【Modern OpenGL】第一个三角形
>说明:跟着learnopengl的内容学习,不是纯翻译,只是自己整理记录。>强烈推荐原文,无论是内容还是排版。 [原文链接](http://learnopengl.com/#!Getting-started/OpenGL)本文地址:http://blog.csdn.net/aganlengzi/article/details/50354237
并不简单的三角形绘制
在OpenGL的世界中,一切都是在三维空间中的,但是屏幕和窗口是二维的像素数组。所以OpenGL的一大工作就是将三维坐标转换为适合屏幕显示的二维像素。这个把三维坐标转换为二维坐标的过程是由OpenGL的图形渲染流水线来管理的。这个图形渲染流水线分为两大部分:首先是将三维坐标转换为二维坐标;其次是键二维坐标转换为真正的有颜色值的像素。在本次教程中,我们将会简单地讨论这个图形渲染流水线以及我们应该怎样使用它来帮助我们创建一些酷炫的像素出来。
注意一个二维坐标和一个像素点是不同的。一个二维坐标是一个点在二维空间中的精确表示,但是一个二维的像素点是一个二维空间中的点在屏幕分辨率的限制下的一个近似表示。
图形渲染流水线以一组三维坐标为输入,把它们转换成屏幕上着色的二维像素点。图形渲染流水线又可以分成许多步骤,每个步骤都是以前面步骤的输出作为当前步骤的输入。每一个步骤都是专用的,它们具有特定的功能,这方便了并行执行。因为这种并行特性,当今显卡基本上都包含成千上万个小的处理核心,这些核心帮助我们在GPU图形渲染流水线中的每个步骤中利用小的程序来快速处理数据。而这些在每个核心上面跑的小程序就叫做着色程序(shaders)。
在这些shader中,有一些是可以被开发者配置的,这些可配置的shader允许我们用自己写的shader来替换默认的shader。这给了我们对这个流水线的某些部分更细粒度的控制权,因为它们是在GPU上运行的,这或许也能够帮助我们节省宝贵的CPU时间。shader是用GLSL(OpenGL Shading Language,简称GLSL)语言开发的,我们将在下个教程中了解更多关于GLSL的知识。
下面这幅图展示的是对图形渲染管线所有阶段的一个抽象表示,其中蓝色的部分代表我们可以注入自己的shader,应该就是可以自己配置的意思。这里的图借鉴了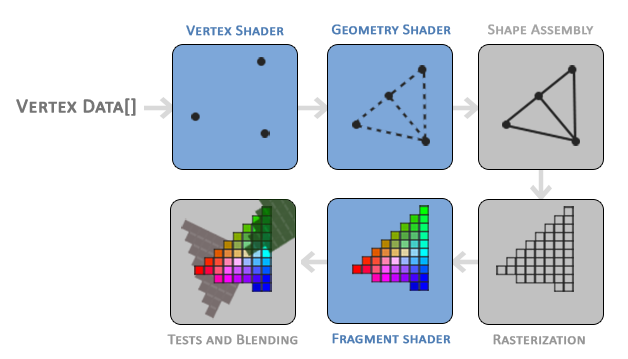
如你所见,这个图形渲染管线中包含了很多阶段,每个阶段完成从顶点数据项最终显示像素点的一部分特定的工作。我们将会以一个简化的方式简短地解释其中的每个阶段,目的是让你有一个对这个流水线工作方式的整体把握。
作为输入,我们把数组中能构成一个三角形的三个三维坐标值(称作顶点数据,Vertex Data)传递进这个流水线;顶点数据实际上就是所有顶点的集合,而每个顶点实际上就是每个三维坐标系中表示这个顶点的数据。实际上,我们用于表示一个点的数据中可以包含我们想要包含的属性,但是为了简化起见,在本例中,我们假设每个顶点只包含这个顶点的三维坐标和顶点的颜色值。
为了让OpenGL知道你想用这些顶点数据或者颜色值绘制什么图形,你需要指定你想用这些数据绘制的图形类型:是需要用它们绘制一些独立的点,还是需要用它们绘制三角形,或者是用它们绘制一条长长的线?点,三角形或者线,这些称作图元,是在任何绘制命令调用前需要告诉OpenGL的,也只有这样,OpenGL才知道在下一个状态用绘制命令和给定的数据绘制什么。指定的方式是通过前面说的状态设置函数完成的,这在后面具体用到的时候会说明。而OpenGL支持的图元类型永宏表示,比如GL_POINTS,GL_TRIANGLES和GL_LINE_STRIP。
好的,以上图为例,假设我们已经指定了要绘制三角形,并且已经输入了顶点数据(包含三个顶点的位置坐标和颜色值),下面真正进入图形渲染流水线:
流水线的第一阶段是顶点处理器,它以单独的顶点(在本例中包含位置坐标和颜色值)作为输入,完成的主要功能是将顶点的三维坐标转换成另一种三维坐标(后面具体会讲到),还有就是对顶点的属性做一些基本的处理。
图元装配阶段,以所有顶点处理器处理过的的顶点为输入(如果在前面指定的绘制的内容是GL_POINTS的话,那么就以单个顶点作为输入),生成一个图元并且根据图元的形状放置所有的顶点。在本例中就是构成一个三角形图元,而且将这个三角形的各个顶点放到该放的位置。
图元装配的输入作为几何处理器的输入。几何shader以形成图元的顶点几何为输入,它能够生成新的顶点形成新的图元(不仅限于前面指定的图元,比如像本例中的三角形)。在本例中,它从给定的三角形(图元装配阶段的输出)中又生成了一个三角形。
几何处理器的输出被传递给光栅化阶段作为输入。光栅化阶段完成图元和最终要显示屏幕的对应像素之间的映射,它生成片段处理器用到的片段。在将这些片段输出到片段处理器之前,裁剪被首先执行。裁剪操作将所有超出显示范围的片段都去除,这样可以提高性能。
在OpenGL中,一个片段就是OpenGL渲染一个像素点需要的所有数据。
片段处理器最主要的作用是计算像素点最终的颜色,这个阶段也是所有高级OpenGL效果施展的地方。通常,片段中包含3D场景的数据(比如说光照、阴影和光照颜色等等),这些数据被用来计算出最终的像素颜色值。
在所有相关的颜色值都被确定后,最终的对象将会被传递到下一个阶段,我们称其为alpha通道测试和混合阶段。这个阶段检查片段的深度值和模板值(我们后面会了解到),并且用他们来检查这些生成的片段是否在其它对象的前面或者后面,如果在其它对象的后面,即被其它对象遮挡,那么这个片段就会被裁减掉。这个阶段也会检查alpha值(alpha值定义了一个对象的透明度)并且进行对象的混合操作(根据透明度的不同生成不同的效果)。所以即使一个像素的颜色值是在片段处理器阶段就生成的,但是到最终显示的时候,还是有可能完全不同(因为在这个阶段还会和其它对象进行相互作用,比如透明遮挡等等)。
