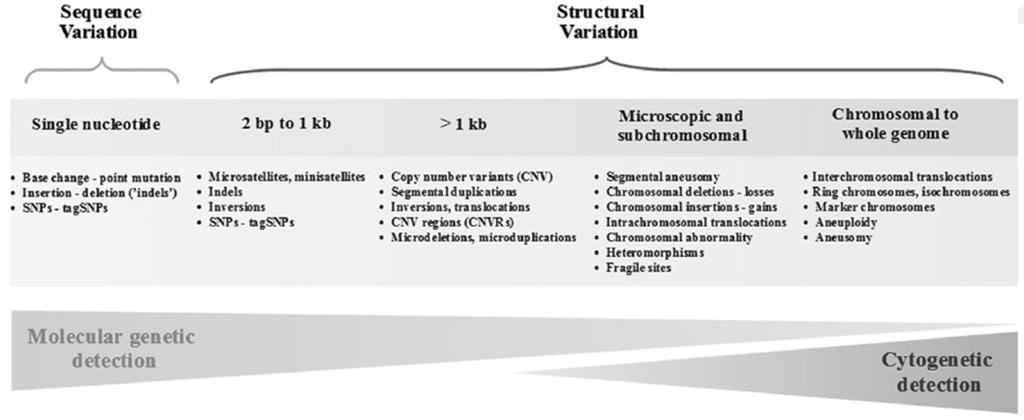
全基因组重测序数据分析
全基因组重测序数据分析
转自:http://www.biodiscover.com/news/research/95875.html
1. 简介(Introduction)
通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使得在disease(cancer)genome中的mutation产生对应的易感机制和功能。我们将在基因组学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。
实验设计与样本
(1)Case-Control 对照组设计 ;
(2)家庭成员组设计:父母-子女组(4人、3人组或多人);
初级数据分析
1.数据量产出: 总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。
2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。
3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。并根据参考基因组信息对检测到的变异进行注释。
4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。在检测过程中,gap的长度为1~5个碱基。对于每个InDel的检测,至少需要3个Paired-End序列的支持。
5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。根据测序个体序列与参考基因组序列比对分析结果,检测全基因组水平的结构变异并对检测到的变异进行注释。
高级数据分析
1.测序短序列匹配(Read Mapping)
(1)屏蔽掉Y染色体上假体染色体区域(pseudo-autosomal region), 将Read与参考序列NCBI36进行匹配(包括所有染色体,未定位的contig,以及线粒体序列mtDNA(将用校正的剑桥参考序列做替代))。采用标准序列匹配处理对原始序列文件进行基因组匹配, 将Read与参考基因组进行初始匹配;给出匹配的平均质量得分分布;
(2)碱基质量得分的校准。我们采用碱基质量校准算法对每个Read中每个碱基的质量进行评分,并校准一些显著性误差,包括来自测序循环和双核苷酸结构导致的误差。
(3)测序误差率估计。 pseudoautosomal contigs,short repeat regions(包括segmental duplication,simple repeat sequence-通过tandem repeat识别算法识别)将被过滤;
2. SNP Calling 计算 (SNP Calling)
