数据预处理:自定义PDF格式批量转换TXT系统
数据预处理:自定义文件格式转换系统
( 白宁超 2018年8月29日15:36:24 )
导读:随着大数据的快速发展,自然语言处理、数据挖掘、机器学习技术应用愈加广泛。针对大数据的预处理工作是一项庞杂、棘手的工作。首先数据采集和存储,尤其高质量数据采集往往不是那么简单。采集后的信息文件格式不一,诸如pdf,doc,docx,Excel,ppt等多种形式。然而最常见便是txt、pdf和word类型的文档。本文主要对pdf和word文档进行文本格式转换成txt。格式一致化以后再进行后续预处理工作。笔者采用一些工具转换效果都不理想,于是才出现本系统的研究与实现。(本文原创,转载必须注明出处: 数据预处理:自定义文件格式转换系统 )
1 本文概述
1.1 背景介绍
为什么要文件格式转换?
无论读者现在是做数据挖掘、数据分析、自然语言处理、智能对话系统、商品推荐系统等等,都不可避免的涉及语料的问题即大数据。数据来源无非分为结构化数据、半结构化数据和非结构化数据。其中结构化数据以规范的文档、数据库文件等等为代表;半结构化数据以网页、json文件等为代表;非结构化数据以自由文本为主,诸如随想录、中医病症记录等等。遗憾的是现实生活中半结构化和非结构化数据居多,而且往往还需要自己去收集。
读者试想以下情况:
- 你的技术主管交给你一堆数据文件,让你做数据分析工作。你打开一看文件格式繁杂,诸如pdf、doc、docx、txt、excel等。更悲催的是有些pdf文件还是加密的,或者是图片格式的等复杂情况。此刻你采用什么方法做数据分析与预处理工作呢?
- 上面情况算你幸运,隔几天技术主管直接给你一堆网站,让你自己去采集信息。你或许会惊喜的说的,那不简单,使用爬虫技术不就可以啦?恭喜你思路完全正确,可是爬取过程中遇到一些网页是pdf格式的情况,你不能直接抓取页面了。你此刻如何去采集信息呢?
现有工具的转换效果如何
针对以上典型的情况,自定义插件PDFMiner、win2com等将派上用场(本文主要讲述文件格式转化,网络爬虫解析读者自行研究)。首先我们看看常规方式的处理,比如我下载个格式转化软件或者在线格式转化软件,具体如下所示:
在线格式转换工具1页面效果如下:
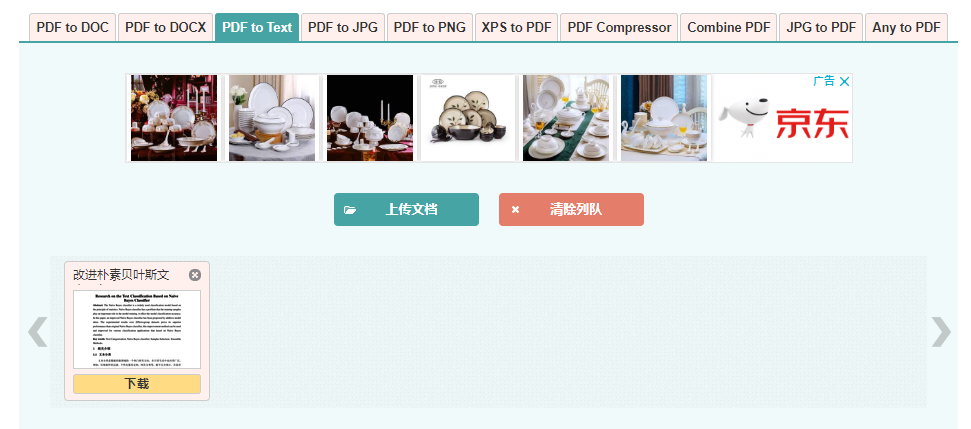
图1-1 在线格式转换工具1
pdf格式转化为txt后的效果如下:

图1-2 工具1pdf格式转化为txt结果
上面转换效果读者是否满意?是否因为某一个在线转换工具不完备,那我们再尝试一个,在线格式转换工具2页面效果如下:
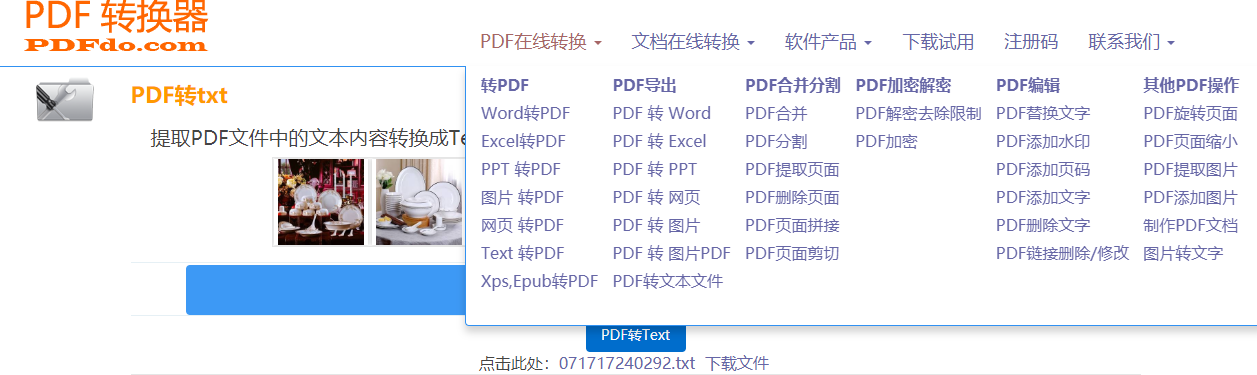
图1-3 在线格式转换工具2
pdf格式转化为txt后的效果如下:

图1-4 工具2pdf格式转化为txt结果
继续我们的格式转换工作,我们这次采用offic软件内带的pdf另存为效果如下:
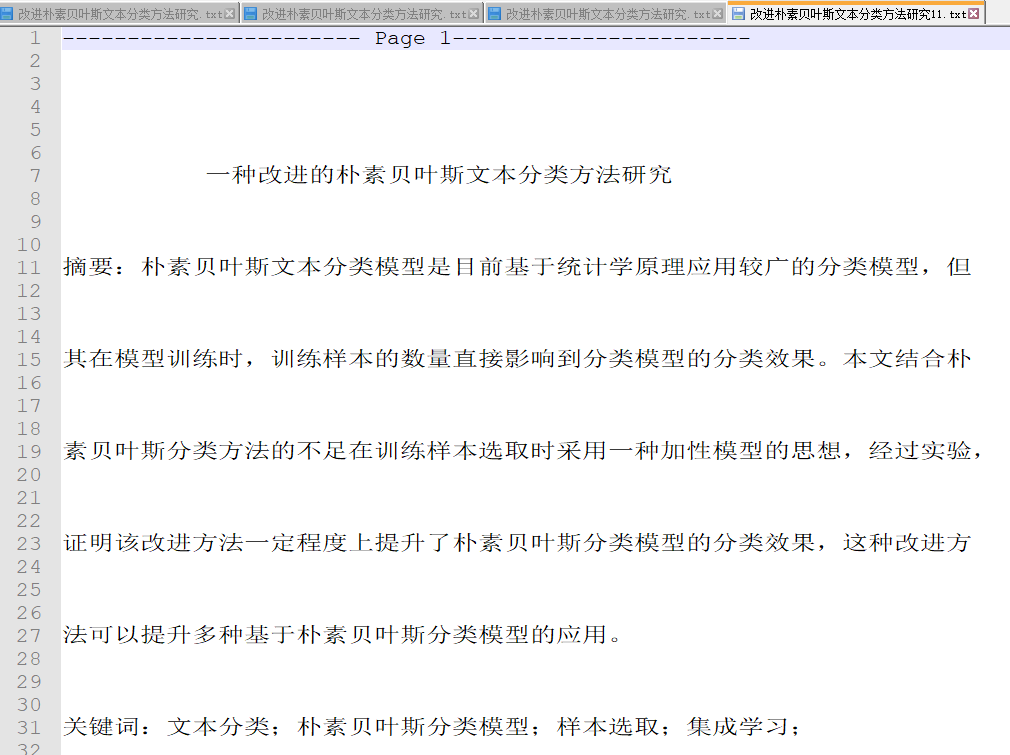
图1-5 offic软件内带的pdf另存为效果
总结
通过上面现有常规的方法,我们总结出以下问题:
1、 格式转换后,识别乱码较多。
2、 不支持或者限制支持批量处理。
3、 格式转换后的txt文件存在编码问题。
4、 生成目标文件的标题跟原标题不一致。
5、 操作不够灵活便捷。
1.2 基于自定义格式转换介绍
预期效果
1、 将带有嵌套的目录放在一个根目录文件下,只需要传入文件名即可自动转化。
2、 自动过滤掉不符合指定格式的文件。
3、 对处理的pdf文件不能识别的(加密文件等)给出日志记录其路径。
4、 生成目标文件的标题跟原文件目录标题保持一致。
5、 生成的文件按照统一的utf-8编码格式保存。
6、 支持默认保存路径与自定义保存路径。
预期效果展示
待处理语料数据如下:

图1-6 处理语料数据集
处理后默认自动保存的结果(支持自定义指定保存目录):

图1-7 默认自动保存转化后的数据集
基于自定义插件的文本转化效果:
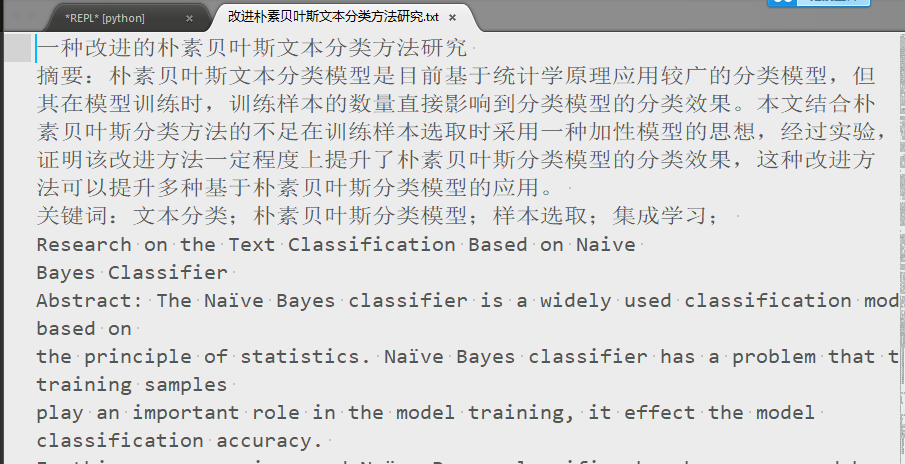
图1-8 自定义插件的文本转化效果
基于pdfminer插件的运行效果
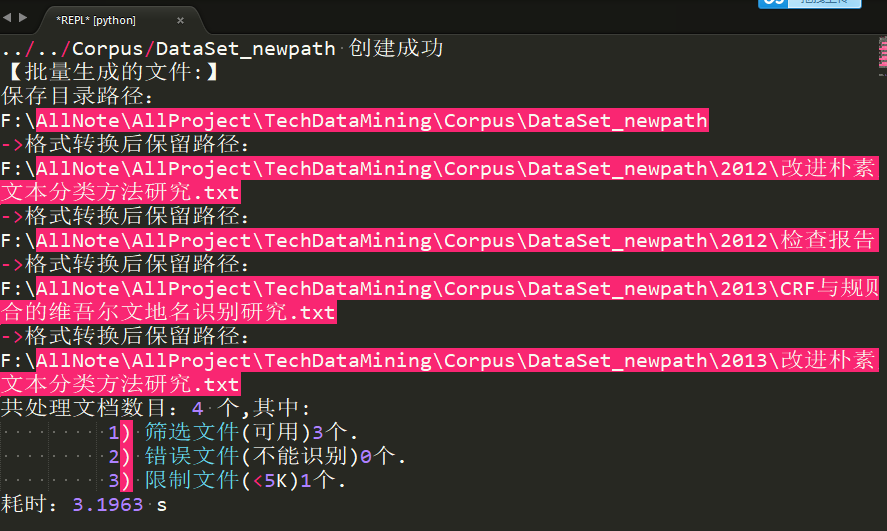
图1-9 整体运行效果图
2 基础配置工作
2.1 基础准备工作
运行环境
1、windows7以上64bit操作系统
2、sublime运行环境
3、python3.0+
需要插件
1、 pdfminer插件: 链接: https://pan.baidu.com/s/1p7X430bvBpjJ-qGNO-Fmcg 密码: v5th或者:pip install pdfminer3k
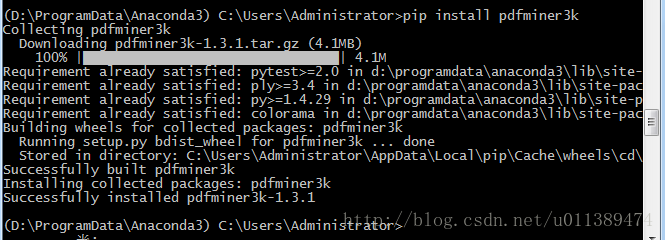
图2-1 pip方式安装pdfminer插件
2、 win2com 插件:链接: https://pan.baidu.com/s/1-2BsiTs8XjMIe5Gnh_GFjw 密码: 7j3tpip install pypiwin32
