国际象棋ai下载_国际象棋AI的解剖
国际象棋ai下载
Chess-playing programs made their grand debut in the 50’s. They were unsurprisingly fairly weak; both technological and theoretical limitations kept engines from playing at the level of a master until around 1990. It was only in 1997 that the program Deep Blue was able to defeat a world champion, Gary Kasparov.
国际象棋比赛程序在50年代盛大亮相。 毫不奇怪,他们很虚弱。 由于技术和理论上的局限性,直到1990年左右,发动机一直无法发挥出大师级的水平。直到1997年,深蓝计划才击败了世界冠军加里·卡斯帕罗夫。
Since then they have surpassed humans completely. The top players have Elo ratings of around 2,800, the top engines are rated around 3,500. The 700-point difference roughly translates to the top human players having a 1.7% chance of winning against these engines.
从那时起,它们已经完全超越了人类。 顶级玩家的Elo评分约为2,800,顶级引擎的评分约为3500。 700分的差额大致意味着顶尖的人类玩家有1.7%的机会与这些引擎抗衡。
The strongest modern chess engine is Lc0, an open-source project inspired by Deepmind’s AlphaZero algorithm. Unlike ordinary chess engines, Lc0 and AlphaZero are based on neural networks and a search algorithm known as Monte-Carlo tree search. This approach comes at a cost: building one of these algorithms from scratch requires a huge amount of resources. Deepmind trained AlphaZero on a server with four TPUs, and Lc0 was trained over months by distributed computing.
最强大的现代象棋引擎是Lc0,这是一个受Deepmind的AlphaZero算法启发的开源项目。 与普通的象棋引擎不同,Lc0和AlphaZero基于神经网络和称为Monte-Carlo树搜索的搜索算法。 这种方法需要付出一定的代价:从头开始构建这些算法之一需要大量资源。 Deepmind在具有四个TPU的服务器上训练了AlphaZero,而Lc0则通过分布式计算进行了数月的训练。
Despite the sheer intuitive power neural networks have over them, traditional networks are still not obsolete. Stockfish, Lc0’s main competitor, is an engine which relies on hard-coded heuristics and a significantly faster but rougher search algorithm known as minimax search. These engines still manage to be competitive thanks to the sheer power of brute-force computation enabled by clever optimizations and heuristic tricks.
尽管神经网络具有强大的直觉能力,但传统网络仍不被淘汰。 Lc0的主要竞争对手Stockfish是一种引擎,它依赖于硬编码的启发式算法以及明显更快但更粗糙的搜索算法,称为minimax搜索。 由于巧妙的优化和启发式技巧使蛮力计算具有强大的功能,因此这些引擎仍然具有竞争力。
评估功能 (The evaluation function)
How do you get a computer to play chess? A simple way would be to program it to make random moves. A harder way, of course, requires finding out which moves are actually good. That is, which moves, if there are any, will lead to checkmate the quickest?
您如何获得一台电脑下棋? 一种简单的方法是对其进行编程以使其随机移动。 当然,更困难的方法是找出哪些动作实际上是好的 。 也就是说,如果有的话,哪一步会导致最快的将死?
Theoretically we could take a given board and exhaustively search every move from that position until the end of the game. If we had all of this data available we could trace out which moves will guarantee a checkmate or, if winning is impossible, which moves will delay being checkmated the longest. Unfortunately this is not feasible as the number of different positions to keep track of grows exponentially, outpacing any machine’s memory capacity. Instead, this search is typically limited to a certain depth, i.e. looking 4 moves ahead. Since checkmates don’t often happen in only 4 moves, we need to introduce some intermediate measure that estimates how likely it is that the given side will win.
从理论上讲,我们可以拿一个给定的棋盘,从该位置直到游戏结束,详尽搜索每一个动作。 如果我们拥有所有可用的数据,我们就可以找出哪些动作将保证将死,或者,如果不可能获胜,则哪些动作将延迟被确认时间最长。 不幸的是,这是不可行的,因为要跟踪的不同位置的数量呈指数增长,超过了任何计算机的存储容量。 取而代之的是,此搜索通常仅限于某个深度,即向前看4个。 由于将要发生的check杀通常不会发生在四步之内,因此我们需要引入一些中间措施来估计给定一方获胜的可能性。
This measure is known as the evaluation function. It can be as simple as an indicator for whether a given side has been checkmated, but for limited-depth search this isn’t useful. A slightly more mature estimate is in counting the pieces on each side in a weighed way. If white has no queen but black does, then the position is unbalanced and white is in trouble. If white is three pawns down but also has an extra bishop, the position is likely to be balanced. This evaluation function scores pieces in terms of how many pawns they’re equivalent to.
该度量称为评估功能。 它可以像确定给定侧是否已被核对的指示器一样简单,但是对于深度有限的搜索而言,这没有用。 稍微成熟一点的估计是以加权方式计算每侧的件数。 如果白色没有女王而黑色则没有女王,则位置不平衡并且白色有麻烦。 如果白色向下三个棋子,但又有一个额外的主教,则该位置很可能是平衡的。 此评估功能根据相当于多少个棋子的方式对作品进行评分。

An algorithm playing with this evaluation function will have general rules down. Taking pieces, especially rooks and queens, is typically good and sacrificing important pieces to take out pawns is typically bad. Sadly, its positional playing will be abhorrent.
使用此评估功能的算法将使通用规则下降。 拿一块,尤其是白嘴鸦和皇后通常是好的,而牺牲重要的东西取出典当通常是不好的。 可悲的是,它的位置发挥将是令人讨厌的。
A slightly move advanced method of scoring would not only take that into account, but also take into account the position of each piece on the board. This gives algorithms a surprising amount of positional intuition: pawns and knights should be in the center, rooks on the enemy’s ranks are powerful, kings should be in the corners, so on. Scoring can be made even more sophisticated by accounting more subtle tactical and positional patterns like pawn structure, connected rooks, and king mobility.
略微提高得分的先进方法不仅会考虑到这一点,而且还会考虑每块在板上的位置。 这给算法带来了令人惊讶的位置直觉:典当和骑士应该居中,敌方队伍中的白嘴鸦要强大,国王应该在角落里,依此类推。 通过考虑更精细的战术和位置模式(例如典当结构,相连的车队和国王的机动性),可以使计分变得更加复杂。
From here we won’t need to worry about what kind of evaluation function we use. For chess engines, evaluation and search are often independent of each other’s implementations. This fact has recently been used in developing Stockfish NNUE, a Stockfish clone that uses a sparsely updated neural network as an evaluation function.
从这里开始,我们不必担心我们使用哪种评估功能。 对于国际象棋引擎,评估和搜索通常彼此独立。 最近,这一事实已用于开发Stockfish NNUE ,这是一个使用稀疏更新的神经网络作为评估函数的Stockfish克隆。
Minimax搜索 (Minimax search)
A search algorithm boils down to the way a chess engine compares possible moves. Thanks to the use of evaluation functions, search algorithms only need to search to a fixed depth to make reasonable decisions. How do they actually decide which moves to play?
搜索算法归结为象棋引擎比较可能动作的方式。 由于使用了评估功能,搜索算法只需要搜索固定深度即可做出合理的决策。 他们实际上如何决定要玩的动作?
Search algorithms involve a search tree, or a way of representing a board and all the possible moves to be made from that position on the board. The root node of the tree is the original board, and all of the nodes branching out from it are reachable positions.
