cenos7 阿里云数据库扩容步骤
扩容数据盘_Linux
扩容这种数据盘需要在控制台上重启实例后才能使扩容后的容量生效,而重启实例会停止实例,中断您的业务,所以请您谨慎操作。
包年包月实例如果做过 续费降配 操作,当前计费周期的剩余时间内,实例上的包年包月云盘不支持扩容磁盘操作。
如果数据盘正在创建快照,则不允许执行扩容数据盘的操作。
磁盘扩容功能只能扩容数据盘,不能扩容系统盘或本地盘(本地 SSD 盘等)。
步骤 1. 在控制台上扩容数据盘的磁盘空间
按以下步骤在控制台上扩容数据盘的磁盘空间:
登录 ECS管理控制台。
在左侧导航栏里,选择 存储 > 云盘。说明 如果您需要扩容的数据盘已经挂载在某个实例上,您可以单击 实例,找到相应实例后,进入实例详情页,并单击 本实例磁盘。
选择地域。
找到需要扩容的磁盘,并在 操作 列中,选择 更多 > 磁盘扩容。
在 磁盘扩容 页面上,设置 扩容后容量,在本示例中为30 GiB。扩容后容量只能比当前容量大。
待页面上显示费用信息后,单击 确定扩容。说明 扩容成功后,磁盘列表里即显示扩容后的容量。但是,如果您的数据盘已经挂载到实例上,只有在控制台上 重启实例 后,登录实例才能看到新的磁盘空间容量。
如果数据盘已经挂载到实例上,您必须 登录实例扩容文件系统。
如果数据盘未挂载到实例上,您必须先挂载数据盘(参见 挂载云盘),再根据数据盘的实际情况执行不同的操作:
如果这是一个未格式化的数据盘,您必须格式化数据盘。详细信息,请参见 Linux 格式化和挂载数据盘。
如果这个数据盘之前已经格式化并分区,您必须 登录实例扩容文件系统。
步骤 2. 登录实例扩容文件系统
在ECS控制台上完成磁盘扩容后,磁盘每个分区的文件系统并未扩容。您需要登录实例扩容文件系统。
在本示例中,假设数据盘挂载在一台Linux实例上,实例的操作系统为CentOS 7.3 64位,未扩容前的数据盘只有一个主分区(/dev/vdb1,ext4文件系统),文件系统的挂载点为 /resizetest,文件系统扩容完成后,数据盘仍然只有一个主分区。
远程连接实例。
运行
umount命令卸载主分区。umount /dev/vdb1
说明 使用
df -h查看是否卸载成功,如果看不到 /dev/vdb1 的信息表示卸载成功。以下为示例输出结果。[root@iXXXXXX ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 40G 1.5G 36G 4% / devtmpfs 487M 0 487M 0% /dev tmpfs 497M 0 497M 0% /dev/shm tmpfs 497M 312K 496M 1% /run tmpfs 497M 0 497M 0% /sys/fs/cgroup tmpfs 100M 0 100M 0% /run/user/0
使用
fdisk命令删除原来的分区并创建新分区:说明 如果您使用parted工具操作分区,不能与fdisk交叉使用,否则会导致分区的起始扇区不一致。关于parted工具的使用说明可以参考这里。运行命令
fdisk -l罗列分区信息并记录扩容前数据盘的最终容量、起始扇区(First sector)位置。运行命令
fdisk [数据盘设备名]进入fdisk界面。本示例中,命令为fdisk /dev/vdb。输入 d 并按回车键,删除原来的分区。说明 删除分区不会造成数据盘内数据的丢失。
输入 n 并按回车键,开始创建新的分区。
输入 p 并按回车键,选择创建主分区。因为创建的是一个单分区数据盘,所以只需要创建主分区。说明 如果要创建4个以上的分区,您应该创建至少一个扩展分区,即选择
e。输入分区编号并按回车键。因为这里仅创建一个分区,所以输入 1。
输入第一个可用的扇区编号:为了保证数据的一致性,First sector需要与原来的分区保持一致。在本示例中,按回车键采用默认值。说明 如果发现First sector显示的位置和之前记录的不一致,说明之前可能使用
parted来分区,那么就停止当前的fdisk操作,使用 parted 重新操作。输入最后一个扇区编号:因为这里仅创建一个分区,所以按回车键采用默认值。
输入
