使用Apache Kudu和Impala实现存储分层
为什么80%的码农都做不了架构师?>>> 
当为应用程序的数据选择一个存储系统时,我们通常会选择一个最适合我们业务场景的存储系统。对于快速更新和实时分析工作较多的场景,我们可能希望使用Apache Kudu,但是对于低成本的大规模可伸缩性场景,我们可能希望使用HDFS。因此,需要一种解决方案使我们能够利用多个存储系统的最佳特性。本文介绍了如何使用Apache Impala的滑动窗口模式,操作存储在Apache Kudu和Apache HDFS中的数据,使用此模式,我们可以以对用户透明的方式获得多个存储层的所有优点。
Apache Kudu旨在快速分析、快速变化的数据。Kudu提供快速插入/更新和高效列扫描的组合,以在单个存储层上实现多个实时分析工作负载。因此,Kudu非常适合作为存储需要实时查询的数据的仓库。此外,Kudu支持实时更新和删除行,以支持延迟到达的数据和数据更正。
Apache HDFS旨在以低成本实现无限的可扩展性。它针对数据不可变的面向批处理的场景进行了优化,与Apache Parquet文件格式配合使用时,可以以极高的吞吐量和效率访问结构化数据。
对于数据小且不断变化的情况,如维度表,通常将所有数据保存在Kudu中。当数据符合Kudu的扩展限制并且可以从Kudu的特性中受益时,在Kudu中保留大表是很常见的。如果数据量大,面向批处理且不太可能发生变化,则首选使用Parquet格式将数据存储在HDFS中。当我们需要利用两个存储层的优点时,滑动窗口模式是一个有用的解决方案。
滑动窗口模式
在此模式中,我们使用Impala创建匹配的Kudu表和Parquet格式的HDFS表。根据Kudu和HDFS表之间数据移动的频率,这些表按时间单位分区,通常使用每日、每月或每年分区。然后创建一个统一视图,并使用WHERE子句定义边界,该边界分隔从Kudu表中读取的数据以及从HDFS表中读取的数据。定义的边界很重要,这样我们就可以在Kudu和HDFS之间移动数据,而不会将重复的记录暴露给视图。移动数据后,可以使用原子的ALTER VIEW语句向前移动边界。
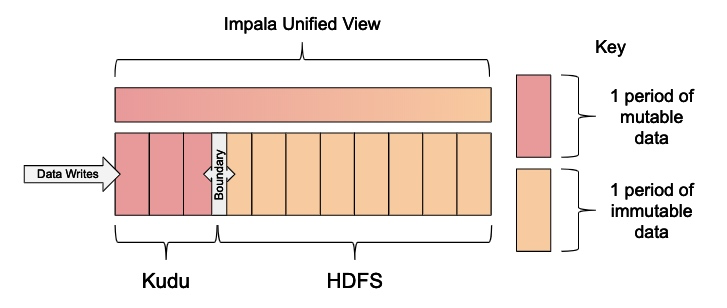
注意:此模式最适用于组织到范围分区(range partitions)中的某些顺序数据,因为在此情况下,按时间滑动窗口和删除分区操作会非常有效。
该模式实现滑动时间窗口,其中可变数据存储在Kudu中,不可变数据以HDFS上的Parquet格式存储。通过Impala操作Kudu和HDFS来利用两种存储系统的优势:
- 流数据可立即查询
(Streaming data is immediately queryable) - 可以对更晚到达的数据或手动更正进行更新
(Updates for late arriving data or manual corrections can be made) - 存储在
HDFS中的数据具有最佳大小,可提高性能并防止出现小文件(Data stored in HDFS is optimally sized increasing performance and preventing small files) - 降低成本
(Reduced cost)
Impala还支持S3和ADLS等云存储方式。此功能允许方便地访问远程管理的存储系统,可从任何位置访问,并与各种基于云的服务集成。由于这些数据是远程的,因此针对S3数据的查询性能较差,使得S3适合于保存仅偶尔查询的“冷”数据。通过创建第三个匹配表并向统一视图添加另一个边界,可以扩展此模式以将冷数据保存在云存储系统中。
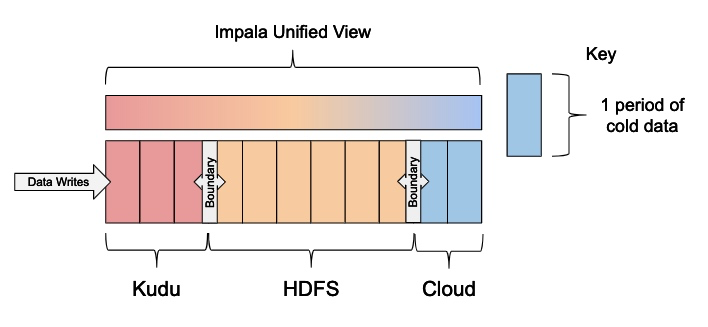
注意:为简单起见,下面的示例中仅说明了Kudu和HDFS。
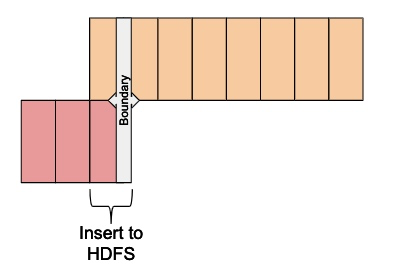
将数据从Kudu移动到HDFS的过程分为两个阶段。第一阶段是数据移动,第二阶段是元数据更改,最后定义一些定期自动运行的数据任务来辅助我们维护滑动窗口。
在第一阶段,将当前不可变数据从Kudu复制到HDFS。即使数据从Kudu复制到HDFS,视图中定义的边界也会阻止向用户显示重复数据。此步骤可以包括根据需要进行的任何验证和重试,以确保数据卸载(data offload)成功。
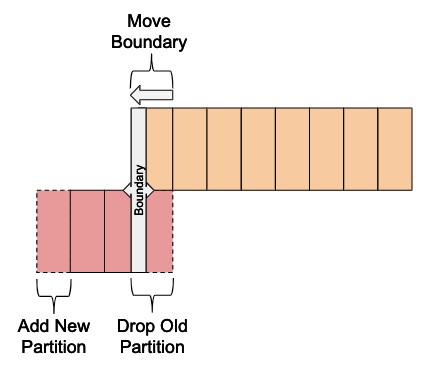
在第二阶段,现在数据被安全地复制到HDFS,需要更改元数据以对分区进行调整。这包括向前移动边界,为下一个时段添加新的Kudu分区,以及删除旧的Kudu分区。
