python爬取酷狗音乐_python 爬虫 爬取酷狗音乐
终于到了周末!怎么能少得了我的每周一更的文章呢?

介绍
你是不是常常想要在各大音乐网站上下载音乐?但是网站却逼迫你下载他们的应用?不要怪他们,这只是他们的赚钱的方式(你不下载他们应用,他们怎么赚钱呢)然而,你下载了应用,它们却逼迫你购买vip……没关系,今天我们就来用爬虫手段“制裁”这些网站!首先,就由最简单的酷狗音乐开始爬!
功能概述
让用户输入要搜索的音乐名,然后把所有的音乐以及每一个音乐对应的信息展示给用户。再询问用户要不要下载任何音乐,如果要,则让用户输入音乐对应的id号来下载(支持批量下载)。
找出思路
首先,在获取多首歌曲的信息和下载地址之前,我们需要知道如何获取一首歌的下载地址。
打开www.kugou.com ,在搜索栏里输入你想要查找的歌曲名。按下回车。切换网页之后,点进一首歌曲的播放页。按下F12,调出开发者工具。选择network,然后点all。可以看到,目前是没有任何东西显示的。因为所有的文件已经在你打开开发者工具的时候加载完了,此时此刻,你只需要F5刷新一下网页。好了,现在
你就能看到类似这样的页面。
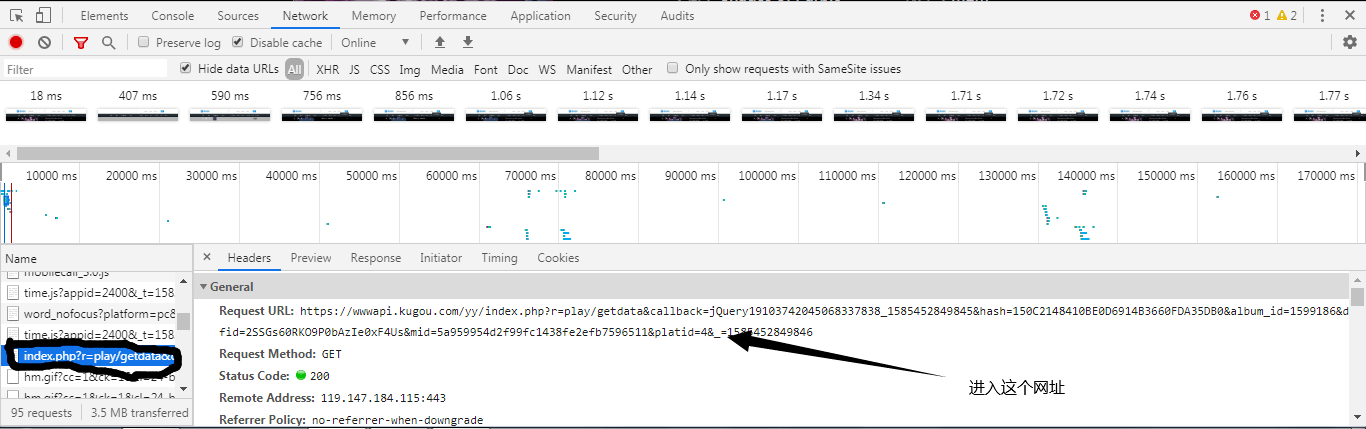
可以看到什么js文件啊,png文件啊,音频文件啊,都没有!因为我们在调出开发者工具之前,网站已经加载完了文件,这个时候,我们只需要按下F5刷新一下网站。好了,所有的文件加载出来了。进入到一个叫做index.php?的文件,然后进入到这个文件的地址。
 、
、
进入这个文件地址之后,这实际上就是音乐的信息(为了方便,我在文章后面就说是信息地址)。我们还可以看到一个叫play_url的东西,这个play_url就是音频的mp3文件地址,可以看到,这些play_url都是把/变成了/。我们不用担心这个,因为网址输入栏会自动帮我们调整成/,但是在用代码实现爬虫的时候,我们就需要把/变成/了。但短时间内,我们先不用管这个。让我们进入到这个网址,咦?这不是我们刚刚播放的音乐吗?