我们可以采用整合多种SNP探测算法的结果,综合地,更准确地识别出SNP。通过对多种算法各自识别的SNP进行一致性分析,保留具有高度一致性的SNP作为最终SNP结果。这些具有高度一致性的SNP同时具有非常高的可信度。在分析中使用到的SNP识别算法包括基于贝叶斯和基因型似然值计算的方法,以及使用连锁不平衡LD或推断技术用于优化SNP识别检出的准确性。
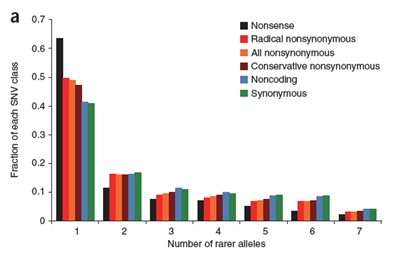
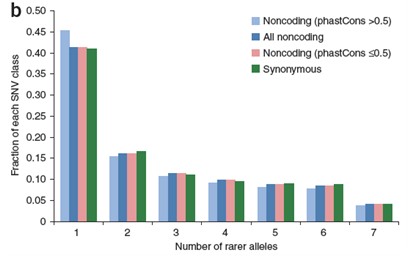
统计SNV的等位基因频率在全基因组上的分布
稀有等位基因数目在不同类别的SNV中的比率分布(a);SNV的类别主要考虑:(1)无义(nonsense),(2)化学结构中非同义,(3)所有非同义,(4)保守的非同义,(5)非编码,(6)同义,等类型SNV; 另外,针对保守性的讨论,我们将分析非编码区域SNV的保守型情况及其分布(图a, b)
3. 短插入/缺失探测(Short Insertion /Deletion (Indel)Call)
(1). 计算全基因组的indel变异和基因型检出值的过程
计算过程主要包含3步:(1)潜在的indel的探测;(2)通过局部重匹配计算基因型的似然值;(3)基于LD连锁不平衡的基因型推断和检出识别。Indel在X,Y染色体上没有检出值得出。
(2). Indel 过滤处理
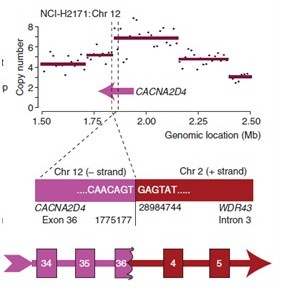
4. 融合基因的发现(Fusion gene Discovery)
选择注释的基因信息来自于当前最新版本的Ensemble Gene数据库,RefSeq数据库和Vega Gene数据库。下面图例给出的是融合基因的形成,即来自不同染色体的各自外显子经过重组形成融合基因的模式图。
5. 结构变异(Structure Variation)
结构变异(Structure Variation-SV)是基因组变异的一类主要来源,主要由大片段序列(一般>1kb)的拷贝数变异(copy number variation, CNV)以及非平衡倒位(unbalance inversion)事件构成。目前主要一些基因组研究探测识别的SV大约有20,000个(DGV数据库)。在某些区域上,甚至SV形成的速率要大于SNP的速率,并与疾病临床表型具有很大关联。我们不仅可以通过测序方式识别公共的SV,也可以识别全新的SV。全新的SV的生成一般在germ line和突变机制方面都具有所报道。然而,当前对SV的精确解析需要更好的算法实现。同时,我们也需要对SV的形成机制要有更重要的认知,尤其是SV否起始于祖先基因组座位的插入或缺失,而不简单的根据等位基因频率或则与参考基因组序列比对判断。SV的功能性也结合群体遗传学和进化生物学结合起来,我们综合的考察SV的形成机制类别。
