六十.完全分布式 、 节点管理 、 NFS网关
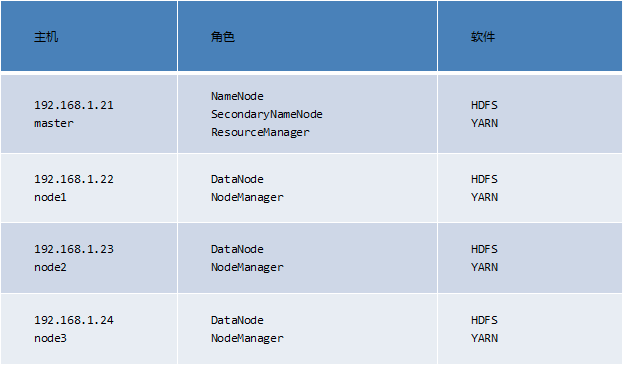

3.1 增加节点
1)增加一个新的节点node4
node4 ~]# yum -y install rsync
node4 ~]# yum -y install java-1.8.0-openjdk-devel
node4 ~]# mkdir /var/hadoop
nn01 ~]# ssh-copy-id 192.168.1.25
nn01 ~]# vim /etc/hosts
192.168.1.21 nn01
192.168.1.22 node1
192.168.1.23 node2
192.168.1.24 node3
192.168.1.25 node4
nn01 ~]# scp /etc/hosts 192.168.1.25:/etc/
nn01 ~]# cd /usr/local/hadoop/
hadoop]# vim ./etc/hadoop/slaves
node1
node2
node3
node4
//同步配置 (jobs -l 确保node4同步完成!)
hadoop]# for i in {22..25}; do rsync -aSH --delete /usr/local/hadoop/ \
192.168.1.$i:/usr/local/hadoop/ -e 'ssh' & done
[1] 12375
[2] 12376
[3] 12377
[4] 12378
node4 hadoop]# ./sbin/hadoop-daemon.sh start datanode //node4启动
2)查看状态
node4 hadoop]# jps
12470 Jps
12396 DataNode
3)设置同步带宽 #其他NN将数据匀一部分过来,匀数据的时候不能占用所有带宽
node4 hadoop]# ./bin/hdfs dfsadmin -setBalancerBandwidth 60000000
Balancer bandwidth is set to 60000000
node4 hadoop]# ./sbin/start-balancer.sh
starting balancer...
nn01 hadoop]# ./bin/hdfs dfsadmin -report #查看状态
Live datanodes (4):...(有node4)
4)删除节点
nn01 hadoop]# vim /usr/local/hadoop/etc/hadoop/slaves
//去掉之前添加的node4
node1
node2
node3
nn01 hadoop]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
//在此配置文件里面加入下面四行
...
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
</property>
nn01 hadoop]# vim /usr/local/hadoop/etc/hadoop/exclude
node4
5)导出数据
nn01 hadoop]# ./bin/hdfs dfsadmin -refreshNodes
Refresh nodes successful
nn01 hadoop]# ./bin/hdfs dfsadmin -report #等待
//查看node4,不要动机器,等待node4显示Decommissioned
Dead datanodes (1):
Name: 192.168.1.25:50010 (node4)
Hostname: node4
Decommission Status : Decommissioned... #显示Decommissioned 才可以
node4 hadoop]# ./sbin/hadoop-daemon.sh stop datanode //停止datanode
stopping datanode
node4 hadoop]# ./sbin/yarn-daemon.sh start nodemanager
//yarn 增加 nodemanager
node4 hadoop]# jps
10342 NodeManager
10446 Jps
node4 hadoop]# ./sbin/yarn-daemon.sh stop nodemanager //停止nodemanager
stopping nodemanager #jps 将没有NodeManager
node4 hadoop]# ./bin/yarn node -list
//yarn 查看节点状态,还是有node4节点,要过一段时间才会消失
19/03/02 18:40:27 INFO client.RMProxy: Connecting to ResourceManager at nn01/192.168.1.21:8032
Total Nodes:4
Node-Id Node-StateNode-Http-AddressNumber-of-Running-Containers
node2:36669 RUNNING node2:8042 0
node4:38698 RUNNING node4:8042 0
