互联网络层的内核实现[内核中的路由机制]
内核中网络层3条线:
A 主机到网络->互联网络层-->传输层:
ip_rcv()
-->NF_INET_PRE_ROUTING
-->ip_rcv_finish
-->ip_route_input查找该分组路由,确定下一步处理函数ip_local_deliver
-->在内核高速路由缓冲中查找
-->在内核路由信息树中查找
-->ip_local_deliver
-->ip_defrag分片整合
-->NF_INET_LOCAL_IN钩子函数
-->ip_local_deliver_finish调用传输层处理函数tcp_v4_rcv等函数,控制转到传输层
B 主机到网络->互联网络层-->主机到网络层[转发]:
ip_rcv()
-->NF_INET_PRE_ROUTING
-->ip_rcv_finish
-->ip_route_input查找该分组路由,确定下一步处理函数ip_forward
-->在内核高速路由缓冲中查找
-->在内核路由信息树中查找
-->ip_forward分组转发函数
-->递减TTL,并重新计算校验和
-->NF_INET_FORWARDING钩子函数
-->ip_forward_finish函数,根据路由选择结果,调用ip_output函数,完成数据发送
-->ip_output
-->NF_INET_POST_ROUTING钩子函数
-->ip_finish_output处理钩子后事
-->ip_fragment,如有必要,进行分片处理
-->ip_finish_output2
-->skb_realloc_headroom分配以太网头部结构
-->dst->neighbour->output[dev_queue_xmit函数],该函数将其放置到特定与网卡的设备缓存中,一定时间后,发送出去
C 传输层->互联网络层-->主机到网络层[发送]:
ip_queue_xmit
-->确定路由
-->生成ip层头部校验和
-->NF_INET_LOCAL_OUT钩子函数
-->ip_queue_xmit2函数,根据路由选择结果,调用ip_output函数,完成数据发送
-->ip_output函数执行
-->NF_INET_POST_ROUTING钩子函数
-->ip_finish_output处理钩子后事
-->ip_fragment,如有必要,进行分片处理
-->ip_finish_output2
-->skb_realloc_headroom分配以太网头部结构
-->dst->neighbour->output[dev_queue_xmit函数],该函数将其放置到特定与网卡的设备缓存中,一定时间后,发送出去
1 网络层简介
网络层与网络适配器的硬件性质的关系体现在:该层负责在互不连接的系统间转发和路由[显然分组会通过很多中间节点]分组,查找最佳路由并选择向适当的网络设备发送分组,也涉及对底层地址族的处理,还有主机到网络层任务的指派,比如为了满足不同网卡硬件的传输需求[不同网卡硬件其传输协议规定的最大传输单元长度不一致],ip层必须将较大的分组划分为较小的单位,有接收方重新组合
2 IP协议首部主要字段
IP数据报的格式如图1所示。普通的IP首部长为20个字节(不含选项字段)。

图1 数据报格式
IP目前的协议版本号是4,因此IP有时也称作IPv4。IP协议首部的具体格式内容:
◆首部长度(IHL):首部占32 bit字的数目,包括任何选项。由于它是一个4比特字段,因此首部最长为60个字节。普通IP数据报(不含选项字段)字段的值是5,首部长度为20字节。
◆服务类型(TOS):包括一个3 bit的优先权子字段(现在已被忽略),4 bit的TOS子字段和1 bit未用位(必须置0),第4至第7比特分别代表延迟、吞吐量、可靠性和花费,最多只能一位置位,供上层协议使用
◆总长度字段(Total Length):整个IP数据报[分片后]的长度,以字节为单位。利用首部长度字段和总长度字段,可以知道IP数据报中数据内容的起始位置和长度。该字段长16比特,所以,IP数据报最长可达65535字节
[为了满足不同硬件的需求,不同传输技术支持分组长度不同,所以在ip层得对上层数据分组和重装]
◆标识字段(Identification)、标志字段(Flags)、分组偏移量字段(Fragment Offset):用来控制数据报的分片和重组。其中,标识字段16位:唯一标识主机发送的每一份数据报,通常每发送一份报文它的值就会加1;
分组偏移字段13位:将同一份数据报进行分组和合并时使用,偏移量单位为8字节;
标志字段3位:DF:该段不可拆分,MF:当前分组在是一个数据的分组,且后面还有分组[最后一个该位=0]
◆生存时间字段TTL(Time to Live):数据报可以经过的最多路由设备数。
◆上层协议字段:ICMP(1)、IGMP(2) 、TCP(6)、UDP(17)等。
◆首部检验和字段(Header Checksum):根据IP首部计算的检验和码。它不对首部后面的数据进行计算。
◆源IP地址和目的IP地址:每一份IP数据报都包含源IP地址和目的IP地址,分别指定发送方和接收方IP地址。
◆选项(Options):选项是最后一个字段,是可变长的可选信息。
3 IP头部
不同于链路层头部,只有14字节,只负责节点到节点的转发,不提供其他任何功能,ip头部提供分组和重组功能,提供头部校验功能,控制分组发送长度,但是不提供数据内容校验相关的服务
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)__u8 ihl:4,version:4; //version 占低4位
#elif defined (__BIG_ENDIAN_BITFIELD)__u8 version:4,ihl:4; //大端定义和读者看起来类似
#else#error "Please fix "
#endif__u8 tos;__be16 tot_len; //小端存储__be16 id;__be16 frag_off;__u8 ttl;__u8 protocol;__sum16 check;__be32 saddr; //网络发送的时候以大端序描述__be32 daddr;/*The options start here. */
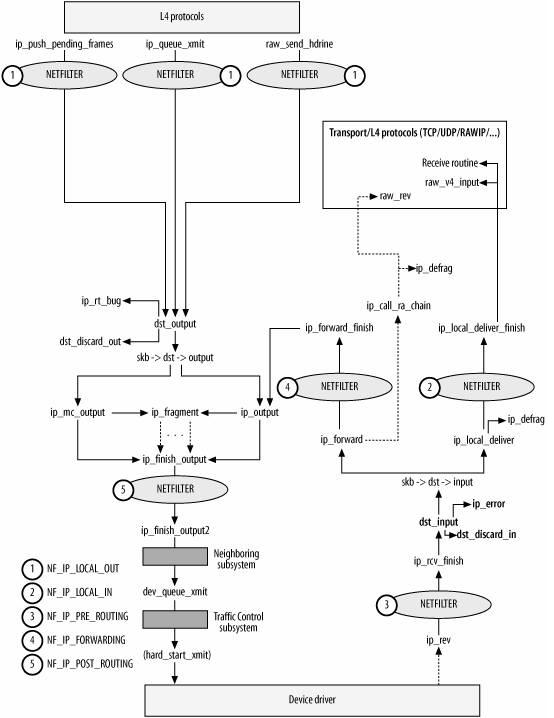
};4 网络层处理框图
图片来自: http://blog.csdn.net/wangxing1018/article/details/4224129
下面以 IPv4 为例,讲解 IPv4 分组在高层的处理。
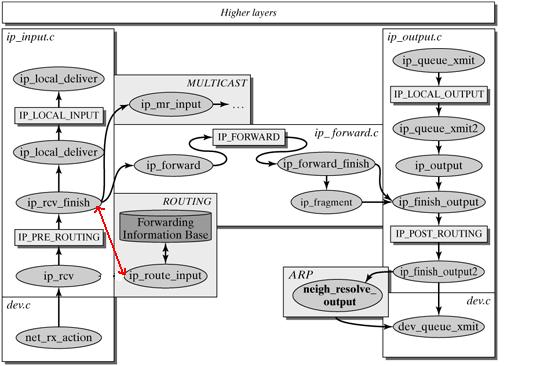
linux 内核协议栈之网络层
5 接收分组
5.1 ip_rcv() 接收来自主机到网络层的分组后,先对skb_buff和iphdr头部校验,然后调用NF_INET_PRE_ROUTING钩子函数
