Offline RL Summary
文章目录
- Value-based
- *Off-Policy Deep Reinforcement Learning without Exploration (2018, ICML)
- *Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (2019, NeurIPS)
- Behavior Regularized Offline Reinforcement Learning (2019)
- *EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL (2020, ICML)
- *Conservative Q-Learning for Offline Reinforcement Learning (2020,NeurIPS)
- *What You See: Implicit Constraint Approach for Offline Multi-Agent Reinforcement Learning (2021, NeurIPS)
- Imitation-based
- *Exponentially Weighted Imitation Learning for Batched Historical Data (2018, NeurIPS)
- *Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning (2019)
- *BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning (2019, NeurIPS)
- *Keep Doing What Worked_Behavioral Modelling Priors for Offline Reinforcement Learning (2020, ICLR)
- *Curriculum Offline Imitating Learning (2021, NeurIPS)
*代表重要文章
关于offline RL更详细的综述可以参考2020年的 Offline Reinforcement Learning
Value-based
基于值的offline RL算法大多数都是围绕BCQ展开的研究,解决Q- leaning 在无法与环境交互的情况下的外推误差问题。而CQI是第一篇不考虑Q learning而考虑如何利用重要性采样解决外推误差的文章。
*Off-Policy Deep Reinforcement Learning without Exploration (2018, ICML)
文章提出了BCQ用来解决在offline Q-learning 中存在的外推误差。首先证明了 Q-learning 可以收敛到对应batch 中的MDP的最优值,并且对于确定性的MDP,batch中的MDP等价于真实MDP,因此所有batch中的state-action pair都收敛到真实MDP的Q值。假设所有batch约束的策略只考虑batch中的数据,则Q-learning可以得到一个batch中的最优策略。文章通过一个生成模型来生成和batch中相似的动作并利用一个扰动模型对动作添加轻微扰动。
Contributions:
- To overcome extrapolation error in off-policy learning, we introduce batch-constrained reinforcement learning, where agents are trained to maximize reward while minimizing the mismatch between the state-action visitation of the policy and the state-action pairs contained in the batch.
- Our deep reinforcement learning algorithm, Batch-Constrained deep Q-learning (BCQ), uses a state-conditioned generative model to produce only previously seen actions. This generative model is combined with a Q-network, to select the highest valued action which is similar to the data in the batch. Under mild assumptions, we prove this batch-constrained paradigm is necessary for unbiased value estimation from incomplete datasets for finite deterministic MDPs.
算法伪代码:

首先文章说明了外推误差 (Extrapolation Error)的三个来源:
- 缺失数据:Qθ(s′,π(s′))Q_θ(s' , π(s' ))Qθ(s′,π(s′)) 可能会很糟糕如果s′,π(s′)s', \pi(s')s′,π(s′) 周围没有足够的state-action pair
- 模型偏差:在执行更新的时候,贝尔曼乘子由数据集中的转移来逼近,可能导致误差
- 分布偏移:如果在数据中数据的分布和当前策略分布的不匹配,那么由当前策略选择的动作的值估计可能会很差。一个例子是该动作在训练中可能出现次数很少导致没有熟练。
文章接下去提出,为了避免外推误差,一个策略应该产生和batch中相似的动作-状态访问频率。并且将这样的策略定义为:batch-constrained
因此一个的策略选择动作应该有如下性质:
- 最小化挑选的动作和batch中数据的距离
- 未来访问的状态应该同数据集中相似
- 最大化值函数
文章重点强调优化(1),As a result, we propose optimizing the value function, along with some measure of future certainty, with a constraint limiting the distance of selected actions to the batch.
文章通过一个state-conditioned generative model来生成batch中相似的动作,并且通过神经网络给生成的动作在小范围内添加干扰,并且利用Q-network挑选值最高的动作。最后训练一些列的Q-network并选择其中最小值用于值更新,并惩罚那些不熟悉的状态。
接着文章分析了如何在有限的MDP中解决外推误差
在有限的MDP中,外推误差可以被描述为batch和真实MDP中转移概率的误差。

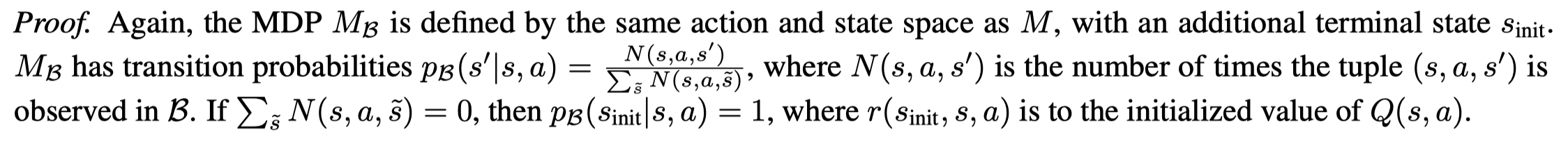
对于上述定义了batch中的MDPMBM_BMB,给出了batch中数据和batch外数据的采样概率(都是有限非零的),因此从batch中采样等价于从 MDP MBM_BMB 中采样,因此满足Q-learning收敛条件:For any given MDP Q-learning converges to the optimal value function given infinite state-action visitation and some standard assumptions.
文章定义 ϵMDP\epsilon_{MDP}ϵMDP 为表格外推误差:
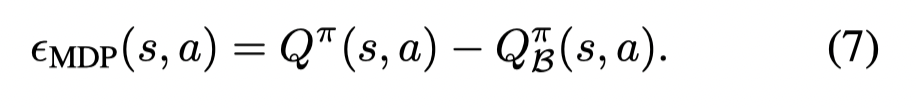
则这个误差可以写成贝尔曼类似的方程:
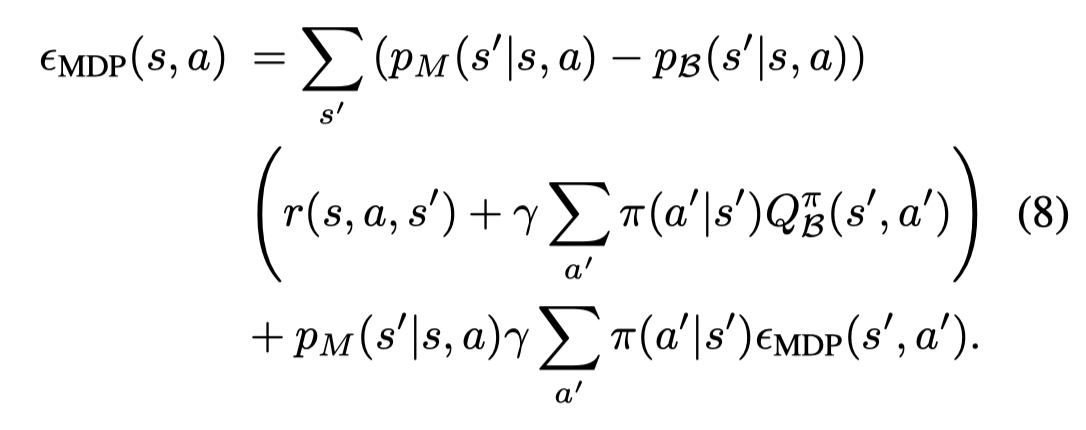
(只需要把Q值写成合的形式再拆分合并就好)
这就意味着外推误差其实就是转移概率的不同乘上值的权重。
定义:
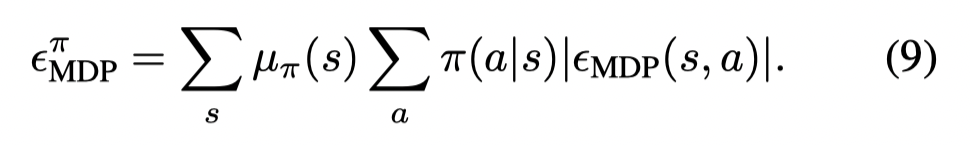
则有:
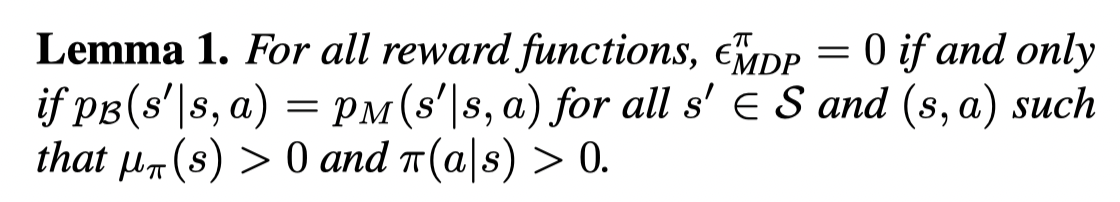
![]()
也就是说只要在相关的区域有相同的转移概率,则策略在batch中可以被正确估计。注意在随机MDP中,这一点需要较大的样本量来实现。但是在确定性的MDP中,计算转移概率只需要一个样本。这就意味着,一个策略只遍历batch中的转移(也就是不考虑那些batch外的转移),就能被正确估计。
文章定义batch-constrained策略为:if for all (s,a)(s, a)(s,a) where µπ(s)>0µ_π(s) > 0µπ(s)>0 and π(a∣s)>0π(a | s) > 0π(a∣s)>0 then (s,a)∈B(s, a) ∈ B(s,a)∈B.
并且定义一个batch是coherent:if for all (s,a,s′)∈B(s, a, s') ∈ B(s,a,s′)∈B then s′∈Bs' ∈ Bs′∈B unless s′s's′ is a terminal state. 只要数据通过trajectory的形式收集的,这个条件就满足。

