetaJθ表示,而对于线性回归模型,我们通常用以下式子来作为其损失函数:
J(θ)=12∑i=1m(hθ(x(i))−y(i))2J(\theta)= \frac{1}{2}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2J(θ)=21i=1∑m(hθ(x(i))−y(i))2
我们的目的就是求得使得损失函数J(θ)J(\theta)J(θ)的值为最小值的时候,对应的θ\thetaθ的取值,从而得到我们最优的模型hθ(x)h_\theta(x)hθ(x)
2.2损失函数的推导过程(最大似然估计与最小二乘法)
我们刚才已经提到J(θ)=12∑i=1m(hθ(x(i))−y(i))2J(\theta)= \frac{1}{2}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2J(θ)=21∑i=1m(hθ(x(i))−y(i))2为我们的损失函数,那么,它是如何得到的呢?
接下来,就让我们根据极大似然估计推导进行推导
在推导之前让我们来看下面这一张图:
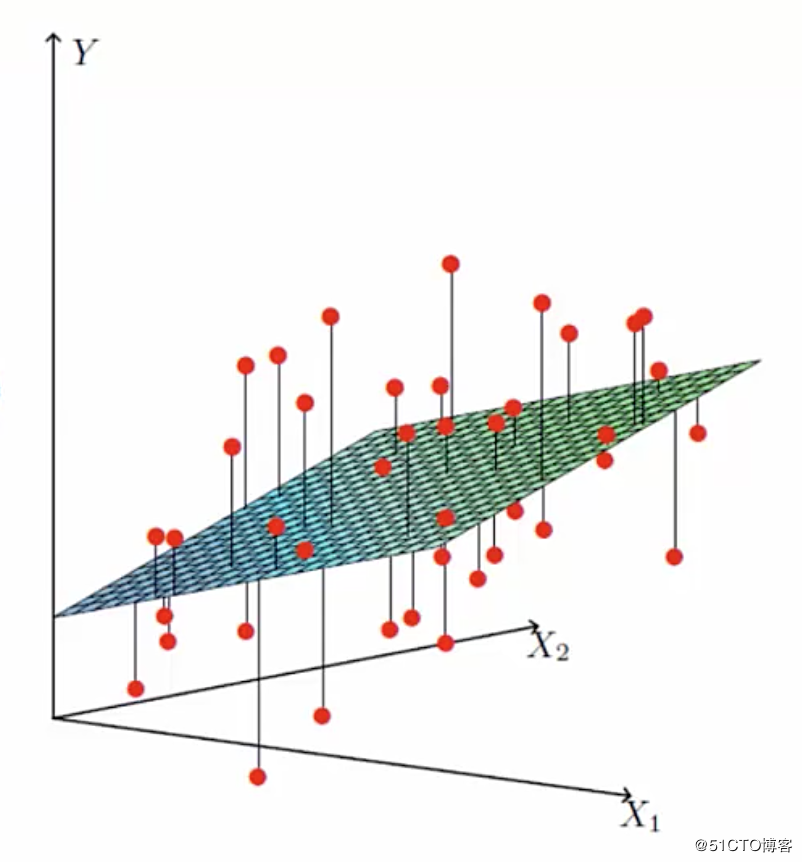
图中的横坐标X1 和 X2 分别代表着 两个特征(房屋单价、房屋面积) 。纵坐标Y代表标签值(房屋总价)。
其中红点代表的就是实际的标签值(房屋总价).而平面上和红点竖向相交的点代表着我们根据线性回归模型得到的预测值。
也就是说实际的标签值和预估的值之间是有一定误差的,这个就是误差项,
我们记为ε(i)\varepsilon^{(i)}ε(i)。因此我们有
y(i)=hθ(x(i))+ε(i)=θTx(i)+ε(i)式③y^{(i)}=h_\theta(x^{(i)})+\varepsilon^{(i)}=\theta^Tx^{(i)}+\varepsilon^{(i)} 式③y(i)=hθ(x(i))+ε(i)=θTx(i)+ε(i) 式③
因为误差项是真实值和误差值之间的一个差距。那么肯定我们希望误差项越小越好。
在这里我们假设误差项ε(i)\varepsilon^{(i)}ε(i)是独立的并且具有相同的分布的,并且服从均值为0,标准偏差为σ\sigmaσ的高斯分布
解释:
1.独立:张三和李四购买的房子,房子总价之间互不影响
2.具有相同分布:张三和李四是买的的是同一座城市的房子
3.高斯分布:绝大多数的情况下,在一个空间内浮动不大
下面是高斯分布的图像,忘记的同学们可以回忆下。
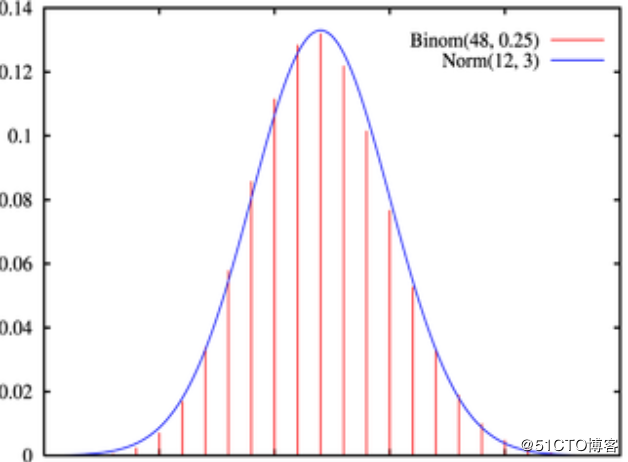