wq并按回车键,开始分区。[root@iXXXXXX ~]# fdisk /dev/vdb Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): d Selected partition 1 Partition 1 is deleted Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): Using default response p Partition number (1-4, default 1): First sector (2048-62914559, default 2048): Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-62914559, default 62914559): Using default value 62914559 Partition 1 of type Linux and of size 30 GiB is set Command (m for help): wq The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks.说明 如果您使用的是
parted工具,进入parted界面后,输入 p 罗列当前的分区情况。如果有分区,则使用 rm+ 序列号来删除老的分区表,然后使用unit s定义起始位置,单位使用扇区个数计量,最后使用mkpart命令来创建即可,如下图所示。
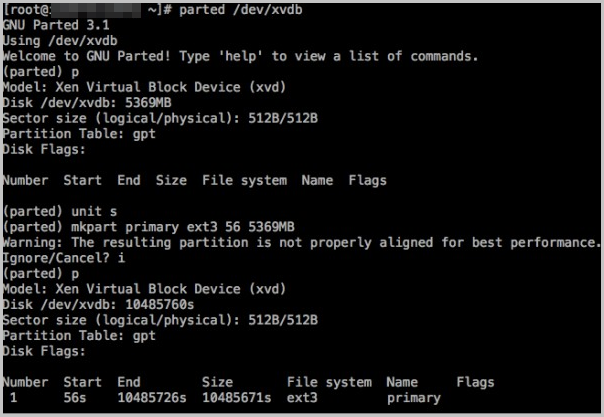
部分操作系统里,修改分区后可能会重新自动挂载文件系统。建议先执行
df -h重新查看文件系统空间和使用情况。如果文件系统重新被挂载,执行umount [文件系统名称]再次卸载文件系统。检查文件系统,并变更文件系统大小。
xfs_growfs /dev/vdb1 # 变更文件系统大小
说明
以下为示例输出结果。
[root@iXXXXXX ~]# xfs_growfs /dev/vdb1 e2fsck 1.42.9 (28-Dec-2013) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/vdb1: 11/1835008 files (0.0% non-contiguous), 159218/7339776 blocks [root@iXXXXXX ~]# resize2fs /dev/vdb1 resize2fs 1.42.9 (28-Dec-2013) Resizing the filesystem on /dev/vdb1 to 7864064 (4k) blocks. The filesystem on /dev/vdb1 is now 7864064 blocks long.
使用
e2fsck时,由于系统需要检查并订正文件系统元数据,所以速度较慢、耗时较长,请耐心等待。正确使用
e2fsck和resize2fs指令,不会造成原有数据丢失。
将扩容完成的文件系统挂载到原来的挂载点(如本示例中的 /resizetest)。
mount /dev/vdb1 /resizetest
查看文件系统空间和使用情况:运行命令 df -h。如果出现扩容后的文件系统信息,说明挂载成功,可以使用扩容后的文件系统了。说明 挂载操作完成后,不需要在控制台上重启实例即可开始使用扩容后的文件系统。
以下为示例输出结果。
[root@iXXXXXX ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 40G 1.5G 36G 4% / devtmpfs 487M 0 487M 0% /dev tmpfs 497M 0 497M 0% /dev/shm tmpfs 497M 312K 496M 1% /run tmpfs 497M 0 497M 0% /sys/fs/cgroup tmpfs 100M 0 100M 0% /run/user/0 /dev/vdb1 30G 44M 28G 1% /resizetest
转载于:https://blog.51cto.com/13293070/2330048
cenos7 阿里云数据库扩容步骤相关推荐
- 阿里云数据库RDS MySQL Serverless测评
文章目录 1. 背景 2. 概念 3. 操作步骤 3.1 购买产品 3.2 配置RDS账号 3.3 设置网络访问权限 3.4 连接实例 4. 与自建数据库相比的优势 4.1 弹性设置 4.2 监控比较 ...
- MySQL性能优化、故障排查及最佳实践秘籍,阿里云数据库专家玄惭的“武功”全记录...
为什么80%的码农都做不了架构师?>>> 文章简介 玄惭,真名罗龙九,阿里云DBA专家,负责阿里云RDS线上稳定以及专家服务团队.他经历过阿里历年双11实战考验,积累了7年对阿 ...
- 阿里云数据库产品HybridDB简介——OLAP数据库,支持行列混合存储,为用户提供基于开源 OLTP、OLAP、BigData 生态的一站式解决方案...
