《深入理解大数据:大数据处理与编程实践》一一1.2 大数据处理技术简介
本节书摘来自华章计算机《深入理解大数据:大数据处理与编程实践》一书中的第1章,第1.2节,作者 主 编:黄宜华(南京大学)副主编:苗凯翔(英特尔公司),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.2 大数据处理技术简介
1.2.1 大数据的发展背景和研究意义
近几年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百TB甚至数十至数百PB规模的行业/企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力,因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。百度目前的总数据量已超过1000PB,每天需要处理的网页数据达到10PB~100PB;淘宝累计的交易数据量高达100PB;Twitter每天发布超过2亿条消息,新浪微博每天发帖量达到8000万条;中国移动一个省的电话通联记录数据每月可达0.5PB~1PB;一个省会城市公安局道路车辆监控数据三年可达200亿条、总量120TB。据世界权威IT信息咨询分析公司IDC研究报告预测:全世界数据量未来10年将从2009年的0.8ZB增长到2020年的35ZB(1ZB=1000EB=1000000PB),10年将增长44倍,年均增长40%。
早几年人们把大规模数据称为“海量数据”,但实际上,大数据(Big Data)这个概念早在2008年就已被提出。2008年,在Google成立10周年之际,著名的《自然》杂志出版了一期专刊,专门讨论未来的大数据处理相关的一系列技术问题和挑战,其中就提出了“Big Data”的概念。
随着大数据概念的普及,人们常常会问,多大的数据才叫大数据?其实,关于大数据,难以有一个非常定量的定义。维基百科给出了一个定性的描述:大数据是指无法使用传统和常用的软件技术和工具在一定时间内完成获取、管理和处理的数据集。进一步,当今“大数据”一词的重点其实已经不仅在于数据规模的定义,它更代表着信息技术发展进入了一个新的时代,代表着爆炸性的数据信息给传统的计算技术和信息技术带来的技术挑战和困难,代表着大数据处理所需的新的技术和方法,也代表着大数据分析和应用所带来的新发明、新服务和新的发展机遇。
由于大数据处理需求的迫切性和重要性,近年来大数据技术已经在全球学术界、工业界和各国政府得到高度关注和重视,全球掀起了一个可与20世纪90年代的信息高速公路相提并论的研究热潮。美国和欧洲一些发达国家政府都从国家科技战略层面提出了一系列的大数据技术研发计划,以推动政府机构、重大行业、学术界和工业界对大数据技术的探索研究和应用。
早在2010年12月,美国总统办公室下属的科学技术顾问委员会(PCAST)和信息技术顾问委员会(PITAC)向奥巴马和国会提交了一份《规划数字化未来》的战略报告,把大数据收集和使用的工作提升到体现国家意志的战略高度。报告列举了5个贯穿各个科技领域的共同挑战,而第一个最重大的挑战就是“数据”问题。报告指出:“如何收集、保存、管理、分析、共享正在呈指数增长的数据是我们必须面对的一个重要挑战”。报告建议:“联邦政府的每一个机构和部门,都需要制定一个‘大数据’的战略”。2012年3月,美国总统奥巴马签署并发布了一个“大数据研究发展创新计划”(Big Data R & D Initiative),由美国国家自然基金会(NSF)、卫生健康总署(NIH)、能源部(DOE)、国防部(DOD)等6大部门联合,投资2亿美元启动大数据技术研发,这是美国政府继1993年宣布“信息高速公路”计划后的又一次重大科技发展部署。美国白宫科技政策办公室还专门支持建立了一个大数据技术论坛,鼓励企业和组织机构间的大数据技术交流与合作。
2012年7月,联合国在纽约发布了一本关于大数据政务的白皮书《大数据促发展:挑战与机遇》,全球大数据的研究和发展进入了前所未有的高潮。这本白皮书总结了各国政府如何利用大数据响应社会需求,指导经济运行,更好地为人民服务,并建议成员国建立“脉搏实验室”(Pulse Labs),挖掘大数据的潜在价值。