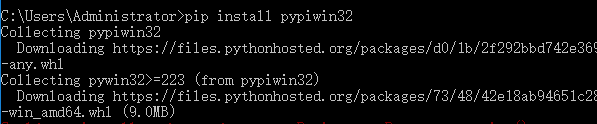
图2-2 pip方式安装win2com插件
2.2 类库重构
算法基础类库重构
重构又称高度代码封装,旨在代码重用和面向对象编程。本文将相关基本方法封装在一个类库中供外部类调用,提高代码复用性和可读性。具体重构文件结构如下:
重构文件名:BaseClass.py'''
功能描述:遍历目录,对子文件单独处理
参数描述:1 rootdir:待处理的目录路径2 deffun: 方法参数,默认为空3 savepath: 保存路径
'''
class TraversalFun():TraversalDir:遍历目录文件方法creat_savepath:支持默认和自定义保存目录方法AllFiles:递归遍历所有文件,并提供具体文件操作功能TranType:通过指定关键字操作,检查文件类型并转化目标类型filelogs:记录文件处理日志方法cleardir:清空目录文件方法writeFile:文件的写操作方法readFile:文件的读操作方法mkdir:创建目录方法'''功能描述:提供全局变量类作 者:白宁超时 间:2017年10月24日15:07:38'''class Global(object):提高各个公共全局变量'''功能描述:测试类作 者:白宁超时 间:2017年10月24日15:07:38'''def TestMethod(filepath,newpath):方法测试类
核心方法详解
1 TraversalFun类方法:
def __init__(self,rootdir,deffun=None,savedir=""):self.rootdir = rootdir # 目录路径self.deffun = deffun # 参数方法self.savedir = savedir # 保存路径''' 遍历目录文件'''
def TraversalDir(self,defpar='newpath'):try:# 支持默认和自定义保存目录newdir = TraversalFun.creat_savepath(self,defpar)# 递归遍历word文件并将其转化txt文件TraversalFun.AllFiles(self,self.rootdir,newdir)except Exception as e:raise e'''支持默认和自定义保存目录'''
# @staticmethod
def creat_savepath(self,defpar):# 文件路径切分为上级路径和文件名('F:\\kjxm\\kjt', '1.txt')prapath,filename = os.path.split(self.rootdir)newdir = ""if self.savedir=="":newdir = os.path.abspath(os.path.join(prapath,filename+"_"+defpar))else:newdir = self.savedirprint("保存目录路径:\n"+newdir)if not os.path.exists(newdir):os.mkdir(newdir)return newdir'''递归遍历所有文件,并提供具体文件操作功能。'''
def AllFiles(self,rootdir,newdir=''):# 返回指定目录包含的文件或文件夹的名字的列表for lists in os.listdir(rootdir):# 待处理文件夹名字集合path = os.path.join(rootdir, lists)# 核心算法,对文件具体操作if os.path.isfile(path):self.deffun(path,newdir) # 具体方法实现功能# TraversalFun.filelogs(rootdir) # 日志文件# 递归遍历文件目录if os.path.isdir(path):newpath = os.path.join(newdir, lists)if not os.path.exists(newpath):os.mkdir(newpath)TraversalFun.AllFiles(self,path,newpath)''' 通过指定关键字操作,检查文件类型并转化目标类型'''
def TranType(filename,typename):# print("本方法支持文件类型处理格式:pdf2txt,代表pdf转化为txt;word2txt,代表word转化txt;word2pdf,代表word转化pdf。")