由上篇博客看出,当在支持传统框架的伪网络设备中的poll函数执行时,对每个到来的套接字缓冲区sk_buff,都会调用互联网络层中所有协议的处理函数进行处理,假设上层协议为ip协议,在遍历过程中会调用ip_rcv函数,该函数执行如下:
/** Main IP Receive routine.*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{struct iphdr *iph;u32 len;/* When the interface is in promisc. mode, drop all the crap* that it receives, do not try to analyse it.*/if (skb->pkt_type == PACKET_OTHERHOST) //根据链路层头部分析,不是给该物理地址,丢弃goto drop;IP_UPD_PO_STATS_BH(dev_net(dev), IPSTATS_MIB_IN, skb->len);if ((skb = skb_share_check(skb, GFP_ATOMIC)) == NULL) {IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);goto out;}if (!pskb_may_pull(skb, sizeof(struct iphdr)))goto inhdr_error;iph = ip_hdr(skb);//获取ip首部地址/** RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.** Is the datagram acceptable?** 1. Length at least the size of an ip header* 2. Version of 4* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]* 4. Doesn't have a bogus length*/if (iph->ihl < 5 || iph->version != 4) //检查ip头部字段值goto inhdr_error;if (!pskb_may_pull(skb, iph->ihl*4)) //分组内容大于20字节goto inhdr_error;iph = ip_hdr(skb);if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl))) //检查校验和,由汇编代码专门实现goto inhdr_error;len = ntohs(iph->tot_len);if (skb->len < len) { //如果该分组是分片后的分组,skb->len = 该分片后的分组的总长度,//由于发送时是按照分片进行转发的,其大小肯定小于MTU长度,而iphdr->tot_len是分片后大小IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INTRUNCATEDPKTS);goto drop;} else if (len < (iph->ihl*4)) //ip分组总长度应该大于ip首部goto inhdr_error;/* Our transport medium may have padded the buffer out. Now we know it* is IP we can trim to the true length of the frame.* Note this now means skb->len holds ntohs(iph->tot_len).*/if (pskb_trim_rcsum(skb, len)) {IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);goto drop;}/* Remove any debris in the socket control block */memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));/* Must drop socket now because of tproxy. */skb_orphan(skb);return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,ip_rcv_finish);
inhdr_error:IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
drop:kfree_skb(skb);
out:return NET_RX_DROP;
}5.2 钩子函数执行完毕后执行ip_rcv_finish函数
等待钩子函数执行完毕,执行ip_rcv_finish函数
static int ip_rcv_finish(struct sk_buff *skb)
{const struct iphdr *iph = ip_hdr(skb);struct rtable *rt;/** Initialise the virtual path cache for the packet. It describes* how the packet travels inside Linux networking.*/if (skb_dst(skb) == NULL) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,iph->tos, skb->dev);/*如果该分组尚未关联到路由,建立分组和路由结果的关联,1 当分组从主机到网络层向上传递到互联网络层,依靠分组目的地不同,建立不同的路由结果,以确定转发还是向上传递2 当分组从传输层传递到互联网络层,依靠分组目的地不同,建立不同的路由结构,以确定是发送到那个主机注:该函数非常重要*/if (unlikely(err)) {if (err == -EHOSTUNREACH)IP_INC_STATS_BH(dev_net(skb->dev),IPSTATS_MIB_INADDRERRORS);else if (err == -ENETUNREACH)IP_INC_STATS_BH(dev_net(skb->dev),IPSTATS_MIB_INNOROUTES);goto drop;}}//找到该分组对应的路由后[此时已经可以确定下一步处理函数],执行下面操作:
#ifdef CONFIG_NET_CLS_ROUTEif (unlikely(skb_dst(skb)->tclassid)) {struct ip_rt_acct *st = per_cpu_ptr(ip_rt_acct, smp_processor_id());u32 idx = skb_dst(skb)->tclassid;st[idx&0xFF].o_packets++;st[idx&0xFF].o_bytes += skb->len;st[(idx>>16)&0xFF].i_packets++;st[(idx>>16)&0xFF].i_bytes += skb->len;}
