【word2vec】Distributed Representation——词向量
Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。
其基本想法是:
通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
为更好地理解上述思想,我们来举一个通俗的例子:假设在二维平面上分布有 N 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点,我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标 (x,y);接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词了。
上面的例子中,坐标(x,y) 的地位相当于词向量,它用来将平面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量也依赖于训练语料、训练算法和词向量长度等因素。
一种生成词向量的途径是利用神经网络算法,当然,词向量通常和语言模型捆绑在一起,即训练完后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出。 这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR 上的 A Neural Probabilistic Language Model,其后有一系列相关的研究工作。
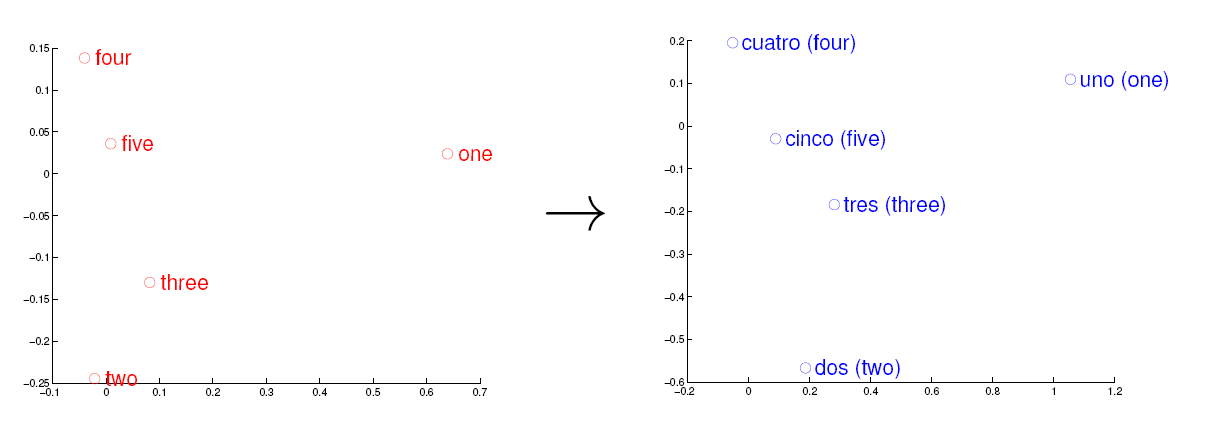
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 E 和 S。从英语中取出五个词 one,two,three,four,five,设其在 E 中对应的词向量分别为 v1,v2,v3,v4,v5,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量 u1,u2,u3,u4,u5,在二维平面上将这五个点描出来,如下图左图所示。类似地,在西班牙语中取出(与 one,two,three,four,five 对应的) uno,dos,tres,cuatro,cinco,设其在 S 中对应的词向量分别为 s1,s2,s3,s4,s5,用 PCA 降维后的二维向量分别为 t1,t2,t3,t4,t5,将它们在二维平面上描出来(可能还需作适当的旋转),如下图右图所示:
<img src="https://pic2.zhimg.com/469f845025ef071bba1a578565d8b261_b.jpg" data-rawwidth="1211" data-rawheight="445" class="origin_image zh-lightbox-thumb" width="1211" data-original="https://pic2.zhimg.com/469f845025ef071bba1a578565d8b261_r.jpg">观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
Tomas Mikolov在Google的时候发的这两篇paper:“Efficient Estimation of Word Representations in Vector Space”、“Distributed Representations of Words and Phrases and their Compositionality”。
这两篇paper中提出了一个word2vec的工具包,里面包含了几种word embedding的方法,这些方法有两个特点。一个特点是速度快,另一个特点是得到的embedding vectors具备analogy性质。analogy性质类似于“A-B=C-D”这样的结构,举例说明:“北京-中国 = 巴黎-法国”。Tomas Mikolov认为具备这样的性质,则说明得到的embedding vectors性质非常好,能够model到语义。
这两篇paper是2013年的工作,至今(2017.3),这两篇paper的引用量早已经超好几千,足以看出其影响力很大。当然,word embedding的方案还有很多
常见的word embedding的方法有:
1. Distributed Representations of Words and Phrases and their Compositionality
2. Efficient Estimation of Word Representations in Vector Space
3. GloVe Global Vectors forWord Representation
4. Neural probabilistic language models
5. Natural language processing (almost) from scratch
6. Learning word embeddings efficiently with noise contrastive estimation
