网页怎么预先加载模型_修补预先训练的语言模型
网页怎么预先加载模型
Can you fill in the words that I’ve removed from a recent announcement?
您能填写我从最近的公告中删除的词吗?
Maintain social ___ throughout the Museum. Capacity will be limited.Temperature checks are required for all visitors, and everyone over the age of two must wear a ___.For a contactless ____, use your digital membership card.
在整个博物馆内保持社交___。 容量将受到限制。所有访客都必须进行温度检查,两岁以上的每个人都必须佩戴___。对于非接触式____,请使用您的数字会员卡。
By now you’re familiar with the term ‘social distancing’ and requirements for masks. The exact phrase ‘contactless visit’ might not have come to mind, but you aren’t surprised by it. Words and their associations have changed meanings in our brains and communication.For machine learning researchers, these changes pose a problem.
到目前为止,您已经熟悉术语“社交距离”和口罩要求。 确切的词句“非接触式访问”可能没有想到,但是您对此并不感到惊讶。 单词及其联想改变了我们大脑和交流中的含义,对于机器学习研究人员来说,这些变化带来了问题。
再培训很难做到 (Retraining is hard to do)
In the machine learning / natural language processing field, researchers develop language models to match human performance on several text- and language-specific tasks. Developing new, state-of-the-art models requires amassing data from around the web, and harnessing a lot of computing power. OpenAI’s GPT-3 model is estimated to have cost $4.6 million to train. When researchers evaluated the model, they realized a technical error in their experiment:
在机器学习/自然语言处理领域,研究人员开发语言模型以匹配人类在几种特定于文本和语言的任务上的表现。 开发最新的模型需要从网上收集大量数据,并利用大量的计算能力。 OpenAI的GPT-3模型估计耗资460万美元 。 当研究人员评估模型时,他们在实验中发现了一个技术错误:
To reduce […] contamination, we searched for and attempted to remove any overlaps with the development and test sets of all benchmarks studied in this paper. Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model.
为了减少污染,我们寻找并尝试消除与本文研究的所有基准测试的开发和测试集重叠的部分。 不幸的是,过滤中的错误导致我们忽略了一些重叠,并且由于训练的成本,重新训练模型是不可行的。
OpenAI proposed some changes to their evaluation, and moved on. This mindset is standard in big AI companies; they want their researchers to be moving on, not tied up in retraining and retreading previous models. When a developer continues using models such as Multilingual BERT (late 2018) or T5 (February 2020) in their projects, they could run into problems with new words and associations. I’m focusing on those two models in this experiment because they are useful, but daunting for a team to collect comparable datasets and retrain from scratch. Consider the instructions for T5’s dataset:
OpenAI提出了对其评估的一些更改,然后继续进行。 这种心态是大型AI公司的标准。 他们希望研究人员继续前进,而不是束缚于重新训练和重读以前的模型。 当开发人员在其项目中继续使用Multilingual BERT(2018年末)或T5(2020年2月)之类的模型时,他们可能会遇到新词和联想的问题。 在本实验中,我将重点放在这两个模型上,因为它们非常有用,但是对于一个团队来说,收集可比较的数据集并从头开始重新训练却令人望而生畏。 考虑一下T5数据集的说明:
The C4 dataset we created for unsupervised pre-training is available in TensorFlow Datasets, but it requires a significant amount of bandwidth for downloading the raw Common Crawl scrapes (~7 TB) and compute for its preparation (~335 CPU-days). We suggest you take advantage of the Apache Beam support in TFDS [...] With 500 workers, the job should complete in ~16 hours.
