python爬网页数据用什么_初学者如何用“python爬虫”技术抓取网页数据?
原标题:初学者如何用“python爬虫”技术抓取网页数据?
在当今社会,互联网上充斥着许多有用的数据。我们只需要耐心观察并添加一些技术手段即可获得大量有价值的数据。而这里的“技术手段”就是指网络爬虫。 今天,小编将与您分享一个爬虫的基本知识和入门教程:
什么是爬虫?
网络爬虫,也叫作网络数据采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需的数据。
想要入门Python 爬虫首先需要解决四个问题:
1.熟悉python编程
2.了解HTML
3.了解网络爬虫的基本原理
4.学习使用python爬虫库

1、熟悉python编程
刚开始入门爬虫,初学者无需学习python的类,多线程,模块和其他稍微困难的内容。我们要做的是查找适合初学者的教科书或在线教程,并花费十多天的时间,您可以对python的基础知识有三到四点了解,这时候你可以玩玩爬虫了!
2、为什么要懂HTML
HTML是一种用于创建网页的标记语言,该网页嵌入了诸如文本和图像之类的数据,这些数据可以被浏览器读取并呈现为我们看到的网页。这就是为什么我们首先爬网HTML,然后解析数据的原因,因为数据隐藏在HTML中。
对于初学者来说学习HTML不难。因为它不是编程语言。 您只需要熟悉其标记规则。 HTML标记包含几个关键部分,例如标签(及其属性),基于字符的数据类型,字符引用和实体引用。
HTML标记是最常见的标记,通常成对出现,例如