如你所见,图形渲染流水线是相当复杂的,而且包含了很多可配置的部分(图中蓝色着色的阶段)。但是,我们大部分只关心顶点和片段处理器。几何处理器虽然是可选的,但是经常被设置为默认的。
在现代OpenGL中,我们需要自己至少定义一个顶点处理器(处理程序,shader)和一个片段处理器。因为在GPU中没有默认的顶点或者片段处理程序供我们选择。基于此,通常开始学习现代OpenGL是非常困难的,因为仅仅是渲染我们的第一个三角形都需要大量的相关知识。但是一旦你成功渲染了你的第一个三角形,你将会学到更多的OpenGL图形编程知识。
下面我们就来渲染我们的第一个三角形吧~
##顶点输入开始绘制之前我们首先要给OpenGL一些顶点数据。OpenGL是一个三维图形库,所以所有的坐标都应该是三维的,即包含x,y和z坐标。OpenGL不会简单地将你的三维坐标转换成屏幕上的二维像素。前面已经提到过,OpenGL中的坐标是标准化设备坐标系,即在x,y和z方向上都是-1到1之间的立方体。所有在这个标准化设备坐标系中的坐标才是可以显示在屏幕上的,而在这个标准化设备坐标系之外的坐标都不可能显示。因为我们想要渲染一个三角形。所以我们总共需要提供构成这个三角形的三个点的三维坐标值。我们利用一个GLfloat类型的数组定义他们在标准化设备坐标系的可见区域。
GLfloat vertices[] = {-0.5f, -0.5f, 0.0f,0.5f, -0.5f, 0.0f,0.0f, 0.5f, 0.0f
}; 因为OpenGL在三维空间中进行处理,但是我们希望渲染的是一个二维的三角形,所以我们将三个顶点的坐标值中的z值全部都设置为0.0。这样的能够使三角形的深度之保持一致,看上去像一个二维图形一样。>####标准化设备坐标系 Normalized Device Coordinates (NDC)当你的顶点坐标在顶点处理器中处理过,它们就应该在标准化设备坐标系中。标准化设备坐标系是一个小的立方体空间中,这个立方体的三个维度上(x,y和z)都在-1到1之间。任何在这个范围之外的坐标都不会在屏幕上显示。下图中可见在标准化设备坐标系统我们上面定义的三角形(先不考虑z轴,可以认为z轴是垂直于纸面的)。
![]()
通常的屏幕坐标系的原点是在屏幕的左上角上,而且y正轴是自原点垂直向下的。在标准化坐标系中却不同,其原点在正中,y轴垂直向上。最终你会希望你绘制的所有的对象的坐标都在这个标准化设备坐标系之内,否则它们不会被显示出来。你的标准化设备坐标最终都会被转换成屏幕坐标系中的坐标。这个转化过程是基于在程序中你设置的glViewport参数来完成的。生成的屏幕坐标系中的坐标被转换成片段并输入到片段处理器。上面我们已经完成了三角形顶点数据的定义,现在我们想要将这些数据作为图形渲染流水线的第一阶段的输入,也就是顶点处理器的输入。为此,我们需要在GPU中申请内存来存储这些顶点数据、告诉OpenGL应该如何解释这块内存并且指定应该如何将这些数据发送到显卡。之后顶点处理器就可以从内存中处理我们指定数量的顶点了。我们利用所谓的顶点缓存对象(vertex buffer objects,简称VBO)来管理这块内存。VBO能够在GPU的内存中存储大量的顶点。利用这种缓存对象的好处是我们可以一次就发送大批量的数据到显卡,而不用每次之传输一个顶点。毕竟从CPU向显卡中传输数据是非常慢的,所以我们总是找机会一次传输尽可能多的数据。一旦数据存储在显卡内存中,顶点处理器对这些数据的访问可以看成是瞬时的,这极大提升了顶点处理器的处理速度。VBO是我们在这个教程中遇到的第一个OpenGL对象。像OpenGL中的其它对象一样,它有一个ID唯一的表示一个缓冲区,所以我们可以像下面这样用glGenBuffers创建一个VBO。
GLuint VBO;
glGenBuffers(1, &VBO); - 1
- 2
OpenGL的缓冲区对象有多种缓冲区类型,顶点缓存区对象的缓冲区类型是GL_ARRAY_BUFFER。我们通过下面的方式使用glBindBuffer将新生成的缓存区绑定到GL_ARRAY_BUFFER目标类型。
glBindBuffer(GL_ARRAY_BUFFER, VBO); - 1
此后,我们对任何缓冲区的调用(以GL_ARRAY_BUFFER为目标类型),都会被用于当前绑定的缓冲区,即VBO。于是我们可以通过调用glBufferData函数来将之前定义的顶点数据拷贝到这个缓冲区内存中:
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);- 1
glBufferData函数负责将用户定义的数据拷贝到当前绑定的缓冲区中,它的第一个参数是我们想要拷贝进数据的缓冲区类型:在本例中顶点缓冲区对象当前被绑定到了GL_ARRAY_BUFFER目标类型。第二个参数指定了我们想要传输进缓冲区的数据量大小(以字节为单位),即使用运算符sizeof对我们定义的数组计算值。第三个参数指定我们想要传输的数据。第四个参数指定了我们想要让显卡怎样来管理这些给定的数据(我感觉是高速显卡我们可能怎样操作这些数据,在其进行存储的时候,为提高性能或者节省能耗而“心里有数”),它有三种形式:
GL_STATIC_DRAW: 这些数据基本上不会改变或者极少情况下会被改变。
GL_DYNAMIC_DRAW: 这些数据可能会经常被改变。