实现步骤
为了实现滑动窗口模式,需要一些Impala基础,下面介绍实现滑动窗口模式的基本步骤。
移动数据
只要我们使用每种存储格式定义匹配表,就可以通过Impala在存储系统之间移动数据。为简洁起见,未描述创建Impala表时可用的所有选项,可以参考Impala的CREATE TABLE文档来查找创建Kudu、HDFS和云存储表的正确语法。下面列出了一些示例,其中包括滑动窗口模式。
创建表后,移动数据就像INSERT ... SELECT语句一样简单:
INSERT INTO table_foo SELECT * FROM table_bar;
SELECT语句的所有功能都可用于选择要移动的特定数据。
注意:如果将数据移动到Kudu,可以使用UPSERT INTO语句来处理重复键。
统一查询
在Impala中查询来自多个表和数据源的数据也很简单。为简洁起见,未描述创建Impala视图时可用的所有选项,可以参考Impala的CREATE VIEW文档。
创建统一查询的视图就像使用两个SELECT子句和UNION ALL的CREATE VIEW语句一样简单:
CREATE VIEW foo_view AS
SELECT col1, col2, col3 FROM foo_parquet
UNION ALL
SELECT col1, col2, col3 FROM foo_kudu;
警告:确保使用UNION ALL而不是UNION。UNION关键字本身与UNION DISTINCT相同,可能会对性能产生重大影响,可以在Impala UNION文档中找到更多信息。
SELECT语句的所有功能都可用于公开每个基础表中的正确数据和列,使用WHERE子句传递和下推任何需要特殊处理或转换的谓词非常重要。下面将在滑动窗口模式的讨论中进行更多示例。
此外,可以通过ALTER VIEW语句更改视图,当与SELECT语句结合使用时,这很有用,因为它可以用于原子地更新视图正在访问的数据。
示例
下面是使用滑动窗口模式来操作具有三个月活动可变的月度周期数据的实现示例,超过三个月的数据将使用Parquet格式卸载到HDFS。
创建Kudu表
首先,创建一个Kudu表,该表将保存三个月的活动可变数据。该表由时间列分区,每个范围包含一个数据周期。拥有与时间周期匹配的分区很重要,因为删除Kudu分区比通过DELETE子句删除数据更有效。该表还由另一个键列进行散列分区,以确保所有数据都不会写入单个分区。
注意:模式设计(schema design)应根据我们的数据和读/写性能考虑因素而有所不同。此示例模式仅用于演示目的,而不是“最佳”模式。有关选择模式的更多指导,请参考Kudu模式设计文档(schema design documentation)。例如,如果数据输入速率较低,则可能不需要任何散列分区,如果数据输入速率非常高,则可能需要更多散列桶。
CREATE TABLE my_table_kudu
( name STRING,time TIMESTAMP,message STRING,PRIMARY KEY(name, time)
)
PARTITION BYHASH(name) PARTITIONS 4,RANGE(time) (PARTITION '2018-01-01' <= VALUES < '2018-02-01', --JanuaryPARTITION '2018-02-01' <= VALUES < '2018-03-01', --FebruaryPARTITION '2018-03-01' <= VALUES < '2018-04-01', --MarchPARTITION '2018-04-01' <= VALUES < '2018-05-01' --April
)
STORED AS KUDU;
注意:有一个额外的月分区(2018-04-01至2018-05-01)可以为数据提供一个时间缓冲区,以便将数据移动到不可变表中。
创建HDFS表
创建Parquet格式的HDFS表,该表将保存较旧的不可变数据。此表按年、月和日进行分区,以便进行有效访问,即使我们无法按时间列本身进行分区,这将在下面的视图步骤中进一步讨论。有关更多详细信息,请参考Impala的分区文档。
CREATE TABLE my_table_parquet
( name STRING,time TIMESTAMP,message STRING
)
PARTITIONED BY (year int, month int, day int)
STORED AS PARQUET;
创建统一视图