SV形成机制分析,包括以下几种可能存在的主要机制的识别发现:
(A)同源性介导的直系同源序列区段重组(NAHR);
(B)与DNA双链断裂修复或复制叉停顿修复相关的非同源重组(NHR);
(C)通过扩展和压缩机制形成可变数量的串联重复序列(VNTR);
(D)转座元件插入(一般主要是长/短间隔序列元件LINE/SINE或者伴随TEI相关事件的两者的组合)。
结构变异探测和扩增子(Amplicon)的探测与识别分析:如下图所示

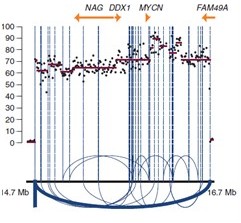
6. 测序深度分析
测序深度分析就是指根据基因组框内覆盖度深度与期望覆盖度深度进行关联,并识别出SV。我们也将采用不同算法识别原始测序数据中的缺失片段(deletion)和重复片段(duplication)。
7. SV探测识别结果的整合与FDR推断(可选步骤)
(1). PCR或者芯片方式验证SV
(2). 计算FDR-错误发现率(配合验证试验由客户指定)
(3) 筛选SV检出结果用于SV的合并和后续分析:我们通过不同方式探测识别SV的目的极大程度的检出SV,并且降低其FDR(<=10%)。通过下属筛选方法决定后续分析所使用到的SV集合。每种SV探测识别算法得到的SV的FDR要求小于10%,并将各自符合条件的SV合并;对于FDR大于10% 的算法计算识别的SV结果,如果有PCR和芯片平台验证数据,同样可以纳入后续SV分析中。最后,针对不同算法得到的SV,整合处理根据breakpoint断点左右重合覆盖度的置信区间来评定;
8. 变异属性分析
(1) neutral coalescent分析
测序数据可以探测到低频率的变异体(MAF<=5%)。根据来自群体遗传学理论(neutral coalescent理论)的期望值可以计算低频度变异的分布。我们用不同等位基因频率下每Mb变异数目与neutral coalescent 选择下的期望值比值,即每Mb 基因组windows内的theta观测值,来刻画和反映自然纯化选择与种群(cancer cell-line可以特定的认为是可以区分的种群)增长速率。该分布分别考察SNP(蓝色线),Indel(红色线),具有基因型的大片段缺失(黑色线),以及外显子区域上的 SNP(绿色线)在不同等位基因频率区间上的theta情况(参见下图)。
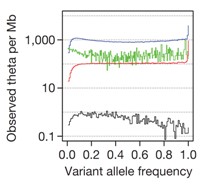
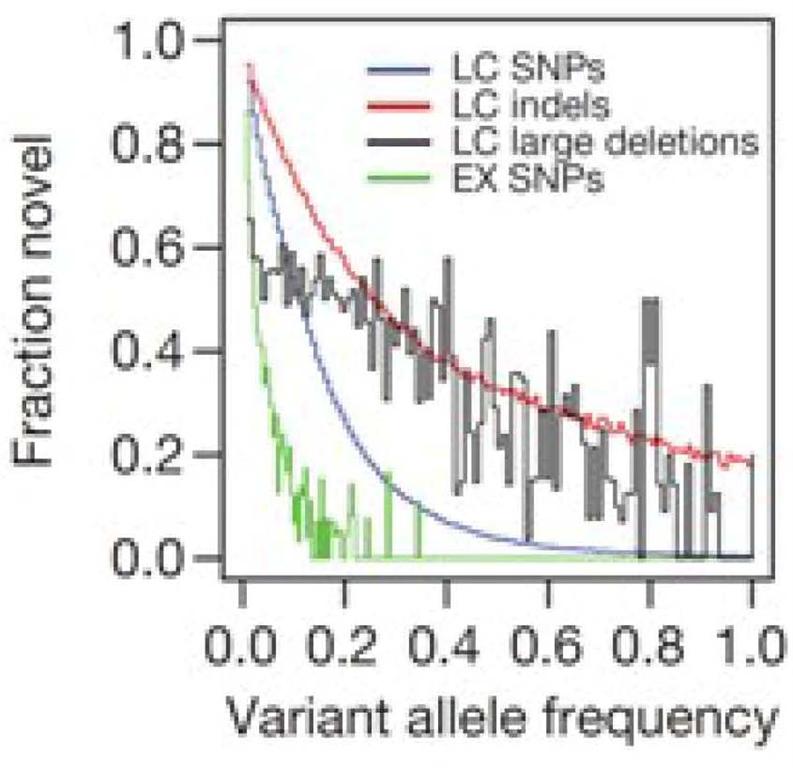
(2). 全新变异体(novel variant)的等位基因频率和数量分布
