MapReduce中的自定义多目录/文件名输出转
最近考虑到这样一个需求:
需要把原始的日志文件用hadoop做清洗后,按业务线输出到不同的目录下去,以供不同的部门业务线使用。
这个需求需要用到MultipleOutputFormat和MultipleOutputs来实现自定义多目录、文件的输出。
需要注意的是,在hadoop 0.21.x之前和之后的使用方式是不一样的:
hadoop 0.21 之前的API 中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat 和 org.apache.hadoop.mapred.lib.MultipleOutputs,而到了 0.21 之后 的API为 org.apache.hadoop.mapreduce.lib.output.MultipleOutputs ,
新版的API 整合了上面旧API两个的功能,没有了MultipleOutputFormat。
本文将给出新旧两个版本的API code。
1、旧版0.21.x之前的版本:
01
|
import java.io.IOException;
|
02
|
03
|
import org.apache.hadoop.conf.Configuration;
|
04
|
import org.apache.hadoop.conf.Configured;
|
05
|
import org.apache.hadoop.fs.Path;
|
06
|
import org.apache.hadoop.io.LongWritable;
|
07
|
import org.apache.hadoop.io.NullWritable;
|
08
|
import org.apache.hadoop.io.Text;
|
09
|
import org.apache.hadoop.mapred.FileInputFormat;
|
10
|
import org.apache.hadoop.mapred.FileOutputFormat;
|
11
|
import org.apache.hadoop.mapred.JobClient;
|
12
|
import org.apache.hadoop.mapred.JobConf;
|
13
|
import org.apache.hadoop.mapred.MapReduceBase;
|
14
|
import org.apache.hadoop.mapred.Mapper;
|
15
|
import org.apache.hadoop.mapred.OutputCollector;
|
16
|
import org.apache.hadoop.mapred.Reporter;
|
17
|
import org.apache.hadoop.mapred.TextInputFormat;
|
18
|
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
|
19
|
import org.apache.hadoop.util.Tool;
|
20
|
import org.apache.hadoop.util.ToolRunner;
|
21
|
22
|
public class MultiFile extends Configured implements Tool {
|
23
|
24
|
public static class MapClass extends MapReduceBase implements
|
25
|
Mapper<LongWritable, Text, NullWritable, Text> {
|
26
|
27
|
@Override
|
28
|
public void map(LongWritable key, Text value,
|
29
|
OutputCollector<NullWritable, Text> output, Reporter reporter)
|
30
|
throws IOException {
|
31
|
output.collect(NullWritable.get(), value);
|
32
|
}
|
33
|
34
|
}
|
35
|
36
|
// MultipleTextOutputFormat 继承自MultipleOutputFormat,实现输出文件的分类
|
37
|
38
|
public static class PartitionByCountryMTOF extends
|
39
|
MultipleTextOutputFormat<NullWritable, Text> { // key is
|
40
|
// NullWritable,
|
41
|
// value is Text
|
42
|
protected String generateFileNameForKeyValue(NullWritable key,
|
43
|
Text value, String filename) {
|
44
|
String[] arr = value.toString().split(",", -1);
|
45
|
String country = arr[4].substring(1, 3); // 获取country的名称
|
46
|
return country + "/" + filename;
|
47
|
}
|
48
|
}
|
49
|
50
|
// 此处不使用reducer
|
51
|
/*
|
52
|
* public static class Reducer extends MapReduceBase implements
|
53
|
* org.apache.hadoop.mapred.Reducer<LongWritable, Text, NullWritable, Text>
|
54
|
* {
|
55
|
*
|
56
|
* @Override public void reduce(LongWritable key, Iterator<Text> values,
|
57
|
* OutputCollector<NullWritable, Text> output, Reporter reporter) throws
|
58
|
* IOException { // TODO Auto-generated method stub
|
59
|
*
|
60
|
* }
|
61
|
*
|
62
|
* }
|
63
|
*/
|
64
|
@Override
|
65
|
public int run(String[] args) throws Exception {
|
66
|
Configuration conf = getConf();
|
67
|
JobConf job = new JobConf(conf, MultiFile.class);
|
68
|
69
|
Path in = new Path(args[0]);
|
70
|
Path out = new Path(args[1]);
|
71
|
72
|
FileInputFormat.setInputPaths(job, in);
|
73
|
FileOutputFormat.setOutputPath(job, out);
|
74
|
75
|
job.setJobName("MultiFile");
|
76
|
job.setMapperClass(MapClass.class);
|
77
|
job.setInputFormat(TextInputFormat.class);
|
78
|
job.setOutputFormat(PartitionByCountryMTOF.class);
|
79
|
job.setOutputKeyClass(NullWritable.class);
|
80
