自动化所在语音识别研究中获进展
自动化所在语音识别研究中获进展
2019-08-05自动化研究所
【字体:大 中 小】

语音播报

中国科学院自动化研究所智能交互团队在环境鲁棒性、轻量级建模、自适应能力以及端到端处理等几个方面进行持续攻关,在语音识别方面获新进展,相关成果将在全球语音学术会议INTERSPEECH2019发表。
现有端到端语音识别系统难以有效利用外部文本语料中的语言学知识,针对这一问题,陶建华、易江燕、白烨等人提出采用知识迁移的方法,首先对大规模外部文本训练语言模型,然后将该语言模型中的知识迁移到端到端语音识别系统中。这种方法利用了外部语言模型提供词的先验分布软标签,并采用KL散度进行优化,使语音识别系统输出的分布与外部语言模型输出的分布接近,从而有效提高语音识别的准确率。
语音关键词检测在智能家居、智能车载等场景中有着重要作用。面向终端设备的语音关键词检测对算法的时间复杂度和空间复杂度有着很高的要求。当前主流的基于残差神经网络的语音关键词检测,需要20万以上的参数,难以在终端设备上应用。为了解决这一问题,陶建华、易江燕、白烨等人提出基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测方法。该方法采用时延神经网络进行降采样,通过自注意力机制捕获时序相关性;并采用共享权值的方法,将自注意力机制中的多个矩阵共享,使其映射到相同的特征空间,从而进一步压缩了模型的尺寸。与目前的性能最好的基于残差神经网络的语音关键词检测模型相比,他们提出的方法在识别准确率接近的前提下,模型大小仅为残差网络模型的1/20,有效降低了算法复杂度。
针对RNN-Transducer模型存在收敛速度慢、难以有效进行并行训练的问题,陶建华、易江燕、田正坤等人提出了一种Self-attention Transducer (SA-T)模型,主要在以下三个方面实现了改进:(1)通过自注意力机制替代RNN进行建模,有效提高了模型训练的速度;(2)为了使SA-T能够进行流式的语音识别和解码,进一步引入了Chunk-Flow机制,通过限制自注意力机制范围对局部依赖信息进行建模,并通过堆叠多层网络对长距离依赖信息进行建模;(3)受CTC-CE联合优化启发,将交叉熵正则化引入到SA-T模型中,提出Path-Aware Regularization(PAR),通过先验知识引入一条可行的对齐路径,在训练过程中重点优化该路径。经验证,上述改进有效提高了模型训练速度及识别效果。