搜索算法涉及搜索树或表示木板的方式,以及从木板上的该位置开始进行的所有可能的移动。 树的根节点是原始板,从它分支出来的所有节点都是可到达的位置。
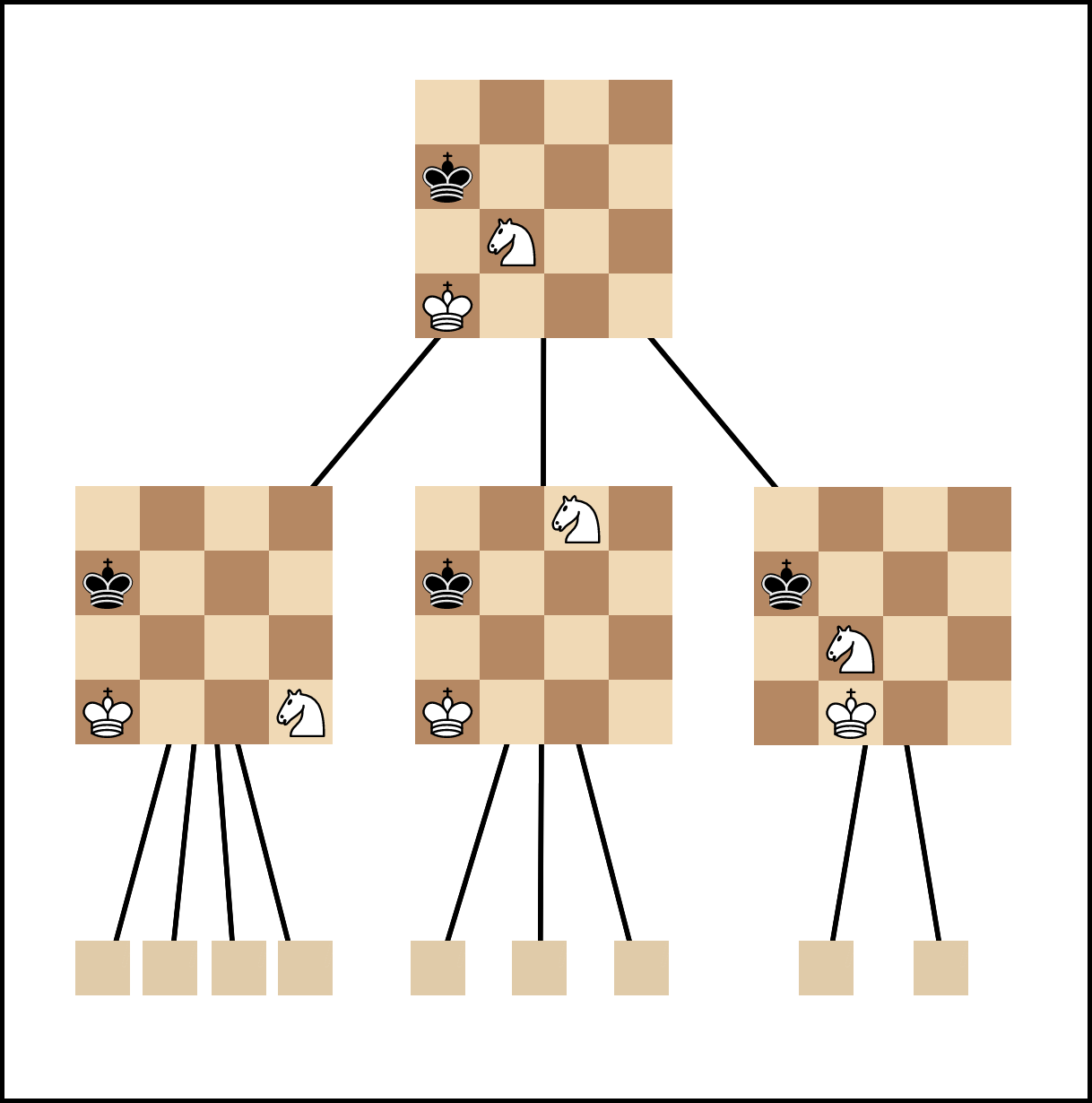
The minimax algorithm takes advantage of the fact that chess is a zero-sum game. Maximizing your chances of winning is the same as minimizing the opponent’s chances of winning. Each turn can be seen as a player making a move to maximize the evaluation function while the other tries to minimize it. In terms of a search tree, this means starting at a given node and choosing the children nodes with the best (or worst) scores.
极小极大算法利用了象棋是零和游戏这一事实。 最大化获胜机会与最小化对手获胜机会相同。 每个回合都可以看作是一个玩家在采取行动以最大化评估功能,而另一方则试图将其最小化。 就搜索树而言,这意味着从给定节点开始,然后选择得分最高(或最差)的子节点。
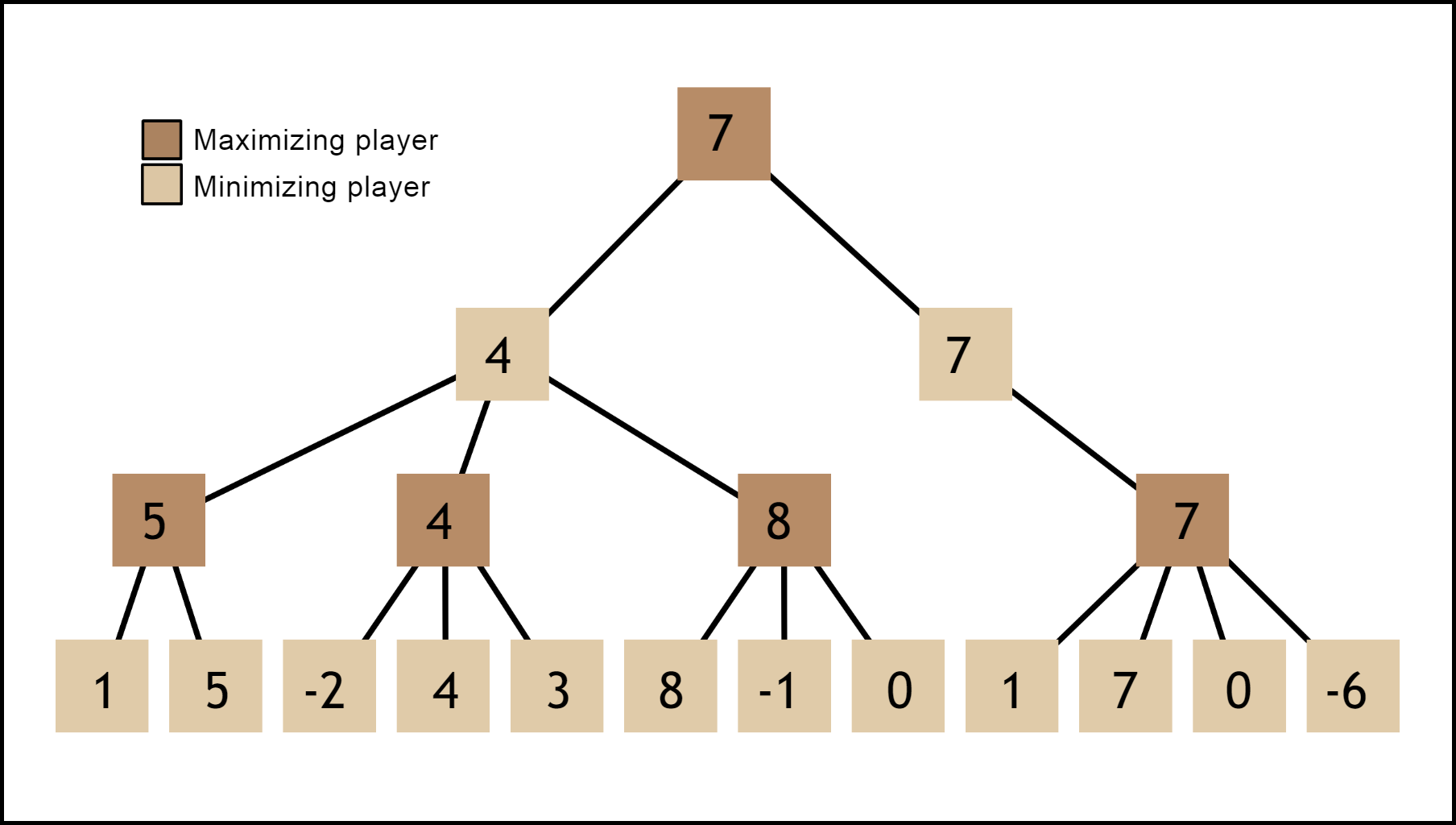
Minimax is the “correct” way to do this, in the sense that if we were to let it go on indefinitely then it would play the game perfectly. That said, it is incredibly slow and impractical. This is thanks to the high branching factor of the search tree; any given position will have 10–20 possible moves, each of those new positions will have around the same amount, and so on. The number of nodes in a search tree increases exponentially with depth.