#endifif (iph->ihl > 5 && ip_rcv_options(skb))goto drop;rt = skb_rtable(skb);if (rt->rt_type == RTN_MULTICAST) {IP_UPD_PO_STATS_BH(dev_net(rt->u.dst.dev), IPSTATS_MIB_INMCAST,skb->len);} else if (rt->rt_type == RTN_BROADCAST)IP_UPD_PO_STATS_BH(dev_net(rt->u.dst.dev), IPSTATS_MIB_INBCAST,skb->len);return dst_input(skb);/*该函数返回:[(struct dst_entry*)(skb->__skb_refdst&(~1UL))]->input(skb);调用特定的处理函数,如果目的地是本地,则inpu函数为ip_local_deliver,output函数是ip_rt_bug函数;如果是其他主机,input=ip_forward函数,ouput=ip_output函数,此时以确定去往该目的主机的下一跳主机;*/
drop:kfree_skb(skb);return NET_RX_DROP;
}5.3 ip_route_input_noref函数执行,负责确定该分组的路由结构
在IP实现中,路由非常重要,不仅在转发外部分组时用,在发送本地产生的分组也要用到,查找数据从计算机外出的正确路径问题,在当本地计算机有几个网络接口时,会予以考虑
A 路由结构
/* Each dst_entry has reference count and sits in some parent list(s).* When it is removed from parent list, it is "freed" (dst_free).* After this it enters dead state (dst->obsolete > 0) and if its refcnt* is zero, it can be destroyed immediately, otherwise it is added* to gc list and garbage collector periodically checks the refcnt.*/
struct sk_buff;
struct dst_entry {struct rcu_head rcu_head;struct dst_entry *child;struct net_device *dev; //处理该分组的网络设备short error;short obsolete;int flags;#define DST_HOST 1#define DST_NOXFRM 2#define DST_NOPOLICY 4#define DST_NOHASH 8unsigned long expires;unsigned short header_len; /* more space at head required */unsigned short trailer_len; /* space to reserve at tail */unsigned int rate_tokens;unsigned long rate_last; /* rate limiting for ICMP */struct dst_entry *path;struct neighbour *neighbour;//存储了可以通过本地主机到网络层直接达到的下一跳主机的ip和硬件地址struct hh_cache *hh;
#ifdef CONFIG_XFRMstruct xfrm_state *xfrm;
#elsevoid *__pad1;
#endifint (*input)(struct sk_buff*); //处理进入的分组函数int (*output)(struct sk_buff*);//处理外出的分组函数struct dst_ops *ops;u32 metrics[RTAX_MAX];
#ifdef CONFIG_NET_CLS_ROUTE__u32 tclassid;
#else__u32 __pad2;
#endif/** Align __refcnt to a 64 bytes alignment* (L1_CACHE_SIZE would be too much)*/
#ifdef CONFIG_64BITlong __pad_to_align_refcnt[1];
#endif/** __refcnt wants to be on a different cache line from* input/output/ops or performance tanks badly*/atomic_t __refcnt; /* client references */int __use;unsigned long lastuse;union {struct dst_entry *next;struct rtable *rt_next; 挂在到内核缓存路由列表中struct rt6_info *rt6_next;struct dn_route *dn_next;};
};该结构实例是在从网络层向主机到网络层发送分组时,在已经确定目的地下一条路由而且在NF_INET_POST_RUNTING之后调用arp地址转换协议实现,此时下一跳路由已经确定,也就是其下一跳ip地址[必然与该主机在局域网中,一般为网关]已经确定,调用arp协议将ip地址转换为MAC地址,并填充struct neighbour结构,填充sk_buff的链路层头部,然后调用neighbour->output()函数发送到主机到网络层
struct neighbour {struct neighbour *next;struct neigh_table *tbl;struct neigh_parms *parms;struct net_device *dev;//从本地那个以太网接口发送unsigned long used;unsigned long confirmed;unsigned long updated;__u8 flags;__u8 nud_state;__u8 type;__u8 dead;atomic_t probes;rwlock_t lock;unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))];//下一跳主机物理地址struct hh_cache *hh;atomic_t refcnt;int (*output)(struct sk_buff *skb);//该函数一般为dev_queue_xmit(),该函数将该套接字缓冲区发送到特定于以太网设备的发送缓冲队列中,//然后再一定时间间隔后,由特定于网络设备的函数hard_start_xmit完成发送struct sk_buff_head arp_queue;struct timer_list timer;const struct neigh_ops *ops;u8 primary_key[0];