现在创建统一视图,用于无缝地查询所有数据:
CREATE VIEW my_table_view AS
SELECT name, time, message
FROM my_table_kudu
WHERE time >= "2018-01-01"
UNION ALL
SELECT name, time, message
FROM my_table_parquet
WHERE time < "2018-01-01"
AND year = year(time)
AND month = month(time)
AND day = day(time);
每个SELECT子句都明确列出要公开的所有列,这可确保不会公开Parquet表所特有的年、月和日列。如果需要,它还允许处理任何必要的列或类型映射。
应用于my_table_kudu和my_table_parquet的初始WHERE子句定义了Kudu和HDFS之间的边界,以确保在卸载数据的过程中不会读取重复数据。
应用于my_table_parquet的附加AND子句用于确保单个年、月和日列的良好谓词下推(good predicate pushdown)。
警告:如前所述,请务必使用UNION ALL而不是UNION。UNION关键字本身与UNION DISTINCT相同,可能会对性能产生重大影响,可以在Impala UNION文档中找到更多信息。
创建定时任务
现在已创建基表和视图,接着创建定时任务以维护滑动窗口,下面定时任务中使用的SQL文件可以接收从脚本和调度工具传递的变量。
创建window_data_move.sql文件以将数据从最旧的分区移动到HDFS:
INSERT INTO ${var:hdfs_table} PARTITION (year, month, day)
SELECT *, year(time), month(time), day(time)
FROM ${var:kudu_table}
WHERE time >= add_months("${var:new_boundary_time}", -1)
AND time < "${var:new_boundary_time}";
COMPUTE INCREMENTAL STATS ${var:hdfs_table};
注意:COMPUTE INCREMENTAL STATS子句不是必需的,但可帮助我们对Impala查询进行优化。
要运行SQL语句,请使用Impala shell并传递所需的变量,示例如下:
impala-shell -i <impalad:port> -f window_data_move.sql
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"
注意:可以调整WHERE子句以匹配给定的数据周期和卸载的粒度,这里,add_months函数的参数为-1,用于从新的边界时间移动过去一个月的数据。
创建window_view_alter.sql文件以通过更改统一视图来调整时间边界:
ALTER VIEW ${var:view_name} AS
SELECT name, time, message
FROM ${var:kudu_table}
WHERE time >= "${var:new_boundary_time}"
UNION ALL
SELECT name, time, message
FROM ${var:hdfs_table}
WHERE time < "${var:new_boundary_time}"
AND year = year(time)
AND month = month(time)
AND day = day(time);
要运行SQL语句,请使用Impala shell并传递所需的变量,示例如下:
impala-shell -i <impalad:port> -f window_view_alter.sql
--var=view_name=my_table_view
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"
创建window_partition_shift.sql文件以调整Kudu分区:
ALTER TABLE ${var:kudu_table}ADD RANGE PARTITION add_months("${var:new_boundary_time}",
${var:window_length}) <= VALUES < add_months("${var:new_boundary_time}",
