(2020)使用Airtest来爬取某宝评论数据
本帖子背景:本帖子,是一个学习的过程。一个爬取某宝评论的小单子,促使我前来学习简单的、不用掉头发的、不用爆肝的(再说,我也没那能力去硬干它啊)教程
昨天晚上,大学四年的舍友微信问我“说还搞爬虫吗,给我搞点某宝的评论数据呗,搞一些就行了,拿来做营销比赛的,做分析的”。我看到是某宝,便回复“阿里的东西不好搞,风控太厉害了,加密参数摸不着入口,晚上回去可以给你试一下,不敢保证做出来哇”
然后,我下班搞了两三个小时还没见到一点点希望,便放弃了,就回复舍友说:搞不定。
0x01、睡觉还在思考:能不能用模拟来做,网易的开源工具Airtest
0x02、早上起床,买完菜,吃完了午饭,下午才开始用Airtest搞它!!!
先给兄弟萌看点结果图呗,不然后面你们说我吹牛
![]()
0x03、Airtest最详细的入门教程
想开发网页爬虫,发现被反爬了?想对 App 抓包,发现数据被加密了?不要担心,使用 Airtest 开发 App 爬虫,只要人眼能看到,你就能抓到,最快只需要2分钟,兼容 Unity3D、Cocos2dx-*、Android 原生 App、iOS App、Windows Mobile……。
Airtest是网易开发的手机UI界面自动化测试工具,它原本的目的是通过所见即所得,截图点击等等功能,简化手机App图形界面测试代码编写工作。
爬虫开发本着天下工具为我所用,能让我获取数据的工具都能用来开发爬虫这一信念,决定使用Airtest来开发手机App爬虫。
安装和使用
由于本文的目的是介绍如何使用Airtest来开发App爬虫,那么Airtest作为测试开发工具的方法介绍将会一带而过,仅仅说明如何安装并进行基本的操作。
安装Airtest
从Airtest官网:https://airtest.netease.com下载Airtest,然后像安装普通软件一样安装即可。安装过程没有什么需要特别说明的地方。Airtest已经帮你打包好了开发需要的全部环境,所以安装完成Airtest以后就能够直接使用了。
Airtest运行以后的界面如下图所示。
连接手机
以Android手机为例,由于Airtest会通过adb命令安装两个辅助App到手机上,再用adb命令通过控制这两个辅助App进而控制手机,因此首先需要确保手机的adb调试功能是打开的,并允许通过adb命令安装App到手机上。
启动Airtest以后,把Android手机连接到电脑上,点击下图方框中的refresh ADB:
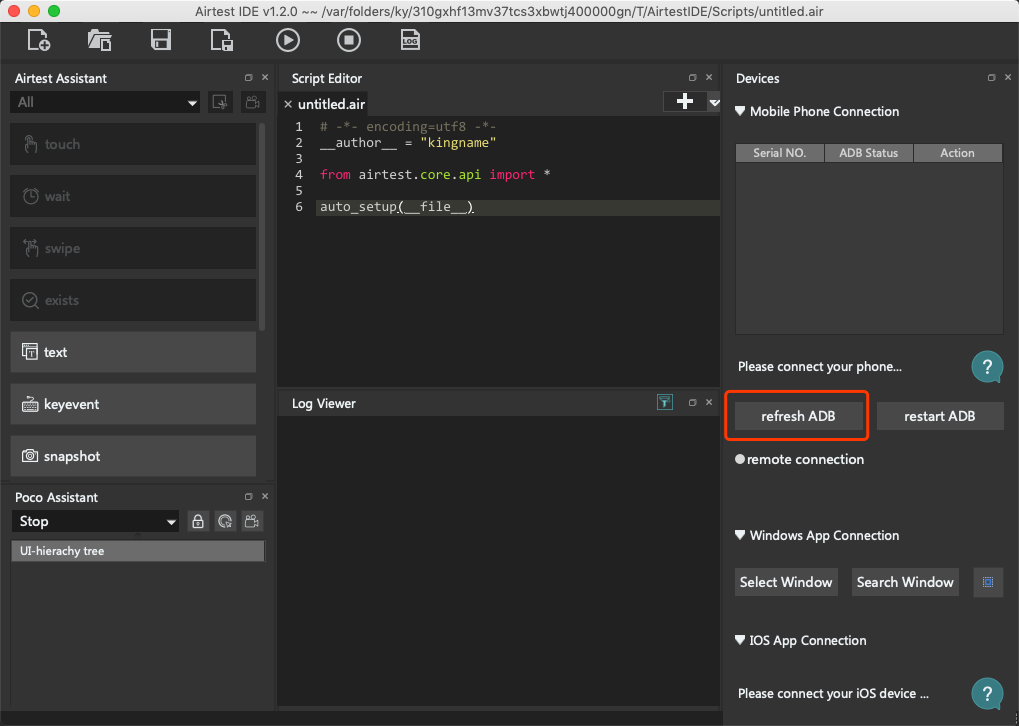
此时在Airtest界面右上角应该能够看到手机的信息,如下图所示。
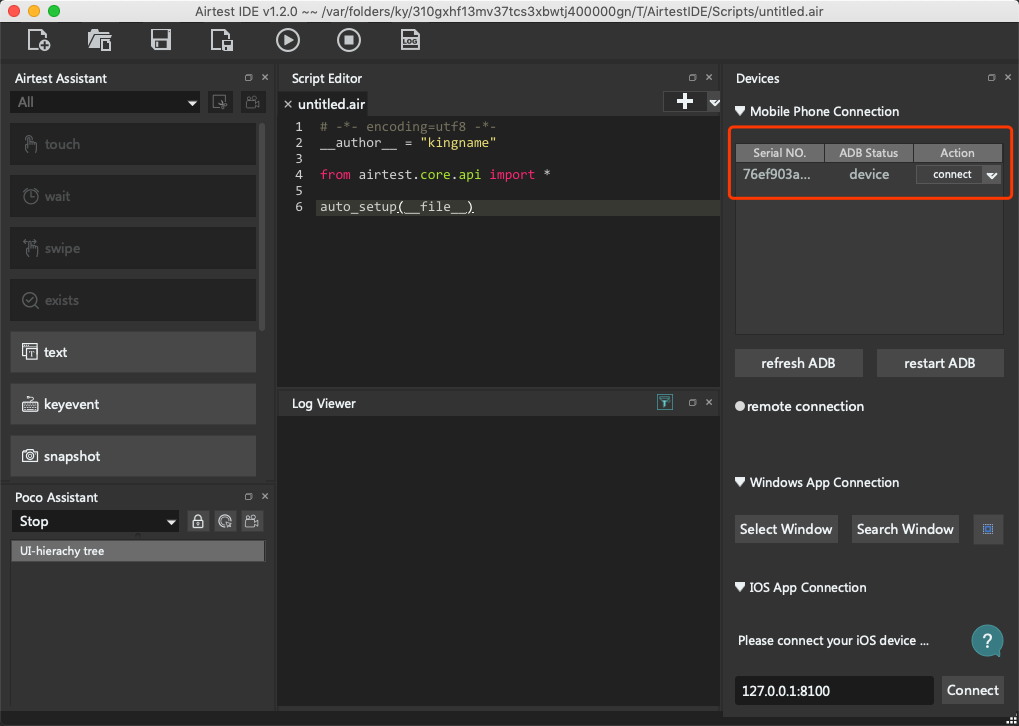
点击connect按钮,此时可以在界面上看到手机的界面,并且当你手动操作手机屏幕时,Airtest中的手机画面实时更新。如下图所示。
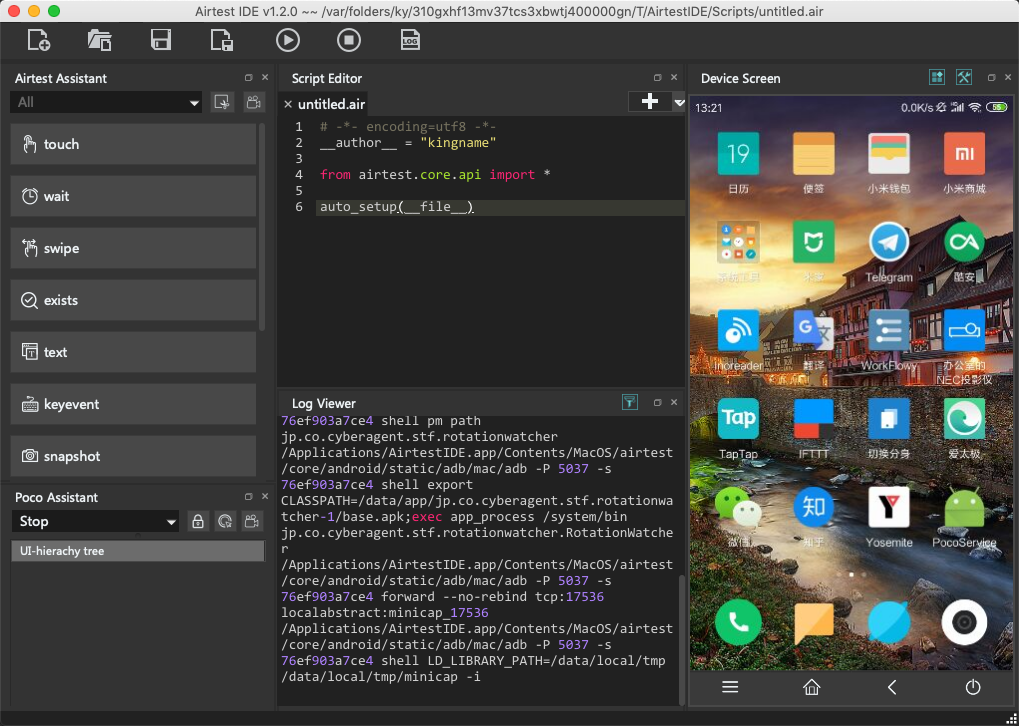
对于某些手机,例如小米,在第一次使用Airtest时,请注意手机上将会弹出提示,询问你是否允许安装App,此时需要点击允许按钮。
打开微信
先通过一个简单的例子,来看看如何快速上手Airtest,稍后再来详解。
例如我现在想使用电脑控制手机,打开微信。
此时,点击下图中方框框住的touch按钮:
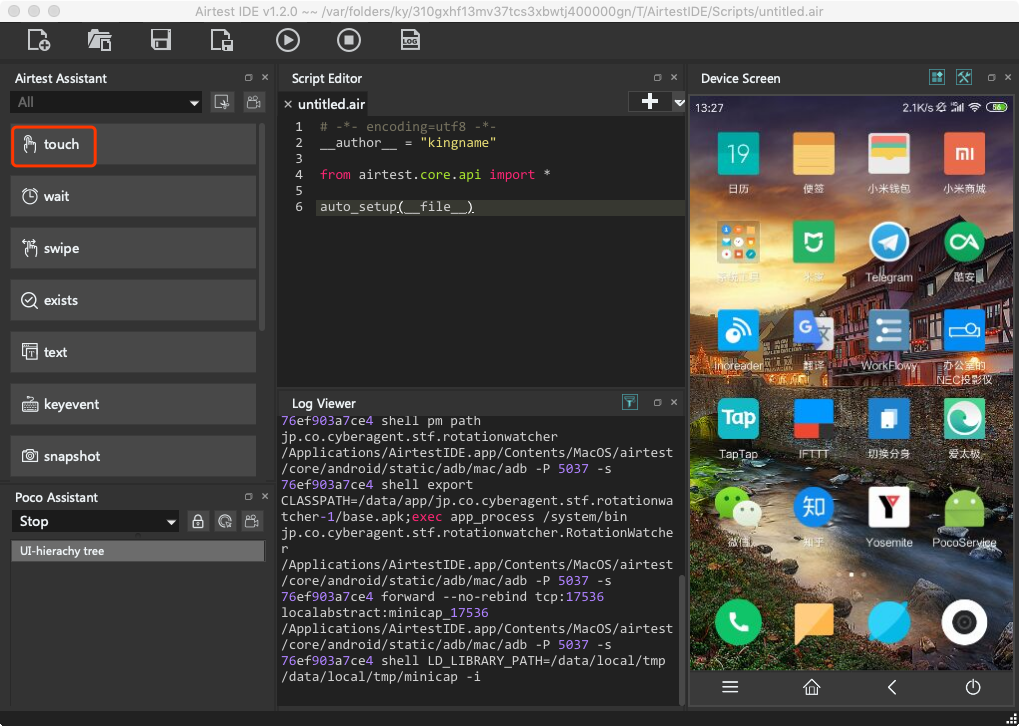
此时,把鼠标移动到Airtest右边的手机屏幕区域,鼠标会变成十字型。在微信图标的左上角按下鼠标左键不放,并拖到微信右下角松开鼠标。此时请注意中间代码区域发生了什么变化,如下图所示。
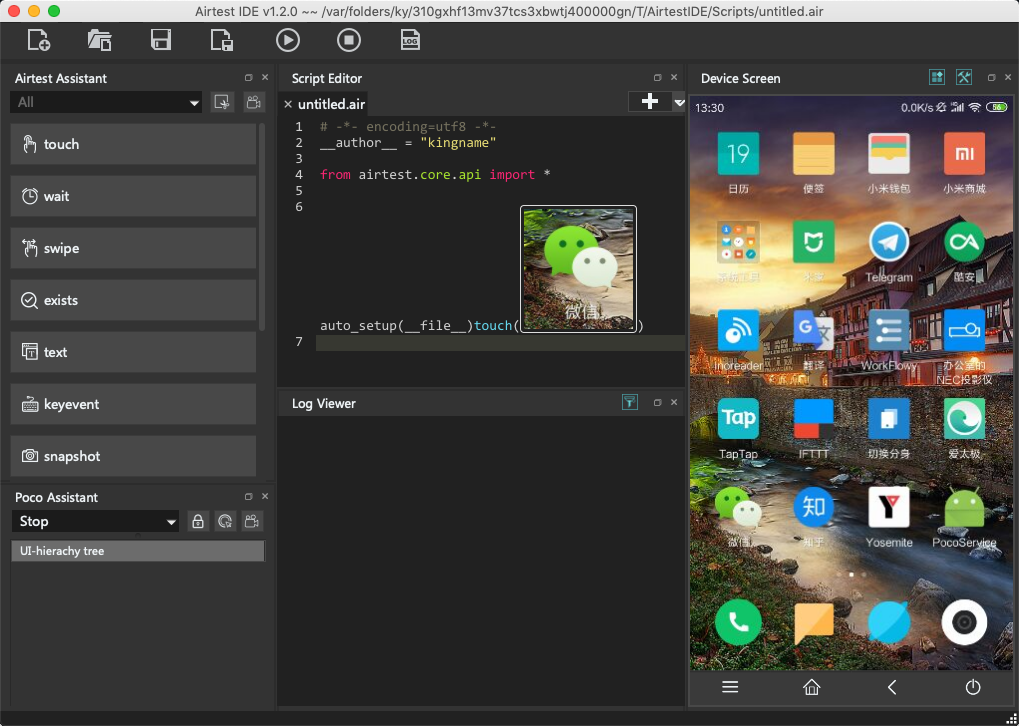
好了。以上就是你需要使用电脑打开微信所要进行的全部操作。