};B 由于网络互联层[从主机到网络层、传输层]接收到分组后,其发送目的地无非:
1 本地计算机
2 与当前计算机直接相连的计算机
3 远程计算机,只能通过局域网网关传送
所以根据目的地的不同需要采用不同的路由策略,其中牵扯到在路由缓存中查找路由,该策略由以下函数实现:
int ip_route_input_common(struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev, bool noref)
{struct rtable * rth;unsigned hash;int iif = dev->ifindex;//网口索引,唯一标示该网口struct net *net;net = dev_net(dev); //找到网络命名空间if (!rt_caching(net))goto skip_cache;tos &= IPTOS_RT_MASK;hash = rt_hash(daddr, saddr, iif, rt_genid(net));//为了提高在内核路由缓存中的路由查找效率,采用杂凑函数实现rcu_read_lock();//遍历路由哈希表,所有的缓存路由都挂在到rt_hash_table全局变量中for (rth = rcu_dereference(rt_hash_table[hash].chain); rth;rth = rcu_dereference(rth->u.dst.rt_next)) {if ((((__force u32)rth->fl.fl4_dst ^ (__force u32)daddr) |((__force u32)rth->fl.fl4_src ^ (__force u32)saddr) |(rth->fl.iif ^ iif) | rth->fl.oif | (rth->fl.fl4_tos ^ tos)) == 0 &&rth->fl.mark == skb->mark && net_eq(dev_net(rth->u.dst.dev), net) && !rt_is_expired(rth)) { //缓存中有匹配该sk_buff的路由if (noref) { //如果该分组尚未匹配路由dst_use_noref(&rth->u.dst, jiffies);//设置该缓存路由的最近使用时间和增加使用计数skb_dst_set_noref(skb, &rth->u.dst);//设置skb->__skb_refdst=(unsigned long)dst|1,//即将套接字缓冲和路由建立连接,最后一位=1表示已经未引用,未引用该内核缓存} else { //否则,说明该套接字缓冲已经关联到一个路由,增加内核该路由引用计数dst_use(&rth->u.dst, jiffies); //增加dst->_refcnt值,设置该缓存路由的最近使用时间和增加使用计数skb_dst_set(skb, &rth->u.dst);//设置skb->__skb_refdst=(unsigned long)dst,最后一位=0,表示引用}RT_CACHE_STAT_INC(in_hit);rcu_read_unlock();return 0; //返回0}RT_CACHE_STAT_INC(in_hlist_search);}rcu_read_unlock();
skip_cache:/* Multicast recognition logic is moved from route cache to here.The problem was that too many Ethernet cards have broken/missinghardware multicast filters :-( As result the host on multicastingnetwork acquires a lot of useless route cache entries, sort ofSDR messages from all the world. Now we try to get rid of them.Really, provided software IP multicast filter is organizedreasonably (at least, hashed), it does not result in a slowdowncomparing with route cache reject entries.Note, that multicast routers are not affected, becauseroute cache entry is created eventually.*/if (ipv4_is_multicast(daddr)) {//多播地址,最高四位为1,exxxxxxx格式struct in_device *in_dev;rcu_read_lock();if ((in_dev = __in_dev_get_rcu(dev)) != NULL) {int our = ip_check_mc(in_dev, daddr, saddr,ip_hdr(skb)->protocol);if (our#ifdef CONFIG_IP_MROUTE||(!ipv4_is_local_multicast(daddr) && IN_DEV_MFORWARD(in_dev))#endif) {rcu_read_unlock();return ip_route_input_mc(skb, daddr, saddr,tos, dev, our);}}rcu_read_unlock();return -EINVAL;}return ip_route_input_slow(skb, daddr, saddr, tos, dev);
}C ip_route_input_slow(skb, daddr, saddr, tos, dev) 新建路由项
内核路由缓存中没有对应的路由,目标地址也不是多播地址,则需要建立一个新的路由,然后填写路由项[复杂的操作],并且将路由放入内核缓存中,建立路由与套接字缓冲的映射
/** NOTE. We drop all the packets that has local source* addresses, because every properly looped back packet[回环数据包]* must have correct destination already attached by output routine.** Such approach solves two big problems:* 1. Not simplex devices[单向通信设备] are handled properly.* 2. IP spoofing[欺骗] attempts are filtered with 100% of guarantee.*/