语音分离又称为鸡尾酒会问题,其目标是从同时含有多个说话人的混合语音信号中分离出不同说话人的信号。当一段语音中同时含有多个说话人时,会严重影响语音识别和说话人识别的性能。目前解决这一问题的两种主流方法分别是:深度聚类(DC, deep clustering)算法和排列不变性训练(PIT, permutation invariant training)准则算法。深度聚类算法在训练过程中不能以真实的干净语音作为目标,性能受限于k-means聚类算法;而PIT算法其输入特征区分性不足。针对DC和PIT算法的局限性,陶建华、刘斌、范存航等人提出了基于区分性学习和深度嵌入式特征的语音分离方法。首先,利用DC提取一个具有区分性的深度嵌入式特征,然后将该特征输入到PIT算法中进行语音分离。同时,为了增大不同说话人之间的距离,减小相同说话人之间的距离,引入了区分性学习目标准则,进一步提升算法的性能。所提方法在WSJ0-2mix语音分离公开数据库上获得较大的性能提升。
端到端系统在语音识别中取得突破。然而在复杂噪声环境下,端到端系统的鲁棒性依然面临巨大挑战。针对端到端系统不够鲁棒的问题,刘文举、聂帅、刘斌等人提出了基于联合对抗增强训练的鲁棒性端到端语音识别方法。具体地说,使用一个基于mask的语音增强网络、基于注意力机制的端到端语音识别网络和判别网络的联合优化方案。判别网络用于区分经过语音增强网络之后的频谱和纯净语音的频谱,可以引导语音增强网络的输出更加接近纯净语音分布。通过联合优化识别、增强和判别损失,神经网络自动学习更为鲁棒的特征表示。所提方法在aishell-1数据集上面取得了较大的性能提升。
说话人提取是提取音频中目标说话人的声音。与语音分离不同,说话人提取不需要分离出音频中所有说话人的声音,而只关注某一特定说话人。目前主流的说话人提取方法是:说话人波束(SpeakerBeam)和声音滤波器(Voice filter)。这两种方法都只关注声音的频谱特征,而没有利用多通道信号的空间特性。因为声源是有方向性的,并且在实际环境中是空间可分的。所以,如果正确利用多通道的空间区分性,说话人提取系统可以更好地估计目标说话人。为了有效利用多通道的空间特性,刘文举、梁山、李冠君等人提出了方向感知的多通道说话人提取方法。首先多通道的信号先经过一组固定波束形成器,来产生不同方向的波束。进而DNN采用attention机制来确定目标信号所在的方向,来增强目标方向的信号。最后增强后的信号经过SpeakerBeam通过频谱线索来提取目标信号。提出的算法在低信噪比或同性别说话人混合的场景中性能提升明显。
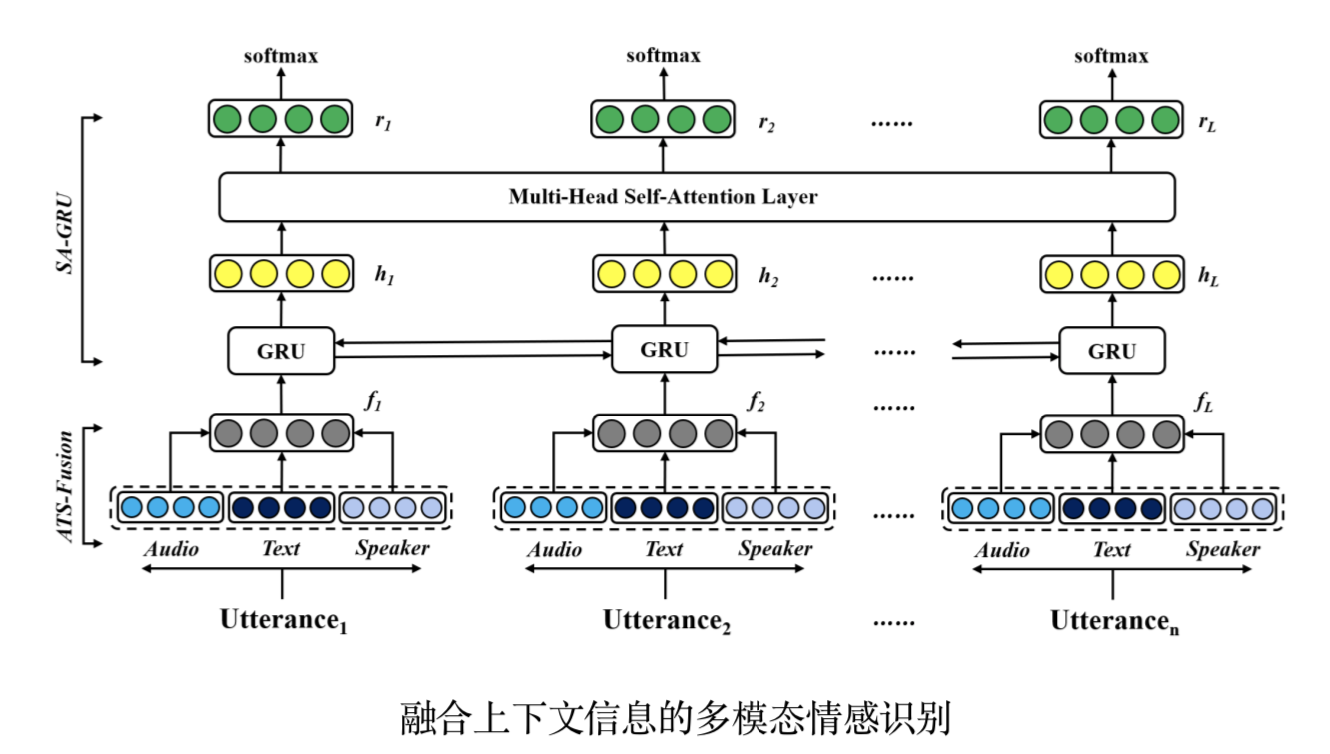
传统的对话情感识别方法通常从孤立的句子中识别情感状态,未能充分考虑对话中的上下文信息对于当前时刻情感状态的影响。针对这一问题,陶建华、刘斌、连政等人提出了一种融合上下文信息的多模态情感识别方法。在输入层,采用注意力机制对文本特征和声学特征进行融合;在识别层,采用基于自注意力机制的双向循环神经网络对长时上下文信息进行建模;为了能够有效模拟真实场景下的交互模式,引入身份编码向量作为额外的特征输入到模型,用于区分交互过程中的身份信息。在IEMOCAP情感数据集上对算法进行了评估,实验结果表明,该方法相比现有最优基线方法,在情感识别性能上提升了2.42%。