由于大数据技术的特点和重要性,目前国内外已经出现了“数据科学”的概念,即数据处理技术将成为一个与计算科学并列的新的科学领域。已故著名图灵奖获得者Jim Gray在2007年的一次演讲中提出,“数据密集型科学发现”(Data-Intensive Scientific Discovery)将成为科学研究的第四范式,科学研究将从实验科学、理论科学、计算科学,发展到目前兴起的数据科学。
为了紧跟全球大数据技术发展的浪潮,我国政府、学术界和工业界对大数据也予以了高度的关注。央视著名“对话”节目2013年4月14日和21日邀请了《大数据时代——生活、工作与思维的大变革》作者维克托·迈尔-舍恩伯格,以及美国大数据存储技术公司LSI总裁阿比分别做客“对话”节目,做了两期大数据专题谈话节目“谁在引爆大数据”、“谁在掘金大数据”,国家央视媒体对大数据的关注和宣传体现了大数据技术已经成为国家和社会普遍关注的焦点。
而国内的学术界和工业界也都迅速行动,广泛开展大数据技术的研究和开发。2013年以来,国家自然科学基金、973计划、核高基、863等重大研究计划都已经把大数据研究列为重大的研究课题。为了推动我国大数据技术的研究发展,2012年中国计算机学会(CCF)发起组织了CCF大数据专家委员会,CCF专家委员会还特别成立了一个“大数据技术发展战略报告”撰写组,并已撰写发布了《2013年中国大数据技术与产业发展白皮书》。
大数据在带来巨大技术挑战的同时,也带来巨大的技术创新与商业机遇。不断积累的大数据包含着很多在小数据量时不具备的深度知识和价值,大数据分析挖掘将能为行业/企业带来巨大的商业价值,实现各种高附加值的增值服务,进一步提升行业/企业的经济效益和社会效益。由于大数据隐含着巨大的深度价值,美国政府认为大数据是“未来的新石油”,对未来的科技与经济发展将带来深远影响。因此,在未来,一个国家拥有数据的规模和运用数据的能力将成为综合国力的重要组成部分,对数据的占有、控制和运用也将成为国家间和企业间新的争夺焦点。
大数据的研究和分析应用具有十分重大的意义和价值。被誉为“大数据时代预言家”的维克托·迈尔-舍恩伯格在其《大数据时代》一书中列举了大量详实的大数据应用案例,并分析预测了大数据的发展现状和未来趋势,提出了很多重要的观点和发展思路。他认为:“大数据开启了一次重大的时代转型”,指出大数据将带来巨大的变革,改变我们的生活、工作和思维方式,改变我们的商业模式,影响我们的经济、政治、科技和社会等各个层面。
由于大数据行业应用需求日益增长,未来越来越多的研究和应用领域将需要使用大数据并行计算技术,大数据技术将渗透到每个涉及到大规模数据和复杂计算的应用领域。不仅如此,以大数据处理为中心的计算技术将对传统计算技术产生革命性的影响,广泛影响计算机体系结构、操作系统、数据库、编译技术、程序设计技术和方法、软件工程技术、多媒体信息处理技术、人工智能以及其他计算机应用技术,并与传统计算技术相互结合产生很多新的研究热点和课题。
大数据给传统的计算技术带来了很多新的挑战。大数据使得很多在小数据集上有效的传统的串行化算法在面对大数据处理时难以在可接受的时间内完成计算;同时大数据含有较多噪音、样本稀疏、样本不平衡等特点使得现有的很多机器学习算法有效性降低。因此,微软全球副总裁陆奇博士在2012年全国第一届“中国云/移动互联网创新大奖赛”颁奖大会主题报告中指出:“大数据使得绝大多数现有的串行化机器学习算法都需要重写”。
大数据技术的发展将给我们研究计算机技术的专业人员带来新的挑战和机遇。目前,国内外IT企业对大数据技术人才的需求正快速增长,未来5~10年内业界将需要大量的掌握大数据处理技术的人才。IDC研究报告指出,“下一个10年里,世界范围的服务器数量将增长10倍,而企业数据中心管理的数据信息将增长50倍,企业数据中心需要处理的数据文件数量将至少增长75倍,而世界范围内IT专业技术人才的数量仅能增长1.5倍。”因此,未来十年里大数据处理和应用需求与能提供的技术人才数量之间将存在一个巨大的差距。目前,由于国内外高校开展大数据技术人才培养的时间不长,技术市场上掌握大数据处理和应用开发技术的人才十分短缺,因而这方面的技术人才十分抢手,供不应求。国内几乎所有著名的IT企业,如百度、腾讯、阿里巴巴和淘宝、奇虎360等,都大量需要大数据技术人才。
