镜面反射辐照模型——不完全的翻译
首先给出PBR的反射方程:
![]()
上节教程主要解决的是漫反射部分,使用了辐照贴图(irradiance map),而这次解决的是镜面反射部分。我们通过类比解决漫反射辐照的方式来解决镜面反射辐照问题,但我们要注意的是,在解决漫反射辐照问题的时候,我们仅仅需要的是入射光线Wi,但是在解决镜面反射辐照的时候,因为双向反射分布函数:
![]()
我们需要的输入变量由入射光Wi和出射(观察)方向Wo两者同时决定,我们不能将Wi和Wo的所有组合都尝试并计算一遍来得出结果(因为性能要求太过庞大),所以我们需要一些别的方法。
Epic Games的split sum approximation(不知道怎么翻译)通过将方程分成两部分,分别计算结果再组合的方式来解决这个问题,他们将镜面反射方程变成如下形式:
![]()
对于第一部分,我们使用预过滤环境贴图(按照字面意思翻译的)来解决,并且我们把粗糙度加入进去。由于粗糙程度的增加,环境贴图需要更多的离散采样向量和更多的模糊反射。对于每一个粗糙度等级,我们将其连续的模糊结果储存在预过滤贴图的mipmap等级中(不熟悉mipmap的可以先去了解一下mipmap的作用)。如下例所示:我们将5个不同模糊等级的结果存储在5个mipmap等级的贴图中。

我们通过获得双向反射分布函数(BRDF)中的输入变量——法线和观察方向及其正态分布函数来生成采样向量和散射强度。但是在这之前,我们无法获取观察向量(因为我们还没有真正绘制物体,现在只是在预处理环境贴图),Epic Games为了解决这个问题,让观察方向总是等于Wo,即下列代码:
vec3 N = normalize(WorldPos);
vec3 R = N;
vec3 V = R;这么做使我们无法得到较好的结果,但是其代价也是可以接受的。

对于方程的第二部分,该部分就是双向反射分布函数(BRDF)的镜面反射积分。如果我们假设每个方向的入射光的颜色是白的(即L(p,x)=1.0),在给出粗糙度和法线n与光向量Wi的夹角的情况下,我们可以预计算双向反射分布函数(BRDF)的返回值。Epic Games 会根据每个法线n与光向量Wi的组合以及粗糙度来存储一个值到2D的查找纹理当中(LUT),这个贴图也叫做BRDF积分贴图。这个2D查找纹理输出一个scale(不知道这里应该怎么翻译,对应于图片的红色分量)和一个偏移值(绿色分量)为菲涅尔方程提供参数(不知道这里翻译的对不对),最终会给予我们第二部分的镜面反射积分:

我们生成的这个查找纹理的水平分量代表BRDF的输入n*Wi,竖直分量则是输入的粗糙度。当我们拥有BRDF积分贴图和预过滤环境贴图后,我们可以将两者合并,并得到镜面积分结果:
float lod = getMipLevelFromRoughness(roughness);
vec3 prefilteredColor = textureCubeLod(PrefilteredEnvMap, refVec, lod);
vec2 envBRDF = texture2D(BRDFIntegrationMap, vec2(roughness, ndotv)).xy;
vec3 indirectSpecular = prefilteredColor * (F * envBRDF.x + envBRDF.y) 一、预过滤HDR环境贴图
预过滤一个环境贴图与我们卷积一个辐照贴图十分相似。其不同之处在于,我们现在要解释(account)粗糙度并且在预过滤贴图的mipmap等级中存储连续的粗糙反射。(原文:Pre-filtering an environment map is quite similar to how we convoluted an irradiance map. The difference being that we now account for roughness and store sequentially rougher reflections in the pre-filtered map’s mip levels.)