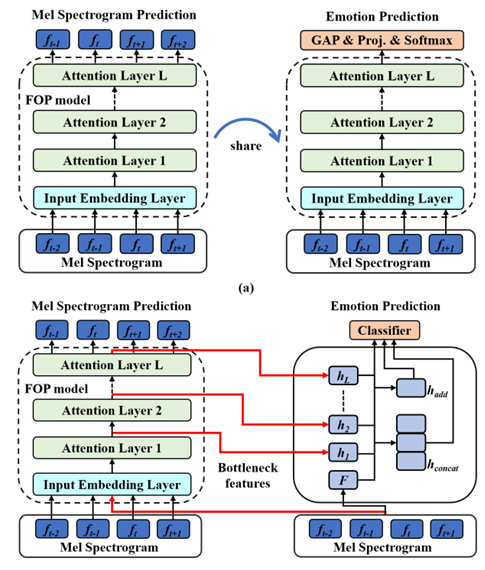
由于情感数据标注困难,语音情感识别面临着数据资源匮乏的问题。虽然采用迁移学习方法,将其他领域知识迁移到语音情感识别,可以在一定程度上缓解低资源的问题,但是这类方法并没有关注到长时信息对语音情感识别的重要作用。针对这一问题,陶建华、刘斌、连政等人提出了一种基于未来观测预测(Future Observation Prediction, FOP)的无监督特征学习方法。FOP采用自注意力机制,能够有效捕获长时信息;采用微调(Fine-tuning)和超列(Hypercolumns)两种迁移学习方法,能够将FOP学习到的知识用于语音情感识别。该方法在IEMOCAP情感数据集上的性能超过了基于无监督学习策略的语音情感识别。
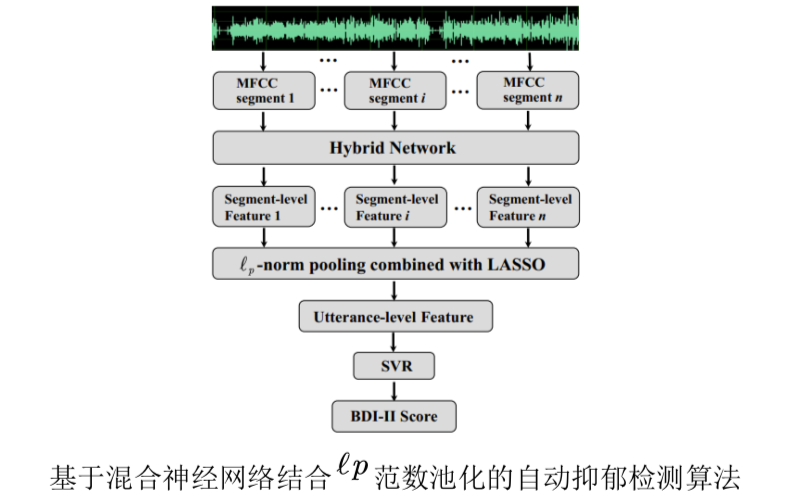
相关生理学研究表明,MFCC (Mel-frequency cepstral coefficient)对于抑郁检测来说是一种有区分性声学特征,这一研究成果使得不少工作通过MFCC来辨识个体的抑郁程度。但是,上述工作中很少使用神经网络来进一步捕获MFCC中反映抑郁程度的高表征特征;此外,针对抑郁检测这一问题,合适的特征池化参数未能被有效优化。针对上述问题,陶建华、刘斌、牛明月等人提出了一种混合网络并结合LASSO (least absolute shrinkage and selection operator)的lp范数池化方法来提升抑郁检测的性能。首先将整段音频的MFCC切分成具有固定大小的长度;然后将这些切分的片段输入到混合神经网络中以挖掘特征序列的空间结构、时序变化以及区分性表示与抑郁线索相关的信息,并将所抽取的特征记为段级别的特征;最后结合LASSO的lp范数池化将这些段级别的特征进一步聚合为表征原始语音句子级的特征。
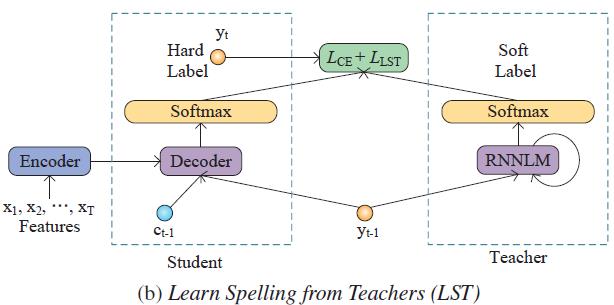
基于知识迁移的端到端语音识别系统
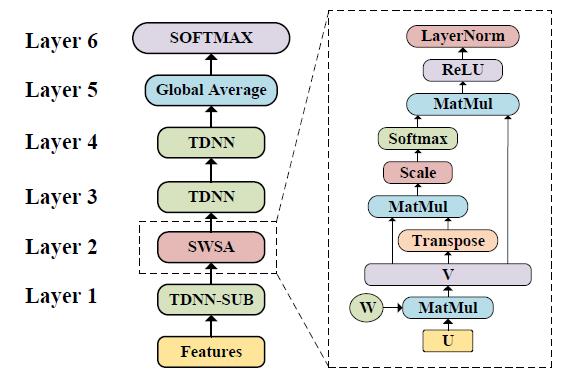
基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测
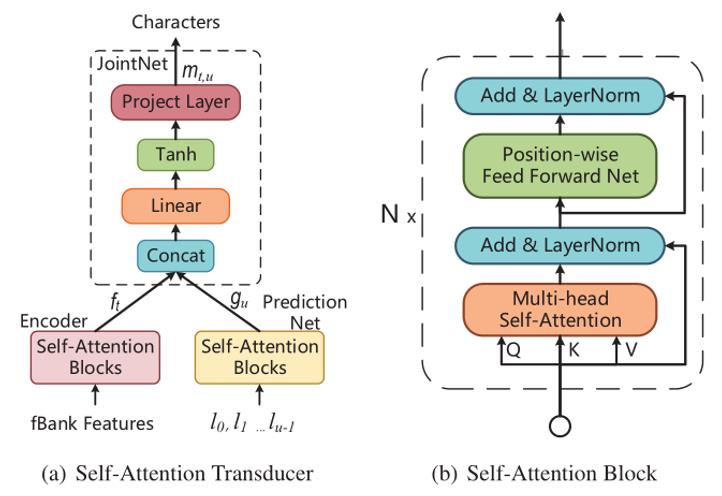
基于自注意力机制的端到端语音转写模型

基于区分性学习和深度嵌入式特征的语音分离方法总体框图