![]()
通过将batch-constrained策略和Q-learning相结合,得到BCQL
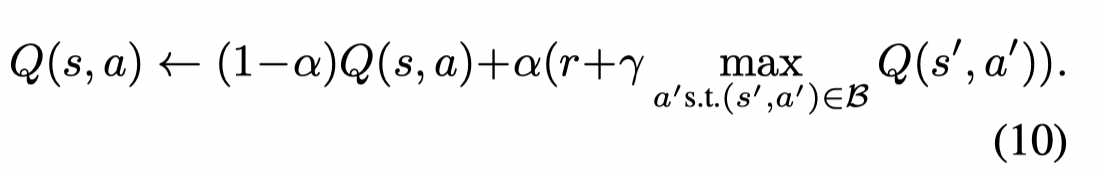
并且讨论了BCQL的收敛性

同时BCQL可以得到batch中最优的batch-constrained 策略

![]()
Batch-Constrained deep Q-learning (BCQ)
给定一个状态,BCQ通过一个generative model生成与batch有着高相似度的候选动作,并且通过Q-network选择值最高的动作。Clipped Double Q-learning来调整值估计,惩罚稀少或没见过的状态。
文章定义了一个conditioned marginal likelihood PBG(a∣s)P_B^G(a | s)PBG(a∣s) 来衡量一个(s,a)(s,a)(s,a) 与batch中数据的相似性,因此可以通过最大化PBG(a∣s)P_B^G(a | s)PBG(a∣s) 来减少外推误差。也就是选择最有可能是batch中的动作。考虑到在高纬空间估计 PBG(a∣s)P_B^G(a | s)PBG(a∣s) 的困难,文章利用一个参数化的生成模型 Gω(s)G_ω(s)Gω(s) 用来采样动作,作为argmaxaPBG(a∣s)\arg\max_aP_B^G(a | s)argmaxaPBG(a∣s) 的近似估计。
文章利用 conditional variational auto-encoder (VAE) 作为生成模型。为了增加动作的多样性,文章利用一个perturbation model给采样的n个动作添加扰动。最后利用 Q-net 选择值最高的动作:
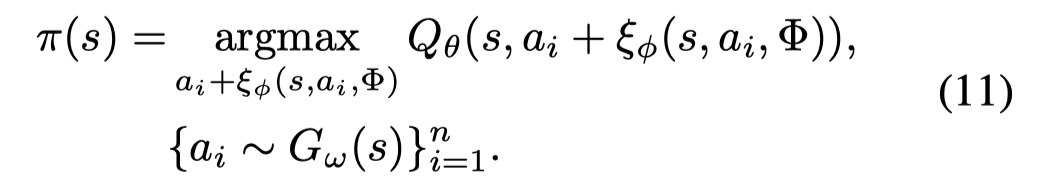
pertubation model 可以通过deterministic policy gradient algorithm来训练:
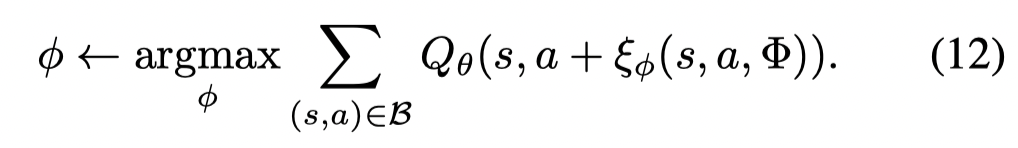
为了惩罚未来状态的不确定性,文章利用了一个修改的Clipped Double Q-learning。其中包含的最小化和最大化两个项目。我认为把带 λ\lambdaλ 项的合并,则在原本的 doule Q-learning 更新公式中中多了一项Q值的差异项(max - min),这一项作为方差的惩罚项。如果将λ\lambdaλ 设置为1,则公式变为Clipped Double Q-learning.
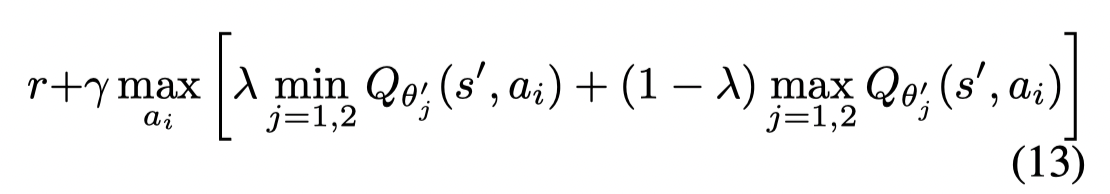
*Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (2019, NeurIPS)
文章提出的BEAR与BCQ相似,都是解决在Q值更新中存在的外推误差问题。只不过BCQ主要要动作的选取限制在batch中并惩罚会导致未知状态的动作。而BEAR限制了策略的选取限制在来训练分布的支撑集上,也就是限制策略的集合而不是限制策略中的分布。通过放宽了限制使得Q-learning可以搜索到一个更优的策略。
Contributions:
- we formalize and analyze the reasons for instability and poor performance when learning from off-policy data. We show that, through careful action selection, error propagation through the Q-function can be mitigated.
- We then propose a principled algorithm called bootstrapping error accumulation reduction (BEAR) to control bootstrapping error in practice, which uses the notion of support-set matching to prevent error accumulation.
算法伪代码:

首先文章分析了在 Q-learning 中OOD的动作。
定义:ζk(s,a)=∣Qk(s,a)−Q∗(s,a)∣ζ_k(s, a) = | Q_k (s, a) − Q^∗ (s, a) |ζk(s,a)=∣Qk(s,a)−Q∗(s,a)∣ 为第k次迭代的总误差,δk(s,a)=∣Qk(s,a)−TQk−1(s,a)∣δ_k (s, a) = | Q_k (s, a)− T Q _{k−1} (s, a) |δk(s,a)=∣Qk(s,a)−TQk−1(s,a)∣ 为第k次迭代的贝尔曼误差,则有ζk(s,a)≤δk(s,a)+γmaxa′Es′[ζk−1(s′,a′)]ζ_k(s, a) ≤ δ_k(s, a) + γ \max_{a'} E_{s′} [ ζ_{k−1} (s' , a' )]ζk(s,a)≤δk(s,a)+γmaxa′Es′[ζk−1(s′,a′)]. 也就是误差可以认为是δk(s,a)δ_k(s, a)δk(s,a) 的折扣累积,并且δk(s,a)δ_k(s, a)δk(s,a) 会在OOD的状态和动作出变得很大。
BCQ约束学习到的策略与行为策略的分布相似,BEAR放宽了这个约束,将分布约束在训练分布的支撑上。考虑到如果行为策略是一个普通的策略,那么除了将学习到的策略约束到行为策略,还需要寻找一个次优解,而BCQ的约束太强,更像是一个结合了Q值的BC。BEAR约束的是策略的支撑集而不是在策略集合中动作的概率 (约束π∈Π\pi \in \Piπ∈Π 而不是 π(a∣s))\pi(a|s))π(a∣s))。
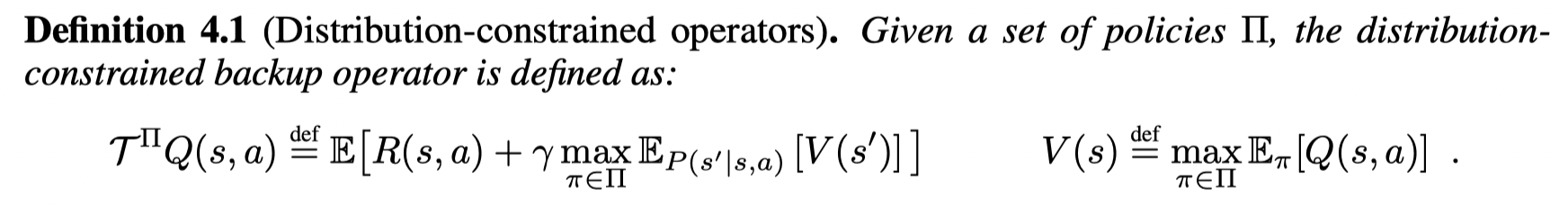
这个乘子满足标准贝尔曼乘子的收敛性,并且可以收敛到一个最优点。
通过这个乘子得到策略的(sub)optimality可以通过两个误差项来分析:
第一个定义为suboptimality bias,也就是最优策略可能在约束集外,因此需要衡量通过该乘子得到的最优解和标准贝尔曼乘子得到的最优解的差距:
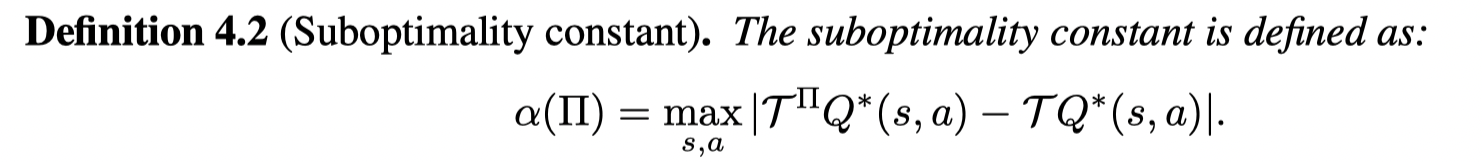
第二个定义为concentrability coefficient,衡量的是distributional shift 的严重性:

则我们可以bound住通过 Distributional-constrained Q-iteration 的表现:
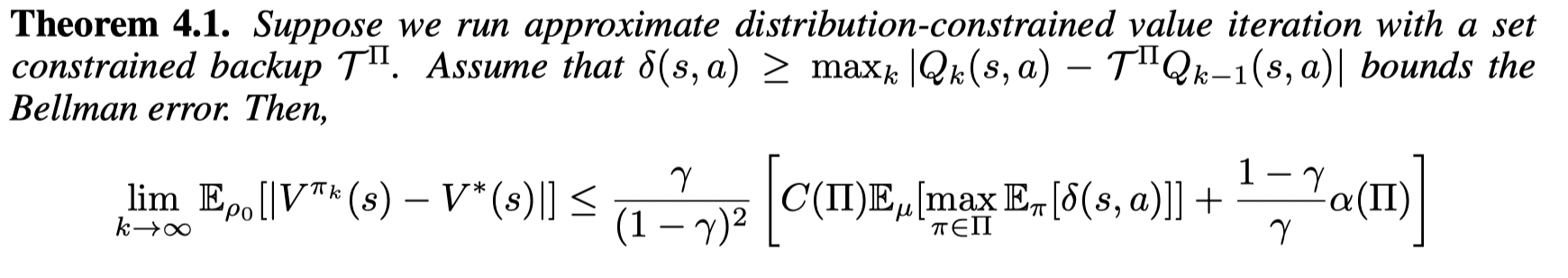
当增大策略集合Π\PiΠ的规模,CCC值会上升,α\alphaα 会下降。
文章分析了一个特俗的策略集合,Πϵ={π∣π(a∣s)=0\Pi_{\epsilon} = \{ π | π(a | s) = 0Πϵ={π∣π(a∣s)=0 whenever $ β (a | s) < 0}$, 而其中 β\betaβ 是行为策略。
则通过这个策略集合,可以bound住concentrability coefficient:

这就意味着我们可以选取在训练分布上支撑的策略(π∈Πϵ\pi \in \Pi_{\epsilon}π∈Πϵ)来减避免Q估计中误差的增加。
Bootstrapping Error Accumulation Reduction (BEAR)
首先是策略提升部分
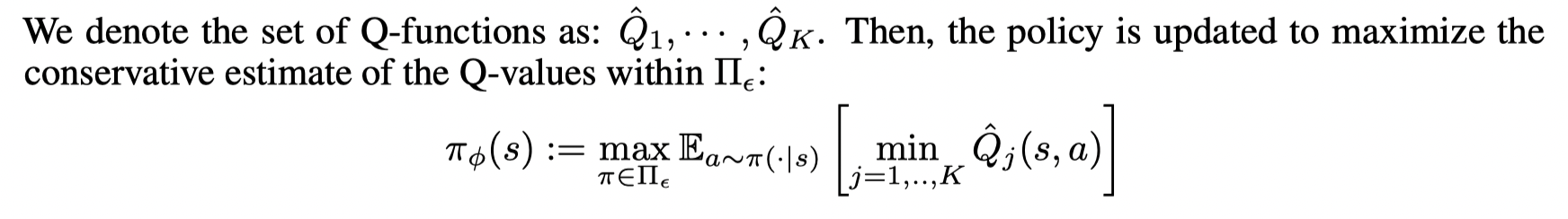
并且设计一个约束项,用于在 Πϵ\Pi_{\epsilon}Πϵ 上搜索策略。考虑到行为策略可能是未知的,文章利用 maximum mean discrepancy (MMD) 来进行逼近这个约束。
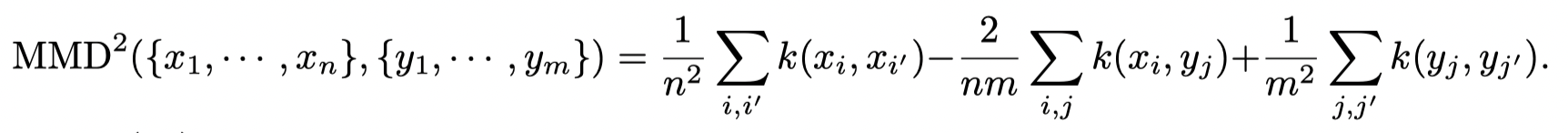
在策略提升中的优化问题为:
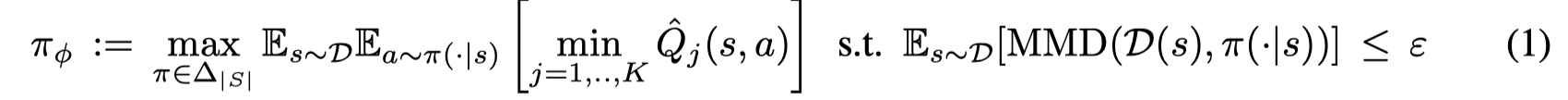
考虑到在计算distribution-constrained backup中的最大化π∈Πϵ\pi \in \Pi_{\epsilon}π∈Πϵ 在实际操作中难以实现,因此可以在 β\betaβ 的支撑集中采样狄利克雷分布。
Behavior Regularized Offline Reinforcement Learning (2019)
文章提出了一个框架BRAC,一个添加了和行为策略相关的惩罚项的 actor-critic 框架,并分析了和 BEAR以及BCQ的关系。
Contributions:
- In this work, we aim at evaluating the importance of different algorithmic building components as well as comparing different design choices in offline RL approaches. We focus on behavior regularized approaches applied to continuous action domains.
- We introduce behavior regularized actor critic (BRAC), a general algorithmic framework which covers existing approaches while enabling us to compare the performance of different variants in a modular way. We find that many simple variants of the behavior regularized approach can yield good performance, while previously suggested sophisticated techniques such as weighted Q-ensembles and adaptive regularization weights are not crucial.
Behavior Regularized Actor Critic
文章提出了两种方式添加策略规范项
第一种为 value penalty (vp):
与SAC相似,给值函数的估计项添加一个惩罚项:
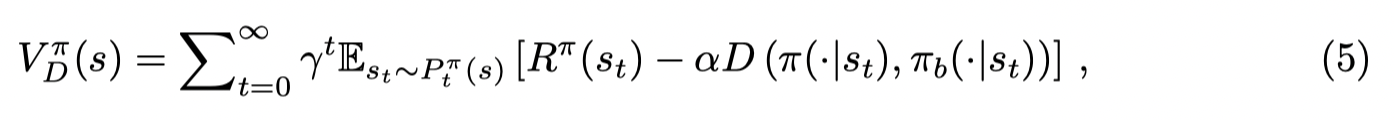
在 actor-critic 框架下,Q-function的目标函数为:
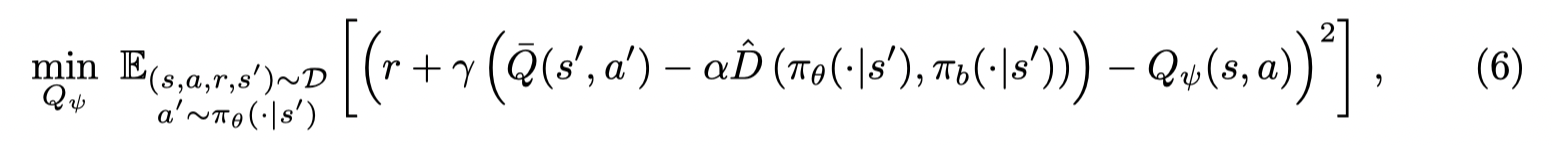
策略学习的目标为:
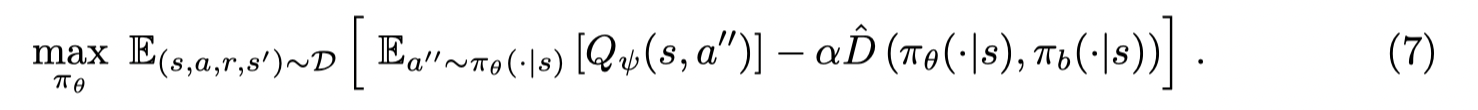
如果 D 是熵函数并且 πb\pi_bπb 是一个均匀策略,则和SAC一样。
第二种为 policy regularization (pr):
在Q 值更新中令 α\alphaα 为0,在 policy 中保持不变。
接着文章讨论了几种不同 DDD 的选择:
Kernel MMD:
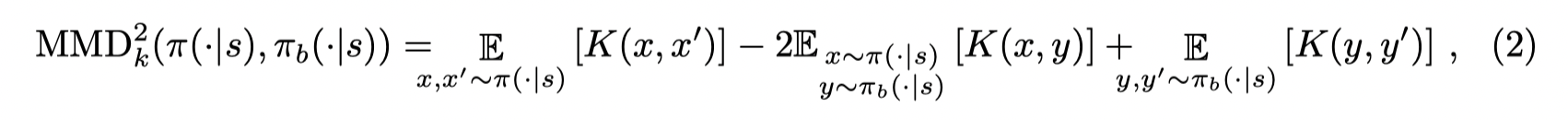
KL Divergence:
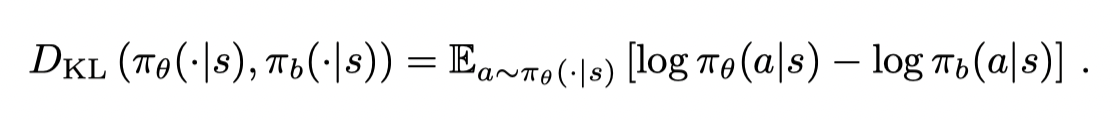
Wasserstein Distance:
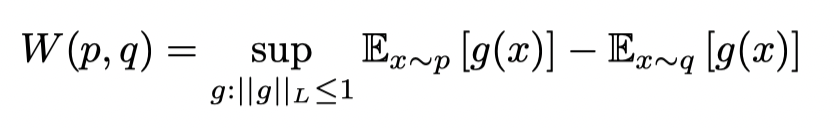
BEAR和BEAC的关系:BEAR 是使用了 pr,其中 kernel MMD 作为惩罚项,并且min-max ensemble estimate 作为Q-target 估计的BEAC
BCQ 与 BEAC无关。
*EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL (2020, ICML)
文章提出了一个BCQ的简化版本EMaQ,定义了一个Expected Max Q operator,在训练过程中保留了BCQ的生成模型, 将扰动模型转变为对采样动作N的分析,并且给出了Expected Max Q operator的理论性质。
Contributions
- We introduce the Expected-Max Q-Learning (EMaQ) operator, which interpolates between the standard Q-function evaluation and Q-learning backup operators. The EMaQ operator makes explicit the relation between the proposal distribution and number of samples used, and leads to sub-optimality bounds which introduce a novel notion of complexity for offline RL problems.
算法伪代码:

首先回顾BCQ的形式:
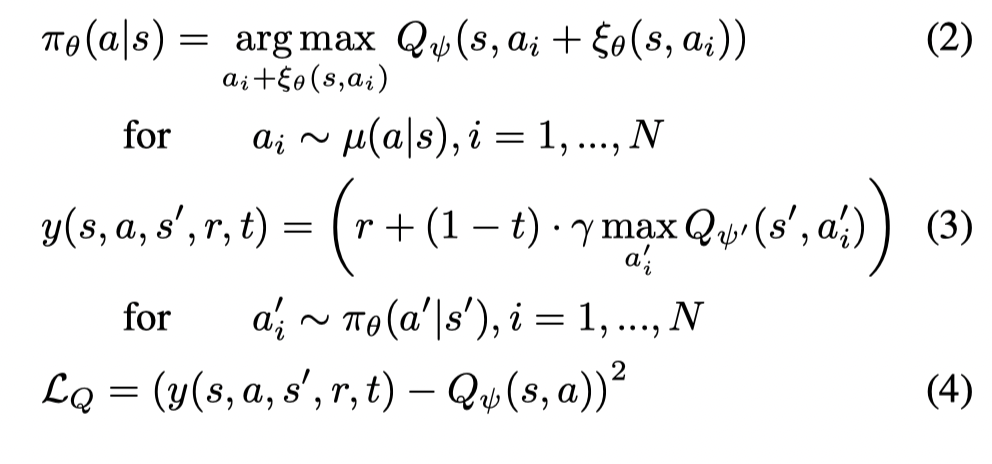
Expected-Max Q-Learning
首先文章定义了一个Expected Max Q operator,只考虑行为策略 μ\muμ 和动作样本数量 NNN:
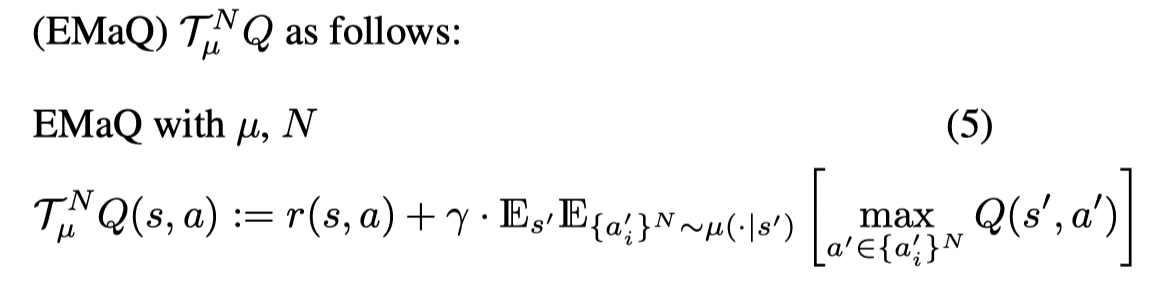
当 N=1N=1N=1 时,这个乘子就是标准的贝尔曼乘子:
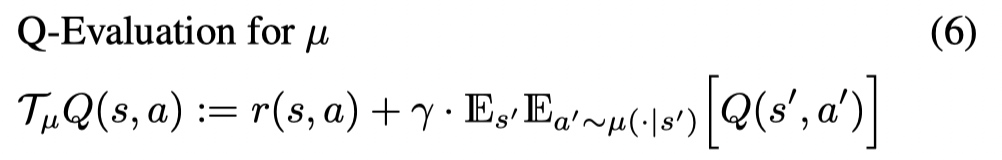
当 N→∞N \rightarrow \inftyN→∞ 时,这个乘子就是最优贝尔曼乘子:
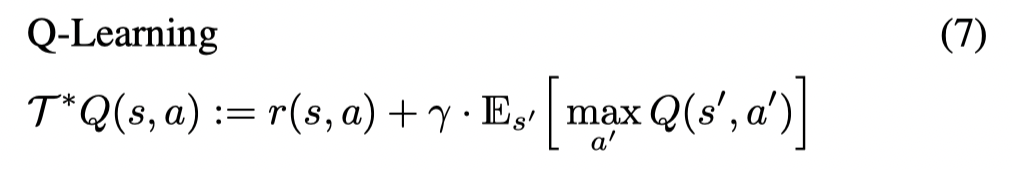
接着文章分析了Expected Max Q operator的一些理论性质
首先这个乘子是满足不动点存在定理的:

接着这个乘子收敛到某个策略对应的Q值:

该策略定义为从 μ\muμ 中采样 N个动作并选取其中Q值最大的动作
接着可以得到 EMaQ族的一些性质:


也就是当 N为1时,通过这个乘子得到的Q值的对应 μ\muμ 的Q值,而当N趋向于无穷大时,得到的Q值是 μ\muμ 支持的策略类中最优策略对应的Q值(当 μ\muμ 覆盖动作空间时,对应的是最优策略的Q值)。
也就是说当增加N时,得到的Q值对应一个更好的策略。
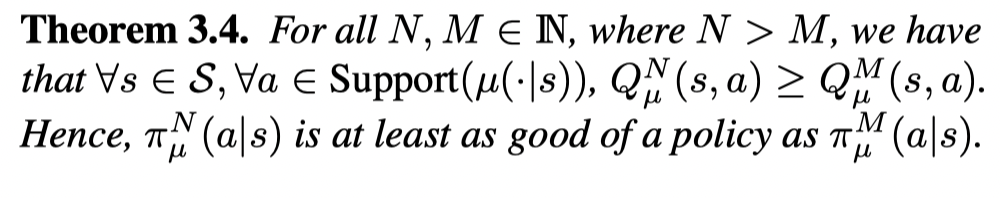
并且给出了 πμN(a∣s)π^N_{\mu} (a | s)πμN(a∣s)和 πμ∗(a∣s)\pi^*_{\mu}(a|s)πμ∗(a∣s) 之间差距的界限:

考虑到实际中的 μ\muμ 并不知道,因此文章依旧拟合一个生成模型。Q-function的目标函数为:
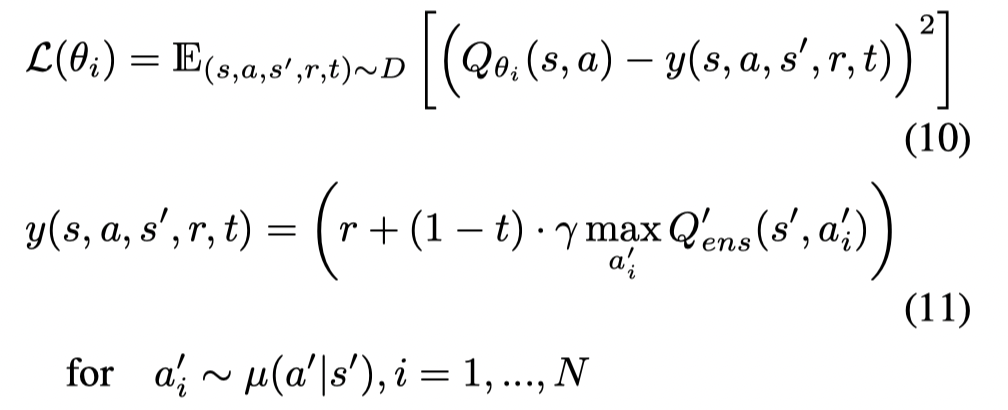
值得注意的是,文章并没有训练一个代表策略的神经网络。在测试时,从 μ\muμ 中生成N个动作并选取 ensemble of Q functions 中最大值对应的动作。
同时 μ\muμ 的拟合也会决定生成动作是否为OOD动作的概率。N也是一个隐形的规范项,当N减少时,会减少生成的动作是OOD动作的概率。并且文章认为BCQ中采用VAE来拟合生成模型效果不好,因此文章采用了MADE。
*Conservative Q-Learning for Offline Reinforcement Learning (2020,NeurIPS)
文章提出了CQL,通过计算出真实值函数的lower-bound来减少由于外推误差导致某些动作有过高的,错误的值估计的问题。
Contributions
Our primary contribution is an algorithmic framework, which we call conservative Q-learning (CQL), for learning conservative, lower-bound estimates of the value function, by regularizing the Q-values during training. Our theoretical analysis of CQL shows that only the expected value of this Q-function under the policy lower-bounds the true policy value, preventing extra under-estimation that can arise with point-wise lower-bounded Q-functions.
算法伪代码:

为了避免值的过估计,可以在标准的贝尔曼方程中增加一个最小化Q值的项来获得 conservative, lower-bound Q-function,最小化Q值可以通过最小化在一个特俗的分布μ(s,a)\mu(s,a)μ(s,a) 下的期望Q值,并且限制 μ\muμ 匹配数据集中的状态边缘分布,Q-function的更新为:
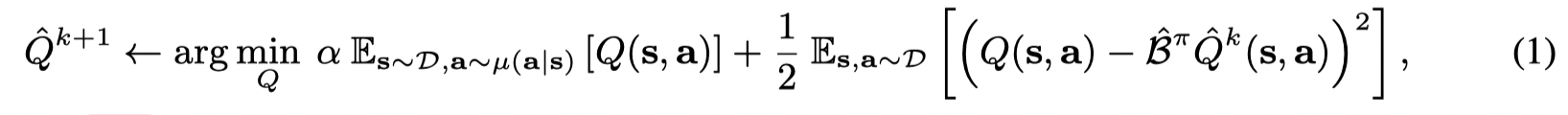
当 kkk 趋向于无穷大时,对于所有的 (s,a)(s,a)(s,a), Q^π\hat Q^πQ^π lower-bounds QπQ^{\pi}Qπ。
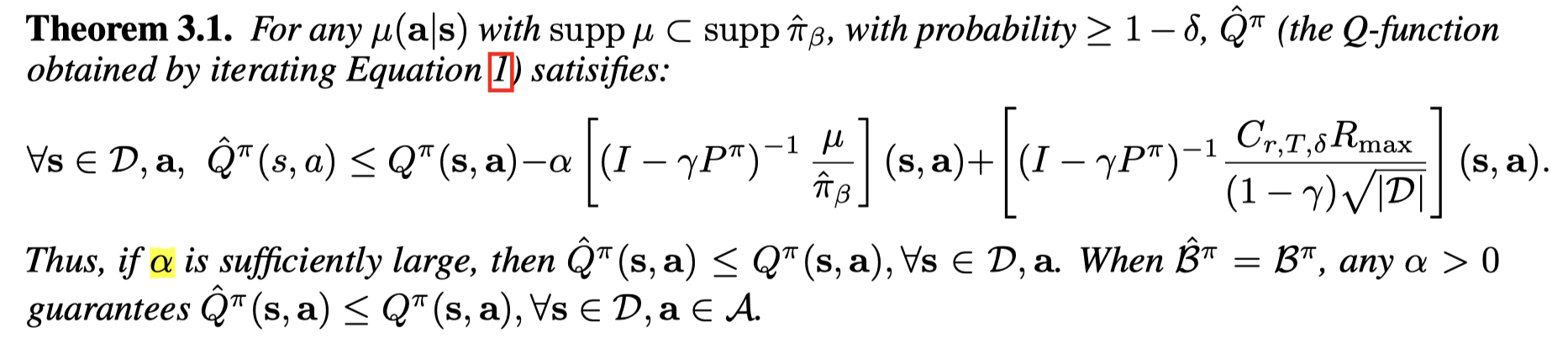
证明:
在 tabular 设置下,对(1)中Q求微分并且设为0可以得到:
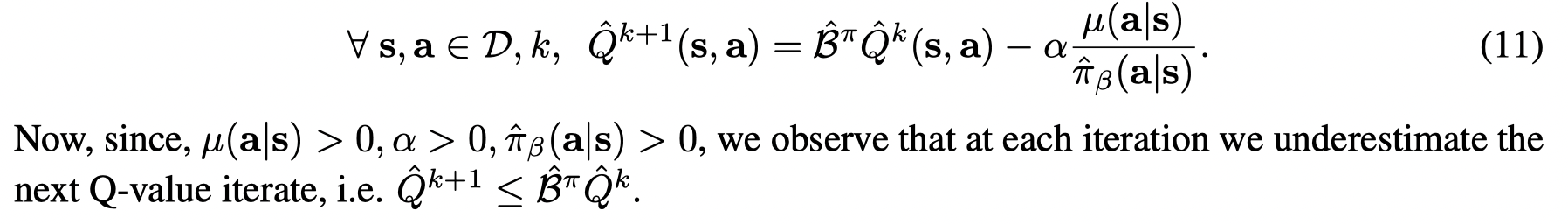
在(11)中,Q值的更新是通过empirical Bellman,而empirical Bellman和actual Bellman 之间的差距可以被bound住,with probability ≥δ\ge \delta≥δ:
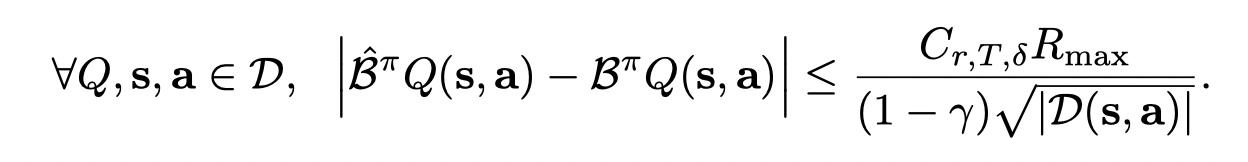
因此有:
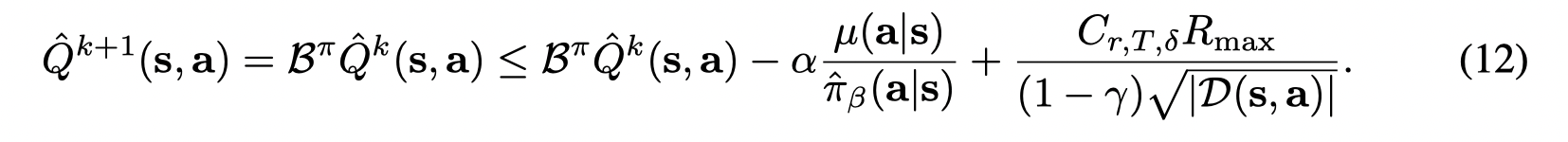
通过迭代,方程(11)的不动点为:
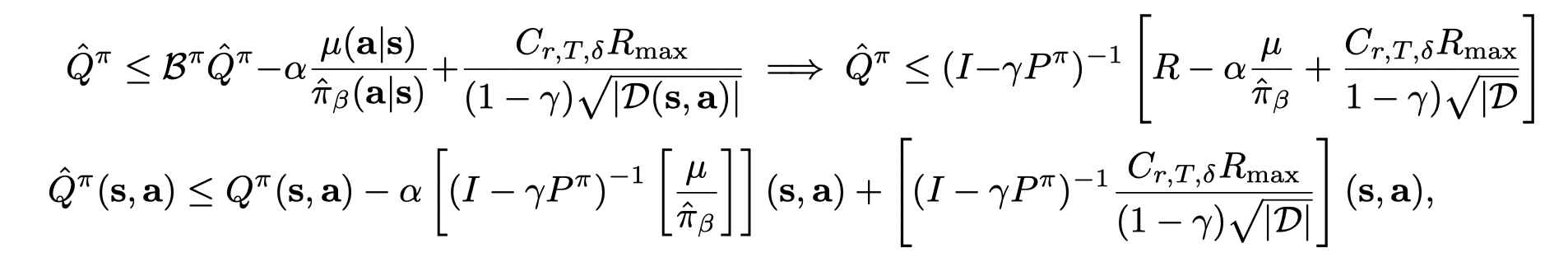
其中对于真实的Q值有,$Q^{\pi} = R + γ P^π Q^{\pi} $,则 (I−γPπ)−1R=Qπ(I− γ P^π)^{−1}R = Q^{\pi}(I−γPπ)−1R=Qπ。
可以通过 α\alphaα 的选择确定 lower-bound,只要:
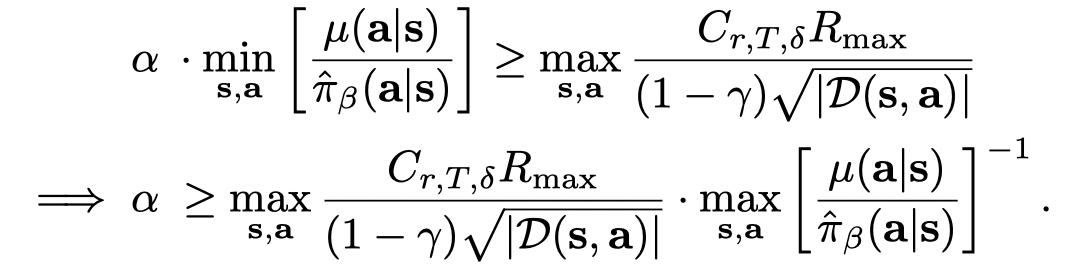
当数据集足够大并且经验贝尔曼和真实贝尔曼相等时,α\alphaα 可以取0。
证毕。
如果我们只对V值感兴趣,则可以进一步把这个bound变紧。通过再添加一项Q值当最大化项(红色项),则Q值当期望 lower-bounds真实的V值:
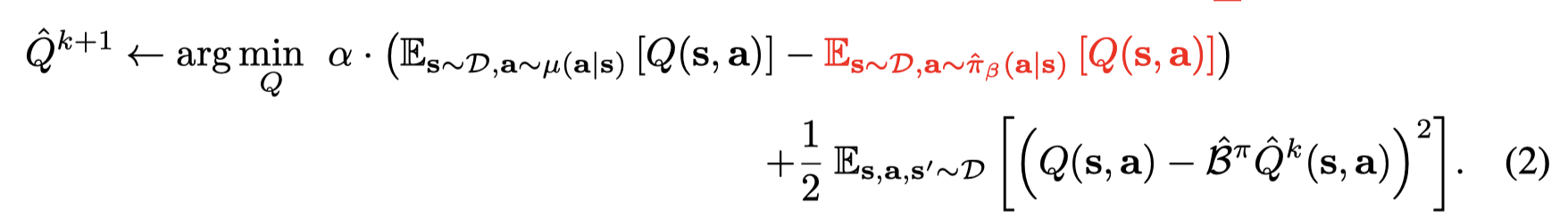
当 μ(a∣s)=π(a∣s)\mu (a | s) = π(a | s)μ(a∣s)=π(a∣s) 时,有Eπ(a∣s)[Q^π(s,a)]≤Vπ(s)E_{π(a|s)} [\hat Q^π(s, a)] ≤ V^π(s)Eπ(a∣s)[Q^π(s,a)]≤Vπ(s),但是无法保证对于所有的 (s,a)(s,a)(s,a), Q^π\hat Q^πQ^π lower-bounds QπQ^{\pi}Qπ。并且只有π^β(a∣s)\hat π_β (a | s)π^β(a∣s) 才能确保lower-bound。