第一步,我们需要生成一个新的立方体贴图来保存预过滤环境贴图的数据。为了确保我们能够分配足够的空间给mipmap等级,我们使用 glGenerateMipmap这个函数:
unsigned int prefilterMap;
glGenTextures(1, &prefilterMap);
glBindTexture(GL_TEXTURE_CUBE_MAP, prefilterMap);
for (unsigned int i = 0; i < 6; ++i)
{glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, GL_RGB16F, 128, 128, 0, GL_RGB, GL_FLOAT, nullptr);
}
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);glGenerateMipmap(GL_TEXTURE_CUBE_MAP);注意,因为我们计划在预过滤贴图的mipmap中采样,你需要保证它的缩小过滤参数是GL_LINEAR_MIPMAP_LINEAR,确保是线性过滤。我们将预过滤镜面反射光的数据存储在一张mipmap等级为0时大小为128*128的贴图中。
在前一个教程中,我们通过使用球面坐标系并在半球体Ω中生成采样向量来对环境贴图进行卷积。当然这种方式只适合辐照贴图,对于镜面反射它并不是很起作用。对于镜面反射,它受限于表面的粗糙程度,灯光的反射会非常聚集或发散(看图):

我们将上图中以绿线包裹起来的部分称之为specular lobe(我就叫它镜叶了( •̀ ω •́ )y)。随着粗糙度的增加,镜叶的大小也会增加,镜叶的形状则随着入射光线的改变而改变。不过镜叶的形状最主要还是取决于物体的材质。
对于微平面模型,当给出入射光线方向后,我们就能得到微平面的半程向量,从而我们可以想象出镜叶的大题反射方向(原文:When it comes to the microsurface model, we can imagine the specular lobe as the reflection orientation about the microfacet halfway vectors given some incoming light direction.)。正如我们所看到的,大部分光线都在以微平面半程向量为基础的镜叶中,这就告诉我们应该如何生成采样向量,而这个过程被命名为重要性采样。(原文:Seeing as most light rays end up in a specular lobe reflected around the microfacet halfway vectors it makes sense to generate the sample vectors in a similar fashion as most would otherwise be wasted. This process is known as importance sampling.)
蒙特卡洛积分与重要性采样
为了完全理解重要性采样,我们要先钻研蒙特卡洛积分。蒙特卡洛积分主要出现在统计和概率学理论中。
举一个例子:假如你想统计某个国家公民的平均身高。为了得到你的答案,你可以测量每个人的身高并取平均值最后得到十分准确的答案。当然,这种方法十分耗时耗力,所以我们会采取更为方便但结果不是很精确的方法。
我们可以在这些人口中完全随机的测量一定人数的身高并获得平均结果。人数可以小到只测量100人的身高。这样你可得到一个比较准确的结果,这被称之为大数定律。具体而言就是,只要做到真正的随机选取一个集合中的子集合进行测量,你就能得到非常接近最终答案的答案,而答案的精确度随着子集合的大小而增加。(原文:A different approach is to pick a much smaller completely random (unbiased) subset of this population, measure their height and average the result. This population could be as small as a 100 people. While not as accurate as the exact answer, you’ll get an answer that is relatively close to the ground truth. This is known as the law of large numbers. The idea is that if you measure a smaller set of size N of truly random samples from the total population, the result will be relatively close to the true answer and gets closer as the number of samples N increases.)
蒙特卡洛积分建立在这个大数定律的基础之上,并且使用同样的方法来解决积分。不使用所有可能的采样值X来计算积分,而是生成几个随机采样值N来解决积分。随着N的增加我们会获得更加接近准确答案的结果:(原文:Monte Carlo integration builds on this law of large numbers and takes the same approach in solving an integral. Rather than solving an integral for all possible (theoretically infinite) sample values xx, simply generate N sample values randomly picked from the total population and average. As N increases we’re guaranteed to get a result closer to the exact answer of the integral:)
![]()
为了解决这个积分,我们在区间a到b中随机选取N个采样向量,求它们的和并最后除以采样的数量。pdf是可能性密度函数,它告诉我们在总采样向量集合中选取某个特定的采样向量的概率。举一个例子:人群身高的pdf看起来是这个样子:
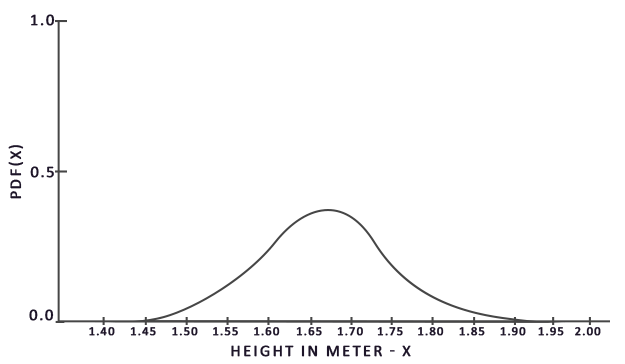
从这幅图片可以看出如果我们对人群随机采样身高,有很高的概率得到1.70,很低的概率得到1.50。
根据蒙特卡洛积分,一些采样值可能会有比其他采样值更高的生成概率。这就是为什么对于任意的蒙特卡洛估计值,我们要除以或者乘上该采样向量的概率值即pdf函数值。到目前为止,对于估算积分的每种情况,我们生成的采样都是统一的,都有相同的生成概率。我们的估计值直到现在都是公平的,这意味着给一个数量不断增长的采样,我们最终会收敛到一个准确的积分值。
当然,一些蒙特卡洛估量是不公平的,这意味着生成采样向量的时候不是完全随机的,而是聚集在某个特殊的值或方向附近。这些非公平的蒙特卡洛估量有着更快的收敛速度,这意味着它们能够非常快的收敛到准确答案,但是由于它们不公正的天性,它们并不是总能收敛到准确答案。这往往意味着需要一个可接受的权衡,特别是在计算机图形当中,准确的答案对结果并不是特别重要。
(原文:However, some Monte Carlo estimators are biased, meaning that the generated samples aren’t completely random, but focused towards a specific value or direction. These biased Monte Carlo estimators have a faster rate of convergence meaning they can converge to the exact solution at a much faster rate, but due to their biased nature it’s likely they won’t ever converge to the exact solution. This is generally an acceptable tradeoff, especially in computer graphics, as the exact solution isn’t too important as long as the results are visually acceptable. As we’ll soon see with importance sampling (which uses a biased estimator) the generated samples are biased towards specific directions in which case we account for this by multiplying or dividing each sample by its corresponding pdf.)