node3:36146 RUNNING node3:8042 0
node1:34124 RUNNING node1:8042 0
4.NFS配置
创建代理用户
启动一个新系统,禁用Selinux和firewalld
配置NFSWG
启动服务
挂载NFS并实现开机自启
4.1 基础准备
1)更改主机名,配置/etc/hosts(/etc/hosts在nn01和nfsgw上面配置)
localhost ~]# echo nfsgw > /etc/hostname
localhost ~]# hostname nfsgw
nn01 ~]# ssh-copy-id 192.168.1.26
nn01 hadoop]# vim /etc/hosts
192.168.1.21 nn01
192.168.1.22 node1
192.168.1.23 node2
192.168.1.24 node3
192.168.1.25 node4
192.168.1.26 nfsgw
2)创建代理用户(nn01和nfsgw上面操作),以nn01为例子
nn01 hadoop]# groupadd -g 200 nfs
nn01 hadoop]# useradd -u 200 -g nfs nfs
3)配置core-site.xml
nn01 hadoop]# ./sbin/stop-all.sh //停止所有服务
This script ...
nn01 hadoop]# cd etc/hadoop
nn01 hadoop]# >exclude
nn01 hadoop]# vim core-site.xml #添加
<property>
<name>hadoop.proxyuser.nfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.nfs.hosts</name>
<value>*</value>
</property>
4)同步配置到node1,node2,node3
nn01 hadoop]# for i in {22..24}; do rsync -aSH --delete /usr/local/hadoop/ 192.168.1.$i:/usr/local/hadoop/ -e 'ssh' & done
[4] 2722
[5] 2723
[6] 2724 #jobs -l 确保同步完成!
5)启动集群
nn01 hadoop]# /usr/local/hadoop/sbin/start-dfs.sh
6)查看状态
nn01 hadoop]# /usr/local/hadoop/bin/hdfs dfsadmin -report
Live datanodes (3):... #恢复到3
4.2 NFSGW配置
1)安装java-1.8.0-openjdk-devel和rsync
nfsgw ~]# yum -y install java-1.8.0-openjdk-devel
nfsgw ~]# yum -y install rsync
nn01 hadoop]# rsync -avSH --delete \
/usr/local/hadoop/ 192.168.1.26:/usr/local/hadoop/ -e 'ssh'
2)创建数据根目录 /var/hadoop(在NFSGW主机上面操作)
nfsgw ~]# mkdir /var/hadoop
3)创建转储目录,并给用户nfs 赋权
nfsgw ~]# mkdir /var/nfstmp
nfsgw ~]# chown nfs:nfs /var/nfstmp
4)给/usr/local/hadoop/logs赋权(在NFSGW主机上面操作)
nfsgw ~]# setfacl -m u:nfs:rwx /usr/local/hadoop/logs
nfsgw ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml #新添加
<property>
<name>nfs.exports.allowed.hosts</name>
<value>* rw</value>
</property>
<property>
<name>nfs.dump.dir</name>
<value>/var/nfstmp</value>
</property>
5)可以创建和删除即可
nfsgw ~]# su - nfs
nfsgw ~]$ cd /var/nfstmp/
nfsgw nfstmp]$ touch 1
nfsgw nfstmp]$ ls
1
nfsgw nfstmp]$ rm -rf 1
nfsgw nfstmp]$ ls
nfsgw nfstmp]$ cd /usr/local/hadoop/logs/
nfsgw logs]$ touch 1
nfsgw logs]$ ls
1 hadoop-root-secondarynamenode-nn01.log
hadoop-root-datanode-nn01.log hadoop-root-secondarynamenode-nn01.out
hadoop-root-datanode-nn01.out hadoop-root-secondarynamenode-nn01.out.1
