【MySQL】17-超详细的MySQL聚合函数总结
目录
- 1. 聚合函数介绍
- 1.1 AVG和SUM函数
- 1.2 MIN和MAX函数
- 1.3 COUNT函数
- 2. GROUP BY
- 2.1 基本使用
- 2.2 使用多个列分组
- 2.3 GROUP BY中使用WITH ROLLUP
- 3. HAVING
- 3.1 基本使用
- 3.2 WHERE和HAVING的对比
- 4. SELECT的执行过程
- 4.1 查询的结构
- 4.2 SELECT执行顺序
上一篇博文介绍了MySQL中的单行函数,这一章介绍MySQL中的多行函数,也称为聚合函数,是一种多进单出的函数 (如查询所有员工中工资最大的那一个员工) 。
1. 聚合函数介绍
这里我们只介绍常用的几个聚合函数。
1.1 AVG和SUM函数
| 函数 | 作用 |
|---|---|
| AVG() | 返回该字段的平均值 |
| SUM() | 返回该字段的总和 |
【注意】
AVG和SUM函数只适用于数值类型的字段,对字符串和日期时间类型的字段使用这些函数是没有意义的,在Oracle中甚至会直接报错。
举个栗子:
SELECT AVG(salary), SUM(salary)
FROM employees;
查询结果:
![]()
1.2 MIN和MAX函数
| 函数 | 作用 |
|---|---|
| MIN() | 返回该字段的最小值 |
| MAX() | 返回该字段的最大值 |
MIN和MAX函数支持数值类型、字符串类型 (ASCII码值) 和日期时间类型的字段。
举个栗子:
SELECT MAX(salary), MIN(salary),MAX(last_name), MIN(last_name),MAX(hire_date), MIN(hire_date)
FROM employees;
查询结果:
![]()
1.3 COUNT函数
COUNT函数作用是统计指定字段在查询结果中出现的个数。也就是查询结果有多少条记录。
举个栗子:
SELECT COUNT(employee_id), COUNT(salary)
FROM employees;
查询结果:

如果COUNT()函数括号内是数字、字符串或者 * 号,是能统计表中一共有多少条数据的。如下代码所示:
SELECT COUNT('a'), COUNT(*), COUNT(1)
FROM employees;
查询结果:
![]()
【注意】
如果字段中有NULL,那么COUNT()函数只会计算该字段中不是NULL的数据的个数。
举个栗子:
SELECT COUNT(commission_pct)
FROM employees;
查询结果:
![]()
- 公式:AVG() = SUM() / COUNT()
举个栗子:
SELECT AVG(commission_pct), SUM(commission_pct) / COUNT(commission_pct)
FROM employees;
查询结果:
![]()
但是这个计算结果,意思是计算公司内有奖金的员工的平均奖金率。而如果要计算公司所有员工 (包括没有奖金的员工) 的评价奖金率,我们应该进行如下的计算:
# 方式一
SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct, 0)) AS "avg_pct"
FROM employees;# 方式二
SELECT AVG(IFNULL(commission_pct, 0)) AS "avg_pct"
FROM employees;
查询结果:
![]()
统计表中的记录数,上面介绍了3种方式:COUNT(*) 、COUNT(1) 和 COUNT(具体字段) 。那么这里有一个自然的问题:这三种方式那个效率更高呢?