GL_STREAM_DRAW: 这些数据在每次绘制的时候都会被改变。三角形三个点的位置数据不会改变,在每次渲染的时候都保持在原来的位置,所以应该被设置为GL_STATIC_DRAW。举例来说,如果缓冲区中的数据会经常改变,那么使用GL_DYNAMIC_DRAW或者GL_STREAM_DRAW参数将会让显卡将这些数据分配到能够更快写入的地方(以提高性能)。到目前,我们通过顶点缓冲区对象(VBO)将顶点数据存储到了显存中。接下来我们想要创建一个顶点处理程序和片段处理程序。>说明:顶点处理器听上去像是GPU中的硬件名称,这里之所以这么翻译,是想和下面的顶点处理程序区别。实际上,顶点处理程序完成的就是上面图形渲染流水线中顶点处理器完成的功能。这样翻译便于理解。实际上原文中上面的和下面的都叫做vertex shader。如果都翻译成顶点处理程序,那么上面流水线的一个阶段是顶点处理程序,怪怪的。所以这样翻译。##顶点处理程序 vertex shader顶点处理程序是我们可以编程的流水线中的一个部分。现代OpenGL要求我们,如果想要进行渲染,至少要建立起顶点处理程序和片段处理程序。所以我们将会简短介绍处理程序而且配置两个非常简单的shaders来绘制我们的第一个三角形,在下一个教程汇总将会讨论关于shader的更多细节。我们首要做的是利用shader语言GLSL来写我们的顶点处理程序并且编译这个shader以便于我们可以再我们自己的程序中使用。下面我们将看到一个用GLSL写的非常基本的vertex shader。
#version 330 corelayout (location = 0) in vec3 position;void main()
{gl_Position = vec4(position.x, position.y, position.z, 1.0);
}正如你所见,GLSL和C类似。每个shader的开头都会定义它的版本,330对应着OpenGL3.3,420对应着OpenGL4.2。我们还明确地声明我们使用core-profile模式。接下来我们声明了这个顶点渲染程序的顶点属性输入,以关键字in标明的position。因为目前我们只关心位置,所以只需要指定单独这个顶点属性作为输入就够了。GLSL中,有一个可以包含1到4个GLfloat类型的vector数据类型。因为三角形的每个顶点都是一个三维坐标,所以我们可以使用vec3类型的vector(vec3表示vector中含有3个GLfloat)来定义名称为position的输入。我们同时还通过layout关键字和location的值(本例设置为0)明确地指定这些输入数据的位置。这在后面告诉GPU我们用的数据在哪儿的时候会用到。>这个程序可以这么理解:声明类型为vec3的变量position,用关键字in指明这是此顶点处理器的输入,并且用关键字layout(location = 0)指明输入数据的索引号,便于后面查找。然后是函数体。>>矢量Vector在图形编程中我们经常使用数学中矢量的概念,因为矢量可以很优雅地在任何维度内表示对象的位置、方向和其他属性(所有想要表示的都可以放到一个矢量中)。而且矢量具有很好的数学特定。GLSL中的矢量最多可以含有四个数值,而且可以通过与C结构体中元素类似的访问方式访问,如vec.x,vec.y,vec.z和vec.w。它们分别代表了对象在空间中的每一个维度的表示。注意vec.w分量在表示三维空间中的位置时是不需要的。但是它用于称作透视图处理中。在后面的教程中应该会对vector有更深入的讲解。在程序中,设置顶点处理程序的输出到在图形渲染流水线中已经定义好的gl_Position变量中。它是一个vec4类型的变量。这个gl_Position理解成是定点处理器和下一个阶段图元装配的接口。因为上面我们设置的输入是3维矢量,我们需要把它转化成4维矢量。妆花方式比较简单,即利用vec4的构造函数来生成四个分量已经指定的一个vec4对象就好了。这里w分量设置为了1,具体原因后面会讲到。目前这个顶点渲染程序应该是可以想象到的最简单的顶点处理程序了。因为它对输入几乎什么也没有做,只是转换了一下数据类型就作为结果输出了。在真正的应用程序中,一般输入的数据不会(像本例中)已经被标准化(所有的坐标值都在标准化设备坐标系中),所以定点处理程序可能首先需要先将这些坐标转化为OpenGL能够处理的标准化设备坐标系。>这里需要说明一下,上面写的定点处理程序(vertex shader)并不是放在单独一个源文件编译链接执行的程序,它是一个shader程序。只是我们用到的图形渲染流水线中的一个阶段(顶点处理器)中用到的程序。所以它是被存储在类似于C的字符数组中的。像下面这样:
const GLchar* vertexShaderSource ="#version 330 core\n \
layout (location = 0) in vec3 position;\n \
void main()\n \
{\n \
gl_Position = vec4(position.x, position.y, position.z, 1.0);\n \
}\n\0";那么怎么将它组装到我们的图形渲染流水线中呢?首先编译,然后组装。接着向下看吧。##编译shader我们已经有了顶点渲染程序(像上面那样存储在了字符数组中),在使用的时候,我们需要在运行时从它的源码动态编译它。为了编译这个shader,我们需要先创建一个shader对象,同样需要一个唯一的ID来标识。像下面这样通过GLuint来存储ID,通过glCreateShader来创建shader对象:
GLuint vertexShader;