点击上方工具栏中的三角形图标,运行代码,如下图所示。
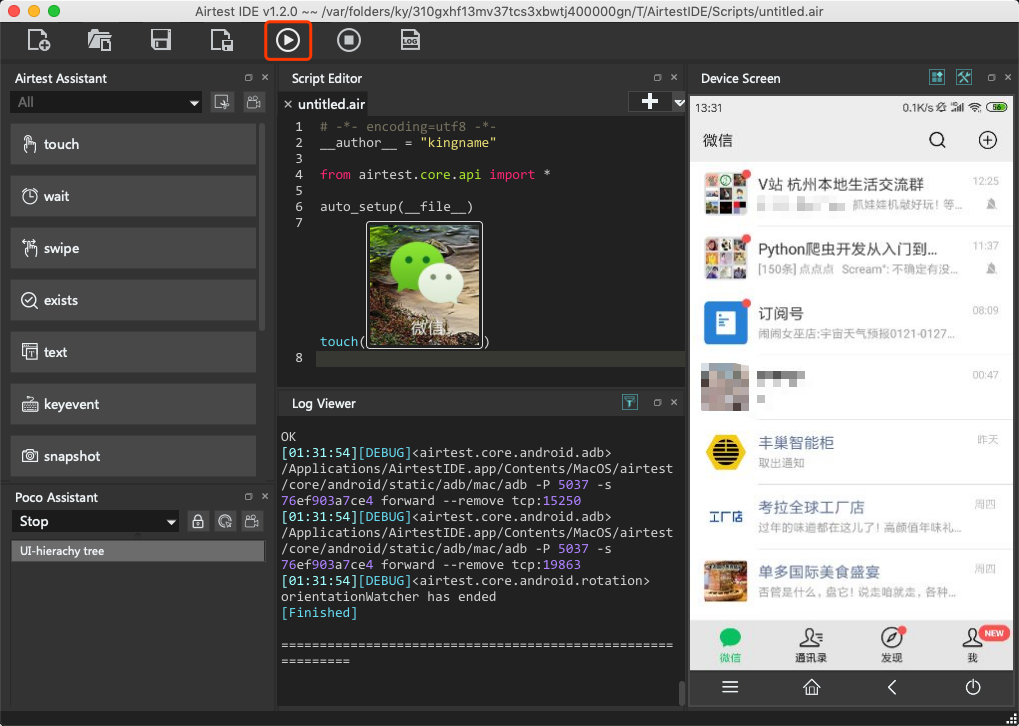
代码运行完成以后,微信被打开了。
界面介绍
在有了一个直观的使用以后,我们再来介绍一下Airtest的界面,将会更加有针对性。
Airtest的界面如下图所示。
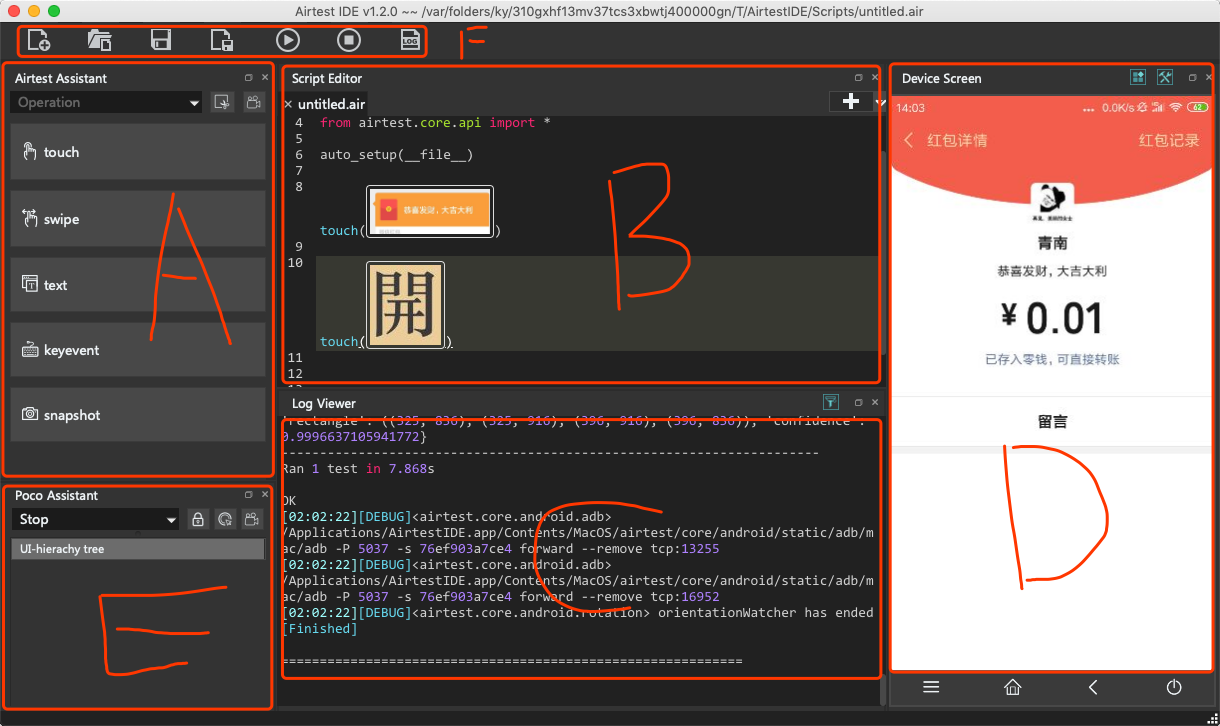
这里,我把Airtest分成了A-F6个区域,他们的功能如下:
- A区:常用操作功能区
- B区:Python代码编写区
- C区:运行日志区
- D区:手机屏幕区
- E区:App页面布局信息查看区
- F区:工具栏
A区是常用的基于图像识别的屏幕操作功能,例如:
touch: 点击屏幕元素swipe: 滑动屏幕exists: 判断屏幕元素是否存在text: 在输入框中输入文字snashot: 截图- ……
一般来说,是点击A区里面的某一个功能,然后在D区屏幕上进行框选操作,B区就会自动生成相应的操作代码。
B区用来显示和编写Python代码。在多数情况下,不需要手动写代码,因为代码会根据你在手机屏幕上面的操作自动生成。只有一些需要特别定制化的动作才需要修改代码。
D区显示了手机屏幕,当你操作手机真机时,这个屏幕会实时刷新。你也可以直接在D区屏幕上使用鼠标操作手机,你的操作动作会被自动在真机上执行。
F区是一些常用工具,从左到右,依次为:
- 新建项目
- 打开项目
- 保存项目
- 运行代码
- 停止代码
- 查看运行报告
其中1-5很好理解,那么什么是查看运行报告呢?
当你至少运行了一次以后,点击这个功能,会自动给你打开一个网页。网页如下图所示,这是你的代码的运行报告,详细到每一步操作了什么元素。
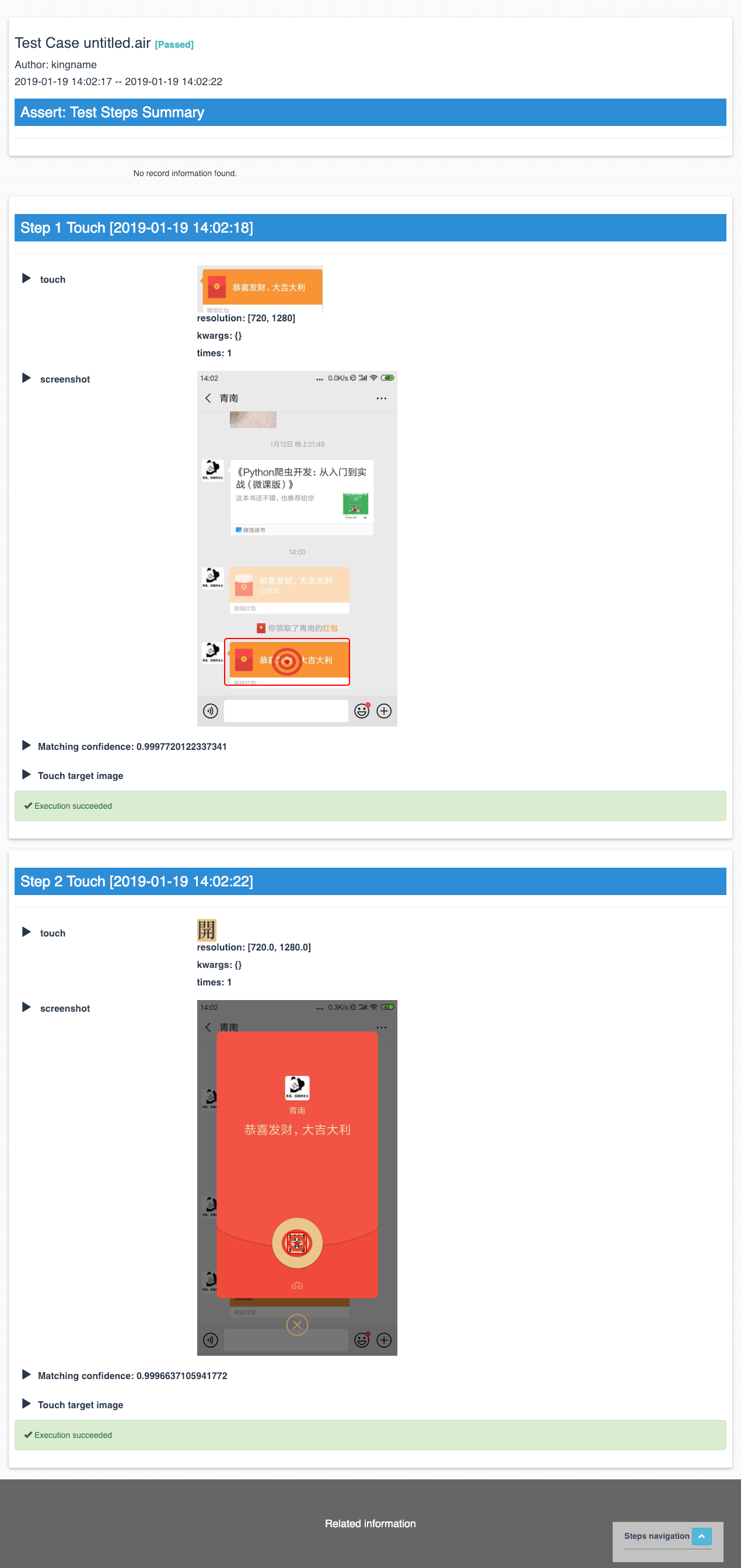
通过截图功能操作手机虽然方便,但是截图涉及到分辨率的问题,代码不能在不同的手机上通用。所以对于A区的功能,做点简单操作即可,不用深入了解。
更高级的功能,需要通过E区实现。
基于App布局信息操作手机
初始化代码
App的布局信息就像网页的HTML一样,保存了App上面各个元素的相对位置和各个参数。对于一个App而言,在不同分辨率的手机上,可能相同的元素有着不同的坐标点,但是这个元素的属性参数一般是不会变的。因此,如果使用元素的属性参数来寻找并控制这个元素,就能实现在不同分辨率手机上的精确定位。
App的布局信息的格式与App的开发环境有关。点击F区的下拉菜单,可以看到这里能够指定不同的App开发环境。其中的Unity、Cocos-*等等一般是做游戏用的,Android是安卓原生App,iOS是苹果的App……如下图所示。
以手机版知乎为例,由于它是Android原生的App,所以在F区下拉菜单选择Android,此时注意B区弹出提示,询问你是否要插入poco初始代码到当前输入光标的位置,点击Yes,如下图所示。
此时,B区自动插入了一段代码,如下图所示。
定位并点击
现在,点击E区的锁形图标,如下图所示。
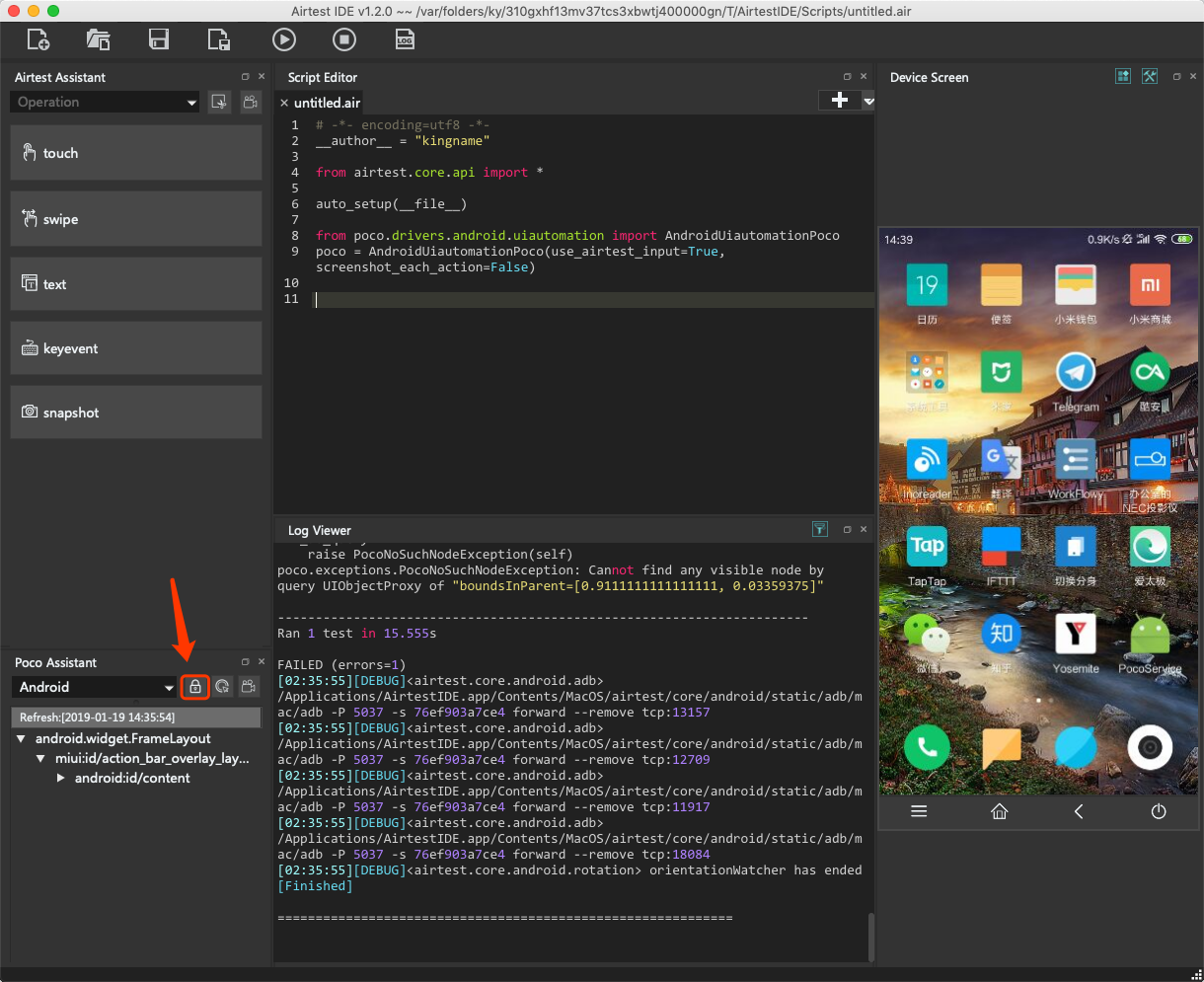
锁形图标激活以后,你再操作D区的屏幕,点击知乎App下面的知乎两个字,会发现屏幕上被点击的App并不会打开。但E区和C区却发生了变化,如下图所示。
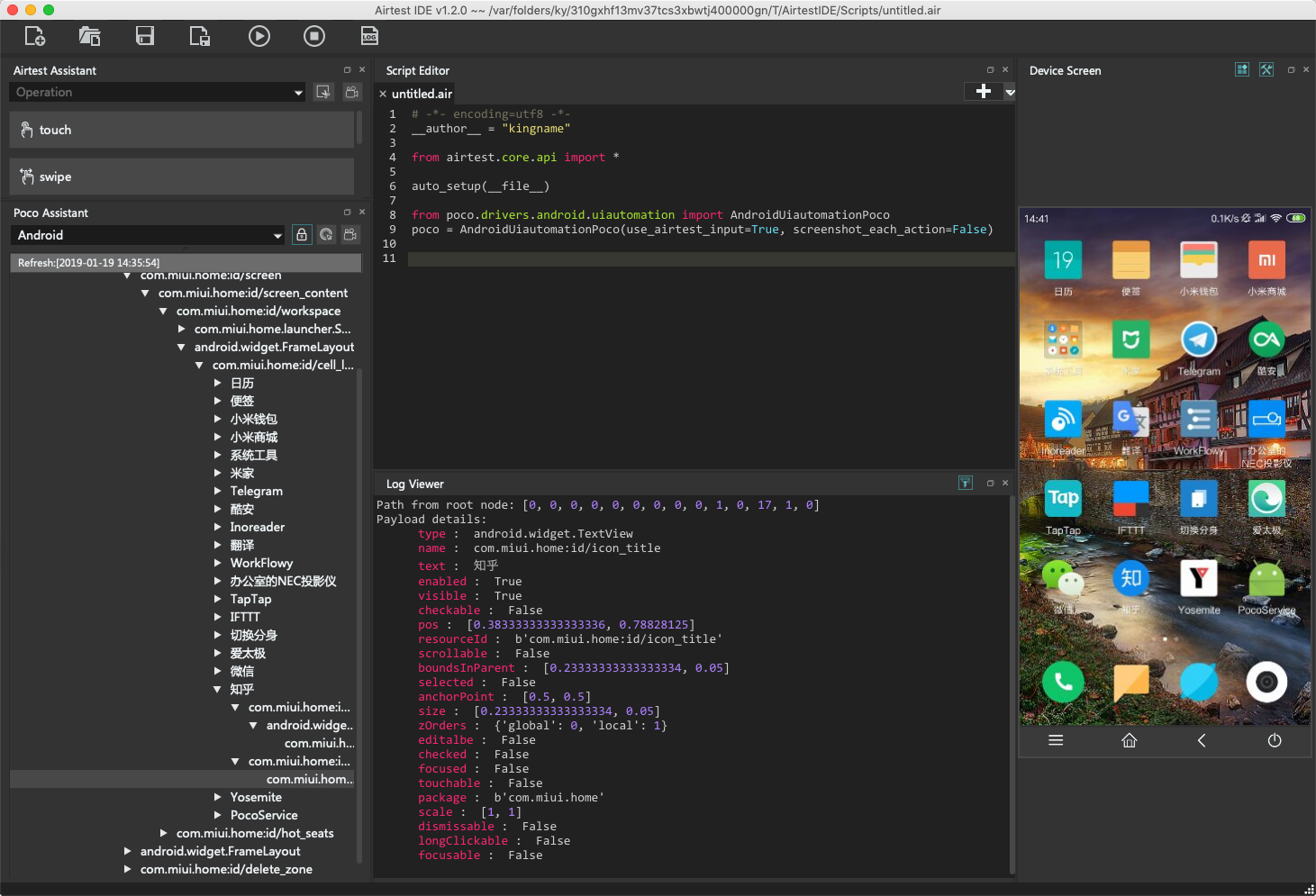
其中E区显示的树状结构就是当前屏幕的布局信息,这与Chrome开发者工具里面显示的HTML结构如出一辙。C区显示的是当前被我点中的元素的信息。
请注意在这些元素信息中,有一个text属性,它的值为知乎。那么,这个属性就可以作为一个定位元素,于是可以在B区编写代码:
|
1
|
poco(text="知乎").click()
|
写完代码以后运行程序,可以看到知乎App被打开了。如下图所示。