12 月 9 日,阿里云宣布数据库产品 HybridDB 正式商业化. HybridDB(ApsaraDB HybridDB)是一款在线 MPP 大规模并行处理数据仓库的服务.它基于 Pivotal ...
- 玄惭 mysql_阿里云数据库专家玄惭的“武功”全记录之最佳实践、双十一特别篇...
原标题:阿里云数据库专家玄惭的"武功"全记录之最佳实践.双十一特别篇 专题简介 玄惭,真名罗龙九,阿里云DBA专家,负责阿里云RDS线上稳定以及专家服务团队.他经历过阿里历年双11 ...
- 媒体声音 | 阿里云王伟民:阿里云数据库的策略与思考
简介: DTCC 2021大会上,阿里云数据库事业部 产品与解决方案部总经理 王伟民(花名:唯敏)发表主题演讲<云原生数据库2.0,一站式全链路数据管理与服务>,并接受IT168企业级&a ...
- 鹏博士和阿里云数据库产品达成战略合作,共赢企业数智化创新市场
简介:近日,生态伙伴的全国总经销商鹏博士与阿里云数据库产品达成战略合作,通过阿里云云原生数据库的产品能力和鹏博士的企业服务能力,助力企业数字创新.鹏博士有服务客户的良好基因,数据库领域也是我们在前行过 ...
- 一文读懂阿里云数据库Autoscaling是如何工作的
简介:阿里云数据库实现了其特有的Autosaling能力,该能力由数据库内核.管控及DAS(数据库自治服务)团队共同构建,内核及管控团队提供了数据库Autoscaling的基础能力,DAS则负责性能数 ...
- redis数据库价格_阿里云数据库Redis购买流程
下面介绍的阿里云数据库Redis购买流程已失效(因阿里云已改版),不必看了. 1.登录阿里云官网,进入控制台-阿里云数据库Redis . 2.在实例列表页, 点击[购买阿里云数据库Redis]按钮,进 ...
- 阿里云mysql服务器太贵_阿里云数据库,跟自己在服务器安装的有什么区别?有人说安装很简单,那为什么要花钱买?...
网友解答: 这个问题本质上就是私有云与公有云的区别.私有云所有的事情都是自己操心,自己采购.自己部署.自己运维,换来的是自己对IT的100%的控制.而公有云很多工作交给了服务商,没有采购的环境.没有运 ...
最新文章
- 中科大提出统一输入过滤框架InFi:首次理论分析可过滤性,支持全数据模态
- gRPC源码分析(c++)
- Django从理论到实战(part9)--path和re_path
- PS教程第十三课:是时候开始战斗了
- MySql某一列累计查询
- 现实生活中我们常常遭遇“怀疑”
- 1.9 编程基础之顺序查找 09 直方图 9分 python
- DB pivot unpivot
- 大数据之-Hadoop3.x_MapReduce_WordCount案例需求分析---大数据之hadoop3.x工作笔记0087
- python从入门到实践课后题_Python 从入门到实践 函数篇 8-6-8习题
- h710阵列卡支持最大硬盘_ORICO推爆品五盘位硬盘柜,一拖五最大支持80TB,你会买吗?...
- 我眼中的《APUE》
- ccy_dlx 模块化与全局变量7-8ms
- mysql blast2go,blast2go
- 通过简单脚本批量取消新浪微博的关注
- 个人资源小仓库之【工具】!
- 时分秒倒计时的js实现
- javascript-obfuscator 代码混淆
- java 四舍五入保留小数点后两位
- Winsock套接字开发网络聊天室实例(C/S)模式
热门文章
- 倒计时或按任意键返回首页_客服魔方更新:首页界面大改版,催拍催付操作更方便...
- C++: 不可拷贝(noncopyable)类
- LeetCode 93. Restore IP Addresses--面试算法题--Python解法
- vscode 使用ssh密钥登录远程Linux -- vscode remote linux ssh key
- 服务器查看gpu状态_如何查看服务器gpu
- php自定义函数出现乱码,php的imagettftext 函数出现乱码的解决方法
- jdbcpingquery mysql_JDBC - liuping - 博客园
- JAVA批量上传下载Excel_如何实现批量上传----------Java解析excel
- mysql文章浏览计数_高并发文章浏览量计数系统设计
- python asyncio tcp server_Python 3.4 中新的 asyncio : Servers、Protocols 和 Transports