由于我们假设ε(i)\varepsilon^{(i)}ε(i)是符合高斯分布的因此,我们关于ε(i)\varepsilon^{(i)}ε(i)的概率密度函数为:
p(ε(i))=12πσexp(−(ε(i))22σ2)式④p(\varepsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{({\varepsilon^{(i)}})^2}{2\sigma^2 }) 式④p(ε(i))=2πσ1exp(−2σ2(ε(i))2)式④
由 式③ 和 式④
p(y(i)∣x(i);θ)=12πσexp(−(y(i)−θTx(i))22σ2)p(y^{(i)}|x^{(i)};\theta) =\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{({y^{(i)}-\theta^Tx^{(i)}})^2}{2\sigma^2 })p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−θTx(i))2)
p(y(i)∣x(i);θ)p(y^{(i)}|x^{(i)};\theta)p(y(i)∣x(i);θ)表示的意思是,在θ\thetaθ已知的情况下,在x(i)x^{(i)}x(i)发生的条件下,y(i)y^{(i)}y(i)发生的条件概率
误差项肯定是越小越好了,那么接下来要讨论的就是什么样的参数和特征的组合能够让误差项最小呢?
这里就引入了似然函数。
似然函数的作用就是要根据样本来求什么样的参数和特征的组成能够最接近真实值。越接近真实值则误差越小。
因此,似然函数为
L(θ)=∏i=1mp(y(i)∥x(i);θ)=∏i=1m12πσexp(−(y(i)−θTx(i))22σ2)L(\theta) = \prod_{i=1}^{m}{p(y^{(i)}\|x^{(i)};\theta)}\\\\ = \prod_{i=1}^{m}\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{({y^{(i)}-\theta^Tx^{(i)}})^2}{2\sigma^2 }) L(θ)=i=1∏mp(y(i)∥x(i);θ)=i=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)
由极大似然估计的定义,我们需要L(θ)L(\theta)L(θ)最大,那么我们怎么才能是的这个值最大呢?