我们为无监督的预训练而创建的C4数据集可在TensorFlow数据集中找到,但是它需要大量带宽才能下载原始的Common Crawl抓取片段(〜7 TB)并进行计算以进行准备(〜335 CPU天)。 我们建议您利用TFDS中的Apache Beam支持[...]有500名工作人员,这项工作应在大约16小时内完成。
提出修补 (Proposing patching)
I’m thinking about this problem, and it seems like we could patch new words into the tokenizer and the embeddings, on one machine, with a single notebook. My plan is to collect 100+ sentences using each new word, [MASK] it out, see what the original model’s suggested weights are, and use that to triangulate a position in vector-space. Then I can use test sentences to see if this patch works.My hope is that a patched model using knowledge from [MASK]-ing will also outperform the original model at other tasks based on up-to-date data (such as filtering spam or health misinformation).My worries are that the benefit will be minimal compared to finetuning, or that my patch will only return vectors (and not connect into the rest of the model’s architecture).
我正在考虑这个问题,似乎我们可以用一个笔记本在一台机器上将新单词打入令牌生成器和嵌入程序中。 我的计划是使用每个新单词收集100多个句子,[屏蔽],查看原始模型的建议权重,然后使用它对向量空间中的位置进行三角测量。 然后,我可以使用测试语句查看此补丁程序是否有效。我希望使用[MASK] -ing知识的补丁程序模型在基于最新数据(例如过滤垃圾邮件)的其他任务上也能胜过原始模型。或健康错误信息)。我担心的是,与微调相比,这样做的好处是微不足道的,或者我的补丁只会返回向量(而不会连接到模型的其余部分)。
以前做过吗? (Has it been done before?)
As I was writing this post and running my code, I found this paper from October 2019, by Facebook AI Research, which tread on similar ground. Their experiment creates two corpuses which are carefully curated:
在撰写本文和运行代码的过程中,我发现Facebook AI Research于2019年10月发布的这篇论文基于类似的观点。 他们的实验创建了两个精心策划的语料库:
we want to check how well does our method allow to update word vector models, especially when the new corpus S_1 contains a lot of new words, never seen in S_0. As this kind of data is hard to find, we simulate this setup by discarding from S_0 lines containing selected words
我们想检查一下我们的方法对单词向量模型的更新效果如何,尤其是当新的语料库S_1包含很多新单词(在S_0中从未见过)时。 由于此类数据很难找到,因此我们通过从包含所选单词的S_0行中丢弃来模拟此设置
Their corpuses are set up so that a question-answering task can be answered only by knowing words from both. They train FastText on ~1.4 billion words (for reference: Wikipedia is around 3.6 billion words).They don’t share their code.My approach is definitely more of a hack, but I think is more applicable to patching large-scale pre-trained transformers models.
设置他们的语料库,以便仅通过了解双方的单词才能回答问题。 他们用大约14亿个单词训练FastText(供参考:维基百科大约是36亿个单词)。他们没有共享代码。我的方法绝对是黑客,但我认为更适合修补大型预训练有素的变压器模型。
客观地识别新词汇 (Objectively identifying new vocabulary)
My first objective is to find new words (COVID-19) or technical words (coronavirus) which were omitted from the original vocabularies:
我的第一个目标是找到在原始词汇中遗漏的新词(COVID-19)或技术性词(冠状病毒):
from transformers import AutoTokenizerll = AutoTokenizer.from_pretrained(‘t5–11b’)ll.tokenize(‘The novel coronavirus can be scary’)> [‘▁The’, ‘▁novel’, ‘▁cor’, ‘on’, ‘a’, ‘virus’, ‘▁can’, ‘▁be’, ‘▁scary’]
从变形金刚import AutoTokenizerll = AutoTokenizer.from_pretrained('t5-11b')ll.tokenize('新型冠状病毒可能会令人恐惧') > ['','新颖','cor','on','一个”,“病毒”,“可以”,“被”,“吓人”]
l2 = AutoTokenizer.from_pretrained(‘bert-base-uncased’)l2.tokenize(‘The novel coronavirus can be scary’)> [‘the’, ‘novel’, ‘corona’, ‘##virus’, ‘can’, ‘be’, ‘scary’]l2.tokenize(‘social distancing’)> [‘social’, ‘di’, ‘##stan’, ‘##cing’]
l2 = AutoTokenizer.from_pretrained('bert-base-uncased')l2.tokenize('新型冠状病毒可能会令人恐惧') > ['','novel','corona','## virus','can' ,'be','scary'] l2.tokenize('social distancing') > ['social','di','## stan','## cing']
BERT’s word-piece approach here is potentially useful. Finetuning the model could get these tokens to do their job… but I expect it would take a lot to predict properly.