Minimax是执行此操作的“正确”方法,在某种意义上,如果我们让它无限期地继续下去,那么它将完美地玩游戏。 就是说,这是非常缓慢且不切实际的。 这要归功于搜索树的高分支因子。 任何给定的头寸都会有10–20个可能的移动,每个新头寸都将具有相同的数量,依此类推。 搜索树中的节点数量随深度呈指数增长。
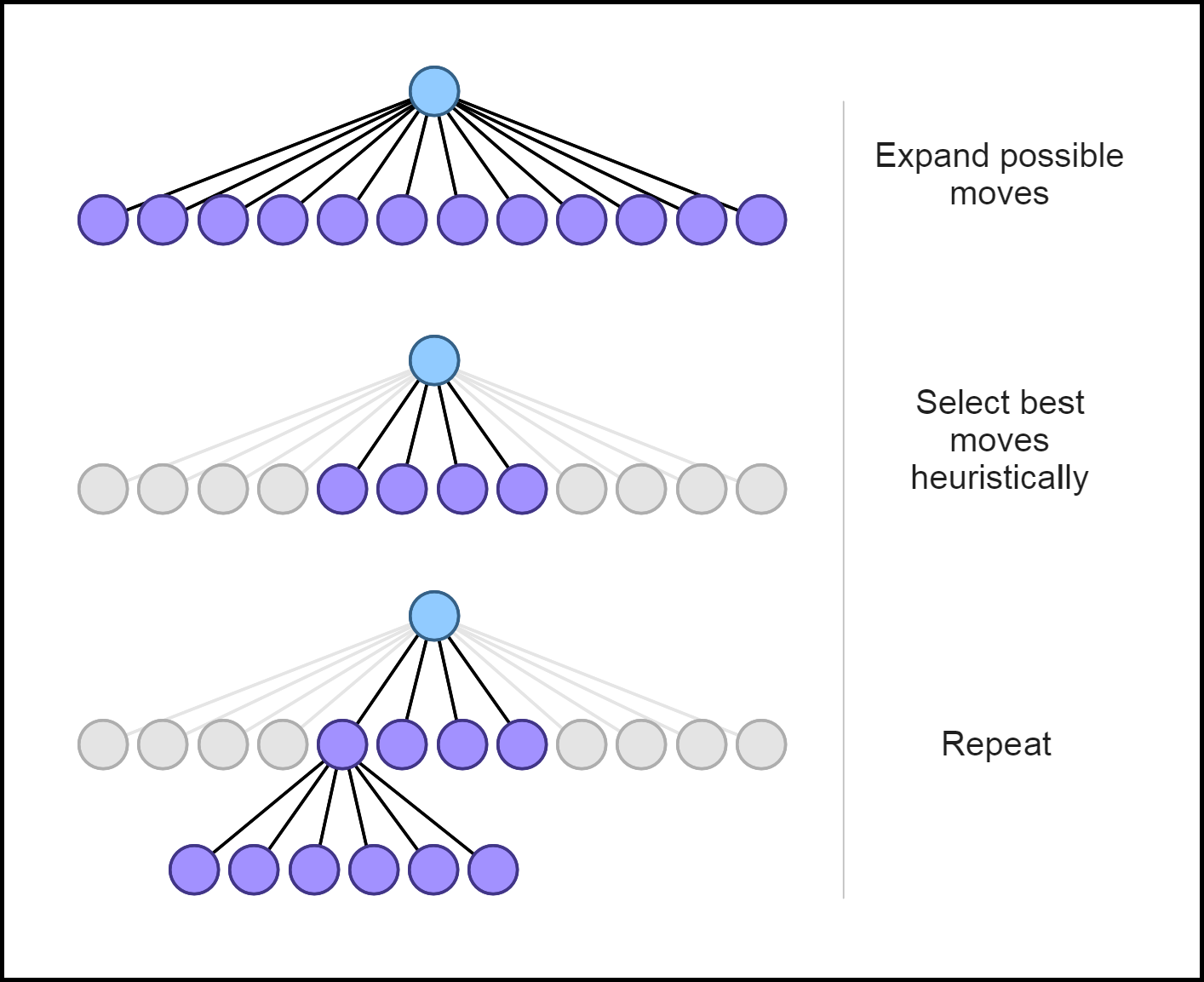
An early way to get around this was by using the “Shannon type B” variation of minimax. Instead of searching every possible move at a node (the type A approach), only a handful of the top moves are looked at. The candidate moves are decided either by the evaluation function, or some other heuristic like “checks-captures-threats”. These types of algorithms keep the branching factor low on the search tree, so they are able to search to a greater depth. However, since they don’t consider many moves they’re prone to miss a lot of important tactics and fall into traps.
解决此问题的早期方法是使用minimax的“ Shannon B型”变体。 而不是搜索节点上的所有可能动作(A类方法),只查看了少数几个最重要的动作。 候选动作由评估功能决定,也可以由其他启发式决定,例如“检查-捕捉-威胁”。 这些类型的算法使分支因子在搜索树上保持较低的位置,因此它们能够搜索到更大的深度。 但是,由于他们考虑的动作不多,因此很容易错过许多重要的战术并陷入陷阱。
By the 70’s, an optimization of minimax known as alpha-beta pruning was discovered that made the Type A approach viable. Selecting candidate moves for a Type B algorithm ended up being too computationally expensive in comparison and it fell out of favor.
到70年代,发现了一种称为alpha-beta修剪的minimax优化,使Type A方法可行。 相比而言,为B型算法选择候选动作最终在计算上过于昂贵,因而不受欢迎。
Alpha-Beta修剪 (Alpha-Beta pruning)
If you’ve ever played chess, you will know that some moves are just bad. These are typically moves that allow the other player to get a clear upper hand on the next few turns; such as blundering a piece. To standard minimax, these moves are just as important to think about as the others. In return, the algorithm gets weighed down by analyzing bad positions.