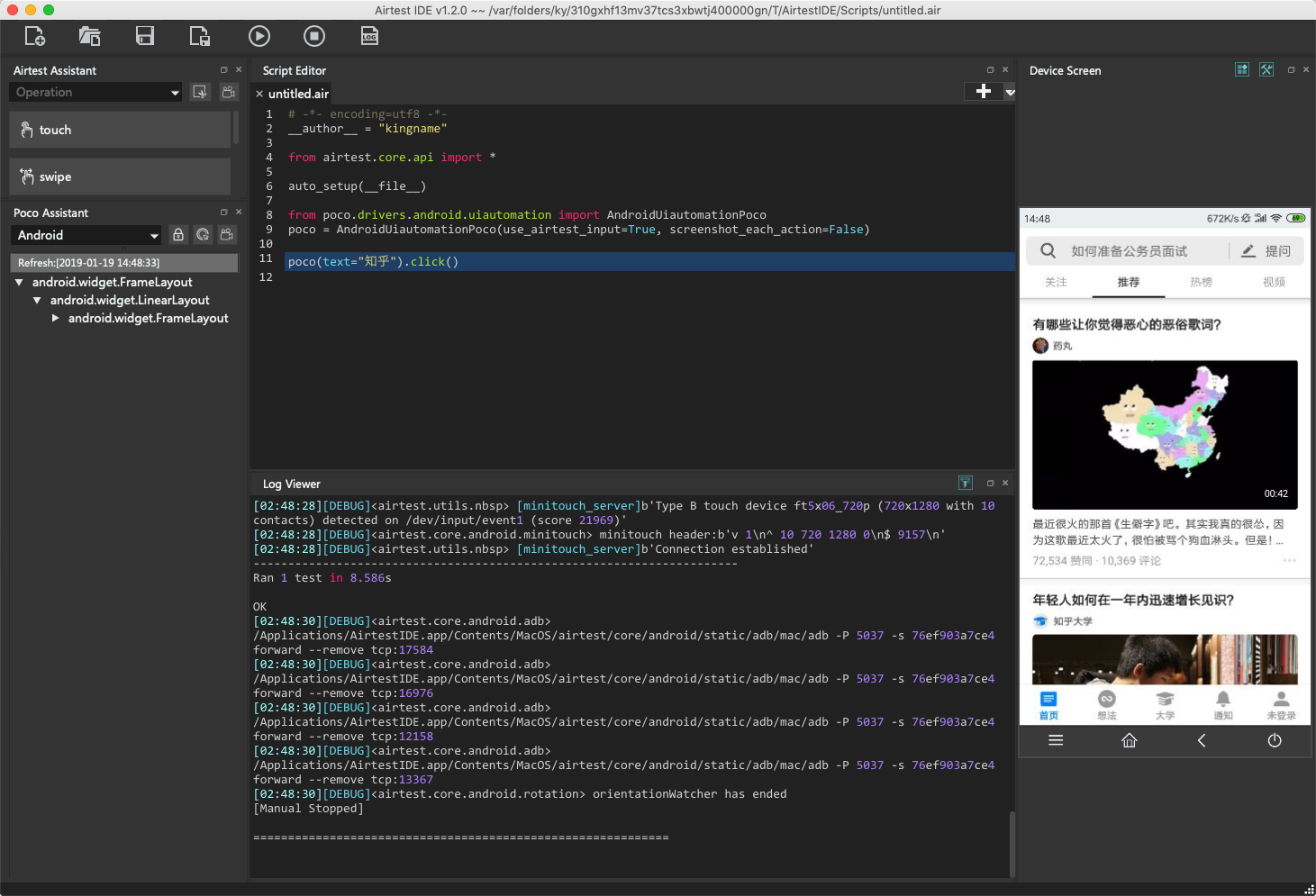
注意,如果你发现手机真机显示的界面与Airtest屏幕显示的手机界面不一致,可能是因为Airtest的屏幕被你锁定了。在F区点一下锁形图标,取消锁定,Airtest中的手机屏幕就会更新了。
定位并输入
打开知乎以后,我想使用知乎的搜索功能,那么继续,把锁形图标激活,然后点击知乎顶部的搜索框,如下图所示:
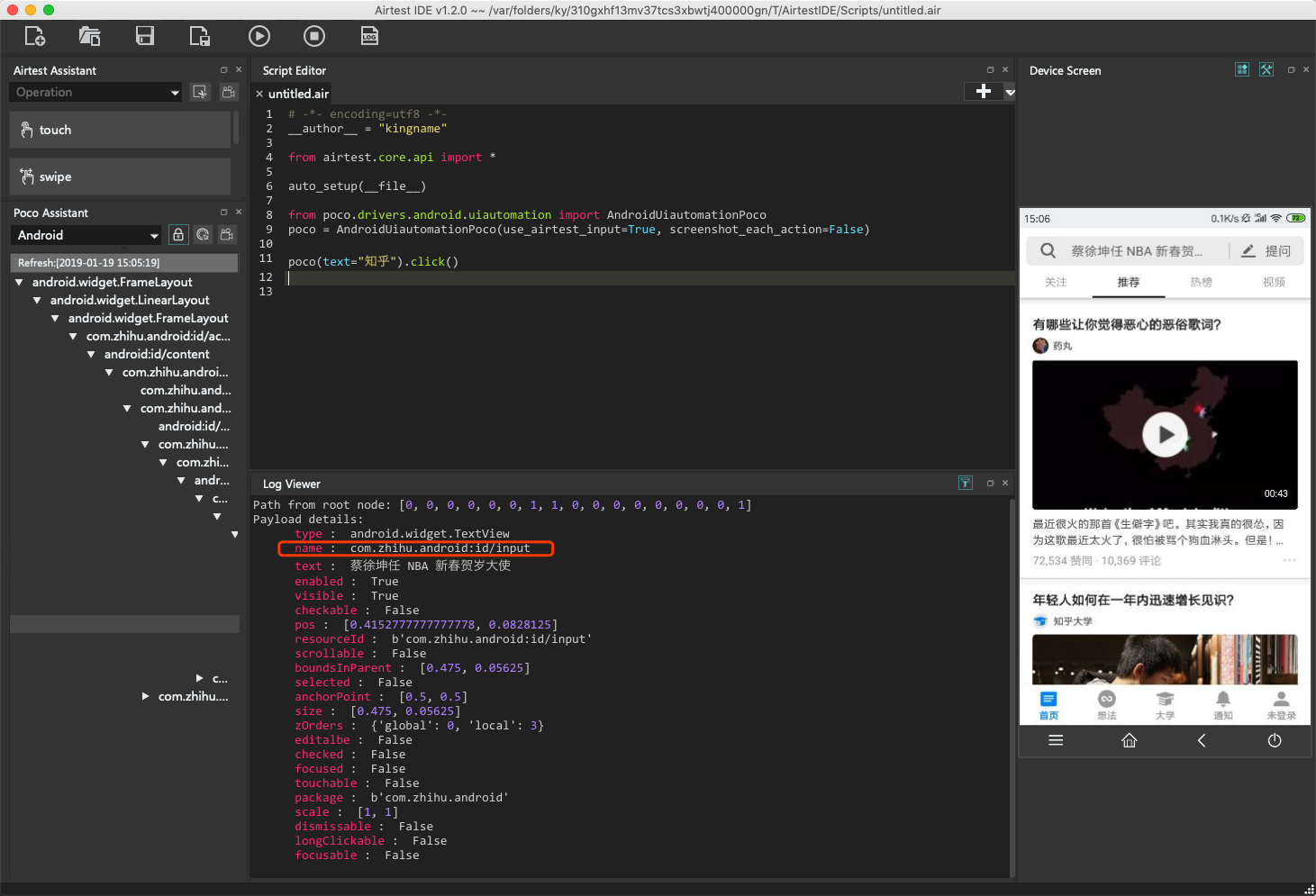
继续看C区显示的搜索框属性,可以看到这里有一个name属性,它的值是com.zhihu.android:id/input,还有一个text属性,它的值为蔡徐坤任 NBA 新春贺岁大使。能不能像前面打开知乎一样,使用text这个属性呢?也行,也不行。说它行,是因为你这么做确实现在能工作;说它不行,因为这是知乎的热门搜索关键词,随时会改变。你今天使用这一句话成功了,明天热门关键词变化了,那么你的代码就无法使用了。所以此时需要使用name这个属性。
常见的基本上不会变化的属性包含但不限于:name type resourceId package。
另外还有一点,知乎首页的这个搜索框,实际上是不能输入内容的,当你点击以后,会跳转到另一个页面,如下图所示。
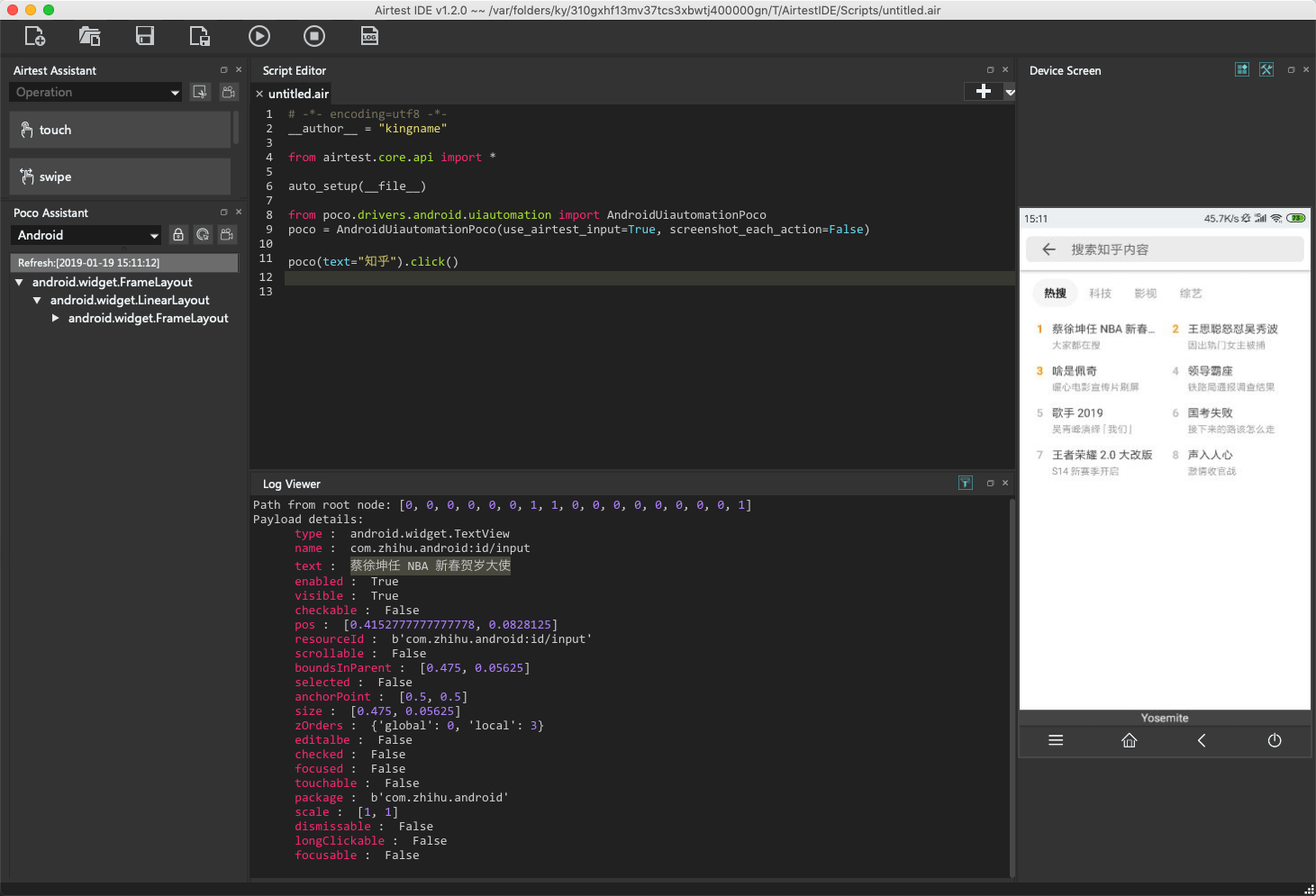
因此你需要先点击一下这个输入框,跳转到真正的搜索界面:
|
1
|
poco(name="com.zhihu.android:id/input").click()
|
在真正的搜索界面如下图所示。
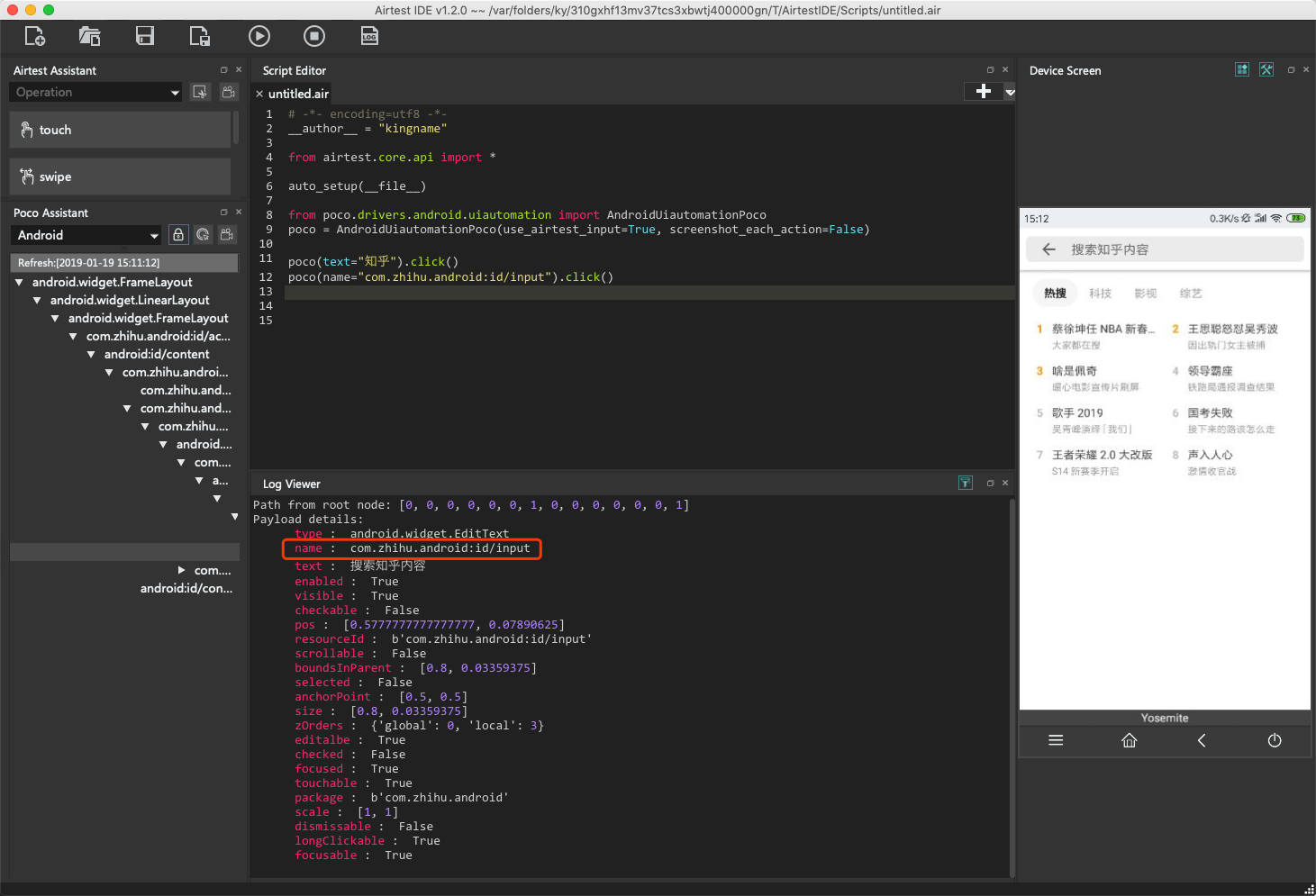
可以看到,name属性的值依然是com.zhihu.android:id/input,此时就可以输入内容了。
输入内容使用的方法为set_text,用法为:
|
1
|
poco(name="com.zhihu.android:id/input").set_text('古剑奇谭三')
|
定位并筛选
输入了搜索关键词以后,再来看看当前页面,搜索出现了三个结果:
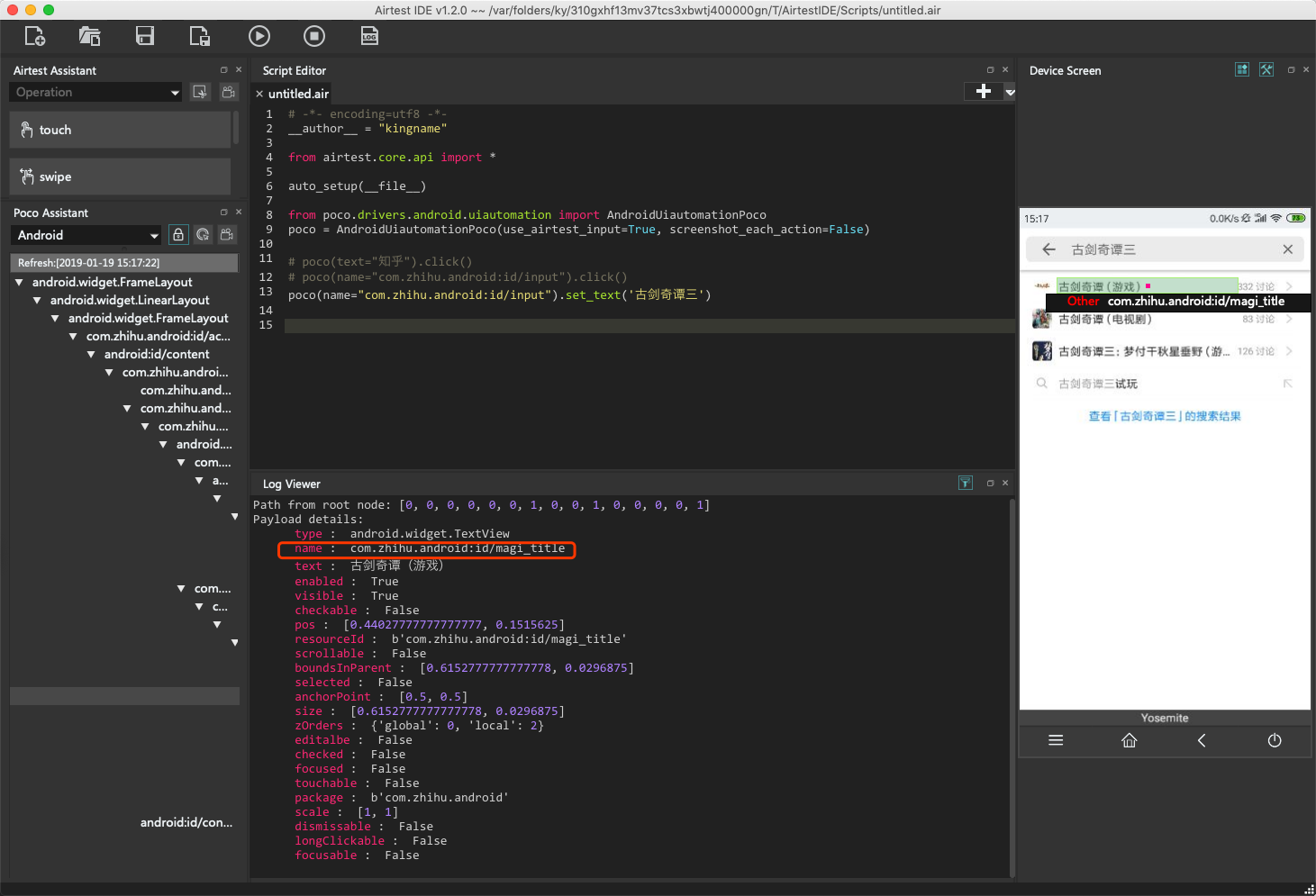
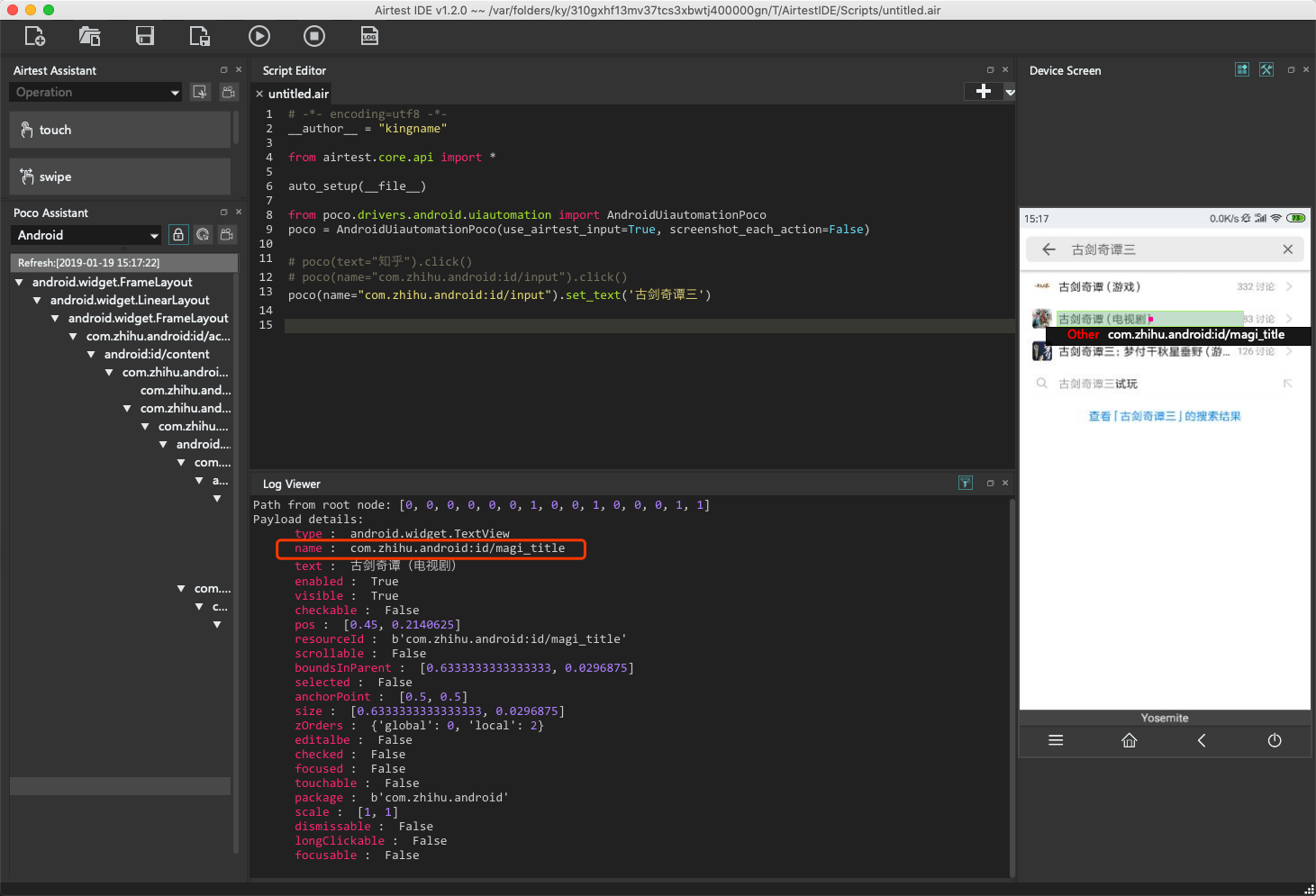
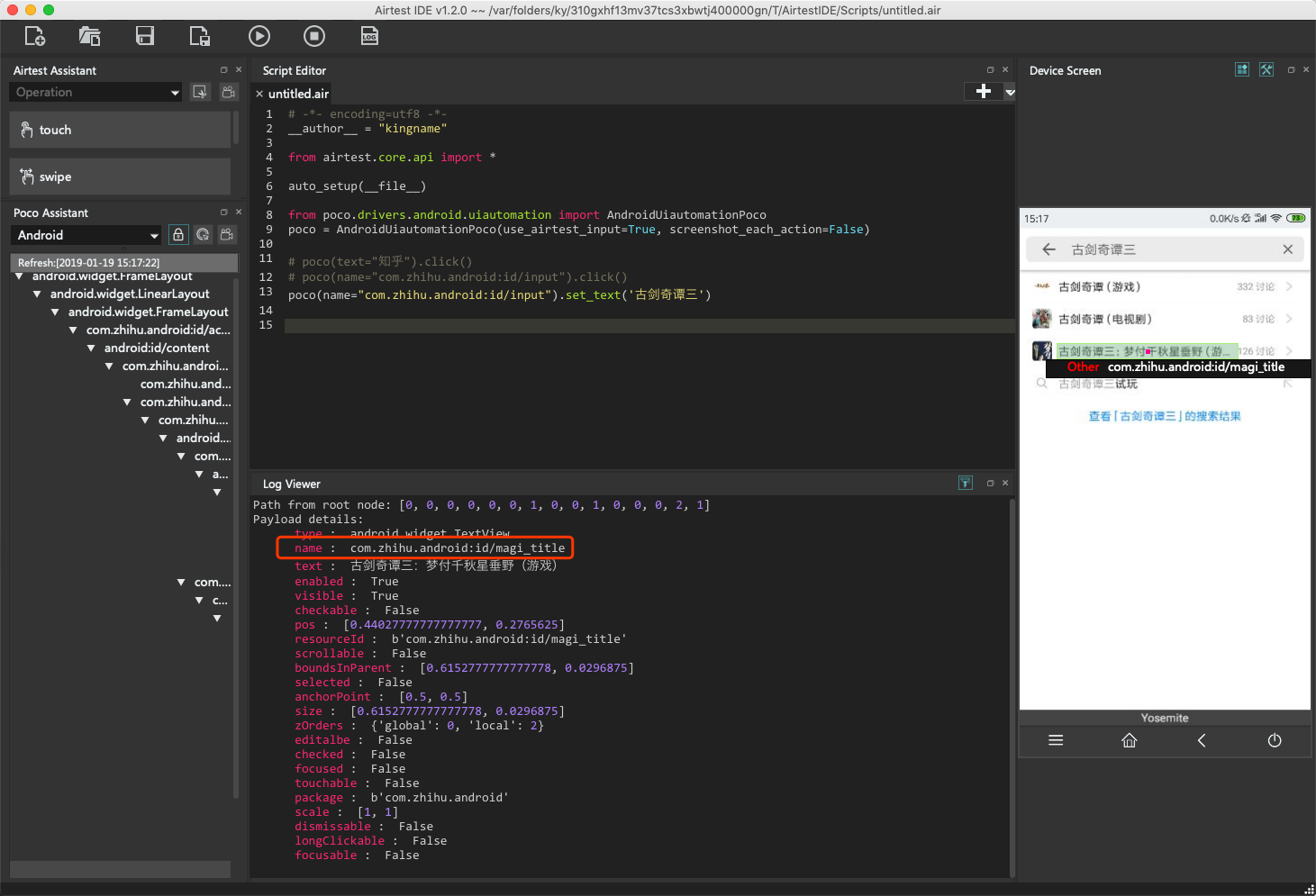
通过对比这三个结果的属性信息,发现他们的name属性都是相同的,而text不同。如果像下面这样写点击动作:
|
1
|
poco(name='com.zhihu.android:id/magi_title').click()
|
那么默认就会点击第一个搜索结果。
如果我想点击第二个搜索结果怎么办呢?可以这样写代码:
|
1
|
poco(name='com.zhihu.android:id/magi_title', text='古剑奇谭(电视剧)').click()
|
或者你也可以像列表一样使用索引定位:
|
1
|
poco(name='com.zhihu.android:id/magi_title')[1].click()
|
这两种写法的前提,都是我们已经知道了每个结果分别是什么。假设现在我就想搜索古剑奇谭三,但我不知道搜索结果是第几项,又应该怎么办呢?此时还可以使用正则表达式:
|
1
|
poco(name='com.zhihu.android:id/magi_title', textMatches='^古剑奇谭三.*$').click()
|
滑动屏幕
进入搜索结果以后,需要查看下面的各种问题,此时就需要不断向上滑动屏幕。这里有一点需要特别注意,Airtest只能获取当前屏幕上的元素布局信息,不在屏幕上的内容是无法获取的。这一点和Selenium是不一样的。