分析对象包括全新预测的SNP,indel,large deletion, 以及外显子SNP在每个等位基因频率类别下的数目比率(fraction)(参见下图);全新预测是指预测分析结果与dbSNP(当前版本129)以及deletion数据库dbVar(2010年6月份版本)和已经发表的有关indels研究的基因组数据经过比较后识别确定的全新的SNP,indel以及deletion。dbSNP包含SNP和indels; dbVAR包含有deletion,duplication,以及mobile element insertion。dbRIP以及其他基因组学研究(JC Ventrer 以及Watson 基因组,炎黄计划亚洲人基因组)结果提供的short indels和large deletion。
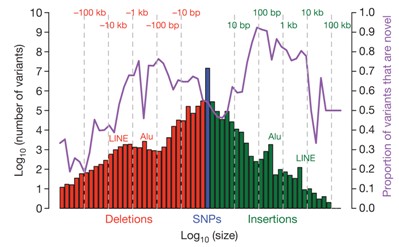
(3). 变异体的大小分布以及新颖性分布
计算SNP,Deletion,以及Insertion 大小分布;计算SNP,Deletion,以及Insertion中属于全新预测结果的数目占已有各自参考数据库数目的比例(相对于dbSNP数据库;dbSNP包含SNP和indels;dbVAR包含有deletion,duplication,以及mobile element insertion。dbRIP以及其他基因组学研究(JC Ventrer 以及Watson 基因组,炎黄计划亚洲人基因组)结果提供的short indels和large deletion)其中,可以给出LINE,Alu的特征位置。
(4). 结构变异SV的断点联结点(BreakPoint Junction)分析
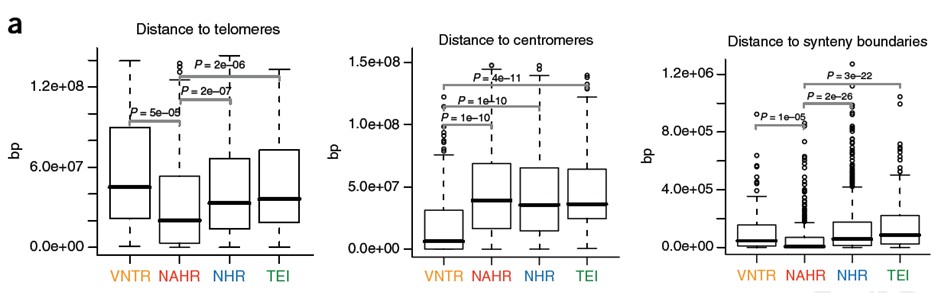
根据SV不同检出结果经过一些列筛选步骤构建所有结构变异SV的断点联结点数据库,保留长度大于等于50bp的SV;分析断点联结点处具有homology或者microhomology的SV;并将同一染色体,起始和终止位置坐标下的不同SV进行去冗余处理。
分析识别SV 的断点联结点(Breakpoint): 将Breakpoint按照可能形成的方式可以分类为以下几类:
(a)非等位基因同源重组型(non-allelic homologous recombination-NAHR);
(b)非同源重组(nonhomologous recombination-NHR),包括nonhomologous end-joining (NHEJ)和fork stalling /template switching(FoSTeS/MMBIR);
(c)可变串联重复(VNTR)
(d)转座插入元件(TEI)。
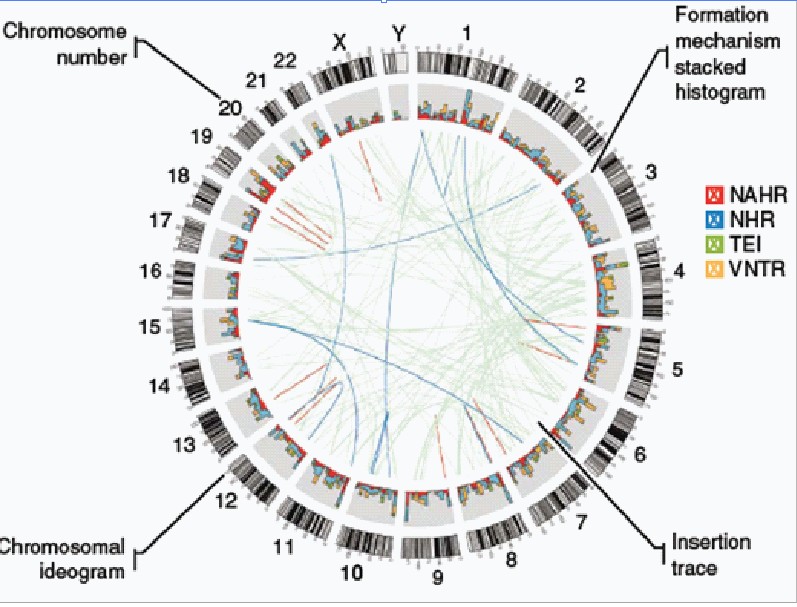
图 C
SV形成偏好性分析
分析SV形成机制与断裂点临近区域序列的关系,包括染色质界标(端粒,中心粒),重组高发热点区域,重复序列以及GC含量,短DNA motif和微同源区域(microhomology region)。
