Introduction to Conditional Random Fields
Introduction to Conditional Random Fields
Imagine you have a sequence of snapshots from a day in Justin Bieber’s life, and you want to label each image with the activity it represents (eating, sleeping, driving, etc.). How can you do this?
One way is to ignore the sequential nature of the snapshots, and build a per-image classifier. For example, given a month’s worth of labeled snapshots, you might learn that dark images taken at 6am tend to be about sleeping, images with lots of bright colors tend to be about dancing, images of cars are about driving, and so on.
By ignoring this sequential aspect, however, you lose a lot of information. For example, what happens if you see a close-up picture of a mouth – is it about singing or eating? If you know that the previous image is a picture of Justin Bieber eating or cooking, then it’s more likely this picture is about eating; if, however, the previous image contains Justin Bieber singing or dancing, then this one probably shows him singing as well.
Thus, to increase the accuracy of our labeler, we should incorporate the labels of nearby photos, and this is precisely what a conditional random field does.
Part-of-Speech Tagging
Let’s go into some more detail, using the more common example of part-of-speech tagging.
In POS tagging, the goal is to label a sentence (a sequence of words or tokens) with tags like ADJECTIVE, NOUN, PREPOSITION, VERB, ADVERB, ARTICLE.
For example, given the sentence “Bob drank coffee at Starbucks”, the labeling might be “Bob (NOUN) drank (VERB) coffee (NOUN) at (PREPOSITION) Starbucks (NOUN)”.
So let’s build a conditional random field to label sentences with their parts of speech. Just like any classifier, we’ll first need to decide on a set of feature functions fifi.
Feature Functions in a CRF
In a CRF, each feature function is a function that takes in as input:
- a sentence s
- the position i of a word in the sentence
- the label lili of the current word
- the label li−1li−1 of the previous word
and outputs a real-valued number (though the numbers are often just either 0 or 1).
(Note: by restricting our features to depend on only the current and previous labels, rather than arbitrary labels throughout the sentence, I’m actually building the special case of a linear-chain CRF. For simplicity, I’m going to ignore general CRFs in this post.)
For example, one possible feature function could measure how much we suspect that the current word should be labeled as an adjective given that the previous word is “very”.
Features to Probabilities
Next, assign each feature function fj a weight λj (I’ll talk below about how to learn these weights from the data). Given a sentence s, we can now score a labeling l of s by adding up the weighted features over all words in the sentence:
![]()
(The first sum runs over each feature function jj, and the inner sum runs over each position ii of the sentence.)
Finally, we can transform these scores into probabilities p(l|s) between 0 and 1 by exponentiating and normalizing:
![]()
Example Feature Functions
So what do these feature functions look like? Examples of POS tagging features could include:
f1(s,i,li,li−1)=1 if li= ADVERB and the ith word ends in “-ly”; 0 otherwise. ** If the weight λ1λ1 associated with this feature is large and positive, then this feature is essentially saying that we prefer labelings where words ending in -ly get labeled as ADVERB.
f2(s,i,li,li−1)=1 if i=1, li= VERB, and the sentence ends in a question mark; 0 otherwise. ** Again, if the weight λ2λ2 associated with this feature is large and positive, then labelings that assign VERB to the first word in a question (e.g., “Is this a sentence beginning with a verb?”) are preferred.
f3(s,i,li,li−1)=1 if li−1= ADJECTIVE and li=li= NOUN; 0 otherwise. ** Again, a positive weight for this feature means that adjectives tend to be followed by nouns.
f4(s,i,li,li−1)=1 if li−1= PREPOSITION and li= PREPOSITION. ** A negative weight λ4λ4 for this function would mean that prepositions don’t tend to follow prepositions, so we should avoid labelings where this happens.
And that’s it! To sum up: to build a conditional random field, you just define a bunch of feature functions (which can depend on the entire sentence, a current position, and nearby labels), assign them weights, and add them all together, transforming at the end to a probability if necessary.
Now let’s step back and compare CRFs to some other common machine learning techniques.
Smells like Logistic Regression…
The form of the CRF probabilities
![]()
might look familiar.
That’s because CRFs are indeed basically the sequential version of logistic regression: whereas logistic regression is a log-linear model for classification, CRFs are a log-linear model for sequential labels.
