利用T-SQL处理SQL Server数据库表中的重复行
Duplicate rows in a SQL Server database table can become a problem. We will see how we can find and handle those duplicate rows using T-SQL in this article.
SQL Server数据库表中的重复行可能会成为问题。 在本文中,我们将看到如何使用T-SQL查找和处理那些重复的行。
介绍 (Introduction)
We might discover duplicate rows in a SQL Server database table. This article will describe T-SQL techniques to find them, and if necessary, remove them.
我们可能会在SQL Server数据库表中发现重复的行。 本文将介绍T-SQL技术来查找它们,并在必要时将其删除。
样本数据库 (Sample Database)
For this article, we’ll focus on a sample database called OFFICE_EQUIPMENT_DATABASE, Built-in SQL Server 2014 Standard Edition, on an updated Windows 10 PC. The database has this overall structure:
在本文中,我们将重点放在更新的Windows 10 PC上的示例数据库OFFICE_EQUIPMENT_DATABASE,内置SQL Server 2014 Standard Edition。 该数据库具有以下总体结构:
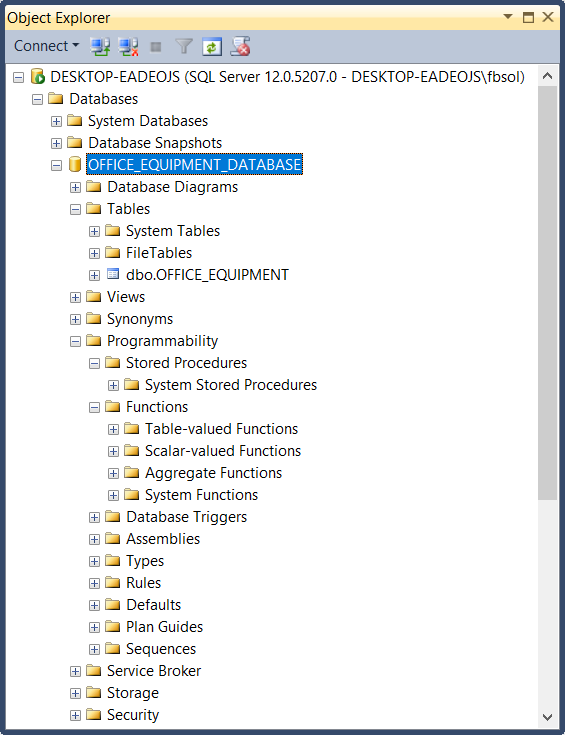
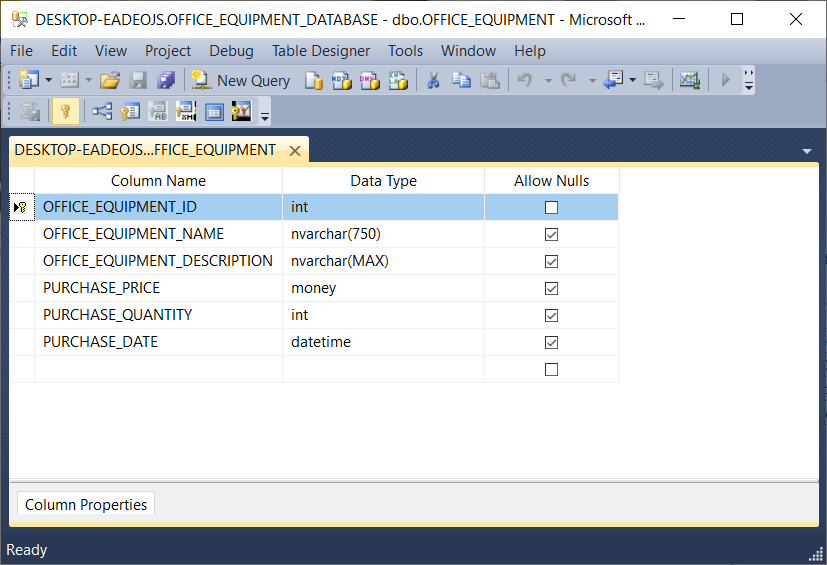
This database has no stored procedures, no user-defined functions, etc. It has one table, called OFFICE_EQUIPMENT as shown here:
该数据库没有存储过程,没有用户定义的函数等。它具有一个表,称为OFFICE_EQUIPMENT,如下所示:
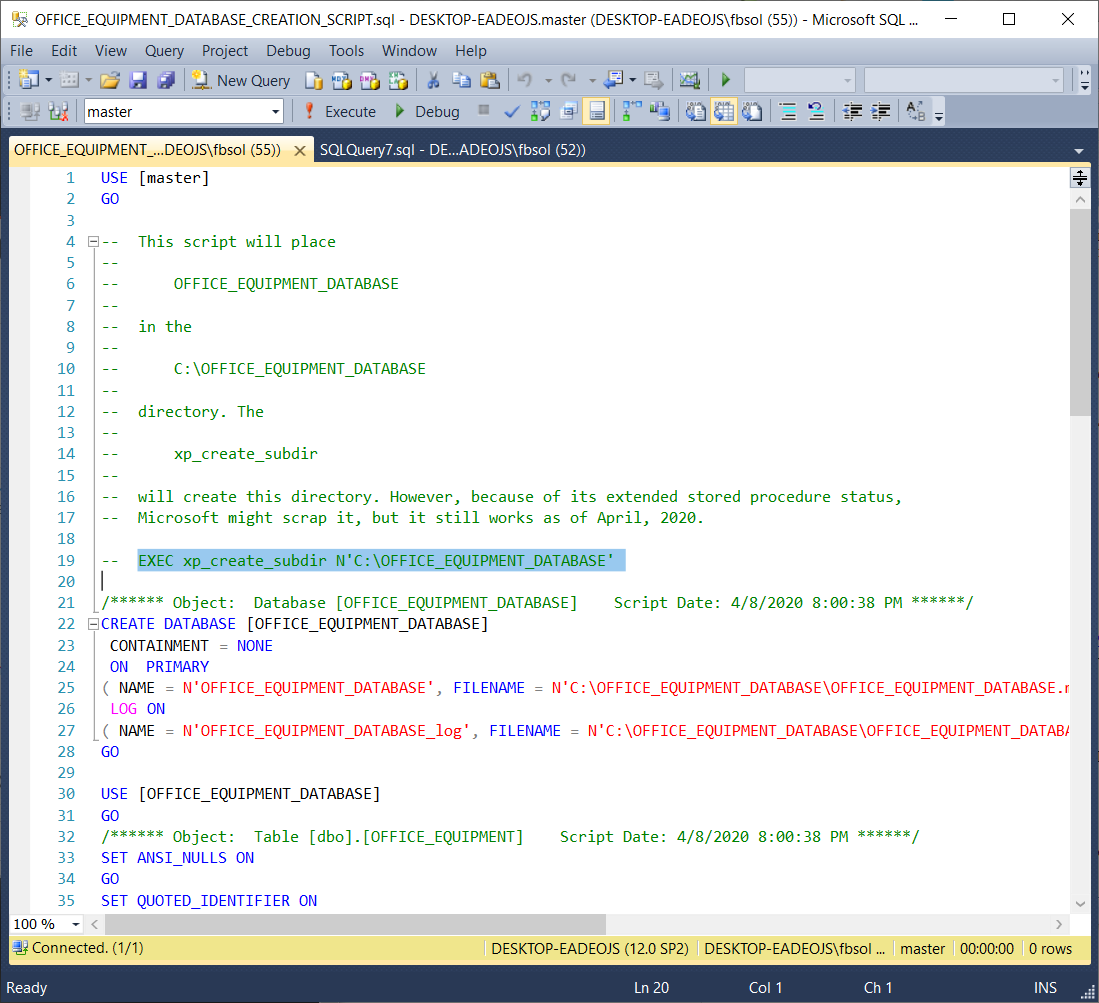
The following script will build the OFFICE_EQUIPMENT_DATABASE database, its table, and the rows in that table:
以下脚本将构建OFFICE_EQUIPMENT_DATABASE数据库,其表以及该表中的行:
USE [master]
GO-- This script will place
--
-- OFFICE_EQUIPMENT_DATABASE
--
-- in the
--
-- C:\OFFICE_EQUIPMENT_DATABASE
--
-- directory. The
--
-- xp_create_subdir
--
-- will create this directory. However, because of its extended stored procedure status,
-- Microsoft might scrap it, but it still works as of April, 2020.-- EXEC xp_create_subdir N'C:\OFFICE_EQUIPMENT_DATABASE'/****** Object: Database [OFFICE_EQUIPMENT_DATABASE] Script Date: 4/8/2020 8:00:38 PM ******/
CREATE DATABASE [OFFICE_EQUIPMENT_DATABASE]CONTAINMENT = NONEON PRIMARY
( NAME = N'OFFICE_EQUIPMENT_DATABASE', FILENAME = N'C:\OFFICE_EQUIPMENT_DATABASE\OFFICE_EQUIPMENT_DATABASE.mdf' , SIZE = 4096KB ,
MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )LOG ON
( NAME = N'OFFICE_EQUIPMENT_DATABASE_log', FILENAME = N'C:\OFFICE_EQUIPMENT_DATABASE\OFFICE_EQUIPMENT_DATABASE_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GOUSE [OFFICE_EQUIPMENT_DATABASE]
GO
/****** Object: Table [dbo].[OFFICE_EQUIPMENT] Script Date: 4/8/2020 8:00:38 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[OFFICE_EQUIPMENT]([OFFICE_EQUIPMENT_ID] [int] NOT NULL,[OFFICE_EQUIPMENT_NAME] [nvarchar](750) NULL,[OFFICE_EQUIPMENT_DESCRIPTION] [nvarchar](max) NULL,[PURCHASE_PRICE] [money] NULL,[PURCHASE_QUANTITY] [int] NULL,[PURCHASE_DATE] [datetime] NULL,CONSTRAINT [PK_OFFICE_EQUIPMENT] PRIMARY KEY CLUSTERED
([OFFICE_EQUIPMENT_ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (1, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (2, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (3, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (4, N'STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (5, N'ENVELOPE', N'#10 BUSINESS SECURITY ENVELOPES - SINGLE WINDOW', 0.0400, 500, CAST(N'2019-08-22 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (6, N'PENCIL', N'#2 PENCIL', 0.0800, 150, CAST(N'2020-02-17 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (7, N'ERASER', N'TICONDEROGA PINK ERASER', 1.6700, 3, CAST(N'2020-01-22 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (8, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (9, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (10, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (11, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 120, CAST(N'2019-11-12 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (12, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (13, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (14, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2018-03-17 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (15, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.8900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime))
GO
INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (16, N'PRINTER PAPER', N'35 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-11-12 00:00:00.000' AS DateTime))
GO
This script places the database LDF and MDF files in the C:\OFFICE_EQUIPMENT_DATABASE directory. We can manually create this directory, but the screenshot below shows the T-SQL call to an extended stored procedure xp_create_subdir at line 19. We can create the directory if we manually “paint” and execute this line. As an extended stored procedure, Microsoft could scrap xp_create_subdir at any time, but the above script includes it as an option. Of course, we can uncomment line 19 before running the script.