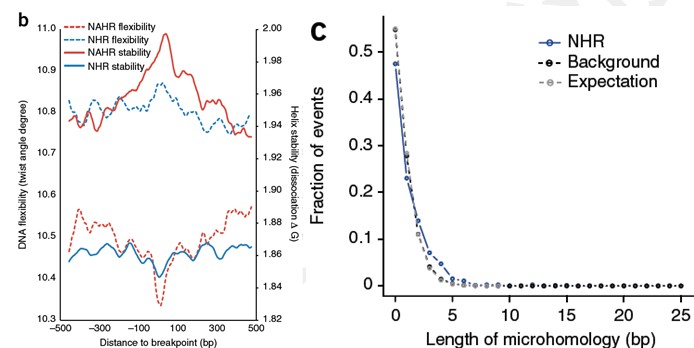

9.突变率估计
针对以家庭成员为单位的测序方案,我们主要探测de novo的突变(DNM);通过采用不同的方法/算法,我们给出每个家庭一份推断的DNM报表;
(1) 根据基因型推断结果,分别对每人每碱基位置上的de novo突变进行综合度量;
(2) 采用贝叶斯方法计算家庭组设计中DNM的后验概率
10. SNP,SNV功能分析与注释
(1). 祖先等位基因的注释
通过将人类(NCBI36),黑猩猩(chimpanzee2.1),猩猩(PPYG2)以及恒河猴(MMUL1)4种基因组进行基因组比对,发现保守的序列区域,计算祖先等位基因;以及duplication/deletion事件的进化分析。
(2). 分析基因结构序列上不同区域的多样性(Diversity)与分歧进化(divergence)
根据基因型分析结果计算基因结构序列上的多样性程度,即杂合度(heterozygosity); 杂合度指标可以说明选择效应的存在以及局部变异的结构分布特征模式。我们将考虑基因5’UTR上游200bp ,5’UTR ,第一个外显子,第一个内含子,中间外显子,中间内含子,最末外显子和内含子,以及3’UTR及其下游200bp区域左右考察的范围(参见下图a)。 分析编码转录本的起始/终止位置临近区域的多样性和进化分歧度(参见下图b)。
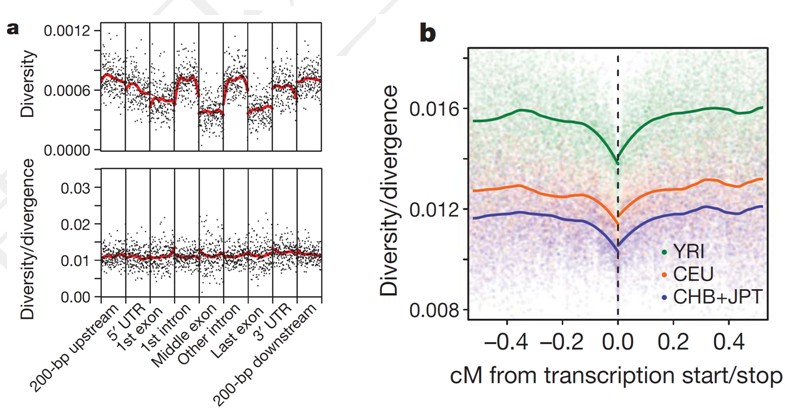
(3). 疾病变异体探测
将样本测序中分析得到SV与HGMD疾病变异体数据进行比对,得到交叉记录的错义和无义的SNP;通过将HGMD疾病关联突变与CUI(疾病概念分类标识数据库)比对获得HGMD中所有SV的疾病表型,并获得HGMD与测序数据分析得到的SV的疾病表型;并通过Fisher检验和Bonferroni多重假设检验校正计算样本SV所富集的疾病表型。
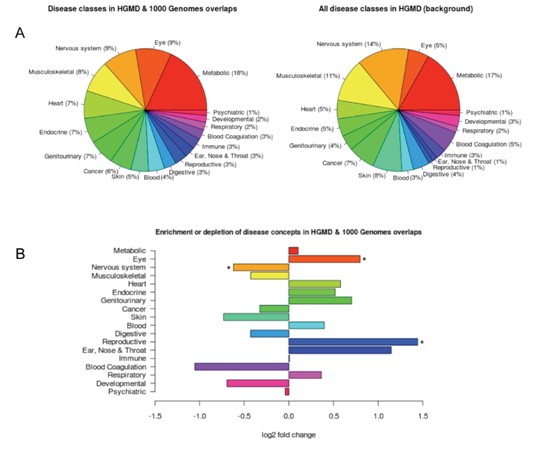
(4). 拷贝数变异CNV所含基因的功能注释
将CNV是否覆盖区段重复SD区域分类为2大类,每类CNV的所含基因的功能富集情况计算,显著性在横轴表示;各种显著性功能在纵轴表示。

(5). 变异的功能性分析与注释
(a). SNP, Indels以及大的结构变异SV的功能注释;
(b). 对包含翻译起始注释信息的转录本编码区上的SNP分类为:同义SNP,非同义SNP和无义SNP(引入终止子),干扰终止子的SNP,以及干扰剪接位点的SNP;为了降低假阳性,我们采用严格的筛选方式过滤来自indels的错误;
(c).对错义编码区突变的功能性分析: 通过信息学分析算法评估相对于生殖系变异的体细胞突变对蛋白质的结构和功能的影响效应。

(6). SNV,SNP与miRNA研究之间的关联分析