7. A scalable hierarchical distributed language model
8. Three new graphical models for statistical language modelling
9. Improving word representations via global context and multiple word prototypes
word2vec中的模型至今(2017.3)还是存在不少未解之谜,因此就有不少papers尝试去解释其中一些谜团,或者建立其与其他模型之间的联系
paper list
2. Linguistic Regularities in Sparse and Explicit Word Representation
3. Random Walks on Context Spaces Towards an Explanation of the Mysteries of Semantic Word Embeddings
4. word2vec Explained Deriving Mikolov et al.’s Negative Sampling Word Embedding Method
链接:https://www.zhihu.com/question/21714667/answer/19433618
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
转载于:https://www.cnblogs.com/zeze/p/6626852.html
【word2vec】Distributed Representation——词向量相关推荐
- 基于word2vec的中文词向量训练
基于word2vec的中文词向量训练 使用katex解析的数学公式,csdn好像不支持 word2vec来源 Google开源 可以在百万数量级的词典和上亿的数据集上进行高效地训练 该工具得到的训练结 ...
- word2vec预训练词向量+通俗理解word2vec+CountVectorizer+TfidfVectorizer+tf-idf公式及sklearn中TfidfVectorizer
文章目录 文分类实(一) word2vec预训练词向量 2 数据集 3 数据预处理 4 预训练word2vec模型 canci 通俗理解word2vec 独热编码 word2vec (Continuo ...
- word2vec 构建中文词向量
2019独角兽企业重金招聘Python工程师标准>>> word2vec 构建中文词向量 词向量作为文本的基本结构--词的模型,以其优越的性能,受到自然语言处理领域研究人员的青睐.良 ...
- tfidf和word2vec构建文本词向量并做文本聚类
一.相关方法原理 1.tfidf tfidf算法是一种用于文本挖掘.特征词提取等领域的因子加权技术,其原理是某一词语的重要性随着该词在文件中出现的频率增加,同时随着该词在语料库中出现的频率成反比下降, ...
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- python自定义类如何定义向量的模_gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- word2vec如何得到词向量
word2vec是如何得到词向量的?这个问题比较大.从头开始讲的话,首先有了文本语料库,你需要对语料库进行预处理,这个处理流程与你的语料库种类以及个人目的有关,比如,如果是英文语料库你可能需要大小写转 ...
- 如何在jieba分词中加自定义词典_Pyspark Word2Vec + jieba 训练词向量流程
摘要:用商品描述为语料库训练商品词向量为例,分享一下用pyspark自带word2vec+jieba分词训练词向量的流程. 工具:python,pyspark,jieba,pandas,numpy 数 ...
最新文章
- N32-马哥Linux第一周学习
- springboot rocket 多个生产者_RabbiMQ原理与SpringBoot使用
- DataList自定义分页
- httpwatchv11.1.46.0免费版
- 安徽省二级c语言笔试样题,安徽省二级C语言程序设计笔试样题1
- 强大的.NET反编译工具Reflector及插件(转载)
- 原以为原神是米哈游的极限,看过美术总监的年番,恍然大悟!
- Swift--基本数据类型(一)
- ubuntu 系统相关
- 【转】Windows消息投递流程:WM_COMMAND消息流程
- 图片轮播器(swift)
- 对C语言实验报告的建议,c语言实验报告.docx
- ResNet网络理解
- gimp中文版教程_Gimp中文经典入门实用教程(合辑).pdf
- while在c语言中的作用,while的用法_C语言中while的用法
- 蓝桥杯算法训练——调和数列问题
- 外省职称计算机,外地职称在当地是否可以用?
- 用Python写个自动批改作业系统~
- OpenCV进阶(8)性别和年龄识别
- while [ -h “$PRG“ ] ; do 该段SHELL脚本的含义及应用