hadoop-root-namenode-nn01.log SecurityAuth-root.audit
hadoop-root-namenode-nn01.out yarn-root-resourcemanager-nn01.log
hadoop-root-namenode-nn01.out.1 yarn-root-resourcemanager-nn01.out
nfsgw logs]$ rm -rf 1
nfsgw logs]$ ls
6)启动服务
nfsgw ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh --script ./bin/hdfs start portmap
//portmap服务只能用root用户启动
starting portmap, logging to /usr/local/hadoop/logs/hadoop-root-portmap-nfsgw.out
nfsgw ~]# jps
1091 Jps
1045 Portmap
nfsgw ~]# su - nfs
nfsgw ~]$ cd /usr/local/hadoop/
nfsgw hadoop]$ ./sbin/hadoop-daemon.sh --script ./bin/hdfs start nfs3
//nfs3只能用代理用户启动
tarting nfs3, logging to /usr/local/hadoop/logs/hadoop-nfs-nfs3-nfsgw.out
nfsgw hadoop]$ jps
1139 Nfs3
1192 Jps
nfsgw hadoop]# jps //root用户执行可以看到portmap和nfs3
1139 Nfs3
1204 Jps
1045 Portmap
7)实现客户端挂载(客户端可以用node4这台主机)
node4 ~]# rm -rf /usr/local/hadoop
node4 ~]# yum -y install nfs-utils
node4 ~]# mount -t nfs -o \
vers=3,proto=tcp,nolock,noatime,sync,noacl 192.168.1.26:/ /mnt/
//挂载 df -h 查看
node4 ~]# cd /mnt/
node4 mnt]# ls
aaa bbb fa system tmp
node4 mnt]# touch a
node4 mnt]# ls
a aaa bbb fa system tmp
node4 mnt]# rm -rf a
node4 mnt]# ls
aaa bbb fa system tmp
8)实现开机自动挂载
node4 ~]# vim /etc/fstab
192.168.1.26:/ /mnt/ nfs vers=3,proto=tcp,nolock,noatime,sync,noacl,_netdev 0 0
node4 ~]# mount -a
node4 ~]# df -h
192.168.1.26:/ 80G 8.2G 72G 11% /dvd
node4 ~]# rpcinfo -p 192.168.1.26
program vers proto port service
100005 3 udp 4242 mountd
100005 1 tcp 4242 mountd
100000 2 udp 111 portmapper
100000 2 tcp 111 portmapper
100005 3 tcp 4242 mountd
100005 2 tcp 4242 mountd
100003 3 tcp 2049 nfs
100005 2 udp 4242 mountd
100005 1 udp 4242 mountd
01:Yarn:集群资源管理系统(核心组件,集群资源管理系统)
MapReduce结构 分布式计算框架
02:(NFS)节点管理 增加 删除 修复
03:Yarn节点管理(NodeManager) 增加 删除
04:NFS网关(HDFS client + NFS server)
访问HDFS文件系统必须是HDFS客户端
将HDFS文件系统mount到本地(使用NFSv3协议,任何机器直接能挂载)
外部客户端要访问 HDFS文件系统,通过NFS网关,采用NFS挂载的方式,NFS网关将NFS指令转化为HDFS客户端的指令,发给HDFS client,以HDFS客户端的方式访问后端HDFS文件系统,NFS网关起到代理转发的作用。
#######################
转载于:https://www.cnblogs.com/luwei0915/p/10496585.html
六十.完全分布式 、 节点管理 、 NFS网关相关推荐
- 信息系统项目管理师必背核心考点(六十)项目集管理
科科过为您带来软考信息系统项目管理师核心重点考点(六十)项目集管理,内含思维导图+真题 [信息系统项目管理师核心考点]项目集指导委员会 1.又称项目集治理委员会,主要负责定义并执行恰当的项目集治理体系 ...
- Hadoop集群管理与NFS网关
目录 一.Hadoop集群管理 1.访问集群文件系统 2.重新初始化集群 3.增加新的节点 4.修复节点 5.删除节点 二.NFS网关 1.NFS网关概述 2.NFS网关架构图 3.HDFS用户授权 ...
