caffe数据集——LMDB
LMDB介紹
Caffe使用LMDB來存放訓練/測試用的數據集,以及使用網絡提取出的feature(為了方便,以下還是統稱數據集)。數據集的結構很簡單,就是大量的矩陣/向量數據平鋪開來。數據之間沒有什麼關聯,數據內沒有復雜的對象結構,就是向量和矩陣。既然數據並不復雜,Caffe就選擇了LMDB這個簡單的數據庫來存放數據。
LMDB的全稱是Lightning Memory-Mapped Database,閃電般的內存映射數據庫。它文件結構簡單,一個文件夾,裡面一個數據文件,一個鎖文件。數據隨意複製,隨意傳輸。它的訪問簡單,不需要運行單獨的數據庫管理進程,只要在訪問數據的代碼裡引用LMDB庫,訪問時給文件路徑即可。
圖像數據集歸根究底從圖像文件而來。既然有ImageDataLayer可以直接讀取圖像文件,為什麼還要用數據庫來放數據集,增加讀寫的麻煩呢?我認為,Caffe引入數據庫存放數據集,是為了減少IO開銷。讀取大量小文件的開銷是非常大的,尤其是在機械硬盤上。 LMDB的整個數據庫放在一個文件裡,避免了文件系統尋址的開銷。 LMDB使用內存映射的方式訪問文件,使得文件內尋址的開銷非常小,使用指針運算就能實現。數據庫單文件還能減少數據集複製/傳輸過程的開銷。一個幾萬,幾十萬文件的數據集,不管是直接複製,還是打包再解包,過程都無比漫長而痛苦。 LMDB數據庫只有一個文件,你的介質有多塊,就能複制多快,不會因為文件多而慢如蝸牛。
Datum數據結構
首先需要注意的是,Caffe並不是把向量和矩陣直接放進數據庫的,而是將數據通過caffe.proto裡定義的一個datum類來封裝。數據庫裡放的是一個個的datum序列化成的字符串。 Datum的定義摘錄如下:
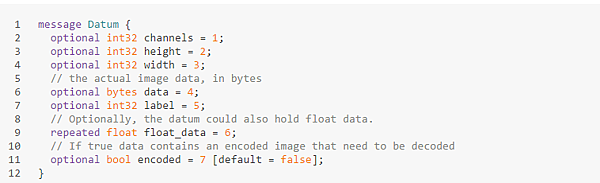
所以要使用的話 首先要用pip 下載 lmdb
由於小編已經安裝過了
所以顯示already satisfied

程式碼:
1.從 array 做出 lmdb
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
import numpy as np
import lmdb
import caffe
N = 1000
# Let's pretend this is interesting data
X = np.zeros((N, 3, 32, 32), dtype=np.uint8)
print "x shape is :",X.shape[1]
y = np.zeros(N, dtype=np.int64)
print "y shape is :",y.shape
# We need to prepare the database for the size. We'll set it 10 times
# greater than what we theoretically need. There is little drawback to
# setting this too big. If you still run into problem after raising
# this, you might want to try saving fewer entries in a single
# transaction.
map_size = X.nbytes * 10
print "map_size is:3*32*32*1000*10 --",map_size
env = lmdb.open('mylmdb', map_size=map_size)
with env.begin(write=True) as txn:
# txn is a Transaction object
for i in range(N):
datum = caffe.proto.caffe_pb2.Datum()
#set channels=3
datum.channels = X.shape[1]
#set height =32
datum.height = X.shape[2]
#set width = 32
datum.width = X.shape[3]
datum.data = X[i].tobytes() # or .tostring() if numpy < 1.9
datum.label = int(y[i])
str_id = '{:08}'.format(i)
# The encode is only essential in Python 3
txn.put(str_id.encode('ascii'), datum.SerializeToString())
|
產生的資料如下:

2.從lmdb讀取資料:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import caffe
import lmdb
lmdb_env = lmdb.open('mylmdb')
lmdb_txn = lmdb_env.begin()
lmdb_cursor = lmdb_txn.cursor()
datum = caffe.proto.caffe_pb2.Datum()
i=0
for key, value in lmdb_cursor:
i=i+1
datum.ParseFromString(value)
label = datum.label
data = caffe.io.datum_to_array(datum)
print "This is counter:",i
print "This is data: ",data.shape
print "This is label:",label,"\n"
|
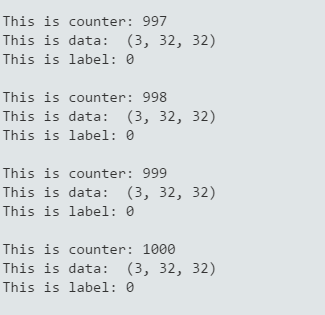
運行結果如下:
參考資料:
http://darren1231.pixnet.net/blog/post/328463403-%E5%AD%B8%E6%9C%83%E5%81%9A%E5%87%BA%E8%87%AA%E5%B7%B1%E7%9A%84%E6%95%B8%E6%93%9A%E9%9B%86%28imdb%29--caffe
http://deepdish.io/2015/04/28/creating-lmdb-in-python/
http://rayz0620.github.io/2015/05/25/lmdb_in_caffe/
https://lmdb.readthedocs.io/en/release/
http://stackoverflow.com/questions/33117607/caffe-reading-lmdb-from-python
转载于:https://www.cnblogs.com/JZ-Ser/p/7097399.html
caffe数据集——LMDB相关推荐
- Caffe︱构建lmdb数据集、binaryproto均值文件及各类难辨的文件路径名设置细解
Lmdb生成的过程简述 1.整理并约束尺寸,文件夹.图片放在不同的文件夹之下,注意图片的size需要规约到统一的格式,不然计算均值文件的时候会报错. 2.将内容生成列表放入txt文件中.两个txt文件 ...