蒙特卡洛积分在计算机图形学中十分流行,因为它使用一种相当直观的方式来近似获取连续积分的结果:在任何地方/体积中进行采样(比如半球体Ω),生成N个随机采样,计算并权衡每个采样对最终结果的贡献。
(原文:Monte Carlo integration is quite prevalent in computer graphics as it’s a fairly intuitive way to approximate continuous integrals in a discrete and efficient fashion: take any area/volume to sample over (like the hemisphere Ω), generate N amount of random samples within the area/volume and sum and weigh every sample contribution to the final result.)
蒙特卡洛积分在数学上有着广泛的应用,在这里我们不对其细节做过多追求,但是我们要注意的是,有许多种方式来生成随机采样。在默认情况下,我们使用的是完全为随机采样,但是通过利用半随机序列的一些特性,我们可以生成一些随机的采样向量,不过会夹杂着一些有趣的性质。例如,我们可以使用一种叫做low-discrepancy sequences可以生成随机采样的序列来计算蒙特卡洛积分,但是每个采样会更加分散:
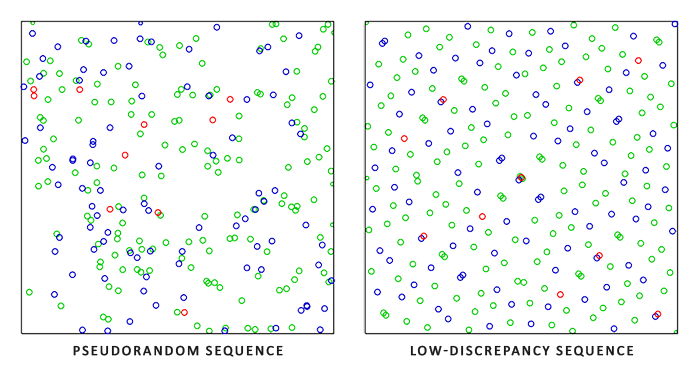
当使用low-discrepancy sequence来生成蒙特卡洛采样向量时,这个过程被称之为Quasi-Monte Carlo积分。Quasi-Monte Carlo方法有一个更快的收敛速度,使他们能够胜任大型复杂的应用。
下面是关于蒙特卡洛和Quasi-Monte Carlo的最新知识,有一个有趣的性质让我们能够更快的收敛得到结果叫做重要性采样。我们已经在这一节提到过他了,但是当用于镜面灯光反射的时候,镜面灯光反射向量会被由平面粗糙度决定大小的镜叶约束(即反射向量都在镜叶里面)。对于任意在镜叶外面的生成采样将不会对镜面反射积分产生影响,这让我们可以聚焦于镜叶中的生成采样。
(原文:Given our newly obtained knowledge of Monte Carlo and Quasi-Monte Carlo integration, there is an interesting property we can use for an even faster rate of convergence known as importance sampling. We’ve mentioned it before in this tutorial, but when it comes to specular reflections of light, the reflected light vectors are constrained in a specular lobe with its size determined by the roughness of the surface. Seeing as any (quasi-)randomly generated sample outside the specular lobe isn’t relevant to the specular integral it makes sense to focus the sample generation to within the specular lobe, at the cost of making the Monte Carlo estimator biased.)
