完全分布式Hadoop2.3安装与配置
一、Hadoop基本介绍
Hadoop优点
1.高可靠性:Hadoop按位存储和处理数据
2.高扩展性:Hadoop是在计算机集群中完成计算任务,这个集群可以方便的扩展到几千台
3.高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度快
4.高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
5.低成本:Hadoop是开源的,集群是由廉价的PC机组成
Hadoop架构和组件
Hadoop是一个分布式系统基础架构,底层是HDFS(Hadoop Distributed File System)分布式文件系统,它存储Hadoop集群中所有存储节点上的文件(64MB块),HDFS上一层是MapReduce引擎(分布式计算框架),对分布式文件系统中的数据进行分布式计算。
1.HDFS架构
NameNode:Hadoop集群中只有一个NameNode,它负责管理HDFS的目录树和相关文件的元数据信息
Sencondary NameNode:有两个作用,一是镜像备份,二是日志与镜像定期合并,并传输给NameNode
DataNode:负责实际的数据存储,并将信息定期传输给NameNode
2.MapReduce架构(Hadoop0.23以后采用MapReduce v2.0或Yarn)
Yarn主要是把jobtracker的任务分为两个基本功能:资源管理和任务调度与监控,ResourceManager和每个节点(NodeManager)组成了新处理数据的框架。
ResourceManager:负责集群中的所有资源的统一管理和分配,接受来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各种应用程序(ApplicationMaster)。
NodeManager:与ApplicationMaster承担了MR1框架中的tasktracker角色,负责将本节点上的资源使用情况和任务运行进度汇报给ResourceManager。
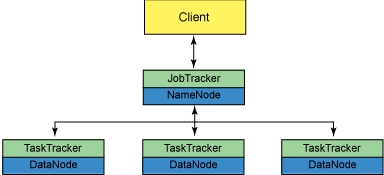
MapReduce v1.0框架(图1)
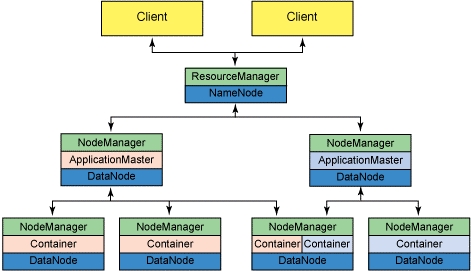
MapReduce v2.0框架(图2)
环境介绍:
master-hadoop 192.168.0.201
slave1-hadoop 192.168.0.202
slave2-hadoop 192.168.0.203
最新稳定版:http://www.apache.org/dist/hadoop/core/hadoop-2.3.0/
JDK下载:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
参考官方文档:http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-common/ClusterSetup.html
Hadoop三种运行方式:单节点方式(单台)、单机伪分布方式(一个节点的集群)与完全分布式(多台组成集群)
二、准备环境
1.Hadoop是用Java开发的,必须要安装JDK1.6或更高版本
2.Hadoop是通过SSH来启动slave主机中的守护进程,必须安装OpenSSH
3.Hadoop更新比较快,我们采用最新版hadoop2.3来安装
4.配置对应Hosts记录,关闭iptables和selinux(过程略)
5.创建相同用户及配置无密码认证
三、安装环境(注:三台配置基本相同)
1.安装JDK1.7
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@master-hadoop ~]# tar zxvf jdk-7u17-linux-x64.tar.gz
[root@master-hadoop ~]# mv jdk1.7.0_17/ /usr/local/jdk1.7
[root@slave1-hadoop ~]# vi/etc/profile #末尾添加变量
JAVA_HOME=/usr/local/jdk1.7
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export JAVA_HOME CLASSPATHPATH
[root@slave1-hadoop ~]#source /etc/profile
[root@slave1-hadoop ~]# java-version #显示版本说明配置成功
java version"1.7.0_17"
Java(TM) SE RuntimeEnvironment (build 1.7.0_17-b02)
Java HotSpot(TM) 64-BitServer VM (build 23.7-b01, mixed mode)
|
2.创建hadoop用户,指定相同UID
|
1
2
3
4
5
6
|
[root@master-hadoop ~]#useradd -u 600 hadoop
[root@master-hadoop ~]#passwd hadoop
Changing password for userhadoop.