miRNA是起重要的调控作用的小分子,我们将对miRNA的pri-mRNA,pre-miRNA以及miRNA靶基因序列进行分析,识别潜在的SNP功能位点。据文献研究提供证据表明Human pre-miRNA的二级结构中存在不同位置上的SNP,我们将通过热力学稳定性分析方法评估SNP对pre-miRNA结构的影响;另外,我们也将对miRNA-Target靶基因相互作用位点做分析,评估对SNP对靶基因靶向性的影响。

(7). SNV,SNP与GWAS研究之间的关联分析
分析GWAS研究中得到的易感基因在基因组上不同坐标上的OR值分布情况; 将当前已知的GWAS研究成果与SNP进行比较;根据LD连锁不平衡将SNP与易感基因的关系进行深入讨论;直接与间接关联方法可以分别识别与表型相关的SNP,对于不易获得(missing)和定位的SNP,通过LD连锁不平衡推断疾病易感基因突变座位。

(8) 生物学通路(代谢通路,信号通路)分析
生物学通路(Biological pathway),包括代谢通路和信号转导通路是生物功能的重要组成部分,我们将各种形式的突变、变异,包括SNV和SNP,的对应基因放到生物学通路中进行综合分析,考察功能性突变对pathway的影响程度和影响的规律。通过GSEA(配合芯片表达谱数据),KS检验,超几何分布检验等方法对变异基因在某些pathway的富集程度进行排序,识别发生功能改变的潜在通路。

(9). 蛋白质-蛋白质相互作用(PPI)网络分析
蛋白质相互作用也是生物分子功能增益和缺失的重要途径,因此我们针对蛋白质相互作用网络中的突变的蛋白及其收到影响的网络节点蛋白进行系统分析,并对收到影响的网络子结构进行功能注释分析和聚类富分析。我们采用网络分析算法对由于各种突变所受到影响的子网络(subnetwork)进行功能富集度的分析;

(10). 顺式基因调控网络模块(CRM)分析
(a) 启动子序列分析
包括动子区域上的Motif预测,并与已知转录因子数据库TRANSFAC和JASPAR中的TFBS结合位点进行比对;
启动子区域上保守性分析,分析突变位置和保守性区域的关联;
(b) 计算全基因组保守性。确定TFBS的保守性以及mutation位置的保守性;

(11)重排(arrangements)与突变(mutation)的全基因组统计
(a). 体细胞(somatic)和生殖系(germline)重排(arrangements)
体细胞突变是相对于germ line 突变的一类需要重要分析的内容,我们针对Case-control设计的测序方案可以分别分析突变的情况,包括SNV,indel,以及CNV;如果仅在tumor/disease(Case组)出现而不在normal(对照组)出现的突变我们可以认为是somatic体细胞突变。将somatic mutation 与dbSNP数据库比对可以发现潜在的全新的突变和有记录的突变位置。