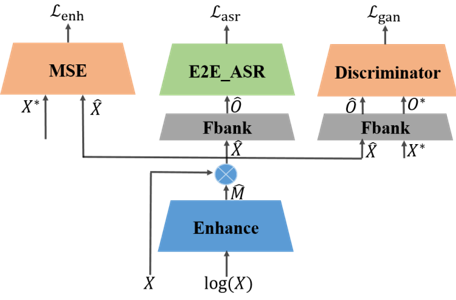
基于联合对抗增强训练的鲁棒性端到端语音识别总体框图
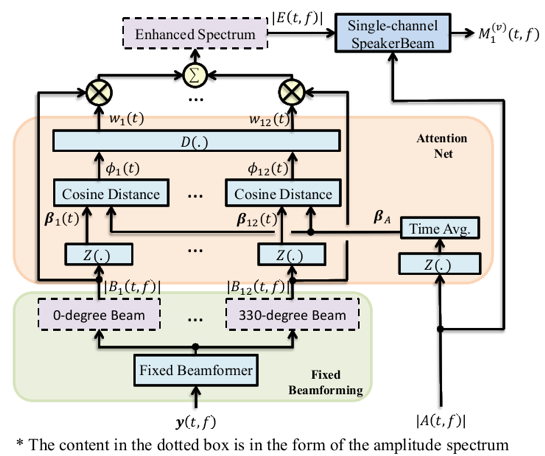
方向感知的多通道说话人提取方法框图
中国科学院自动化研究所智能交互团队在环境鲁棒性、轻量级建模、自适应能力以及端到端处理等几个方面进行持续攻关,在语音识别方面获新进展,相关成果将在全球语音学术会议INTERSPEECH2019发表。
现有端到端语音识别系统难以有效利用外部文本语料中的语言学知识,针对这一问题,陶建华、易江燕、白烨等人提出采用知识迁移的方法,首先对大规模外部文本训练语言模型,然后将该语言模型中的知识迁移到端到端语音识别系统中。这种方法利用了外部语言模型提供词的先验分布软标签,并采用KL散度进行优化,使语音识别系统输出的分布与外部语言模型输出的分布接近,从而有效提高语音识别的准确率。
语音关键词检测在智能家居、智能车载等场景中有着重要作用。面向终端设备的语音关键词检测对算法的时间复杂度和空间复杂度有着很高的要求。当前主流的基于残差神经网络的语音关键词检测,需要20万以上的参数,难以在终端设备上应用。为了解决这一问题,陶建华、易江燕、白烨等人提出基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测方法。该方法采用时延神经网络进行降采样,通过自注意力机制捕获时序相关性;并采用共享权值的方法,将自注意力机制中的多个矩阵共享,使其映射到相同的特征空间,从而进一步压缩了模型的尺寸。与目前的性能最好的基于残差神经网络的语音关键词检测模型相比,他们提出的方法在识别准确率接近的前提下,模型大小仅为残差网络模型的1/20,有效降低了算法复杂度。
针对RNN-Transducer模型存在收敛速度慢、难以有效进行并行训练的问题,陶建华、易江燕、田正坤等人提出了一种Self-attention Transducer (SA-T)模型,主要在以下三个方面实现了改进:(1)通过自注意力机制替代RNN进行建模,有效提高了模型训练的速度;(2)为了使SA-T能够进行流式的语音识别和解码,进一步引入了Chunk-Flow机制,通过限制自注意力机制范围对局部依赖信息进行建模,并通过堆叠多层网络对长距离依赖信息进行建模;(3)受CTC-CE联合优化启发,将交叉熵正则化引入到SA-T模型中,提出Path-Aware Regularization(PAR),通过先验知识引入一条可行的对齐路径,在训练过程中重点优化该路径。经验证,上述改进有效提高了模型训练速度及识别效果。