滑动屏幕使用的命令为swipe,滑动屏幕需要使用坐标信息。但这种坐标和屏幕分辨率无关。这里的坐标定义为:(x, y),其中x为横坐标,y为纵坐标。屏幕左上角为(0, 0),屏幕右下角为(1, 1),从左向右,横坐标从0逐渐增大到1,从上到下,纵坐标从0逐渐增大到1。
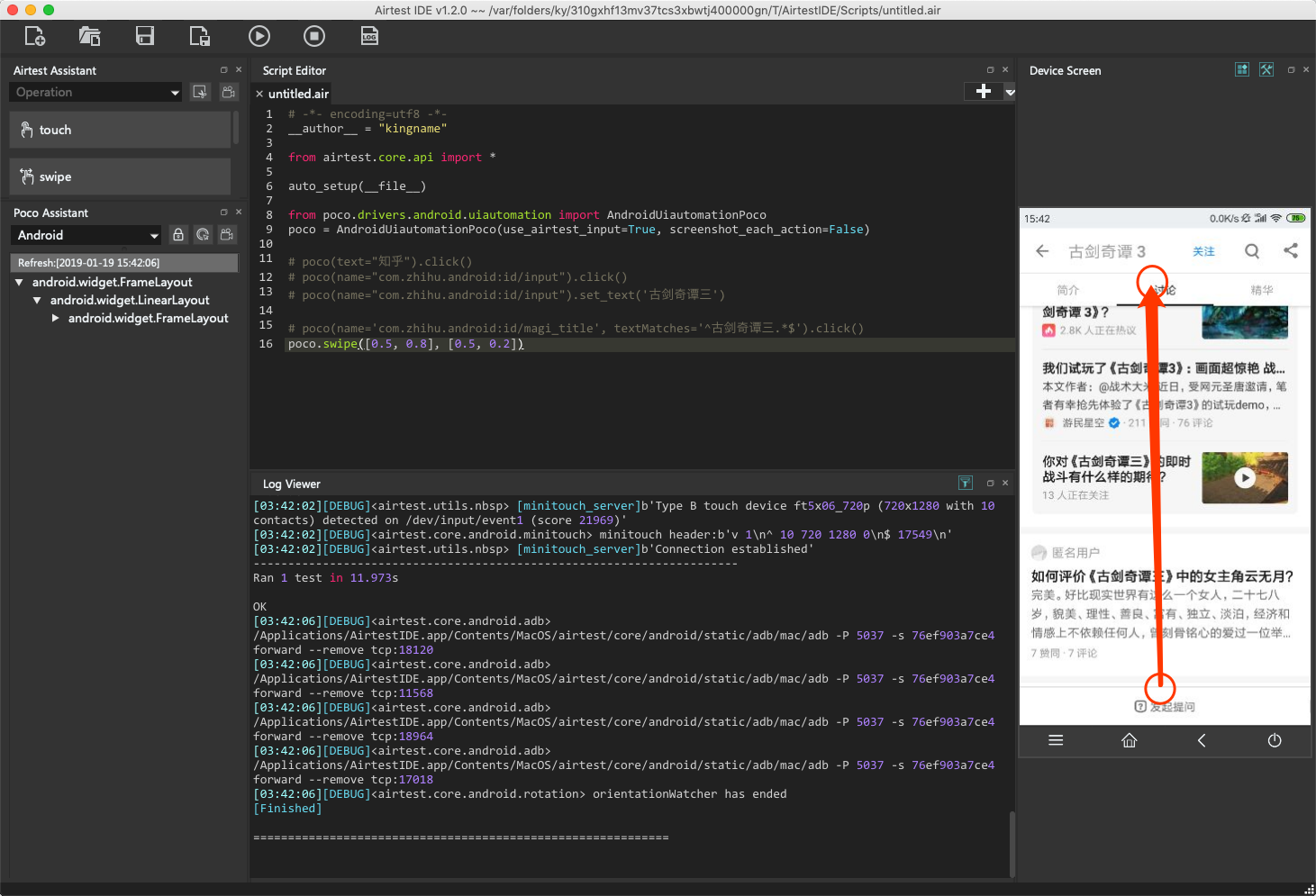
现在我要把屏幕向上滑动,那么在真机上面,我是先按住屏幕下方,然后把屏幕向上滑动,所以代码可以这样写:
|
1
2
3
|
# poco.swipe(起点坐标,终点左边)
poco.swipe([0.5, 0.8], [0.5, 0.2])
|
方向示意图如下图所示:
在一般情况下:
- 向上滑动,只需要改动纵坐标,且起点值大于终点值
- 向下滑动,只需要改动纵坐标,且起点值小于终点值
- 向左滑动,只需要改动横坐标,且起点值大于终点值
- 向右滑动,只需要改动横坐标,且起点值小于终点值
在爬虫开发中,涉及到的Airtest操作基本上已经介绍完毕。
单独使用Python控制手机
在Airtest操作手机虽然方便,但是不可能在每一台电脑上都安装Airtest吧。所以需要想办法把代码从Airtest这个程序中分离出来。
Airtest基于Python的一个开源库Poco开发,而在Airtest的B区写的Python代码,实际上就是Poco的代码。所以只要安装Poco库,就可以在Python中直接控制手机。
安装Poco库的命令为:
|
1
|
pip install pocoui
|
这个库依赖的东西有点多,安装稍稍慢一些。安装完成以后,我们把代码复制到PyCharm中,如下图所示。
运行这段代码,如果是Linux或者macOS的用户,请注意看运行结果是不是有报错,提示adb没有运行权限。这是因为随Poco安装的adb没有运行权限,需要给它添加权限,在终端执行命令:
|
1
2
3
|
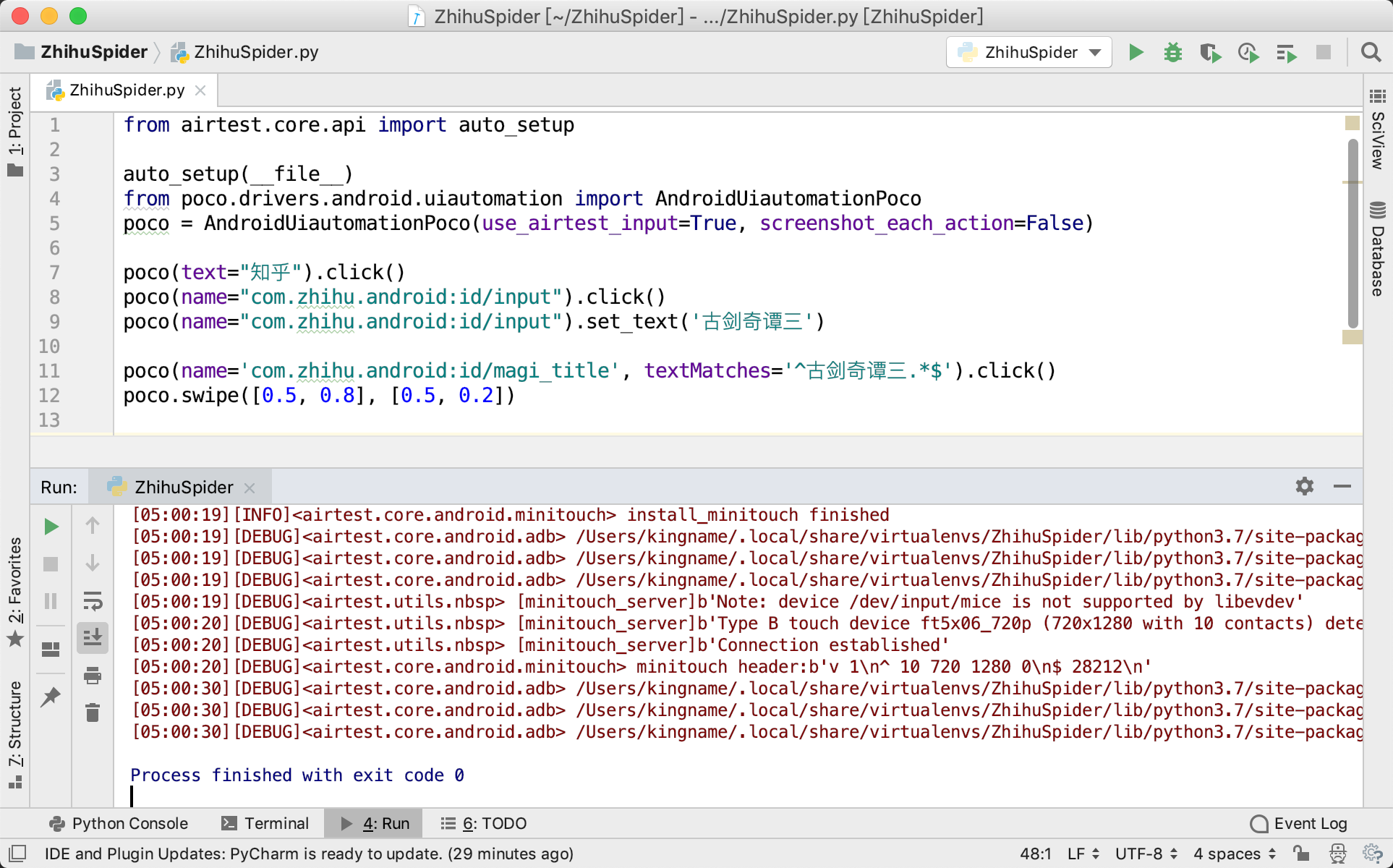
# chmod +x 报错信息中给出的adb地址
chmod +x /Users/kingname/.local/share/virtualenvs/ZhihuSpider/lib/python3.7/site-packages/airtest/core/android/static/adb/mac/adb(实际执行时请换成你的地址)
|
命令运行完成以后再次执行代码,可以看到代码运行成功,手机被成功控制了,如下图所示。
如何获取屏幕文字
由于Airtest的编辑器中的代码运行后无法正常打印出中文,因此后面的代码都直接在PyCharm中执行。
既然要做爬虫,就需要获取手机上的文字内容。回到搜索页面,我想知道“古剑奇谭”三这个关键字能搜索出多少条结果,每条结果有多少个讨论,如下图所示:
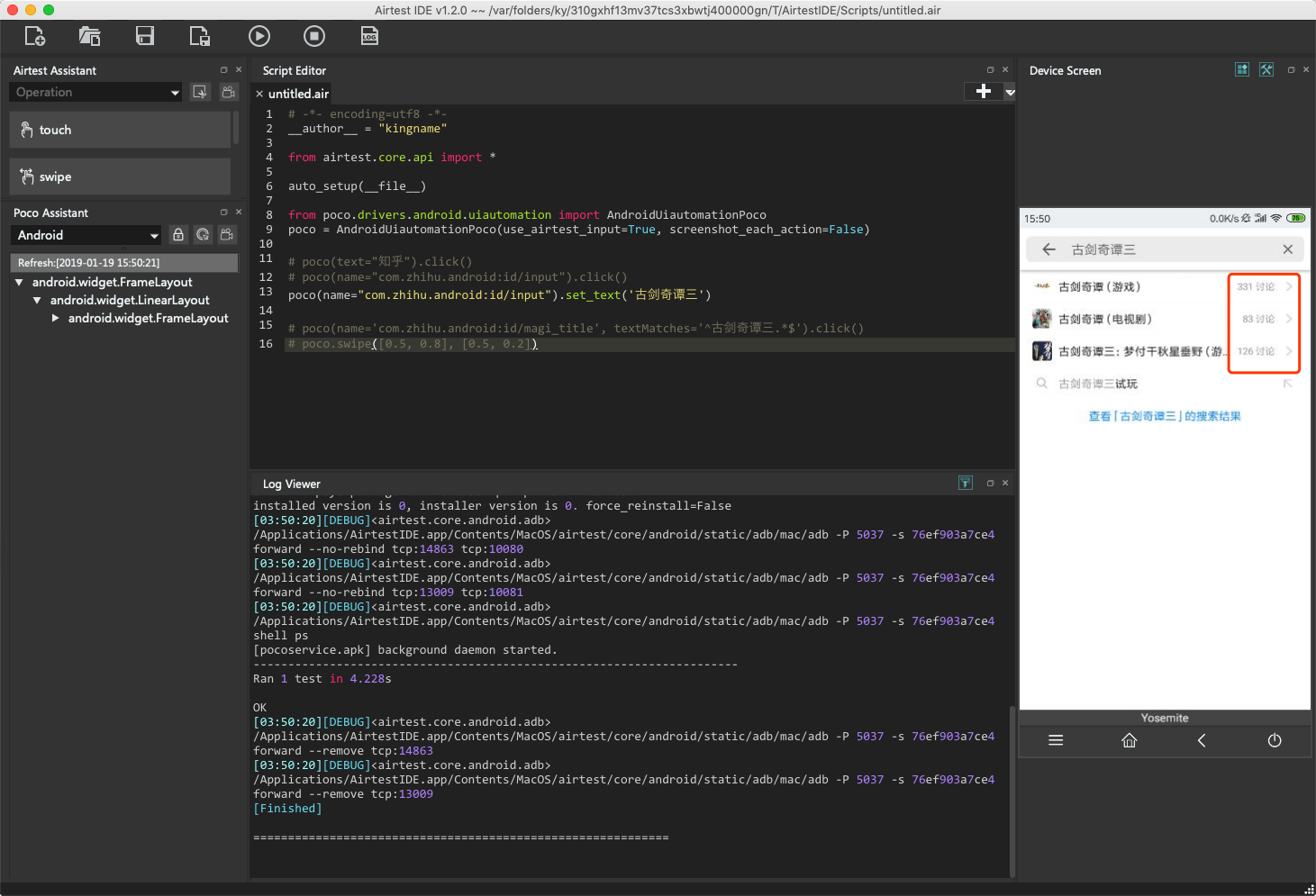
此时我们需要做两件事情:
- 分别查看每一个搜索结果
- 获取屏幕上的文字
E区的树状结构如下图所示:
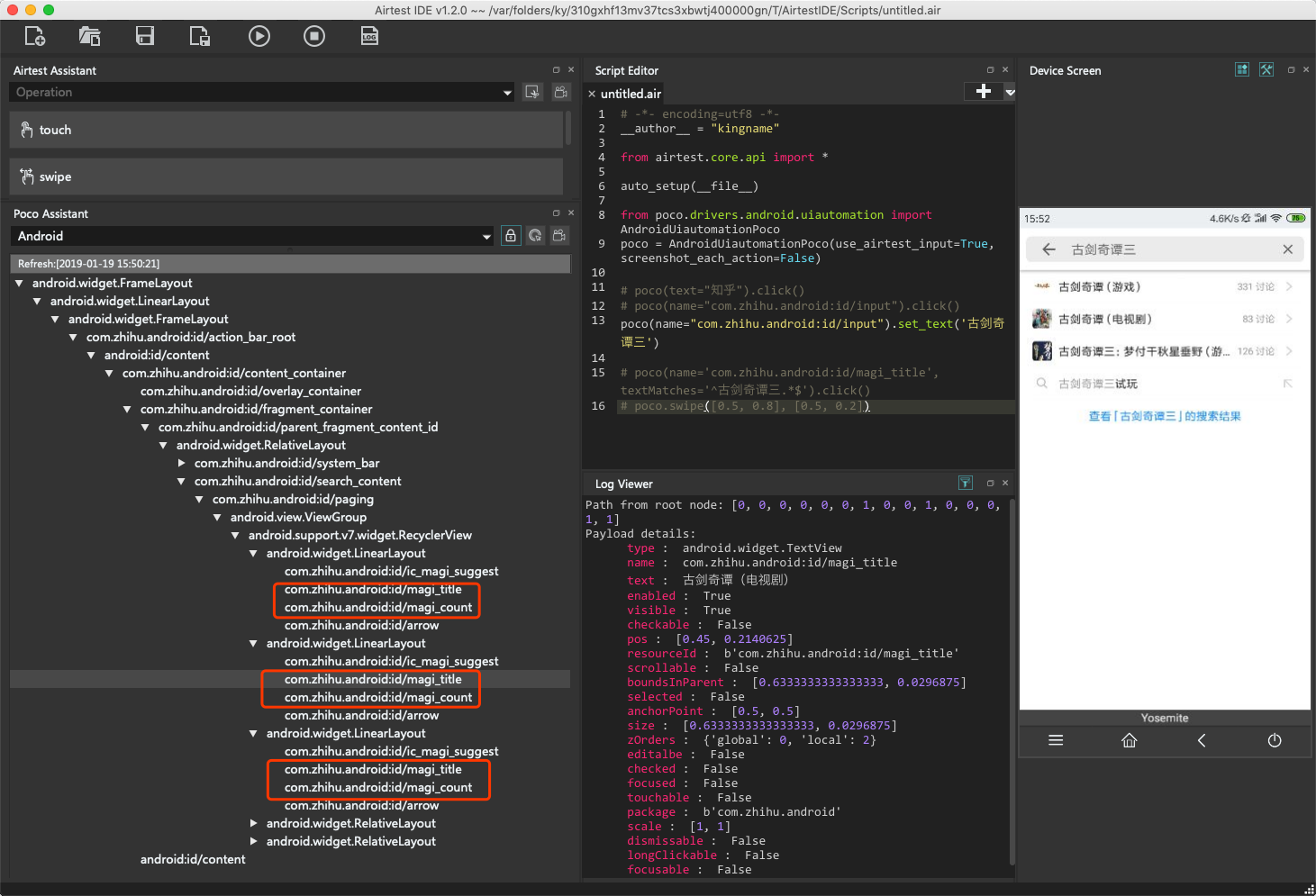
每一个搜索结果的标题作为text属性的值,在name='com.zhihu.android:id/magi_title'对应的元素中;每一个搜索结果的讨论数作为text属性的值,在name='com.zhihu.android:id/magi_count'对应的元素中。
最直接的做法就是分别获取三个标题和三个讨论数,然后把它们合并在一起:
|
1
2
3
4
5
6
7
8
|
title_obj_list = poco(name='com.zhihu.android:id/magi_title')
title_list = [title.get_text() for title in title_obj_list]