static int ip_route_input_slow(struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev)
{struct fib_result res;struct in_device *in_dev = in_dev_get(dev);struct flowi fl = { .nl_u = { .ip4_u ={ .daddr = daddr,.saddr = saddr,.tos = tos,.scope = RT_SCOPE_UNIVERSE,} },.mark = skb->mark,.iif = dev->ifindex };//新建一个与该套接字缓冲区对应的路由子结构,作为内核缓存中路由匹配的关键结构,//该结构和dst_entry一起位于struct rtbale中,而该结构作为连接进内核路由缓存的关键结构体unsigned flags = 0;u32 itag = 0;struct rtable * rth;unsigned hash;__be32 spec_dst;int err = -EINVAL;int free_res = 0;struct net * net = dev_net(dev);/* IP on this device is disabled. */if (!in_dev)goto out;/* Check for the most weird martians, which can be not detectedby fib_lookup.*/if (ipv4_is_multicast(saddr) || ipv4_is_lbcast(saddr) ||ipv4_is_loopback(saddr))//如果源地址是多播地址或者广播地址或者回环地址127.xxx.xxx.xxx,出错goto martian_source;if (daddr == htonl(0xFFFFFFFF) || (saddr == 0 && daddr == 0))goto brd_input;/* Accept zero addresses only to limited broadcast;* I even do not know to fix it or not. Waiting for complains :-)*/if (ipv4_is_zeronet(saddr))goto martian_source;if (ipv4_is_lbcast(daddr) || ipv4_is_zeronet(daddr) ||ipv4_is_loopback(daddr)) //目标地址是127.xxx.xxx.xxx,丢弃分组goto martian_destination;/** Now we are ready to route packet.*/if ((err = fib_lookup(net, &fl, &res)) != 0) { //返回一个flb_result结构res,在内核保存的路由选择信息中查找,否则没有路由信息if (!IN_DEV_FORWARD(in_dev))//找着返回0,否则非0goto e_hostunreach;goto no_route;}free_res = 1;RT_CACHE_STAT_INC(in_slow_tot); //增加每cpu计数if (res.type == RTN_BROADCAST)goto brd_input;if (res.type == RTN_LOCAL) { //发送到本地,在内核中保存的路由信息中选择出来的int result;result = fib_validate_source(saddr, daddr, tos,net->loopback_dev->ifindex,dev, &spec_dst, &itag, skb->mark);if (result < 0)goto martian_source;if (result)flags |= RTCF_DIRECTSRC;spec_dst = daddr;goto local_input; //如果目的地址为本地主机,则跳到local_input,在那建立路由缓冲,//并初始化input,output函数,其中input函数为ip_local_deliver}if (!IN_DEV_FORWARD(in_dev))goto e_hostunreach;if (res.type != RTN_UNICAST)goto martian_destination;err = ip_mkroute_input(skb, &res, &fl, in_dev, daddr, saddr, tos); //此处说明目的主机不是本地,建立内核路由高速缓存rtable结构,并初始化,//将其input函数设为ip_forward路由转发函数,output函数设为ip_output函数
done:in_dev_put(in_dev);if (free_res)fib_res_put(&res); //释放该fib_result结构out: return err;brd_input:if (skb->protocol != htons(ETH_P_IP))goto e_inval;if (ipv4_is_zeronet(saddr))spec_dst = inet_select_addr(dev, 0, RT_SCOPE_LINK);else {err = fib_validate_source(saddr, 0, tos, 0, dev, &spec_dst,&itag, skb->mark);if (err < 0)goto martian_source;if (err)flags |= RTCF_DIRECTSRC;}flags |= RTCF_BROADCAST;res.type = RTN_BROADCAST;RT_CACHE_STAT_INC(in_brd);
local_input:rth = dst_alloc(&ipv4_dst_ops); //分配并填写rtable结构,其中input和output函数均为:dst_discardif (!rth)goto e_nobufs;rth->u.dst.output= ip_rt_bug;//修改output函数为[向内核日志输出错误信息]rth->u.dst.obsolete = -1;rth->rt_genid = rt_genid(net);atomic_set(&rth->u.dst.__refcnt, 1);rth->u.dst.flags= DST_HOST;if (IN_DEV_CONF_GET(in_dev, NOPOLICY))rth->u.dst.flags |= DST_NOPOLICY;rth->fl.fl4_dst = daddr;rth->rt_dst = daddr;rth->fl.fl4_tos = tos;rth->fl.mark = skb->mark;rth->fl.fl4_src = saddr;rth->rt_src = saddr;