BERT的分词方法可能很有用。 对模型进行微调可以使这些代币发挥作用……但是我希望正确预测将需要很多时间。
I start by downloading a recent en.wikipedia.org dump (August 20, 2020) and running WikiExtractor to convert the structured data into raw text. I ended up with about several gigabytes before hitting some constraints. Then I ran HuggingFace’s tokenizers to get a 30,000 word / word-piece vocabulary.Disappointingly, there are thousands of words and word-pieces frequently present on Wikipedia but not given individual tokens in BERT or T5, from typewriter to ##iovascular. For our project, coronavirus, ##avirus, distanced, did appear in several tokenizer runs.By reducing my ideal vocabulary size, I could create a 15,000-word vocabulary list with only 300 tokens missing from both models. These small word lists didn’t include coronavirus terms.
首先下载最近的en.wikipedia.org转储(2020年8月20日),然后运行WikiExtractor将结构化数据转换为原始文本。 在遇到一些限制之前,我最终获得了大约数GB的存储空间。 然后我运行了HuggingFace的标记器,得到了30,000个单词/每个单词的词汇量。令人失望的是,维基百科上经常出现成千上万个单词和单词,但没有提供BERT或T5中的单个标记,从typewriter到##iovascular 。 对于我们的项目, coronavirus , ##avirus , distanced ,没有出现在几个标记者runs.By减少我理想中的词汇量,我可以创建只有300标记从两个模型缺少一个15000字的词汇表。 这些小单词列表不包含冠状病毒术语。
I had thought that tokenizers would be an easy way to objectively measure new vocabulary. Instead, I found that the output depended a lot on parameters (such as vocabulary size) and the token splits (typewriter vs. type+writer) were not obviously right or wrong, one way or the other.Re-focusing, I decided to use words from COVID-19 glossaries.
我曾经认为,分词器将是一种客观地衡量新词汇的简便方法。 相反,我发现输出在很大程度上取决于参数(例如词汇量),并且令牌拆分( typewriter与type + writer )显然不是对还是错,一种或另一种方式。使用COVID-19词汇中的单词。
[MASK]后面是什么字? (What word is behind the [MASK]?)
CoLab notebook: colab.research.google.com/drive/1lQfWFOPZCO5IVVw_3YwiXEY96fZ1zhoV
CoLab笔记本: colab.research.google.com/drive/1lQfWFOPZCO5IVVw_3YwiXEY96fZ1zhoV
Maintain social ___ throughout the Museum. Capacity will be limited.
在整个博物馆内保持社交___。 容量将受到限制。
BERT suggests:atmosphere (11.2031), services (10.9623), programs (10.9131), events (10.8517), activities (10.4883), networks (10.4397), relations (10.4010), connections (10.0624)
BERT建议:气氛(11.2031),服务(10.9623),程序(10.9131),事件(10.8517),活动(10.4883),网络(10.4397),关系(10.4010),联系(10.0624)
T5 suggests: interaction, media presence, “and educational programs", spaces, media, “and educational programming”, gatherings, activities, “interaction with visitors”. [T5 is not typically used for mask-fill, so it’s unclear to me how these results are weighted and sorted].
T5建议:交互,媒体存在,“和教育程序”,空间,媒体,“和教育程序”,聚会,活动,“与访客的交互” [T5通常不用于口罩填充,所以我不清楚这些结果如何加权和排序]。
Researchers produced a detailed picture of the part of SARS-CoV-2 — the novel ___ that causes COVID-19.
