kudu学习资料总结
1 , kudu 是什么 ,为什么要用kudu
2 kudu 的基本架构,概念和术语
3 kudu 的表的schema文件改如何设计
4 Kudu的java操作代码,
5 利用impala来操作kudu
6 kudu和spark的结合
1 ,kudu 是什么 ,为什么要用kudu
kudu是开发的Hadoop平台的柱状存储管理。它的商品硬件上运行,是横向扩展,并支持高可用性运行。
kudu的设计与众不同。Kudu的一些好处包括:
OLAP负载快速处理。
结合MapReduce,spark和其他的Hadoop生态系统的组成部分。
与Cloudera的Impala的紧密集成,形成了一个很好的选择,使用HDFS的Parquet
强大而灵活的一致性模型,让你选择在每个请求的基础上一致性的要求,包括严格的序列化的一致性选择。
运行顺序和随机工作负载同时强劲的性能。
易于管理和Cloudera经理管理。
高可用性。Tablet Servers and Masters use the Raft Consensus Algorithm, ,这确保只要一半以上的副本总数可用,Tablet 可用于读写。例如,如果2个副本中的3个或3个副本中有5个可用,该片剂是可用的。
结构化数据模型。
结合所有这些特性,Kudu目标的支持,是很难或不可能在当前一代的Hadoop存储技术实现应用程序的家庭。一个申请的kudu是一个伟大的解决方案的例子:
报告新到达的数据需要立即为最终用户提供的应用程序
必须同时支持的时间序列应用程序:
大量历史数据的查询
关于一个必须快速返回的实体的粒度查询
使用预测模型和周期进行实时决策,应用刷新所有基于历史数据的预测模型
2 kudu 的基本架构,概念和术语
Columnar Data Store 柱状数据存储
kudu是一种柱状数据存储。列数据存储在强类型列中存储数据.。有了适当的设计,它是优越的分析或数据仓库的工作量有几个原因。
Read Efficiency 阅读效率
对于分析查询,您可以读取单个列或该列的一部分,而忽略其他列.。这意味着您可以在读取磁盘上最少数量的块时完成查询.。使用基于行的存储,您需要读取整行,即使仅从几个列返回值.。
Data Compression 数据压缩
因为给定的列只包含一种类型的数据,所以基于schema的压缩可以比压缩混合数据类型更有效,这在基于行的解决方案中使用.。结合从列读取数据的效率,压缩允许您在读取磁盘中更少的块时实现查询.。看数据压缩
Table 表
一张Table就是你的数据存储在库杜。表具有架构和完全有序主键.。一张Table被分割成称为Tablet部分。
Tablet
tablet是table的一个连续的部分.。一个给定的tablet被复制在多个tablet上,这些副本之一被认为是领导者的tablet。任何副本可以服务读取,并要求在tablet服务tablet之间的书面要求一致。
tablet server
tablet server为客户存储和服务tablet。对于一个给定的tablet,一个tablet服务的铅片,和其他服务复制的tablet的追随者。只有领导者服务写请求,而领导者或追随者每个服务读取请求。领导者使用RAFT共识算法当选。一个tablet server可以提供多片,一个tablet可以由多个tablet server服务。
Master
master跟踪所有的tablet、tablet server、目录表和与群集相关的其他元数据.。在一个给定的时间点,只有一个表演大师(领导者)。如果当前的领导者消失,一个新的主人当选使用RAFT共识算法。
主还为客户端协调元数据操作.。例如,当创建一个新表时,客户端发送一个RPC内部主。主程序将新表的元数据写入目录表,并协调在tablet server上创建平板的过程.。
所有的主数据被存储在一个tablet,它可以被复制到所有其他候选大师。
在一个设定的时间间隔上,tablet server的心跳(默认是每秒一次)。
Raft Consensus Algorithm 筏一致性算法
kudu采用筏共识算法作为一种手段来保证容错性和一致性,既为普通片和主数据。通过筏,一个tablet的多个副本选举一个领导者,这是负责接受和复制写入追随者副本。一旦写入坚持在大多数副本,它是公认的客户端。一组给定的N副本(通常是3或5)是能够接受写入至多(N - 1)/ 2故障副本。
目录表
目录表是元数据库中心位置。它存储有关表和片剂的信息。目录表通过主客户端使用客户端API访问.。
Catalog Table
The catalog table is the central location for metadata of Kudu. It stores information about tables and tablets. The catalog table is accessible to clients via the master, using the client API.
