从商业视角理解数据:数据科学家的思维之路
在过去的几个月内,来自不同行业人不约而同问我能否提供一个端到端的视图,使他们了解成为一个数据科学家的思维过程。为这个问题寻找答案时,我想的不仅仅是提供一个端到端的视图过程,而是面对一个分析问题时我们应该更深入的了解他/她是怎么想的。
接下来我将分五个板块带领大家体验数据科学家的思维之路。文章的前半部分将介绍数据科学家如何进行任务的公式化建模以及数据点的工程化,这样可以为我们后续数据科学之旅提供规范和方向。我们还将深入了解整个生命周期中的另外两个重要因素,即探索性数据分析和特征工程。这些过程在制定问题的正确模型方面是很重要的。
当我们试图解开数据科学家的思维过程时,我们需要经历如下五个过程:
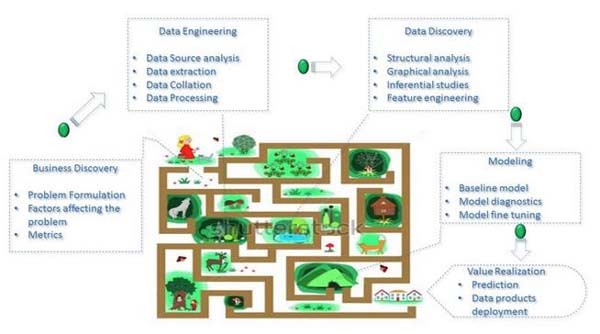
以上是对数据科学家试着定位问题时思维迷宫的一个鸟瞰图。所以让我们沿着这些路径指示并开始踏上数据科学家思维之旅。
一、业务探索:开始
每次开始总有一些业务挑战或问题,这些困难为以后的数据科学铺平了道路。
为了更能理解,我们先举个例子,假设一个农产品公司生产鸡蛋,然后找到我们,希望能够帮助他们预测鸡蛋的产量。为了能解决这些业务预测问题,他们给了我们内部系统中的可用历史数据。
那你认为我们应该从哪里开始着手这个任务呢?最好的方法是对不利于我们预测的变量建立直觉和假设。我们可以称它为响应变量,在该例子中就是产蛋量。为了获得影响我们响应变量关键因素的直觉,我们必须采取一些辅助研究并且跟该公司的相关人员进行接洽。我们可以把这一阶段作为熟悉、业务发现的阶段。在这个阶段,我们建立对影响我们响应变量关键因素的直觉。这些关键因素称为独立变量或特征。通过业务发现(上面也译为发现)阶段,我们可发现影响鸡蛋产量的关键特征是温度、电力、好的水源、营养成分、鸡饲料质量、疾病流行情况、疫苗接种等。除了关键特性的识别,我们还基于特征和响应变量之间的关系上构建直觉。
比如——
- 温度和鸡蛋产量上存在哪种关系?
- 那种鸡饲料会影响产量吗?
- 电力和产量之间是否有关联?
一开始建立的直觉将帮助我们下一阶段的数据探索工作。从变量上的直觉开始发挥作用了且变量之间存在关联,那下一个任务就是验证我们的直觉和假设。让我们看看接下来如何做到这一点。
二、历练:准备好数据来验证我们的直觉和假设
为了验证前面得到的直觉和假设,我们需要与解决问题相关的数据点。统一数据点的数据格式,这将是我们旅程中最乏味的部分。许多数据点在组织内可能以不同的形式和模式提供,还需要补充组织内部可用的数据与外部可用的数据。比如社交媒体数据或者公共领域的可用开放数据。我们的目标是格式化所有相关数据点,以方便我们的工作。对这一工作,并没有规定我们如何去实现。我们解决问题的唯一指南是需解决问题的相关描述。然而,这一部分是整个旅程中最耗时的部分之一。
当我们在谈论准备数据时,需做好数据的四个V:
- 数据量(Volume of data)
- 数据多样性(Variety of data)
- 数据速率(Velocity of data)
- 数据真实性(Veracity of data)
数据量:容量决定了我们可以使用的数据量。在大多数情况下,数据量越大,创建的模型就越好、越具代表性。然而,更大的数据量也对我们手头处理这些数据的资源的速度和能力提出了挑战。数据量评估将有助于我们在处理数据时采用合适的并行处理技术来加快处理时间。