Looks like HMMs…
Recall that Hidden Markov Models are another model for part-of-speech tagging (and sequential labeling in general). Whereas CRFs throw any bunch of functions together to get a label score, HMMs take a generative approach to labeling, defining
![]()
where
 are transition probabilities (e.g., the probability that a preposition is followed by a noun);
are transition probabilities (e.g., the probability that a preposition is followed by a noun);- are emission probabilities (e.g., the probability that a noun emits the word “dad”).
So how do HMMs compare to CRFs? CRFs are more powerful – they can model everything HMMs can and more. One way of seeing this is as follows.
Note that the log of the HMM probability is ![]() . This has exactly the log-linear form of a CRF if we consider these log-probabilities to be the weights associated to binary transition and emission indicator features.
. This has exactly the log-linear form of a CRF if we consider these log-probabilities to be the weights associated to binary transition and emission indicator features.
That is, we can build a CRF equivalent to any HMM by…
Thus, the score p(l|s)p(l|s) computed by a CRF using these feature functions is precisely proportional to the score computed by the associated HMM, and so every HMM is equivalent to some CRF.
However, CRFs can model a much richer set of label distributions as well, for two main reasons:
- CRFs can define a much larger set of features. Whereas HMMs are necessarily local in nature (because they’re constrained to binary transition and emission feature functions, which force each word to depend only on the current label and each label to depend only on the previous label), CRFs can use more global features. For example, one of the features in our POS tagger above increased the probability of labelings that tagged the first word of a sentence as a VERB if the end of the sentence contained a question mark.
- CRFs can have arbitrary weights. Whereas the probabilities of an HMM must satisfy certain constraints (e.g., 0<=p(wi|li)<=1,, the weights of a CRF are unrestricted (e.g., logp(wi|li)logp(wi|li) can be anything it wants).
Learning Weights
Let’s go back to the question of how to learn the feature weights in a CRF. One way, unsurprisingly, is to use gradient descent.
Assume we have a bunch of training examples (sentences and associated part-of-speech labels). Randomly initialize the weights of our CRF model. To shift these randomly initialized weights to the correct ones, for each training example…
In other words, every step takes the difference between what we want the model to learn and the model’s current state, and moves λiλi in the direction of this difference.
Finding the Optimal Labeling
Suppose we’ve trained our CRF model, and now a new sentence comes in. How do we do label it?
The naive way is to calculate p(l|s)p(l|s) for every possible labeling l, and then choose the label that maximizes this probability. However, since there are kmkm possible labels for a tag set of size k and a sentence of length m, this approach would have to check an exponential number of labels.
A better way is to realize that (linear-chain) CRFs satisfy an optimal substructure property that allows us to use a (polynomial-time) dynamic programming algorithm to find the optimal label, similar to the Viterbi algorithm for HMMs.
A More Interesting Application
Okay, so part-of-speech tagging is kind of boring, and there are plenty of existing POS taggers out there. When might you use a CRF in real life?
轻松理解条件随机场(CRF)
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?
一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。
这样可行吗?
乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。
所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。这——就是条件随机场(CRF)大显身手的地方!
从例子说起——词性标注问题
啥是词性标注问题?
非常简单的,就是给一个句子中的每个单词注明词性。比如这句话:“Bob drank coffee at Starbucks”,注明每个单词的词性后是这样的:“Bob (名词) drank(动词) coffee(名词) at(介词) Starbucks(名词)”。
下面,就用条件随机场来解决这个问题。
以上面的话为例,有5个单词,我们将:(名词,动词,名词,介词,名词)作为一个标注序列,称为l,可选的标注序列有很多种,比如l还可以是这样:(名词,动词,动词,介词,名词),我们要在这么多的可选标注序列中,挑选出一个最靠谱的作为我们对这句话的标注。
怎么判断一个标注序列靠谱不靠谱呢?
就我们上面展示的两个标注序列来说,第二个显然不如第一个靠谱,因为它把第二、第三个单词都标注成了动词,动词后面接动词,这在一个句子中通常是说不通的。
假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们至少可以说,凡是标注中出现了动词后面还是动词的标注序列,要给它负分!!