成功之后,我们就有了更大的信心和思路去爬虫。我们只要把每首歌曲的信息地址找出来,然后用正则表达式把每首歌曲的信息和音乐地址获取出来。再一次用爬虫获取到音乐的二进制编码,保存在本地。
那我们如何获取每首歌的信息地址呢?通过拼接地址!让我们看这两首歌的url有啥不同,你就知道了。
来拼接每首歌的信息地址就行了。那歌曲的hash要去那里找呢?回到酷狗的音乐搜索栏,随便搜一首歌按下回车。可以看到这里有好多首歌。F12-NETWORK-ALL-F5,我们找出一个这样的文件。
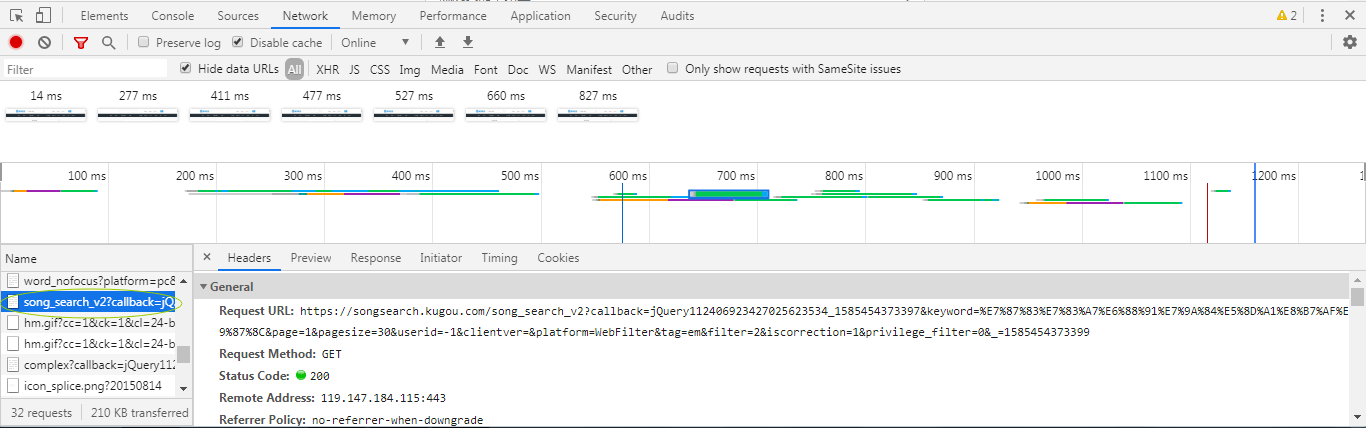
这个搜索的歌曲名,我们代码用input让用户输入歌曲名就行了。那么,你找到思路了吗?
思路:拼接出hash信息网址,正则表达式获取到所有歌曲的hash,再拼接出单首歌曲的url。最后再一次用正则表达式获取歌曲的play_url即可。
开始写代码
首先导入我们的requests和re正则表达式库。re用来找出音乐的信息和下载地址,requests负责获取文本和下载音乐。
import requests
import re
我们还要设置一些变量,这些变量在后面可是会派上大用场的。
timer = 0
song_urls = {}
names = {}
我们不是要拼接出多首歌曲的信息网址吗?那我们就先要让用户输入歌曲名。接着再拼。
songs = input("请输入歌曲名:")
url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery112409090559630919017_1585358668138&keyword=%s&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1585358668140'%songs
现在,我们就可以用requests请求文本了!由于这个网址是get请求的而且我们请求的是文本,所以,我们也要用方法requests.get().text方法。
texts = requests.get(url).text
接着,你可以试着打印一下文本。打印出来的文本和我们拼接的网址的内容毫无区别(我这里就不打印了,等下python卡死就完了)
在这些文本里,我们可以获取到每首歌的hash值。用正则表达式查找就行了。
song_hashes = re.findall('"FileHash":"(.*?)"',texts)
打印一下song_hashes,可以看到,他是个列表。所以我们要进行for遍历。
for i in song_hashes:
information_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104610954889760035_1585364074033&hash=%s&album_id=0&dfid=2SSGs60RKO9P0bAzIe0xF4Us&mid=5a959954d2f99fc1438fe2efb7596511&platid=4&_=1585364074034'%i
information = requests.get(information_url).text
song_url = re.findall('"play_url":"(.*?)"',information)
song_names = bytes(re.findall('"audio_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape')
singers = bytes(re.findall('"author_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape')
if song_names not in names.values():
names[str(timer)] = song_names
print("%d.%s"%(timer,song_names))
print("作者:%s"%singers)
print()
timer += 1
if song_url[0] not in song_urls.values():
song_urls[str(timer-1)] = song_url[0]
上段代码中,我们进行了每个hash的拼接操作,然后我们在从单首歌曲的信息文本里找到了音乐名和作者和下载地址。由于音乐名和作者是进行ascii编码过的,所以我们也要进行一个解码。由于歌曲名和歌手有时候会重复打印,所以我们每一次打印音乐和作者之前,都会把音乐和作者名加入到一个字典。每一次打印都会进行一次是否存在字典的判断。字典的key就由我们的timer变量的变化进行改变key名。另外,我们还把每首歌的下载地址保存到了song_urls字典里。
打印了音乐信息之后,就要询问用户要下载那首歌了。
print('输入n就不下载,若要下载多首歌曲,请用英文符号","隔开')
choice = input('请输入要下载歌曲的编号:').split(',')
if choice == "n":
exit()
else:
path = input("请输入要保存的路径:")
for i in choice:
song_url = song_urls[i].replace('\\/','/')
song = requests.get(song_url).content
save_name = names[i]
with open(path + '/' + save_name + '.mp3','wb') as f:
f.write(song)
print("保存完成!")