Tables
table schemas, locations, and states
Tablets
the list of existing tablets, which tablet servers have replicas of each tablet, the tablet’s current state, and start and end keys.
Logical Replication 逻辑复制
kudu的复制操作,不在磁盘上的数据。这被称为逻辑复制,而不是物理复制.。这有几个优点:
尽管插入和更新确实在网络上传输数据,但删除不需要移动任何数据.。删除操作将发送到每个tablet server,该 server执行本地删除操作.。
物理操作,如压实,不需要在库杜的网络数据传输。这是从不同的存储系统,使用HDFS的块,需要通过网络传输完成规定数量的副本。
片不需要进行压实,同时或在同一时间,或停留在对物理存储层同步。这降低了所有tablet server在同一时间经历高延迟的机会,由于并发症或重写负载。
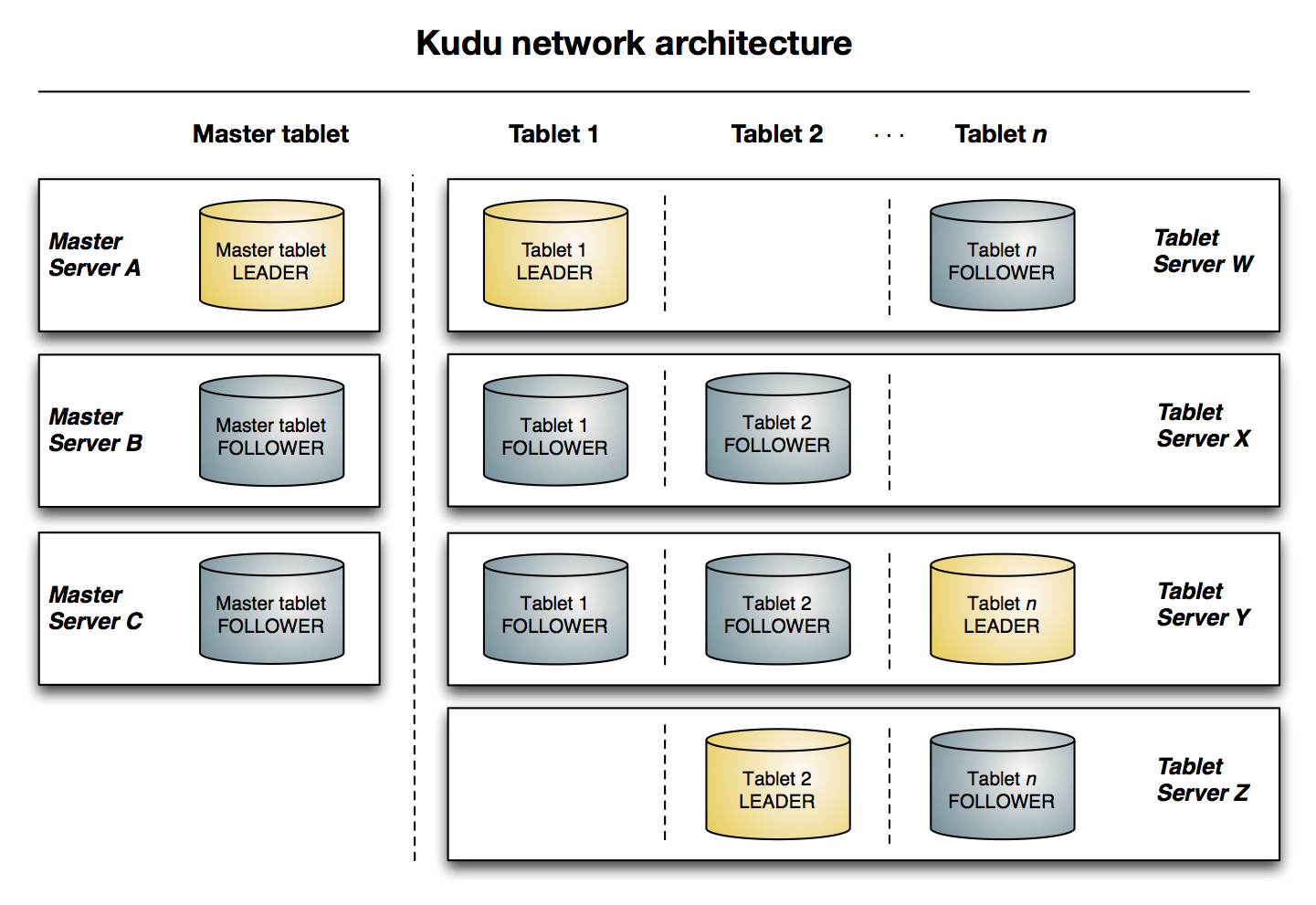
Architectural Overview
The following diagram shows a Kudu cluster with three masters and multiple tablet servers, each serving multiple tablets. It illustrates how Raft consensus is used to allow for both leaders and followers for both the masters and tablet servers. In addition, a tablet server can be a leader for some tablets, and a follower for others. Leaders are shown in gold, while followers are shown in blue.