为了计算方便,两边取对数logloglog把多个数相乘,转化成多个数相加的形式,对这个表达式进行化简如下:
logL(θ)=log∏i=1mp(y(i)∥x(i);θ)=∑i=1mlog12πσexp(−(y(i)−θTx(i))22σ2)=mlog12πσ−12σ2∑i=1m(y(i)−θTx(i))2logL(\theta) =log \prod_{i=1}^{m}{p(y^{(i)}\|x^{(i)};\theta)}\\\\ = \sum_{i=1}^{m}log\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{({y^{(i)}-\theta^Tx^{(i)}})^2}{2\sigma^2 })\\\\ = mlog\frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{2\sigma^2} \sum_{i=1}^{m}{({y^{(i)}-\theta^Tx^{(i)}})^2} logL(θ)=logi=1∏mp(y(i)∥x(i);θ)=i=1∑mlog2πσ1exp(−2σ2(y(i)−θTx(i))2)=mlog2πσ1−2σ21i=1∑m(y(i)−θTx(i))2
记l(θ)=logL(θ)l(\theta)=logL(\theta)l(θ)=logL(θ)
则l(θ)=mlog12πσ−12σ2∑i=1m(y(i)−θTx(i))2l(\theta)=mlog\frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{2\sigma^2} \sum_{i=1}^{m}{({y^{(i)}-\theta^Tx^{(i)}})^2}l(θ)=mlog2πσ1−2σ21i=1∑m(y(i)−θTx(i))2
要使得l(θ)l(\theta)l(θ)最大,由于
mlog12πσmlog\frac{1}{\sqrt{2\pi}\sigma}mlog2πσ1是常数,
只要使得−12σ2∑i=1m(y(i)−θTx(i))2-\frac{1}{2\sigma^2} \sum_{i=1}^{m}{({y^{(i)}-\theta^Tx^{(i)}})^2}−2σ21∑i=1m(y(i)−θTx(i))2最大即可
也就是使得−12∑i=1m(y(i)−θTx(i))2-\frac{1}{2} \sum_{i=1}^{m}{({y^{(i)}-\theta^Tx^{(i)}})^2}−21∑i=1m(y(i)−θTx(i))2最大即可,即
12∑i=1m(y(i)−θTx(i))2\frac{1}{2} \sum_{i=1}^{m}{({y^{(i)}-\theta^Tx^{(i)}})^2}21∑i=1m(y(i)−θTx(i))2最小即可
我们记
J(θ)=12∑i=1m(hθ(x(i))−y(i))2J(\theta)= \frac{1}{2}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2J(θ)=21∑i=1m(hθ(x(i))−y(i))2 (最小二乘法)
所以,我们最后由极大似然估计推导得出,我们希望 J(θ)J(\theta)J(θ)最小,而这刚好就是最小二乘法做的工作。
而回过头来我们发现,之所以最小二乘法有道理,是因为我们之前假设误差项服从高斯分布,假如我们假设它服从别的分布,那么最后的目标函数的形式也会相应变化。
好了,上边我们得到了有极大似然估计或者最小二乘法。
我们的模型求解需要最小化目标函数J(θ)J(\theta)J(θ)。
那么我们的θ\thetaθ到底怎么求解呢?有没有一个解析式可以表示θ\thetaθ?
接下来,我们就对θ\thetaθ进行求解
三.正规方程求解θ\thetaθ
在上一节,我们推导得到线性回归模型的损失函数为:
J(θ)=12∑i=1m(hθ(x(i))−y(i))2=12(Xθ−Y)T(Xθ−Y)=12((Xθ)T−YT)(Xθ−Y)=12(θTXT−YT)(Xθ−Y)=12(θTXTXθ−θTXTY−YTXθ+YTY)J(\theta) = \frac{1}{2}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2\\\\ = \frac{1}{2}(X\theta-Y)^T(X\theta-Y)\\\\ = \frac{1}{2}({(X\theta)}^T-Y^T)(X\theta-Y)\\\\ = \frac{1}{2}(\theta^TX^T-Y^T)(X\theta-Y)\\\\ = \frac{1}{2}(\theta^TX^TX\theta-\theta^TX^TY-Y^TX\theta+Y^TY) J(θ)=21i=1∑m(hθ(x(i))−y(i))2=21(Xθ−Y)T(Xθ−Y)=21((Xθ)T−YT)(Xθ−Y)=21(θTXT−YT)(Xθ−Y)=21(θTXTXθ−θTXTY−YTXθ+YTY)
