python爬取一张图片并保存_python爬取网页图片并保存到本地
先把原理梳理一下:首先我们要爬取网页的代码,然后从中提取图片的地址,通过获取到的地址来下载数据,并保存在文件中,完成。
下面是具体步骤:
先确定目标,我挑选的是国服守望先锋的官网的英雄页面,我的目标是爬取所有的英雄的图片
页面是这样的
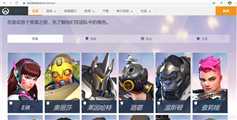
首先做的就是得到它的源代码找到图片地址在哪里
这个函数最终会返回网页代码
def getHtml(url):
html = requests.get(url)
return html.text
将其先导入文本文件观察
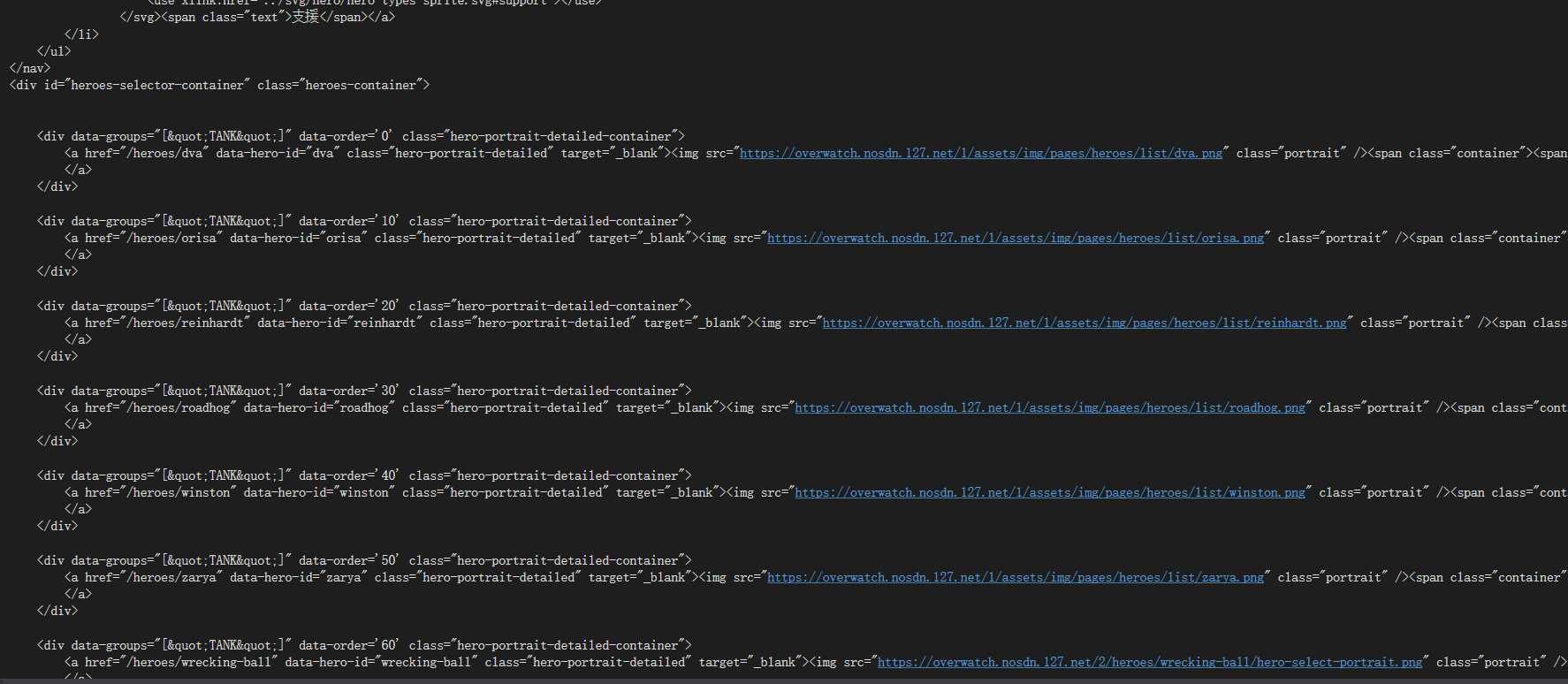
发现图片的地址所在位置格式是这样

因此就可以依此写出正则表达式,并从网页代码中将图片地址提取出来
imagelist=re.findall(‘img src="(.*?)" class="portrait"‘,html)
上面这句话得到的就是图片地址的集合
之后要做的就是遍历集合中的地址,依此下载并保存到目标的文件夹中
下面是项目完整代码
# -*- coding: utf-8 -*-
‘‘‘
Created on 2020年3月12日
@author: 20514
‘‘‘
import requests
import re
#打开网页,获取网页源码
def getHtml(url):
html = requests.get(url)
return html.text
def getImag(html):
imagelist=re.findall(‘img src="(.*?)" class="portrait"‘,html)
pat = ‘list/(.*?).png‘
ex = re.compile(pat)
i=1
for url in imagelist:
print ‘Downloding:‘+url
#从图片地址下载数据
image=requests.get(url)
# 获取英雄名(这里可以自己为文件取名就行,下面的name变量是从图片地址中提取到的英雄名)
pat = ‘list/(.*?).png‘
ex = re.compile(pat)
if ex.search(url):
name=ex.search(url).group(1)
else:
pat =‘heroes/(.*?)/hero-select‘
ex = re.compile(pat)
if ex.search(url):
name=ex.search(url).group(1)
else:
name=‘new‘+str(i)+‘?‘
i=i+1
#在目标路径创建相应文件
f=open(‘C:\\Users\\20514\\Desktop\\owhero\\‘+name+‘.png‘,‘wb‘)
#将下载到的图片数据写入文件
f.write(image.content)
f.close()
return ‘结束‘
print(‘获取ow官网英雄图片‘)
url=‘https://ow.blizzard.cn/heroes/‘
print(‘正在获取图片‘)
html=getHtml(url)
print(‘下载图片中‘)
print(getImag(html))
print(‘下载完成‘)
效果:
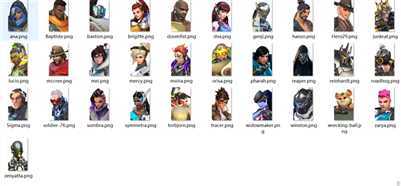
-------------------------------------------------------------------------------------------------------------------------------------
近几天学了点通过python爬取网页的知识,不得不说跟java相比起来,这方面python真的方便太多了。
原文:https://www.cnblogs.com/liuleliu/p/12482021.html
python爬取一张图片并保存_python爬取网页图片并保存到本地相关推荐
- node.js 爬虫 实现爬取网页图片并保存到本地