此脚本将数据库LDF和MDF文件放置在C:\ OFFICE_EQUIPMENT_DATABASE目录中。 我们可以手动创建此目录,但是下面的屏幕快照在第19行显示了对扩展存储过程xp_create_subdir的T-SQL调用。如果我们手动“绘制”并执行此行,则可以创建目录。 作为扩展存储过程,Microsoft可以随时取消xp_create_subdir,但是上面的脚本将其作为选项包含在内。 当然,我们可以在运行脚本之前取消注释第19行。
表数据 (The Table Data)
Run the below statements to see all of the OFFICE_EQUIPMENT table rows, as seen in this screenshot:
运行以下语句以查看所有OFFICE_EQUIPMENT表行,如此屏幕截图所示:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE
FROM OFFICE_EQUIPMENT
ORDER BY OFFICE_EQUIPMENT_NAME;
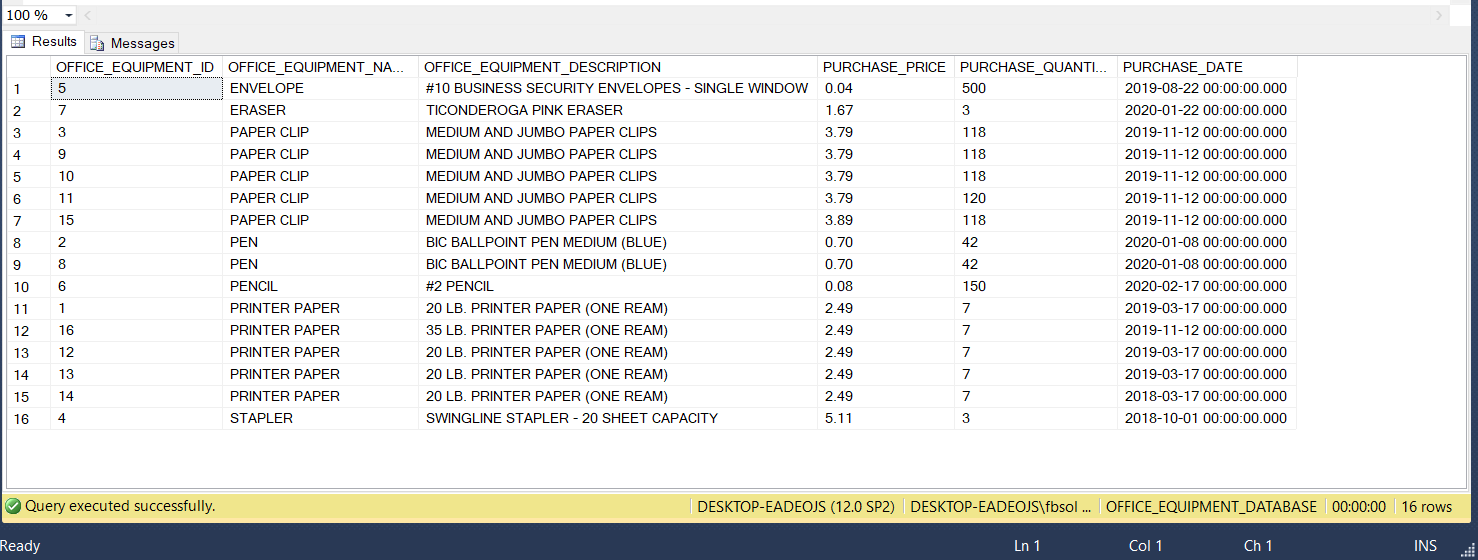
Every row has a unique OFFICE_EQUIPMENT_ID value. In a way, the table has unique rows because the OFFICE_EQUIPMENT_ID column operates as a primary key field in this table. If we ignore this column, however, we can clearly see that many rows have duplicate data shared across other columns. For example, this code returns rows with duplicate non-ID values:
每行都有一个唯一的OFFICE_EQUIPMENT_ID值。 在某种程度上,该表具有唯一的行,因为OFFICE_EQUIPMENT_ID列用作该表中的主键字段。 但是,如果忽略此列,我们可以清楚地看到许多行在其他列之间共享重复的数据。 例如,此代码返回具有重复的非ID值的行:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE
FROM OFFICE_EQUIPMENT
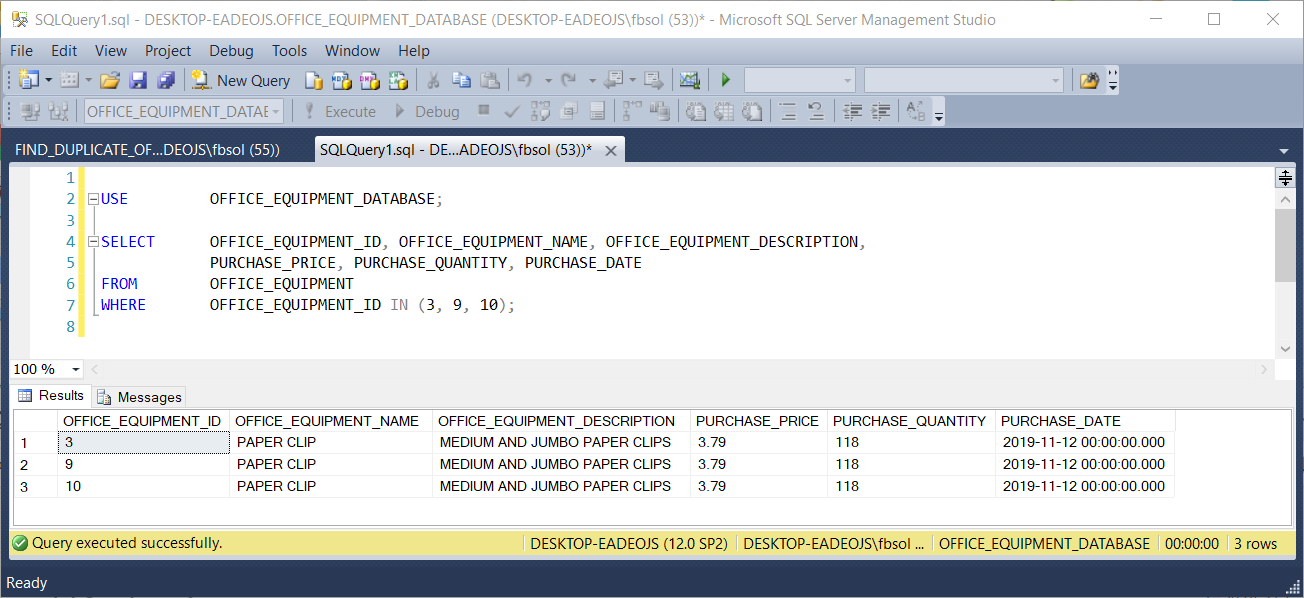
WHERE OFFICE_EQUIPMENT_ID IN (3, 9, 10);
This screenshot shows the result set:
此屏幕快照显示了结果集:
This code returns another result set with similar behavior:
此代码返回另一个具有类似行为的结果集:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE
FROM OFFICE_EQUIPMENT
WHERE OFFICE_EQUIPMENT_ID IN (1, 13, 14);
This screenshot shows the second result set:
此屏幕快照显示了第二个结果集:

Simply looking for duplicate rows by eye might work for a sixteen-row table, but it won’t work for a table with thousands, or millions, of rows. We need a better technique.