数据多样性:指的是我们的数据点产生于那些不同的数据源,数据可能存在多种形式,比如传统的关系型数据库、文本数据、图像、视频、日志文件等等,这些数据的存储形式越多样,我们的聚合过程就越复杂。数据点的多样性能够为我们采用正确的数据聚合技术提供线索。
数据速率:即是数据处理时产生数据点的频率。可以是生成非常规则的数据,如WEB流数据,也可以是间歇性产生的数据。所以数据速率特征工程和采用正确的数据聚合技术的重要考虑因素。
数据的真实性:真实性是每个数据点在整个业务过程中产生的值(既可能是真实的数据,也有可能是噪声)。如果我们未能在选择数据多样性的同时正确判断其真实性被大量的噪音所淹没,如此的变量选择方法是不明智的,这会让我们很难从手握的数据中提取有效的数据。
所有上述因素都必须记住,当我们统一的数据格式后,这将使以后任务分析更加容易。 在整个过程中涉及的复杂性和重要性已经产生为流,称之为数据工程流。 简而言之,数据工程是关于提取,收集和处理无数的数据点,为后续处理提供一致性。
三、数据发现阶段
这个阶段是整个周期中最关键的阶段之一。在这个阶段,需要努力调整和适应数据结构和变量之间的关系。通常来说,对于如何处理数据发现阶段,存在两种看法,一种是从商业的角度出发,另一种是从统计的角度出发。两种视角描述如下:
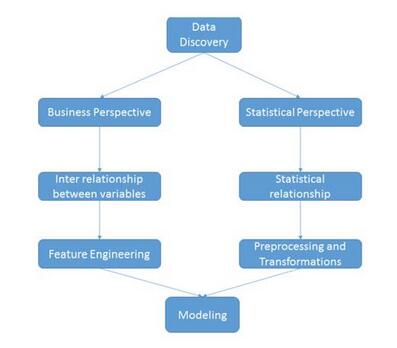
商业视角用于处理来自商业问题领域的变量之间的关系。相对的,统计学视角则更多地关注数据的统计特性,如其分布,正态性,偏移等。为了帮助阐明这些概念,让我们通过一个案例进行说明。
假设一个拥有多种基站的客户联系我们,希望我们帮助他们解决一个耗费很多精力但仍然得不到解决的问题。他们想预先获知各基站供电电池的健康状态,希望预测出电池何时会发生故障。这样情况下,他们需要提供与测量相关的历史数据。读取到的一些关键变量包括电导、电压、电流、温度、基站所在位置等。客户也需要提供电池发生故障条件的线索。他们希望我们关注电导值的走向,如果随着时间推移电导值急剧下降,表示电池很可能发生故障了。配置这些数据后,让我们看看数据发现是怎样开展的。我们首先从商业视角开始。
四、商业视角的数据发现阶段
最佳方法是从业务问题的角度思考。我们的业务问题是预测可能会发生的电池故障。在我们头脑中呈现出的最关键的问题是什么是电池故障?当然在此时此刻我们不可能对电池故障有明确的说明,然而我们所拥有的是一个需要遵循的线索,这个线索是随着时间的推移电导呈现下降趋势的电池。遵循这一线索,我们需要将呈现下降的趋势的电池与那些没有呈现下降趋势的电池分离开。那么,下一个问题就是,我们如何把那些有下降趋势的电池从其他的电池中分离出来?最好的方法是用与我们的业务问题相关的基本单元的聚集度量。让我通过数据集图像来阐述。
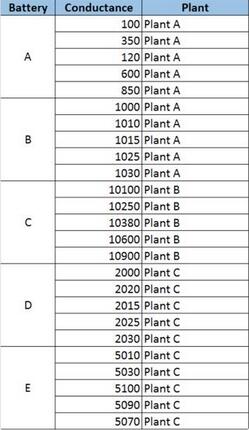
我们的数据样本如上图所示。 我们有大约20,000个的电池。 对于每个电池,读取大约2 - 3年时间内的电导。 每个电池与一个设备(基站位置)相关联。 一个设备可以具有多个电池,然而电池仅与一个设备相关联。 现在我们已经看到了数据集的结构,回到前面的语句,即“与业务问题相关的基本单元的聚合度量”。
有两个主要术语是重要的——
- 基本单位(Basic Unit)
- 聚合度量(Aggregating Metric)