如果您曾经下过象棋,您会知道有些举动是不好的 。 这些通常是允许其他玩家在接下来的几回合中占据上风的动作。 例如弄虚作假。 对于标准的minimax,这些动作与其他动作一样重要。 作为回报,算法会通过分析不良位置来权衡。
Alpha-beta pruning speeds up minimax by skipping the “irrelevant” nodes of a search tree. This can be accomplished by adding extra data to each node, an “alpha” and a “beta” value, which represent the worst outcome for each player from that node. Since the maximizing player knows that the minimizing player will pick a response that minimizes the evaluation, they also know that they can avoid thinking about moves that allow the minimizing player to make things worse than they already are. These moves are “pruned” from the search tree and skipped.
Alpha-beta修剪通过跳过搜索树的“无关”节点来加快minimax的速度。 这可以通过向每个节点添加额外的数据,“ alpha”和“ beta”值来完成,这代表该节点上每个玩家的最差结果。 因为最大化玩家知道最小化玩家会选择使评估最小化的响应,所以他们也知道他们可以避免考虑使最小化玩家使事情变得比现在更糟的动作。 这些动作从搜索树中被“修剪”并被跳过。
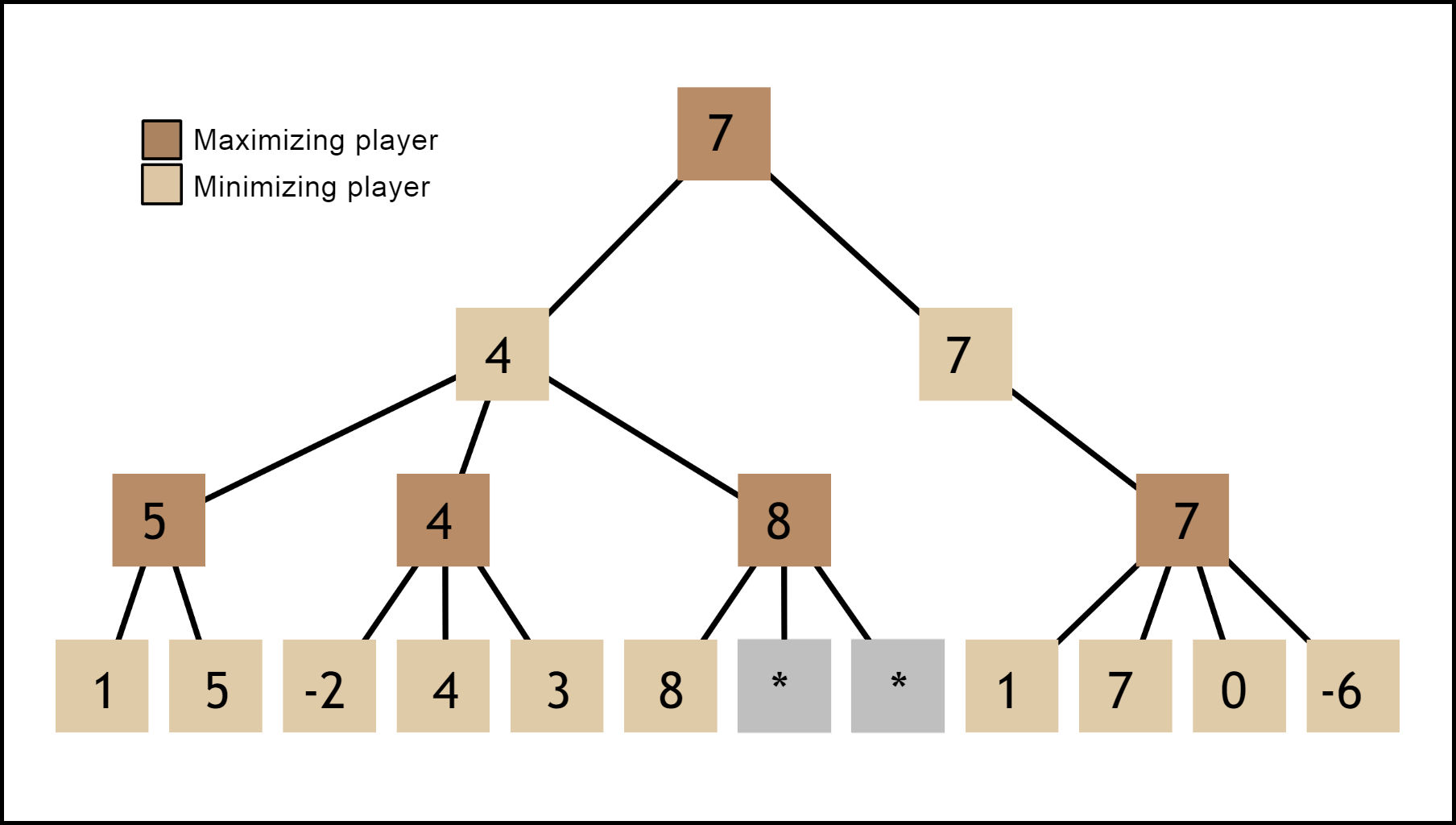
Alpha-beta pruning makes brute-force search possible. Even better, it yields exactly the same results as naive minimax would, so it’s also the “correct” algorithm for tree search. However, it is still limited.
Alpha-beta修剪功能使暴力搜索成为可能。 更好的是,它产生的结果与朴素的minimax完全相同,因此它也是树搜索的“正确”算法。 但是,它仍然是有限的。
In the best case, alpha-beta pruning reduces the computational time by a “square root”. For example, if minimax takes 100 seconds to determine the best move, then alpha-beta pruning will take only 10. In most cases, however, alpha-beta pruning will not preform as well and will take some intermediate amount of time to run.
