Kafka+Log4j实现日志集中管理
引言
前段时间写的《Spring+Log4j+ActiveMQ实现远程记录日志——实战+分析》得到了许多同学的认可,在认可的同时,也有同学提出可以使用Kafka来集中管理日志,于是今天就来学习一下。
特别说明,由于网络上关于Kafka+Log4j的完整例子并不多,我也是一边学习一边使用,因此如果有解释得不好或者错误的地方,欢迎批评指正,如果你有好的想法,也欢迎留言探讨。
第一部分 搭建Kafka环境
安装Kafka
下载:http://kafka.apache.org/downloads.html
|
1
2
|
tar zxf kafka-<VERSION>.tgz
cd kafka-<VERSION>
|
启动Zookeeper
启动Zookeeper前需要配置一下config/zookeeper.properties:

接下来启动Zookeeper
|
1
|
bin/zookeeper-server-start.sh config/zookeeper.properties
|
启动Kafka Server
启动Kafka Server前需要配置一下config/server.properties。主要配置以下几项,内容就不说了,注释里都很详细:

然后启动Kafka Server:
|
1
|
bin/kafka-server-start.sh config/server.properties
|
创建Topic
|
1
|
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
|
查看创建的Topic
|
1
|
>bin/kafka-topics.sh --list --zookeeper localhost:2181
|
启动控制台Producer,向Kafka发送消息
|
1
2
3
4
|
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
^C
|
启动控制台Consumer,消费刚刚发送的消息
|
1
2
3
|
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
|
删除Topic
|
1
|
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test
|
注:只有当delete.topic.enable=true时,该操作才有效
配置Kafka集群(单台机器上)
首先拷贝server.properties文件为多份(这里演示4个节点的Kafka集群,因此还需要拷贝3份配置文件):
|
1
2
3
|
cp config/server.properties config/server1.properties
cp config/server.properties config/server2.properties
cp config/server.properties config/server3.properties
|
修改server1.properties的以下内容:
|
1
2
3
|
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
|
同理修改server2.properties和server3.properties的这些内容,并保持所有配置文件的zookeeper.connect属性都指向运行在本机的zookeeper地址localhost:2181。注意,由于这几个Kafka节点都将运行在同一台机器上,因此需要保证这几个值不同,这里以累加的方式处理。例如在server2.properties上:
|
1
2
3
|
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
|
把server3.properties也配置好以后,依次启动这些节点:
|
1
2
3
|
bin/kafka-server-start.sh config/server1.properties &
bin/kafka-server-start.sh config/server2.properties &
bin/kafka-server-start.sh config/server3.properties &
|
Topic & Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
现在在Kafka集群上创建备份因子为3,分区数为4的Topic:
|
1
|
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 4 --topic kafka
|
说明:备份因子replication-factor越大,则说明集群容错性越强,就是当集群down掉后,数据恢复的可能性越大。所有的分区数里的内容共同组成了一份数据,分区数partions越大,则该topic的消息就越分散,集群中的消息分布就越均匀。
然后使用kafka-topics.sh的--describe参数查看一下Topic为kafka的详情:
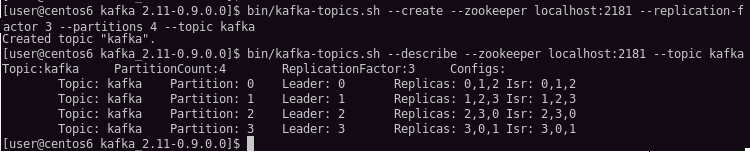
输出的第一行是所有分区的概要,接下来的每一行是一个分区的描述。可以看到Topic为kafka的消息,PartionCount=4,ReplicationFactor=3正是我们创建时指定的分区数和备份因子。
另外:Leader是指负责这个分区所有读写的节点;Replicas是指这个分区所在的所有节点(不论它是否活着);ISR是Replicas的子集,代表存有这个分区信息而且当前活着的节点。
拿partition:0这个分区来说,该分区的Leader是server0,分布在id为0,1,2这三个节点上,而且这三个节点都活着。
再来看下Kafka集群的日志:

其中kafka-logs-0代表server0的日志,kafka-logs-1代表server1的日志,以此类推。
从上面的配置可知,id为0,1,2,3的节点分别对应server0, server1, server2, server3。而上例中的partition:0分布在id为0, 1, 2这三个节点上,因此可以在server0, server1, server2这三个节点上看到有kafka-0这个文件夹。这个kafka-0就代表Topic为kafka的partion0。
第二部分 Kafka+Log4j项目整合
先来看下Maven项目结构图:
作为Demo,文件不多。先看看pom.xml引入了哪些jar包:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.8.2.1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