3 kudu 的表的描述文件改如何设计
kudu表有一个结构化的数据模型类似于一个传统的RDBMS表。架构设计是实现最佳的性能和运行稳定性的关键来自库杜。每个工作负载都是唯一的,并且没有单一的架构设计是最好的每一个表。本文概述了库杜有效的架构设计理念,尤其要注意,他们不同于传统的关系数据库schema的使用方法。
在一个较高的水平,有三个问题:当创建kudu表柱设计,主键设计和分区设计。其中,只有分区将是一个新的概念,熟悉传统的非分布式关系数据库。最后一节讨论改变现有的表的架构,和已知的限制方面的架构设计。
较好的schema文件
完美的schema将完成以下内容:
数据将以这样一种方式分布,读取和写入均在tablet server上均匀传播.。这是通过分区的影响。
tablet将在一个均匀的,可预测的速度增长和负载在平板电脑将保持稳定随着时间的推移。这是最受影响的分区。
扫描将读取满足查询所需的最小数据量.。这主要是由主键设计的影响,但分区也起到了作用,通过分区修剪。
完美的schema依赖于数据的特性,你需要做什么,以及你的集群的拓扑结构.。架构设计是
最重要的事情在你的控制范围内最大限度地提高你的kudu集群性能
Column Design
表由一个或多个列,每一个定义的类型。那不是主键列可为空。支持的列类型包括:
boolean
8-bit signed integer
16-bit signed integer
32-bit signed integer
64-bit signed integer
unixtime_micros (64-bit microseconds since the Unix epoch)
single-precision (32-bit) IEEE-754 floating-point number
double-precision (64-bit) IEEE-754 floating-point number
UTF-8 encoded string
Binary
布尔
8位有符号整数
16位有符号整数
32位有符号整数
64位有符号整数
unixtime_micros(64位微秒的Unix纪元以来)
单精度(32位)IEEE-754浮点数
双精度(64位)IEEE-754浮点数
UTF-8编码的字符串
二进制的
Kudu利用强类型的列和磁盘存储格式的柱状提供高效编码和序列化。充分利用这些特点,柱应指定适当的类型,而不是模拟使用字符串或二进制列为可能是结构化的数据“无模式”的表。除了编码,Kudu允许压缩是在每一个柱的基础上指定。
Column Encoding
在一个kudu表每一列可以与编码创建,基于该列的类型。列默认使用纯编码。
|
Column Type |
Encoding |
|
int8, int16, int32 |
plain, bitshuffle, run length |
|
int64, unixtime_micros |
plain, bitshuffle |
|
float, double |
plain, bitshuffle |
|
bool |
plain, run length |
|
string, binary |
plain, prefix, dictionary |
Plain Encoding 普通的编码
数据存储在其自然格式。比如Int32值存储为固定大小的32位小端字节整数。
Bitshuffle Encoding 编码
将一个值块重新排列以存储每个值的最重要位,其次是每一个值的第二个最有效位,等等.。最后的结果是lz4压缩。bitshuffle编码是有许多重复值的列的一个很好的选择,或改变的价值由少量当按主键。的bitshuffle项目具有良好的性能和使用情况概述。
Run Length Encoding 游程长度编码
连续运行(连续重复值)仅通过存储值和计数在列中压缩.。游程长度编码对主键连续排序时具有连续重复值的列有效.。
Dictionary Encoding 字典编码
建立了唯一值字典,并将每个列值作为字典中的相应索引进行编码.。字典编码为低基数的列是有效的。如果一个给定的行集的列的值不能被压缩,因为独特的值数太高,库杜将明显回落到平原,行集编码。这是在冲洗过程中进行评估。