#ifdef CONFIG_NET_CLS_ROUTErth->u.dst.tclassid = itag;
#endifrth->rt_iif =rth->fl.iif = dev->ifindex;rth->u.dst.dev = net->loopback_dev;dev_hold(rth->u.dst.dev);rth->idev = in_dev_get(rth->u.dst.dev);rth->rt_gateway = daddr;rth->rt_spec_dst= spec_dst;rth->u.dst.input= ip_local_deliver; //转发到上层的函数rth->rt_flags = flags|RTCF_LOCAL;if (res.type == RTN_UNREACHABLE) {rth->u.dst.input= ip_error;rth->u.dst.error= -err;rth->rt_flags &= ~RTCF_LOCAL;}rth->rt_type = res.type;hash = rt_hash(daddr, saddr, fl.iif, rt_genid(net));err = rt_intern_hash(hash, rth, NULL, skb, fl.iif);goto done;
no_route:RT_CACHE_STAT_INC(in_no_route);spec_dst = inet_select_addr(dev, 0, RT_SCOPE_UNIVERSE);res.type = RTN_UNREACHABLE;if (err == -ESRCH)err = -ENETUNREACH;goto local_input;/** Do not cache martian addresses: they should be logged (RFC1812)*/
martian_destination:RT_CACHE_STAT_INC(in_martian_dst);
#ifdef CONFIG_IP_ROUTE_VERBOSEif (IN_DEV_LOG_MARTIANS(in_dev) && net_ratelimit())printk(KERN_WARNING "martian destination %pI4 from %pI4, dev %s\n",&daddr, &saddr, dev->name);
#endif
e_hostunreach:err = -EHOSTUNREACH;goto done;
e_inval:err = -EINVAL;goto done;
e_nobufs:err = -ENOBUFS;goto done;
martian_source:ip_handle_martian_source(dev, in_dev, skb, daddr, saddr);goto e_inval;
}
//注:内核中路由信息存储方式:
//网络命名卡空间net中:struct hlist_head* net->ipv4.fib_table_hash[2]为2种类型的路由表存储结构
#define TABLE_LOCAL_INDEX 0
#define TABLE_MAIN_INDEX 1
struct fib_table {struct hlist_node tb_hlist; //挂在在hlist_head头部中u32 tb_id;int tb_default;unsigned char tb_data[0];
};其中fib_table->tb_data[0]的结构为:struct trie*
该结构类型为:
struct trie{ struct node* trie;} 为树节点的根,实质上struct node* 是strut tnode的内在一部分,所以该结构可以找到struct tnode结构,该结构是内核路由信息的树所在根,当进行查找时,以目的ip和当前tnode值组合为key,然后取得下一级tnode=father_tnode->child[hash[dstIp,tnode->x]]结构,直到取到叶子节点,或失败
struct tnode{unsigned long parent; t_key key;... struct node* child[0]
}
struct node *{unsigned long parent; t_key key;}
struct leaf *{unsigned long parent; t_key key;struct hlist_head list; struct rcu_head rcu;}
//当取到叶子节点时,其list指针为所有leaf_info的头部,该结构如下:
struct leaf_info{ struct hlist_node hlist; struct rcu_head rcu; int plen;struct list_head falh;}
//当取到leaf_info结构时,falh为所有fib_alias结构的头部,该结构定义如下:
struct fib_alias { //由目的ip可到达特定的fib_alias结构,fa_type表明dstIp对于本主机是那种类型的,是往本地还是往其他主机struct list_head fa_list; //连接元素struct fib_info *fa_info;u8 fa_tos;u8 fa_type;/*每个ip地址可以对应的类型有: TIN_UNSPEC,RTN_UNCAST,RTN_LOCAL,RTN_BROADCAST,RTN_MULTICAST,RTN_NAT,RTN_UNREACHABLE*/u8 fa_scope;u8 fa_state;
#ifdef CONFIG_IP_FIB_TRIEstruct rcu_head rcu;
#endif
};
struct fib_alias {struct list_head fa_list;struct fib_info *fa_info;u8 fa_tos;u8 fa_type;u8 fa_scope;u8 fa_state;
#ifdef CONFIG_IP_FIB_TRIEstruct rcu_head rcu;
#endif
};再找到对应的fib_alias后,更具信息填充fib_result结构
在函数fib_semantic_match最后:
out_fill_res:
fib_result->type = fib_alias->fa_type; ...