# 新的文件名称new_name = ""if typename == "pdf2txt" :#如果不是pdf文件,或者是pdf临时文件退出if not fnmatch.fnmatch(filename, '*.pdf') or not fnmatch.fnmatch(filename, '*.PDF') or fnmatch.fnmatch(filename, '~$*'):return# 如果是pdf文件,修改文件名if fnmatch.fnmatch(filename, '*.pdf') or fnmatch.fnmatch(filename, '*.PDF'):new_name = filename[:-4]+'.txt' # 截取".pdf"之前的文件名if typename == "word2txt" :#如果是word文件:if fnmatch.fnmatch(filename, '*.doc') :new_name = filename[:-4]+'.txt'print(new_name)if fnmatch.fnmatch(filename, '*.docx'):new_name = filename[:-5]+'.txt'# 如果不是word文件,或者是word临时文件退出else:returnif typename == "word2pdf" :#如果是word文件:if fnmatch.fnmatch(filename, '*.doc'):new_name = filename[:-4]+'.pdf'if fnmatch.fnmatch(filename, '*.docx'):new_name = filename[:-5]+'.pdf'#如果不是word文件:继续else:returnreturn new_name'''记录文件处理日志'''
def filelogs(rootdir):prapath,filename = os.path.split(rootdir)# 创建日志目录dirpath = prapath+r"/"+filename+"_logs"TraversalFun.mkdir(dirpath)# 错误文件路径errorpath = dirpath+r"/errorlogs.txt"# 限制文件路径limitpath = dirpath+r"/limitlogs.txt"# 错误文件日志写入TraversalFun.writeFile(errorpath,'\n'.join(Global.error_file_list))# # 限制文件日志写入TraversalFun.writeFile(limitpath,'\n'.join(Global.limit_file_list))'''清空目录文件'''
def cleardir(dirpath):if not os.path.exists(dirpath):TraversalFun.mkdir(dirpath)else:shutil.rmtree(dirpath)TraversalFun.mkdir(dirpath)''' 文件的写操作'''
def writeFile(filepath,strs): #encoding="utf-8"with open(filepath,'wb') as f:f.write(strs.encode())''' 文件的读操作'''
def readFile(filepath):isfile = os.path.exists(filepath)readstr = ""if isfile:with open(filepath,"r",encoding="utf-8") as f:readstr = f.read()else:returnreturn readstr''' 创建目录 '''
def mkdir(dirpath):# 判断路径是否存在isExists=os.path.exists(dirpath)# 判断结果if not isExists:os.makedirs(dirpath)print(dirpath+' 创建成功')else:pass
2 TestMethod测试类
'''
功能描述:测试类
作 者:白宁超
时 间:2017年10月24日15:07:38
'''
def TestMethod(filepath,newpath):if os.path.isfile(filepath) :print("this is file name:"+filepath)else:pass
3 利用测试类方法运行方法参数效果图
方法的调用:传达参数分别是跟目录和测试类中的方法参数
t1=time.time()# 根目录文件路径
rootDir = r"../../Corpus/DataSet"
tra=TraversalFun(rootDir,TestMethod) # 默认方法参数打印所有文件路径
tra.TraversalDir() # 遍历文件并进行相关操作t2=time.time()
totalTime=Decimal(str(t2-t1)).quantize(Decimal('0.0000'))
print("耗时:"+str(totalTime)+" s"+"\n")
input()
运行结果如图所示:
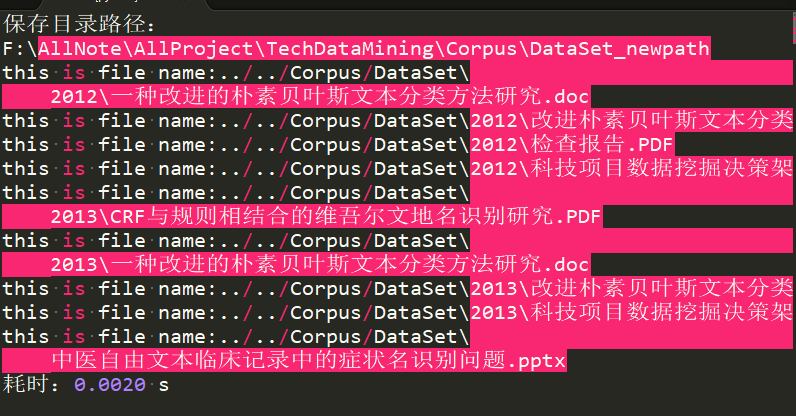
图2-3 测试方法参数判断是文件的打印文件路径
3 基于pdfminer插件的pdf批量格式转换代码实现
pdfminer原理介绍
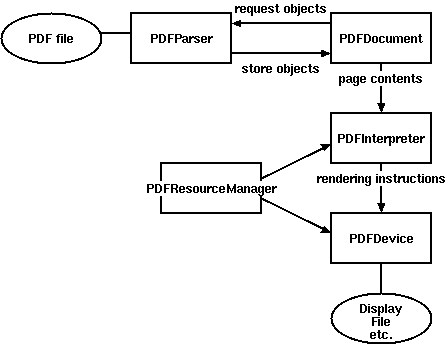