- 如果使用的是 MyISAM 存储引擎,则三者效率相同,都是 O(1)O(1)O(1) 。因为MyISAM中专门有一个变量实时记录表的行数。
- 如果使用的是 InnoDB 存储引擎,则三者效率从高到低分别是:COUNT(*) = COUNT(1) > COUNT(具体字段) 。
2. GROUP BY
GROUP BY是对某个字段进行分组操作。上一节中的求平均函数 AVG() 函数针对的都是整个员工表 employees 的平均工资,那么有没有办法查询某个部门 department_id 或某个工种 job_id 的员工的平均工资呢?只需要使用关键字 GROUP BY 对字段进行分组即可。
2.1 基本使用
【例子1】想查询员工表 employees 中各个部门的平均工资和最高工资。如下图所示:
SELECT department_id, AVG(salary), MAX(salary)
FROM employees
GROUP BY department_id;
查询结果:
![]()
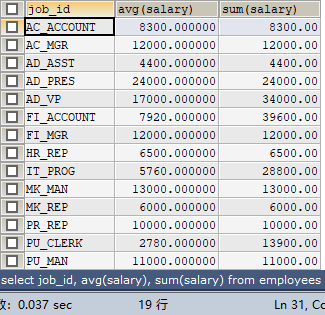
【例子2】查询员工表 employees 中各个工种 job_id 的平均工资和工资总和。
SELECT job_id, AVG(salary), SUM(salary)
FROM employees
GROUP BY job_id;
查询结果:
2.2 使用多个列分组
上一节中只是按照一个字段 (如部门 department_id 或 工种 job_id ) 进行分组。那有没有可能,可以先按照部门 department_id 分组,再按照工种 job_id 分组呢?答案是可以的。
在MySQL中,只需要在关键字 GROUP BY 后添加你想要分组的所有字段,并用逗号分隔,即可实现多列分组。
举个栗子:查询各个部门 department_id 中各个工种 job_id 的平均工资。
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id;
查询结果:
![]()
【注意】
department_id和job_id的先后顺序对查询结果没有影响。
【知识点2】SELECT中出现的非组函数的字段必须声明在 GROUP BY 中;反之,GROUP BY中声明的字段可以不出现在SELECT中。
举个例子,下面的代码中是错误的:
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id;
第3行中只对部门 department_id 进行了分组,意思是查询各个部门的平均工资。而第1行代码中却又加了查询工种 job_id 字段,这是错误且没有意义的。
查询结果:

虽然在MySQL中没有报错,但是在Oracle是会报错的。
【知识点3】GROUP BY 声明位置在FROM后面、WHERE后面、ORDER BY前面、LIMIT前面。
2.3 GROUP BY中使用WITH ROLLUP
WITH ROLLUP 关键字声明在 GROUP BY 最后面,意思是除了查询各个分组的信息,还会查询整个表的信息。
举个栗子:查询员工表 employees 中各个部门的平均工资。加上WITH ROLLUP后,在查询结果表的最后一行会加上所有员工的平均工资。
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id WITH ROLLUP;
查询结果:
![]()
【注意】
WITH ROLLUP与ORDER BY是相互排斥的。这两个关键字不能同时使用。
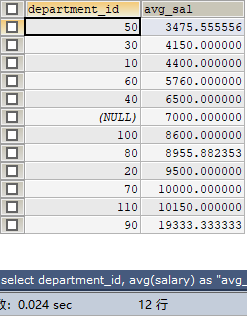
举个栗子:查询员工表 employees 中各个部门的平均工资,并按平均工资从低到高排列。在MySQL5.7中会报错,在MySQL8.0中会把全员工的平均工资参与排序。
# 正确写法
SELECT department_id, AVG(salary) AS "avg_sal"
FROM employees
GROUP BY department_id
ORDER BY avg_sal ASC;
查询结果:
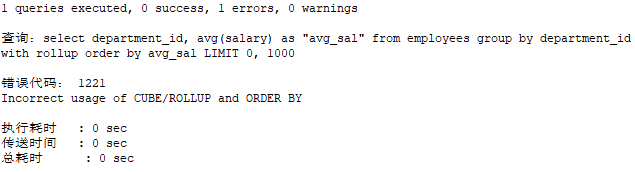
【MySQL8.0】
SELECT department_id, AVG(salary) AS "avg_sal"
FROM employees
GROUP BY department_id WITH ROLLUP
ORDER BY avg_sal ASC;
查询结果:

【MySQL5.7】
SELECT department_id, AVG(salary) AS "avg_sal"
FROM employees
GROUP BY department_id WITH ROLLUP
ORDER BY avg_sal;
查询结果:
3. HAVING
HAVING关键字的作用是过滤数据。与WHERE不同,HAVING是与GROUP BY结合使用的。
3.1 基本使用
【例子1】查询员工表 employees 中各个部门中最高工资比10000高的部门信息。
# 错误的写法1
SELECT department_id, MAX(salary) AS "max_sal"