按以前的做法,用requests.get().content把音乐转换成二进制文件再进行保存。在get之前,我们还需要把网址的乱七八糟的\/变成/。之后,就能保存下来了!
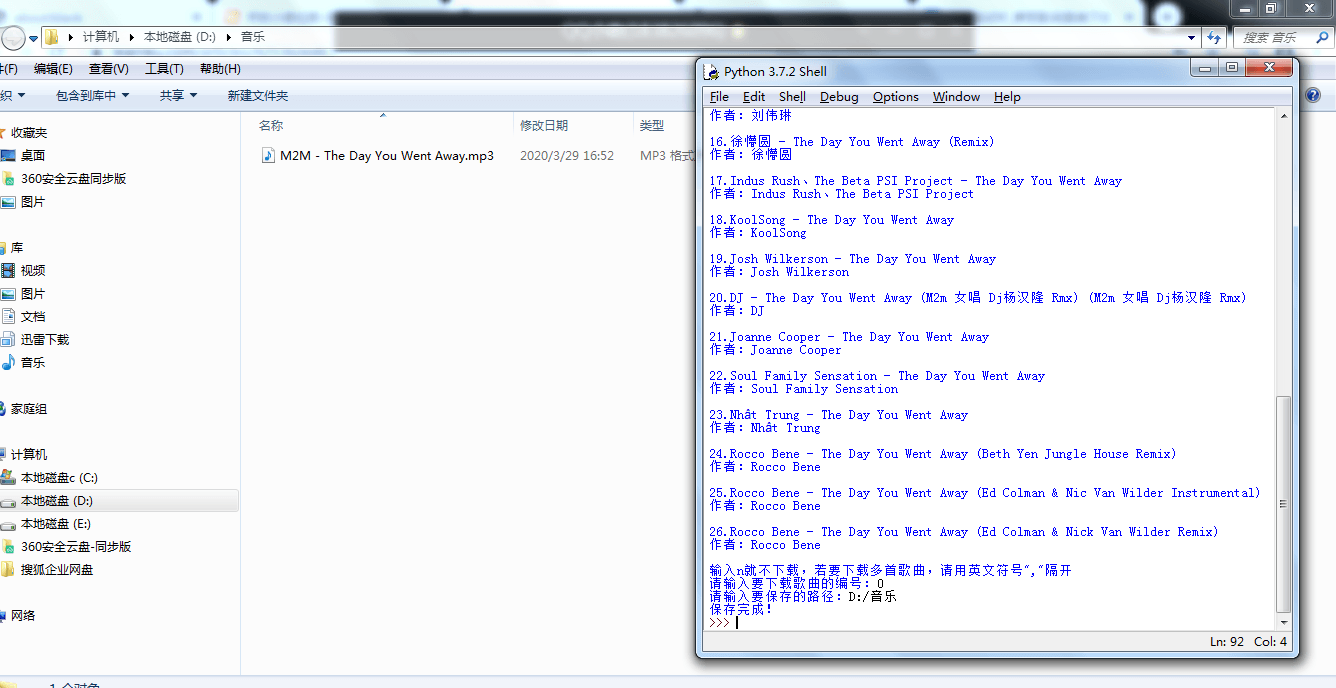
我们就拿一首叫做the day you went away的歌试一下
代码实现效果:
程序的不足
酷狗每隔一段时间都会弄个滑动验证码,这个时候我们的程序就不能获取到数据。这种情况,用selenium就可以轻松解决。
完整代码:
#导入库
import requests
import re
import os
#设置好一些变量
timer = 0 #设置一个计算歌曲顺序的机器
song_urls = {}
names = {}
songs = input("请输入歌曲名:")
url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery112409090559630919017_1585358668138&keyword=%s&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1585358668140'%songs
texts = requests.get(url).text
song_hashes = re.findall('"FileHash":"(.*?)"',texts)
print("请稍等...")