语音分离又称为鸡尾酒会问题,其目标是从同时含有多个说话人的混合语音信号中分离出不同说话人的信号。当一段语音中同时含有多个说话人时,会严重影响语音识别和说话人识别的性能。目前解决这一问题的两种主流方法分别是:深度聚类(DC, deep clustering)算法和排列不变性训练(PIT, permutation invariant training)准则算法。深度聚类算法在训练过程中不能以真实的干净语音作为目标,性能受限于k-means聚类算法;而PIT算法其输入特征区分性不足。针对DC和PIT算法的局限性,陶建华、刘斌、范存航等人提出了基于区分性学习和深度嵌入式特征的语音分离方法。首先,利用DC提取一个具有区分性的深度嵌入式特征,然后将该特征输入到PIT算法中进行语音分离。同时,为了增大不同说话人之间的距离,减小相同说话人之间的距离,引入了区分性学习目标准则,进一步提升算法的性能。所提方法在WSJ0-2mix语音分离公开数据库上获得较大的性能提升。
端到端系统在语音识别中取得突破。然而在复杂噪声环境下,端到端系统的鲁棒性依然面临巨大挑战。针对端到端系统不够鲁棒的问题,刘文举、聂帅、刘斌等人提出了基于联合对抗增强训练的鲁棒性端到端语音识别方法。具体地说,使用一个基于mask的语音增强网络、基于注意力机制的端到端语音识别网络和判别网络的联合优化方案。判别网络用于区分经过语音增强网络之后的频谱和纯净语音的频谱,可以引导语音增强网络的输出更加接近纯净语音分布。通过联合优化识别、增强和判别损失,神经网络自动学习更为鲁棒的特征表示。所提方法在aishell-1数据集上面取得了较大的性能提升。
说话人提取是提取音频中目标说话人的声音。与语音分离不同,说话人提取不需要分离出音频中所有说话人的声音,而只关注某一特定说话人。目前主流的说话人提取方法是:说话人波束(SpeakerBeam)和声音滤波器(Voice filter)。这两种方法都只关注声音的频谱特征,而没有利用多通道信号的空间特性。因为声源是有方向性的,并且在实际环境中是空间可分的。所以,如果正确利用多通道的空间区分性,说话人提取系统可以更好地估计目标说话人。为了有效利用多通道的空间特性,刘文举、梁山、李冠君等人提出了方向感知的多通道说话人提取方法。首先多通道的信号先经过一组固定波束形成器,来产生不同方向的波束。进而DNN采用attention机制来确定目标信号所在的方向,来增强目标方向的信号。最后增强后的信号经过SpeakerBeam通过频谱线索来提取目标信号。提出的算法在低信噪比或同性别说话人混合的场景中性能提升明显。
传统的对话情感识别方法通常从孤立的句子中识别情感状态,未能充分考虑对话中的上下文信息对于当前时刻情感状态的影响。针对这一问题,陶建华、刘斌、连政等人提出了一种融合上下文信息的多模态情感识别方法。在输入层,采用注意力机制对文本特征和声学特征进行融合;在识别层,采用基于自注意力机制的双向循环神经网络对长时上下文信息进行建模;为了能够有效模拟真实场景下的交互模式,引入身份编码向量作为额外的特征输入到模型,用于区分交互过程中的身份信息。在IEMOCAP情感数据集上对算法进行了评估,实验结果表明,该方法相比现有最优基线方法,在情感识别性能上提升了2.42%。