New password:
Retype new password:
passwd: all authenticationtokens updated successfully.
|
3.配置SSH无密码登录(注:master-hadoop本地也要实现无密码登录)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@master-hadoop ~]# su - hadoop
[hadoop@master-hadoop ~]$ ssh-keygen -t rsa #一直回车生成密钥
[hadoop@master-hadoop ~]$ cd/home/hadoop/.ssh/
[hadoop@master-hadoop .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@slave1-hadoop ~]$ mkdir /home/hadoop/.ssh #登录两台创建.ssh目录
[hadoop@slave2-hadoop ~]$ mkdir /home/hadoop/.ssh
[hadoop@master-hadoop .ssh]$ scp id_rsa.pub hadoop@slave1-hadoop:/home/hadoop/.ssh/
[hadoop@master-hadoop .ssh]$ scp id_rsa.pub hadoop@slave2-hadoop:/home/hadoop/.ssh/
[hadoop@slave1-hadoop ~]$ cd/home/hadoop/.ssh/
[hadoop@slave1-hadoop .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@slave1-hadoop .ssh]$ chmod 600 authorized_keys
[hadoop@slave1-hadoop .ssh]$ chmod 700 ../.ssh/ #目录权限必须设置700
[root@slave1-hadoop ~]# vi /etc/ssh/sshd_config #开启RSA认证
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
[root@slave1-hadoop ~]# service sshd restart
|
四、Hadoop的安装与配置(注:三台服务器配置一样,使用scp复制过去)
|
1
2
3
4
5
6
7
|
[root@master-hadoop ~]# tar zxvf hadoop-2.3.0.tar.gz -C /home/hadoop/
[root@master-hadoop ~]# chown hadoop.hadoop -R /home/hadoop/hadoop-2.3.0/
[root@master-hadoop ~]# vi /etc/profile #添加hadoop变量,方便使用
HADOOP_HOME=/home/hadoop/hadoop-2.3.0/
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME PATH
[root@master-hadoop ~]# source /etc/profile
|
1. hadoop-env.sh设置jdk路径
|
1
2
3
|
[hadoop@master-hadoop ~]$ cd hadoop-2.3.0/etc/hadoop/
[hadoop@master-hadoop hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7/
|
2.slaves设置从节点
|
1
2
3
|