研究人员详细绘制了SARS-CoV-2的一部分,这是导致COVID-19的新型___。
BERT suggests: gene, virus, protein, drug, enzymeT5 suggests: virus, vaccine, strain, COVID, SARS virus [at first I was impressed by COVID and SARS appearing here, but they appear to be repeated from the original sentence]
BERT建议:基因,病毒,蛋白质,药物,酶T5建议:病毒,疫苗,毒株,COVID,SARS病毒[起初,这里出现的COVID和SARS给我留下了深刻的印象,但它们似乎与原始句子重复了]
Temperature checks are required for all visitors, and everyone over the age of two must wear a ___.
所有来访者都必须进行体温检查,两岁以上的每个人都必须佩戴___。
BERT suggests: uniform, coat, suit, passport, blanketT5 suggests: hat, life jacket, helmet, seatbelt, face mask, jumper[‘face mask’ here is interesting]
BERT建议:制服,外套,西服,护照,毯子T5建议:帽子,救生衣,头盔,安全带,口罩,套头衫[“口罩”在这里很有趣]
For a contactless __, use your digital membership card.
对于非接触式__,请使用您的数字会员卡。
BERT: membership, account, card, service, phoneT5: payment, payment option, card payment, payment system[it’s interesting that BERT did not think of contactless payment at all]
BERT:成员身份,帐户,卡,服务,电话T5:付款,付款选项,卡付款,付款系统[有趣的是,BERT根本没有想到非接触式付款]
Wikipedia was difficult to work with in the previous section, so I changed gears and used daily Reddit comment dumps on pushshift.io.On April 1st, there were 20,000 comments with ‘covid’ or ‘coronavirus’ and none of my other keywords, so the sentence is otherwise legible.
上一节中很难使用Wikipedia,因此我更改了档位,并在pushshift.io上使用了Reddit的每日评论转储。 4月1日 ,有20,000条带有'covid'或'coronavirus'的注释,而我没有其他关键字,因此该句子清晰易读。
After many test sentences, I decided to count BERT’s suggestions with a score ≥ 9.8. After summing these scores over all of my example sentences, we get a list of most-associated words for ‘Wuhan’:
经过许多测试句子后,我决定对BERT的建议计数≥9.8。 在将所有示例句子中的分数相加后,我们获得了与“武汉”最相关的单词列表:
‘Distancing’ continues to be an oddity. As you can see from these sentences, the most recommended fill-ins are any words which often follow ‘social’.
“距离”仍然是一个奇怪的现象。 从这些句子中可以看出,最推荐的填充词是经常出现在“社交”后面的任何单词。

将单词插入令牌生成器和向量空间 (Inserting words into tokenizer and vector-space)
HuggingFace already has a function to add words to tokenizers.
HuggingFace已经具有向标记器添加单词的功能 。
Ironically, adding COVID to the T5 tokenizer actually made it disappear from the suggested words from T5 (as it now is assigning that word to a random vector). Calling t5_mlm.get_input_embeddings(), I discover that T5 inputs have dimension 32,128, and my new vocabulary index starts at 32,100. The weights applied to this word (embedding.weight[32101]) are gettable and settable. By zeroing its embedding, all of the model’s suggestions for any sentence become ‘COVID COVID COVID’.
具有讽刺意味的是,将COVID添加到T5标记器实际上使它从T5的建议单词中消失了(因为它现在正在将该单词分配给随机向量)。 调用t5_mlm.get_input_embeddings() ,我发现T5输入的维度为32,128,而我的新词汇索引从32,100开始。 应用于此单词的权重( embedding.weight[32101] )是可设置的和可设置的。 通过将其嵌入置零,该模型对任何句子的所有建议都将变为“ COVID COVID COVID”。
I repeat the process on BERT. Thanks to the HuggingFace libraries, these very different models work similarly. I can use add_tokens and get_added_vocab to review my choices. New tokens start at 30,522. In this case, though, get_input_embeddings reveals that the BERT model expects no new inputs. Luckily this issue explained how to usemodel.resize_token_embeddings. I zeroed out these initial tensors, but there were no changes to output as I’d seen with T5.