Prefix Encoding 前缀编码
常见的前缀在连续的列值压缩。前缀编码可以为价值观,共同的前缀是有效的,或第一列的主键,自行按主键内片。
柱压缩
kudu让每列压缩使用lz4,,或zlib压缩编解码器。默认情况下,列存储压缩。考虑使用压缩,如果减少存储空间比原始扫描性能更重要。
每个数据集的压缩方式不同,但总的来说lz4是最高效的编解码器,而zlib将压缩到最小的数据大小。bitshuffle编码列使用lz4自动压缩,所以不推荐使用在这上面附加的压缩编码。
Primary Key Design主键设计
每捻表必须声明主键索引包含一个或多个列。主键列必须是非空的,可能不是一个布尔或浮点型。一旦在表创建过程中设置,主键中的列集可能不会被更改.。像一个关系数据库的主键,主键的kudu强制唯一性约束;试图插入一行具有相同主键值的行的存在将导致重复键错误。
不像RDBMS,Kudu不提供一个自动递增列特征,所以应用必须在插入期间提供完整的主键。行的删除和更新操作也必须指定行要改变全主键;捻不原生支持范围删除或更新。在插入行后,不能更新列的主键值;但是可以删除行并重新插入更新值。
Primary Key Index 主键索引
与许多传统的关系型数据库,kudu的主键是一个聚集索引。在一个平板内的所有行都保持在主键排序顺序。kudu扫描指定平等或范围限制在主键会自动跳过不满足谓词的行。通过指定主键列的相等约束,可以有效地找到单个行.。
Partitioning 分区
为了提供可扩展性,kudu表划分为单位称为片剂,并分布在许多平板电脑服务器。一行总是属于一个平板电脑。将行分配给片的方法由表的分区决定,该表在表创建期间设置.。
选择分区策略需要了解数据模型和表的期望工作量.。对于编写繁重的工作负载,重要的是要设计的分区,这样的书面传播到平板电脑,以避免过载一个单一的平板电脑。对于涉及许多短的扫描,其中接触远程服务器占主导地位的工作负载,性能可以提高,如果所有的扫描数据位于相同的平板电脑。了解这些基本的权衡是设计一个有效的分区模式的核心。
没有默认的分区
库杜没有提供默认的分区策略创建表时。建议新的表,预计有沉重的读写工作量至少有许多平板电脑平板电脑。
Range Partitioning 范围分区
范围分区使用完全有序的范围分区键分配行.。每个分区分配的范围划分空间的一个连续的段。键必须由主键列的一个子集组成.。如果范围分区列与主键列匹配,则行的分区分区键将等于主键.。在没有哈希分区的范围分区表中,每个范围分区将对应一个。
在表创建过程中,初始分区集被指定为一组分区界限和拆分行.。对于每个绑定,将在表中创建一个范围分区.。每个拆分将两个分区划分为。如果没有指定分区界限,则表将默认为覆盖整个密钥空间的一个分区(下面和下面无界)。范围分区必须始终是非重叠的,拆分行必须位于范围分区内.。
见范围划分的例子进一步讨论范围划分。
范围分区管理
kudu允许范围分区可以动态添加和删除一个表在运行时,不影响其他分区的可用性。删除分区将删除属于分区的片,以及包含在其中的数据。后续插入到已删除的分区将失败。可以添加新分区,但不能与任何现有的分区分区重叠.。kudu允许滴加在单个事务ALTER TABLE操作任意数量的范围分区。
动态添加和丢弃范围分区对于时间序列用例是特别有用的.。随着时间的推移,范围分区可以添加到覆盖即将到来的时间范围。例如,存储事件日志的表可以在每个月开始之前添加一个月宽的分区,以便保持即将发生的事件。旧的范围分区可以被丢弃,以便有效地删除历史数据,如有必要。
Hash Partitioning 哈希分区
哈希分区通过散列值将行分配到多个桶中的一个.。在单级哈希分区表中,每个桶将对应一个。在创建表时设置桶数.。通常主键列用作散列的列,但与范围分区一样,主键列的任何子集都可以使用.。
哈希分区是一个有效的策略时,不需要有序访问表。散列分区是有效的扩频写随机片之间,这有助于减轻热点斑点和不均匀的平板电脑尺寸。
有关哈希划分的进一步讨论,请参见哈希分区示例.。
Multilevel Partitioning多级划分
kudu允许表结合在一个单一的表分区的多层次。零个或多个哈希分区级别可以与可选范围分区级别相结合.。在单个分区类型的约束之外,多级分区的唯一附加约束是,多个级别的哈希分区不能散列相同的列.。