discuss_obj_list = poco(name='com.zhihu.android:id/magi_count')
discuss_list = [discuss.get_text() for discuss in discuss_obj_list]
for title, discuss in zip(title_list, discuss_list):
print(title, discuss)
|
运行效果如下图所示:
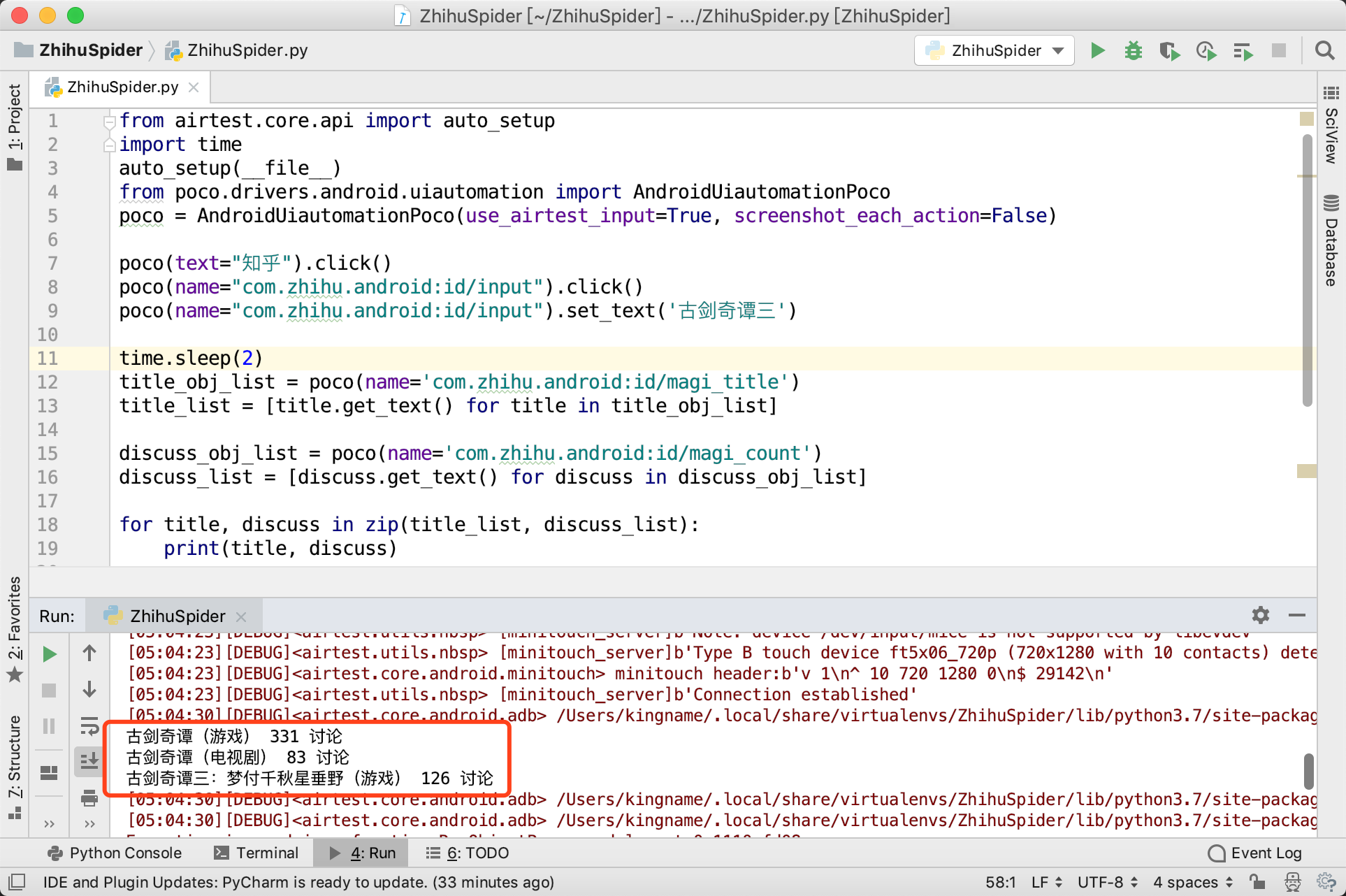
但是这种做法实际上是很危险的,假设会有某一个很生僻的搜索结果,只有标题没有讨论数,那么这样分开抓取再组合的做法,就会导致最后匹配错位。所以合理的做法是先抓大再抓小。每一组标题和讨论数,他们都有自己的父节点,如下图箭头所指向的三个android.widget.LinearLayout:
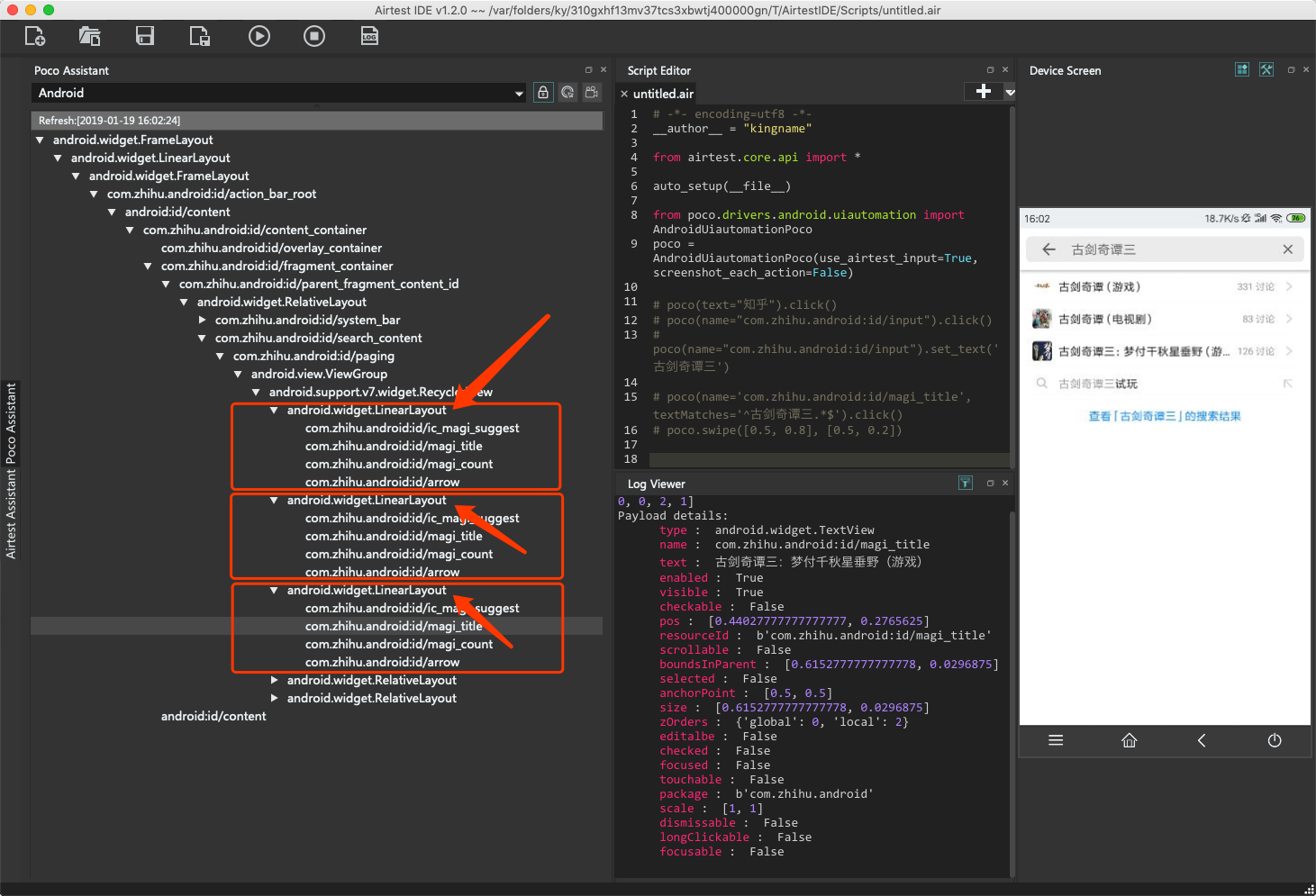
那么现在,使用先抓大再抓小的技巧,先把每一组结果的父节点抓下来,再到每一个结果里面分别获取标题和讨论数。
然而这个父节点又怎么获取呢?如下图所示,这个父节点每一个属性值都没有什么特殊的,写任何一个都有可能与别的节点撞上。
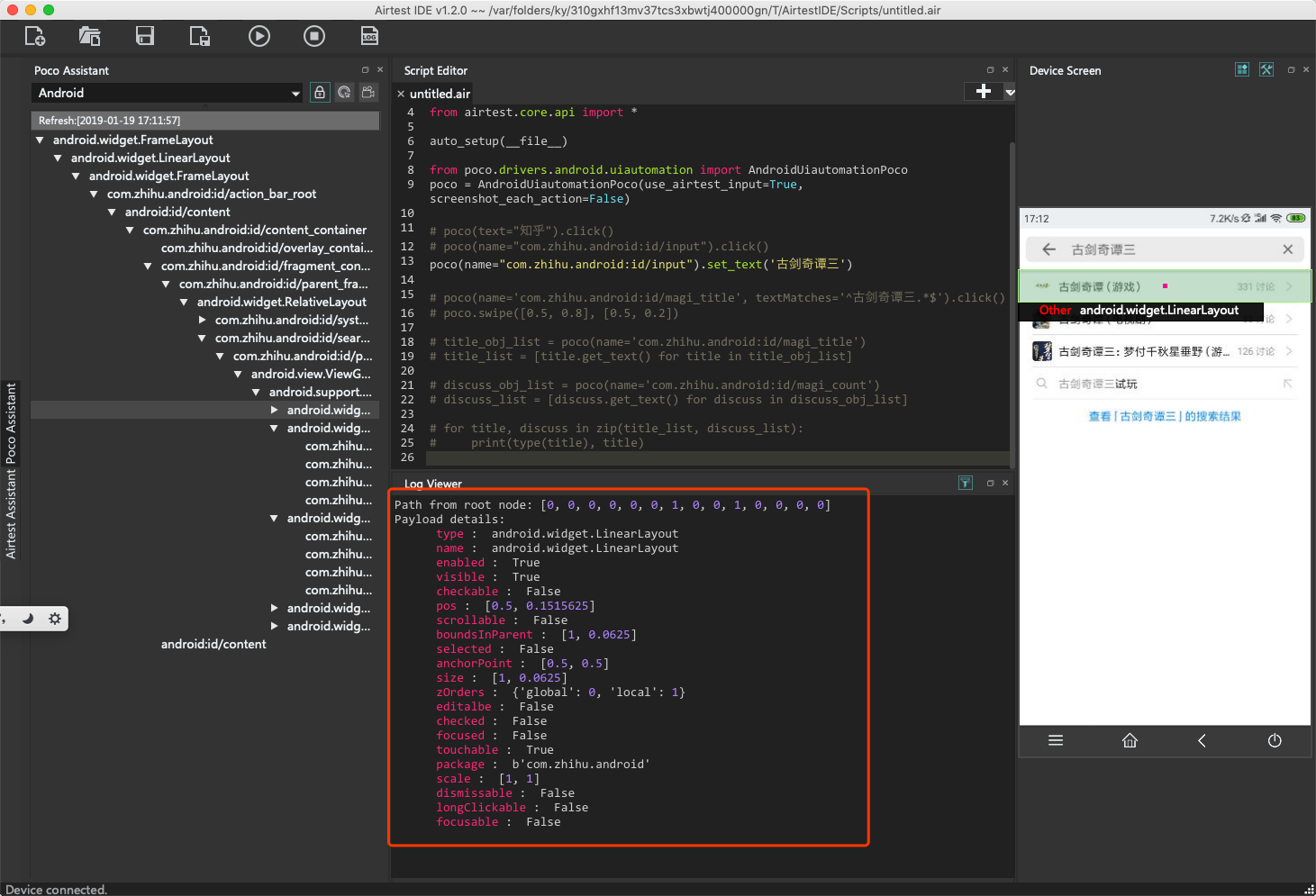
此时,最简单的办法,就是在E区,双击父节点。定位代码就会自动添加,如下图所示。
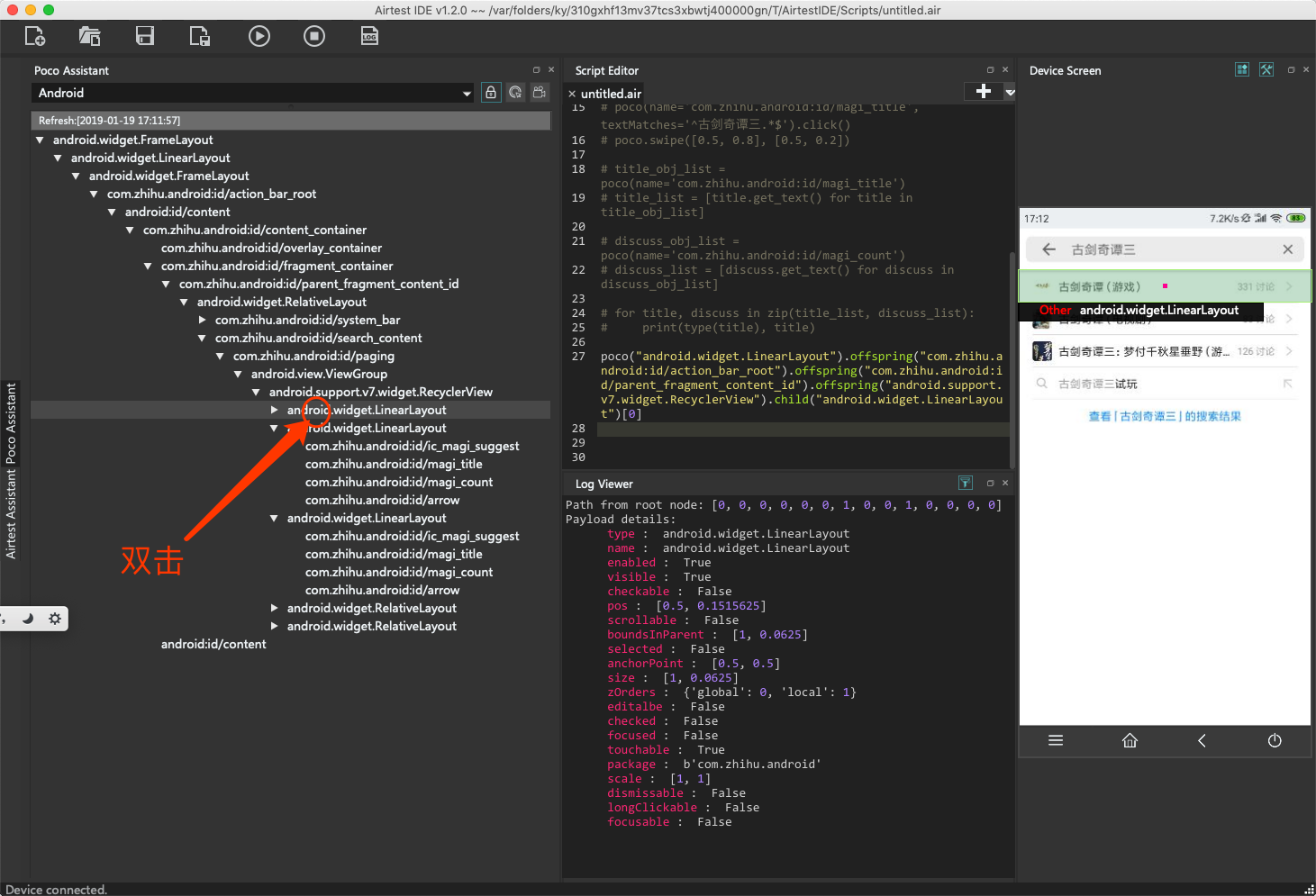
这个定位代码看起来非常复杂,但实际上它的内在逻辑非常简单,就是从顶层一层一层往下找而已。
自动生成的定位代码如下:
|
1
|
poco("android.widget.LinearLayout").offspring("com.zhihu.android:id/action_bar_root").offspring("com.zhihu.android:id/parent_fragment_content_id").offspring("android.support.v7.widget.RecyclerView").child("android.widget.LinearLayout")[0]
|
在这个自动生成的定位代码中,我们看到了offspring、child这两种方法。其中child代表子节点,offspring代表孙节点、孙节点的子节点、孙节点的孙节点……。简言之,使用child只会在子节点中搜索需要的内容,而使用offspring会像文件夹递归一样把里面的所有节点都遍历一次,直到找到符合条件的属性为止。显然,offspring速度会比child慢。
实际上,我们可以对这个定位代码做一些精简:
|
1
|
poco("com.zhihu.android:id/parent_fragment_content_id").offspring("android.support.v7.widget.RecyclerView").child("android.widget.LinearLayout")[0]
|
这个精简的方法,与从Chrome复制的XPath中进行精简是一样的逻辑,根本原则就是找到“独一无二”的属性值,然后用这个属性值来进行定位。
由于我点击的是第一个搜索结果,所以定位代码的最后有一个[0]。现在由于需要获得所有搜索结果的内容,所以应该去掉[0]而使用for循环展开,然后获取里面的内容:
|
1
2
3
4
5
|
result_obj = poco("com.zhihu.android:id/parent_fragment_content_id").offspring("android.support.v7.widget.RecyclerView").child("android.widget.LinearLayout")
for result in result_obj:
title = result.child(name='com.zhihu.android:id/magi_title').get_text()
count = result.child(name='com.zhihu.android:id/magi_count').get_text()
print(title, count)
|
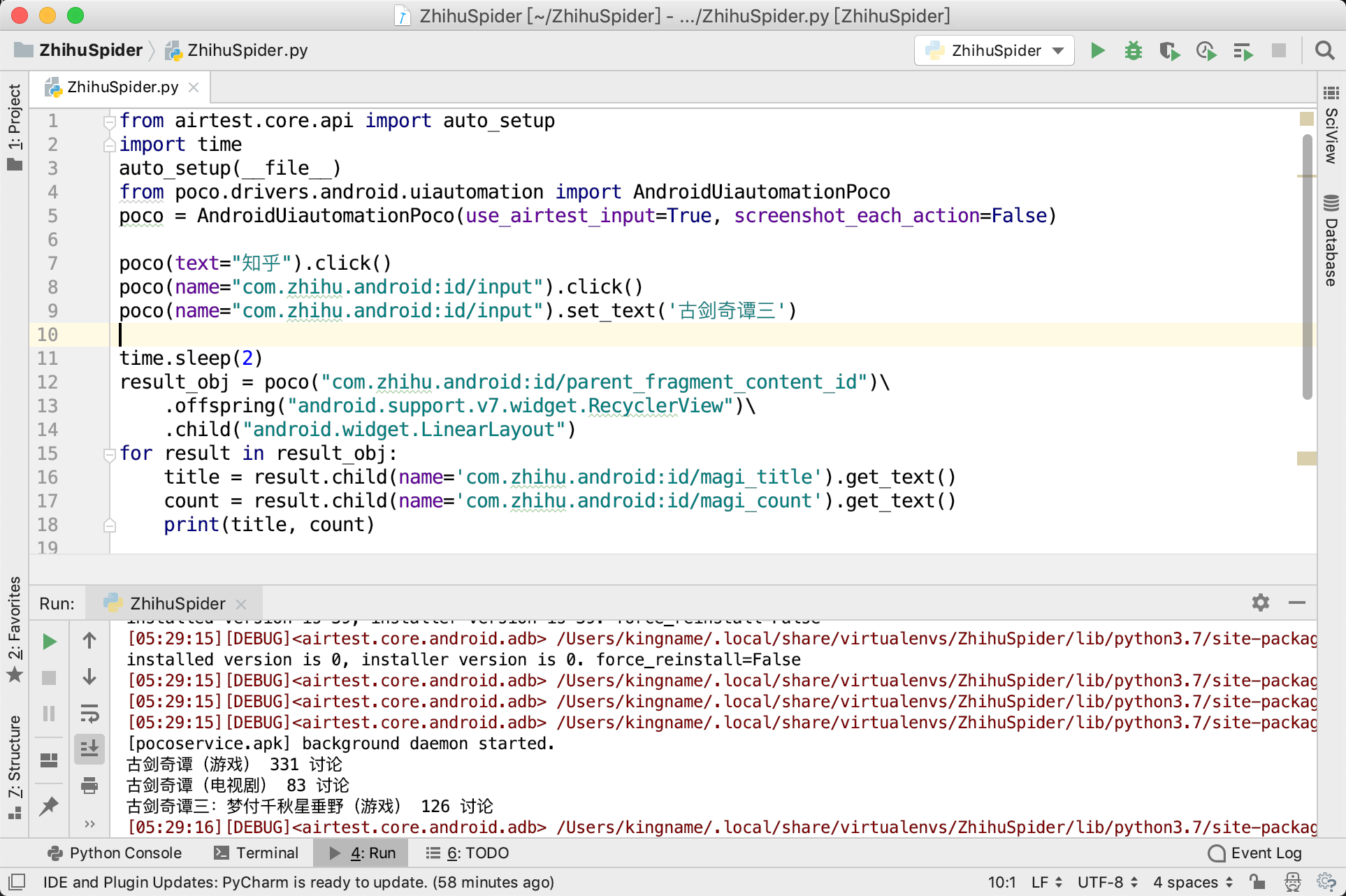
运行效果如下图所示。
控制多台手机
当我们在电脑上插入多个Android手机时,执行命令:
|
1
|
adb devices -l
|
运行效果如下图所示。
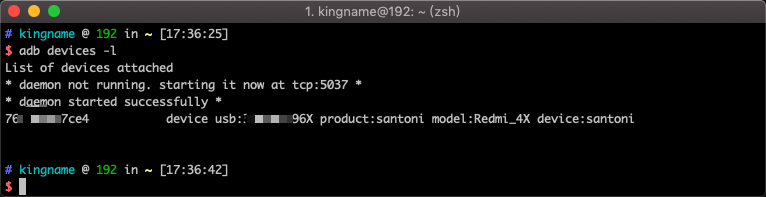
每个手机都会被列出来。在最左边的编号就是手机串号。使用这个串号可以指定多个手机:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
from airtest.core.api import auto_setup
from airtest.core.android import Android
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
auto_setup(__file__)
device_1 = Android('76efadf3a7ce4')
device_2 = Android('adfasdfasf23')
device_3 = Android('adifu39ernla')
poco_1 = AndroidUiautomationPoco(device_1, use_airtest_input=True, screenshot_each_action=False)
poco_2 = AndroidUiautomationPoco(device_2, use_airtest_input=True, screenshot_each_action=False)
poco_3 = AndroidUiautomationPoco(device_3, use_airtest_input=True, screenshot_each_action=False)
|
通过这种方式,在一台电脑上使用USBHub,连上二三十台手机是完全没有问题的。
无线模式
Airtest支持无线模式,不需要USB,只要电脑和手机连接同一个WIFI就能控制:
如果大家对如何开启无线模式有兴趣,请留言,我就会继续写。
搭建手机爬虫集群
一台电脑可以连接三十台手机,那么如果有很多电脑和很多手机,就可以实现手机爬虫集群,其运行效果如下图所示。

感谢认真读完这篇教程的您
先别走呗,这里有可能有你需要的文章:
woff字体反爬实战,10分钟就能学会(ttf字体同理);
CSS字体反爬实战,10分钟就能学会;
爬虫:js逆向目前遇到的知识点集合;
woff字体反爬实战,10分钟就能学会;
爬虫js解密分析:某某猫小说;
爬虫js解密分析:某某云文学;
个人总结-js逆向解析思路;
最后:可能你们说“这TM骗流量的吧,标题明明说的是爬取某宝的评论数据,教程呢?”
下面只给最核心的代码,评论页的代码,看得懂的总看得懂,看不懂的,建议你可以直接先按照前面的教程,爬取一次知乎就清楚了:
data = []
total = 0