vertexShader = glCreateShader(GL_VERTEX_SHADER);需要注意的是,我们需要在调用glCreateShader的时候指定我们想要创建的shader的类型,因为我们创建的是顶点处理程序,所以给的参数是GL_VERTEX_SHADER。接下来我们将上面写的shader源码和新创建的这个shader对象绑定。并且通过调用glCompileShader来编译这个shader:
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);glShaderSource函数的第一个参数是一个shader对象,第二个参数指定传递的源码数量,第三个参数是shader源码字符数组的指针,第四个参数目前我们先不用管,直接设置为NULL就可以。>实际上完成上面的过程也就完成了一个shader的编译,不管编译哪个shader,其原理和做法都是相似的。但是总感觉不是那么放心,编译成功没有?错在哪儿了?以下提供了可以检查编译结果的方法:
GLint success;
GLchar infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);即首先设置一个flag,即success变量,然后设置一个比较大的缓冲区来装编译结果输出信息。最重要的是glGetShaderiv函数,它帮助我们得到编译结果信息。如果success为0,表示编译出错,这时我们应该来获取错误输出信息,这通过glGetShaderInfoLog来完成:
if(!success)
{glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}当然如果编译成功,就不会有报错信息,也就是编译成功了。## 片段处理程序 Fragment shader上面提到,为了渲染三角形,我们还需要提供片段处理程序。片段处理程序提供图形渲染流水线中片段处理器完成的功能。它负责计算像素点的颜色值。简化起见,我们的片段处理程序为所有的像素都总是输出一种颜色——橙色。在计算机图形中,颜色值是由四个值来表示的:分别是红、绿、蓝和alpha通道分量,通常简写为RGBA。在OpenGL和GLSL中,我们通过设置每种分量值(0.0-1.0)来定义一个颜色值。举例来说,如果我们想要设置黄色,那么我们将红绿两个分量设置成1.0。由三种颜色分量我们可以得到16,000,000种颜色值。
#version 330 coreout vec4 color;void main()
{color = vec4(1.0f, 0.5f, 0.2f, 1.0f);
} 如上面的程序所示,片段渲染程序只输出一个vec4类型的变量,也就是color,通过out关键字来标识。程序的主体部分知识将这个输出值赋值为橙色。这应该也是一个非常简单的片段处理器了。编译片段处理程序的过程和编译顶点处理程序的过程是十分相似的。只是在调用glCreateShader的时候指定的参数是GL_FRAGMENT_SHADER:
GLuint fragmentShader;
fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);>同样,可以使用上面介绍的方法检验我们的编译是否成功。现在我们已经准备好了我们必须要提供的两个shader,下面就是要将它们组装到我们的图形渲染流水线中(别忘了它们只是整个图形渲染流水线中的两个阶段),以便于我们使用它来进行渲染。## Shader program整个图像渲染流水线可以看成是一个渲染程序,它由不同阶段的shader构建而成。OpenGL中对应的概念是渲染程序对象(shader program object),它是编译好和连接到一起的不同阶段的shader的整体。这里可以把它看成是可以装配的流水线。为了使用刚刚编译好的顶点和片段shader,我们需要把它们装配到渲染程序对象中并且激活它们。这样我们才能够在调用渲染指令的之后使用包含这些shaders的渲染程序对象来渲染我们的图形。这个过程应该是一个状态设置过程,而调用渲染命令是状态使用过程。如上面讲到的,在图形渲染流水线中,前面阶段的输出是后面阶段的输入。同理,在渲染程序对象中,装配不同的shader的时候也是这样,将前面阶段的shader的输出作为后面阶段shader的输入,而且其它阶段默认已经存在。理解成渲染程序对象会帮我们处理这些就好了。创建一个渲染程序对象是简单的:
GLuint shaderProgram;
shaderProgram = glCreateProgram();glCreateProgram创建了一个程序对象,而shaderProgram保存了其ID,现在我们将我们之前创建并编译好的两个shader通过调用glAttachShader和glLinkProgram装配到这个渲染程序对象中:
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);好的,上面的过程就像是我们组装了一条生产线,让人激动的是,其中的两个模块使我们自己实现的。它几乎可以开始生产了,而其产品将会是输出到屏幕上的图形。>我们可以像检查shader程序是否编译好一样检查这条生产线是否组装好。只不过需要使用与之不同但是十分类似的函数:
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if(!success) {glGetProgramInfoLog(shaderProgram, 512, NULL, infoLog);...