|
重要的内容是log4j.properties:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
log4j.rootLogger=INFO,console
# for package com.demo.kafka, log would be sent to kafka appender.
log4j.logger.com.demo.kafka=DEBUG,kafka
# appender kafka
log4j.appender.kafka=kafka.producer.KafkaLog4jAppender
log4j.appender.kafka.topic=kafka
# multiple brokers are separated by comma ",".
log4j.appender.kafka.brokerList=localhost:9092, localhost:9093, localhost:9094, localhost:9095
log4j.appender.kafka.compressionType=none
log4j.appender.kafka.syncSend=true
log4j.appender.kafka.layout=org.apache.log4j.PatternLayout
log4j.appender.kafka.layout.ConversionPattern=%d [%-5p] [%t] - [%l] %m%n
# appender console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d [%-5p] [%t] - [%l] %m%n
|
App.java里面就很简单啦,主要是通过log4j输出日志:
|
1
2
3
4
5
6
7
8
9
10
11
|
package com.demo.kafka;
import org.apache.log4j.Logger;
public class App {
private static final Logger LOGGER = Logger.getLogger(App.class);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 20; i++) {
LOGGER.info("Info [" + i + "]");
Thread.sleep(1000);
}
}
}
|
MyConsumer.java用于消费kafka中的信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
package com.demo.kafka;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import com.google.common.collect.ImmutableMap;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
public class MyConsumer {
private static final String ZOOKEEPER = "localhost:2181";
//groupName可以随意给,因为对于kafka里的每条消息,每个group都会完整的处理一遍
private static final String GROUP_NAME = "test_group";
private static final String TOPIC_NAME = "kafka";
private static final int CONSUMER_NUM = 4;
private static final int PARTITION_NUM = 4;
public static void main(String[] args) {
// specify some consumer properties
Properties props = new Properties();
props.put("zookeeper.connect", ZOOKEEPER);
props.put("zookeeper.connectiontimeout.ms", "1000000");
props.put("group.id", GROUP_NAME);
// Create the connection to the cluster
ConsumerConfig consumerConfig = new ConsumerConfig(props);
ConsumerConnector consumerConnector =
Consumer.createJavaConsumerConnector(consumerConfig);
// create 4 partitions of the stream for topic “test”, to allow 4
// threads to consume
Map<String, List<KafkaStream<byte[], byte[]>>> topicMessageStreams =
consumerConnector.createMessageStreams(
ImmutableMap.of(TOPIC_NAME, PARTITION_NUM));
List<KafkaStream<byte[], byte[]>> streams = topicMessageStreams.get(TOPIC_NAME);
// create list of 4 threads to consume from each of the partitions
ExecutorService executor = Executors.newFixedThreadPool(CONSUMER_NUM);
// consume the messages in the threads
for (final KafkaStream<byte[], byte[]> stream : streams) {
executor.submit(new Runnable() {
public void run() {
for (MessageAndMetadata<byte[], byte[]> msgAndMetadata : stream) {
// process message (msgAndMetadata.message())
System.out.println(new String(msgAndMetadata.message()));
}
}
});
}
}
}
|
MyProducer.java用于向Kafka发送消息,但不通过log4j的appender发送。此案例中可以不要。但是我还是放在这里:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package com.demo.kafka;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class MyProducer {
private static final String TOPIC = "kafka";
private static final String CONTENT = "This is a single message";
private static final String BROKER_LIST = "localhost:9092";
private static final String SERIALIZER_CLASS = "kafka.serializer.StringEncoder";
public static void main(String[] args) {
Properties props = new Properties();
props.put("serializer.class", SERIALIZER_CLASS);
props.put("metadata.broker.list", BROKER_LIST);
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config);
//Send one message.