和 h1>。 在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。 在两个标签之间是元素的内容(文本,图像等)。 有些标签没有内容,并且是空元素,例如。
以下是经典的Hello World程序的示例:
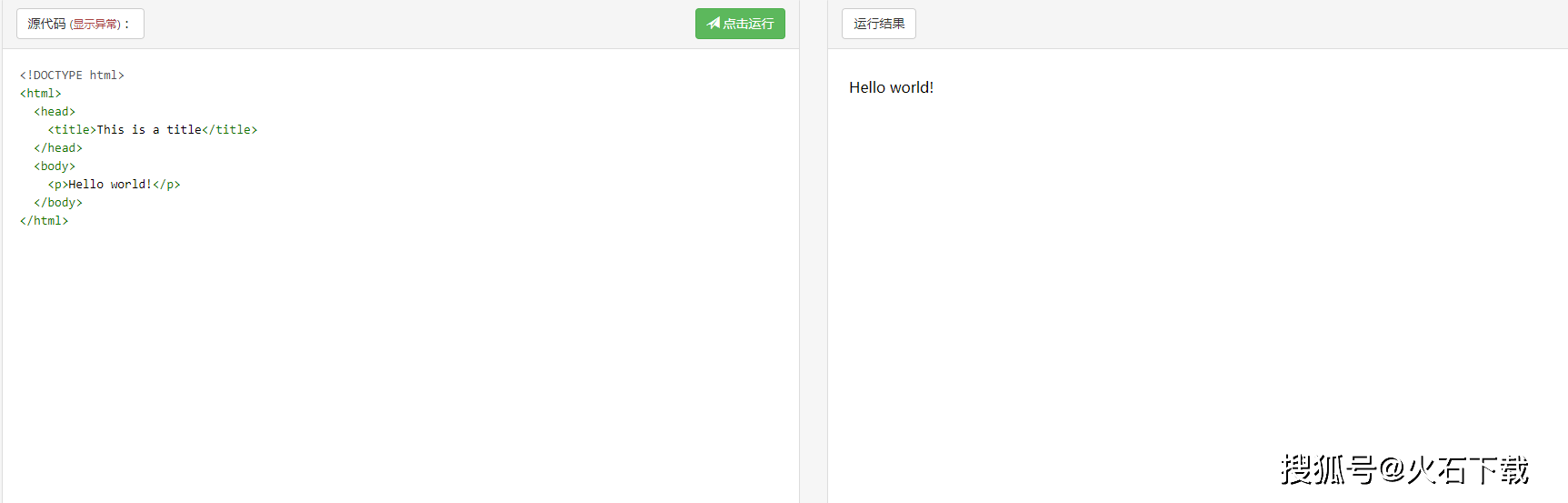
HTML文档由嵌套的HTML元素组成。 它们由括在尖括号中的HTML标记表示,例如
。 通常,一个元素由一对标记表示:“开始标记”
和“结束标记” p>。 如果元素包含文本内容,则将其放置在这些标签之间。
3、了解python网络爬虫的基本原理
编写python搜寻器程序时,只需执行以下两项操作:发送GET请求以获取HTML; 解析HTML以获取数据。 对于这两件事,python有相应的库可以帮助您做到这一点,您只需要知道如何使用它们即可。
4、用python库爬取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,该库具有urlopen函数,该函数可以根据url获取HTML文件。 在这里,尝试获取百度首页的HTML内容

看看效果:
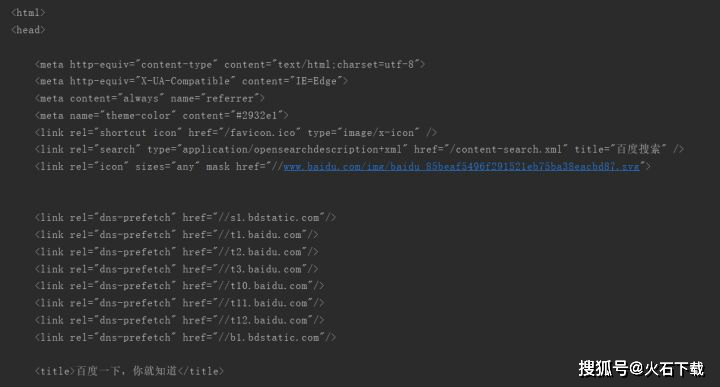
输出HTML内容的部分拦截
让我们看看真正的百度首页的html是什么样的。 如果您使用的是Google Chrome浏览器,请在百度首页上打开“设置”>“更多工具”>“开发者工具”,单击元素,您会看到:
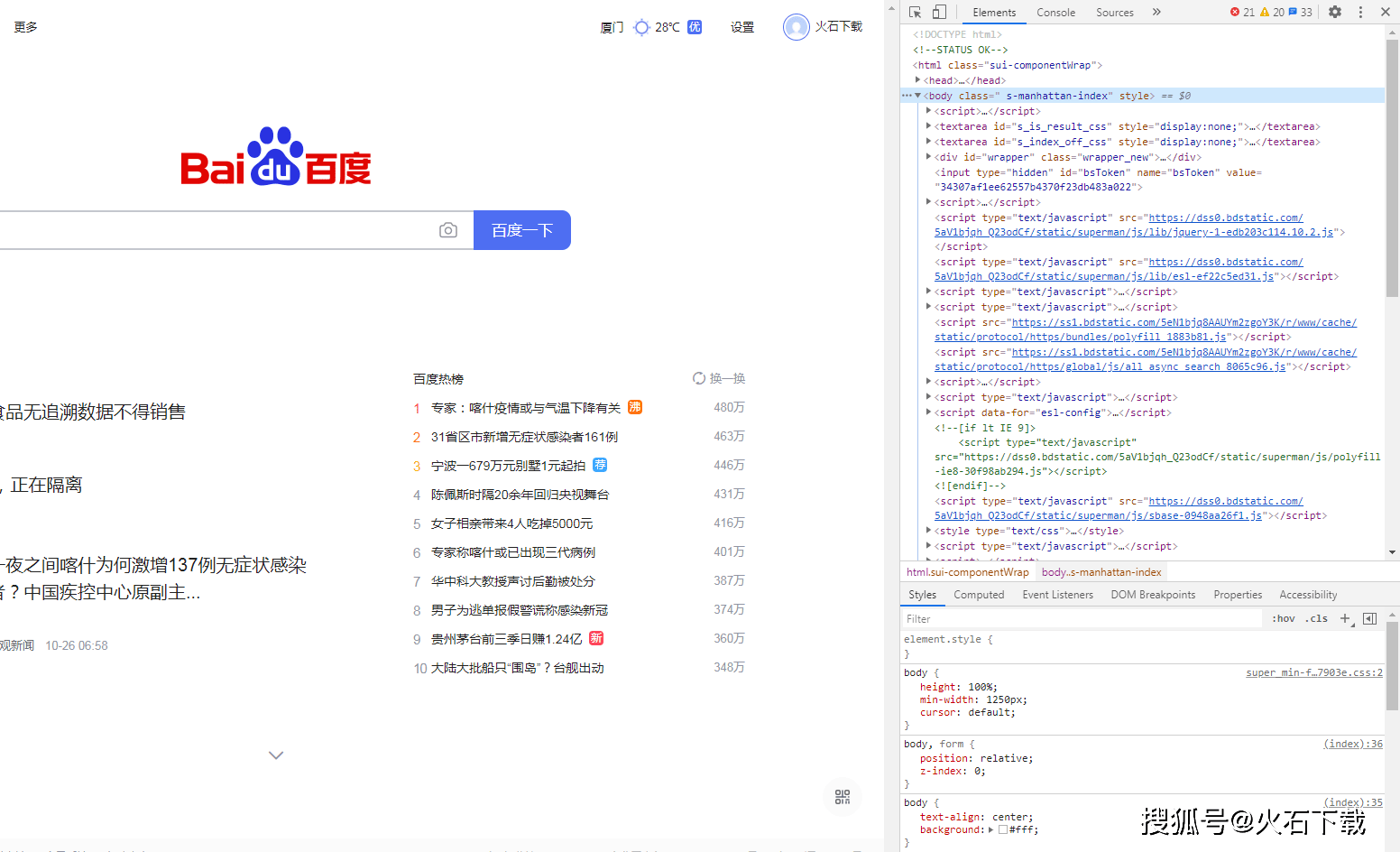
在Google Chrome浏览器中查看HTML
相比之下,您会知道刚才通过python程序获得的HTML与网页相同!