}怎么样启动这个生产线呢?我们首先需要告诉OpenGL我们想要激活这个渲染程序对象,这通过函数glUseProgram完成:
glUseProgram(shaderProgram);- 1
这样,在此之后我们调用的任何渲染指令,都会用这个渲染程序(这条生产线)来执行。当然不要忘记在将编译好的shader装配到渲染程序对象后删除它们,因为我们不再需要它们:
glDeleteShader(vertexShader);
glDeleteShader(fragmentShader); 上面的过程相当于我们已经准备好了生产产品的硬件条件。一条我们定制化(顶点和片段处理器都由我们创建)的生产线(渲染程序对象),而且我们已经准备好了原材料(顶点数据)。我们似乎可以开工生产我们的产品(渲染我们的图形)了。但是并没有。OpenGL并不知道它应该如何使用我们的原材料(数据)。比如应该怎样取出和存入,怎样将它们和顶点渲染程序中定义的输入数据联系起来。下面我们将告诉OpenGL应该怎么使用这些数据。 ##设定顶点输入方式 前面,我们写的顶点处理程序只是设定了输入的类型(vec3)和输入后的索引(location=0),但是并没有指明我们的顶点数据的输入方式。我们的数组中一共有三个顶点9个数据,是下标为2的先输进去还是下标为0的先输进去?实际上,在OpenGL中顶点定点渲染程序允许我们以多种方式指定类似的输入方式,这提供了数据输入的巨大灵活性,但是也意味着我们需要手工指定我们的顶点数据和顶点处理程序中的顶点属性的对应关系。即我们需要指定OpenGL在渲染前应该如何解释或理解这些顶点数据。我们的顶点缓冲区中的数据的个数如下图所示:
![]()
位置坐标值都是32位(4字节)的浮点类型;每个位置由三个坐标值构成;在每组3个坐标值之间没有任何间隙,换句话说,数值在内存中是连续紧密存放的;数据的第一个值位于缓冲区开始的位置。基于以上这些信息,我们可以通过glVertexAttribPointer函数来告诉OpenGL应该如何解释这些顶点数据:
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat), (GLvoid*)0);
glEnableVertexAttribArray(0); glVertexAttribPointer函数的参数较多,我们逐一来看一下:第一个参数:指定了我们想要配置哪个顶点属性(顶点属性是一个词,这里可以理解成一个顶点属性集合,即矢量)。还记得我们在顶点处理程序的开始处指定的输入的位置顶点属的location值吗,就是这个实参0的含义。“layout (location = 0)“就限定了顶点属性的位置是0,方便我们在这个地方使用的时候易于索引。第二个参数指定了顶点属性的大小,因为我们设置的输入是vec3类型的,所以这里设置为3,表示由3个数据构成。第三个参数指定数据的类型,设置为GL_FLOAT。因为GLSL中的vector中的数值类型是GLfloat。第四个参数指定我们是否需要将数据标准化,因为我们的数据在生成的时候就已经标准化了,所以这里并不需要,设置为GL_FALSE。如果设置为GL_TRUE,所有不满足数值大小范围为[-1,1]的数值都会被首先标准化为标准化设备坐标系中的坐标值。第五个参数指定了在连续顶点属性集合之间的空隙——称作步进长度。我们的例子中每两个顶点属性之间相差三个GLfloat空间,所以设置为“3 * sizeof(GLfloat)“,实际上,因为这里数据都是紧密排列的,设置为0,OpenGL就会认为顶点属性之间没有空隙,也是能够正常解析的。最后一个参数将0转换为GLvoid*类型,它指明了数据在缓冲区中的偏移。上面已经说了,我们例子中的数据在缓冲区中的偏移是0,所以这里这么给实参。>还记得前面讲的VBO吗?实际上,上述顶点属性的取得都要经过VBO,因为VBO是OpenGL和Memory之间的接口。那么在有多个VBO时,哪一个才是我们要取的呢?也就是说,如果我们设定的取数据的地方不是我们想象的,而是其他的VBO呢?实际上,在每次取数据的时候,程序能看到的VBO只有一个,也就是绑定到 GL_ARRAY_BUFFER目标的那个VBO。那么,如果我们想要从其他VBO中取数据也是简单的,只需要在取之前将含有我们想要数据的VBO绑定到 GL_ARRAY_BUFFER就好了。到目前为止,我们已经指定好了OpenGL应该怎样解释我们的原材料(顶点数据)。我们还应该通过上面所示的glEnableVertexAttribArray函数设置顶点属性生效,因为顶点属性默认是disabled的,参数就是设置的location(为0)。OK,到这儿基本上所有该准备的都已经准备完成了!我们首先利用VBO准备好了顶点数据,接着创建了两个shader(顶点和片段),然后将它们装配到当前使用的渲染程序对象中,最后我们告诉OpenLGL应该如何解释我们的数据。是时候绘制我们的图形了。至此,我们知道了渲染图形的整个流程大致是这么个样子:
// 0. Copy our vertices array in a buffer for OpenGL to use
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 1. Then set the vertex attributes pointers
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat), (GLvoid*)0);
glEnableVertexAttribArray(0);
// 2. Use our shader program when we want to render an object
glUseProgram(shaderProgram);
// 3. Now draw the object