在最佳情况下,α-β修剪会减少“平方根”的计算时间。 例如,如果minimax需要100秒来确定最佳移动,则alpha-beta修剪将仅花费10。但是,在大多数情况下,alpha-beta修剪也不会执行,并且会花费一些中间时间。
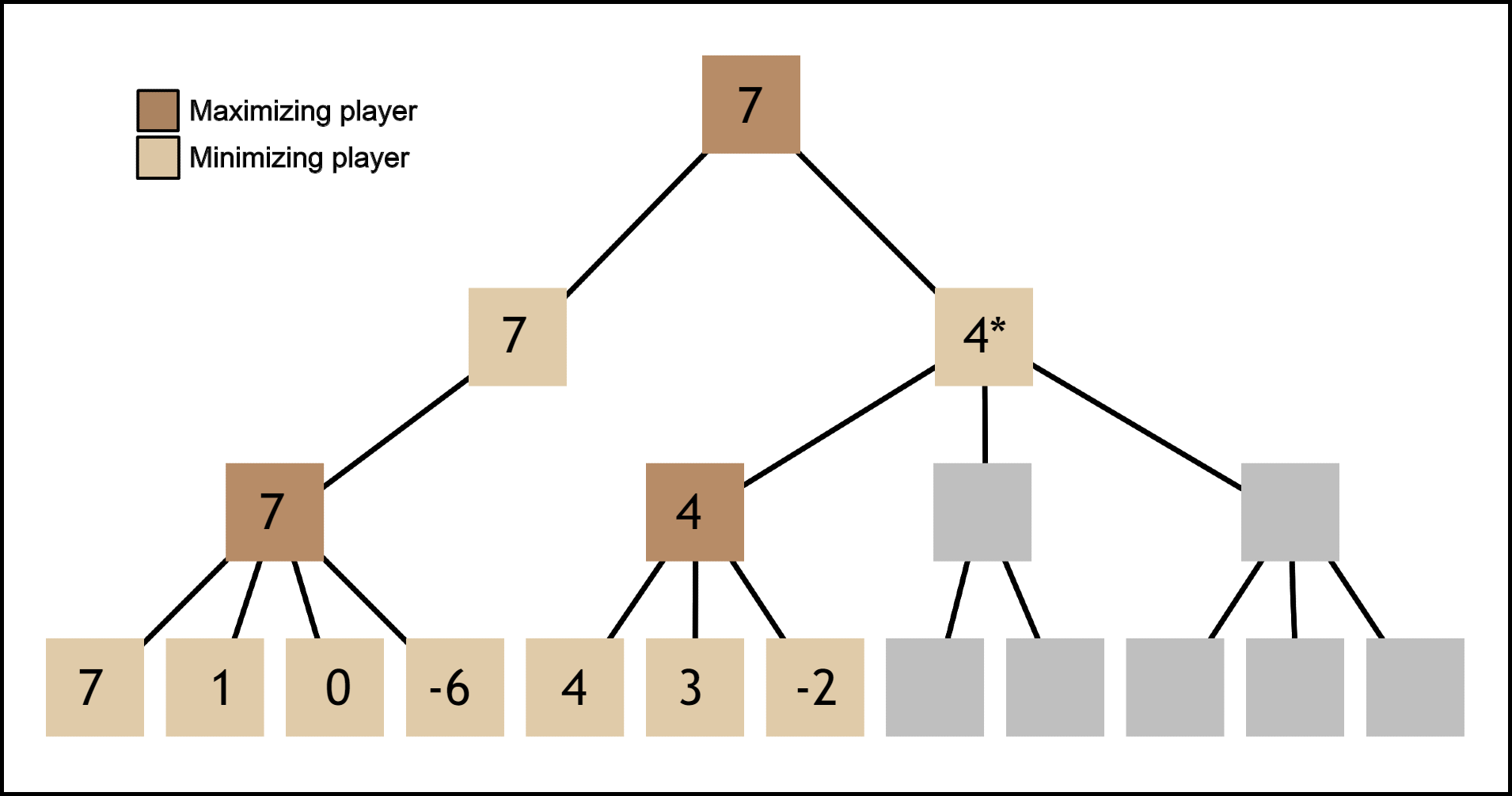
The reason this happens is due to how this algorithm visits nodes. So far there’s no system for deciding which nodes to look at first, so the algorithm just looks through them at random. This can lead to a situation where the program looks at the worst move when it does not yet know that it’s the worst move, as opposed to skipping it when it knows that there’s already a better move to pick.
发生这种情况的原因是由于该算法如何访问节点。 到目前为止,还没有确定先看哪个节点的系统,因此该算法只是随机地查看它们。 这可能会导致一种情况,即程序在尚不知道这是最坏的举动时就看最坏的举动,而不是在知道已经有更好的举动选择时跳过它。
移动订购 (Move ordering)
The trick to mimicking the ideal case for alpha-beta search comes through move ordering. The idea is to look at the most promising moves first so that bad moves can be quickly eliminated. Since it’s impossible to tell what moves are best without actually performing a search on them, this method has to be guided by heuristics. Thanks to this, there are several possible ways to implement this in a chess engine.
模仿alpha-beta搜索理想情况的技巧来自移动顺序。 这个想法是先看看最有前途的举动,以便Swift消除不良举动。 由于无法在不进行实际搜索的情况下分辨出哪些动作是最好的,因此该方法必须以试探法为指导。 因此,有几种可能的方法可以在国际象棋引擎中实现此功能。
This technique is similar to the Type B approach to minimax. Instead of choosing a subset of moves, they are instead just preferentially ordered. This can be something simple like ordering captures first and considering everything else after all the captures have been analyzed. Some finer-scale heuristics may be used, such as first looking at capturing the last moved piece.
此技术类似于B型最小极大值方法。 他们没有选择动作的子集,而是仅对其进行了优先排序。 这可以很简单,例如首先对捕获进行排序,然后在对所有捕获进行分析之后再考虑其他所有内容。 可以使用一些更精细的启发式方法,例如首先查看捕获最后移动的片段。
Non-capturing moves may also be ordered. The most common heuristic for these is the “killer” heuristic. Within the alpha-beta search tree, two sibling nodes (descended from the same parent node) are going to have very similar positions. This means that a move which causes an alpha-beta cutoff in one node will likely be just as important for its sibling nodes, so it will be analyzed first once the algorithm gets to those nodes.
也可以订购不打招呼的举动。 最常见的启发式方法是“杀手”启发式方法。 在alpha-beta搜索树中,两个同级节点(从同一父节点下降)将具有非常相似的位置。 这意味着在一个节点中导致alpha-beta截止的移动对其同级节点同样重要,因此一旦算法到达这些节点,将首先对其进行分析。
Another heuristic method for move ordering is known as relative history. It’s actually a combination of the history and butterfly heuristics, which are inadequate by themselves. The history heuristic orders moves by the number of times they’ve cause an alpha-beta cutoff in the search tree. The butterfly heursitic orders moves by how many times they are played overall. Relative history orders moves by the ratio of these two scores, essentially picking out the moves that were most effective when played.
用于移动排序的另一种启发式方法称为相对历史记录 。 它实际上是历史和蝶探启发法的结合,它们本身是不够的。 历史启发式订单的移动次数导致搜索树中的alpha-beta截止。 蝴蝶试探性命令的移动量为整体被播放的次数。 相对历史记录按这两个得分的比率来排列动作,从本质上挑选出演奏时最有效的动作。
If we allow the search algorithm to keep information about its search tree from previous moves, then we can also employ a form of move-ordering based on each node’s preferred moves from the previous search. This way, a chess AI searching a position to a depth of 8 doesn’t need to throw away all of that analysis and start anew on the next turn.