在正确使用时,多级划分可以保留个人的分区类型的好处,同时降低各自的缺点。多层次分区表中的片总数是每个级别的分区数的乘积.。
请参见哈希和范围分区示例和哈希和哈希分区示例,以进一步讨论多级分区.。
Partition Pruning分区修剪
kudu扫描会自动跳过扫描整个分区时,可以确定该分区可以通过扫描完全过滤谓词。修剪哈希分区,扫描必须包括在每个哈希列等式谓词。要修剪范围分区,扫描必须包含范围分区列上的相等或范围谓词.。在多级分区表上的扫描可以利用独立于任意级别的分区修剪.。\
分区的例子
CREATE TABLE metrics (
host STRING NOT NULL,
metric STRING NOT NULL,
time INT64 NOT NULL,
value DOUBLE NOT NULL,
PRIMARY KEY (host, metric, time),
);
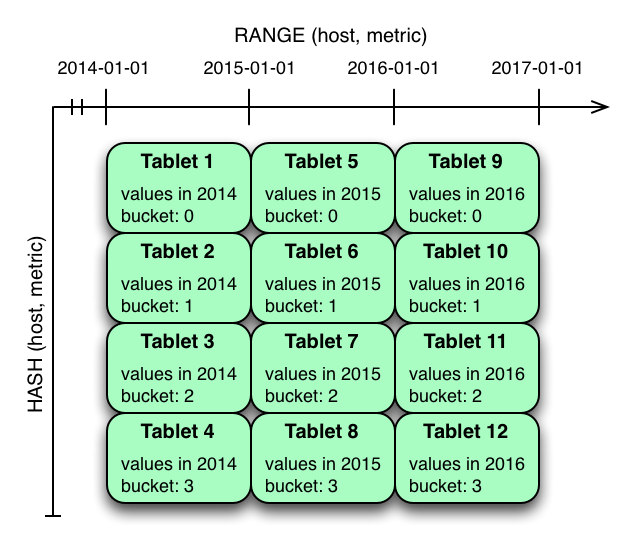
在上面的示例中,时间列上的范围分区与主机和度量列的哈希分区相结合.。这种策略可以被认为有两个维度的分区:一个哈希级别和一个范围级。写这个表的当前时间将并行到哈希桶的数目,在这种情况下,4。读取可以利用时间绑定和特定的主机和度量谓词修剪分区。可以添加新的范围分区,这将导致创建4个额外的片(如图中添加了新的列)。
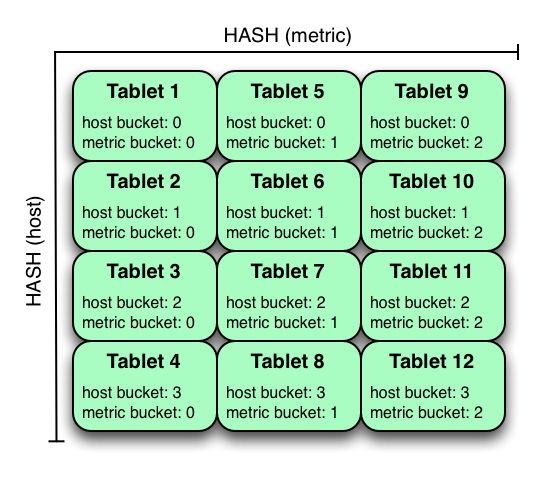
在上面的示例中,该表将主机上的哈希分区划分为4个桶,并将哈希划分为公制的3个桶,从而产生了12片.。虽然使用这种策略时,在所有的平板电脑中,书写往往会被传播,但它比在多个独立的列上进行哈希划分时更容易出现热点问题,因为单个主机或度量值的所有值总是属于一个单独的平板.。扫描可以利用相等的谓词在主机和度量列分别修剪分区。
多层次的哈希分区也可以结合范围划分,这在逻辑上增加了分区的另一个维度.。
Schema Alterations
您可以用下列方式更改表的架构:
重命名的表
重命名、添加或删除非主键列
添加和拖放范围分区
可以在单个事务操作中组合多个更改步骤.。
重命名主键列
kudu-1626:Kudu还不支持重命名主键列。
4 Kudu的java操作代码,
详细见另外一篇博客
6 利用impala来操作kudu
kudu的整合功能
创建表
impala支持创建和删除表使用Kudu作为持久层。表遵循相同的内部/外部的方法在impala的其他表,允许灵活的数据提取和查询。
插入
可以将数据插入到Kudu表使用相同的语法和其他impala表像那些使用HDFS和HBase的持久性。
更新/删除
impala支持更新和删除SQL命令修改的行的kudu表行或作为批处理现有的数据。SQL命令的语法是选择尽可能的兼容与现有的标准。除了简单的删除或更新命令,你可以用在子查询子句指定复杂的联接。并不是所有类型的联接都被测试过。
灵活分割
类似于蜂巢的分区表,Kudu允许动态预裂表散列或范围到一个预定义的片,以分发写和均匀地分布在集群的查询。你可以通过任何数量的主键列分区,由任何数目的哈希值,并分排的可选列表。参见schema设计。
并行扫描
为了实现最高的性能在现代的硬件,用impala的库杜客户在多片并行扫描。
高效的查询
在可能的情况下,impala推下来的谓词评估到库杜,这样的谓词进行尽可能的数据。查询性能与许多工作量拼花
内部和外部的impala表
创建一个新的使用Impala表时,您可以创建表的一个内部或外部表表。
内部
内表是由impala,当你把它从impala、数据和表格真正落。当你创建一个新表使用的impala,它通常是一个内部表。
外部
外部表(由创建外部表)不是由impala,把这样一个表不从其源位置删除表(在这里,Kudu)。相反,它只是删除了impala和库杜之间的映射。这是用在了捻为现有的表映射到impala的语法模式。
CREATE TABLE 创建表
CREATE DATABASE impala_kudu;
USE impala_kudu;
CREATE TABLE my_first_table
(
id BIGINT,
name STRING
)
DISTRIBUTE BY HASH INTO 16 BUCKETS