重要性采样的本质是:通过微平面的半程向量和粗糙度来约束生成采样向量。将Quasi-Monte Carlo与low-discrepancy sequence 组合并使用重要性采样,我们能得到极高的收敛速率。为了让我们能够更快得到解,我们需要更少的采样来得到近似值。正因为如此,图形应用才能实时解决镜面反射积分,虽然这种方法相比预计算结果要慢得多。
A low-discrepancy sequence
在这片篇教程中,再给出基于Quasi-Monte Carlo 方法的一个随机low-discrepancy sequence的基础上,使用重要性采样和间接反射方程来预计算镜面反射部分。我们将要使用的序列被称之为Hammersley Sequence由Holger Dammertz发明。Hammersley sequence是基于Van Der Corpus sequence,对于10进制的van der corpus sequence来说,它的序列是:
![]()
对于二进制的van der corpus sequence来说它的序列是:
![]()
即为:
![]()
接下来我们就可以在van der corpus sequence的基础上生成Hammersley sequence了:
float RadicalInverse_VdC(uint bits)
{bits = (bits << 16u) | (bits >> 16u);bits = ((bits & 0x55555555u) << 1u) | ((bits & 0xAAAAAAAAu) >> 1u);bits = ((bits & 0x33333333u) << 2u) | ((bits & 0xCCCCCCCCu) >> 2u);bits = ((bits & 0x0F0F0F0Fu) << 4u) | ((bits & 0xF0F0F0F0u) >> 4u);bits = ((bits & 0x00FF00FFu) << 8u) | ((bits & 0xFF00FF00u) >> 8u);return float(bits) * 2.3283064365386963e-10; // / 0x100000000
}
// ----------------------------------------------------------------------------
vec2 Hammersley(uint i, uint N)
{return vec2(float(i)/float(N), RadicalInverse_VdC(i));
} 上述代码让我们可以在大小为N 的采样集合中得到low-discrepancy sample i。
注意!对于某些OpenGL版本不支持位运算,可以用下述代码:
float VanDerCorpus(uint n, uint base)
{float invBase = 1.0 / float(base);float denom = 1.0;float result = 0.0;for(uint i = 0u; i < 32u; ++i){if(n > 0u){denom = mod(float(n), 2.0);result += denom * invBase;invBase = invBase / 2.0;n = uint(float(n) / 2.0);}}return result;
}
// ----------------------------------------------------------------------------
vec2 HammersleyNoBitOps(uint i, uint N)
{return vec2(float(i)/float(N), VanDerCorpus(i, 2u));
}GGX Importance sampling
我们将使用基于表面粗糙度的微平面半程向量作为基础来生成采样向量代替原先完全随机的的蒙特卡洛生成向量。采样过程和之前见到的很像:一开始是一个大循环,生成一个随机序列值,使用序列值在切线空间中生成采样向量,转换到世界空间并采样场景的辐射。不同之处在于这次我们用的是low-discrepancy sequence的值作为生成向量的输入值:
const uint SAMPLE_COUNT = 4096u;
for(uint i = 0u; i < SAMPLE_COUNT; ++i)
{vec2 Xi = Hammersley(i, SAMPLE_COUNT); 此外,为了建立采样向量,我们需要一些方法使采样向量在镜叶中。我们可以使用NDF和GGX NDF相结合的方式:
vec3 ImportanceSampleGGX(vec2 Xi, vec3 N, float roughness)
{float a = roughness*roughness;float phi = 2.0 * PI * Xi.x;float cosTheta = sqrt((1.0 - Xi.y) / (1.0 + (a*a - 1.0) * Xi.y));float sinTheta = sqrt(1.0 - cosTheta*cosTheta);// from spherical coordinates to cartesian coordinatesvec3 H;H.x = cos(phi) * sinTheta;H.y = sin(phi) * sinTheta;H.z = cosTheta;// from tangent-space vector to world-space sample vectorvec3 up = abs(N.z) < 0.999 ? vec3(0.0, 0.0, 1.0) : vec3(1.0, 0.0, 0.0);vec3 tangent = normalize(cross(up, N));vec3 bitangent = cross(N, tangent);vec3 sampleVec = tangent * H.x + bitangent * H.y + N * H.z;return normalize(sampleVec);
} 在拥有输入的粗糙度和low-discrepancy sequenc的值Xi后,我们能够的到微平面的半程向量,既而得到采样向量。
最终的预过滤积分着色器如下:
#version 330 core
out vec4 FragColor;
in vec3 localPos;uniform samplerCube environmentMap;
uniform float roughness;const float PI = 3.14159265359f;float RadicalInverse_VdC(uint bits);
vec2 Hammersley(uint i, uint N);
vec3 ImportanceSampleGGX(vec2 Xi, vec3 N, float roughness);void main()
{ vec3 N = normalize(localPos); vec3 R = N;vec3 V = R;const uint SAMPLE_COUNT = 1024u;float totalWeight = 0.0; vec3 prefilteredColor = vec3(0.0); for(uint i = 0u; i < SAMPLE_COUNT; ++i){vec2 Xi = Hammersley(i, SAMPLE_COUNT);vec3 H = ImportanceSampleGGX(Xi, N, roughness);//半程向量vec3 L = normalize(2.0 * dot(V, H) * H - V);//反射向量float NdotL = max(dot(N, L), 0.0);if(NdotL > 0.0){prefilteredColor += texture(environmentMap, L).rgb * NdotL;totalWeight += NdotL;}}prefilteredColor = prefilteredColor / totalWeight;FragColor = vec4(prefilteredColor, 1.0);