node.js 爬虫 实现爬取网页图片并保存到本地 没有废话直接看代码 /*** 请求网站数据* 将数据保存本地文件*/ //不同协议引用不同模块,http https const http = re ...
- python爬取音乐并保存_Python爬取网易云音乐上评论火爆的歌曲
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论.但是,网易云音乐并没有提供热评排行 ...
- python爬取淘宝商品信息_python爬取淘宝商品信息并加入购物车
先说一下最终要达到的效果:谷歌浏览器登陆淘宝后,运行python项目,将任意任意淘宝商品的链接传入,并手动选择商品属性,输出其价格与剩余库存,然后选择购买数,自动加入购物车. 在开始爬取淘宝链接之前, ...
- python爬取微博数据存入数据库_Python爬取新浪微博评论数据,写入csv文件中
因为新浪微博网页版爬虫比较困难,故采取用手机网页端爬取的方式 操作步骤如下: 1. 网页版登陆新浪微博 2.打开m.weibo.cn 3.查找自己感兴趣的话题,获取对应的数据接口链接 4.获取cook ...
- python可以爬取的内容有什么_Python爬取视频(其实是一篇福利)过程解析 Python爬虫可以爬取什么...
如何用python爬取视频网站的数据 如何用python爬取js渲染加载的视频文件不是每个人都有资格说喜欢,也不是每个人都能选择伴你一生! 有哪位大神指导下,有些视频网站上的视频文件是通过 js 加载 ...
- python测试脚本截图_Python+selenium实现截图图片并保存截取的图片
这篇文章介绍如何利用Selenium的方法进行截图,在测试过程中,是有必要截图,特别是遇到错误的时候进行截图.在selenium for Python中主要有三个截图方法,我们挑选其中最常用的一种. ...
- python抓取贴吧_python抓取百度贴吧-校花吧,网页图片
该楼层疑似违规已被系统折叠 隐藏此楼查看此楼 #!/usr/bin/python3 #code=utf-8 import urllib.request import re path = "C ...
- python爬虫网页图片并保存到本地
#coding=utf-8 import urllib import re #py抓取页面图片并保存到本地 #获取页面信息 def getHtml(url): page = urllib.urlope ...
- python爬取一张图片并保存_python爬取百度图片并保存到本地
安装scrapy pip install Scrapy 进入终端,切换到自己项目代码的工作空间下,执行 scrapy startproject baidu_pic_spider 生成如下工程文件: i ...
最新文章
- yii2.0验签组件(jwt)
- 有一种灾难,叫数据中心被大火烧了
- 学计算机怎样才能考上大学,中国式家长考清华北大方法 重点大学怎么才能考上...
- 【Level 08】U06 Good Feeling L6 A 3D experience
- Linux虚拟化KVM-Qemu分析(十)之virtio驱动
- 组策略之文件夹的重定向
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_05 IO字符流_2_字符输入流读取字符数据...
- Xshell 7免费版下载及安装
- oracle讲表通过主键去重,数据库试题,数据库基础试题及答案
- 数学建模的论文格式以及visio画图
- SpringCloud-Netflix-04-Eureka 注册中心
- vue各模块功能范围,webpack属性配置
- Elongated Matrix
- 如何成为技术大牛--摘自牛人
- 计算机桌面 文字大小,电脑屏幕字体怎么调大小_电脑系统字体大小设置方法-win7之家...
- 10分钟读懂什么是产品定位
- Gvim计数器模板经典练习
- python itemgetter函数_[问题解决] sorted函数以及operator.itemgetter函数
- S-AES的加密与解密
- 将csv写入mysql数据库_从.csv文件到数据库