一下为该查找过程的总体执行:
static inline int fib_lookup(struct net *net, const struct flowi *flp,struct fib_result *res)
{struct fib_table *table;table = fib_get_table(net, RT_TABLE_LOCAL);if (!fib_table_lookup(table, flp, res))return 0;table = fib_get_table(net, RT_TABLE_MAIN);if (!fib_table_lookup(table, flp, res))return 0;return -ENETUNREACH;
}
static inline struct fib_table *fib_get_table(struct net *net, u32 id)
{struct hlist_head *ptr;ptr = id == RT_TABLE_LOCAL ?&net->ipv4.fib_table_hash[TABLE_LOCAL_INDEX] :&net->ipv4.fib_table_hash[TABLE_MAIN_INDEX];return hlist_entry(ptr->first, struct fib_table, tb_hlist);
}在路由信息表中查找过程:
int fib_table_lookup(struct fib_table* tb,const strut flowi* fip,struct fib_result* res)
该函数由于比较长,不再复制,查找原理可见前面描述,本质上内核对每个可能的ip地址,都在内核的基数树中按照ip关键字存储,查找时按照顺序层层遍历直到叶子节点即可
关键点查找:
我们知道,在接受到分组进行选择处理时或者发送分组到外部主机时,都需要选择路由,如果根据目标地址,如果分组是向上转发的,则路由非常好选择,如果是转发的,则会调用_mkroute_input函数完成转发路由选择,如果是发送出去[源地址是本机],则会调用__mkroute_output函数完成路由选择,这两个函数都需解决这个问题:在目标地址不是本机所在的网络时,需要转发分组,那么如何根据目标地址,确定下一跳的节点地址呢?
下面摘取小片段分析:
在__mkroute_output函数最后,填充分组路由信息时:
rth->fl.fl4_dst = daddr;rth->rt_dst = daddr;rth->fl.fl4_tos = tos;rth->fl.mark = skb->mark;rth->fl.fl4_src = saddr;rth->rt_src = saddr;rth->rt_gateway = daddr; //上述将下一跳路由ip地址设置为和目标地址一样rth->rt_iif =rth->fl.iif = in_dev->dev->ifindex;rth->u.dst.dev = (out_dev)->dev;dev_hold(rth->u.dst.dev);rth->idev = in_dev_get(rth->u.dst.dev);rth->fl.oif = 0;rth->rt_spec_dst= spec_dst;rth->u.dst.input = ip_forward;rth->u.dst.output = ip_output;rth->rt_genid = rt_genid(dev_net(rth->u.dst.dev));rt_set_nexthop(rth, res, itag);rt_set_nexthop(rth, res, itag);该函数执行如下:
static void rt_set_nexthop(struct rtable *rt, struct fib_result *res, u32 itag)
{struct fib_info *fi = res->fi;if (fi) {if (FIB_RES_GW(*res) && FIB_RES_NH(*res).nh_scope == RT_SCOPE_LINK)rt->rt_gateway = FIB_RES_GW(*res); //设置网关地址memcpy(rt->u.dst.metrics, fi->fib_metrics,sizeof(rt->u.dst.metrics));if (fi->fib_mtu == 0) {rt->u.dst.metrics[RTAX_MTU-1] = rt->u.dst.dev->mtu;if (dst_metric_locked(&rt->u.dst, RTAX_MTU) && rt->rt_gateway != rt->rt_dst && rt->u.dst.dev->mtu > 576)rt->u.dst.metrics[RTAX_MTU-1] = 576;}
#ifdef CONFIG_NET_CLS_ROUTErt->u.dst.tclassid = FIB_RES_NH(*res).nh_tclassid;
#endif} elsert->u.dst.metrics[RTAX_MTU-1]= rt->u.dst.dev->mtu;if (dst_metric(&rt->u.dst, RTAX_HOPLIMIT) == 0)rt->u.dst.metrics[RTAX_HOPLIMIT-1] = sysctl_ip_default_ttl;if (dst_mtu(&rt->u.dst) > IP_MAX_MTU)rt->u.dst.metrics[RTAX_MTU-1] = IP_MAX_MTU;if (dst_metric(&rt->u.dst, RTAX_ADVMSS) == 0)rt->u.dst.metrics[RTAX_ADVMSS-1] = max_t(unsigned int, rt->u.dst.dev->mtu - 40,ip_rt_min_advmss);if (dst_metric(&rt->u.dst, RTAX_ADVMSS) > 65535 - 40)rt->u.dst.metrics[RTAX_ADVMSS-1] = 65535 - 40;
#ifdef CONFIG_NET_CLS_ROUTE
#ifdef CONFIG_IP_MULTIPLE_TABLESset_class_tag(rt, fib_rules_tclass(res));
#endifset_class_tag(rt, itag);
#endifrt->rt_type = res->type;
}然后再在发送的最后,会调用arp协议将网关的ip地址转换为硬件地址,发送出去
互联网络层的内核实现[内核中的路由机制]相关推荐
- php框架中uri路由机制,URI 路由 — CodeIgniter 3.1.5 中文手册|用户手册|用户指南|中文文档...