要求J(θ)J(\theta)J(θ)的最小值所对应的θ\thetaθ值,即求驻点,我们让∂J(θ)∂θ=0\frac{\partial J(\theta)}{\partial \theta}=0∂θ∂J(θ)=0即可
因为J(θ)=12(θTXTXθ−θTXTY−YTXθ+YTY)J(\theta) = \frac{1}{2}(\theta^TX^TX\theta-\theta^TX^TY-Y^TX\theta+Y^TY) J(θ)=21(θTXTXθ−θTXTY−YTXθ+YTY)
所以
∂J(θ)∂θ=12(2XTXθ−XTY−(YTX)T)=12(2XTXθ−XTY−XTY)=12(2XTXθ−2XTY)=XTXθ−XTY\frac{\partial J(\theta)}{\partial \theta} = \frac{1}{2}(2X^TX\theta-X^TY-(Y^TX)^T)\\= \frac{1}{2}(2X^TX\theta-X^TY-X^TY)\\ = \frac{1}{2}(2X^TX\theta-2X^TY)\\= X^TX\theta-X^TY ∂θ∂J(θ)=21(2XTXθ−XTY−(YTX)T)=21(2XTXθ−XTY−XTY)=21(2XTXθ−2XTY)=XTXθ−XTY
因为∂J(θ)∂θ=0\frac{\partial J(\theta)}{\partial \theta}=0∂θ∂J(θ)=0即XTXθ−XTY=0X^TX\theta-X^TY=0XTXθ−XTY=0
则XTXθ=XTYX^TX\theta=X^TYXTXθ=XTY
因此
θ=(XTX)−1XTY\theta=(X^TX)^{-1}X^TYθ=(XTX)−1XTY
至此,我们就可以求得到θ\thetaθ的值了
上述最后一步有一些问题,假如 XTXX^TXXTX不可逆呢?
我们知道 XTXX^TXXTX 是一个半正定矩阵,所以若XTXX^TXXTX 不可逆或为了防止过拟合,我们增加λ\lambdaλ扰动,得到
θ=(XTX+λI)−1XTY\theta=(X^TX+\lambda I)^{-1}X^TYθ=(XTX+λI)−1XTY
三.梯度下降法求解θ\thetaθ
在上边我们用正规方程求解出了参数θ\thetaθ,实际python 的 numpy库就是使用的这种方法。
但是,这仅仅适用于参数维度不大的情况下,通常我们在项目工程中,参数的维度是相当大的,使用正规方程求解就不适用了,这里我们用梯度下降算法求解θ\thetaθ。
梯度下降算法是一个最优化算法,它是沿梯度下降的方向求解损失函数J(θ)J(\theta)J(θ)极小值。
损失函数:J(θ)=12m∑i=1m(hθ(x(i))−y(i))2损失函数:J(\theta)= \frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2损失函数:J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
这个损失函数是我们之前推导出来的最小二乘的公式。只不过1/2后面多了个m。m是总的数据量。意味着是求多个数据之后的平均值。
我们的目标是
minimizeθJ(θ)minimize_{\theta}J(\theta)minimizeθJ(θ)
3.1梯度下降的通俗理解:
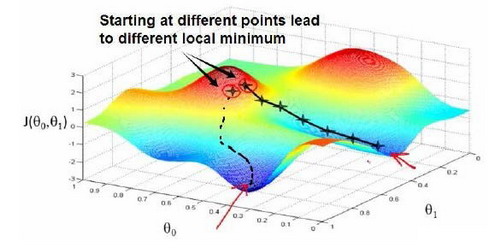
想象一下你正站立在这座红色山上。
在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的一点,你看一下周围,你会发现最佳的下山方向。
你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步。
重复上面的步骤,直到你接近局部最低点的位置。
3.2梯度下降法的具体过程:
梯度下降法的具体过程如下:
1)对θ\thetaθ进行初始化。
我们可以随机初始化,或者初始化为全零的向量。
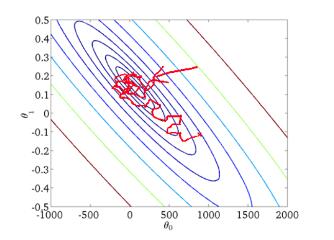
图片中红圈上的点,从上面的图可以看出:初始点不同,获得的最小值也不同,因此梯度下降求得的只是局部最小值;
2)确定学习率(Learning rate)α\alphaα
学习率可以理解为下山时每一步迈的大小。
步子迈得太大有可能不收敛,无法到达山的最低处,即损失函数的最小值处。
步子迈的太小下山速度太慢。
**工程经验:**学习率我们可以先使用0.1试下,如果不收敛或者收敛慢,再试0.01、0.001。
**小窍门:**学习率并不一定全程不变,可以刚开始的时候大一些,后期的时候不断调小。
3)沿着负梯度方向更新θ\thetaθ。
采用负梯度方向的原因是负梯度方向是函数值减小的最快的方向
θ:=θ−α⋅∂J(θ)∂θ\theta := \theta - \alpha\cdot \frac{\partial J(\theta)}{\partial \theta} θ:=θ−α⋅∂θ∂J(θ)
在线性回归中,
4)训练终止。
不断重复步骤3)
损失函数达到预设值的一个值,或者收敛不明显时,可以终止训练。
最后得到一个局部最优解,不一定是全局最优,但是是堪用的。