1.2.2 大数据的技术特点
大数据具有五个主要的技术特点,人们将其总结为5V特征(见图1-11):
1)Volume(大体量):即可从数百TB到数十数百PB、甚至EB的规模。
2)Variety(多样性):即大数据包括各种格式和形态的数据。
3)Velocity(时效性):即很多大数据需要在一定的时间限度下得到及时处理。
4)Veracity(准确性):即处理的结果要保证一定的准确性。
5)Value(大价值):即大数据包含很多深度的价值,大数据分析挖掘和利用将带来巨大的商业价值。
传统的数据库系统主要面向结构化数据的存储和处理,但现实世界中的大数据具有各种不同的格式和形态,据统计现实世界中80%以上的数据都是文本和媒体等非结构化数据;同时,大数据还具有很多不同的计算特征。我们可以从多个角度分类大数据的类型和计算特征。
1)从数据结构特征角度看,大数据可分为结构化与非结构化/半结构化数据。
2)从数据获取处理方式看,大数据可分为批处理与流式计算方式。
3)从数据处理类型看,大数据处理可分为传统的查询分析计算和复杂数据挖掘计算。
4)从大数据处理响应性能看,大数据处理可分为实时/准实时与非实时计算,或者是联机计算与线下计算。前述的流式计算通常属于实时计算,此外查询分析类计算通常也要求具有高响应性能,因而也可以归为实时或准实时计算。而批处理计算和复杂数据挖掘计算通常属于非实时或线下计算。
5)从数据关系角度看,大数据可分为简单关系数据(如Web日志)和复杂关系数据(如社会网络等具有复杂数据关系的图计算)。
6)从迭代计算角度看,现实世界的数据处理中有很多计算问题需要大量的迭代计算,诸如一些机器学习等复杂的计算任务会需要大量的迭代计算,为此需要提供具有高效的迭代计算能力的大数据处理和计算方法。
7)从并行计算体系结构特征角度看,由于需要支持大规模数据的存储和计算,因此目前绝大多数大数据处理都使用基于集群的分布式存储与并行计算体系结构和硬件平台。MapReduce是最为成功的分布式存储和并行计算模式。然而,基于磁盘的数据存储和计算模式使MapReduce难以实现高响应性能。为此人们从分布计算体系结构层面上又提出了内存计算的概念和技术方法。
1.2.3 大数据研究的主要目标、基本原则和基本途径
1.?大数据研究的主要目标
大数据研究的主要目标是,以有效的信息技术手段和计算方法,获取、处理和分析各种应用行业的大数据,发现和提取数据的深度价值,为行业提供高附加值的应用和服务。因此,大数据研究的核心目标是价值发现,而其技术手段是信息技术和计算方法,其效益目标是为行业提供高附加值的应用和服务。
2.?大数据研究的基本特点
大数据研究具有以下几方面的主要特点:
1)大数据处理具有很强的行业应用需求特性,因此大数据技术研究必须紧扣行业应用需求。
2)大数据规模极大,超过任何传统数据库系统的处理能力。
3)大数据处理技术综合性强,任何单一层面的计算技术都难以提供理想的解决方案,需要采用综合性的软硬件技术才能有效处理。
4)大数据处理时,大多数传统算法都面临失效,需要重写。
3.?大数据研究的基本原则
大数据研究的基本原则是:
1)应用需求为导向:由于大数据问题来自行业应用,因此大数据的研究需要以行业应用问题和需求为导向,从行业实际的应用需求和存在的技术难题入手,研究解决有效的处理技术和解决方案。
2)领域交叉为桥梁:由于大数据技术有典型的行业应用特征,因此大数据技术研究和应用开发需要由计算技术人员、数据分析师、具备专业知识的领域专家相互配合和协同,促进应用行业、IT产业与计算技术研究机构的交叉融合,来提供良好的大数据解决方法。
3)技术综合为支撑:与传统的单一层面的计算技术研究和应用不同,大数据处理是几乎整个计算技术和信息技术的融合,只有采用技术交叉融合的方法才能提供较为完善的大数据处理方法。
4.?大数据研究的基本途径
大数据处理有以下三个基本的解决途径:
1)寻找新算法降低计算复杂度。大数据给很多传统的机器学习和数据挖掘计算方法和算法带来挑战。在数据集较小时,很多在O(n)、O(nlogn)、O(n2)或O(n3)等线性或多项式复杂度的机器学习和数据挖掘算法都可以有效工作,但当数据规模增长到PB级尺度时,这些现有的串行化算法将花费难以接受的时间开销,使得算法失效。因此,需要寻找新的复杂度更低的算法。