我在BERT上重复此过程。 多亏了HuggingFace库,这些非常不同的模型可以类似地工作。 我可以使用add_tokens和get_added_vocab来查看我的选择。 新代币从30,522开始。 但是,在这种情况下, get_input_embeddings显示BERT模型不需要新输入。 幸运的是, 此问题说明了如何使用model.resize_token_embeddings 。 我将这些初始张量归零,但是输出没有改变,就像我在T5中看到的那样。
Based on the thousands of Reddit sentences, I give each word a weighted average based on the most frequent top-ranking vectors over many sentences.
基于数千个Reddit句子,我根据许多句子中最频繁出现的排名最高的向量,为每个单词赋予了加权平均值。
测量精度 (Measuring accuracy)
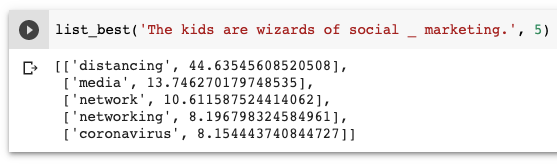
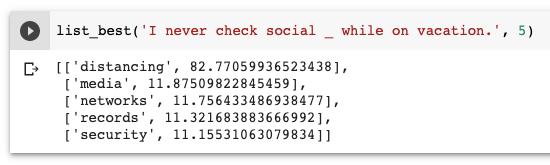
Re-running the code with the new vectors, ‘Wuhan’ is listed first 28% of the time, and appears in the top five 42% of the time. These numbers are 60/61% for ‘coronavirus’, and 89/94% for ‘distancing’.
使用新的向量重新运行代码,“武汉”在28%的时间中排名第一,并在42%的时间中排名前五位。 对于“冠状病毒”,这些数字是60/61%,对于“距离”,这些数字是89/94%。
The main problem with my approach is overfitting — if a single word is suggested most of the time, the current program will simply try to follow that word’s vector as closely as possible. If there are two equally suitable words (such as, flu/measles vaccine), the averaging would place this new word in between, creating an overpowered area which prefers ‘coronavirus’ in many sentences which would normally fit ‘flu’, ‘measles’, or either word.
我的方法的主要问题是过拟合-如果在大多数情况下建议使用单个单词,则当前程序将仅尝试尽可能接近该单词的向量。 如果有两个同样合适的词(例如流感/麻疹疫苗),则取平均值将在两个词之间插入一个平均值,从而形成一个过大的区域,在许多通常适合“流感”,“麻疹”的句子中更喜欢“冠状病毒”或任何一个字。

Relevant code and links: colab.research.google.com/drive/1lQfWFOPZCO5IVVw_3YwiXEY96fZ1zhoV
相关代码和链接: colab.research.google.com/drive/1lQfWFOPZCO5IVVw_3YwiXEY96fZ1zhoV
提案:最新自然语言和知识的基准 (Proposal: a benchmark for up-to-date natural language + knowledge)
Now that I have a word list and corresponding lists of words that are expected by pre-COVID language models, I changed my vision for model patching. The metrics should encourage ML researchers to patch/update their models, but not overfit and overwrite existing language.They should contain coronavirus-related examples, but also breaking news headlines which would be best solved with a knowledge graph.
现在,我有了一个单词列表以及COVID之前的语言模型所期望的相应单词列表,我改变了对模型修补的看法。 这些指标应鼓励ML研究人员修补/更新其模型,但不宜过度拟合和覆盖现有语言,它们应包含与冠状病毒相关的示例,但也应包含突发新闻标题,最好用知识图来解决。
- Relevant new tokens: either crowdsource tokens, monitor frequently-used words missing from BERT and similar models, or use Mechanical Turk. Eventually this would include phrases (‘social distancing’, ‘Green New Deal’).
相关的新令牌:要么众包令牌,监视BERT和类似模型中缺少的常用单词,要么使用Mechanical Turk。 最终,这将包括短语(“社交疏远”,“绿色新政”)。 - Training and test sentences: weekly, extract single sentences from recent headlines, Reddit comments, and Wikipedia edits. Filter out sentences which use multiple new tokens.