然后,将突变分别比对到基因区域和非基因区域。基因区域具体包括:内含子区,UTR,剪接位点区和外显子区。其中外显子区分别统计:同义(synonymous),缺失(deletion),阅读框移位(frameshift),插入(insertion),错义(missense),无义(nonsense)以及非编码蛋白外显子(non-protein coding exon)等不同类型。综合不同方面分析的结果,并按照突变分类给出各重排(arrangements)类型:SNV,CNV的数目统计数据表(参见下图) 。对每一测序样本分别进行标注,包括体细胞突变和生殖系突变。
(b) 全基因组全局重排分布特征分析

主要将(a)染色体间和染色体内部的结构变异,(b)杂合体缺失(LOH)与等位基因不平衡的状况,(c)拷贝数变异(增益或者缺失)以及高可信度的SNV(在1Mb间隔区间统计)等不同情况配合染色体核型在环状图的不同层次上分别的表示出来(参见下图例对应a-d)
(c) 单核苷酸突变趋势与模式分析
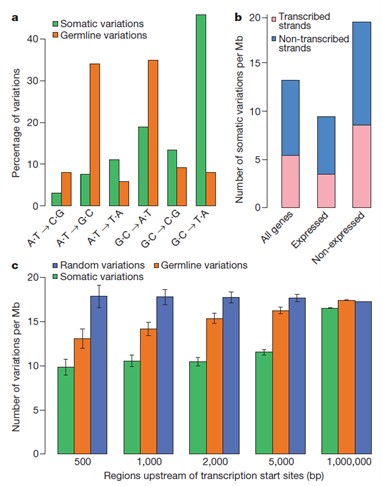
分别统计在体细胞和生殖系细胞水平上的transversion的主要形式与各自所占比重(a);如果有表达谱数据,可以分析表达基因与非表达基因所分别具有的突变重排数目或者种类(b);转录起始位点上游区域的体细胞变异,生殖系germline变异以及随机变异的各自数目统计(c)和已知210种的不同肿瘤疾病的突变谱进行比较.
11 自然选择分析
我们通过测序所观测到的体细胞突变可能是经历了复杂的过程所成的。因此,我们在研究这些突变的起源,突变如何受到DNA修复机制的影响,以及在疾病发展与进化过程中突变的规律方面需要做深入的分析。自然选择一般在两个方面发挥作用,即保留有利于疾病发展进化的突变的同时限制其在基因组中重要功能区域发生突变,例如转录调控区域和编码蛋白质的区域。因此,(1)如果实验设计是将primary disease与normal control做比较的话,系统的分析可以解析复杂疾病在形成突变过程中可能的机制和自然选择的因素。(2)如果实验设计是基于病灶及其转移位置或者邻接位置样本作测序,我们可以构建突变进化与转移的模型解析突变的动态模式和基因组中不稳定态变异的模式。
正向选择的判定: 分析SNP,SNV区域的正向选择趋势,在进化和群体遗传水平解释SNV,SNP的功能性;对待control与case 组样本,我们分别采用不同统计算法计算SNP,CNV在各自样本中的差异,进而从中发现具有正向选择特征的SV。
全基因组重测序数据分析相关推荐
- 全基因组重测序基础及高级分析知识汇总
全基因组重测序基础及高级分析知识汇总 oddxix 已关注 2018.09.20 17:04 字数 11355 阅读 212评论 0喜欢 6 转自:http://www.360doc.com/cont ...