KeyedMessage<String, String> message =
new KeyedMessage<String, String>(TOPIC, CONTENT);
producer.send(message);
//Send multiple messages.
List<KeyedMessage<String,String>> messages =
new ArrayList<KeyedMessage<String, String>>();
for (int i = 0; i < 5; i++) {
messages.add(new KeyedMessage<String, String>
(TOPIC, "Multiple message at a time. " + i));
}
producer.send(messages);
}
}
|
到这里,代码就结束了。
第三部分 运行与验证
先运行MyConsumer,使其处于监听状态。同时,还可以启动Kafka自带的ConsoleConsumer来验证是否跟MyConsumer的结果一致。最后运行App.java。
先来看看MyConsumer的输出:

再来看看ConsoleConsumer的输出:
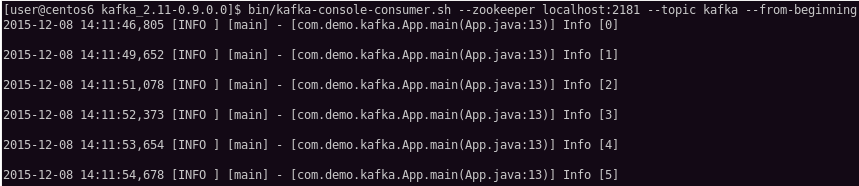
可以看到,尽管发往Kafka的消息去往了不同的地方,但是内容是一样的,而且一条也不少。最后再来看看Kafka的日志。
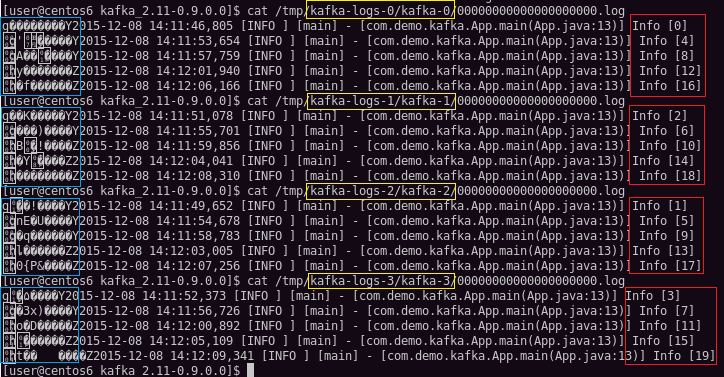
我们知道,Topic为kafka的消息有4个partion,从之前的截图可知这4个partion均匀分布在4个kafka节点上,于是我对每一个partion随机选取一个节点查看了日志内容。
上图中黄色选中部分依次代表在server0上查看partion0,在server1上查看partion1,以此类推。
而红色部分是日志内容,由于在创建Topic时准备将20条日志分成4个区存储,可以很清楚的看到,这20条日志确实是很均匀的存储在了几个partion上。
摘一点Infoq上的话:每个日志文件都是一个log entrie序列,每个log entrie包含一个4字节整型数值(值为N+5),1个字节的"magic value",4个字节的CRC校验码,其后跟N个字节的消息体。每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:
|
1
2
3
4
|
message length : 4 bytes (value: 1+4+n)
"magic" value : 1 byte
crc : 4 bytes
payload : n bytes
|
这里我们看到的日志文件的每一行,就是一个log entrie,每一行前面无法显示的字符(蓝色选中部分),就是(message length + magic value + crc)了。而log entrie的后部分,则是消息体的内容了。
问题:
1. 如果要使用此种方式,有一种场景是提取某天或者某小时的日志,那么如何设计Topic呢?是不是要在Topic上带入日期或者小时数?还有更好的设计方案吗?
2. 假设按每小时设计Topic,那么如何在使用诸如logger.info()这样的方法时,自动根据时间去改变Topic呢?有类似的例子吗?