证明:
在 tubular 设置下,假设B^π=Bπ\hat B^π = B^πB^π=Bπ(不相等时的误差已经在上述证明中给出,这里是为了简化证明),并且令π^β=πβ\hat \pi_{\beta} = \pi_{\beta}π^β=πβ 同样求导得到:
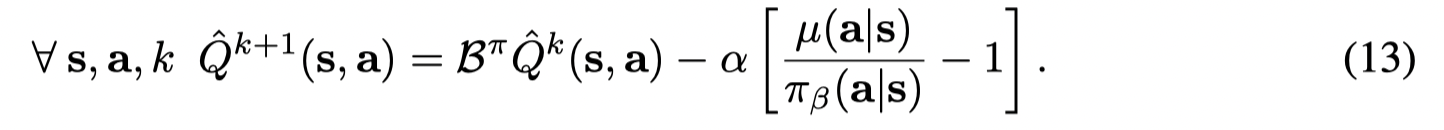
因为 μ(a∣s)\mu(a|s)μ(a∣s) 不一定大于 π(a∣s)\pi(a|s)π(a∣s),因此Q值的lower bound 无法保证。但是V值是underestimated:
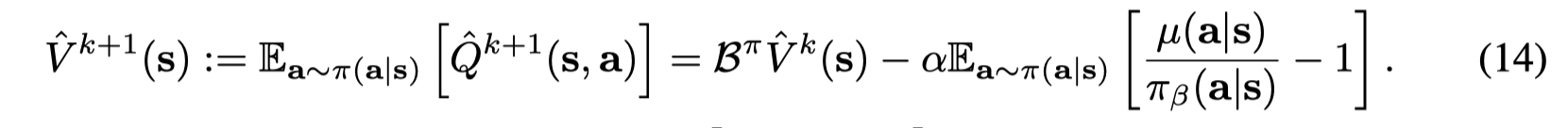
而最后一项恒大于等于0
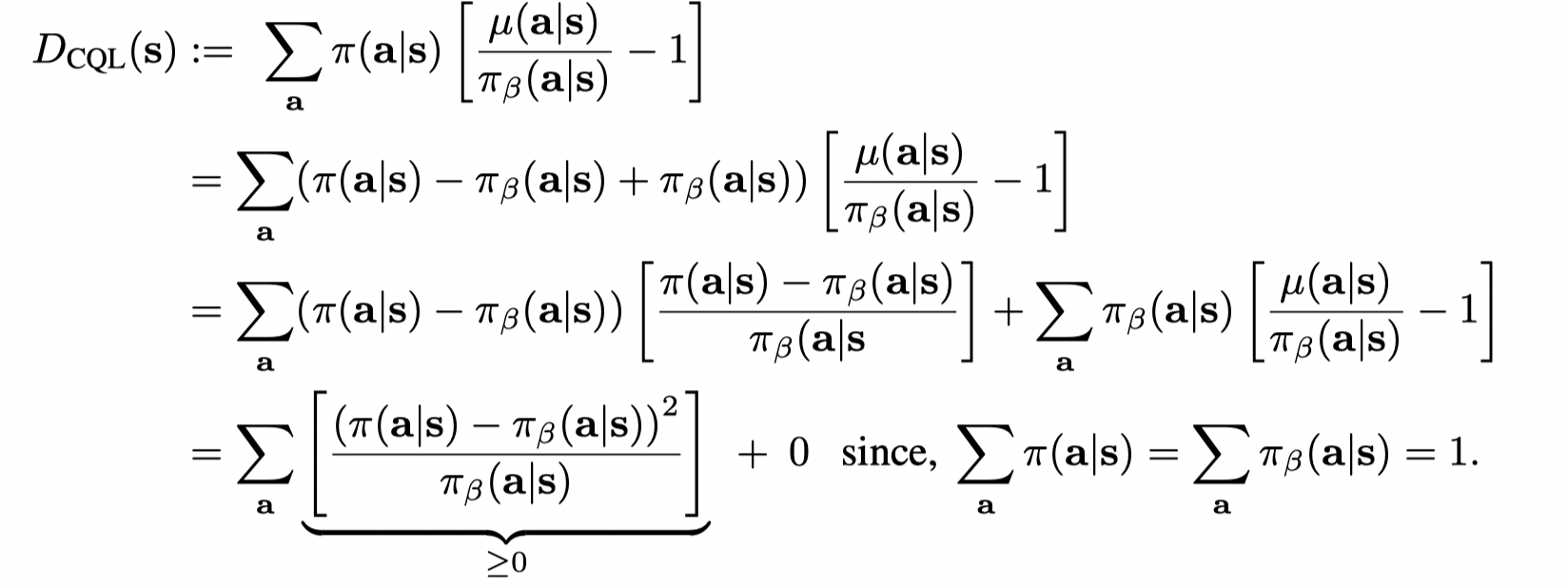
因此我们有 V^k+1(s)≤BπV^k(s)\hat V_{k+1}(s) ≤ B^π \hat V_k(s)V^k+1(s)≤BπV^k(s)。
因此计算方程(14)中 的不动点,有:
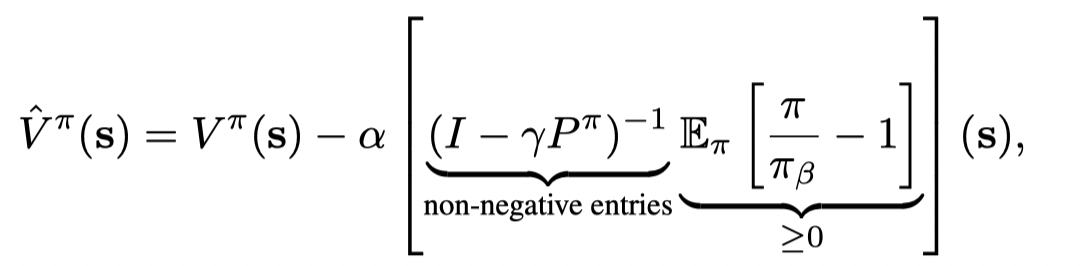
结合采样误差则有:
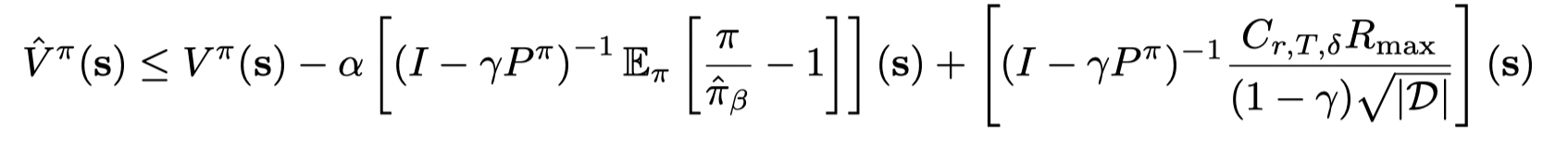
只要选取合适的 α\alphaα 值就可以避免过估计:
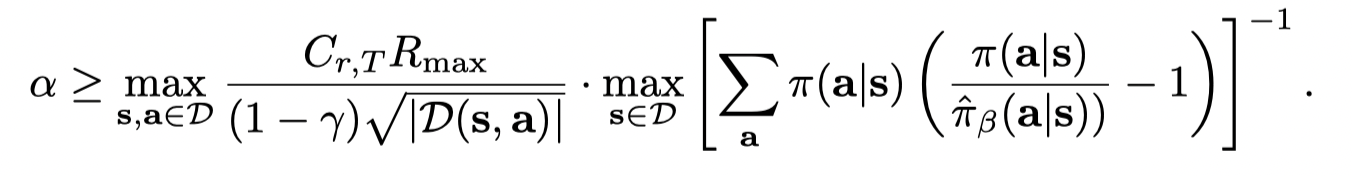
Conservative Q-Learning (CQL)
在上述讨论中,只要将 μ=π\mu = \piμ=π, 则可以在每次策略迭代时轮流执行完整的策略评估和一步的策略提升,但是这是computationally expensive。考虑到每一步迭代中的策略都是从Q值得到的,因此可以选择 μ\muμ 使得当前的 Q-function 最大化来逼近当前策略。这将导致一个online 算法(为什么是online?),我们可以通过定义一个优化问题来转变为offline算法:
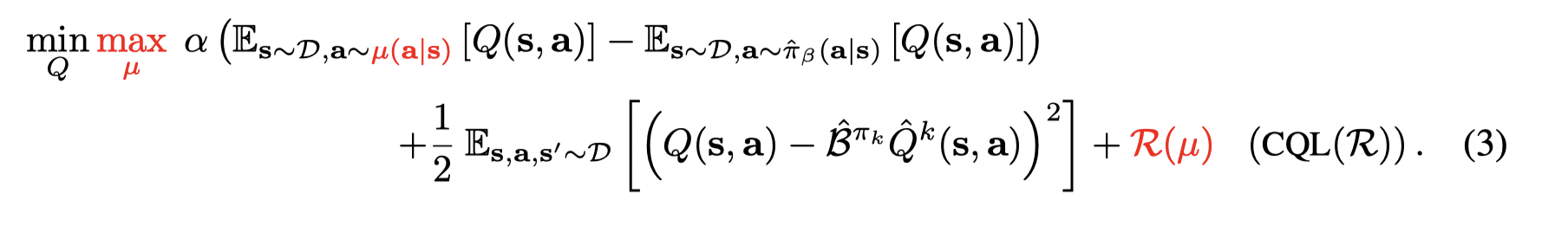
接着文章分析了一些Variants of CQL
CQL(H)CQL(H)CQL(H),将R(μ)R(\mu)R(μ) 定义为与一个均分分布的KL散度(也可以理解为 μ\muμ 的熵)