}Capturing pre-filter mipmap levels
我们下一步要做的是让OpenGL在不同的粗糙值下预过滤环境贴图并存在不同的mipmap等级中。
prefilterShader.Use();
glUniform1i(environmentMapUniformLoc, 0);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_CUBE_MAP, envCubemap);
glUniformMatrix4fv(projectionUniformLoc, 1, GL_FALSE, glm::value_ptr(captureProjection));glBindFramebuffer(GL_FRAMEBUFFER, captureFBO);
unsigned int maxMipLevels = 5;
for (unsigned int mip = 0; mip < maxMipLevels; ++mip)
{// reisze framebuffer according to mip-level size.unsigned int mipWidth = 128 * std::pow(0.5, mip);unsigned int mipHeight = 128 * std::pow(0.5, mip);glBindRenderbuffer(GL_RENDERBUFFER, captureRBO);glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT24, mipWidth, mipHeight);glViewport(0, 0, mipWidth, mipHeight);float roughness = (float)mip / (float)(maxMipLevels - 1);glUniform1f(roughnessUniformLoc, roughness);for (unsigned int i = 0; i < 6; ++i){glUniformMatrix4fv(viewUniformLoc, 1, GL_FALSE, glm::value_ptr(captureViews[i]));glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, prefilterMap, mip);glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);renderCube();}
}
glBindFramebuffer(GL_FRAMEBUFFER, 0); 这个过程和计算辐照贴图卷积的过程很相似,但这次我们通过调整帧缓存的大小来适应mipmap规格,每个mip等级的大小比上一个的大小少2。此外,我们指定渲染的mip等级到glFramebufferTexture2D的最后的参数并且将我们正在预过滤的粗糙值传入到相应的着色器中。
(原文:The process is similar to the irradiance map convolution, but this time we scale the framebuffer’s dimensions to the appropriate mipmap scale, each mip level reducing the dimensions by 2. Additionally, we specify the mip level we’re rendering into in glFramebufferTexture2D’s last parameter and pass the roughness we’re pre-filtering for to the pre-filter shader.)
完成上述过程后,会得到一个适当预过滤贴图,这个预过滤贴图会返回比我们使用的更高等级的mip的模糊反射。如果我们将预过滤环境立方体贴图放到天空盒中并且想要进行取样的话应该这么做:
(原文:This should give us a properly pre-filtered environment map that returns blurrier reflections the higher mip level we access it from. If we display the pre-filtered environment cubemap in the skybox shader and forecefully sample somewhat above its first mip level in its shader like so:)
vec3 envColor = textureLod(environmentMap, WorldPos, 1.2).rgb; 完整结果如下:

它看起来有点像预过滤的HDR环境贴图。使用不同的mipmap等级,图片会从锐利变得越来越模糊。
Pre-filter convolution artifacts
虽然预过滤贴图在大部分情况下都会工作的很好,但是也会出现一些问题,下面会讲解并修复一些常见问题。
Cubemap seams at high roughness
一张图来表现问题所在:

从图中能够非常明显的看到立方体贴图的缝合线,我们接下来就要解决这个问题。
很简单,开启GL_TEXTURE_CUBE_MAP_SEAMLESS
glEnable(GL_TEXTURE_CUBE_MAP_SEAMLESS); Bright dots in the pre-filter convolution
由于镜面反射中有高频率细节和许多不同的光照强度,于是对镜面反射进行卷积需要大量的采样来适应HDR环境反射的不同变量。我们已经有了大量的采样,但在某些环境中数量可能还是不够的,在这种情况下,你可能会在明亮的区域看到一些点状图案:
(原文:One option is to further increase the sample count, but this won’t be enough for all environments. As described by Chetan Jags we can reduce this artifact by (during the pre-filter convolution) not directly sampling the environment map, but sampling a mip level of the environment map based on the integral’s PDF and the roughness:)

一种选项是尽可能增加采样数量,但是这不适合所有的环境。Chetan Jags剔除,我们可以通过不直接采样环境题图来解决这个问题,而是采样基于积分的PDF和粗糙度的环境贴图的mip等级:
float D = DistributionGGX(NdotH , _Roughness);
float pdf = (D * NdotH / (4. * HdotV)) + 0.0001; float resolution = 512.0; // resolution of source cubemap (per face)
float saTexel = 4.0 * PI / (6.0 * resolution * resolution);
float saSample = 1.0 / (float(SAMPLE_COUNT) * pdf + 0.0001);float mipLevel = _Roughness == 0.0 ? 0.0 : 0.5 * log2(saSample / saTexel); 不要忘记设置成线性过滤:
glBindTexture(GL_TEXTURE_CUBE_MAP, envCubemap);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR); 让OpenGL在立方体贴图的0等级mipmap纹理被载入后再生成其他的mipmap等级:
// convert HDR equirectangular environment map to cubemap equivalent
[...]