[hadoop@master-hadoophadoop]$ vi slaves
slave1-hadoop
slave2-hadoop
|
3.core-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master-hadoop:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
</configuration>
4.hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name> #数据副本数量,默认3,我们是两台设置2
<value>2</value>
</property>
</configuration>
|
6.yarn-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master-hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master-hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master-hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master-hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master-hadoop:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
|
7.mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master-hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master-hadoop:19888</value>
</property>
</configuration>
|
五、格式化文件系统并启动
1.格式化新的分布式文件系统(hdfs namenode -format)
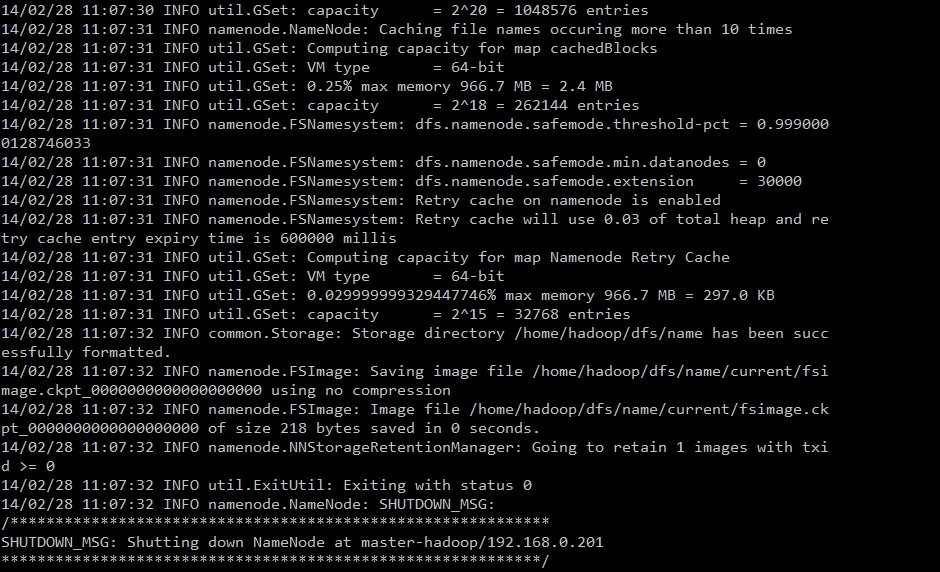
2.启动HDFS文件系统并使用jps检查守护进程是否启动

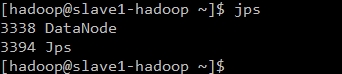
可以看到master-hadoop已经启动NameNode和SecondaryNameNode进程,slave-hadoop已经启动DataNode进程说明正常。
3.启动新mapreduce架构(YARN)

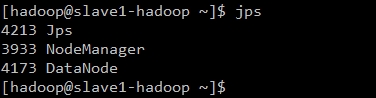
可以看到master-hadoop已经启动ResourceManger进程,slave-hadoop已经启动NodeManager进程说明正常。
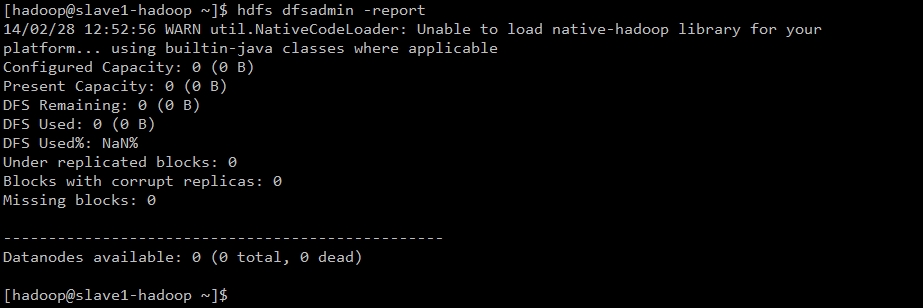
4.查看集群状态
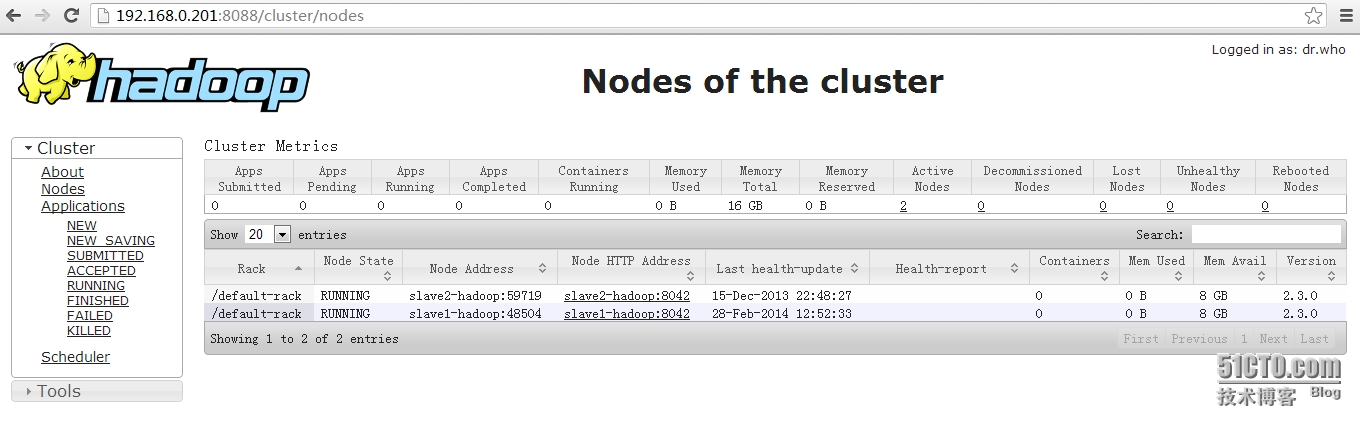
5.通过web查看资源(http://192.168.0.201:8088)
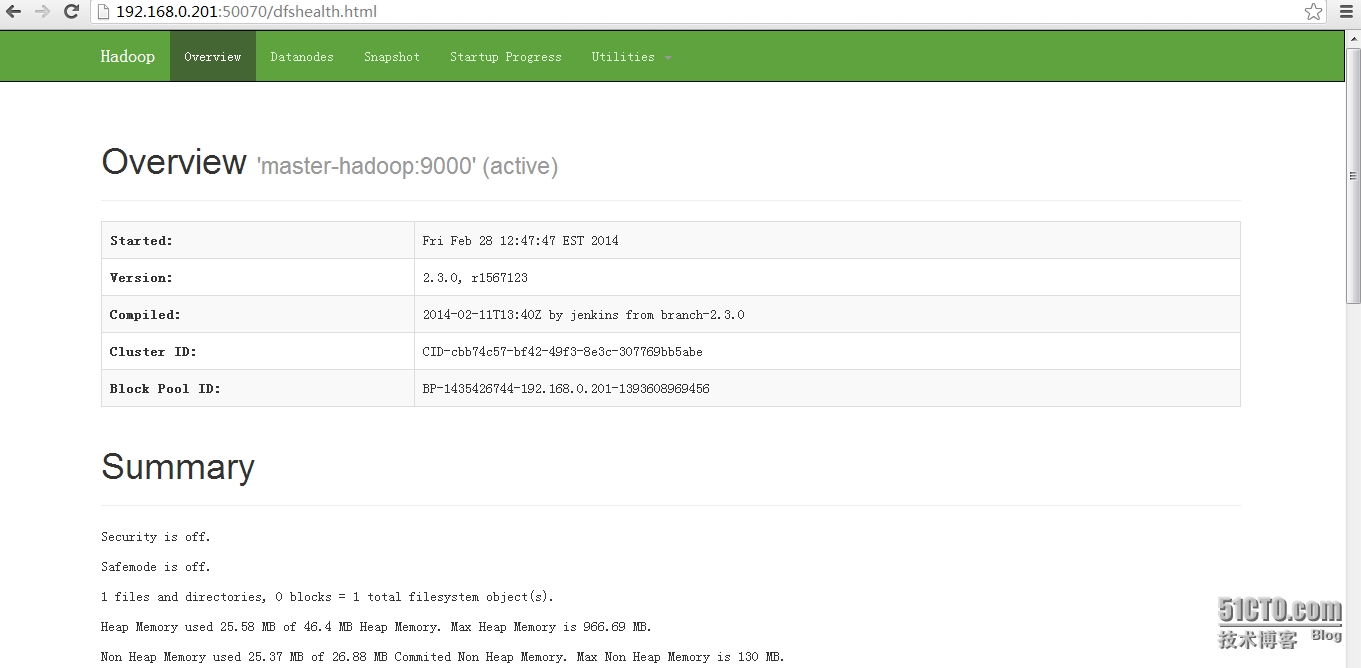
6、查看HDFS状态(http://192.168.0.201:50070)
本文出自 ““企鹅”那点事儿” 博客,请务必保留此出处http://going.blog.51cto.com/7876557/1365883
完全分布式Hadoop2.3安装与配置相关推荐
- sql server分布式_如何安装,配置和使用SQL Server分布式重播