someOpenGLFunctionThatDrawsOurTriangle(); 在绘制之前,还有最后一步——更标准地绘制我们的三角形! 在每一次我们想要绘制一个对象的时候,这个流程都需要执行一次。现在看上去可能不是那么多,但是,如果后面我们的绘制更加复杂的时候就会出现问题了。快速绑定合适的缓冲区对象和配置所有的顶点属性变成一个庞杂的过程。要是能有一个对象将我们配置的所有的状态都记录下来,只要在使用的时候绑定这个对象就好了。这种对象就是下文要讲到的顶点数组对象(Vertex Array Object,简称VAO)。##顶点数组对象 Vertex Array Object 顶点数组对象(VAO)可以像VBO类似方式绑定,随后的对数组对象的调用都将被存储到顶点数组对象中。这样的好处是,在进行顶点属性指针配置的时候只需要调用一次必要的函数,再次使用的时候,只需要绑定相关的VAO就可以了,因为VAO已经将这个配置全部记录下来。这样的话,在不同的对象绘制之间就简化了配置的过程。因为我们设置要绘制对象的状态设置都已经存储到了VAO中。OpenGL的core-profile模式要求我们使用VAO,这样的话它能够知道对我们的顶点输入的具体操作。如果我们绑定VAO失败,OpenGL很有可能停止运行。一个顶点数组对象(VAO)存储以下信息:对glEnableVertexAttribArray或者glDisableVertexAttribArray调用对顶点属性的配置,即对glVertexAttribPointer的调用通过调用glVertexAttribPointer与顶点属性关联的VBO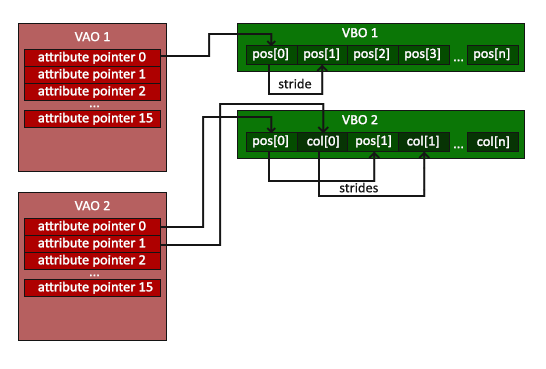创建VAO的过程和创建VBO类似:
GLuint VAO;
glGenVertexArrays(1, &VAO); 使用VAO时唯一要做的就是使用glBindVertexArray函数来绑定VAO。绑定之后我们应该绑定或者配置相关的VBO和属性指针,然后解绑这个VAO留作后用。在我们想要绘制一个对象的时候,我们只需要将包含我们想要的设置的VAO在绘制之前再次绑定就可以了。这个过程大概如下所示:
// ..:: Initialization code (done once (unless your object frequently changes)) :: ..
// 1. Bind Vertex Array Object
glBindVertexArray(VAO);// 2. Copy our vertices array in a buffer for OpenGL to useglBindBuffer(GL_ARRAY_BUFFER, VBO);glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);// 3. Then set our vertex attributes pointersglVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat), (GLvoid*)0);glEnableVertexAttribArray(0);
//4. Unbind the VAO
glBindVertexArray(0);[...]// ..:: Drawing code (in Game loop) :: ..
// 5. Draw the object
glUseProgram(shaderProgram);
glBindVertexArray(VAO);
someOpenGLFunctionThatDrawsOurTriangle();
glBindVertexArray(0); >通常在每次配置之后将对象解绑是一个比较好的做法,因为这样可以防止在其它地方对其无意之间的绑定。终于,所有的东西都已经准备好了,实际上在VAO讲解之前就已经好了,只不过我们对自己的要求比较高,要用更规范的方式来进行我们图形的绘制。实际上利用VAO的方式也的确方便我们后面的学习和理解。而且当我们有很对对象或者很多VBO或者很多配置需要时常切换的时候,我们利用VAO可以大大提高工作效率。嗯,这是值得的!##期待已久的三角形!我们通过OpenGL提供的图元绘制函数glDrawArrays(实际上还有其他,我们现在先选择glDrawArrays)来绘制我们的对象。相关的VAO,VBO就是前面花了这么长时间准备的:
glUseProgram(shaderProgram);
glBindVertexArray(VAO);
glDrawArrays(GL_TRIANGLES, 0, 3);
glBindVertexArray(0); glDrawArrays函数的第一个参数是OpenGL支持绘制的图元类型的宏定义。GL_TRIANGLES代表三角形。 第二个参数指定了开始绘制的顶点数组下标,我们就让它为0。最后一个参数指定了我们要绘制多少个点,我们只有三个点。现在试着编译我们的程序并且运行吧,我已经迫不及待了。我的运行的结果是:
到目前为止,全部的代码在这儿。
##元素缓冲对象 Element Buffer Objects除了上面介绍的利用glDrawArrays函数进行图形渲染的方式,实际上还有一种渲染方式,就是借助glDrawElements进行图形渲染。它和元素缓冲对象(Element Buffer Objects,简称EBO)是联系在一起的。解释元素缓冲对象(EBO)是如何工作的最好方式是给出一个例子:假设我们想要绘制一个矩形而不是三角形。我们可以利用两个三角形(OpenGL主要是利用基本图元三角形来完成复杂对象的绘制)来绘制一个矩形。按照上面讲过的流程,首先是数据的产生:
GLfloat vertices[] = {// First triangle0.5f, 0.5f, 0.0f, // Top Right0.5f, -0.5f, 0.0f, // Bottom Right-0.5f, 0.5f, 0.0f, // Top Left // Second triangle0.5f, -0.5f, 0.0f, // Bottom Right-0.5f, -0.5f, 0.0f, // Bottom Left-0.5f, 0.5f, 0.0f // Top Left