仅凭眼图查找重复的行可能适用于16行的表,但不适用于具有数千或数百万行的表。 我们需要更好的技术。
识别重复的数据行 (Identify Duplicate Data Rows)
In an earlier SQL Shack article Overview of the SQL ROW_NUMBER function, Prashanth Jayaram explored the SQL Server ROW_NUMBER() function. This function will become an important part of the solution we’ll build. When we use the T-SQL ROW_NUMBER() function, we must also add a certain SQL clause to separate, or partition, a query result set. This partition separates the result set rows into at least one defined subset of rows, only for use by the ROW_NUMBER() function. The partition process might produce one subset that covers all the rows – that’s OK. ROW_NUMBER() needs this separation to support its row numbering operations. The partitioning does not change the data in any way. Prashanth explained that the ROW_NUMBER() function will set a sequential number, in a separate column, for every row in the row subset partition. The OVER() clause placed right after the ROW_NUMBER() function handles the partitioning task for ROW_NUMBER(). In this T-SQL query, the ROW_NUM column sequentially numbers every row:
在较早SQL Shack文章SQL ROW_NUMBER函数概述中 , Prashanth Jayaram探索了SQL Server ROW_NUMBER()函数。 此功能将成为我们将构建的解决方案的重要组成部分。 当我们使用T-SQL ROW_NUMBER()函数时,我们还必须添加某个SQL子句来分隔或分区查询结果集。 此分区将结果集行分成至少一个定义的行子集,仅供ROW_NUMBER()函数使用。 分区过程可能会产生一个覆盖所有行的子集-可以。 ROW_NUMBER()需要这种分隔来支持其行编号操作。 分区不会以任何方式更改数据。 Prashanth解释说,ROW_NUMBER()函数将在单独的列中为行子集分区中的每一行设置一个顺序号。 ROW(NUMBER)函数之后的OVER()子句处理ROW_NUMBER()的分区任务。 在此T-SQL查询中,ROW_NUM列按顺序对每一行编号:
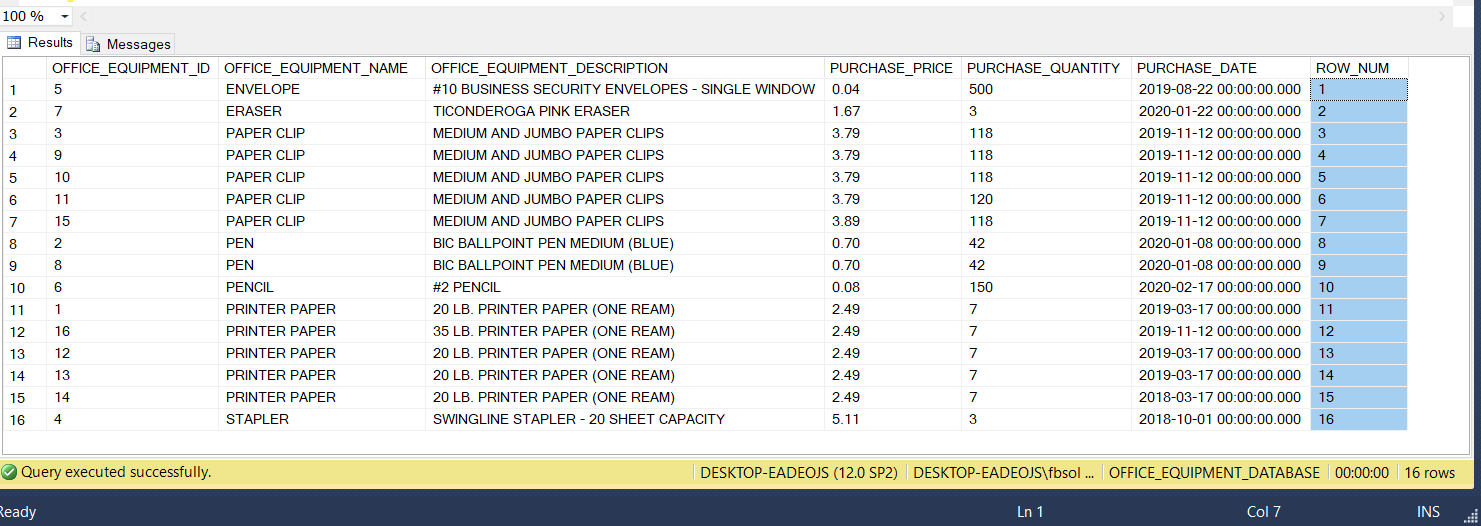
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE,ROW_NUMBER() OVER(ORDER BY OFFICE_EQUIPMENT_NAME) AS ROW_NUM
FROM OFFICE_EQUIPMENT;
This screenshot shows the result set:
此屏幕快照显示了结果集:
Microsoft explains that the OVER() clause “ . . . determines the partitioning and ordering of a rowset . . .” Its syntax offers many options, but to solve our specific problem, we’ll use the ORDER BY clause with the ROW_COUNT() function. The ORDER BY clause as used here expects at least one column, and we’ll use the OFFICE_EQUIPMENT_NAME column, as seen at line 6 in the above screenshot. Any specific table column, or any combination of table columns, will work here. The T-SQL ROW_NUMBER() function will get the complete OVER() clause it wants, and it can then set a ROW_NUM value for each row. As a side effect, this ORDER BY clause will also determine the row order of the final query result set. We made some progress, but we must define the rules that make rows identical. Then, we must gather those defined duplicate rows together. The PARTITION BY clause will solve this part of the problem.