图3-1 pdfminer解析原理
由于解析PDF是一件非常耗时和内存的工作,因此PDFMiner使用了一种称作lazy parsing的策略,只在需要的时候才去解析,以减少时间和内存的使用。要解析PDF至少需要两个类:PDFParser 和 PDFDocument,PDFParser 从文件中提取数据,PDFDocument保存数据。另外还需要PDFPageInterpreter去处理页面内容,PDFDevice将其转换为我们所需要的。PDFResourceManager用于保存共享内容例如字体或图片。
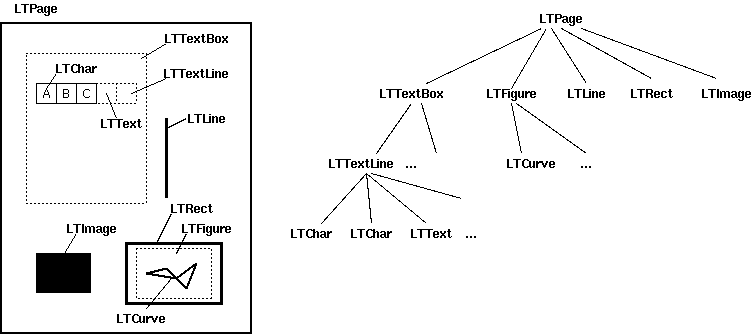
图3-2 LTpage解析原理
- LTPage :表示整个页。可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象。
- LTTextBox:表示一组文本块可能包含在一个矩形区域。注意此box是由几何分析中创建,并且不一定表示该文本的一个逻辑边界。它包含TTextLine对象的列表。使用 get_text()方法返回的文本内容。
- LTTextLine :包含表示单个文本行LTChar对象的列表。字符对齐要么 水平或垂直,取决于文本的写入模式。
- get_text()方法返回的文本内容。
- LTAnno:在文本中实际的字母表示为Unicode字符串(?)。需要注意的是,虽然一个LTChar对象具有实际边界,LTAnno对象没有,因为这些是“虚拟”的字符,根据两个字符间的关系(例如,一个空格)由布局分析后插入。
- LTImage:表示一个图像对象。嵌入式图像可以是JPEG或其它格式,但是目前PDFMiner没有放置太多精力在图形对象。
- LTLine:代表一条直线。可用于分离文本或附图。
- LTRect:表示矩形。可用于框架的另一图片或数字。
- LTCurve:表示一个通用的 Bezier曲线
pdfminer学习文献
英文官方:https://euske.github.io/pdfminer/index.html 中文:https://blog.csdn.net/robolinux/article/details/43318229
pdfminer代码实现
# pdfminer库的地址 https://pypi.python.org/pypi/pdfminer3k
# 下载后,用cmd执行命令 setup.py install
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowedfrom decimal import Decimal
import time,fnmatch,os,re,sysfrom BaseClass import * #全局变量
# from BaseClass import TraversalFun # 文件遍历处理基类函数# 清除警告
import logging
logging.Logger.propagate = False
logging.getLogger().setLevel(logging.ERROR)'''pdf文件格式转换为txt'''
def PdfToText(filepath,newdir=''):# 文件路径切分为上级路径和文件名prapath,filename = os.path.split(filepath)new_txt_name=TraversalFun.TranType(filename,"pdf2txt") # 更改文件名if new_txt_name ==None:returnnewpath = os.path.join(newdir,new_txt_name) # 文件保存路径print ("->格式转换后保留路径:\n"+newpath)try:praser = PDFParser(open(filepath, 'rb')) # 创建一个pdf文档分析器doc = PDFDocument() # 创建一个PDF文档praser.set_document(doc) # 连接分析器 与文档对象doc.set_parser(praser)doc.initialize() # 提供初始化密码,如果没有密码 就创建一个空的字符串# 检测文档是否提供txt转换,不提供就忽略if not doc.is_extractable:Global.error_file_list.append(filepath)returnrsrcmgr = PDFResourceManager() # 创建PDf 资源管理器管理共享资源laparams = LAParams() # 创建一个PDF设备对象device = PDFPageAggregator(rsrcmgr, laparams=laparams)interpreter = PDFPageInterpreter(rsrcmgr, device) # 创建一个PDF解释器对象pdfStr = "" # 存储解析后的提取内容# 循环遍历列表,每次处理一个page的内容for