${var:window_length} + 1);ALTER TABLE ${var:kudu_table} DROP RANGE PARTITION add_months("${var:new_boundary_time}", -1)
<= VALUES < "${var:new_boundary_time}";
要运行SQL语句,请使用Impala shell并传递所需的变量,示例如下:
impala-shell -i <impalad:port> -f window_partition_shift.sql
--var=kudu_table=my_table_kudu
--var=new_boundary_time="2018-02-01"
--var=window_length=3
注意:应该定期在Kudu表上运行COMPUTE STATS,以确保Impala的查询性能最佳。
试验
我们已经创建了表、视图和脚本实现了滑动窗口模式,现在可以通过插入不同时间范围的数据并运行脚本来向前移动窗口来进行试验。
将一些示例值插入Kudu表:
INSERT INTO my_table_kudu VALUES
('joey', '2018-01-01', 'hello'),
('ross', '2018-02-01', 'goodbye'),
('rachel', '2018-03-01', 'hi');
在每个表/视图中显示数据:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;
将1月数据移动到HDFS:
impala-shell -i <impalad:port> -f window_data_move.sql
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"
确认数据在两个位置,但在视图中不重复:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;
改变视图将时间边界向前移至2月:
impala-shell -i <impalad:port> -f window_view_alter.sql
--var=view_name=my_table_view
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"
确认数据仍在两个位置,但在视图中不重复:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;
调整Kudu分区:
impala-shell -i <impalad:port> -f window_partition_shift.sql
--var=kudu_table=my_table_kudu
--var=new_boundary_time="2018-02-01"
--var=window_length=3
确认1月数据现在仅在HDFS中:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;
使用Impala的EXPLAIN语句确认谓词下推:
EXPLAIN SELECT * FROM my_table_view;
EXPLAIN SELECT * FROM my_table_view WHERE time < "2018-02-01";
EXPLAIN SELECT * FROM my_table_view WHERE time > "2018-02-01";
在explain输出中,我们应该看到“kudu谓词”,其中包括“SCAN KUDU”部分中的时间列过滤器和“谓词”,其中包括“SCAN HDFS”部分中的时间、日、月和年列。
参考资料:
实时性和完整性兼得,使用 Kudu 和 Impala 实现透明的分层存储管理
神策分析的技术选型与架构实现
编译自:Transparent Hierarchical Storage Management with Apache Kudu and Impala
转载于:https://my.oschina.net/dabird/blog/3051625
使用Apache Kudu和Impala实现存储分层相关推荐
- 未明确定义列存储过程没问题_使用Apache Kudu和Impala实现存储分层
当为应用程序的数据选择一个存储系统时,我们通常会选择一个最适合我们业务场景的存储系统.对于快速更新和实时分析工作较多的场景,我们可能希望使用 Apache Kudu ,但是对于低成本的大规模可伸缩性场 ...