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
定义CRF中的特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
句子s(就是我们要标注词性的句子)
i,用来表示句子s中第i个单词
l_i,表示要评分的标注序列给第i个单词标注的词性
l_i-1,表示要评分的标注序列给第i-1个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
从特征函数到概率
定义好一组特征函数后,我们要给每个特征函数f_j赋予一个权重λ_j。现在,只要有一个句子s,有一个标注序列l,我们就可以利用前面定义的特征函数集来对l评分。
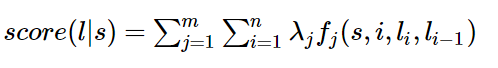
上式中有两个求和,外面的求和用来求每一个特征函数f_j评分值的和,里面的求和用来求句子中每个位置的单词的的特征值的和。
对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值p(l|s),如下所示:
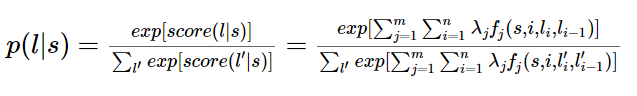
几个特征函数的例子
前面我们已经举过特征函数的例子,下面我们再看几个具体的例子,帮助增强大家的感性认识。
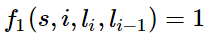
当l_i是“副词”并且第i个单词以“ly”结尾时,我们就让f1 = 1,其他情况f1为0。不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列
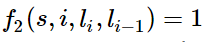
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。
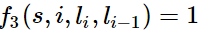
当l_i-1是介词,l_i是名词时,f3 = 1,其他情况f3=0。λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。
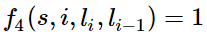
如果l_i和l_i-1都是介词,那么f4等于1,其他情况f4=0。这里,我们应当可以想到λ4是负的,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
好了,一个条件随机场就这样建立起来了,让我们总结一下:
为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
CRF与逻辑回归的比较
观察公式:
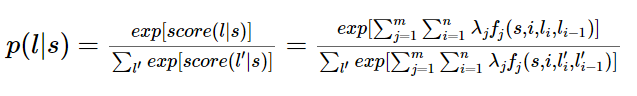
是不是有点逻辑回归的味道?
事实上,条件随机场是逻辑回归的序列化版本。逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型。
CRF与HMM的比较
对于词性标注问题,HMM模型也可以解决。HMM的思路是用生成办法,就是说,在已知要标注的句子s的情况下,去判断生成标注序列l的概率,如下所示:
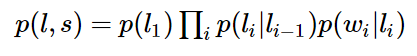
这里:
p(l_i|l_i-1)是转移概率,比如,l_i-1是介词,l_i是名词,此时的p表示介词后面的词是名词的概率。
p(w_i|l_i)表示发射概率(emission probability),比如l_i是名词,w_i是单词“ball”,此时的p表示在是名词的状态下,是单词“ball”的概率。
那么,HMM和CRF怎么比较呢?
答案是:CRF比HMM要强大的多,它可以解决所有HMM能够解决的问题,并且还可以解决许多HMM解决不了的问题。事实上,我们可以对上面的HMM模型取对数,就变成下面这样:
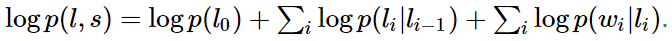
我们把这个式子与CRF的式子进行比较:
不难发现,如果我们把第一个HMM式子中的log形式的概率看做是第二个CRF式子中的特征函数的权重的话,我们会发现,CRF和HMM具有相同的形式。
换句话说,我们可以构造一个CRF,使它与HMM的对数形式相同。怎么构造呢?
对于HMM中的每一个转移概率p(l_i=y|l_i-1=x),我们可以定义这样的一个特征函数:
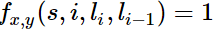
该特征函数仅当l_i = y,l_i-1=x时才等于1。这个特征函数的权重如下:
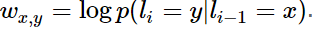
同样的,对于HMM中的每一个发射概率,我们也都可以定义相应的特征函数,并让该特征函数的权重等于HMM中的log形式的发射概率。
用这些形式的特征函数和相应的权重计算出来的p(l|s)和对数形式的HMM模型几乎是一样的!
用一句话来说明HMM和CRF的关系就是这样:
每一个HMM模型都等价于某个CRF
每一个HMM模型都等价于某个CRF
每一个HMM模型都等价于某个CRF
但是,CRF要比HMM更加强大,原因主要有两点:
CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,如这个特征函数:
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。
CRF可以使用任意的权重 将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,如
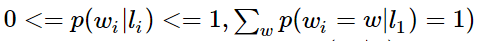
但在CRF中,每个特征函数的权重可以是任意值,没有这些限制。
Introduction to Conditional Random Fields相关推荐
- 条件随机场CRF简介Introduction to Conditional Random Fields
Imagine you have a sequence of snapshots from a day in Justin Bieber's life, and you want to label e ...