page in doc.get_pages(): # doc.get_pages()获取page列表interpreter.process_page(page)layout = device.get_result() # 接受该页面的LTPage对象# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,for x in layout:if (isinstance(x, LTTextBoxHorizontal)):pdfStr = pdfStr + x.get_text()TraversalFun.writeFile(newpath,pdfStr) # 写文件# 限制文件列表filesize = os.path.getsize(newpath)if filesize < Global.limit_file_size :Global.limit_file_list.append(newpath+"\t"+ str(Decimal(filesize/1024).quantize(Decimal('0.00'))) +"KB")os.remove(newpath)else :Global.all_FileNum+=1except Exception as e:Global.error_file_list.append(filepath)returnif __name__ == '__main__':t1=time.time()rootDir = r"../../Corpus/DataSet" # 默认处理路径TraversalFun.cleardir(r'../../Corpus/DataSet_newpath') # 每次加载清空目录print ('【批量生成的文件:】')tra=TraversalFun(rootDir,PdfToText) # 默认方法参数打印所有文件路径tra.TraversalDir()# 写入日志文件TraversalFun.filelogs(rootDir)print ('共处理文档数目:'+str(Global.all_FileNum+len(Global.error_file_list)+len(Global.limit_file_list))+' 个,其中:\n \1) 筛选文件(可用)'+str(Global.all_FileNum)+'个.\n \2) 错误文件(不能识别)'+ str(len(Global.error_file_list)) +'个.\n \3) 限制文件(<5K)'+ str(len(Global.limit_file_list))+'个.' )t2=time.time()totalTime=Decimal(str(t2-t1)).quantize(Decimal('0.0000'))print("耗时:"+str(totalTime)+" s"+"\n")input()
解析pdf文件用到的类:
- PDFParser:从一个文件中获取数据
- PDFDocument:保存获取的数据,和PDFParser是相互关联的
- PDFPageInterpreter处理页面内容
- PDFDevice将其翻译成你需要的格式
- PDFResourceManager用于存储共享资源,如字体或图像。
pdfminer页面结果:
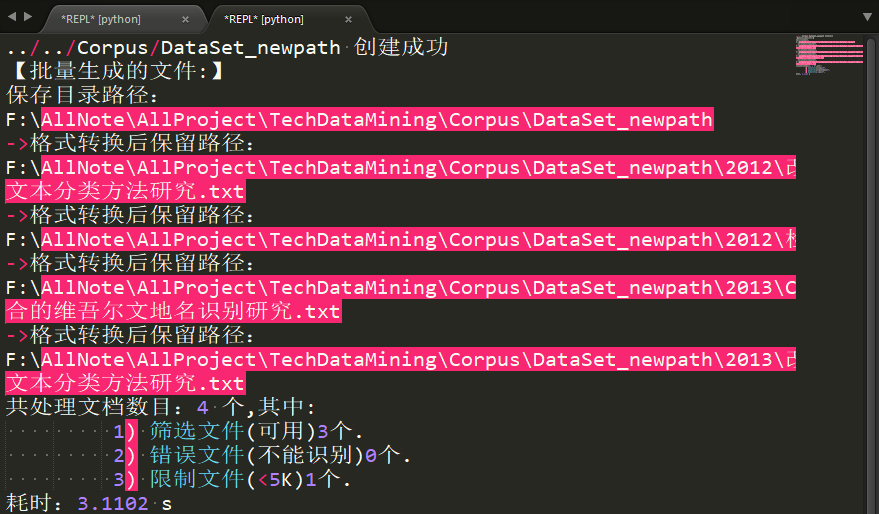
图3-3 pdfminer运行效果
pdfminer转化结果
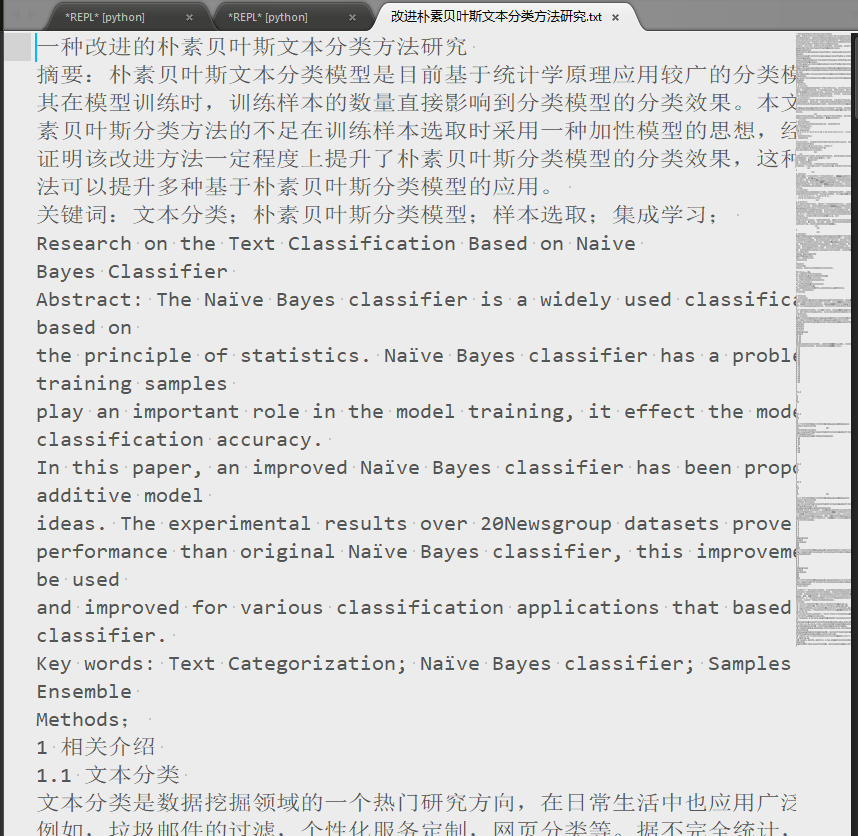
图3-4 pdfminer转化结果
实验结论
错误分析,打开日志文件查看
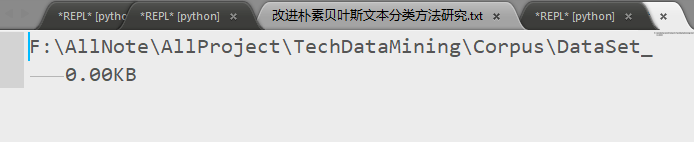
图3-5 pdfminer转化限制文件
错误原因分析:因为我们在全局变量中限制了最小文件读取1KB,该文件0KB不符合要求故而过滤出来。打开查看发现该pdf是一张图片转换出来的,没有成功识别。但是,通过技术研究是可以实现的,本文没有深入进行。还有以下结论:
1 可以支持批量文本和单文本转化。
2 编码格式一致,默认utf-8。
3 生成文件名誉原始处理文件名保存一致。
4 生成的文本信息相对比较规范。
支持多方式转化,其他案例读者自行研究。
扩展学习
在解析有些PDF的时候会报这样的异常:pdfminer.pdfdocument.PDFEncryptionError: Unknown algorithm: param={'CF': {'StdCF': {'Length': 16, 'CFM': /AESV2, 'AuthEvent': /DocOpen}}, 'O': '\xe4\xe74\xb86/\xa8)\xa6x\xe6\xa3/U\xdf\x0fWR\x9cPh\xac\xae\x88B\x06_\xb0\x93@\x9f\x8d', 'Filter': /Standard, 'P': -1340, 'Length': 128, 'R': 4, 'U': '|UTX#f\xc9V\x18\x87z\x10\xcb\xf5{\xa7\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00', 'V': 4, 'StmF': /StdCF, 'StrF': /StdCF}