获取HTML之后,下一步是解析HTML,因为所需的文本,图片和视频隐藏在HTML中,因此您需要通过某种方式提取所需的数据。
Python还提供了许多功能强大的库来帮助您解析HTML。 在这里,著名的Python库BeautifulSoup被用作解析上面获得的HTML的工具。
BeautifulSoup是第三方库,需要安装和使用。 在命令行上使用pip安装即可:
BeautifulSoup会将HTML内容转换为结构化内容,您只需要从结构化标签中提取数据就可以了:

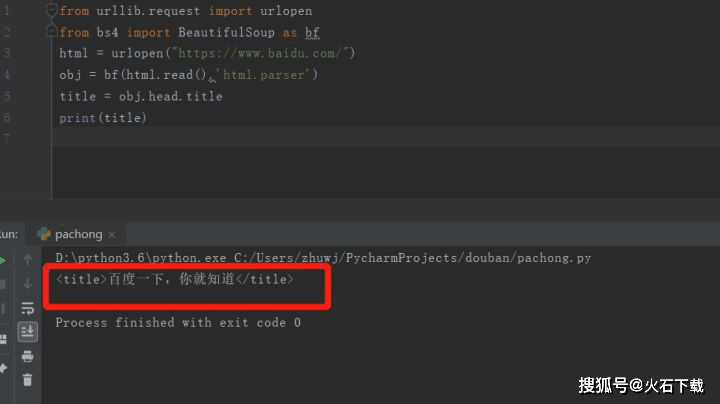
例如,我想获得百度首页的标题“百度一下,我就知道”,该怎么办?
该标题周围有两个标签,一个是第一级标签
,另一个是第二级标签,因此只需从标签中取出信息即可。

看看结果:
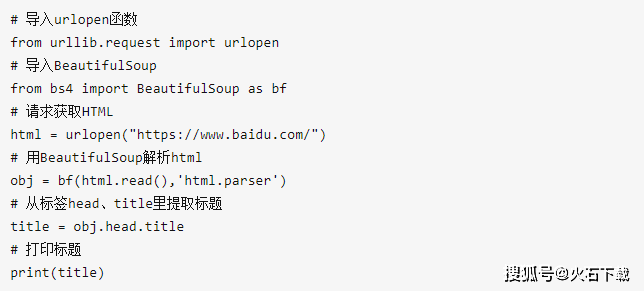
完成此操作,并成功提取了百度首页的标题。
本文以抓取百度首页标题为例,解释python爬虫的基本原理以及相关python库的使用。 这是相对基本的爬虫知识。 房屋是逐层建造的,知识是一点一点地学习的。 刚接触python的朋友们想学python爬虫就要打下良好的基础,也可以从视频资料中学习,并自己动手实践课程。
python爬网页数据用什么_初学者如何用“python爬虫”技术抓取网页数据?相关推荐
- python抓取网页电话号码_利用正则表达式编写python 爬虫,抓取网页电话号码!...
利用正则表达式编写python 爬虫,抓取网页联系我们电话号码!这里以九奥科技(www.jiuaoo.com)为例,抓取'联系我们'里面的电话号码,并输出. #!/usrweilie/bin/pyth ...