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'my_first_table',
'kudu.master_addresses' = 'kudu-master.example.com:7051',
'kudu.key_columns' = 'id'
);
storage_handler
由impala用来确定数据源类型的机制。对于角羚表,这一定是com.cloudera.kudu.hive.kudustoragehandler。
kudu.table_name
impala将创建的表的名称(或图)库杜。
kudu.master_addresses
捻角羚羚羊清单应与大师。
kudu.key_columns
逗号分隔的主键列清单,其内容不应为空。
CREATE TABLE AS SELECT 创建表,数据来自另外一张表
CREATE TABLE new_table
DISTRIBUTE BY HASH INTO 16 BUCKETS
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'new_table',
'kudu.master_addresses' = 'kudu-master.example.com:7051',
'kudu.key_columns' = 'ts, name'
)
AS SELECT * FROM old_table;
Pre-Splitting Tables 预分区
CREATE TABLE cust_behavior (
_id BIGINT,
salary STRING,
edu_level INT,
usergender STRING,
`group` STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
sku STRING,
rating INT,
fulfilled_date BIGINT
)
DISTRIBUTE BY RANGE (_id)
SPLIT ROWS((1439560049342),
(1439566253755),
(1439572458168),
(1439578662581),
(1439584866994),
(1439591071407))
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'cust_behavior',
'kudu.master_addresses' = 'a1216.halxg.cloudera.com:7051',
'kudu.key_columns' = '_id',
'kudu.num_tablet_replicas' = '3'
);
DISTRIBUTE BY HASH 利用hash分区
CREATE TABLE cust_behavior (
id BIGINT,
sku STRING,
salary STRING,
edu_level INT,
usergender STRING,
`group` STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
rating INT,
fulfilled_date BIGINT
)
DISTRIBUTE BY HASH INTO 16 BUCKETS
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'cust_behavior',
'kudu.master_addresses' = 'kudu-master.example.com:7051',
'kudu.key_columns' = 'id, sku'
);
Advanced Partitioning 高级的分区
CREATE TABLE customers (
state STRING,
name STRING,
purchase_count int32,
)
DISTRIBUTE BY RANGE (state, name)
SPLIT ROWS (('al', ''),
('al', 'm'),
('ak', ''),
('ak', 'm'),
...