训练和测试句子:每周一次,从最近的头条新闻,Reddit评论和Wikipedia编辑中提取单个句子。 过滤使用多个新标记的句子。 - [MASK] out the new words, and see which words are suggested by commonly-used pre-trained models.
[MASK]找出新单词,并查看常用的预训练模型建议的单词。 Extract an equal number of example sentences to balance out each new token. For example, for every ‘Wuhan’ or ‘social distancing’ sentence, there should be a similar sentence using ‘Beijing’ or ‘social media’. This tests against overfitting. I originally called these as ‘adversarial examples’, but these should also be select real-world sentences.
提取相等数量的例句以平衡每个新标记。 例如,对于每个“武汉”或“社交疏远”句子,都应使用“北京”或“社交媒体”使用类似的句子。 这可以防止过度拟合。 我最初称这些为“对抗性示例”,但这些也应该是精选的真实句子。
I’m not sure how to design this fairly because masked sentences can be ambiguous or simultaneously true (“I visited _ once” could easily be filled with ‘Wuhan’ or ‘China’). This suggests that I should provide more context beyond a single sentence.
我不确定如何公平地设计它,因为被掩盖的句子可能是模棱两可的,或者可能同时是真实的(“我曾经来过_一次”很容易被“武汉”或“中国”填充)。 这表明我应该提供一个句子之外的更多上下文。
- Models submitted to the benchmark are tested on masked train and test sentences, and continue to be offered training examples.
提交给基准的模型将在掩盖的训练和测试语句中进行测试,并继续提供训练示例。
翻译自: https://medium.com/swlh/patching-pre-trained-language-models-28ed6ea8b0bc
网页怎么预先加载模型
相关文章:
- 字典(python学习)
- Buffer之position,limit,capacity
- CF Canada Cup 2016 D 优先队列
- 138 - 打球过程
- git core.autocrlf配置说明
- android自定义view(三)绘制表格和坐标系
- 函数的谓词是什么? cin的返回值是什么?
- c语言中char * string,浅析string 与char* char[]之间的转换
- 两个超实用的 Kubernetes 集群中 Flannel 故障排除案例
- 程序员常用资源工具集合
- Java 程序员常用资源工具集合
- 看看别人怎么学习的。
- Java爬虫之批量下载LibreStock图片(可输入关键词查询下载)
- 一次性能优化引发的思考
- 你有什么经验一定要分享给初入职场的新人?
- 凡事都要追求公平?还真不一定!
- 想要做大事,就要有高效的协作机制
- 无论夫妻还是情人,能陪你一生的男人,都有这个特征
- 凡事别太认真执着
- 怎样做一个更有价值的人
- 【转】凡事事必躬亲 是一种恶习
- 【转载】巴菲特:比能力更重要的是靠谱
- 一个人靠不靠谱,就看这三点: 凡事有交代,件件有着落,事事有回音
- 凡事有交代
- API知识点脑图
- 中铁汇达保险经纪保单计算个人理解
- vue的props父向子传值
- 深拷贝方式
- 获取浏览器版本
- 获取上个月的第一天和最后一天和当前月最后一天
网页怎么预先加载模型_修补预先训练的语言模型相关推荐
- 网页怎么预先加载模型_使用预先训练的模型进行转移学习
网页怎么预先加载模型 深度学习 (Deep Learning) 什么是转学? (What is Transfer Learning?) Transfer learning is a research ...
- babylonjs 分部加载模型_如何使用BabylonJS加载OBJ或STL模型
BabylonJS(也就是babylon.js,这是一个和three.js类似的WebGL开发框架),更多的用在游戏领域. 本文说明和演示如何使用babylon.js来加载一个标准3d模型文件,如OB ...
- babylonjs 分部加载模型_基于Babylonjs自制WebGL3D模型编辑器
一.总述 当代WebGL编程所使用的3D模型大多是从3DsMax模型或Blender模型转化而来,这种工作模式比较适合3D设计师和3D程序员分工配合的场景.但对于单兵作战的WebGL爱好者来讲这种模式 ...