如上是加密的PDF,所以无法解析 ,但是如果直接打开PDF却是可以的并没有要求输密码什么的,原因是这个PDF虽然是加过密的,但密码是空,所以就出现了这样的问题。
解决这个的问题的办法是通过qpdf命令来解密文件(要确保已经安装了qpdf),要想在python中调用该命令只需使用call即可:
1 from subprocess import call
2 call('qpdf --password=%s --decrypt %s %s' %('', file_path, new_file_path), shell=True)
其中参数filepath是要解密的PDF的路径,newfile_path是解密后的PDF文件路径,然后使用解密后的文件去做解析就OK了
4 基于win32com插件的代码实现
导入相关包
from win32com import client as wc
from win32com.client import Dispatch, constants, gencache
import os,fnmatch,time,sys
from decimal import Decimalfrom BaseClass import * # 自定义类库
word的doc或docx文件转化pdf文本
1 代码实现
'''
功能名称:word的doc或docx文件转化pdf文本
功能描述:输入一个doc或docx文件路径,自动转化为pdf文件,并存储在当前路径下。用户可以指定存储文件路径。
参数描述:1 filepath:单个文件路径2 newdir: 指定保存路径
测试路径: F:\corper\kjt\1.docx
'''
def doc2pdf(filepath,newDir=''):# 文件路径切分为上级路径和文件名prapath,filename = os.path.split(filepath)# 单文件处理使用if newDir=='':newDir = prapathelse:newDir =newDirnew_txt_name=TraversalFun.TranType(filename,"word2pdf")if new_txt_name ==None:returnelse:print(new_txt_name)newpath = os.path.join(newDir,new_txt_name)word = wc.DispatchEx("Word.Application")worddoc = word.Documents.Open(filepath,ReadOnly = 1)worddoc.SaveAs(newpath, FileFormat = 17)worddoc.Close()Global.all_FileNum+=1
2 单个word转换pdf
主程序运行代码:
# 单个word转换pdf
filepath=os.path.abspath(r"../../Corpus/DataSet/2012/科技项目数据挖掘决策架构.docx")
doc2pdf(filepath)
控制台打印效果:
科技项目数据挖掘决策架构.pdf
共处理文档数目:1 个
耗时:3.6121 s
结果:
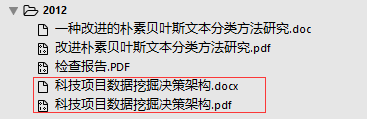
图4-1 word文档单文件转化结果
打开显示:

图4-2 转化后规范的pdf文件
3 批量word转换pdf
主程序运行代码:
rootDir =os.path.abspath(r"../../Corpus/DataSet")
# 1 批量的word转换pdf
tra=TraversalFun(rootDir,doc2pdf) # 默认方法参数打印所有文件路径
tra.TraversalDir('word2pdf')
控制台打印效果:
保存目录路径:
F:\AllNote\AllProject\TechDataMining\Corpus\DataSet_word2pdf
科技项目数据挖掘决策架构.pdf
科技项目数据挖掘决策架构.pdf
共处理文档数目:2 个
耗时:7.1494 s
结果:
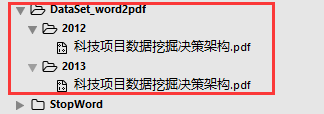
图4-3 word文档批量转化结果
word的doc或docx文件转化txt文本
1 代码实现
'''
功能名称:单个word的doc或docx文件转化txt文本
'''