// then generate mipmaps
glBindTexture(GL_TEXTURE_CUBE_MAP, envCubemap);
glGenerateMipmap(GL_TEXTURE_CUBE_MAP);Pre-computing the BRDF
预过滤环境运行成功后,我们就可以将注意力集中在第二部分了:双向反射分布函数。
![]()
对于上面图片中的方程,我们已经将左边部分预计算。右边部分要求我们在给出N与W0的夹角、表面粗糙度和菲涅尔F0后对BRDF方程惊醒卷积。这很像当Li为1.0时对镜面BRDF进行积分。在3个变量的情况下对BRDF进行卷积十分麻烦,但是我们可以把F0移出镜面BRDF方程:
![]()
F代表的是菲涅尔方程。将菲涅尔移动到BRDF的分母上,可以得到如下方程:
![]()
我们用菲涅尔方程的近似值来代替最右边的菲涅尔方程:
![]()
让我们用α来代替(1−ωo⋅h)5(1−ωo⋅h)^5,以便于更方便的解决F0:
![]()
然后我们将其分成两部分:
![]()
接下来,我们可以把F0提到积分外面,并将α变回原来的式子:
![]()
注意!!:因为本身f(p,ωi,ωo)包含菲涅尔方程:
![]()
所以我们可以将分母上的F与其抵消~
使用一种相似的方式更早的对环境贴图进行卷积,我们可以通过BRDF方程的输入进行卷积:N与W0的夹角和粗糙度以及存储在纹理中的卷积结果。我们将卷积结果存储在一张2D查找纹理中(LUT),也被称为BRDF积分贴图,我们稍后会在PBR光照着色器中使用它来得到简介镜面反射结果。
BRDF卷积着色器对一个2D平面进行操作,使用2D纹理的坐标作为BRDF 卷积的直接输入(NdotV和粗糙度)。这部分的卷积代码与预过滤卷积代码十分的相似,不同之处是它的采样向量是根据BRDF的几何函数和菲涅尔方程近似值得到的:
vec2 IntegrateBRDF(float NdotV, float roughness)
{vec3 V;V.x = sqrt(1.0 - NdotV*NdotV);V.y = 0.0;V.z = NdotV;float A = 0.0;float B = 0.0;vec3 N = vec3(0.0, 0.0, 1.0);const uint SAMPLE_COUNT = 1024u;for(uint i = 0u; i < SAMPLE_COUNT; ++i){vec2 Xi = Hammersley(i, SAMPLE_COUNT);vec3 H = ImportanceSampleGGX(Xi, N, roughness);vec3 L = normalize(2.0 * dot(V, H) * H - V);float NdotL = max(L.z, 0.0);float NdotH = max(H.z, 0.0);float VdotH = max(dot(V, H), 0.0);if(NdotL > 0.0){float G = GeometrySmith(N, V, L, roughness);float G_Vis = (G * VdotH) / (NdotH * NdotV);float Fc = pow(1.0 - VdotH, 5.0);A += (1.0 - Fc) * G_Vis;B += Fc * G_Vis;}}A /= float(SAMPLE_COUNT);B /= float(SAMPLE_COUNT);return vec2(A, B);
}
// ----------------------------------------------------------------------------
void main()
{vec2 integratedBRDF = IntegrateBRDF(TexCoords.x, TexCoords.y);FragColor = integratedBRDF;
}正如你所看到的,BRDF卷积十分直接的将数学公司转变成代码。我们把角度 θ和粗糙度作为输入,生成重要采样向量,使用BRDF的几何和菲涅尔部分,对于每个采样输出规格和偏移值F0,最后取它们的平均值。
注意:对于IBL(辐照度模型)来说,K值和之前的直接照射有所不同:
![]()
因为BRDF卷积是镜面IBL积分的一部分,我们要使用KIBL作为Schlick-GGX geometry函数中的变量值:
float GeometrySchlickGGX(float NdotV, float roughness)
{float a = roughness;float k = (a * a) / 2.0;float nom = NdotV;float denom = NdotV * (1.0 - k) + k;return nom / denom;
}
// ----------------------------------------------------------------------------
float GeometrySmith(vec3 N, vec3 V, vec3 L, float roughness)
{float NdotV = max(dot(N, V), 0.0);float NdotL = max(dot(N, L), 0.0);float ggx2 = GeometrySchlickGGX(NdotV, roughness);float ggx1 = GeometrySchlickGGX(NdotL, roughness);return ggx1 * ggx2;
}最后,为了存储BRDF卷积结果,我们将生成一个512*512的2D纹理:
unsigned int brdfLUTTexture;
glGenTextures(1, &brdfLUTTexture);// pre-allocate enough memory for the LUT texture.