如果我们允许搜索算法保留有关其先前搜索动作的搜索树的信息,那么我们还可以根据先前搜索中每个节点的首选动作采用某种移动排序方式。 这样,一架象棋AI搜索深度为8的位置并不需要扔掉所有分析并在下一回合重新开始。
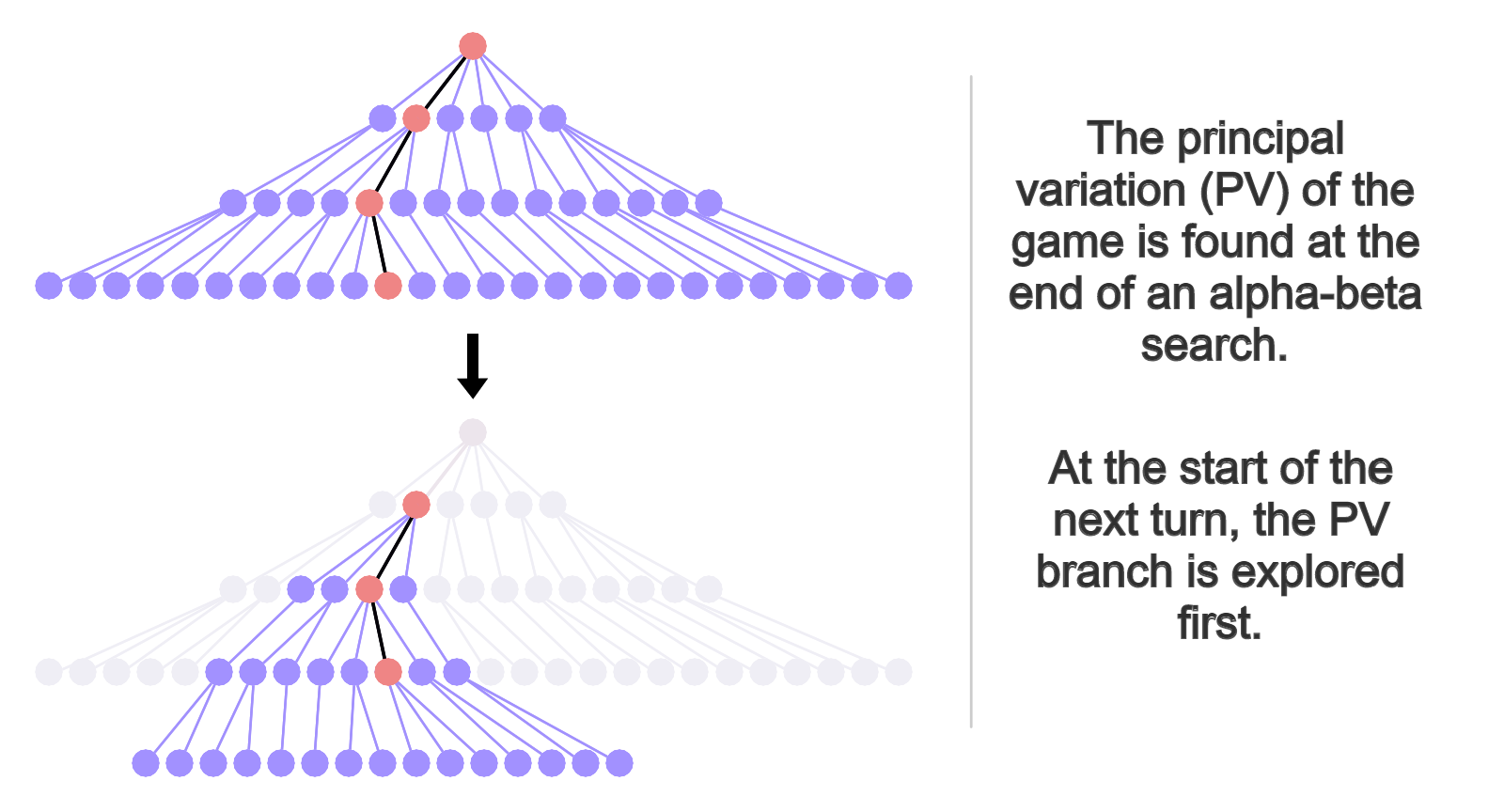
Since this relies on storing nodes and information about them, there needs to be a memory-efficient way to store this data. For picking out principal variations, we can get away with storing the board as-is since we don’t need to store very many. This isn’t always the best way.
由于这依赖于存储节点及其相关信息,因此需要一种内存有效的方式来存储此数据。 为了挑选主要的变化形式,我们不需要按原样存储板,因为我们不需要存储很多板。 这并不总是最好的方法。
换位表 (Transposition tables)
The speed of alpha-beta pruning is vastly improved by move ordering. Although it seems we’ve gone as far into optimizing this as possible, we can go even further through the use of transposition tables. A transposition table stores data about nodes throughout the search algorithm, allowing it to skip nodes it has already seen before in the search.
通过移动顺序极大地提高了alpha-beta修剪的速度。 尽管似乎我们已经尽可能地优化了这一点,但是我们可以通过使用转置表来走得更远。 换位表存储有关整个搜索算法中的节点的数据,从而使其可以跳过之前在搜索中已经看到的节点。
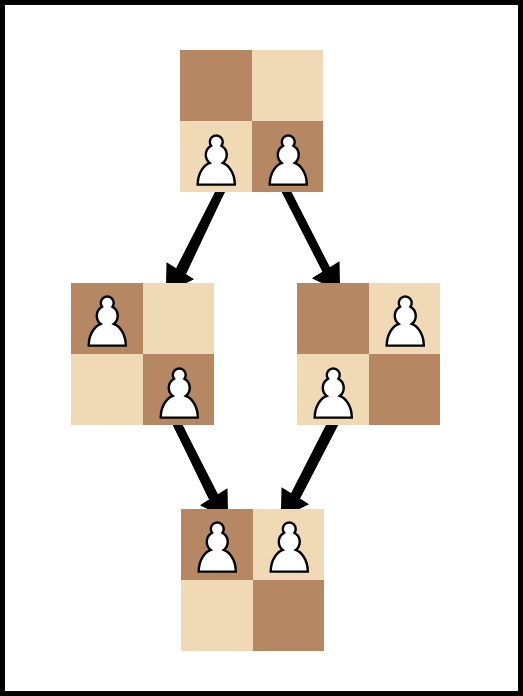
In a game like chess, transposed nodes show up all across the search tree. With the use of transposition tables, a given transposition will only need to be analyzed once before the algorithm remembers it and knows not to waste time re-analyzing it elsewhere in the tree.
在象棋这样的游戏中,转置的节点会在整个搜索树中显示。 通过使用换位表,给定的换位只需要在算法记忆之前就被分析一次,并且知道不会浪费时间在树中的其他位置重新分析它。
Keeping a transposition table requires a large amount of memory. Storing the entire position of a board becomes impractical here, so programmers got creative. Since the program only needs to check if two positions are the same, we can take an idea from cryptography and check their hashes instead.
保留转置表需要大量内存。 在这里存储板子的整个位置变得不切实际,因此程序员变得很有创造力。 由于该程序仅需要检查两个位置是否相同,因此我们可以从密码学中了解一个概念,然后检查其哈希值。
The idea behind hashing two objects is that most of the information of the objects is obscured, but their equality can still be checked. In our case, “obscuring information” means simplifying the object to save memory. The next special property of hashing is that two similar objects should have completely dissimilar hashes; which means that the hashing function should be fairly random and chaotic.
对两个对象进行哈希处理的想法是,对象的大多数信息都被遮盖了,但是仍然可以检查它们的相等性。 在我们的案例中,“模糊信息”意味着简化对象以节省内存。 哈希的下一个特殊属性是,两个相似的对象应该具有完全不同的哈希值。 这意味着散列函数应该是相当随机且混乱的。

How do we hash a chess board? The answer comes from the Zobrist hashing method. This method takes the 8x8 chess board as being made up of 12 (for 6 pieces x 2 colors) 64-bit binary strings, along with a smaller binary string to keep track of castling and en passant rights. It then generates a hash key made up of a 8x8x12 matrix of random 32-bit strings (with a similar key for the substring). Finally, it takes an empty string and performs a bitwise XOR on it with the “keys” of each piece on the board, the random strings in the 8x8x12 key matrix which correspond to the 1’s in the 12 64-bit strings.