URI 路由¶ 一般情况下,一个 URL 字符串和它对应的控制器中类和方法是一一对应的关系. URL 中的每一段通常遵循下面的规则: example.com/class/function/id/ 但是 ...
- Transformer中的注意力机制
在自然语言处理领域中,Transformers已经成为了非常流行的模型.其中,最受欢迎的Transformer模型是BERT(Bidirectional Encoder Representations ...
- Linux内核源码中使用宏定义的若干技巧
在C中,宏定义的概念虽然简单,但是真要用好却并不那么容易,下面从Linux源码中抽取一些宏定义的使用方法,希望能从中得到点启发: 1. 类型检查 比如module_init的宏定义: 点击(此处)折叠 ...
- 【Linux 内核】Linux 操作系统结构 ( Linux 内核在操作系统中的层级 | Linux 内核子系统及关系 | 进程调度 | 内存管理 | 虚拟文件系统 | 网络管理 | 进程间通信 )
文章目录 一.Linux 内核在操作系统中的层级 二.Linux 内核子系统 三.Linux 内核子系统之间的关系 一.Linux 内核在操作系统中的层级 Linux 内核 所在层级 : 整个计算机系 ...
- Linux内核中的platform机制
Linux内核中的platform机制 从Linux 2.6起引入了一套新的驱动管理和注册机制:platform_device和platform_driver.Linux中大部分的设备驱动,都可以使用 ...
- Intel Realsense pyrealsense rs.decimation_filter()类(通过使用具有特定内核大小的中值执行下采样)(抽取过滤器/抽取滤波器)
from decimation_filter.py class decimation_filter(filter):""" Performs downsampling b ...
- 详解Linux2.6内核中基于platform机制的驱动模型
原文地址:详解Linux2.6内核中基于platform机制的驱动模型 作者:nacichan [摘要]本文以Linux 2.6.25 内核为例,分析了基于platform总线的驱动模型.首先介绍了P ...
- 【内核驱动】 在内核源码中添加第一个驱动程序
开发环境: Redhat6.5 开发板: Tiny4412 (ARM Cortex A9) 1. 在内核源码中创建自己的目录 2. 在对应的目录中创建源文件和Makefile文件 3. 对应文件 ...
- 驱动框架2——内核驱动框架中LED的基本情况、初步分析
以下内容源于朱有鹏嵌入式课程的学习,如有侵权,请告知删除. 一.内核驱动框架中LED的基本情况 1.相关文件 (1)drivers/leds目录 驱动框架规定的LED这种硬件的驱动应该待的地方. (2 ...
最新文章
- 第二十章:异步和文件I/O.(十一)
- python 如何跳过异常继续执行
- [CF1076E]Vasya and a Tree
- kvm 虚拟机 实用工具笔记(方便查看ip 磁盘复制和修改文件等)
- java获取栈最大值_实现O(1)获取最大最小值的栈----java
- 获取指定包名下的所有类
- JS JAVASCRIPT 判断两个日期相隔多少天
- java逻辑运算符_Java逻辑运算符
- C++11Mutex(互斥锁)详解
- springboot全局异常处理_SpringMVC全局异常处理
- office下载哪个版本比较好
- Java 插入、隐藏/显示、删除Excel行或列
- kali使用jd-gui
- Http协议是无状态的 作者:cp_insist
- 超声波模块SRF05
- 图片太大加载不出来的解决方法
- 去年中国水上交通安全形势稳定
- 文件加解密,AIDE入侵检测,扫描与抓包
- 最优化之凸集、凸函数、上确界、Jensen不等式、共轭函数、Fenchel不等式、拉格朗日乘子法、KKT条件
- nodo合并多个mp3文件
热门文章
- Java 算法 学做菜
- linux查看php命令目录权限,PHP执行linux命令mkdir权限问题
- python pandas借助pandas-profiling自动生成EDA
- Destoon源数据库配置文件在哪_数据库监控软件Lepus安装部署详解
- keil c语言 位域,联合体位域在keil c遇到的问题怎样解决?
- 08 Tomcat+Java Web项目的创建和War的生成
- Asp.Net Core 轻松学-玩转配置文件
- C#图解教程 第十八章 枚举器和迭代器
- http://ju.outofmemory.cn/entry/307891---------TICK
- LightOJ 1197 Help Hanzo 素数筛