def WordTranslate(filepath,newDir=''):# 文件路径切分为上级路径和文件名prapath,filename = os.path.split(os.path.abspath(filepath))if newDir=='':newDir = prapathelse:newDir =newDirnew_txt_name=TraversalFun.TranType(filename,'word2txt')if new_txt_name == None:returnelse:word_to_txt = os.path.join(newDir,new_txt_name)print ("格式转换后保留路径:\n"+word_to_txt)#加载处理应用wordapp = wc.Dispatch('Word.Application')doc = wordapp.Documents.Open(filepath)#为了让python可以在后续操作中r方式读取txt和不产生乱码,参数为4doc.SaveAs(word_to_txt,4)doc.Close()# print(word_to_txt)Global.all_FileNum += 1
2 单个word转换txt
# 单个word转换txt
filepath=os.path.abspath(r"../../Corpus/DataSet/2012/科技项目数据挖掘决策架构.docx")
WordTranslate(filepath)
3 批量的word转换txt
# 批量的word转换txt
tra=TraversalFun(rootDir,WordTranslate) # 默认方法参数打印所有文件路径
tra.TraversalDir('word2txt')
4 批量的word转换txt结果
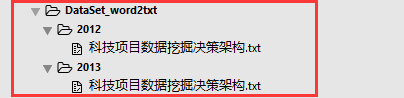
图4-4 批量的word转换txt结果
pdf文件转化txt文本
1 代码实现
'''
功能名称:pdf文件转化txt文本
功能描述:输入一个pdf文件路径,自动转化为txt文件,并存储在当前路径下。用户可以指定存储文件路径。
参数描述:1 filepath:单个文件路径2 newdir: 指定保存路径
测试路径: F:\corper\kjt\申报书.pdf
'''def PdfTranslate(filepath,newDir=''):# 文件路径切分为上级路径和文件名prapath,filename = os.path.split(filepath)if newDir=="":newDir = prapathelse:newDir = newDirnew_txt_name=TraversalFun.TranType(filename,"pdf2txt")if new_txt_name ==None:returnelse:word_to_txt = os.path.join(newDir,new_txt_name)# print(word_to_txt)#加载处理应用wordapp = wc.Dispatch('Word.Application')doc = wordapp.Documents.Open(filepath)#为了让python可以在后续操作中r方式读取txt和不产生乱码,参数为4doc.SaveAs(word_to_txt,4)doc.Close()Global.all_FileNum += 1
2 单个pdf文件转化txt文本
# 单个pdf转换txt
filepath=os.path.abspath(r"../../Corpus/DataSet/2012/改进朴素贝叶斯文本分类方法研究.pdf")
PdfTranslate(filepath)
3 批量pdf文件转化txt文本
# 3 批量的pdf转换txt
tra=TraversalFun(rootDir,PdfTranslate) # 默认方法参数打印所有文件路径
tra.TraversalDir("pdf2txt")
4 批量pdf文件转化txt文本结果

图4-5 批量pdf文件转化txt文本结果
5 完整代码下载
机器学习和自然语言QQ群:436303759

【微信公众号:datathinks】

源码请进QQ群文件下载:
图5-1 完整项目文件
参考文献
- http://www.unixuser.org/~euske/python/pdfminer/programming.html
- https://www.cnblogs.com/jamespei/p/5339769.html
- https://blog.csdn.net/u011389474/article/details/60139786
- https://blog.csdn.net/u010983763/article/details/78654651
- https://blog.csdn.net/zyc121561/article/details/77879831
- https://blog.csdn.net/zyc121561/article/details/77877912?locationNum=7&fps=1
声明
本文原创,转载必须注明出处: 数据预处理:自定义文件格式转换系统
数据预处理:自定义PDF格式批量转换TXT系统相关推荐
- PDF怎么批量转换成TXT格式?