- Apache Kudu 与 Impala Shell 的结合使用文档(创建表、删、改、查)
Kudu与Apache Impala紧密集成,允许您在Impala使用Impala的SQL语法从Kudu去做 插入,查询,更新和删除数据,作为使用Kudu API 构建自定义Kudu应用程序的替代方法 ...
- 独家 | 一文读懂Apache Kudu
前言 Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力.Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impa ...
- KUDU和IMPALA的结合使用
Kudu 与 Apache Impala紧密集成,允许使用 Impala 的 SQL 语法从 Kudu tablets 插入,查询,更新和删除数据.此外,还可以用 JDBC 或 ODBC, Impal ...
- kudu on impala 基本用法。
好久没用kudu了 突然别的项目组开始用kudu,问各种问题,实在招架不住.... 于是自我学习一波. https://impala.apache.org/docs/build/impala-2.12 ...
- Apache Kudu 简介
Introducing Apache Kudu Kudu是cloudera开源的运行在hadoop平台上的列式存储系统,拥有Hadoop生态系统应用的常见技术特性,运行在一般的商用硬件上,支持水平扩展 ...
- Apache Kudu的介绍
一.Apache Kudu的介绍 1.1.背景介绍 在kudu之前,大数据主要以两种方式存储: (1)静态数据 : 以HDFS引擎作为存储,适用于高吞吐量的离线大数据分析场景. 这类存储的局限性是 ...
- Apache Kudu 1.9.0 发布,支持位置感知
开发四年只会写业务代码,分布式高并发都不会还做程序员? Apache Kudu 1.9.0 发布了,Kudu 是一个支持结构化数据的开源存储引擎,具有低延迟随机读取与高效分析读取模式.它基于 Ap ...
- mongodb存储数据_在MongoDB中存储分层数据
mongodb存储数据 继续使用MongoDB进行 NoSQL之旅,我想谈一谈一个经常出现的特定用例:存储分层文档关系. MongoDB是很棒的文档数据存储,但是如果文档具有父子关系,该怎么办? 我们 ...
最新文章
- 【c语言】蓝桥杯算法提高 3-3求圆面积表面积体积
- 每日一皮:男性同胞,是时候反击了!
- 虚拟机中mysql-cobar安装_cobar配置安装
- javaweb学习总结(七)——HttpServletResponse对象(一)
- 箱线图怎么判断异常值_箱形图(Box-plot)识别异常值,是否有数据依据?还是经验法则?...
- mysql中的各种join整理
- echarts图表的内边距_echarts——各个配置项详细说明总结
- MSN消息提示类(II)
- 11月16日云栖精选夜读:阿里云 oss JavaScript客户端签名文件上传 vue2.0
- [转载] Python输入,输出,Python导入
- Kronecker 定理
- Windows版Tcpdump抓包工具
- Java框架学习顺序是哪些
- 十六进制转二进制(C代码)
- ArcGIS 关于三维立体地图 简单使用,里面的资源就在 arcgis 的demo里面有
- TODA项目Part1—后端项目设置与连接数据库
- navicat查询oracle表结构,利用Navicat Premium导出数据库表结构信息至Excel的方法
- Java8新特性——Lambda函数式编程
- 浅谈根号分治——暴力的美学
- C语言10道入门题集