FROM employees
GROUP BY department_id
WHERE max_sal > 10000;# 错误的写法2
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
WHERE MAX(salary) > 10000;
查询结果:

【结论1】
如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则报错。
HAVING必须放在GROUP BY后面。
# 正确的写法1
SELECT department_id, MAX(salary) AS "max_sal"
FROM employees
GROUP BY department_id
HAVING max_sal > 10000;# 正确的写法2
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
查询结果:
![]()
【注意】
虽说HAVING与GROUP BY结合使用,但没有GROUP BY的情况下,使用HAVING并不会报错。但是这样做没有意义。
SELECT last_name, salary
FROM employees
HAVING salary > 8000;
查询结果:
![]()
【例子2】查询员工表 employees 中各个部门编号 department_id 为 10, 20, 30, 40 的这四个部门中最高工资比10000高的部门信息。
# 方式一:推荐,执行效率高于方式二
SELECT department_id, MAX(salary)
FROM employees
WHERE department_id IN(10, 20, 30, 40)
GROUP BY department_id
HAVING MAX(salary) > 10000;# 方式二
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN(10, 20, 30, 40);
查询结果:
![]()
【结论】
- 当过滤条件中有聚合函数时,过滤条件必须写在HAVING中。
- 当过滤条件中没有聚合函数时,过滤条件写在HAVING和WHERE中都可以。但是建议优先写在WHERE中,因为WHERE执行效率比HAVING高。
3.2 WHERE和HAVING的对比
- 从适用范围上来讲,HAVING的适用范围比WHERE更广。因为HAVING既可以写聚合函数的过滤条件,又可以写非聚合函数的过滤条件。而WHERE只能写非聚合函数的过滤条件。
- 如果过滤条件都是非聚合函数的前提下,WHERE的执行效率要比HAVING高。
4. SELECT的执行过程
4.1 查询的结构
学习至今,SQL中的所有基础查询操作都已经介绍完毕了。总结一下学习过的所有查询语句,其结构顺序如下代码所示:
# SQL92语法
SELECT ..., ..., ...(存在聚合函数)
FROM ..., ...
WHERE 多表查询的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ..., ...
HAVING 包含聚合函数的过滤条件
ORDER BY ..., ...(ASC / DESC)
LIMIT ..., ...
# SQL99语法
SELECT ..., ..., ...(存在聚合函数)
FROM ... (LEFT / RIGHT OUTER)JOIN ... ON 多表查询的连接条件
(LEFT / RIGHT OUTER)JOIN ... ON 多表查询的连接条件
WHERE 不包含聚合函数的过滤条件
GROUP BY ..., ...
HAVING 包含聚合函数的过滤条件
ORDER BY ..., ...(ASC / DESC)
LIMIT ..., ...
上述关键字的顺序不能错,否则会报错。
4.2 SELECT执行顺序
下面的内容是查询章节的核心内容。理解了这节的内容,前面很多问题都能得到解答。
在SQL中,查询语句的执行顺序并不是按顺序从上往下执行的。SELECT语句的实行顺序为:
FROM --> ON --> (LEFT / RIGHT OUTER)JOIN --> WHERE --> GROUP BY --> HAVING --> SELECT --> DISTINCT --> ORDER BY --> LIMIT
- 执行顺序在前的别名可以用在执行顺序在后的语句中。这就解释了为什么SELECT中起的别名能在ORDER BY中使用,却不能在WHERE中使用。因为WHERE的执行顺序在SELECT的前面,ORDER BY在SELECT的后面。
- 这也解释了为什么使用WHERE要比HAVING效率高。WHERE在前面先过滤了很多不要的数据,再进行分组,防止为很多的数据分好组,却被过滤掉而做无用功。
【MySQL】17-超详细的MySQL聚合函数总结相关推荐
- 了解MySQL(超详细的MySQL工作原理 体系结构)
了解MySQL(超详细的MySQL工作原理 体系结构) 1.MySQL体系结构 2.MySQL内存结构 3.MySQL文件结构 4.innodb体系结构 一.了解MySQL前你需要知道的 引擎是什么: ...