2)寻找和采用降低数据尺度的算法。在保证结果精度的前提下,用数据抽样或者数据尺度无关的近似算法来完成大数据的处理。
3)分而治之的并行化处理。除上述两种方法外,目前为止,大数据处理最为有效和最重要的方法还是采用大数据并行化算法,在一个大规模的分布式数据存储和并行计算平台上完成大数据并行化处理。
1.2.4 大数据计算模式和系统
MapReduce计算模式的出现有力推动了大数据技术和应用的发展,使其成为目前大数据处理最成功的主流大数据计算模式。然而,现实世界中的大数据处理问题复杂多样,难以有一种单一的计算模式能涵盖所有不同的大数据计算需求。研究和实际应用中发现,由于MapReduce主要适合于进行大数据线下批处理,在面向低延迟和具有复杂数据关系和复杂计算的大数据问题时有很大的不适应性。因此,近几年来学术界和业界在不断研究并推出多种不同的大数据计算模式。
所谓大数据计算模式,是指根据大数据的不同数据特征和计算特征,从多样性的大数据计算问题和需求中提炼并建立的各种高层抽象(Abstraction)和模型(Model)。传统的并行计算方法主要从体系结构和编程语言的层面定义了一些较为底层的抽象和模型,但由于大数据处理问题具有很多高层的数据特征和计算特征,因此大数据处理需要更多地结合其数据特征和计算特性考虑更为高层的计算模式。
根据大数据处理多样性的需求,目前出现了多种典型和重要的大数据计算模式。与这些计算模式相适应,出现了很多对应的大数据计算系统和工具,如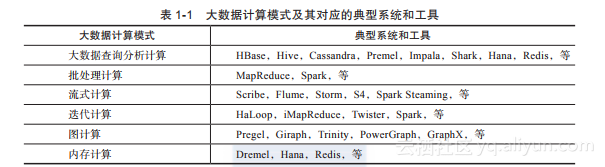
1.?大数据查询分析计算模式与典型系统
由于行业数据规模的增长已大大超过了传统的关系数据库的承载和处理能力,因此,目前需要尽快研究并提供面向大数据存储管理和查询分析的新的技术方法和系统,尤其要解决在数据体量极大时如何能够提供实时或准实时的数据查询分析能力,满足企业日常的管理需求。然而,大数据的查询分析处理具有很大的技术挑战,在数量规模较大时,即使采用分布式数据存储管理和并行化计算方法,仍然难以达到关系数据库处理中小规模数据时那样的秒级响应性能。
大数据查询分析计算的典型系统包括Hadoop下的HBase和Hive、Facebook公司开发的Cassandra、Google公司的Dremel、Cloudera公司的实时查询引擎Impala;此外为了实现更高性能的数据查询分析,还出现了不少基于内存的分布式数据存储管理和查询系统,如Apache Spark下的数据仓库Shark、SAP公司的Hana、开源的Redis等。
2.?批处理计算模式与典型系统
最适合于完成大数据批处理的计算模式是MapReduce,这是MapReduce设计之初的主要任务和目标。MapReduce是一个单输入、两阶段(Map和Reduce)的数据处理过程。首先,MapReduce对具有简单数据关系、易于划分的大规模数据采用“分而治之”的并行处理思想;然后将大量重复的数据记录处理过程总结成Map和Reduce两个抽象的操作;最后MapReduce提供了一个统一的并行计算框架,把并行计算所涉及到的诸多系统层细节都交给计算框架去完成,以此大大简化了程序员进行并行化程序设计的负担。
MapReduce的简单易用性使其成为目前大数据处理最成功的主流并行计算模式。在开源社区的努力下,开源的Hadoop系统目前已成为较为成熟的大数据处理平台,并已发展成一个包括众多数据处理工具和环境的完整的生态系统。目前几乎国内外的各个著名IT企业都在使用Hadoop平台进行企业内大数据的计算处理。此外,Spark系统也具备批处理计算的能力。
3.?流式计算模式与典型系统
流式计算是一种高实时性的计算模式,需要对一定时间窗口内应用系统产生的新数据完成实时的计算处理,避免造成数据堆积和丢失。很多行业的大数据应用,如电信、电力、道路监控等行业应用以及互联网行业的访问日志处理,都同时具有高流量的流式数据和大量积累的历史数据,因而在提供批处理计算模式的同时,系统还需要能具备高实时性的流式计算能力。流式计算的一个特点是数据运动、运算不动,不同的运算节点常常绑定在不同的服务器上。