我们如何哈希棋盘? 答案来自Zobrist哈希方法。 此方法将8x8国际象棋棋盘由12个(6个x 2色) 64位二进制字符串组成 ,以及一个较小的二进制字符串,以跟踪连铸和附带权利。 然后,它生成一个由随机32位字符串的8x8x12矩阵组成的哈希密钥(子字符串具有类似的密钥)。 最后,它获取一个空字符串,并与板上每块棋子的“键”进行按位异或,即8x8x12密钥矩阵中的随机字符串对应于12个64位字符串中的1。
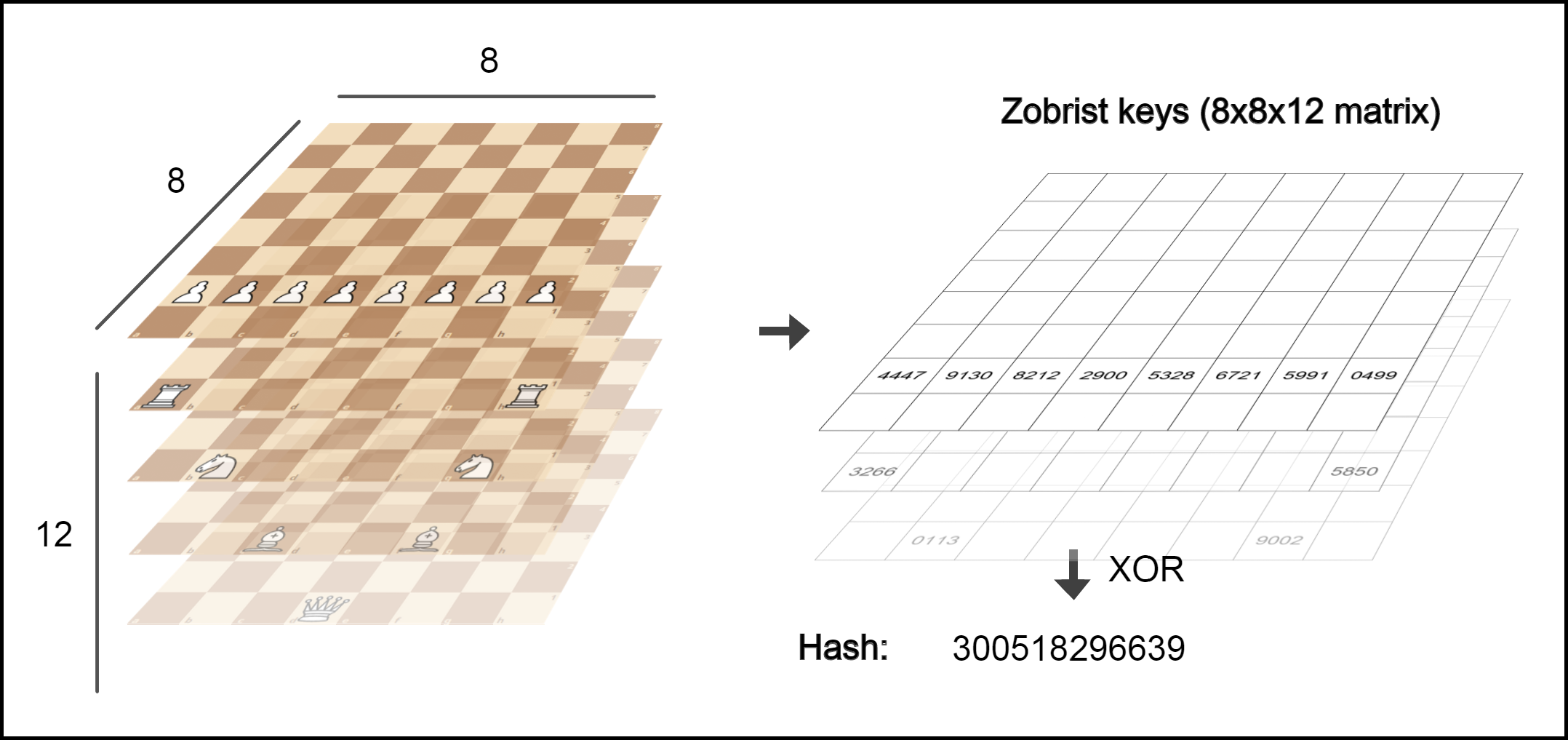
What makes this hash useful is that the XOR operation is reversible. This means we can effectively add and remove pieces from the board. So, instead of recalculating the whole hash from scratch, we can simply XOR that hash with the Zobrist key corresponding to that piece and square. This makes hashing efficient enough to use in a chess engine, since recalculating a board’s hash after a move only requires two XOR operations.
使此哈希有用的原因是XOR操作是可逆的。 这意味着我们可以有效地在板上添加和删除碎片。 因此,我们无需从头开始重新计算整个哈希,而只需将哈希与对应于该片段和正方形的Zobrist键进行XOR即可。 这使得散列效率足以在象棋引擎中使用,因为移动后仅需执行两个XOR操作即可重新计算棋盘的散列。
Information about a given node may be stored in a hash table. Encountering a new node prompts the algorithm to check whether that node is stored in the hash table. If so, it copies the data from the hash table over to that node without needing to perform a search.
关于给定节点的信息可以存储在哈希表中。 遇到新节点会提示算法检查该节点是否存储在哈希表中。 如果是这样,它将数据从哈希表复制到该节点,而无需执行搜索。
The use of hashing has it’s downsides, however. Since hashing reduces high-information objects into low-information objects, there could be overlaps where two totally different positions somehow have the same hash value. This can be mitigated by having a large transposition table size. A size of around one to ten million entries is generally good enough.
但是,使用散列有其缺点。 由于哈希将高信息对象减少为低信息对象,因此可能存在重叠,其中两个完全不同的位置以某种方式具有相同的哈希值。 可以通过使用较大的换位表大小来缓解这种情况。 通常,大约一到一千万个条目的大小就足够了。
静态搜索 (Quiescence search)
Until this point we’ve been dealing with fixed-depth searches. Since these programs are limited by how far they can look ahead, they can easily miss multi-move sequences that take place towards the terminal nodes. This is known as the horizon effect.
到目前为止,我们一直在处理固定深度的搜索。 由于这些程序受到它们可以向前看多远的限制,因此它们很容易错过发生在终端节点上的多步序列。 这就是所谓的地平线效应 。
An example of the horizon effect in chess would be declining a favorable exchange. If the AI only notices that it is down a piece without knowing that it can recapture on the next turn with a good position, then it is unlikely to play that move and will miss it.
国际象棋中视界效应的一个例子就是减少有利的交换。 如果AI仅在不知道它可以在下一回合以良好位置重新夺回的情况下注意到它处于下降状态,则不太可能打出这一步而错过。
The way around this is to perform a second limited search on the “unstable” terminal nodes. This is a quiescence search, as it is meant to resolve a dynamic position into a stable one where the evaluation function will be more accurate. This mitigates the horizon effect for the nodes that are the most susceptible to it.
解决此问题的方法是在“不稳定”的终端节点上执行第二次受限搜索。 这是一种静态搜索,因为它意在将动态位置解析为稳定的位置,从而使评估功能更加准确。 这减轻了最易受其影响的节点的地平线效应。

In chess, a position may be called unstable if any pieces can be captured. This limited search will only look at capturing moves, so its branching factor will be significantly smaller than the main search. Thanks to this, the search is also allowed to go on at a higher depth than the original search.
在国际象棋中,如果可以捕获任何棋子,则该位置可能称为不稳定。 这种有限的搜索将仅着眼于捕获的移动,因此其分支因子将明显小于主搜索。 因此,搜索的深度也比原始搜索高。
电脑如何下棋 (How computers play chess)
Depth-limited searches with an imperfect evaluation function will always lead to errors in play. Computers can only manage to approximate a perfect strategy, so they all have weaknesses. The horizon effect was one of these weaknesses. A more unusual one is search pathology, in which the search gets worse as its depth increases. Luckily, this doesn’t happen for chess.