};如你所见,两个三角形之间是有所重合的:左上角和右下角的点被指定了两次。相对于一个矩形的四个顶点来说,我们指定了六个点(其中有两个是重合的),这相当于多做了50%的工作!当我们要绘制更为复杂的模型的时候这种情况还会更糟,因为它们可能有更多的重合。是不是能有一种方法只需要存储(矩形)模型的不同的点,在绘制的时候只需要指定特定的绘制顺序就能够得到我们想要的图形呢?在这种情况下,我们只需要存储矩形的四个顶点(右上,右下,左上,左下),且每个顶点存储一次,而且只需要在绘制的时候指定先绘制右上–右下–左上一个三角形,在绘制右下–左下–左上一个三角形就可以了。OpenGL会提供给我们这种方便的方式吗?幸运的是,元素缓冲对象(EBO)就是干这个事的!EBO是一个像VBO一样的缓存区,但是它存储的是OpenGL需要绘制的顶点的索引(而不是坐标)。这种称作为索引绘制的方法解决了上述的重复的问题。为了使用这种方法,我们需要首先设定顶点的坐标值和我们期望OpenGL在绘制的时候的索引值,它们是两个数组,如下所示:
GLfloat vertices[] = {0.5f, 0.5f, 0.0f, // Top Right0.5f, -0.5f, 0.0f, // Bottom Right-0.5f, -0.5f, 0.0f, // Bottom Left-0.5f, 0.5f, 0.0f // Top Left
};
GLuint indices[] = { // Note that we start from 0!0, 1, 3, // First Triangle1, 2, 3 // Second Triangle
}; 如代码所示,我们仅仅在顶点坐标的数组中指定了我们想要绘制的矩形的四个顶点,而在索引数组中指定了在绘制每个三角形时使用的点。接下来我们来创建元素缓冲对象:
GLuint EBO;
glGenBuffers(1, &EBO);创建过程和VBO的创建过程是一致的,因为二者本质上就是一块缓存区。同样像VBO一样,可以使用glBindBuffer来指定EBO的缓冲区类型,可以使用glBufferData将索引数组的数据复制到这块缓冲区中。同样,和VBO绑定到GL_ARRAY_BUFFER目标类似,我们将EBO绑定到GL_ELEMENT_ARRAY_BUFFER目标,以保证调用相关的函数的时候操作的是我们现在生成的这个索引数组:
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO); 接下来,我们需要调用另一个绘制函数glDrawElements来完成这个矩形的绘制。调用glDrawElements表明我们想要按照我们当前绑定的EBO中的索引值来绘制我们的图形。如下所示:
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);glDrawElements函数的第一个参数指定了我们想要绘制的图元类型,这里指定为GL_TRIANGLES,第二个参数是要绘制的元素个数。这里设置为6因为我们要绘制两个三角形(2*3=6个顶点,就是索引数组中的六个顶点)。第三个参数指定了索引的数据类型,这里设置的是无符号整型GL_UNSIGNED_INT,最后一个参数允许我们指定EBO中的一个偏移(或者在不用EBO的时候这个参数直接给一个索引数据名),这里我们给定的值是0。glDrawElements函数从当前绑定到GL_ELEMENT_ARRAY_BUFFER目标的EBO中取得索引值。这意味着我们在每次绘制对象的时候都需要绑定相应的EBO到GL_ELEMENT_ARRAY_BUFFER,这看上去似乎又有些繁杂。恰好之前介绍过的VAO也同样能够帮助我们解决这个问题。一个顶点数组对象(VAO)也可以保留EBO的绑定信息(和VBO类似)。所以如果在绑定VAO之后进行了EBO的绑定也会被VAO记录下来,等到再次绑定VAO的时候,同样相应的EBO也就被绑定到了相应的GL_ELEMENT_ARRAY_BUFFER。如下图所示: 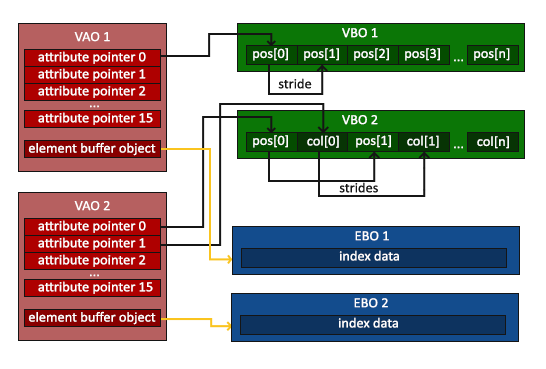>VAO在绑定目标是GL_ELEMENT_ARRAY_BUFFER存储glBindBuffer调用。这意味着它也存储它的解绑调用,以确保你在解绑VAO之前不会解绑EBO,否则,它就没有EBO来进行配置了。利用EBO、VAO和glDrawElements的初始化和绘制代码基本流程如下所示:
// ..:: Initialization code :: ..
// 1. Bind Vertex Array Object
glBindVertexArray(VAO);// 2. Copy our vertices array in a vertex buffer for OpenGL to useglBindBuffer(GL_ARRAY_BUFFER, VBO);glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);// 3. Copy our index array in a element buffer for OpenGL to useglBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);// 3. Then set the vertex attributes pointersglVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat), (GLvoid*)0);glEnableVertexAttribArray(0);
// 4. Unbind VAO (NOT the EBO)
glBindVertexArray(0);[...]// ..:: Drawing code (in Game loop) :: ..