glBindTexture(GL_TEXTURE_2D, brdfLUTTexture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RG16F, 512, 512, 0, GL_RG, GL_FLOAT, 0);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); 注意:我们推荐使用16位浮点数,并确定对纹理的S和T使用GL_CLAMP_TO_EDGE。
然后我们再次使用相同的帧缓存对象并在NDC控件运行这个着色器:
glBindFramebuffer(GL_FRAMEBUFFER, captureFBO);
glBindRenderbuffer(GL_RENDERBUFFER, captureRBO);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT24, 512, 512);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, brdfLUTTexture, 0);glViewport(0, 0, 512, 512);
brdfShader.Use();
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
RenderQuad();glBindFramebuffer(GL_FRAMEBUFFER, 0); BRDF卷积部分会给你如下结果:
拥有预过滤环境贴图和BRDF2D查找贴图后,我们可以根据和的近似值来重构借鉴镜面反射积分。混合后的结果会作为间接或环境镜面光照。
Completing the IBL reflectance
最后,为了使间接镜面反射方程运行,我们需要将两部分计算结果进行缝合,注意我们通过表面粗糙度来选取合适的mip等级进行采样。让我们开始吧预计算光照数据加入到PBR着色器中:
uniform samplerCube prefilterMap;
uniform sampler2D brdfLUT; 第一步,我们通过反射向量采样预过滤环境贴图得到间接镜面反射结果。注意,我们根据表面粗糙度采样合适的mip等级,对于更粗糙的表面返回更模糊的镜面反射。
void main()
{[...]vec3 R = reflect(-V, N); const float MAX_REFLECTION_LOD = 4.0;vec3 prefilteredColor = textureLod(prefilterMap, R, roughness * MAX_REFLECTION_LOD).rgb; [...]
}在预过滤的时候,我们仅仅使用了5个mip等级来存储卷积结果,我们设置MAX_REFLECTION_LOD来确保我们不会采样到超出数据范围的地方。
然后我们用材质粗糙度和法线与观察向量的夹角作为参数,从BRDF查找纹理中采样:
vec3 F = FresnelSchlickRoughness(max(dot(N, V), 0.0), F0, roughness);
vec2 envBRDF = texture(brdfLUT, vec2(max(dot(N, V), 0.0), roughness)).rg;
vec3 specular = prefilteredColor * (F * envBRDF.x + envBRDF.y);从查找纹理得到规格和偏移量F0(这里我们直接使用间接菲涅尔结果F),我们将其与IBL反射方程的左边部分进行组合,并且重构近似积分结果。
最后我们再把漫反射部分的内容添加进来,得到完整的PBR IBL结果:
vec3 F = FresnelSchlickRoughness(max(dot(N, V), 0.0), F0, roughness);vec3 kS = F;
vec3 kD = 1.0 - kS;
kD *= 1.0 - metallic; vec3 irradiance = texture(irradianceMap, N).rgb;
vec3 diffuse = irradiance * albedo;const float MAX_REFLECTION_LOD = 4.0;
vec3 prefilteredColor = textureLod(prefilterMap, R, roughness * MAX_REFLECTION_LOD).rgb;
vec2 envBRDF = texture(brdfLUT, vec2(max(dot(N, V), 0.0), roughness)).rg;
vec3 specular = prefilteredColor * (F * envBRDF.x + envBRDF.y);vec3 ambient = (kD * diffuse + specular) * ao; 注意,我们不会将镜面反射结果与Ks相乘。
最后运行一下程序,你会得到如下结果:
![]()
![]()
镜面反射辐照模型——不完全的翻译相关推荐
- Hugging Face 每周速递: 扩散模型课程完成中文翻译,有个据说可以教 ChatGPT 看图的模型开源了...