由于情感数据标注困难,语音情感识别面临着数据资源匮乏的问题。虽然采用迁移学习方法,将其他领域知识迁移到语音情感识别,可以在一定程度上缓解低资源的问题,但是这类方法并没有关注到长时信息对语音情感识别的重要作用。针对这一问题,陶建华、刘斌、连政等人提出了一种基于未来观测预测(Future Observation Prediction, FOP)的无监督特征学习方法。FOP采用自注意力机制,能够有效捕获长时信息;采用微调(Fine-tuning)和超列(Hypercolumns)两种迁移学习方法,能够将FOP学习到的知识用于语音情感识别。该方法在IEMOCAP情感数据集上的性能超过了基于无监督学习策略的语音情感识别。
相关生理学研究表明,MFCC (Mel-frequency cepstral coefficient)对于抑郁检测来说是一种有区分性声学特征,这一研究成果使得不少工作通过MFCC来辨识个体的抑郁程度。但是,上述工作中很少使用神经网络来进一步捕获MFCC中反映抑郁程度的高表征特征;此外,针对抑郁检测这一问题,合适的特征池化参数未能被有效优化。针对上述问题,陶建华、刘斌、牛明月等人提出了一种混合网络并结合LASSO (least absolute shrinkage and selection operator)的lp范数池化方法来提升抑郁检测的性能。首先将整段音频的MFCC切分成具有固定大小的长度;然后将这些切分的片段输入到混合神经网络中以挖掘特征序列的空间结构、时序变化以及区分性表示与抑郁线索相关的信息,并将所抽取的特征记为段级别的特征;最后结合LASSO的lp范数池化将这些段级别的特征进一步聚合为表征原始语音句子级的特征。
基于知识迁移的端到端语音识别系统
基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测
基于自注意力机制的端到端语音转写模型
基于区分性学习和深度嵌入式特征的语音分离方法总体框图
基于联合对抗增强训练的鲁棒性端到端语音识别总体框图
方向感知的多通道说话人提取方法框图
更多分享
责任编辑:叶瑞优
自动化所在语音识别研究中获进展相关推荐
- 中大李文均团队在氮循环功能基因的生物地理学分布格局研究中取得进展
中山大学生命科学学院李文均教授团队在氮循环功能基因的生物地理学分布格局研究中取得进展 稿件来源:生命科学学院 | 编辑:郑龙飞.王冬梅 | 审核:夏瑛 | 发布日期:2021-11-24 | 阅读次数 ...