|
job.setOutputValueClass(Text.class);
|
81
|
82
|
job.setNumReduceTasks(0);
|
83
|
JobClient.runJob(job);
|
84
|
return 0;
|
85
|
}
|
86
|
87
|
public static void main(String[] args) throws Exception {
|
88
|
int res = ToolRunner.run(new Configuration(), new MultiFile(), args);
|
89
|
System.exit(res);
|
90
|
}
|
91
|
92
|
}
|
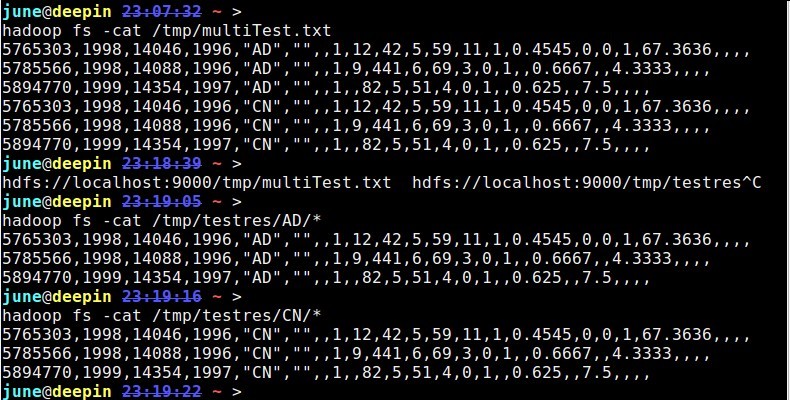
测试数据及结果:
1
|
hadoop fs -cat /tmp/multiTest.txt
|
2
|
5765303,1998,14046,1996,"AD","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,,
|
3
|
5785566,1998,14088,1996,"AD","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,,
|
4
|
5894770,1999,14354,1997,"AD","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,
|
5
|
5765303,1998,14046,1996,"CN","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,,
|
6
|
5785566,1998,14088,1996,"CN","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,,
|
7
|
5894770,1999,14354,1997,"CN","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,
|
from:
MultipleOutputFormat Example
http://mazd1002.blog.163.com/blog/static/665749652011102553947492/
2、新版0.21.x及之后的版本:
01
|
public class TestwithMultipleOutputs extends Configured implements Tool {
|
02
|
03
|
public static class MapClass extends Mapper<LongWritable,Text,Text,IntWritable> {
|
04
|
05
|
private MultipleOutputs<Text,IntWritable> mos;
|
06
|
07
|
protected void setup(Context context) throws IOException,InterruptedException {
|
08
|
mos = new MultipleOutputs<Text,IntWritable>(context);
|
09
|
}
|
10
|
11
|
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
|
12
|
String line = value.toString();
|
13
|
String[] tokens = line.split("-");
|
14
|
15
|
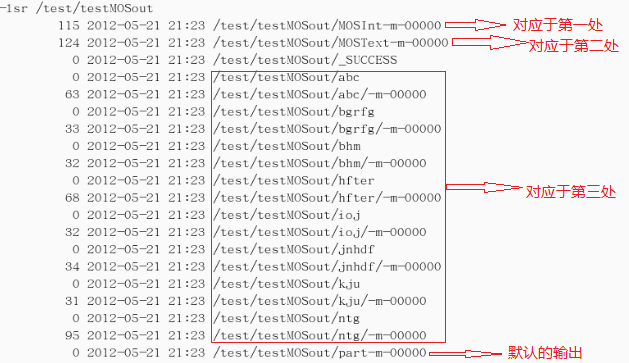
mos.write("MOSInt",new Text(tokens[0]), new IntWritable(Integer.parseInt(tokens[1]))); //(第一处)
|
16
|
mos.write("MOSText", new Text(tokens[0]),tokens[2]); //(第二处)
|
17
|
mos.write("MOSText", new Text(tokens[0]),line,tokens[0]+"/"); //(第三处)同时也可写到指定的文件或文件夹中
|
18
|
}
|
19
|
20
|
protected void cleanup(Context context) throws IOException,InterruptedException {
|
21
|
mos.close();
|
22
|
}
|
23
|
24
|
}
|
25
|
public int run(String[] args) throws Exception {
|
26
|
27
|
Configuration conf = getConf();
|
28
|
29
|
Job job = new Job(conf,"word count with MultipleOutputs");
|
30
|
31
|
job.setJarByClass(TestwithMultipleOutputs.class);
|
32
|
33
|
Path in = new Path(args[0]);
|
34
|
Path out = new Path(args[1]);
|
35
|
36
|
FileInputFormat.setInputPaths(job, in);
|
37
|
FileOutputFormat.setOutputPath(job, out);
|
38
|
39
|
job.setMapperClass(MapClass.class);
|
40
|
job.setNumReduceTasks(0);
|
41
|
42
|
MultipleOutputs.addNamedOutput(job,"MOSInt",TextOutputFormat.class,Text.class,IntWritable.class);
|
43
|
MultipleOutputs.addNamedOutput(job,"MOSText",TextOutputFormat.class,Text.class,Text.class);
|
44
|
45
|
System.exit(job.waitForCompletion(true)?0:1);
|
46
|
return 0;
|
47
|
}
|
48
|
49
|
public static void main(String[] args) throws Exception {
|
50
|
51
|
int res = ToolRunner.run(new Configuration(), new TestwithMultipleOutputs(), args);
|
52
|
System.exit(res);
|
53
|
}
|
54
|
55
|
}
|
测试的数据:
abc-1232-hdf
abc-123-rtd
ioj-234-grjth
ntg-653-sdgfvd
kju-876-btyun
bhm-530-bhyt
hfter-45642-bhgf
bgrfg-8956-fmgh
jnhdf-8734-adfbgf
ntg-68763-nfhsdf
ntg-98634-dehuy
hfter-84567-drhuk
结果截图:(结果输出到/test/testMOSout)
MapReduce中的自定义多目录/文件名输出转相关推荐
- MapReduce中的自定义多目录/文件名输出HDFS
转载自 http://my.oschina.net/leejun2005/blog/94706 最近考虑到这样一个需求: 需要把原始的日志文件用hadoop做清洗后,按业务线输出到不同的目录下去,以供 ...