while 1:try:# 获取当前屏幕下的所有可见的评论相关数据comment_lists = poco("android:id/content").offspring("com.taobao.taobao:id/fl_detail_fragment").child("android.widget.RelativeLayout").offspring("android.support.v7.widget.RecyclerView").child("android.widget.FrameLayout")# 逐条遍历获取评论for _i, one_comment in enumerate(comment_lists):view_lists = one_comment.child("android.view.ViewGroup").child(type="android.view.View")if len(view_lists) < 4: # 跳过,当前屏幕页看不全的数据print("当前的评论数据不完整, len:{}".format(len(view_lists)))continuecomment_dict = {"user": "","time": "","size": "","color": "","content": "","click_num": 0,}for index, one_view in enumerate(view_lists):if index == 1: # 2020-01-08 净含量:450g 颜色分类:玫瑰+草木+莓果comment_dict["time"] = one_view.attr("desc").split("净含量:")[0].strip()comment_dict["size"] = one_view.attr("desc").split("颜色分类:")[0].split("净含量:")[-1].strip()comment_dict["color"] = one_view.attr("desc").split("颜色分类:")[-1].strip()comment_dict["content"] = one_view.attr("desc") if index == 2 else comment_dict["content"]comment_dict["click_num"] = int(re.search("\d+", one_view.attr("desc")).group()) if index == 3 else comment_dict["click_num"]comment_dict["user"] = one_view.attr("desc") if index == 0 else comment_dict["user"]if comment_dict in data: # TODO 你可以使用布隆过滤器,会更好一点end_count += 1print("已存在的评论啊!!!")if end_count>20:breakcontinuedata.append(comment_dict)end_count = 0 # 记得清0total += 1print("当前共采集到{}条评论. 当前评论内容是:{}".format(total, comment_dict))print("-" * 50)if (total % 50) == 0:# todo 可以做每50条数据保存一次pass# 遍历完毕之后,进行向下拖动滑动poco.swipe(p1=[0.5, 0.8], p2=[0.5, 0.2])except Exception as e:print("出现异常:\n{}".format(traceback.print_exc()))if end_count > 20:print("已经尝试最大次数20,已判断为最后一页的评论数据")print("进度: 共{}条数据, 已经做保存".format(len(total)))breakend_count += 1print("-" * 100)
(2020)使用Airtest来爬取某宝评论数据相关推荐
- python爬淘宝app数据_一篇文章教会你用Python爬取淘宝评论数据(写在记事本)