在我们的案例中,与业务问题相关的基本单元是单个电池本身。如果我们的业务问题是预测可能会出现故障的基站设备,那么基本单位将是每个基站设备。第二项,即聚合度量,它是考虑了与基本单元相关联变量的聚合度量。在我们的案例中,它是每个电池电导的一些聚合。同样,聚合度量的类型将取决于业务问题。所以,让我们回到刚才的问题,我们关心的是识别出有下降趋势的电池。下降趋势越明显,它更可能是一个故障电池。因此,当我们考虑一个聚合度量时,应该着重考虑数据的范围。表示数据散布范围非常方便的度量是标准偏差(Standard deviation)。因此,如果我们通过采用每个电池的电导标准偏差来聚集每个电池的值,将有一个非常有效的方法来识别我们想要的电池组。同样的情况在下面的图中表示。
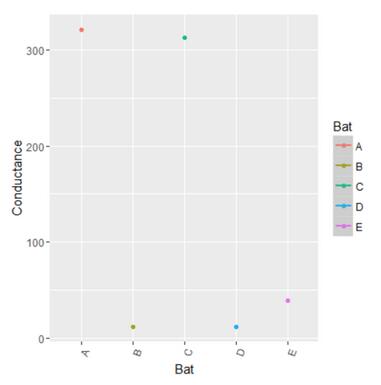
上图是沿x轴的电池图和沿y轴的电导标准偏差。 我们可以清楚地看到,使用我们的聚合度量,我们清楚地有两组电池,一个标准偏差小于100,另一个大于300.第二组电池A&C的标准偏差高于其余的电池,正是我们所寻找的。 接下来我们再尝试绘制这些电池的实际电导值随时间的变化趋势,以证实我们的假设。
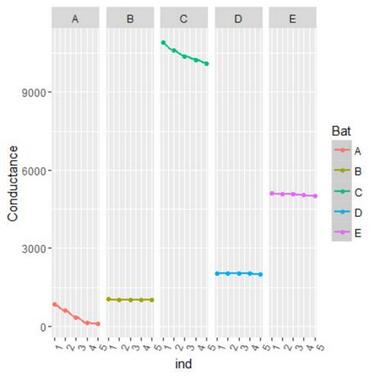
从上述曲线可以清楚地看出,电池A和C显示出由这些电池的高标准偏差所表明的下降趋势。 所以采取这样的聚合度量将有助于对想进一步挖掘的案例进行归零。
五、深入挖掘
现在我们已经确定了可能有问题的一组电池,下一步是深入研究这些案例,并尝试识别与电导率下降相关的其他指标。我们需要仔细观察数据的一些图形表示,然后提出进一步的问题:
- 这些趋势发生的时间是否呈现在一个时间段之中?
- 是否有任何特定的模式,我们可以发现电导率下降趋势?
- 有任何特别的曲线的斜率显示一个下降趋势?
我们需要观察所有具有变量的可辨别的模式,并构建我们对这些模式的直接辨识能力。一旦我们在一个变量上构建出了直接辨识能力,就可以进行下一步并关联其他变量。可以引入如电压,电流,温度等变量,并看看相对于只有一个变量(电导)时所看到的特定趋势,这些变量的变化。
可以看到的趋势如下——
- 当电导降低时,电压,电流或温度如何表现?
- 在电导率呈现下降趋势之前,这些变量有什么特殊趋势吗?
- 这些变量在电导值下降后如何表现?
- 除了已有的变量,是否还存在其他变量的可能?
这些是有助于我们发现存在于数据集中变量的各种关系的问题。通过这些问题划分到每个变量帮助我们实现以下:
- 帮助确定变量的相对重要性
- 提供关于变量之间的关系的一个粗略的想法
- 深入了解需要根据现有变量得到的任何变量
- 让我们直观了解需要引入的任何新变量
- 通过提出上述问题而获得的洞见,能够在后续的建模过程中提供极大帮助。
六、总结
现在我们已经开始从商业视角了解数据发现阶段,这个过程中的主要步骤包括:
- 识别一个变量,即能够潜在地给出我们要解决的问题指示的变量
- 为识别的变量导出一些聚合度量,以帮助分解与问题相关的基本单元
- 深入了解情况,并寻找关于我们正在寻找的变量的趋势
- 引入其他变量,并寻找新引入的变量和我们看到的第一个变量的趋势的联系。
- 寻找给出问题线索的变量之间的关系。
- 对可以引入的任何新变量,构建一个能够直接辨识的形式,这有助于解决问题。
以上是一套广泛的指导方针,用以指导从数据发现的商业视角构建思维过程。
本文作者:tvjoseph
来源:51CTO
从商业视角理解数据:数据科学家的思维之路相关推荐
- 大数据数据科学家常用面试题_面试有关数据科学,数据理解和准备的问答
大数据数据科学家常用面试题 问题1:在数据科学术语中,您如何称呼所分析的数据? (Q1: In the data science terminology, how do you call the da ...