Microsoft 解释说OVER()子句“。 。 。 确定行集的分区和顺序。 。 。” 它的语法提供了许多选项,但是要解决我们的特定问题,我们将在ROW_COUNT()函数中使用ORDER BY子句。 此处使用的ORDER BY子句至少需要一列,而我们将使用OFFICE_EQUIPMENT_NAME列,如上面的屏幕快照中的第6行所示。 任何特定的表格列或表格列的任何组合都将在这里工作。 T-SQL ROW_NUMBER()函数将获取所需的完整OVER()子句,然后可以为每行设置ROW_NUM值。 副作用是,此ORDER BY子句还将确定最终查询结果集的行顺序。 我们取得了一些进展,但是我们必须定义使行相同的规则。 然后,我们必须将这些定义的重复行收集在一起。 PARTITION BY子句将解决此部分问题。
Placed in the OVER() clause, the T-SQL PARTITION BY clause divides, or separates, the result set rows into subsets, or partitions. The OVER clause can use these subsets in its own operations that support other SQL Server functions. We can use the OVER() clause here to build a definition of duplicate rows.
T-SQL PARTITION BY子句放置在OVER()子句中,将结果集行划分为多个子集或分区。 OVER子句可以在支持其他SQL Server功能的自己的操作中使用这些子集。 我们可以在这里使用OVER()子句来建立重复行的定义。
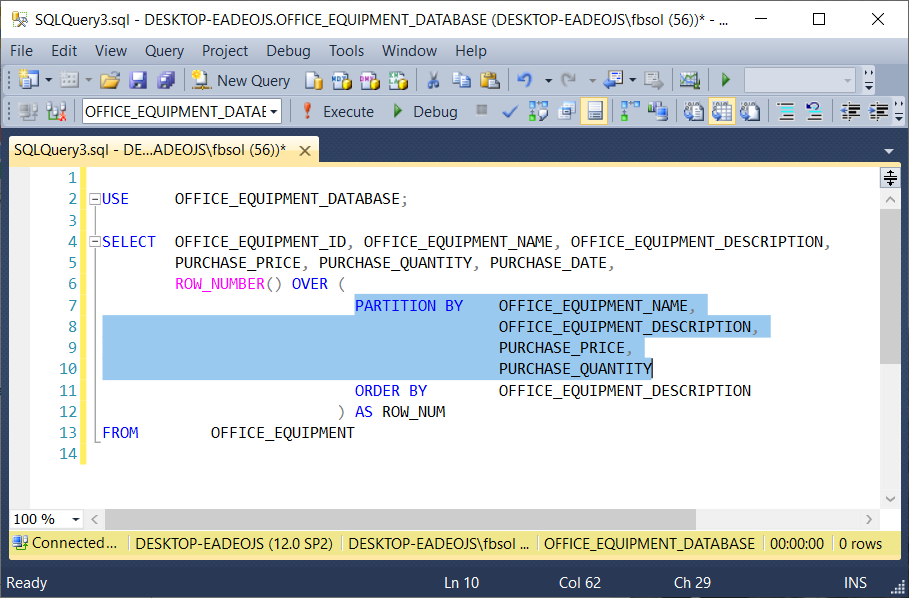
In the below query, the OVER clause has a PARTITION BY clause, in addition to its required ORDER BY clause. As seen in a new query tab, this screenshot highlights the PARTITION BY clause:
在下面的查询中,除了其必需的ORDER BY子句外,OVER子句还具有PARTITION BY子句。 在新的查询选项卡中可以看到,此屏幕截图突出显示了PARTITION BY子句:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE,ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME,OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE,PURCHASE_QUANTITYORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS ROW_NUM
FROM OFFICE_EQUIPMENT
As used in the OVER() clause of this example, the PARTITION BY clause has a list of columns. In this case, PARTITION BY has columns from the OFFICE_EQUIPMENT table. When the ROW_NUMBER() function separates, or partitions, the result set rows, it uses the PARTITION BY column list to decide which columns have the values that define duplicate rows. This screenshot shows the query result set:
如本示例的OVER()子句中所使用的,PARTITION BY子句具有列列表。 在这种情况下,PARTITION BY具有OFFICE_EQUIPMENT表中的列。 当ROW_NUMBER()函数分隔或分区结果集行时,它使用PARTITION BY列列表来确定哪些列具有定义重复行的值。 此屏幕快照显示了查询结果集:
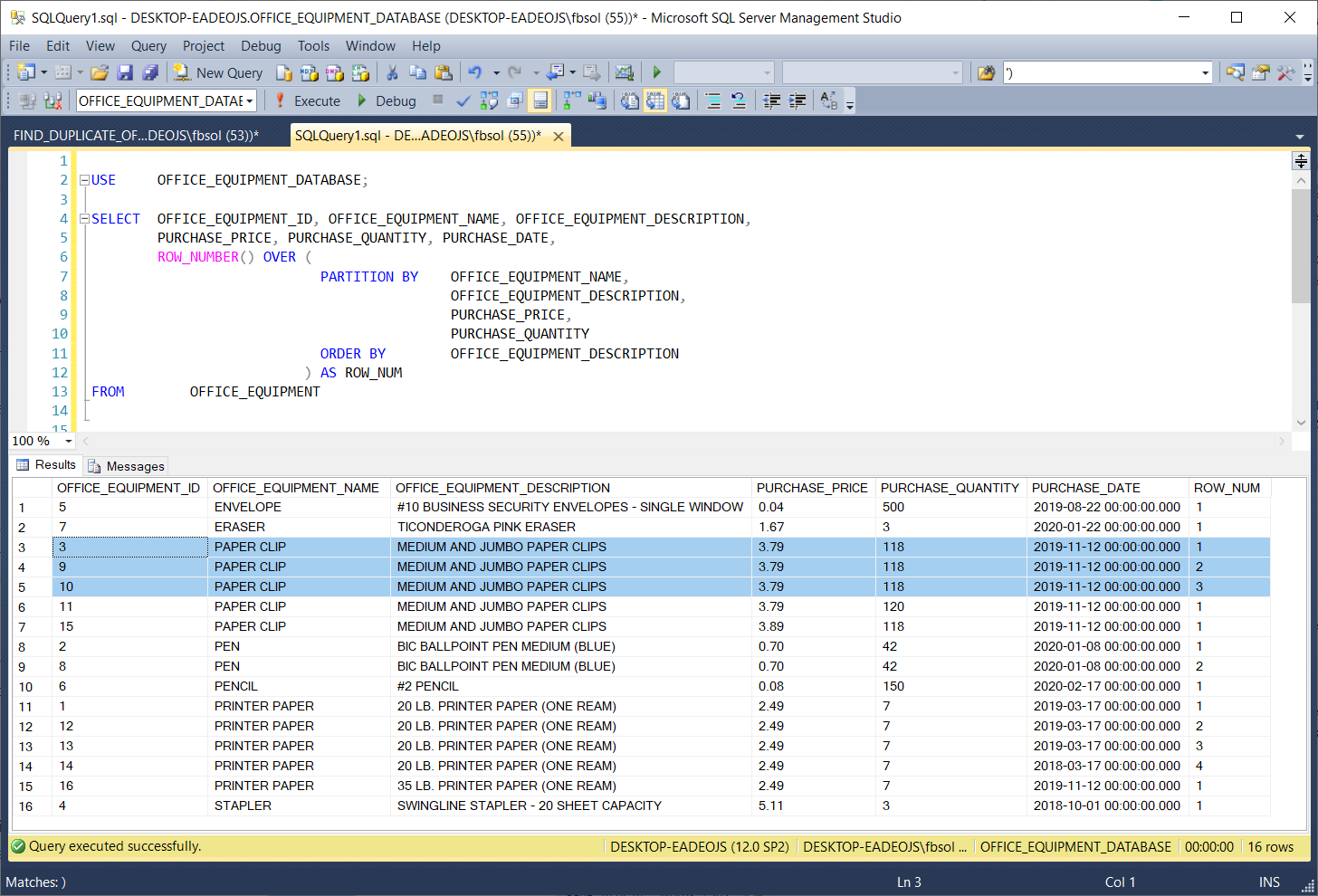
In this query, PARTITION BY looks at the values in the columns and if it finds result set rows that have identical values in all of these columns, it places these rows into a separate partition.
在此查询中,PARTITION BY将查看列中的值,如果发现所有这些列中具有相同值的结果集行,则会将这些行放入单独的分区中。
OFFICE_EQUIPMENT_NAME,
OFFICE_EQUIPMENT_DESCRIPTION,
PURCHASE_PRICE,
PURCHASE_QUANTITY
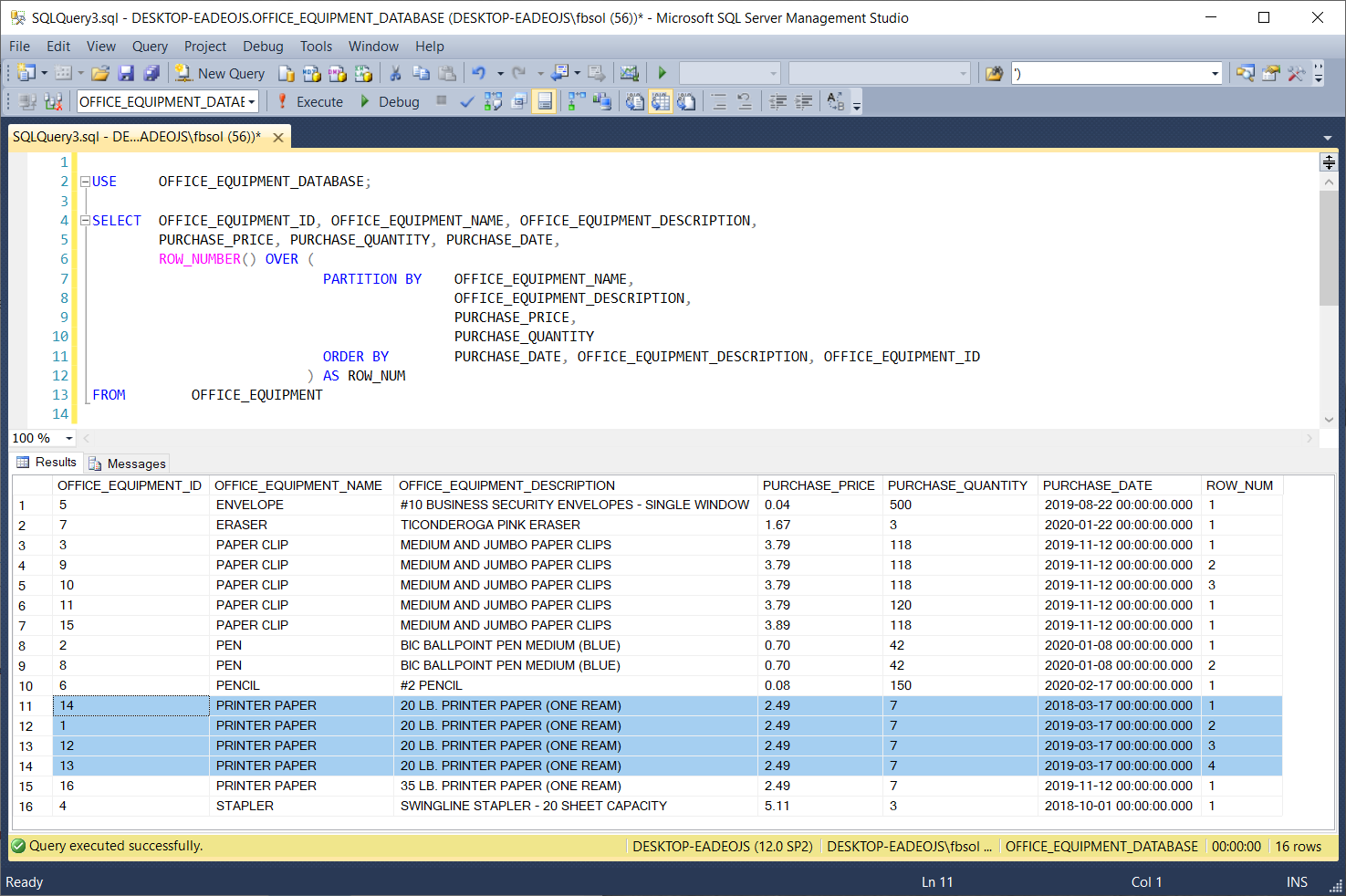
If it can build more than one different partition from the same result set, it will do so. The highlighted result set rows have identical values in these columns, so PARTITION BY brought them together in a separate partition. Then, the T-SQL ROW_NUMBER() function numbered these rows in the ROW_NUM column, starting at 1 and ending at 3. At rows 11 through 14, PARTITION BY brought another set of rows together, as shown in this screenshot:
如果它可以从同一结果集中构建多个分区,那么它将这样做。 突出显示的结果集行在这些列中具有相同的值,因此PARTITION BY将它们放在一个单独的分区中。 然后,T-SQL ROW_NUMBER()函数在ROW_NUM列中为这些行编号,从1开始到3结束。在第11到14行,PARTITION BY将另一组行放在一起,如以下屏幕快照所示:
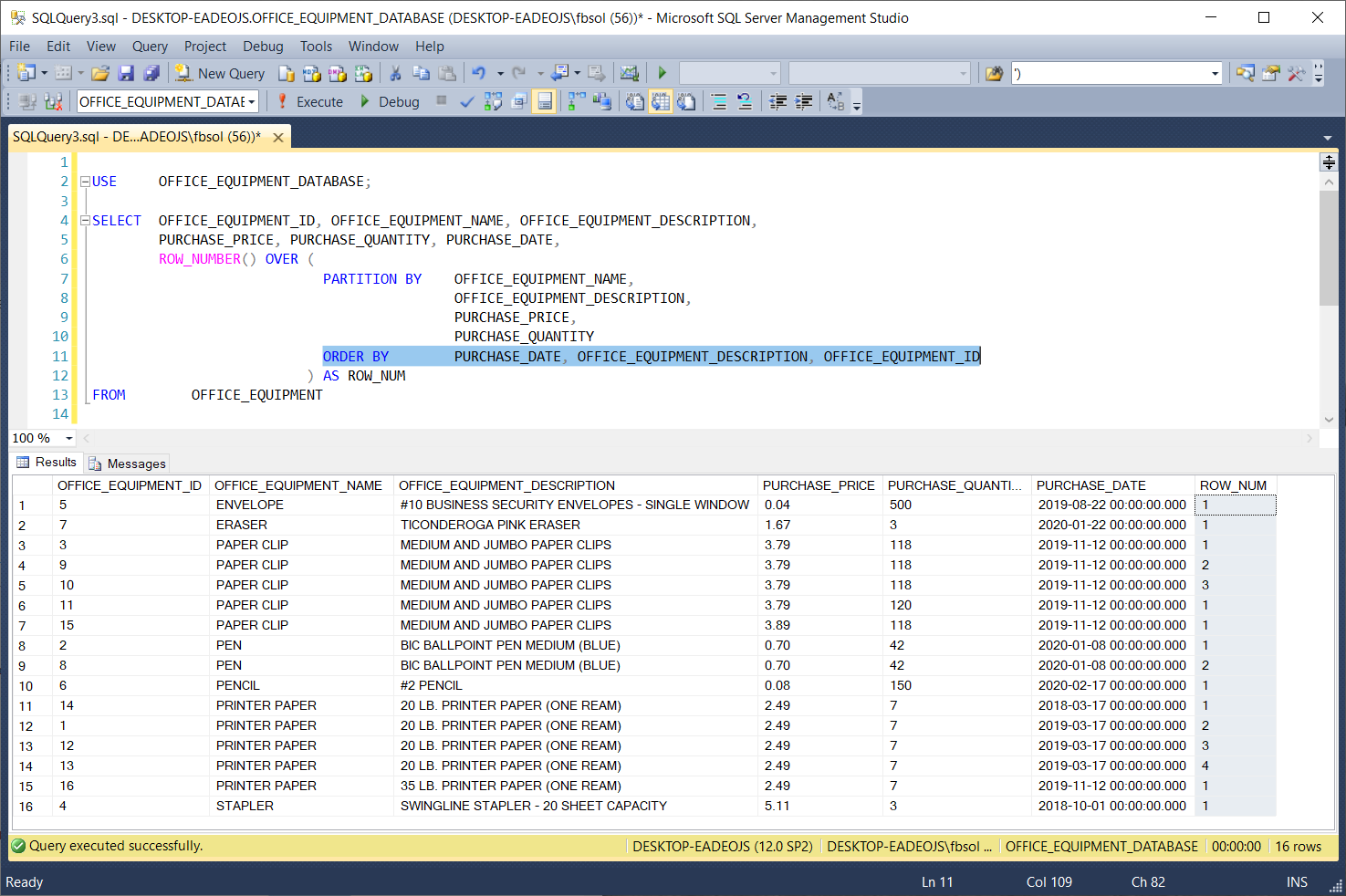
ROW_NUMBER(), OVER(), and PARTITION BY make no changes to the original data in any source database tables. Also, the ORDER BY clause in the T-SQL OVER() clause handles one, some, or all of the OFFICE_EQUIPMENT table columns, as seen in this screenshot:
ROW_NUMBER(),OVER()和PARTITION BY不会对任何源数据库表中的原始数据进行任何更改。 同样,T-SQL OVER()子句中的ORDER BY子句处理一个,一些或所有OFFICE_EQUIPMENT表列,如以下屏幕快照所示:
In the OFFICE_EQUIPMENT table, the OFFICE_EQUIPMENT_ID column has unique values in all of the rows. If we add this column to the PARTITION BY column list, the ROW_NUM will have values of 1 in all rows, as shown in this screenshot:
在OFFICE_EQUIPMENT表中,OFFICE_EQUIPMENT_ID列在所有行中都有唯一的值。 如果将此列添加到PARTITION BY列列表中,则ROW_NUM在所有行中的值均为1,如以下屏幕截图所示:
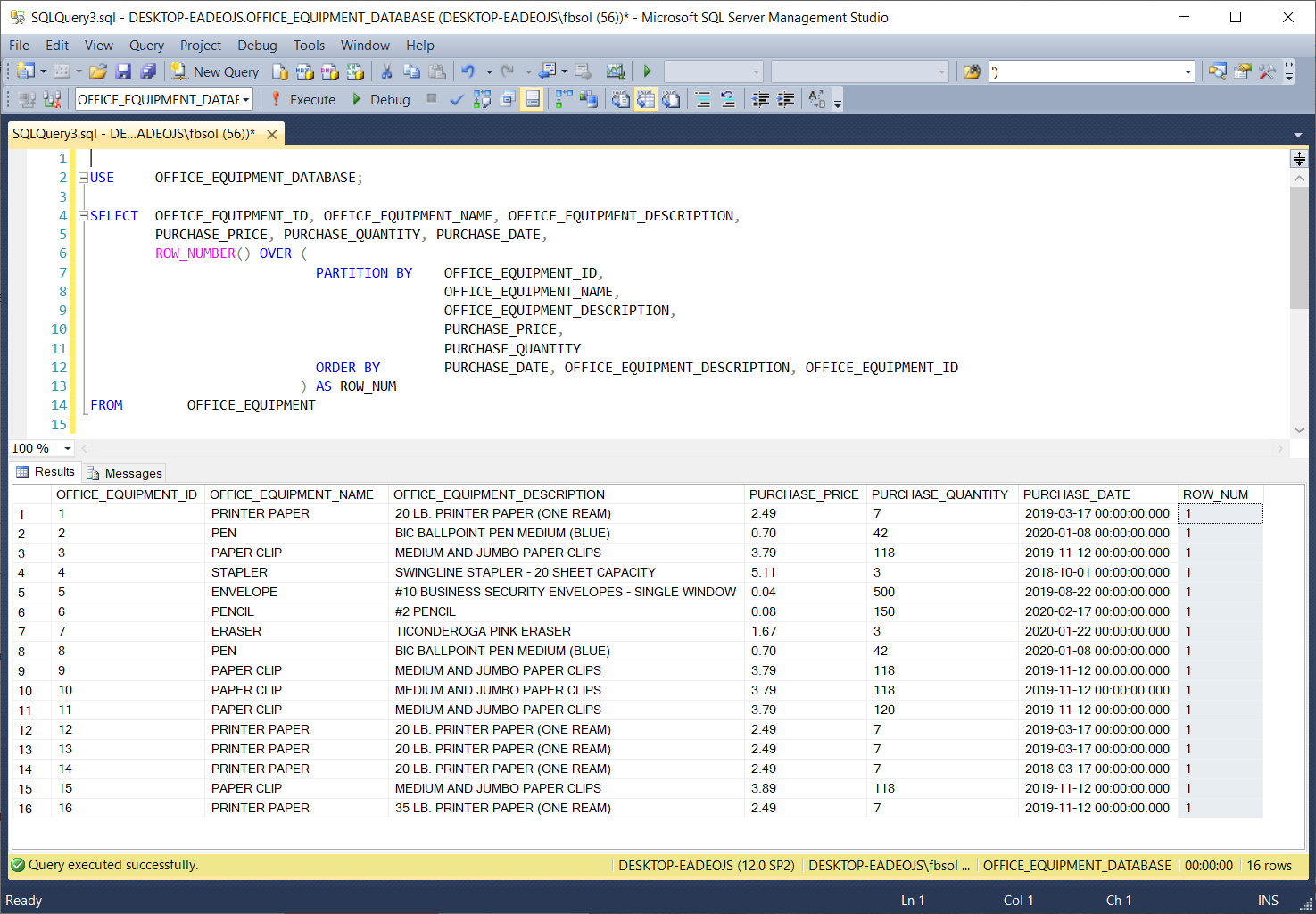
This makes sense, because PARTITION BY now looks at a column set with unique values in at least one column – in this case, OFFICE_EQUIPMENT_ID. Therefore, every row that PARTITION BY sees has a unique set of values, and it will place every row in a separate partition. Those partitions will have only one row. Therefore, every row, in every partition, will have a ROW_NUM value of 1.
这是有道理的,因为PARTITION BY现在查看的是至少有一列具有唯一值的列集-在本例中为OFFICE_EQUIPMENT_ID。 因此,PARTITION BY看到的每一行都有一组唯一的值,并将每一行放在单独的分区中。 这些分区只有一行。 因此,每个分区中的每一行的ROW_NUM值均为1。
The PARTITION BY clause offers fine-grained control over the columns we use to define the duplicate rows that form the partitions themselves. This query modifies an earlier query, commenting out the OFFICE_EQUIPMENT_DESCRIPTION column in the PARTITION BY clause:
PARTITION BY子句提供了对列的细粒度控制,这些列用于定义构成分区本身的重复行。 该查询修改了先前的查询,并注释了PARTITION BY子句中的OFFICE_EQUIPMENT_DESCRIPTION列:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE,ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME,-- OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE,PURCHASE_QUANTITYORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS ROW_NUM
FROM OFFICE_EQUIPMENT
This screenshot shows the result set:
此屏幕快照显示了结果集:

The T-SQL PARTITION BY clause gathered the highlighted rows into one separate partition, similar to the highlighted rows shown three screenshots above. In this case, however, row 15, with OFFICE_EQUIPMENT_ID value of 16, has an OFFICE_EQUIPMENT_DESCRIPTION value of “35 LB. PRINTER PAPER (ONE REAM)” which differs from the values of this column in the other rows in this subset of rows. Additionally, row 14, with OFFICE_EQUIPMENT_ID value of 14, has a PURCHASE_DATE value of 2018-03-17 00:00:00.000 which differs from the values of this column in the other rows in this subset of rows.