sql server分布式 介绍 (Introduction) The Microsoft SQL Server Distributed Replay feature has been provide ...
- hadoop2.9安装及配置_阿里云服务器上装Hadoop的心得(内附Hadoop2.9.2详细安装教程)...
以前装Hadoop-3.1.2是跟着厦大林子雨的详细教程装的,所以遇到的问题不多,自己没怎么思考,导致跟着官网再装了一个Hadoop-2.9.2(为了装Hbase2.2.0)时装了两天,现在把遇到过的 ...
- FastDFS分布式文件系统的安装及配置
由于网站使用nfs共享方式保存用户上传的图片,附件等资料,然后通过apache下载的方式供用户访问,在网站架构初期,使用这种简单的方式实现了静态资源的读写分离,但随着网站数据量的增加,图片服务器渐渐成 ...
- hadoop-2.5安装与配置
安装之前准备4台机器:bluejoe0,bluejoe4,bluejoe5,bluejoe9 bluejoe0作为master,bluejoe4,5,9作为slave bluejoe0作为nameno ...
- hadoop 完全分布式模式的安装和配置
博客已经搬家,请访问如下地址:http://www.czhphp.com 我的本地虚拟机都是用root用户登录的: 1 配置hosts文件,每个节点都要配置 2 建立hadoop运行账号,每个节点都要 ...
- 分布式搜索Lily安装与配置
http://blog.csdn.net/morning_pig/article/details/8569842 参考文档: http://docs.ngdata.com/lily-docs-curr ...
- Hbase完全分布式集群安装配置(Hbase1.0.0,Hadoop2.6.0)
1.安装软件 OS:centos6.5 Hadoop:hadoop2.6.0 Hbase:hbase.1.0.0 JDK: jdk1.7.0_51 集群机器: 192.168.153.130(hado ...
- 第六天 - 安装第二、三台CentOS - SSH免密登陆 - hadoop全分布式安装、配置、集群启动
第六天 - 安装第二.三台CentOS - SSH免密登陆 - hadoop全分布式安装.配置.集群启动 第六天 - 安装第二.三台CentOS - SSH免密登陆 - hadoop全分布式安装.配置 ...
- Hadoop之——Hadoop2.2.0分布式集群安装
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/45748111 一.安装系统 虚拟软件 : VMware workstation ...
最新文章
- Linux防火墙iptables学习
- WebPart中的ReplaceTokens 方法
- windows 2008 server NTP Server
- .Net Core with 微服务 - Consul 注册中心
- 运行maven项目整合ssm时的错误笔记
- Python 对文件进行编码转换
- 4个空格 tab vetur_Python成为专业人士笔记–程序行空白及tab缩进的作用
- ShadowGun Deadzone 放出 GM Kit Mod 包
- python保存简单网页图片到本地(详细步骤)
- libev的ev_periodic介绍
- Three.js学习七——播放模型动画时模型沿着轨迹移动
- jQuery教程_编程入门自学教程_菜鸟教程-免费教程分享
- C++之Queue容器初学
- Genero BDL 数据类型(1)
- 安装cPanelWHM 技巧
- idea入门级配置(初)
- 异动K线--庄家破绽
- 云平台车载终端开发项目日志
- cpu,cpu风扇安装?
- 利用python数据分析,获取双色球历史中奖信息!(内含详细代码)