- 人人都是网站分析师:从分析师的视角理解网站和解读数据
人人都是网站分析师:从分析师的视角理解网站和解读数据 <人人都是网站分析师>是一本真正能让网站分析的数据结果产生商业价值的著作.很多人都知道网站分析中的指标,但很少有人知道它们使用的场景. ...
- 西瓜创客张平曦:从商业目标出发解决数据治理中的困境
在以"矩·变"为主题的神策 2019 数据驱动大会现场,西瓜创客数据分析负责人张平曦发表了名为<从商业目标出发解决数据治理中的困境>的主题演讲.以下内容根据其现场演讲整 ...
- 【工业大数据】 昆仑数据首席科学家田春华:人工智能降低了工业大数据分析的门槛
机器之心原创 作者:高静宜 在刚刚结束的国际 PHM 数据竞赛中,昆仑数据的 K2 代表队以绝对优势一举夺冠,成为 PHM Data Challenge 十年竞赛史上首个完全由中国本土成员组成的冠军团 ...
- 易观郭炜:企业如何理解大数据价值,如何用好大数据?
大数据,企业数字化的新能源. 导读 2018年,世界上科学家搜索频率最高的词汇前三分别是"癌症""区块链""大数据".其中,"大数 ...
- 《大数据导论》一第1章 理解大数据
本节书摘来自华章出版社<大数据导论>一书中的第1章,第1.1节,作者托马斯·埃尔(Thomas Erl),瓦吉德·哈塔克(Wajid Khattak),保罗·布勒(Paul Buhler) ...
- 世界顶级机器学习科学家黄恒加入京东,出任京东大数据首席科学家
雷锋网消息,京东集团今日宣布,美国匹兹堡大学John A. Jurenko 杰出冠名讲席教授黄恒博士加入京东. 雷锋网(公众号:雷锋网)注:黄恒教授 黄恒教授是机器学习.人工智能.大数据.计算机视觉等 ...
- 《深入理解大数据:大数据处理与编程实践》一一1.2 大数据处理技术简介
本节书摘来自华章计算机<深入理解大数据:大数据处理与编程实践>一书中的第1章,第1.2节,作者 主 编:黄宜华(南京大学)副主编:苗凯翔(英特尔公司),更多章节内容可以访问云栖社区&quo ...
- 通俗理解大数据及其应用价值
大数据概述 在大数据这个概念兴起之前,信息系统存储数据的方法主要是我们熟知的关系型数据库,关系型数据库,关系型模型之父 Edgar F. Codd,在 1970 年 Communications of ...
最新文章
- BAPC2014 Bamp;amp;HUNNU11582:Button Bashing(BFS)
- qt创建线程和退出线程
- 电感器在交流电路中的作用
- 全球及中国益生菌市场应用发展与投资前景调研报告2022版
- jlabel 不能连续两次set_为什么有时连续多次setState只有一次生效?
- 三星530换固态硬盘_速度与安全在指尖跳跃 三星移动固态硬盘T7 Touch评测
- 大学实训_软件毕设_Java入门实战_商场管理系统_Punrain
- Chrome浏览器另存为时浏览器假死问题
- 【转】IOS开发小技巧
- 36氪独家|「秦汉胡同」完成1亿元A轮融资,将发力线上内容产品和女性生活学习服务社群...
- 微信小程序获取微信绑定授权手机号
- 电脑显示屏无信号怎么办?
- decelerate(decelerates)
- sqlserver查询时间范围
- kmeans算法c语言实现,能对不同维度的数据进行聚类
- python大一题库西农_西农植物学试题
- METHODS FOR NON-LINEAR LEAST SQUARES PROBLEMS 翻译(六)
- 选择比努力更重要,这些微信号值得你细细品味
- 图片轮换的按钮如何通过像素定位
- libIEC61850学习记录
热门文章
- 伸展树算法c语言,数据结构伸展树介绍及C语言的实现方法
- Java天使之恋攻略,跑跑卡丁车手游天使之恋怎么得 天使之恋获取攻略[多图]
- cat卡特鞋有实体店吗_保养课堂 | 小小密封件,竟然是CAT油缸和连杆耐用的秘密...
- 完美设置“Word表格中文字上下居中”
- 半导体基础知识(2):PN结二极管和二极管特性
- Win7桌面快捷切换技巧?
- 【 Verilog HDL 】寄存器数据类型(reg)与线网数据类型(wire,tri)
- 自然语言处理之机器处理流程
- extern C __declspec(dllexport) __declspec(dllimport) 和 def
- WiFi是SD-WAN的良好组合,但不是必备选择