T-SQL PARTITION BY子句将突出显示的行收集到一个单独的分区中,类似于上面三个屏幕快照所示的突出显示的行。 但是,在这种情况下,OFFICE_EQUIPMENT_ID值为16的第15行的OFFICE_EQUIPMENT_DESCRIPTION值为“ 35LB。 打印机纸(一个纸)”,与该行子集中的其他行中此列的值不同。 此外,OFFICE_EQUIPMENT_ID值为14的第14行的PURCHASE_DATE值为2018-03-17 00:00:00.000 ,与该行子集中其他行中此列的值不同。
The query gathered and numbered these rows in the same row partition because the T-SQL PARTITION BY clause in this query defines duplicate rows based on the columns.
该查询在同一行分区中对这些行进行了收集并编号,因为该查询中的T-SQL PARTITION BY子句基于列定义了重复的行。
OFFICE_EQUIPMENT_NAME
PURCHASE_PRICE
PURCHASE_QUANTITY
It ignores columns with potentially different values, as it builds the partitions of rows it defines as identical.
当建立它定义为相同的行的分区时,它将忽略具有潜在不同值的列。
处理重复的数据行 (Handling Duplicate Data Rows)
Now that we can define and identify duplicate rows, we can decide what to do with them. Before we begin, this script will delete and reinsert the original rows in the OFFICE_EQUIPMENT table:
现在我们可以定义和识别重复的行,我们可以决定如何处理它们。 在开始之前,此脚本将删除并将原始行重新插入到OFFICE_EQUIPMENT表中:
USE OFFICE_EQUIPMENT_DATABASE;TRUNCATE TABLE OFFICE_EQUIPMENT;INSERT INTO OFFICE_EQUIPMENT (OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE,
PURCHASE_QUANTITY, PURCHASE_DATE)
VALUES (1, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)),(2, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)),(3, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)),(4, N'STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime)),(5, N'ENVELOPE', N'#10 BUSINESS SECURITY ENVELOPES - SINGLE WINDOW', 0.0400, 500, CAST(N'2019-08-22 00:00:00.000' AS DateTime)),(6, N'PENCIL', N'#2 PENCIL', 0.0800, 150, CAST(N'2020-02-17 00:00:00.000' AS DateTime)),(7, N'ERASER', N'TICONDEROGA PINK ERASER', 1.6700, 3, CAST(N'2020-01-22 00:00:00.000' AS DateTime)),(8, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)),(9, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)),(10, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)),(11, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 120, CAST(N'2019-11-12 00:00:00.000' AS DateTime)),(12, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)),(13, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)),(14, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2018-03-17 00:00:00.000' AS DateTime)),(15, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.8900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)),(16, N'PRINTER PAPER', N'35 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-11-12 00:00:00.000' AS DateTime));
We saw this query earlier in this article:
我们在本文前面看到了此查询:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE,ROW_NUMBER() OVER (
PARTITION BY OFFICE_EQUIPMENT_NAME,
OFFICE_EQUIPMENT_DESCRIPTION,
PURCHASE_PRICE,
PURCHASE_QUANTITY
ORDER BY OFFICE_EQUIPMENT_DESCRIPTION
) AS ROW_NUM
FROM OFFICE_EQUIPMENT
This query partitions the OFFICE_EQUIPMENT table on these columns:
该查询在这些列上对OFFICE_EQUIPMENT表进行分区:
OFFICE_EQUIPMENT_NAME
OFFICE_EQUIPMENT_DESCRIPTION
PURCHASE_PRICE
PURCHASE_QUANTITY
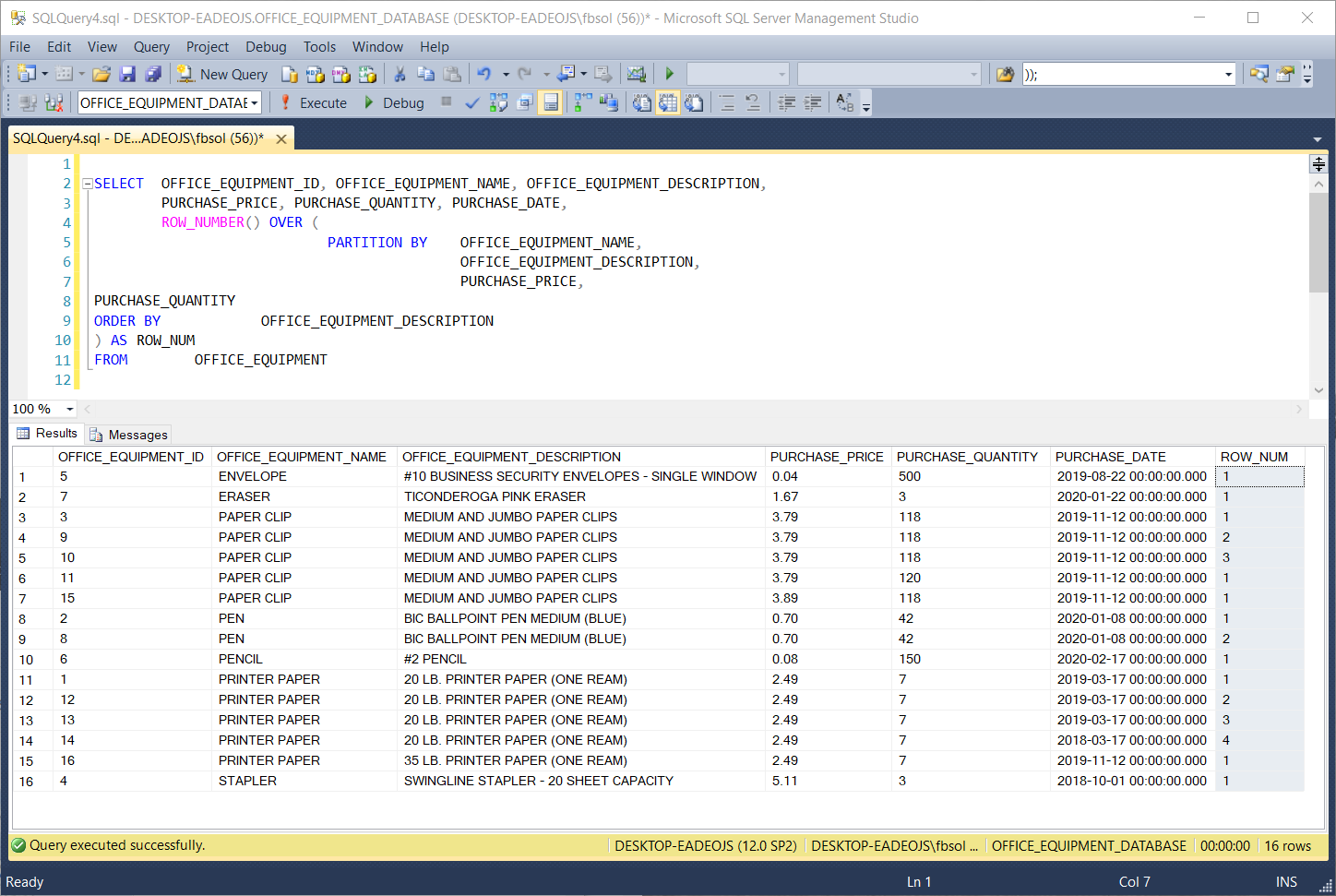
In this screenshot, the ROW_NUM column values greater than 1 flag the duplicate rows, as we defined them in the PARTITION BY clause. We can try to return only those duplicate rows, with this query:
在此屏幕快照中,ROW_NUM列值大于1标记了重复的行,正如我们在PARTITION BY子句中定义的那样。 我们可以使用此查询尝试仅返回那些重复的行:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE,ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME,OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE,
PURCHASE_QUANTITY
ORDER BY OFFICE_EQUIPMENT_DESCRIPTION
) AS ROW_NUM
FROM OFFICE_EQUIPMENT
WHERE ROW_NUM > 1
However, this won’t work, as this screenshot shows:
但是,此操作无效,如以下屏幕截图所示:
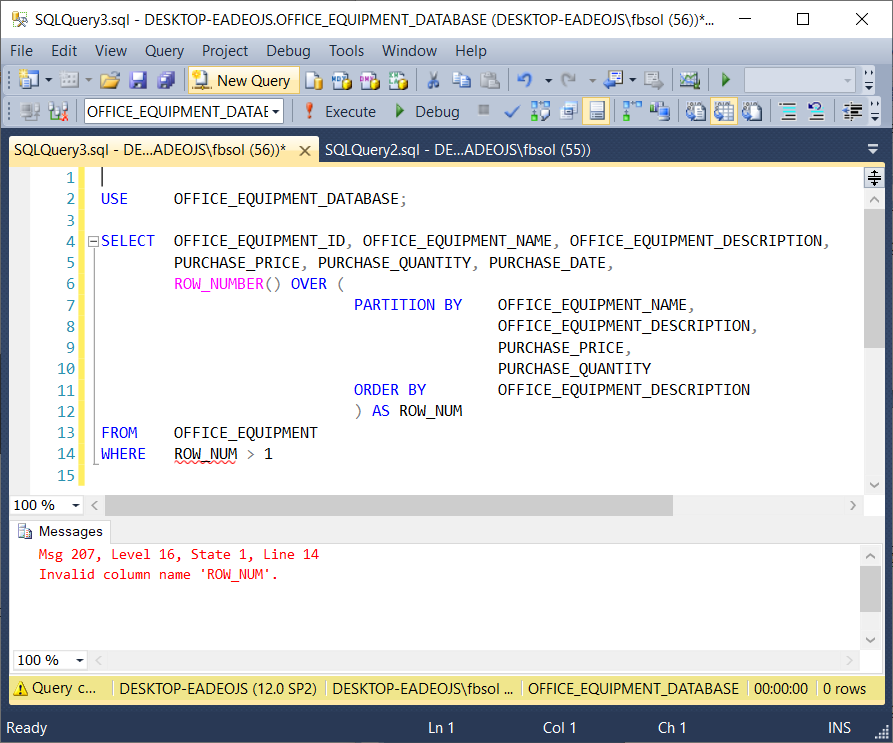
Microsoft explains that the WHERE clause executes before the SELECT clause. As a result, the WHERE clause in this query will never see the ROW_NUM column, and the query returns an error. However, the Microsoft source also explains that the FROM clause executes first. With this in mind, we can rebuild the query. We’ll use the above query as a subquery in the FROM clause of a parent query, as seen here:
Microsoft 解释说WHERE子句在SELECT子句之前执行。 结果,此查询中的WHERE子句将永远不会看到ROW_NUM列,并且该查询返回错误。 但是,Microsoft源代码也解释了FROM子句首先执行。 考虑到这一点,我们可以重建查询。 我们将上面的查询用作父查询的FROM子句中的子查询,如下所示:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,
PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUM
FROM
(
SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE,ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME,OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE,PURCHASE_QUANTITYORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS ROW_NUMFROM OFFICE_EQUIPMENT
) TMP
WHERE ROW_NUM > 1;
This screenshot shows that the WHERE clause filter worked:
此屏幕快照显示WHERE子句过滤器有效:
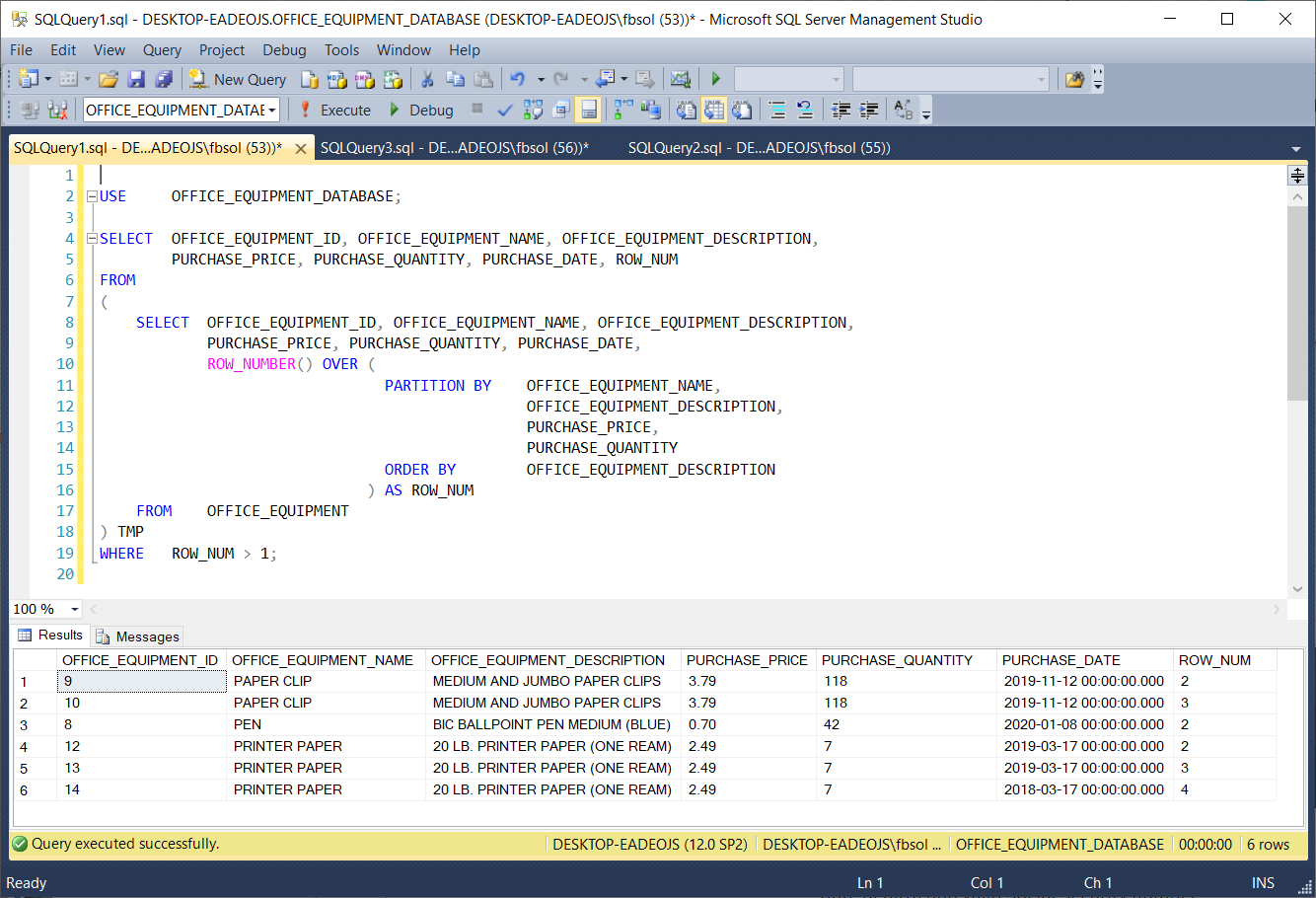
Expanding on this approach, this query will delete the duplicate rows:
扩展此方法,此查询将删除重复的行:
USE OFFICE_EQUIPMENT_DATABASE;DELETE OE
FROM (SELECT OFFICE_EQUIPMENT_ID,ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME,OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE,PURCHASE_QUANTITYORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS ROW_NUMFROM OFFICE_EQUIPMENT) DRT INNER JOIN OFFICE_EQUIPMENT OE ON -- ALIAS DUPLICATE_ROW_TABLE AS DRTDRT.OFFICE_EQUIPMENT_ID = OE.OFFICE_EQUIPMENT_ID
WHERE DRT.ROW_NUM > 1;
This screenshot shows that the query worked:
此屏幕快照显示查询有效:
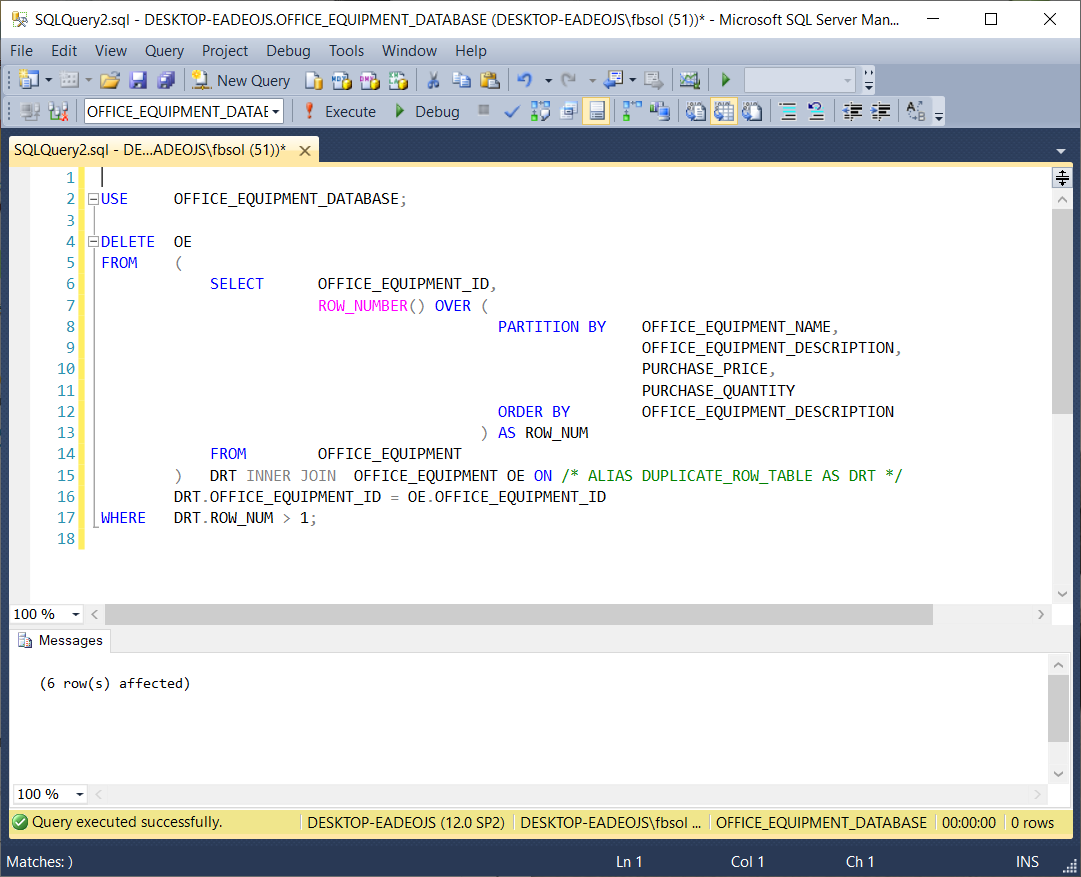
The information from Microsoft helped out. In a parent query, we placed the original ROW_NUMBER() query as a subquery in the FROM clause. We aliased this subquery as DRT at line 15, and joined DRT to the OFFICE_EQUIPMENT table at lines 15 and 16. The parent query WHERE clause at line 17 filtered the duplicate rows found in the DRT subquery.