Facebook的Scribe和Apache的Flume都提供了一定的机制来构建日志数据处理流图。而更为通用的流式计算系统是Twitter公司的Storm、Yahoo公司的S4以及Apache Spark Steaming。
4.?迭代计算模式与典型系统
为了克服Hadoop MapReduce难以支持迭代计算的缺陷,工业界和学术界对Hadoop MapReduce进行了不少改进研究。HaLoop把迭代控制放到MapReduce作业执行的框架内部,并通过循环敏感的调度器保证前次迭代的Reduce输出和本次迭代的Map输入数据在同一台物理机上,以减少迭代间的数据传输开销;iMapReduce在这个基础上保持Map和Reduce任务的持久性,规避启动和调度开销;而Twister在前两者的基础上进一步引入了可缓存的Map和Reduce对象,利用内存计算和pub/sub网络进行跨节点数据传输。
目前,一个具有快速和灵活的迭代计算能力的典型系统是Spark,其采用了基于内存的RDD数据集模型实现快速的迭代计算。
5.?图计算模式与典型系统
社交网络、Web链接关系图等都包含大量具有复杂关系的图数据,这些图数据规模很大,常常达到数十亿的顶点和上万亿的边数。这样大的数据规模和非常复杂的数据关系,给图数据的存储管理和计算分析带来了很大的技术难题。用MapReduce计算模式处理这种具有复杂数据关系的图数据通常不能适应,为此,需要引入图计算模式。
大规模图数据处理首先要解决数据的存储管理问题,通常大规模图数据也需要使用分布式存储方式。但是,由于图数据具有很强的数据关系,分布式存储就带来了一个重要的图划分问题(Graph Partitioning)。根据图数据问题本身的特点,图划分可以使用“边切分”和“顶点切分”两种方式。在有效的图划分策略下,大规模图数据得以分布存储在不同节点上,并在每个节点上对本地子图进行并行化处理。与任务并行和数据并行的概念类似,由于图数据并行处理的特殊性,人们提出了一个新的“图并行”(Graph Parallel)的概念。事实上,图并行是数据并行的一个特殊形式,需要针对图数据处理的特征考虑一些特殊的数据组织模型和计算方法。
目前已经出现了很多分布式图计算系统,其中较为典型的系统包括Google公司的Pregel、Facebook对Pregel的开源实现Giraph、微软公司的Trinity、Spark下的GraphX,以及CMU的GraphLab以及由其衍生出来的目前性能最快的图数据处理系统PowerGraph。
6.?内存计算模式与典型系统
Hadoop MapReduce为大数据处理提供了一个很好的平台。然而,由于MapReduce设计之初是为大数据线下批处理而设计的,随着数据规模的不断扩大,对于很多需要高响应性能的大数据查询分析计算问题,现有的以Hadoop为代表的大数据处理平台在计算性能上往往难以满足要求。随着内存价格的不断下降以及服务器可配置的内存容量的不断提高,用内存计算完成高速的大数据处理已经成为大数据计算的一个重要发展趋势。例如,Hana系统设计者总结了很多实际的商业应用后发现,一个提供50TB总内存容量的计算集群将能够满足绝大多数现有的商业系统对大数据的查询分析处理要求,如果一个服务器节点可配置1TB~2TB的内存,则需要25~50个服务器节点。目前Intel Xeon E-7系列处理器最大可支持高达1.5TB的内存,因此,配置一个上述大小规模的内存计算集群是可以做到的。
1.2.5 大数据计算模式的发展趋势
近几年来,由于大数据处理和应用需求急剧增长,同时也由于大数据处理的多样性和复杂性,针对以上的典型的大数据计算模式,学术界和工业界不断研究推出新的或改进的计算模式和系统工具平台。目前主要有以下三方面的重要发展趋势和方向:Hadoop性能提升和功能增强,混合式大数据计算模式,以及基于内存计算的大数据计算模式和技术。
1.?Hadoop性能提升和功能增强
尽管Hadoop还存在很多不足,但由于Hadoop已发展成为目前最主流的大数据处理平台、并得到广泛的使用,因此,目前人们并不会抛弃Hadoop平台,而是试图不断改进和发展现有的平台,增加其对各种不同大数据处理问题的适用性。目前,Hadoop社区正努力扩展现有的计算模式框架和平台,以便能解决现有版本在计算性能、计算模式、系统构架和处理能力上的诸多不足,这正是目前Hadoop2.0新版本“YARN”的努力目标。目前不断有新的计算模式和计算系统出现,预计今后相当长一段时间内,Hadoop平台将与各种新的计算模式和系统共存,并相互融合,形成新一代的大数据处理系统和平台。