('wy', ''),
('wy', 'm'))
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'customers',
'kudu.master_addresses' = 'kudu-master.example.com:7051',
'kudu.key_columns' = 'state, name'
);
DISTRIBUTE BY HASH and RANGE 范围分区和hash分区的联合使用
CREATE TABLE cust_behavior (
id BIGINT,
sku STRING,
salary STRING,
edu_level INT,
usergender STRING,
`group` STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
rating INT,
fulfilled_date BIGINT
)
DISTRIBUTE BY HASH (id) INTO 4 BUCKETS,
RANGE (sku)
SPLIT ROWS (('g'),
('o'),
('u'))
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'cust_behavior',
'kudu.master_addresses' = 'kudu-master.example.com:7051',
'kudu.key_columns' = 'id, sku'
);
Multiple DISTRIBUTE BY HASH Definitions hash多层级分区
CREATE TABLE cust_behavior (
id BIGINT,
sku STRING,
salary STRING,
edu_level INT,
usergender STRING,
`group` STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
rating INT,
fulfilled_date BIGINT
)
DISTRIBUTE BY HASH (id) INTO 4 BUCKETS,
HASH (sku) INTO 4 BUCKETS
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'cust_behavior',
'kudu.master_addresses' = 'kudu-master.example.com:7051',
'kudu.key_columns' = 'id, sku'
);
Inserting Single Values 插入
INSERT INTO my_first_table VALUES (99, "sarah");
INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");
INSERT and the IGNORE Keyword 插入忽略关键字
INSERT INTO my_first_table VALUES (99, "sarah");
INSERT IGNORE INTO my_first_table VALUES (99, "sarah");
Updating a Row 更新
UPDATE my_first_table SET name="bob" where id = 3;
Deleting a Row 删除
DELETE FROM my_first_table WHERE id < 3;
Rename a Table 表的重命名
ALTER TABLE my_table RENAME TO my_new_table;
Change the Kudu Master Address 改变kudu的集群地址
ALTER TABLE my_table
SET TBLPROPERTIES('kudu.master_addresses' = 'kudu-new-master.example.com:7051');
Change an Internally-Managed Table to External 把内部管理改为外部管理
ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');
Dropping a Kudu Table Using Impala 删除表
DROP TABLE my_first_table;
6 kudu和spark的结合
import org.apache.kudu.spark.kudu._
// Read a table from Kudu
val df = sqlContext.read.options(Map("kudu.master" -> "kudu.master:7051","kudu.table" -> "kudu_table")).kudu
// Query using the Spark API...