此时所对应的θ\thetaθ的值就是所求的θ\thetaθ
3.3梯度下降法的分类:
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)以及小批量梯度下降(Mini-Batch Gradient Descent)。其中小批量梯度下降法也常用在深度学习中进行模型的训练。接下来,我们将对这三种不同的梯度下降法进行理解。
为了便于理解,这里我们将使用只含有一个特征的线性回归来展开。此时线性回归的假设函数为:
hθ(x(i))=θ1x(i)+θ0h_{\theta} (x^{(i)})=\theta_1 x^{(i)}+\theta_0hθ(x(i))=θ1x(i)+θ0
其中,i=1,2,...,mi=1,2,...,mi=1,2,...,m表示样本数。
对应的**目标函数(代价函数)**即为:
J(θ0,θ1)=12m∑i=1m(hθ(x(i))−y(i))2J(\theta_0, \theta_1) = \frac{1}{2m} \sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)})^2J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
下图为J(θ0,θ1)J(\theta_0,\theta_1)J(θ0,θ1) 与参数 θ0,θ1\theta_0,\theta_1θ0,θ1的关系的图:

3.3.1、批量梯度下降(Batch Gradient Descent,BGD)
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。从数学上理解如下:
(1)对目标函数求偏导:
ΔJ(θ0,θ1)Δθj=1m∑i=1m(hθ(x(i))−y(i))xj(i)\frac{\Delta J(\theta_0,\theta_1)}{\Delta \theta_j} = \frac{1}{m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)}ΔθjΔJ(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))xj(i)
其中i=1,2,...,mi=1,2,...,mi=1,2,...,m 表示样本数, j=0,1j=0,1j=0,1 表示特征数,这里我们使用了 偏置项 x0(i)=1x_0^{(i)} = 1x0(i)=1
2)每次迭代对参数进行更新:
θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))xj(i)\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)}θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
注意这里更新时存在一个求和函数,即为对所有样本进行计算处理,可与下文SGD法进行比较。
伪代码形式为:
repeat{
θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))xj(i)(forj=0,1)\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)} (for j =0,1)θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)(forj=0,1)
}
优点:
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
(1)当样本数目 m 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
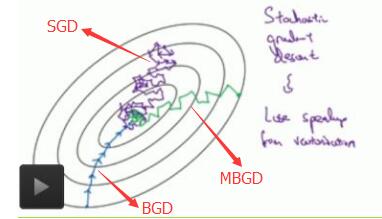
从迭代的次数上来看,BGD迭代的次数相对较少。其迭代的收敛曲线示意图可以表示如下:
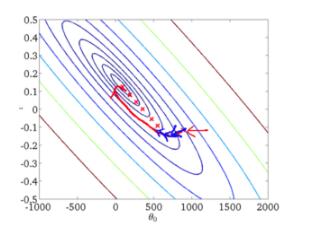
3.3.2随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降法不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快。
对于一个样本的目标函数为:
J(i)(θ0,θ1)=12(hθ(x(i))−y(i))2J^{(i)}(\theta_0,\theta_1) = \frac{1}{2}(h_{\theta}(x^{(i)})-y^{(i)})^2J(i)(θ0,θ1)=21(hθ(x(i))−y(i))2
(1)对目标函数求偏导:
ΔJ(i)(θ0,θ1)θj=(hθ(x(i))−y(i))xj(i)\frac{\Delta J^{(i)}(\theta_0,\theta_1)}{\theta_j} = (h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}_jθjΔJ(i)(θ0,θ1)=(hθ(x(i))−y(i))xj(i)