----欢迎交流,共同进步。
Kafka+Log4j实现日志集中管理相关推荐
- java打印设备集中管理_Kafka+Log4j实现日志集中管理
记录如何使用Kafka+Log4j实现集中日志管理的过程. 引言 前面写的<Spring+Log4j+ActiveMQ实现远程记录日志--实战+分析>得到了许多同学的认可,在认可的同时,也 ...
- Spark使用Log4j将日志发送到Kafka
文章目录 自定义KafkaAppender 修改log4j.properties配置 启动命令配置添加参数 启动之后可以在Kafka中查询发送数据 时区问题-自定义实现JSONLayout解决 自定义 ...
- log4j 压缩日志_Spring Boot 日志各种使用姿势,是时候捋清楚了!
来自公众号:江南一点雨 1. Java 日志概览 1.1 总体概览 1.2 日志级别 1.3 综合对比 1.4 最佳实践 2. Spring Boot 日志实现 2.1 Spring Boot 日志配 ...
- slf4j+log4j打印日志,控制台无日志输出
slf4j+log4j 实现日志打印 项目场景: 今天看以前的项目,运行起来报错,项目日志对于项目是很重要的,但是控制台没有打印出来日志,运行起来报错的问题先放一放,先把日志的问题解决了,我项目中有l ...
- 使用Log4j进行日志操作(牛小浩)不错的
使用Log4j进行日志操作 一.Log4j简介 (1)概述 Log4j是Apache的一个开放源代码项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台.文件.GUI组件.甚至是 ...
- java jar log4j_java项目打包成可执行jar用log4j将日志写在jar所在目录操作
开发一个demo时想将日志输出到最终打包的jar所在目录,从网上学习实验整理之后的配置如下, log4j.properties log4j.rootLogger = INFO,console,logF ...
- SpringMVC学习(三)——SpringMVC+Slf4j+Log4j+Logback日志集成实战分享
文章目录 1.概述 1.1 说明 1.2 日志体系 1.2.1 JCL日志面门介绍 1.2.2 Slf4j日志面门介绍 2.几种日志系统介绍: 2.1 Slf4j 2.2 Commons-loggin ...
- SpringBoot中使用log4j进行日志管理
场景 SpringBoot项目中使用log4j进行日志管理. 实现 1.因为SpringBoot默认是使用logback,所以要修改pom.xml 过滤掉自带的spring-boot-starter- ...
- log4j添加日志一定记住在工程的web.xml文件下加一些内容
log4j添加日志一定记住在工程的web.xml文件下加如下内容: 转载于:https://www.cnblogs.com/oymx/p/3965878.html
最新文章
- (译) 函数式 JS #2: 函数!
- LeetCode Range Sum Query - Mutable(树状数组、线段树)
- linux fedora安装、运行mybase7.3.5报错:error while loading shared libraries: libpng12.so.0
- 可能是全网首个前端源码共读活动,诚邀你加入一起学习
- java线程工作原型_深度解析Java内存的原型及工作原理
- VS2010与OpenCV2410简单配置
- SQL Server2000导出数据时包含主键、字段默认值、描述等信息
- 《伟大的小细节:互联网产品设计中的微创新思维》——3.3 位置环境因素
- 利用Power Designer反向数据库结构
- 屏幕共享软件开发_工作生活离不开软件,你知道什么是免费软件与共享软件吗?...
- Postman最新版本汉化教程
- python混合线性模型_Python Statsmodels Mixedlm(混合线性模型)随机效应
- Flutter 转 null safe时报错: The argument type ‘Object‘ can‘t be assigned to the parameter type XXX
- python读取json文件,大批量写入mongo
- 什么是分布式微服务架构?三分钟彻底弄懂什么是分布式和微服务
- 正则表达式纯数字校验 JS
- python 进程间同步_python之路29 -- 多进程与进程同步(进程锁、信号量、事件)与进程间的通讯(队列和管道、生产者与消费者模型)与进程池...
- linux挂在网络文件系统出现 INFO: taskblocked formorethan120 seconds 问题
- 算法设计之DP练习(组硬币问题)
- iPad2 4.3.3完美越狱教程 一键即可操作