df.select("id").filter("id" >= 5).show()
// ...or register a temporary table and use SQL
df.registerTempTable("kudu_table")
val filteredDF = sqlContext.sql("select id from kudu_table where id >= 5").show()
// Use KuduContext to create, delete, or write to Kudu tables
val kuduContext = new KuduContext("kudu.master:7051")
// Create a new Kudu table from a dataframe schema
// NB: No rows from the dataframe are inserted into the table
kuduContext.createTable("test_table", df.schema, Seq("key"), new CreateTableOptions().setNumReplicas(1))
// Insert data
kuduContext.insertRows(df, "test_table")
// Delete data
kuduContext.deleteRows(filteredDF, "test_table")
// Upsert data
kuduContext.upsertRows(df, "test_table")
// Update data
val alteredDF = df.select("id", $"count" + 1)
kuduContext.updateRows(filteredRows, "test_table"
// Data can also be inserted into the Kudu table using the data source, though the methods on KuduContext are preferred
// NB: The default is to upsert rows; to perform standard inserts instead, set operation = insert in the options map
// NB: Only mode Append is supported
df.write.options(Map("kudu.master"-> "kudu.master:7051", "kudu.table"-> "test_table")).mode("append").kudu
// Check for the existence of a Kudu table
kuduContext.tableExists("another_table")
// Delete a Kudu table
kuduContext.deleteTable("unwanted_table")
转载于:https://my.oschina.net/u/269325/blog/817106
kudu学习资料总结相关推荐
- 【收藏清单】AI学习资料汇总——你想要的AI资源,这里都有
本文汇总了TinyMind站内AI资料类热门文章TOP10,欢迎大家各取所需.来源:https://www.tinymind.cn/ 1.[AI入门者必看]--人工智能技术人才成长路线图 入门AI的两 ...
- Django介绍和虚拟环境(django特点、MVC、MVT、Django学习资料)
MVT流程: 创建Django项目和应用 django-admin startproject name python manager.py startapp name 视图和ULR 视图的请求和响应 ...
- 彻底搞懂基于LOAM框架的3D激光SLAM全套学习资料汇总!
地图定位算法是自动驾驶模块的核心,而激光SLAM则是地图定位算法的关键技术,其重要性不言而喻,在许多AI产品中应用非常多(包括但不限于自动驾驶.移动机器人.扫地机等).相比于传统的视觉传感器,激光传感 ...
- 史上最全DSO学习资料
点击上方"3D视觉工坊",选择"星标" 干货第一时间送达 DSO(Direct Sparse Odometry)是一种视觉里程计方法.在SLAM领域,DSO属于 ...
- 教程 | 一文读懂自学机器学习的误区和陷阱(附学习资料)
来源:机器学习与统计学 本文约6296字,建议阅读10分钟. 本文为你指出一些自学的误区,推荐学习资料,提供客观可行的学习表并给出进阶学习的建议. 后台回复"20190426"获取 ...
- 独家 | 一文带你上手卷积神经网络实战(附数据集学习资料)
原文标题:Understanding deep Convolutional Neural Networks with a practical use-case in Tensorflow and Ke ...
- 限时删!一套目标检测、卷积神经网络和OpenCV学习资料(教程/PPT/代码)
AI 显然是最近几年非常火的一个新技术方向,从几年前大家认识到 AI 的能力,到现在产业里已经在普遍的探讨 AI 如何落地了. 计算机视觉目前在很多领域都已经实现了商业应用,从现实市场规模角度,目前人 ...
- 【干货】机器学习经典书PRML 最新 Python 3 代码实现,附最全 PRML 笔记视频学习资料...
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! 将 Bishop 大神的 PRML 称为机器学习圣经一点也不为过,该书系统地介绍了 ...
- android Fragment 学习资料推荐
为什么80%的码农都做不了架构师?>>> android Fragment 学习资料推荐:android大神 郭霖 http://blog.csdn.net/guolin_ ...
最新文章
- 「LibreOJ β Round #2」计算几何瞎暴力
- java poi excel 单元格样式_java poi批量导出excel 设置单元格样式
- [Nginx]location 指令说明
- jqprintsetup已经安装还会提示_Windows 10更新将修复困扰用户已久的循环安装问题...
- easyUI layout 中使用tabs+iframe解决请求两次方法
- 想要转人工智能,程序员该如何学习?
- 420.强密码检测器
- docx4j文档差异比较
- html5 颜色对应8进制,十进制字体颜色html代码参照表 rgb值颜色查询对照表
- 大数据可视化之医疗大数据平台
- 查找SSH Key路径
- iconfont显示小方块
- PLEASE小组KTV点歌系统简要说明
- How to update BOL entity property value via ABAP code
- python数据挖掘(1.亲和性分析)
- 特征工程——推荐系统里的特征工程
- IP地址与子网掩码计算、划分子网
- 人口压力与资本主义-----《万历十五年》读后感
- 北京二中通州分校2021高考成绩查询,速来查看!通州3所、昌平1所、门头沟1所学校2021中招计划...
- InDesign 教程之如何将颜色保存为色板?