(2)参数更新:
θj:=θj−α(hθ(x(i))−y(i))xj(i)\theta_j := \theta_j - \alpha (h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}_jθj:=θj−α(hθ(x(i))−y(i))xj(i)
注意,这里不再有求和符号
伪代码形式:
repeat{
for i=1,…,m{
θj:=θj−α(hθ(x(i))−y(i))xj(i)\theta_j := \theta_j -\alpha (h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)}θj:=θj−α(hθ(x(i))−y(i))xj(i)
(for j =0,1)
}
}
优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
解释一下为什么SGD收敛速度比BGD要快:
答:这里我们假设有30W个样本,对于BGD而言,每次迭代需要计算30W个样本才能对参数进行一次更新,需要求得最小值可能需要多次迭代(假设这里是10);而对于SGD,每次更新参数只需要一个样本,因此若使用这30W个样本进行参数更新,则参数会被更新(迭代)30W次,而这期间,SGD就能保证能够收敛到一个合适的最小值上了。也就是说,在收敛时,BGD计算了 10×30W 次,而SGD只计算了 1×30W 次。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图可以表示如下:
3.3.3 mini-batch梯度下降法
小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代 使用 batch_size 个样本来对参数进行更新。
这里我们假设 batchsize=10batchsize=10batchsize=10 ,样本数 m=1000m=1000m=1000 。
伪代码形式为:
repeat{
for i=1,11,21,31,…,991{
θj:=θj−α110∑k=i(i+9)(hθ(x(k))−y(k))xj(k)\theta_j := \theta_j - \alpha \frac{1}{10} \sum_{k=i}^{(i+9)}(h_{\theta}(x^{(k)})-y^{(k)})x_j^{(k)}θj:=θj−α101k=i∑(i+9)(hθ(x(k))−y(k))xj(k)
(for j =0,1)
}
}
优点:
(1)通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
(2)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代3000次,远小于SGD的30W次)
(3)可实现并行化。
缺点:
(1)batch_size的不当选择可能会带来一些问题。
batcha_size的选择带来的影响:
(1)在合理地范围内,增大batch_size的好处:
a. 内存利用率提高了,大矩阵乘法的并行化效率提高。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
c. 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
(2)盲目增大batch_size的坏处:
a. 内存利用率提高了,但是内存容量可能撑不住了。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
c. Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
下图显示了三种梯度下降算法的收敛过程:
【一文带你读懂机器学习】线性回归原理相关推荐
- 机器学习中为什么需要梯度下降_机器学习101:一文带你读懂梯度下降
原标题 | Machine Learning 101: An Intuitive Introduction to Gradient Descent 作者 | Thalles Silva 译者 | 汪鹏 ...
- DNN、RNN、CNN.…..一文带你读懂这些绕晕人的名词
DNN.RNN.CNN.-..一文带你读懂这些绕晕人的名词 https://mp.weixin.qq.com/s/-A9UVk0O0oDMavywRGIKyQ 「撞脸」一直都是娱乐圈一大笑梗. 要是买 ...
- 一文带您读懂FCC、CE、CCC认证的区别
一文带您读懂FCC.CE.CCC认证的区别 参考资料:https://3g.k.sohu.com/t/n411629823 FCC认证,CE认证,CCC认证是产品认证中比较常见的几个认证,前两者经常有 ...
- 一文带你读懂HTTP协议的前世今生
点击上方蓝字关注我们 HTTP,Hypertext Transfer Protocol,超文本协议,是在万维网上传输文件(如文本.图形图像.声音.视频和其他多媒体文件)的规则集.如果web用户打开他们 ...