- mapreduce中设置自定义的输入类,进行文本解析(默认以tab键为分隔符)
job.setInputFormatClass(KeyValueTextInputFormat.class);//此时map端输入的键的内容为第一个tab键以左的内容,值得内容为第一个tab键以右的内 ...
- 在Module中使用自定义过滤器,来统一对站内所有请求响应的输出内容进行采集或更改。...
因项目需要,对每一个访问网站的请求要做原始数据记录,其中要包括几个要素: 1.客户端的IP 2.客户端请求的页面路径 3.客户端发出的请求头 4.服务器返回的正文内容. 在代码设计前分析了一下,前三个 ...
- Python提取文件夹中的所有文件名输出到excel
Python提取文件夹中的所有文件名输出到excel import os import openpyxldef getfilelist(dir,file_out,sheet_out):filelist ...
- 如何在 Word 中使用自定义样式生成文章目录
如何在 Word 中使用自定义样式生成文章目录 概要 本文介绍如何在 Microsoft Word 2002 和 Microsoft Office Word 2003 中使用自定义样式创建目录.在 W ...
- MapReduce中加强内容
课程大纲(MAPREDUCE详解) MapReduce快速入门 如何理解map.reduce计算模型 Mapreudce程序运行演示 Mapreduce编程规范及示例编写 Mapreduce程序运行模 ...
- mapreduce工作流程_详解MapReduce中的五大编程模型
前言 我们上一节讲了关于 MapReduce 中的应用场景和架构分析,最后还使用了一个CountWord的Demo来进行演示,关于MapReduce的具体操作.如果还不了解的朋友可以看看上篇文章:[初 ...
- python显示目录中的文件_Python中的文件和目录操作实现
Python中的文件和目录操作实现 对于文件和目录的处理,虽然可以通过操作系统命令来完成,但是Python语言为了便于开发人员以编程的方式处理相关工作,提供了许多处理文件和目录的内置函数.重要的是,这 ...
- 绒毛动物探测器:通过TensorFlow.js中的迁移学习识别浏览器中的自定义对象
目录 起点 MobileNet v1体系结构上的迁移学习 修改模型 训练新模式 运行物体识别 终点线 下一步是什么?我们可以检测到脸部吗? 下载TensorFlowJS-Examples-master ...
最新文章
- pytorch单维筛选 相乘
- 业界盘点|为什么推荐算法都开始结合图神经网络了?
- 【软件开发底层知识修炼】十四 快速学习GDB调试一 入门使用
- python在另一个函数中使用其他函数的变量_在另一个函数中访问函数的变量,如function() . var in python...
- Linux 牛书推荐:《Linux网络编程》
- Windows Server 2003成员服务器基准用户权限分配策略
- C# Random生成相同随机数的解决方案
- 修改VS2017密钥
- HUAWEI Mate40Pro解除账号忘记密码ID强制刷机鸿蒙系统激活锁能解开吗
- 解决树莓派开机黑屏不显示桌面问题
- 恭贺德林教点穴网成立
- Perfectly Secret Encryption
- 河南理工大学计算机专业几本,河南理工大学是几本?河南理工大学是985或211吗...
- 计算机人工智能应用,计算机在人工智能中的应用研究
- review代码从哪些角度_转载:CodeReview正确的姿势是什么?
- Tecplot操作记录
- 苏宁易购商品详情 API
- 从零开始之uboot、移植uboot2017.01(五、board_init_f分析)
- JavaCV依赖精简
- Web地图服务发布及运维方案