- 超详细的MySQL工作原理 体系结构
超详细的MySQL工作原理 体系结构 妖精的杂七杂八 2020-08-13 13:54:12 了解MySQL(超详细的MySQL工作原理 体系结构) 1.MySQL体系结构 2.MySQL内存结构 3 ...
- 超详细的MySQL入门教程(四)
MySQL:简单的增删改查 查询数据 基本语法介绍 打印任意值 查询表中全部数据 查询表中部分字段 限定条件查询 例1:查询编号值小于指定值的记录 例2:查询地址不等于某值的记录 例3:查询一级地址等 ...
- 【MySQL】16-超详细的MySQL单行函数汇总
目录 1. MySQL函数简介 1.1 按数据类型分类 1.2 按输入数量分类 2. 数值函数 2.1 基本函数 2.2 角度与弧度互换函数 2.3 三角函数 2.4 指数与对数 2.5 进制间的转换 ...
- 一份超详细的MySQL高性能优化实战总结!
一份超详细的MySQL高性能优化实战总结! MySQL 对于很多 Linux 从业者而言,是一个非常棘手的问题,多数情况都是因为对数据库出现问题的情况和处理思路不清晰. 在进行 MySQL 的优化之前 ...
- apache mysql 连接数 winnt,APACHE PHP MYSQL PHPMYADMIN超详细配置教程
Apache+PHP+MySQL+phpMyAdmin超详细配置教程 安装之前需要下载 Apache2.0.59 PHP4.4.4Win32 MySQL4.12 phpMyAdmin2.9.1.1rc ...
- 【超详细】MySQL零基础入门实战
文章目录 1.MySQL入门 1.1.源码安装MySQL5.7 1.2.Docker安装MySQL5.7 1.3.忘记MySQL超户密码 1.4.MySQL支持简体中文 2.MySQL数据库操作 2. ...
- 超详细的MySQL三万字总结
文章目录 MySQL基础 数据库的介绍 数据库概述 数据的存储方式 数据库的概念 常见数据库排行榜 数据库的安装与卸载 数据库的安装 数据库的卸载 数据库服务的启动与登录 Windows 服务方式启动 ...
- MYSQL中最基础的的聚合函数(重点!)
一.聚合函数的介绍 在数据库查询过程中,不仅只返回数据的基础信息,有时还需对这些数据进行统计和汇总.MySQL 提供了聚合函数,用于实现这些高级功能. 二.聚合函数的基础运用 聚合函数用于对一组值进行 ...
最新文章
- H5使用百度地图SDK获取用户当前位置并且标记显示在地图
- 梳理:python—同一个类中的方法调用
- python 模拟浏览器下载文件-python爬虫:使用Selenium模拟浏览器行为
- Spring注解使用方法
- 将Java应用程序作为Windows服务安装
- Java提高篇——JVM加载class文件的原理机制
- 2017.8.7 序列计数 思考记录
- CSS进阶(五)border
- comment on 视图_oracle 使用comment语句添加表注释
- python3函数重载_9.20 利用函数注解实现方法重载
- zip 后压缩包带路径
- linux chmod -r,linux chmod -R 777 / 的危害
- 浅谈toB交付质量体系建设
- arduino——ATtiny85 SSD1306 + DHT
- 计算机性能和拷机软件
- 面试算法 香槟塔 ,算法:暴力算法
- 苹果6s照相快门声音设置_苹果手机内置录屏技巧,还能加入自己的声音,花3秒钟设置一下...
- Ngrok的外网映射
- CF407B 「Long Path」
- 如何将java集合中重复的元素取出来