- 用程序员计算机算进制,一文带你读懂计算机进制
hi,大家好,我是开发者FTD.在我们的学习和工作中少不了与进制打交道,从出生开始上学,最早接触的就是十进制,当大家学习和使用计算机时候,我们又接触到了二进制.八进制以及十六进制.那么大家对进制的认识 ...
- 一文带你读懂“经典TRIZ”
本文承接上文<一文带第读懂TRIZ>,下面开始看第二个问题:什么是"经典TRIZ"? 很多书里都有对TRIZ的产生与发展的描述. 我个人在看了很多的书和文献以后,认为: ...
- 简单一文带你读懂Java变量的作用和三要素
Java变量的作用 不只是java,在其他的编程语言中变量的作用只有一个:存储值(数据) 在java中,变量本质上是一块内存区域,数据存储在java虚拟机(JVM)内存中 变量的三要素 变量的三要素分 ...
- 一文带你读懂感知机的前世今生(上)
一文带你读懂感知机的前世今生 前言 男女不分 什么是神经元 M-P神经元 全或无定律 McCulloch和Pitts 一种高度简化的模型 MP神经元和真值表 MP神经元的几何理解 后记 参考 前言 男 ...
- 《一文带你读懂:云原生时代业务监控》
点击上方蓝字关注我们! 对业务来说,完备的应用健康性和数据指标的监控非常重要,通过采集准确的监控指标.配置合理的告警机制,我们能够提前或者尽早发现问题,并做出响应.解决问题,进而保证产品的稳定性,提升 ...
- au加载默认的输入和输出设备失败_一文带你读懂 C/C++ 语言输入输出流与缓存区...
(给CPP开发者加星标,提升C/C++技能) 作者:技术让梦想更伟大 / 李肖遥 (本文来自作者投稿) 前言 有没有发现,基本上所有的C语言入门书籍,或者是我们的教程里面,第一个C语言程序实体,都是& ...
最新文章
- ASP.NET 2.0 绑定高级技巧
- QIIME 2用户文档. 22Python命令行模式(2019.7)
- Java开发面试题及答案,5年crud“经验
- 客户机系统已禁用cpu_Metricbeat System process metricset系统进程监控参数详情
- Linux 硬盘管理
- 项目管理与项目组合管理的不同
- php生产txt_PHP生成TXT资料
- Ubuntu 10.10 下安装spoonwep-wpa工具
- Supporting hyperplane
- [渝粤教育] 西南科技大学 语言学概论(英语) 在线考试复习资料
- ICP备案线下注销 网站域名备案注销
- html鼠标放大镜效果,CSS3实现鼠标放大镜和放小镜的效果
- 小学生计算机按键分布图,小学生计算器上各种按键的作用
- VPN、IPSEC、AH、ESP、IKE、DSVPN
- 转 CSS兼容技巧整理--从IE6-IE9 火狐谷歌浏览器兼容
- Git关联多个远程仓库
- mac连接蓝牙耳机只有一个有声音
- 很多男性的瘦腰细腿比女性更骨感?原因告诉你,或许他们真没减肥
- 婴幼儿呼吸道感染和发烧
- Python实现孤立森林(IForest)+SVR的组合预测模型
热门文章
- python f检验 模型拟合度_Python 爬取北京二手房数据,分析北漂族买得起房吗? | 附完整源码...
- 阿卡索口语学习(Learn And Talk 0)短语及单词(二)
- 20.时空跳跃者的魔法
- Mac 解决终端:-bash: /Users/xxx/.profile: No such file or directory
- 完美解决Sudo doesn‘t work: “/etc/sudoers is owned by uid 1000, should be 0”
- 软件工程师职业规划_我如何在11个月内转变职业以成为软件工程师(以及如何也可以)...
- 北京“全面城市化”之后,你怎么看?
- 表格内容如何合并在一起
- OSChina 周五乱弹 —— 毁人不倦的大师们
- ADXL345 三轴加速度角度传感器