- 条件随机场介绍(7)—— An Introduction to Conditional Random Fields
参考文献 [1] S.M.AjiandR.J.McEliece,"Thegeneralizeddistributivelaw,"IEEETrans- actions on Info ...
- 条件随机场介绍(5)—— An Introduction to Conditional Random Fields
5. 参数估计 本节我们讨论如何估计条件随机场的参数\(\theta = \{ \theta_k \}\).在最简单最典型情况下,我们面对的数据是完全标注的独立数据,但是也有关于半监督学习的条件随机场 ...
- 条件随机场(Conditional random fields,CRFs)文献阅读指南
与最大熵模型相似,条件随机场(Conditional random fields,CRFs)是一种机器学习模型,在自然语言处理的许多领域(如词性标注.中文分词.命名实体识别等)都有比较好的应用效果.条 ...
- Conditional Random Fields:ProbabilisticModels for Segmenting and Labeling Sequence Data
Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data 条件随机场:对于段落和 ...
- 条件随机场(conditional random fields) 及代码实现
条件随机场模型是由Lafferty在2001年提出的一种典型的判别式模型.它在观测序列的基础上对目标序列进行建模,重点解决序列化标注的问题条件随机场模型既具有判别式模型的优点,又具有产生式模型考虑到上 ...
- matlab 高斯随机场,条件随机场(Conditional random fields)
条件随机场模型是Lafferty于2001年,在最大熵模型和隐马尔科夫模型的基础上,提出的一种判别式概率无向图学习模型,是一种用于标注和切分有序数据的条件概率模型.CRF最早是针对序列数据分析提出的, ...
- [Style Transfer]—Combining Markov Random Fields and Convolutional Neural Network for Image Synthesis
Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis 基于马尔科夫随机场和卷积神经网 ...
- 基于Continuous Conditional Neural Fields for Structured Regression的人脸特征点检测和头部姿态估计
Continuous Conditional Neural Fields for Structured Regression 效果图:头部姿态和特征点检测
- Predicting Human Microbe-Drug Associations via Graph Convolutional Network with Conditional Random F
l论文题目:Predicting Human Microbe-Drug Associations via Graph Convolutional Network with Conditional Ra ...
最新文章
- 小白给小白详解维特比算法(二)
- python3 面向对象(一)
- python语言标号_Python 编码为什么那么蛋疼?
- Linux 有关管理进程的命令小结
- [No00009B]win10快捷键大全
- ann人工神经网络_深度学习-人工神经网络(ANN)
- 使用ArcGIS Server发布我们的数据
- Free tour II SPOJ - FTOUR2 点分治 + 树状数组
- 关于SubSonic3.0生成的表名自动加复数(s)的“用户代码未处理SqlException,对象名'xxxs'无效”异常处理...
- 访问自己的网站有病毒提示,为什么?
- 一个WinForm记事本程序(包含主/下拉/弹出菜单/打开文件/保存文件/打印/页面设置/字体/颜色对话框/剪切版操作等等控件用法以及记事本菜单事件/按键事件的具体代码)...
- 页面优化必须知道的技能:meta标签中的http-equiv属性使用介绍
- Pandas高级教程之:时间处理
- linux中如何分割字符串数组中,Linux教程——Shell中字符串与数组操作实例
- CSU2020期中测试题(2)WOWO爬水井
- 密码学基础(三)密码分析
- 优秀的人都在读的10本好书!
- 验证sqlserver 2000 sp4补丁是否安装成功(安装补丁后可以远程访问)
- 从“人、货、场”搭建数据指标体系,助力电商增长
- 小闫陪你入门 Java (二)
热门文章
- 编译ok6410linux内核,OK6410新手学习心得(一)Linux中加入led驱动及测试程序详解...
- Struts2-03-拦截器(BOS物流项目用户登录拦截)
- Kotlin实战【三】表示与选择
- python基础篇——列表与列表算法(上)
- android package.xml,文件没问题的情况下not read packageName from xxx\AndroidManifest.xml?
- c语言中代码中的作用,C语言中#的神奇作用
- java equals重写原则_如何正确的重写equals方法(避免各种陷阱)
- ie型lfsr_什么是PRBS
- linux apache 配置视频教程,《Linux服务器配置视频教程》ubuntu centos apache iptables 后盾网向军老师主讲[WMV]...
- 图象关于y轴对称是什么意思_关于新风系统的全热交换到底是什么意思?艾尔文技术解读篇...