2.?混合式计算模式
现实世界大数据应用复杂多样,可能会同时包含不同特征的数据和计算,在这种情况下单一的计算模式多半难以满足整个应用的需求,因此需要考虑不同计算模式的混搭使用。
混合式计算模式可体现在两个层面上。一个层面是传统并行计算所关注的体系结构与低层并行程序设计语言层面计算模式的混合,例如,在体系结构层,可根据大数据应用问题的需要搭建混合式的系统构架,如MapReduce集群+GPU-CUDA的混合,或者MapReduce集群+基于MIC(Intel Xeon Phi众核协处理系统)的OpenMP/MPI的混合模型。
混合模型的另一个层面是以上所述的大数据处理高层计算模式的混合。比如,一个大数据应用可能同时需要提供流式计算模式以便接收每天产生的大量流式数据,这些数据得到保存后成为历史数据,此时会需要提供基于SQL或NoSQL的数据查询分析能力以便进行日常的数据查询分析;进一步,为了进行商业智能分析,可能还需要进行基于机器学习的深度数据挖掘分析,此时系统需要能提供线下批处理计算模式以及复杂机器学习算法的迭代计算模式;一些大数据计算任务可能还直接涉及到复杂图计算或者间接转化为图计算问题。因此,很多大数据处理问题都需要有多种混合计算模式的支持。此外,为了提高各种计算模式处理大数据时的计算性能,各种计算模式都在与内存计算模式混合,实现高实时性的大数据查询和计算分析。
混合计算模式之集大成者当属UC Berkeley AMPLab研发、现已成为Apache开源项目的Spark系统,其涵盖了几乎所有典型的大数据计算模式,包括迭代计算、批处理计算、内存计算、流式计算(Spark Streaming)、数据查询分析计算(Shark)以及图计算(GraphX),提供了优异的计算性能,同时还保持与Hadoop平台的兼容性。
3.?内存计算
为了进一步提高大数据处理的性能,目前已经出现一个基本共识,即随着内存成本的不断降低,内存计算将成为最终跨越大数据计算性能障碍、实现高实时高响应计算的一个最有效的技术手段。因此,目前越来越多的研究者和开发者在关注基于内存计算的大数据处理技术,不断推出各种基于内存计算的计算模式和系统。
内存计算是一种在体系结构层面上的解决方法,因此可以适用于各种不同的计算模式,从基本的数据查询分析计算,到批处理计算和流式计算,再到迭代计算和图计算,都可以基于内存计算加以实现,因此我们可以看到各种大数据计算模式下都有基于内存计算实现的系统,比较典型的系统包括SAP公司的Hana内存数据库、开源的键值对内存数据库Redis、微软公司的图数据计算系统Trinity、Apache Spark等。
1.2.6 大数据的主要技术层面和技术内容
大数据是诸多计算技术的融合。从大的方面来分,大数据技术与研究主要分为大数据基础理论、大数据关键技术和系统、大数据应用以及大数据信息资源库等几个重要方面。
从信息系统的角度来看,大数据处理是一个涉及整个软硬件系统各个层面的综合性信息处理技术。从信息系统角度可将大数据处理分为基础设施层、系统软件层、并行化算法层以及应用层。图1-12所示是从信息处理系统角度所看到的大数据技术的主要技术层面和技术内容。
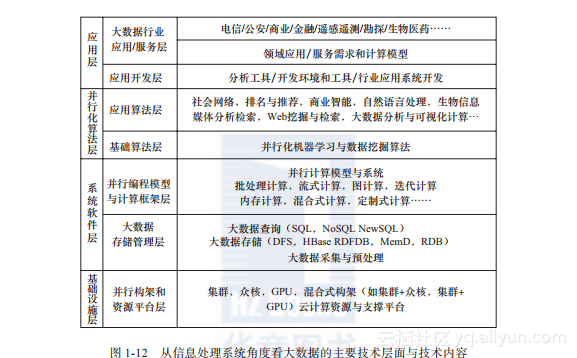
图1-12 从信息处理系统角度看大数据的主要技术层面与技术内容
1.?基础设施层
基础设施层主要提供大数据分布存储和并行计算的硬件基础设施和平台。目前大数据处理通用化的硬件设施是基于普通商用服务器的集群,在有特殊的数据处理需要时,这种通用化的集群也可以结合其他类型的并行计算设施一起工作,如基于众核的并行处理系统(如GPU或者Intel新近推出的MIC),形成一种混合式的大数据并行处理构架和硬件平台。此外,随着云计算技术的发展,也可以与云计算资源管理和平台结合,在云计算平台上部署大数据基础设施,运用云计算平台中的虚拟化和弹性资源调度技术,为大数据处理提供可伸缩的计算资源和基础设施。
2.?系统软件层
在系统软件层,需要考虑大数据的存储管理和并行化计算系统软件。