评估功能不完善的深度限制搜索将始终导致播放错误。 计算机只能设法近似完美的策略,因此它们都有缺点。 地平线效应是这些弱点之一。 一种更不寻常的是搜索病理学 ,其中搜索随着深度的增加而变差。 幸运的是,国际象棋不会发生这种情况。
Chess computers are extremely good with direct attacks and sharp lines. When it comes to “quieter” positions based more on positional play, they tend to fail. However, since the past 20 years they’ve managed to rise above human players in skill. Better optimization and knowledge-based heuristics on the game have closed the gap.
国际象棋计算机非常擅长直接攻击和清晰的线条。 当谈到更多基于位置游戏的“安静”位置时,它们往往会失败。 然而,自从过去20年以来,他们在技术上已经超越了人类。 更好的优化和基于知识的游戏启发式方法填补了这一空白。
跟着我: (Follow me:)
WordPress: https://austeretriceratops.wordpress.com/
WordPress: https : //austeretriceratops.wordpress.com/
翻译自: https://medium.com/the-innovation/the-anatomy-of-a-chess-ai-2087d0d565
国际象棋ai下载
http://www.taodudu.cc/news/show-4952121.html
相关文章:
- java国际象棋_chess 一个用JAVA编写的国际象棋的程序 - 下载 - 搜珍网
- java游戏下载象棋暗棋_JS小游戏之象棋暗棋源码详解
- python·pygame小游戏--中国象棋(原码附上,免费下载)
- 提示信息国际化配置
- mysql国际化存储方案
- Flutter的国际化方式
- Spring Boot——国际化
- 国际化 中英文切换
- VSCode插件开发 国际化
- 国际化多语言
- 国际化设计方案概要
- Go 程序的国际化
- SpringBoot项目国际化
- Laravel 如何实现中英文国际化
- java 国际化方案,java 项目国际化完全实现
- springcloud微服务国际化
- springboot国际化配置中英文切换
- [Swift]国际化
- java国际化实现_JAVA实现国际化
- android 国际化方案 简书,国际化
- 国际化(Internationalization)被缩写为I18N, 即只取首尾两个字母, 中间字母为18个。
- 宝骏530中控屏怎么安装软件_#申精#宝骏530改装中控大屏导航
- 闲置手机改摩托车车机导航,支持短时停车休眠,长时停车断电,点火开机(大屏平板也可参照此方案用于汽车)
- 【软件定义汽车】SOA协议DDS和Some/IP对比
- 御用导航提示页面_终实现微信位置发送到汽车导航 越用越好用
- 电动汽车行业蓬勃发展,是时候关注电动汽车软件了
- 【vue】vue网站设计----汽车导航网站
- LabVIEW开发汽车惯性导航系统测试
- 收音机RDS功能介绍
- C++版本ECDSA-with-SHA256签名验证
国际象棋ai下载_国际象棋AI的解剖相关推荐
- ai模型_这就是AI的样子:用于回答问题的BiDAF模型
ai模型 We at Zetane are all about democratizing AI, but getting to the laudable goal of empowering mor ...
- ai人工智能_当AI接手我们的三种情况时
ai人工智能 不像Luddites (Unlike the Luddites) In the 19th century, a group of textile workers, know as the ...
- 用python实现ai围棋_围棋AI.Leela+Python脚本分析棋谱
完成了Sabaki+LeelaSabaki+Leela GTP搭建完美围棋AI平台后,在"飞扬围棋论坛"看到有棋友介绍用Leela+Python脚本分析棋谱,于是也试了一下. 软件 ...
- python api调用百度ai平台_百度ai开放平台使用方法(附带详细案例步骤)
百度ai开放平台 1.百度ai开放平台内有众多功能,如文字识别,语音技术等等内容,本文章以身份证识别为例子,教大家怎么使用它啦 链接走起:https://cloud.baidu.com/?from=c ...
- java ai库_百度AI开放平台 Java SDK
安装Java SDK Java SDK主要目录结构 com.baidu.aip ├── auth //签名相关类 ├── http //Http通信相关类 ├── client //公用类 ├── e ...
- python国际象棋ai程序_用Python编写一个国际象棋AI程序
最近我用Python做了一个国际象棋程序并把代码发布在Github上了.这个代码不到1000行,大概20%用来实现AI.在这篇文章中我会介绍这个AI如何工作,每一个部分做什么,它为什么能那样工作起来. ...
- python国际象棋ai程序_使用Python创建属于你的国际象棋AI
使用Python创建属于你的国际象棋AI Python3 最后更新 2020-10-23 16:23 阅读 120 最后更新 2020-10-23 16:23 阅读 120 Python3 ##Fly ...
- python国际象棋ai程序_用 Python 编写一个国际象棋 AI 程序
最近我用Python做了一个国际象棋程序并把代码发布在Github上了.这个代码不到1000行,大概20%用来实现AI.在这篇文章中我会介绍这个AI如何工作,每一个部分做什么,它为什么能那样工作起来. ...
- python编写ai电话_用Python编写一个国际象棋AI程序
最近我用Python做了一个国际象棋程序并把代码发布在Github上了.这个代码不到1000行,大概20%用来实现AI.在这篇文章中我会介绍这个AI如何工作,每一个部分做什么,它为什么能那样工作起来. ...
最新文章
- R语言dim函数返回NULL
- js和php获取页面的url信息
- 关于PR转PO的注意事项
- Mysql流程控制结构
- Too many files open; check that FILES = 20 in your CONFIG.SYS file 解决方案
- JavaScript中创建对象的方法
- java不同进程的相互唤醒_Java线程生命周期与状态切换
- 亲密关系沟通-【表达情绪】如何说出感受却不伤人
- uniapp-蓝牙模块封装
- 简易c语言编程软件,c语言开发工具下载
- iOS使用得图SDK开发VR播放器
- 定点运算之补码一位乘法(Booth算法)
- 《SEM长尾搜索营销策略解密》一一2.8 长尾虽好,但核心不可或缺
- Eclipse中source folder、folder、package的区别?
- 总有一项适合你:联想 Miix2 8寸版触摸屏失灵的各项解决方案
- 5个典型实例告诉你:什么是数据可视化
- TensorFlow-GPU的安装及keras的安装
- p2p打洞stun的原理
- QtCreator插件开发(四)——QtCreator编辑器
- 青云QingCloud与陕中二院联手打造智慧医院范本
热门文章
- 新鲜出炉!最新CKA备考指南!!
- 金九银十,看看你在哪个阶段
- Fire Game FZU - 2150 (水搜索)
- 【无标题】ubuntu添加文件到mkinitramfs命令生成的initramfs中
- poweriso 红旗linux,下载PowerISO
- 计算机维修管理国内外研究现状,管理信息系统的研究背景及国内外现状
- 【java毕业设计】基于javaEE+原生servlet+tomcat的教师工资管理系统设计与实现(毕业论文+程序源码)——教师工资管理系统
- [ICLR 2018] mixup: Beyond Empirical Risk Minimization
- 博弈论学习笔记(三)迭代剔除和中位选民定理
- 促进高校内涵发展教学质量提高数码钢琴实训室建设方案