glUseProgram(shaderProgram);
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0)
glBindVertexArray(0);运行上面的程序应该得到如下所示的画面。左边的图形看上去应该是比较熟悉的填充模式,右边的方式是用线框模式绘制的。线框的三角形显示出这个矩形确实是由两个三角形组成的。
线框模式和填充模式
以线框模式绘制三角形(或者其它图元),需要利用状态设置函数glPolygonMode(GL_FRONT_AND_BACK, GL_LINE)来完成,其中第一个参数指定对要绘制的图元的两个面(OpenGL中的绘制对象都是有两个面的,正面和反面,后面应该会讲到怎么区分这两个面)都采用同样的绘制模式,第二个参数指定以线框来绘制图元。随后的绘制命令都会以设定的线框模式来绘制图形,知道我们将绘制模式再次通过glPolygonMode函数将绘制模式指定为填充模式。
错误是不可避免的,如果有错误,说明前面的某一步可能出问题了。同时,也代表理解上可能有点问题,当然也有可能是我表述不清。。。。可以回过头来检查一下,到目前为止的多有代码都在这儿。值得注意的是,代码中为了和glDrawArrays绘制方式区别,以索引绘制的方式为其创建了另一份对应的VBO,EBO和VAO,所以有多个VBO和VAO,这样在切换的时候可以体会利用VAO进行状态设置保存的好处。
如果你按照上面的过程成功绘制了三角形或者矩形。你已经挺过了学习现代OpenGL几乎是最艰难的一段:绘制一个简单的三角形。万事开头难嘛。实际上,这其中包含了很多相关的知识,如果没有学过图形学相关的内容,看起来还是比较吃力的。如果有相关的图形学基础,可以发现,本次教程是对理论知识的一次小小实践。充分地理解这个过程是十分必要的,也是后面继续学习的基础。一旦对这些概念和过程有了充分的了解,后面的内容应该就相对简单一些了。
【Modern OpenGL】第一个三角形相关推荐
- 现代OpenGL学习笔记二:第一个三角形
本笔记主要是跟学LearnOpenGL的内容,并将其中一些不懂的地方通过查阅资料进行整理补充,推荐参考原文: 整个教程:https://learnopengl-cn.github.io/ 本笔记参考教 ...
- 【一步步学OpenGL 3】-《第一个三角形》
教程 3 第一个三角形 原文:http://ogldev.atspace.co.uk/www/tutorial03/tutorial03.html CSDN完整版专栏: http://blog.csd ...
- OpenGL蓝宝书学习日记(1)—— 配置OpenGL环境与创造第一个三角形
OpenGL蓝宝书学习日记(1)-- 配置OpenGL环境与创造第一个三角形 一.安装VS VS有众多版本,本人使用的是VS2017,在官网即可下载,有为学生专门提供的免费版,注册账号登陆后即可无限试 ...
- OpenGL绘制Triangle三角形
OpenGL绘制Triangle三角形 前期知识准备 顶点输入 顶点着色器 编译着色器 片段着色器 着色器程序 链接顶点属性 顶点数组对象 我们一直期待的三角形 索引缓冲对象 前期知识准备 在Open ...
- 【Modern OpenGL】坐标系统 Coordinate Systems
说明:跟着learnopengl的内容学习,不是纯翻译,只是自己整理记录. 强烈推荐原文,无论是内容还是排版. 原文链接 本文地址: http://blog.csdn.net/aganlengzi/a ...
- QT使用openGL绘制一个三角形
对于opengl的学习来说,绘制一个三角形是学习一种计算机语言时的一个hello world级的入门程序,个人觉得相比主流语言的helloworld,openGL的入门确实是有一些劝退,虽然说有不错的 ...
- 【OpenGL】绘制三角形
[OpenGL]绘制三角形 效果展示 准备条件 图形渲染管线的各个阶段概览 创建着色器程序与绘制OpenGL图元 参考资料 效果展示 准备条件 首先已经通过[OpenGL]使用OpenGL创建窗口使用 ...
- OpenGL 绘制彩色三角形的实例
OpenGL 绘制彩色三角形 先上图,再解答. 完整主要的源代码 源代码剖析 先上图,再解答. 完整主要的源代码 #include <sb7.h> #define INTERPOLATE_ ...
- OpenGL绘制一个三角形
OpenGL绘制一个三角形 OpenGL绘制一个三角形简介 源代码剖析 主要源代码 OpenGL绘制一个三角形简介 在本课中,我们仍然不转换坐标,因此顶点仅在正方形内可见.从 Z 的反轴看,正方形如下 ...
最新文章
- sql 随机数高效率算法
- 【MySQL】求每门科目成绩排名前二的学生信息
- Head First JSP---随笔六
- SearchRecentsuggestionsProvider
- BZOJ 3527: [ZJOI2014]力(FFT)
- day_01 解析简单的程序
- 如何跨域来同步不同网站之间的Cookie
- jsonarray转liast_fastjson List转JSONArray以及JSONArray转List
- SxSW小组成员讨论了Valley调查中的Elephant
- UI设计灵感|996打工人必备,日程计划网页设计
- python画图颜色代码_Python-使用matplotlib创建自己的颜色图并绘制颜色比例
- Android SDK的下载与安装
- 利用dialogArguments进行网页页面传值
- 生物化学复习题I·蛋白质
- 最受欢迎的中国 50 技术博客评选结果
- 手机删掉的照片怎么恢复
- QQ样式的在线客服代码
- Unity接入ChatGPT基于Python.Runtime的实现
- PCB布线这几种走线方式,你会吗?
- 《冰封王座》世界魔兽界十大叱咤风云人物
热门文章
- 关于win32与win64的兼容性问题
- ajax 高并发请求,理解node.js处理高并发请求原理
- 文件读写的“二进制模式”和“文本模式”
- 使用jdbc执行SQL实现登录查询2-避免SQL注入版
- 线程高级篇-Lock锁和Condition条件
- 面向对象思想 常说的OOP五大原则就是指1、单一职责原则; 2、开放闭合原则; 3、里氏替换原则; 4、依赖倒置原则; 5、接口隔离原则。...
- python shelve模块
- Newtonsoft.Json反序列化(Deserialize)出错:Bad JSON escape sequence
- Redis实现之对象(三)
- Python学习笔记——基础篇【第六周】——hashlib模块