(1)分布式文件系统与数据查询管理系统
大数据处理首先面临的是如何解决大数据的存储管理问题。为了提供巨大的数据存储能力,人们的普遍共识是,利用分布式存储技术和系统提供可扩展的大数据存储能力。
首先需要有一个底层的分布式文件系统,以可扩展的方式支持对大规模数据文件的有效存储管理。但文件系统主要是以文件方式提供一个最基础性的大数据存储方式,其缺少结构化/半结构化数据的存储管理和访问能力,而且其编程接口对于很多应用来说还是太底层了。传统的数据库技术主要适用于规模相对较小的结构化数据的存储管理和查询,当数据规模增大或者要处理很多非结构化或半结构化数据时,传统数据库技术和系统将难以胜任。现实世界中的大数据不仅数据量大,而且具有多样化的形态特征。据统计,现实世界80%的数据都是非结构化或半结构化的。因此,系统软件层还需要研究解决大数据的存储管理和查询问题。由于SQL不太适用于非结构化/半结构化数据的管理查询,因此,人们提出了一种NoSQL的数据管理查询模式。但是,人们发现,最理想的还是能提供统一的数据管理查询方法,能对付各种不同类型的数据的查询管理。为此,人们进一步提出了NewSQL的概念和技术。
(2)大数据并行计算模式和系统
解决了大数据的存储问题后,进一步面临的问题是,如何能快速有效地完成大规模数据的计算。大数据的数据规模之大,使得现有的串行计算方法难以在可接受的时间里快速完成大数据的处理和计算。为了提高大数据处理的效率,需要使用大数据并行计算模型和框架来支撑大数据的计算处理。目前最主流的大数据并行计算和框架是Hadoop MapReduce技术。与此同时,近年来人们开始研究并提供不同的大数据计算模型和方法,包括高实时低延迟要求的流式计算,具有复杂数据关系的图计算,面向基本数据管理的查询分析类计算,以及面向复杂数据分析挖掘的迭代和交互计算等。在大多数场景下,由于数据量巨大,大数据处理通常很难达到实时或低延迟响应。为了解决这个问题,近年来,人们提出了内存计算的概念和方法,尽可能利用大内存完成大数据的计算处理,以实现尽可能高的实时或低延迟响应。目前Spark已成为一个具有很大发展前景的新的大数据计算系统和平台,正受到工业界和学术界的广泛关注,有望成为与Hadoop并存的一种新的计算系统和平台。
3.?并行化算法层
基于以上的基础设施层和系统软件层,为了完成大数据的并行化处理,进一步需要考虑的问题是,如何能对各种大数据处理所需要的分析挖掘算法进行并行化设计。
大数据分析挖掘算法大多最终会归结到基础性的机器学习和数据挖掘算法上来。然而,面向大数据处理时,绝大多数现有的串行化机器学习和数据挖掘算法都难以在可接受的时间内有效完成大数据处理,因此,这些已有的机器学习和数据挖掘算法都需要进行并行化的设计和改造。
除此以外,还需要考虑很多更贴近上层具体应用和领域问题的应用层算法,例如,社会网络分析、分析推荐、商业智能分析、Web搜索与挖掘、媒体分析检索、自然语言理解与分析、语义分析与检索、可视化分析等,虽然这些算法最终大都会归结到底层的机器学习和数据挖掘算法上,但它们本身会涉及到很多高层的特定算法问题,所有这些高层算法本身在面向大数据处理时也需要考虑如何进行并行化算法设计。
4.?应用层
基于上述三个层面,可以构建各种行业或领域的大数据应用系统。大数据应用系统首先需要提供和使用各种大数据应用开发运行环境与工具;进一步,大数据应用开发的一个特别问题是,需要有应用领域的专家归纳行业应用问题和需求、构建行业应用和业务模型,这些模型往往需要专门的领域知识,没有应用行业领域专家的配合,单纯的计算机专业专业技术人员往往会无能为力,难以下手。只有在领域专家清晰构建了应用问题和业务模型后,计算机专业人员才能顺利完成应用系统的设计与开发。行业大数据分析和价值发现会涉及到很多复杂的行业和领域专业知识,这一特征在今天的大数据时代比以往任何时候都更为突出,这就是为什么我们在大数据研究原则中明确提出,大数据的研究应用需要以应用需求为导向、领域交叉为桥梁,从实际行业应用问题和需求出发,由行业和领域专家与计算机技术人员相互配合和协同,以完成大数据行业应用的开发。
《深入理解大数据:大数据处理与编程实践》一一1.2 大数据处理技术简介相关推荐
- 《深入理解大数据:大数据处理与编程实践》一一3.3 HDFS文件存储组织与读写...