- caffe生成lmdb数据集的脚本
#!/usr/bin/env sh set -eEXAMPLE=/home/hadoop/桌面/caffe_study/more_eyes DATA=/home/hadoop/桌面/caffe_stu ...
- caffe 提取LMDB时可能出现的错误
在深度学习的实际应用中,我们经常用到的原始数据是图片文件,如jpg,jpeg,png,tif等格式的,而且有可能图片的大小还不一致.而在caffe中经常使用的数据类型是lmdb或leveldb,因此就 ...
- Caffe:图像数据转换成ldb(leveldb/lmdb)文件
转载自:denny的学习专栏(前半部分)和 深度学习文档 在深度学习的实际应用中,我们经常用到的原始数据是图片文件,如jpg,jpeg,png,tif等格式的,而且有可能图片的大小还不一致.而在caf ...
- 利用Caffe训练模型(solver、deploy、train_val) + python如何使用已训练模型
版权声明:博主原创文章,微信公众号:素质云笔记,转载请注明来源"素质云博客",谢谢合作!! https://blog.csdn.net/sinat_26917383/article ...
- 【深度学习】Keras vs PyTorch vs Caffe:CNN实现对比
作者 | PRUDHVI VARMA 编译 | VK 来源 | Analytics Indiamag 在当今世界,人工智能已被大多数商业运作所应用,而且由于先进的深度学习框架,它非常容易部署.这些深度 ...
- SSD框架训练自己的数据集
SSD demo中详细介绍了如何在VOC数据集上使用SSD进行物体检测的训练和验证.本文介绍如何使用SSD实现对自己数据集的训练和验证过程,内容包括: 1 数据集的标注2 数据集的转换3 使用SSD如 ...
- ubuntu16.04caffe训练mnist数据集
搭好了环境,下面就该训练模型了呀!实践才是真理的唯一标准!大多数情况下,新接触caffe的小白们第一个训练的模型一定是Mnist数据集吧.这篇文章就以mnist数据集为例介绍下如何训练模型吧!(训 ...
- 利用Caffe训练模型(solver、deploy、train_val)+python使用已训练模型
本文部分内容来源于CDA深度学习实战课堂,由唐宇迪老师授课 如果你企图用CPU来训练模型,那么你就疯了- 训练模型中,最耗时的因素是图像大小size,一般227*227用CPU来训练的话,训练1万次可 ...
- seresnet50训练自己的数据集_SSD框架训练自己的数据集
SSD demo中详细介绍了如何在VOC数据集上使用SSD进行物体检测的训练和验证. 本文介绍如何使用SSD实现对自己数据集的训练和验证过程,内容包括: 1 数据集的标注 2 数据集的转换 3 使用S ...
最新文章
- linux新内核的freeze框架以及意义
- 【FPGA】SRIO IP核系统总览以及端口介绍(一)(User Interfaces 之 I/O Port)
- zabbix------监控H3C MSR路由器
- [概统]本科二年级 概率论与数理统计 第五讲 二元随机变量
- Matlab多项式回归实现
- 你应该关注的几个网站
- 实战Cisco路由器交换机各型号密码恢复
- 2019蓝桥杯省赛---java---C---1(求和)
- 我懵了,那个听起来很厉害的微内核架构是个什么鬼?
- android studio moudel,Android Studio将module变为library
- Python+OpenCV:Feature Matching + Homography to find Objects
- python必背入门代码-初学Python必背手册
- html5光标进去默认值消失,html点击input没有出现光标怎么办
- python接口自动化登录后保存个人简介_python接口自动化三(登录及发帖)
- 《JSP实用教程(第2版)/耿祥义》错误之import属性导入多个包
- C语言面向对象(下):驱动设计技巧
- 清华操作系统课程(向勇、陈渝)笔记——第十二章(一)(基本概念:文件系统和文件,文件描述符,目录,文件别名,文件系统种类)
- ECC椭圆曲线加密的特点以及在有限域(Fp)的三点共线问题
- Java学习day08--方法引用和Stream流
- 使用PHP从Access数据库中提取对象,第2部分