这里注意 Z=∑aexp(f(x))Z = \sum_a \exp(f(x))Z=∑aexp(f(x)),带回原项的时候不要忽略Z。
则优化方程由(3)变成 (4)
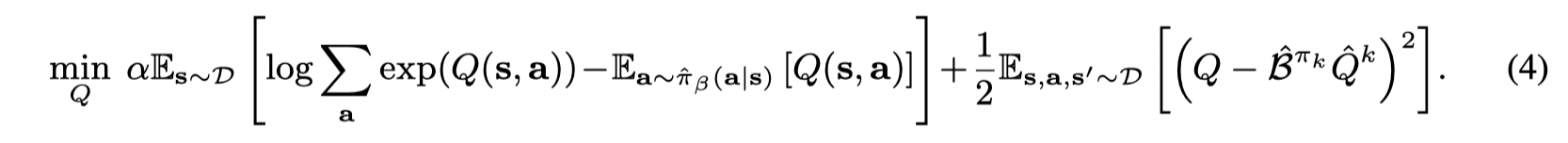
CQL(ρ)CQL(\rho)CQL(ρ),将 R(μ)R(\mu)R(μ) 定义为与前一个策略的KL散度
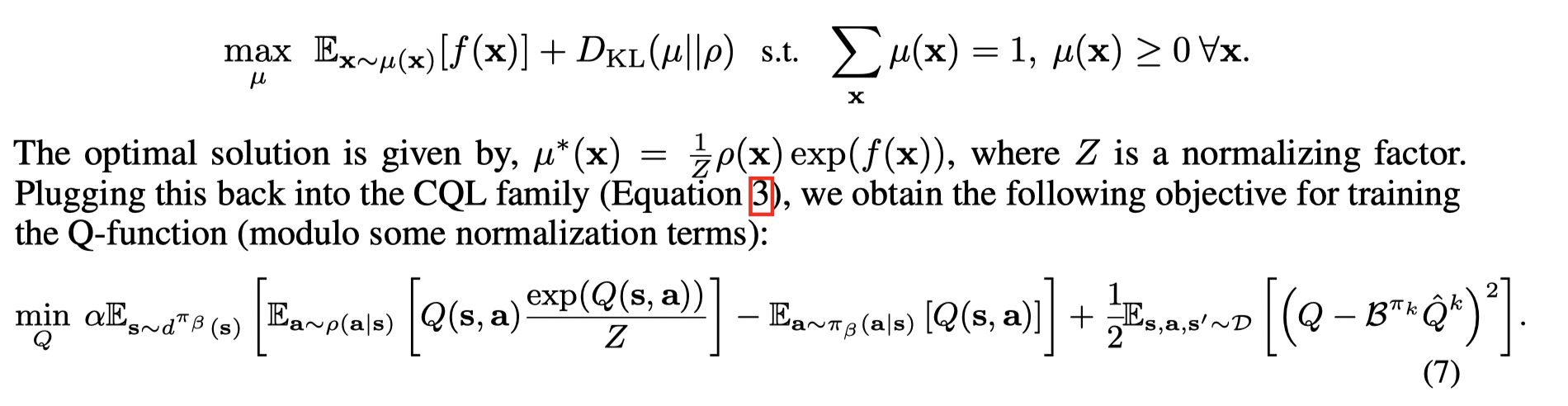
CQL(var)CQL(var)CQL(var)
接着文章分析了为何通过这种方式得到的策略是conservative
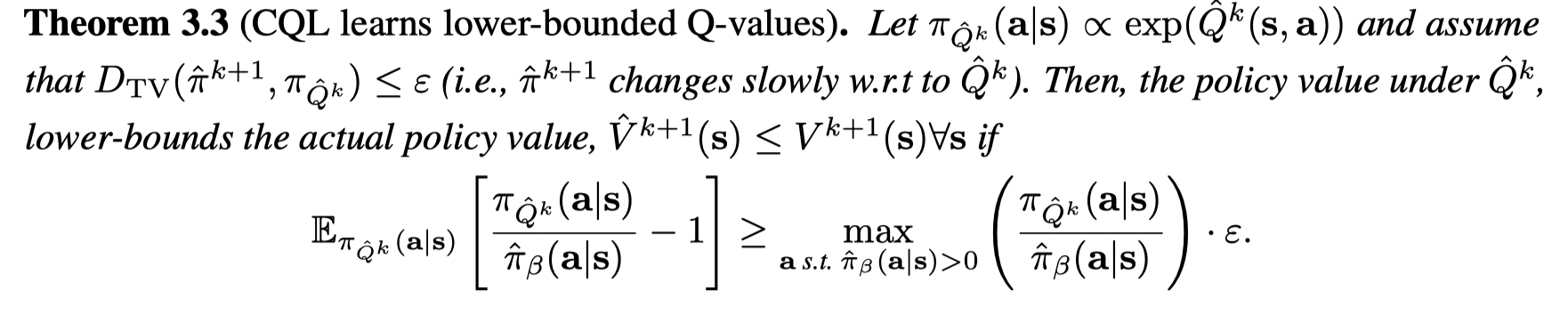
证明:
首先注意到和Theorem3.2中不同的是,在方程(3)中的优化问题,μ=πQ^k\mu = \pi_{\hat Q^k}μ=πQ^k,因此我们只需要证明 V^k+1(s)≤BπV^k(s)\hat V_{k+1}(s) ≤ B^π \hat V_k(s)V^k+1(s)≤BπV^k(s),剩余的证明部分不变。根据以下公式:
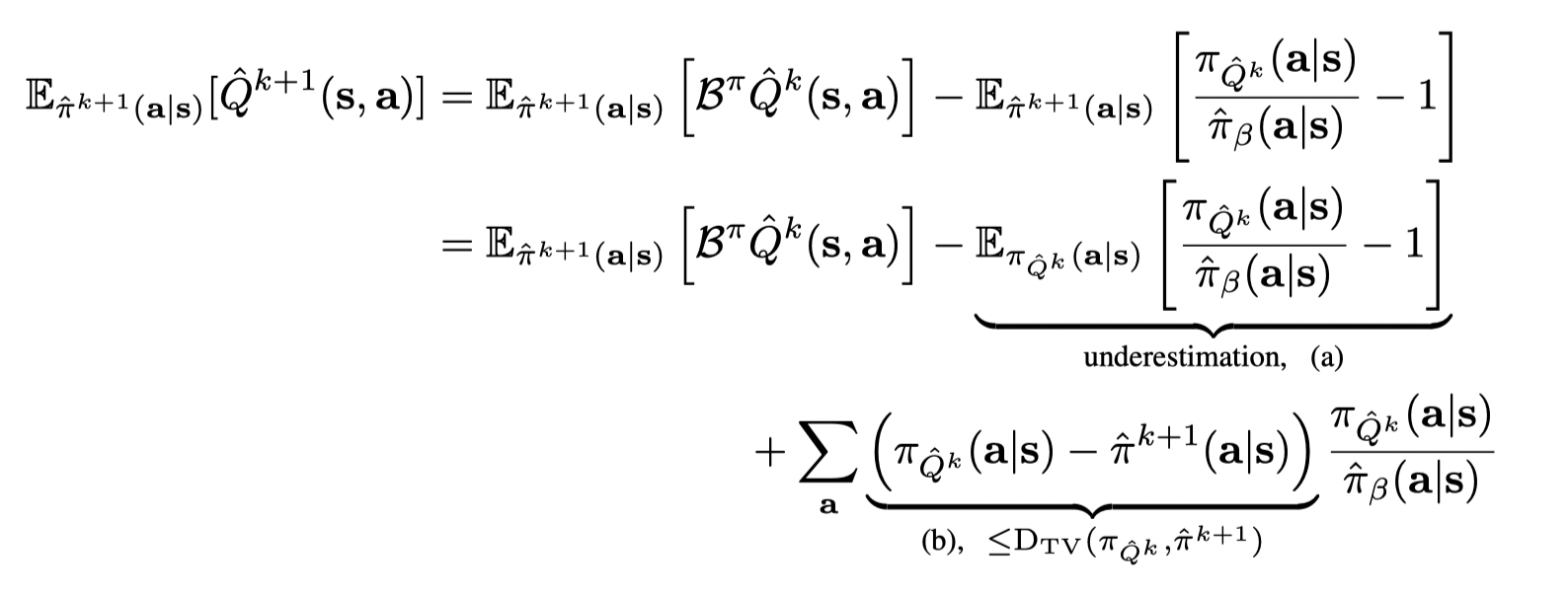
也就是如果(a) 大于 (b), 则CQL得到的V值lower-bounds真实的V值。证毕。
最后文章证明了CQL Q-function是 gap-expanding 的,也就是说CQL的得到的 in-distributions 的动作的和OOD的动作之间Q值的差异比真实的Q值要大。如果 πk(a∣s)∝exp(Q^k(s,a))π_k(a | s) ∝ exp(\hat Q_k(s, a))πk(a∣s)∝exp(Q^k(s,a)) , 则策略被约束接近数据集分布。这个我不理解。 我觉得Theorme3.4中的不等式左右两边应该都为负,所以左边的值更小(否则的话得到的策略比行为策略还差),才样得到 μk\mu_kμk 更接近 πβ\pi_{\beta}πβ 并且约束πk(a∣s)π_k(a | s)πk(a∣s) 也更接近数据分布从而减少distributional shift 的问题。