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. [二.项目准备工作] 准备Pycharm,下载安装等,可以参考这篇文章 ...
- 如何写一个python程序浏览淘宝_一篇文章教会你用Python爬取淘宝评论数据(写在记事本)...
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. [二.项目准备工作] 1. 准备Pycharm,下载安装等,可以参考这 ...
- Python入门--爬取淘宝评论并生成词云
Python爬取淘宝评论并生成词云 最新修改于2021/04/01 所需相关Python第三方库(目前最新版本即可) 推荐使用Anaconda,其使用十分方便.快捷. requests库 json库 ...
- python 爬虫实例-python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- Python爬虫实例,一小时上手爬取淘宝评论(附代码)!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- 爬取淘宝手机数据,并进行清洗,并可视化展示
爬取所需环境 selnium安装 Win+R输入cmd敲回车进入到cmd窗口: 输入"pip3 install selenium -i https://pypi.tuna.tsinghua. ...
- python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- python爬取抖音用户评论_python实现模拟器爬取抖音评论数据的示例代码
目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记. 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理 ...
- 使用Appium爬取淘宝App数据
0x01.介绍说明 1.简介 Appium是一个自动化测试开源工具.通过WebDriver协议驱动IOS.Android.Windows Phone平台上的原生应用.混合应用和web应用. 2.App ...
最新文章
- 女生做大数据有发展前景吗?能学会吗?
- java 验证码 插件_javaweb中验证码插件Kaptcha的使用
- 根据另外一个表来更新,增加字段
- java xlsx怎么转换成excel格式_python小工具 | Excel的xls和xlsx格式文件转换
- sql server使用convert来取得datetime日期数据
- Flutter中富文件标签的解决方案
- fastText:极快的文本分类工具
- 从草图到人脸:这篇SIGGRAPH2020论文帮你轻松画出心中的「林妹妹」,开源「计图」实现代码...
- 【第十届“泰迪杯”数据挖掘挑战赛】B题:电力系统负荷预测分析 ARIMA、AutoARIMA、LSTM、Prophet、多元Prophet 实现
- AVR 上的汇编圈圈操作系统
- 悠歌“即时”游戏回合文案
- 易语言浏览本地html,简单的易语言读取网页文本程序
- Python报错UnicodeEncodeError: 'gbk' codec can't encode character '\xa9' in position 1919: illegal mult
- [论文速度] 同时解决成像时,曝光不足和曝光过度问题:Deep Reciprocating HDR Transformation
- Unit5 Going places
- 拒绝一心多用的工作学习方式(转)
- Python实验报告一 python基础试题练习
- 从数据分析,看公司员工流失率分析报告
- Nginx的动静分离实验
- 用html5写一个模拟钢琴