- 一个全基因组重测序分析实战
Original 2017-06-08 曾健明 生信技能树 这里选取的是 GATK best practice 是目前认可度最高的全基因组重测序分析流程,尤其适用于 人类研究. PS:其实本文应该属于 ...
- signature=d363d26bda212f777fef81d270ecd42b,基于DNA-pooling全基因组重测序初步筛查CAD易感基因变异位点...
摘要: 目的:应用DNApooling全基因组重测序技术初步筛查CAD易感基因变异位点并进行功能分析.方法:分别收集CAD病例组血液样本和正常对照组血液样本各100例.提取病例组和对照组DNA,制作D ...
- 全基因组重测序揭示了野生大豆的局部适应和分化的特征
近日,凌恩生物客户南京农业大学在<Evolutionary Applications>发表题为"Whole-genome resequencing reveals signatu ...
- 全基因组重测序基础分析
本文仅为个人记录 流程说明 从零开始完整学习全基因组测序(WGS)数据分析:第3节 数据质控 2015a 2016a 全基因组测序数据获取后应该怎么分析 samtools samtools常用命令详解 ...
- 易基因技术推介|全基因组重亚硫酸盐甲基化测序(WGBS)
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因.今天跟大家介绍一下易基因的王牌产品:全基因组重亚硫酸盐甲基化测序(WGBS). 全基因组重亚硫酸盐甲基化测序(WGBS)可以在全基因组范围 ...
- 基因组重测序全流程(简易版)
已知达松维尔拟诺卡氏菌亚种是会导致人类放线菌瘤的环境生物,该样本是来自Keddieii血根杆菌DSM 10542的通用样品,旨通过基因组重测序探索其和参考基因组有何不同,找出基因组变异信息. 1.需要 ...
- 精准医学: 应用脑脊液游离DNA全基因组甲基化测序筛选小儿髓母细 胞瘤早期诊断与预后监测的可靠生物标志物|液体活检专题
易点评 本文是液体活检DNA甲基化标志物发现的典型研究案例.儿童脑恶性肿瘤如髓母细胞瘤(MB)致癌基因突变频率较低,但DNA甲基化改变明显,根据MB的这一特点作者使用了WGBS和CMS-IP-seq技 ...
- 中国人泛基因组发了 Nature,基因组重测序的CNS值得拥有
33333福利公告:前 10期<临床基因组/外显组数据分析实战>线上/线下课程已圆满结束.现于2023年6月30~7月1日,在北京安排第十一期课程. 线上课是通过腾讯会议实时直播线下课,实 ...
- 人类线粒体全基因组二代测序原始数据过滤
关于线粒体全基因组下机的fastq文件如何过滤变成待分析的VCF文件....具体过滤流程和相关参数,跪求大神帮忙指导!!!!必有重谢
最新文章
- CSP 202006-1 线性分类器 python实现+详解
- linux 线程与CPU绑定
- IE浏览器Cookie信息提取工具Galleta
- NO。58 新浪微博顶部新评论提示层效果——position:fixed
- 移植memtester到android平台
- php mysql grant_mysql grant命令详解_MySQL
- 2步判断晶体管工作状态
- 关于java方向的思考
- win7安装英语语言包
- 用Java语言编写ajax设计模式_《松本行弘的程序世界》读书笔记(上)——面向对象、程序块、设计模式、ajax...
- python调用virustota接口api实现上传文件返回查毒结果
- 方差,协方差,标准差和均值标准差等各种差
- 八.deepin V20.6安装mysql8.0.30
- 豪森药业阿美乐获批,全球第二个三代EGFR-TKI创新药
- php 数组函数特点,php常见数组函数
- 3.1 51单片机-LED灯模块
- 国外主流网站分析工具介绍
- html如何制作一个手机商城网页通栏
- 大门门窗怎么画?各种大门的绘画技巧
- 易语言多线程大漠多线程进程线程多线程