- 中科大量子计算机重大突破,中国科大在量子计算研究中获重大突破
近日,中国科学技术大学微尺度物质科学国家实验室杜江峰教授领导的研究小组和香港中文大学刘仁保教授合作,通过电子自旋共振实验技术,在国际上首次通过固态体系实验实现了最优动力学解耦,极大地提高了电子自旋相干 ...
- 前沿科技 | 中科院科学家在关于运动规划的环路机制研究方面获进展
来源:中国科学院网站 今年5月11日,Nature Communications在线发表了题为<皮层上丘环路在记忆依赖感知决策任务中的作用机制>的研究论文,该研究由中国科学院科学家团队-- ...
- 前沿科技 | 中科院科学家在视觉学习行为的神经机制研究中取得进展
来源:中国科学院 6月3日,<自然-通讯>(Nature Communications)期刊在线发表了题为<眶额叶皮层通过调节初级视皮层的反应增益促进视觉偶联学习>的研究论文, ...
- 金属所等在天然生物材料力学理论研究中取得进展
生物体是由材料组成的,力学性能是材料的基本性能指标.不断提高力学性能使其更好地满足实际应用需求是天然与人造材料发展的共同目标,同时也是它们面临的共性难题.在长期的自然选择与进化过程中,天然生物材料的组 ...
- 微电子所等在二维材料异质结构光电器件研究中取得进展
半导体光伏结构因其能够有效地将太阳能转化为电能,被认为是实现清洁能源的重要途径.然而早在1961年,美国科学家肖克莱.德国科学家凯赛尔便提出光伏单元的效率由于难以避免的损耗而存在理论极限.其中,由于光 ...
- 超表面仿真>超透镜研究的国内进展
近年来,超表面和超透镜的研究是光学前沿和技术热点,超表面和超透镜被视为光学领域新的革命性技术.超表面是由大量亚波长单元在二维平面上周期或非周期排布而构成的人工结构阵列,能够对电磁波进行灵活操控.由于超 ...
- 智能家居中语音识别算法研究_语音识别研究获进展
中国科学院自动化研究所智能交互团队在环境鲁棒性.轻量级建模.自适应能力以及端到端处理等几个方面进行持续攻关,在语音识别方面获新进展,相关成果将在全球语音学术会议INTERSPEECH2019发表. 现 ...
- 口音与方言语音识别研究进展
本文总结于2021年10月30日汤志远博士在深蓝学院关于[口音与方言语音识别研究进展]的公开课,更多详细内容可以参见公开课.见文末~ 汤博士和大家一起分享了关于口音与方言语音识别的研究进展,并介绍了口 ...
最新文章
- 深度学习的算法实践和演进
- 利用SecureCRT在linux与Windows之间传输文件
- 从网络字节流中提出整数
- 1 SAP DEBUG调试改表操作手册
- 项目经理的商务指南系列之二:认识责任(敏捷开发,专家与杂家)
- ORA-02030: can only select from fixed tables/views
- HDU 2553 N皇后问题 DFS 简单题
- Qml文件的两种加载方式
- MMORPG大型游戏设计与开发(构架)
- 尼康数码相机照片数据恢复怎么办
- 非线性拟合(C++版)
- 图灵——如迷的解谜者
- 空间变换网络(STN)
- fai 安装debian
- Error running SecureCardJavaApp. Command line is too long. Shorten the command line and rerun.
- 财务人员的6大数据分析方法
- 时间转换数字与日期互转
- jquery对文本赋值和取值_jQuery常用的取值或赋值的方法
- Miniconda软件安装教程(Windows)
- gitlab仓储搭建