- 加载dict_Pytorch模型resume training,加载模型基础上继续训练
Step1:首先查看源码train.py中如何保存模型的: checkpoint_dict = {'epoch': epoch, 'model_state_dict': model.state_dic ...
- pytorch 加载模型_福利,PyTorch中文版官方教程来啦(附下载)
PyTorch 中文版官方教程来了. PyTorch 是近期最为火爆的深度学习框架之一,然而其中文版官方教程久久不来.近日,一款完整的 PyTorch 中文版官方教程出炉,读者朋友从中可以更好的学习了 ...
- python加载模型_解决python 无法加载downsample模型的问题
downsample 在最新版本里面修改了位置 from theano.tensor.single import downsample (旧版本) 上面以上的的import会有error raise: ...
- babylonjs 分部加载模型_用基于WebGL的BabylonJS来共享你的3D扫描模型
用基于WebGL的BabylonJS来共享你的3D扫描模型 本文由 极客范 - 杰克祥子 翻译自 Andy Beaulieu.欢迎加入极客翻译小组,同我们一道翻译与分享.转载请参见文章末尾处的要求. ...
- babylonjs 分部加载模型_使用 Babylon.js 在 HTML 页面加载 3D 对象
五一 Windwos Blogs 推了一篇博客, Babylon.js v3.2 发布了.因为一直有想要在自己博客上加载 3D 对象的冲动,这两天正好看到了,就动手研究研究.本人之前也并没有接触过 W ...
- babylonjs 分部加载模型_初学WebGL引擎-BabylonJS:第2篇-基础模型体验
此次学习进度会比之前快很多,有了合适的学习方法后也就会有更多的乐趣产生了. 接上一章代码 上章代码 Babylon - Getting Started }#renderCanvas{width:100 ...
最新文章
- iOS tableViewCell自适应高度 第三发类库
- Newtonsoft.Json(Json.net)的基本用法
- html语言 input button,Html-button和input的区别
- linux内核那些事之虚拟空间划分
- python 写入excel_基于Python实现Excel的读写
- 使用Kmeans聚类分析对复杂的数据进行分类
- 阶段1 语言基础+高级_1-3-Java语言高级_09-基础加强_第2节 反射_8_反射_Class对象功能_获取Field...
- web服务器共享文件夹,局域网web共享文件夹的方法
- python笔记:太困了,读取并显示按行业分类的股票数据提提神
- 怎么把m4a转换成mp3,分享几个方法给大家!
- san mysql,高性能MySQL :应该用SAN吗?
- Genome Aggregation Database (gnomAD) 简介 | 参考人群等位基因频率数据库
- 时光倒流:业务支撑那些事(四)
- 假如生活欺骗了你 (俄)普希金
- Java的时代依然还在,合格的Java工程师成为紧缺人才
- □ 影片名:《审死官》(1203) 在线播放
- java的Overriding和Overloading
- 3d建模师工资高吗?
- 论文写作的技巧与书籍推荐(2020年版)
- 计算机无法ghost安装系统安装系统安装,惠普电脑无法安装GHOST系统的修复教程...
热门文章
- crosstab交叉表_用Python统计推断——交叉表篇(上:crosstab与热图)
- 收到了CSDN送的图书,表示感谢|对《程序员的三门课》的一表格表示疑问
- 文章标题 execution(* cn.sxt.dao.impl.*.*(..))解释
- 【现代遗传学原理-基因和基因组学】
- Oracle数据库:oracle内连接inner join on,多表查询各种自链接、内连接、外连接的练习示例
- Linux:冯诺伊曼体系结构 | 操作系统 | 显卡 | 主板
- java 级联删除_JPA级联删除
- mysql数据库教程级联_Mysql实现级联操作(级联更新、级联删除)
- 生成划掉的字_哪种备忘录划删除线,能划掉文字在字中间划线的便签
- 手把手教你做个AR涂涂乐