for i in song_hashes:
information_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104610954889760035_1585364074033&hash=%s&album_id=0&dfid=2SSGs60RKO9P0bAzIe0xF4Us&mid=5a959954d2f99fc1438fe2efb7596511&platid=4&_=1585364074034'%i
information = requests.get(information_url).text
song_url = re.findall('"play_url":"(.*?)"',information)
song_names = bytes(re.findall('"audio_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape')
singers = bytes(re.findall('"author_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape')
if song_names not in names.values():
names[str(timer)] = song_names
print("%d.%s"%(timer,song_names))
print("作者:%s"%singers)
print()
timer += 1
if song_url[0] not in song_urls.values():
song_urls[str(timer-1)] = song_url[0]
print('输入n就不下载,若要下载多首歌曲,请用英文符号","隔开')
choice = input('请输入要下载歌曲的编号:').split(',')
if choice == "n":
exit()
else:
path = input("请输入要保存的路径:")
has_path = os.path.exists(path)
while has_path == False:
print("路径不存在!!")
path = input("请输入要保存的路径:")
has_path = os.path.exists(path)
for i in choice:
song_url = song_urls[i].replace('\\/','/')
song = requests.get(song_url).content
save_name = names[i]
with open(path + '/' + save_name + '.mp3','wb') as f:
f.write(song)
print("保存完成!")
本作品采用《CC 协议》,转载必须注明作者和本文链接
coder Derek
python爬取酷狗音乐_python 爬虫 爬取酷狗音乐相关推荐
- python跑一亿次循环_python爬虫爬取微博评论
原标题:python爬虫爬取微博评论 python爬虫是程序员们一定会掌握的知识,练习python爬虫时,很多人会选择爬取微博练手.python爬虫微博根据微博存在于不同媒介上,所爬取的难度有差异,无 ...
- python爬取网页数据流程_Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python爬取大众点评评论_python爬虫抓取数据 小试Python——爬虫抓取大众点评上的数据 - 电脑常识 - 服务器之家...
python爬虫抓取数据 小试Python--爬虫抓取大众点评上的数据 发布时间:2017-04-07
- python爬取晋江小说简介_python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇...
知识就像碎布,记得"缝一缝",你才能华丽丽地亮相. 1.Beautiful Soup 1.Beautifulsoup 简介 此次实战从网上爬取小说,需要使用到Beautiful S ...
- python爬虫爬取多个页面_Python 爬虫爬取多页数据
但是,按照常规的爬取方法是不可行的,因为数据是分页的: 最关键的是,不管是第几页,浏览器地址栏都是不变的,所以每次爬虫只能爬取第一页数据.为了获取新数据的信息,点击F12,查看页面源代码,可以发现数据 ...
- python爬取论坛付费内容_Python爬虫抓取论坛关键字过程解析
前言: 之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能.由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统 ...
- python爬取知乎标题_python爬虫 爬取知乎文章标题及评论
目的:学习笔记 2.首先我们试着爬取下来一篇文章的评论,通过搜索发现在 response里面我们并没有匹配到评论,说明评论是动态加载的. 3.此时我们清空请求,收起评论,再次打开评论 4.完成上面操作 ...
- python爬今日头条组图_python 爬虫抓取今日头条街拍图片
1. 打开google浏览器,输入www.toutiao.com, 搜索街拍.html 2.打开开发者选项,network监看加载的xhr, 数据是ajax异步加载的,能够看到preview里面的da ...
- python爬取交通违法记录_python爬虫爬取汽车页面信息,并附带分析(静态爬虫)...
1 importrequests2 from bs4 importBeautifulSoup3 importre4 importrandom5 importtime6 7 8 #爬虫主函数 9 def ...
- python爬取贴吧数据_Python爬虫——抓取贴吧帖子
原博文 2016-11-13 23:13 − 抓取百度贴吧帖子 按照这个学习教程,一步一步写出来,中间遇到很多的问题,一一列举 首先, 获得 标题 和 贴子总数 # -*- coding:utf-8 ...
最新文章
- Swift3.0和OC桥接方法
- html选择字段至左边的列表,css – 如何将列表项显示为保留从左到右顺序的列?...
- 对比激光SLAM与视觉SLAM:谁会成为未来主流趋势?
- Laravel 集成 JPush 极光推送指北
- php 上传加水印,php 图片上传加水印(自动增加水印)
- 如何使用iOS AddressBook
- sql每个月每个人的花销占比_11月:每个认真生活的人,都值得被认真对待
- 硬件结构图_那曲地表水电子除垢仪结构图
- 检测浏览器是否支持WebSocket
- 【设计模式】第五章 责任链模式
- NYOJ-摆方格(贪心)
- 利用T-SQL处理SQL Server数据库表中的重复行
- 发生无法识别的错误_车牌识别系统的核心部件抓拍摄像机怎么安装?
- 矩阵运算_迹的相关性质
- Hadoop2.6分布式集群安装配置
- iOS16 beta8 描述文件官方地址下载
- 算法-贪心算法知识总结
- 计算机术语中bit的中文含义是,在计算机术语中bit的中文含义是
- 【5G核心网】PFCP Message PFCP 消息
- ubuntu 20 无法联网或无法解析域名(2022最新办法,实测有效)