- python正则表达式提取电话号码_利用正则表达式编写python 爬虫,抓取网页电话号码!...
利用正则表达式编写python 爬虫,抓取网页联系我们电话号码!这里以九奥科技(www.jiuaoo.com)为例,抓取'联系我们'里面的电话号码,并输出. #!/usrweilie/bin/pyth ...
- python推特爬虫_Tweepy1_抓取Twitter数据
之前一直想用爬虫登陆并抓取twitter数据,试过scrapy,requests等包,都没成功,可能是我还不太熟悉的原因,不过 今天发现了一个新包tweepy,专门用于在Python中处理twitte ...
- java爬虫 京东_教您使用java爬虫gecco抓取JD全部商品信息(一)
#教您使用java爬虫gecco抓取JD全部商品信息(一) ##gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全部商品信息的抓取 ...
- python数据抓取技术与实战训练_师傅带徒弟学Python:项目实战1:网络爬虫与抓取股票数据...
本视频基于**Python 3.X版本 本视频课程是第四篇第一个实战项目,内容包括网络爬虫技术.使用urllib爬取数据.使用Selenium爬取数据.使用正则表达式.使用BeautifulSoup库 ...
- python爬虫爬取网页图片_Python爬虫实现抓取网页图片
在逛贴吧的时候看见贴吧里面漂亮的图片,或有漂亮妹纸的图片,是不是想保存下来? 但是有的网页的图片比较多,一个个保存下来比较麻烦. 最近在学Python,所以用Python来抓取网页内容还是比较方便的: ...
- java爬虫异步取数据_教您使用java爬虫gecco抓取JD全部商品信息(三)
##详情页抓取 商品的基本信息抓取完成后,就要针对每个商品的详情页进行抓取,可以看到详情页的地址格式一般如下:http://item.jd.com/1861098.html.我们建立商品详情页的Bea ...
- python一个图画两条曲线_烦恼如何用python同一图里画多数据曲线吗?教你6种解法...
概要: python的matplotlib作图很强大,本文教你用6种不同方式解决将多种数据曲线画到一起. 问题: 今天,老板又要一个数据报表,小明选择用 python来实现."用matplo ...
- Scrapy爬虫轻松抓取网站数据
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也 ...
最新文章
- aidl使用_借助 AIDL 理解 Android Binder 机制——Binder 来龙去脉
- linux mread 命令详解
- Android Studio不安装opencv manager配置
- php显示TABLE数据
- UA MATH523A 实分析3 积分理论例题 Fubini定理计算简单二重积分的一个例题
- c 正则提取html,c – 正则表达式以获取HTML表格内容
- unchecked异常_为什么要在Java中使用Unchecked异常而不是Checked异常
- 《Power Designer系统分析与建模实战》——2.1 需求模型简介
- python读行-Python如何一次读取N行
- HTML5中Nav元素作用及应用场景知识点
- VC++2010Express下载
- 备战秋招之数电模电知识点
- 电磁场与电磁波公式总结
- 计算机网络适配器高级属性,右击我的电脑——属性——设备管理器——1394网络适配器下面那个选项右击属性——高级——大量传送减负——...
- easyui-filebox文件上传格式
- Speedtest在线测试html,配置HTML5 Speedtest测试本地与服务器之间的速度
- 听声变位测试软件,刺激战场:听声辩位其实有很大的学问,想了解的朋友请进来...
- 跳跃游戏 (动态规划剪枝/前缀和/滑动窗口/BFS剪枝)
- 【E2E】E2E通信保护协议学习1
- word如何添加页码
热门文章
- python使用正则表达式识别大写字母并在大写字母前插入空格
- 机器学习的优化目标、期望最大化(Expectation-Maximum, EM)算法、期望最大化(EM)和梯度下降对比
- Linux下测试的c++的使用
- lisp 线性标注自动避让_泰州支重轮双头车自动化生产线
- javascript 判断字符串中是否包含某个字符串
- 模型加速--CLIP-Q: Deep Network Compression Learning by In-Parallel Pruning-Quantization
- ubuntu安装KVM
- 宝塔服务器环境好不好_服务器环境怎么搭建?(宝塔环境搭建教程)
- 鸿蒙系统合适上线手机端,华为官方:鸿蒙系统2.0上线,手机能否搭载鸿蒙操作系统?...
- python mqtt tls_python mqtt使用