微软提供的信息有所帮助。 在父查询中,我们将原始ROW_NUMBER()查询作为子查询放置在FROM子句中。 我们在第15行将这个子查询别名为DRT,并在第15和16行将DRT联接到OFFICE_EQUIPMENT表。第17行的父查询WHERE子句过滤了在DRT子查询中找到的重复行。
We can use this query to test the DELETE:
我们可以使用此查询来测试DELETE:
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITY,ROW_NUMBER() OVER
(PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE, PURCHASE_QUANTITYORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS RANK1
FROM OFFICE_EQUIPMENT
Using this test query, this screenshot verifies the DELETE query:
使用此测试查询,此屏幕截图验证了DELETE查询:
Instead of deleting the duplicate rows, we might want to identify them first, and decide what to do later. We can modify the DELETE query we saw earlier to build a new query as seen here and in the screenshot below.
与其删除重复的行,不如先识别它们,然后再决定要做什么。 我们可以修改我们之前看到的DELETE查询,以构建一个新查询,如此处和以下屏幕快照所示。
USE OFFICE_EQUIPMENT_DATABASE;SELECT OFFICE_EQUIPMENT_ID
FROM (SELECT OFFICE_EQUIPMENT_ID,ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME,OFFICE_EQUIPMENT_DESCRIPTION,PURCHASE_PRICE,PURCHASE_QUANTITYORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS ROW_NUMFROM OFFICE_EQUIPMENT) ROW_NUM
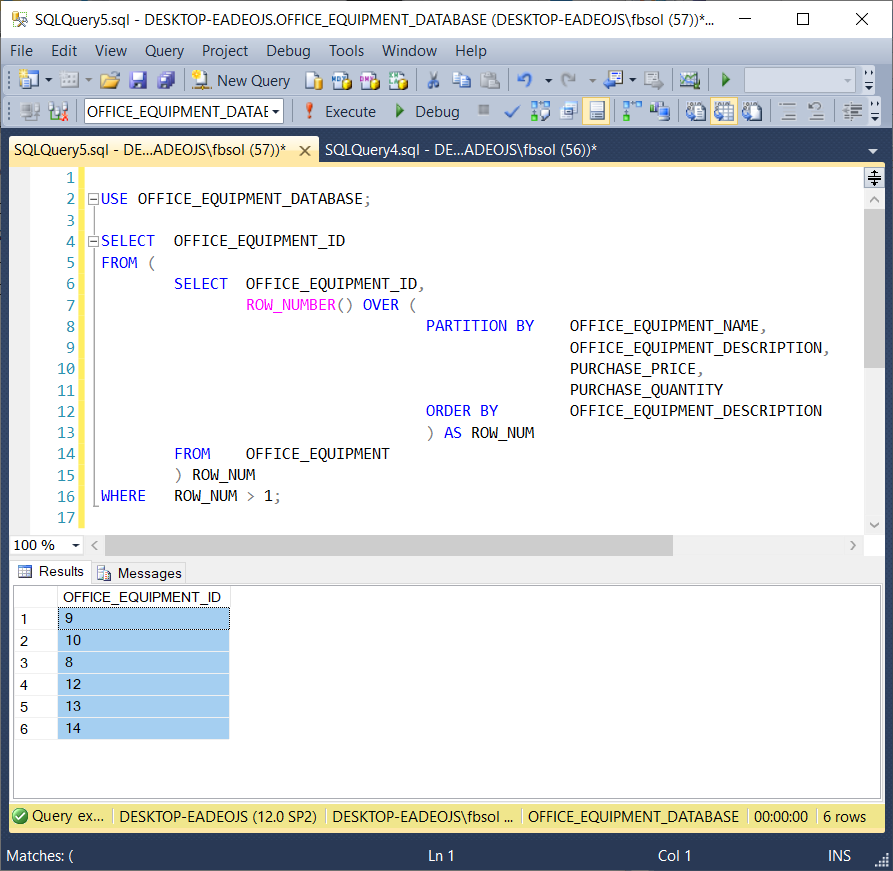
Similar to the earlier DELETE query, we placed the original ROW_NUMBER() query as a subquery in the FROM clause. The FROM clause at line 5 executes first – before the line 16 WHERE clause. This means that the T-SQL WHERE clause can see the ROW_NUMBER() data, and filter on it. Now that we have the specific OFFICE_EQUIPMENT_ID values that we need in a list, we can place these values in another table, use them in other queries, etc.
与早期的DELETE查询类似,我们将原始ROW_NUMBER()查询作为子查询放置在FROM子句中。 第5行的FROM子句首先执行-在第16行WHERE子句之前。 这意味着T-SQL WHERE子句可以看到ROW_NUMBER()数据并对其进行过滤。 现在,我们已经在列表中有了特定的OFFICE_EQUIPMENT_ID值,我们可以将这些值放在另一个表中,在其他查询中使用它们,等等。
结论 (Conclusion)
As database resources grow in size and importance, we need to measure their data quality, to identify and fix problems. As part of that, we should identify duplicate database table rows. Then, we can delete them. We can move them to other tables, other databases, or even other servers. Once we find those duplicate rows, we can decide what to do next. This article shows how to lever T-SQL to find those duplicate rows.
随着数据库资源规模和重要性的增长,我们需要衡量其数据质量,以发现并解决问题。 作为其中的一部分,我们应该识别重复的数据库表行。 然后,我们可以删除它们。 我们可以将它们移动到其他表,其他数据库甚至其他服务器。 找到这些重复的行后,我们可以决定下一步要做什么。 本文介绍了如何利用T-SQL查找那些重复的行。
翻译自: https://www.sqlshack.com/lever-t-sql-to-handle-duplicate-rows-in-sql-server-database-tables/
利用T-SQL处理SQL Server数据库表中的重复行相关推荐
- columnproperty server sql_导出SQL Server数据库表中字段的说明/备注
时 间:2013-02-18 09:09:11 作 者:摘 要:导出SQL Server数据库表中字段的说明/备注 正 文: 打开SQL企业管理器 ,找到你要导出用户表字段信息的那个数据库 ,点击工具 ...
- 如何删除SQL Server表中的重复行
若在你的MS Sql Server数据库表中,有重复的多行,你可能想去删除这些重复的记录. T_SQL Row_Number()函数能帮助sql开发者去解决这个sql的问题. 1.创建TUser表: ...
- sql删除表中重复记录_SQL从SQL表中删除重复行的不同方法
sql删除表中重复记录 This article explains the process of performing SQL delete activity for duplicate rows f ...
- 删除数据表中的重复行
原表数据 select subscrbid, prcplnid,min(begtime),min(endtime),count(*) from NEW_TRAIN_TAB_SUBSCRBPRCPLN ...
- 温故知新MySQL--如何在MySQL表中删除重复行
2019独角兽企业重金招聘Python工程师标准>>> 如何在MySQL表中删除重复行 在实际应用中,会有需要删除重复数据的场景.这里简单介绍下如何删除重复的数据 1. 准备数据 C ...
- sql server 数据库表中增加列,增加字段,插入列,插入字段,修改列,修改字段,
格式 --增加列 alter table 表名 add 字段名 类型 null default 默认值--给列增加注释 execute sp_addextendedproperty 'MS_Descr ...
- MySQL5.5.27使用Restore From SQL Dump功能导入数据库表中出现Row size too large
问题描述:MySQL数据库版本为MySQL5.5.27,在使用其Restore From SQL Dump功能导入数据库表时出现以下错误提示 Row size too large. The maxim ...
- 【SQL】去除表中的重复行
去除emp表中相同的行: SCOTT@LGR> delete from emp a where rowid not in (select max(rowid) from emp b where ...
- 消除数据库表中的重复组
重复组是在整个数据库表中重复的一系列字段/属性.大型和小型组织都面临着一个普遍的问题,这个问题可能会带来多种后果.例如,在不同区域中存在的同一组信息会导致数据冗余和数据不一致.而且,所有这些重复的数据 ...
最新文章
- 【直播】林锦弘:CV赛事高分经验分享
- 网友:Java岗,自学一个月跳槽计算机视觉,其实入门很简单
- linux c 宏定义 #define _GNU_SOURCE 含义
- PHP Memcache详解
- texturepacker使用心得
- SpringData 简单的条件查询
- SQL Server的数据导入MySQL数据库方法简介
- 华为手机可以安装python吗_何安装python2.6
- python socket udp_python网络-Socket之udp编程(24)
- ASP.NET MVC5使用AjaxHelp
- 数据结构上机实践第九周项目3 - 利用二叉树遍历思想解决问题
- Web前端:javascript实现图片轮播
- java并发包 atomic_Java并发包之AtomicXX
- ubuntu2004 安装protoc
- 深度学习MatConvNet安装
- win10重装应用商店
- 联想拯救者15isk清灰_联想拯救者-15介绍_联想 拯救者15-ISK_笔记本评测-中关村在线...
- 移动端应该如何动态设置字体大小?
- Java SPI机制详解
- TCP/IP协议概念通俗讲解, 端口号与套接字的区别