本节书摘来自华章计算机<深入理解大数据:大数据处理与编程实践>一书中的第3章,第3.3节,作者 主 编:黄宜华(南京大学)副主编:苗凯翔(英特尔公司),更多章节内容可以访问云栖社区&quo ...
- 大数据第二阶段Python基础编程学习笔记(待完善)
大数据第二阶段Python基础编程学习笔记(待完善) 第一章 Python基础语法 3.8 1-1Python概述 python基础部分: ●Python基础语法: 标识符,关键字,变量,判断循环.. ...
- 《大数据》专题征文:国产环境下的大数据处理系统
点击上方蓝字关注我们 <大数据>专题征文:国产环境下的大数据处理系统 (截稿时间:2021年5月31日) 目前,我国在一些前沿领域开始进入并跑.领跑阶段,但仍然面临很多"卡脖子& ...
- 2015年《大数据》高被引论文Top10文章No.2——大数据时代的数据挖掘 —— 从应用的角度看大数据挖掘(上)...
2015年<大数据>高被引论文Top10文章展示 [编者按]本刊将把2015年<大数据>高被引论文Top10的文章陆续发布,欢迎大家关注!本文为高被引Top10论文的No.2, ...
- 【2015年第4期】大数据时代的数据挖掘 —— 从应用的角度看大数据挖掘(上)...
大数据时代的数据挖掘 -- 从应用的角度看大数据挖掘 李 涛1,2,曾春秋1,2,周武柏1,2,周绮凤3,郑 理1,2 1. 南京邮电大学计算机学院 南京 210023:2. 美国佛罗里达国际大学 迈 ...
- 《大数据》2015年第2期“专题”——我国大数据交易的主要问题及建议
我国大数据交易的主要问题 及建议 杨 琪,龚南宁 数据堂(北京)科技股份有限公司北京 100190 摘要:数据的开放和流通是数据资源价值体现的前提和基础,我国数据交易市场仍处在发展的初级阶段,大数据在 ...
- 大数据就业前景如何?马云曾经说过大数据是未来顶峰时代应验了
根据教育部的数据,35所高校在中国开设了大数据专业.也就是说,高考报考可以直接汇报专业的主要数据. 我要推荐下我自己建的大数据开发学习群:119599574,专注大数据分析方法,大数据编程,大数据仓库 ...
- 2021超全大数据面试宝典,吐血总结十万字,大数据面试收藏这一篇就够了
本文最新版已发布至公众号[五分钟学大数据] 获取此套面试题最新pdf版,请搜索公众号[五分钟学大数据],对话框发送 面试宝典 扫码获取最新PDF版: 版本 时间 描述 V1.0 2020-02-18 ...
- 挖财基于大数据的信贷审批系统实践
挖财基于大数据的信贷审批系统实践 时间 2016-09-24 16:01:40 代码说 原文 http://h2ex.com/1607 主题 大数据 HBase 数据库 大家好,今天给大家带来的分 ...
最新文章
- 153和154.寻找旋转排序数组中的最小值
- 多少行数_技术分享 | MySQL:查询字段数量多少对查询效率的影响
- pythonjson数据写入csv_将JSON数据从“Requests”Python模块写入CSV
- 2015 ICL, Finals, Div. 1 Ceizenpok’s formula(组合数取模,扩展lucas定理)
- windows使用glade2开发gtk程序
- iOS Cookie相关操作
- 税务计算机网络管理制度,税务系统电子数据处理管理办法(试行)
- SAP Loyalty management模块演示场景的测试数据
- 一步步编写操作系统 35 内存为何要分页
- G6图可视化引擎 v4.1.7
- 【机器学习】Andrew Ng——02单变量线性回归
- iOS关于iPhone6和iPhone6 Plus的屏幕适配问题
- 勤哲excel服务器2017试用
- Visual Studio 2017各版本安装包离线下载、安装全解析
- 计算机网络——各层次网络互联设备
- arcgis怎么关联excel表_arcgis中如何跟excel连接?
- 绘图基础--画弧,扇形,弓形
- C#小游戏之疯狂字母
- 如何处理PHP 表单?
- windows 运行打开服务命令