- 【Microsoft Azure 的1024种玩法】六十二.利用Azure Private DNS 实现虚拟网络中域名的管理解析
[简介] Azure Private DNS是Azure为我们虚拟网络提供的安全可靠的DNS服务,我们无需自行配置DNS即可在虚拟网络中实现域名的解析及配置, 于此同时,我们在内网中也可以利用自己的自 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念...
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲-elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 数据库管理-第四十九期 Exadata的存储节点管理(20221223)
数据库管理 2022-12-23 第四十九期 Exadata的存储节点管理 1 咋个查看数据是否被缓存到闪存卡了没 2 EM13.5的Exadata监控 3 存储降级 总结 第四十九期 Exadata ...
- Senparc.Weixin.MP SDK 微信公众平台开发教程(十六):AccessToken自动管理机制
在<Senparc.Weixin.MP SDK 微信公众平台开发教程(八):通用接口说明>中,我介绍了获取AccessToken(通用接口)的方法. 在实际的开发过程中,所有的高级接口都需 ...
- 六十八个超级经典的管理故事
一. 用人之道 去过庙的人都知道,一进庙门,首先是弥陀佛,笑脸迎客,而在他的北面,则是黑口黑脸的韦陀.但相传在很久以前,他们并不在同一个庙里,而是分别掌管不同的庙.弥乐佛热情快乐,所以来的人非常多,但 ...
- 六十八个超级经典管理小故事(转)
一. 用人之道 去过庙的人都知道,一进庙门,首先是弥陀佛,笑脸迎客,而在他的北面,则是黑口黑脸的韦陀.但相传在很久以前,他们并不在同一个庙里,而是分别掌管不同的庙. 弥乐佛热情快乐,所以来的人非常多, ...
- 面渣逆袭:三万字,七十图,详解计算机网络六十二问(收藏版)
大家好,我是老三,开工大吉,虎年第一篇,面渣逆袭系列继续! 这次给大家带来了计算机网络六十二问,三万字,七十图详解,大概是全网最全的网络面试题. 建议大家收藏了慢慢看,新的一年一定能够跳槽加薪,虎年& ...
最新文章
- 关于Java 垃圾收集器你应该知道这些
- 传奇世界RollBall设计
- XamarinSQLite教程在Xamarin.Android项目中定位数据库文件
- Java Review - 并发组件ConcurrentHashMap使用时的注意事项及源码分析
- 安卓自动化测试(一)
- Windows下Oracle的下载与安装
- oracle 数据更新
- mysql 命令行 设置同步_MySQL同步(二) 设置同步
- Mybatis(12)事务原理和自动提交设置
- android java 时间格式化_(Java / Android)计算两个日期之间的日期,并以特定格式显示结果...
- linux清除硬盘,linux下清除硬盘的几种方法
- Java商店管理系统
- 用Python合并文件夹下所有pdf文件(包括多级子目录下的pdf文件)
- Java版通用身份证验证
- Linux下oracle数据库备份方案
- COMSOL求解常微分方程
- Win10如何删除输入法(删除默认输入法)
- ubuntu无法识别android手机
- 拼多多关键词推广技巧有哪
- 【OpenCV学习】 《OpenCV3编程入门》--毛星云 01 邂逅OpenCV(OpenCV基本概念与基本架构) ROS系统上的运用(python实现)
热门文章
- Ubuntu安装webmin
- 增长黑盒:零代码基础做智能电商网站,不要重复发明轮子
- Logback Pattern 日志格式配置
- centos7和centos6的区别
- Codeforces Beta Round #9 (Div. 2 Only) C. Hexadecimal's Numbers dfs
- iOS - 切换图片/clip subview/iCarousel
- Tcpdump源码分析系列7:main函数
- Vue 组件间通信方法汇总
- 加/减数组中的值得到指定的和 Target Sum
- CentOS Linux解决Device eth0 does not seem to be present