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 基于PyTorch的Seq2Seq翻译模型详细注释介绍(一)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qysh123/article/deta ...
- 对比学习还能这样用:字节推出真正的多到多翻译模型mRASP2
AI科技评论报道 作者 | 潘小小 编辑 | 陈大鑫 大家都知道目前研究界主流的多语言翻译模型主要在英语相关的语对上进行训练.这样的系统通常在英语相关的语向(有监督语向)上表现不错,而在非英语方向(零 ...
- AI同传效果媲美人类,百度翻译出品全球首个上下文感知机器同传模型
鱼羊 发自 凹非寺 量子位 报道 | 公众号 QbitAI AI同传领域又有新进展,这次突破来自百度. 百度机器翻译团队创新性地提出了全球首个感知上下文的机器同传模型,并基于此发布了最新的语音到语音 ...
- 综述:基于GAN的图像翻译模型盘点
作者丨薛洁婷 学校丨北京交通大学硕士生 研究方向丨图像翻译 图像翻译(Image translation)是将一个物体的图像表征转换为该物体的另一种图像表征,也就是找到一个函数能让 A 域图像映射到 ...
- 对比学习还能这样用:字节推出真正的多到多翻译模型mRASP2
作者 | 潘小小 编辑 | 陈大鑫 大家都知道目前研究界主流的多语言翻译模型主要在英语相关的语对上进行训练.这样的系统通常在英语相关的语向(有监督语向)上表现不错,而在非英语方向(零资源方向)的翻译效 ...
- pytorch做seq2seq注意力模型的翻译
以下是对pytorch 1.0版本 的seq2seq+注意力模型做法语--英语翻译的理解(这个代码在pytorch0.4上也可以正常跑): 1 #-*- coding: utf-8 -*- 2 &qu ...
- NeurIPS 2022 | 能量函数指导的图图翻译扩散模型
EGSDE 扩散模型作为一种新的深度生成模型,在图像生成领域取得了 SOTA 的效果,并且逐渐在诸多应用领域展现出强大的性能,如视频生成.分子图建模等. 最近来自人民大学李崇轩课题组的研究者们提出了一 ...
- 技术美术个人笔记(六)——shading model着色模型
UE材质编辑器中预设着色模型有 下面摘取记录官方文档中较为常用的几种着色模型,在官方翻译的基础上给出自己的理解,需更详细直观的说明可参见官方文档:虚幻官方文档 文章目录 Unlit无光照/自发光 De ...
最新文章
- 我国量子计算机真假,中国半导体量子芯片研究获得突破:首次实现三量子比特逻辑门...
- cesium面积计算_cesium-长度测量和面积测量
- ElasticSearch评分分析 explian 解释和一些查询理解
- CPU 可以跑多快?地球到火星的距离告诉你!
- java接收rowtype类型_Java PhysType.getJavaRowType方法代码示例
- 蓝桥杯 ALGO-96 算法训练 Hello World!
- QT5之修改程序图标
- python顺序查找算法解释_顺序查找算法详解(包含C语言实现代码)
- linux nginx rtmp 直播,linux下利用nginx搭建rtmp直播服务
- MYSQL安装+Mysql-front 注册码
- cad直线和圆弧倒角不相切_在cad绘制倒圆角的方法技巧步骤详解
- 中国最好大学网爬取大学排名信息
- hdoj1897 SnowWolf's Wine Shop (multiset)
- ATT加入Verizon与KT的合作圈,共同开发SDN/NFV/5G
- Python批量采集某网站高清壁纸,这下不用担心没壁纸换了
- Android中WebP图片文件
- 张飞硬件MOSFET驱动电路_sdchguyi_新浪博客
- 使用nginx搭建音视频点播服务——基于DASH协议
- 通过C++类方法地址调用类的虚方法
- 北京理工大学ACM冬季培训课程之C++的应用
热门文章
- win10 安装并配置docker
- Flink SQL JSON Format 源码解析
- 99%的人都想要的广告拦截软件
- flutter web h5微信授权与支付
- mybatis-plus出错:Invalid bound statement (not found): com.kuang.mapper.UserMapper.selectList
- 用Kettle的一套流程完成对整个数据库迁移
- 新氧《2021中国医美抗衰消费趋势报告》:医美抗衰市场规模超755亿元
- sqlserver查询今日和昨日数据
- AARRR模型 | 用户留存套路与习惯养成
- 猝灭剂BHQ-1 amine/1308657-79-5/BHQ-2 氨基/1241962-11-7者相关的物理性质还是有一定的区别,整理以下相关的数据进行对比。