现在大部分人都有阅读电子书的习惯,通常电子书的文件格式都是TXT文件形式,TXT文件是微软在操作系统上附带的一种最常见文本格式,它体积小.存储简单方便,所以我们通常会使用这种格式文档.有时候我们在网上 ...
- 如何将PDF文件批量转换成图片格式
在我们的日常工作中文件转换是一件常见的日常工作,而PDF文件转换是每一个上班族必备的技能之一,比如讲PDF文件转换成图片格式.毫无疑问PDF格式给用户带来更好的阅读体验,PDF文件是一页一页的文件形式 ...
- 怎么把PDF格式文件转换成PPT格式
我们经常会遇到不同格式转换的问题,如怎么办PDF格式文件转换成PPT格式,往往急于找不到有效的方法,事实上,要把PDF文件转换成PPT是非常简单的工作.下面小编就为大家分享一个最新最有效的办法.希望能 ...
- pdf格式怎么转换成word格式
pdf格式怎么转换成word格式 从事文职工作的我深有感触,录入资料是一件考验人耐性的事情,每当有一大推资料需要录入到Word文档时,我的心都快憔悴了.不过现在好了,网络上新推出了一款迅捷PDF转换成 ...
- PPT转换PDF格式怎么转换?后悔现在才知道
PPT和PDF文件大家运用的还是比较广泛的,大家在制作完一份PPT文件,为了格式不发生错乱通常将文件保存为PDF格式,接下来小编告诉大家PPT转换PDF格式怎么转换. 借助软件: ×××换器 1.大家 ...
- 图片转换成pdf格式如何转换?
图片转换成pdf格式如何转换?大家对图片格式应该不会陌生,比如JPG,JPEG,PNG,BMP,GIF,TIF等,但是大家对于PDF格式可能有人还不太了解,其实PDF是一种便携式文档文件格式,这种格式 ...
- jpg转换成pdf格式在线转换
jpg转换成pdf格式在线转换 在线JPG转换成PDF转换器是非常具有实用价值的在线工具,它可以将一些陌生的文件格式转变为我们熟悉或喜欢的格式,以符合我们的习惯.免费的在线工具,对菜鸟这些不愿意安装大 ...
- pdf格式怎么转换成word
pdf格式怎么转换成word 大家对PDF文件并不陌生,根据每个用户的不同需求,有的希望能将PDF转成Word格式,这样能够摘抄.那么什么样的软件能够转换PDF文件呢?今天笔者给大家介绍的这款软件叫做 ...
- Word文档转换PDF格式常见转换技巧汇总
时下,随着PDF文件格式的优点爆出,PDF文件已成为出版业的新宠.不过大部分工作族仍习惯使用Word文档编辑,而不适应PDF文件编辑,但在传输上又造成了一定的麻烦,这就有了"转换" ...
最新文章
- 稳定性专题 | Spring Boot 常见错误及解决方法
- python生成器使用场景桌面_Python – 如何更简洁地使用生成器?
- 如何验证自己的网络是否支持ipv6
- 近两年火热的微服务springboot不同配置文件详细讲解
- 打开多个界面_使用 Terminator 在一个窗口中运行多个终端
- 「 每日一练,快乐水题 」504. 七进制数
- Redux源码分析(一)
- 前端学习(2588):前端权限的控制思路
- c++byte数组和文件的相互转换_终于!word、excel、ppt文件相互转换技巧来了!
- 企业级软件协作,没有数据怎么人工智能?
- 关于USES_CONVERSION宏
- 鼠标hover表格头部信息出现闪烁
- 九宫格锁屏和设置密码(九点密码盘)
- 【计算机组成原理】定点乘法运算之补码一位乘法(Booth算法)(对初学者的步骤详解)
- UWP 中的各种文件路径(用户、缓存、漫游、安装……)
- 页面自动添加font标签
- 题目 1548: 盾神与砝码称重
- 移动云平台的基础架构之旅(一):云应用
- Linux系统下tmux的分屏使用
- 模拟浏览器下载Excel 到本地