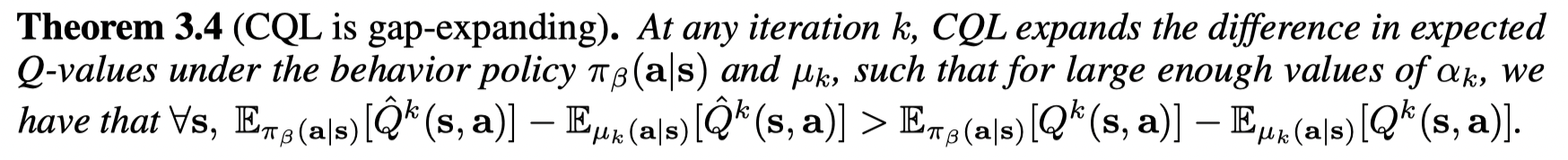
证明:
在 tabular 设置下证明:
![]()
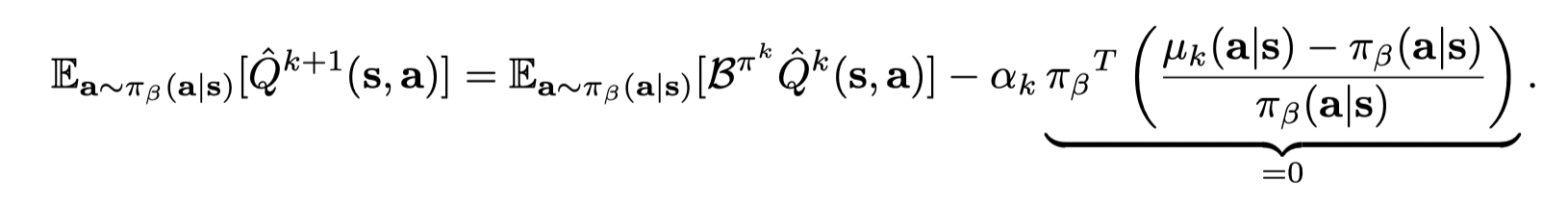
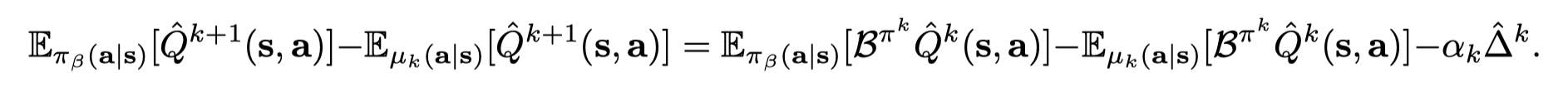
减去 Eπβ(a∣s)[Qk+1(s,a)]−Eµk(a∣s)[Qk+1(s,a)]E_{π_β(a | s)} [Q^{k+1} (s, a)] − E_{µ_k(a| s)} [Q^{k+1} (s, a)]Eπβ(a∣s)[Qk+1(s,a)]−Eµk(a∣s)[Qk+1(s,a)],得到:
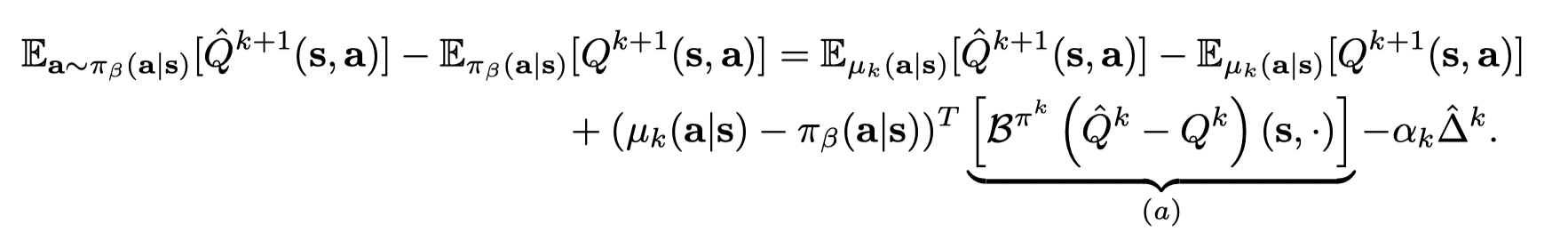
(我自己推了一遍以后得到的是 πβ(a∣s)−μk(a∣s)\pi_{\beta}(a|s) - \mu_k(a|s)πβ(a∣s)−μk(a∣s),不过这一项的正负并不影响结果)
因此只需要选择适当的 αk\alpha_kαk 就能得到不等式,并且可以结合采样误差(这里不写了)。证毕。
我认为在结合了采样误差后,这个定理是存在问题的。
*What You See: Implicit Constraint Approach for Offline Multi-Agent Reinforcement Learning (2021, NeurIPS)
文章提出了ICQ,BCQ以及其他相似的算法都证明了Q- learning在某些条件下收敛到batch中的最优值,而文章提出了一个SARSA形式的乘子,通过不断迭代该乘子Q值也能收敛到batch中的最优值。并且BCQ需要一个生成模型来拟合 μ(a∣s)\mu(a|s)μ(a∣s),并且从 μ\muμ 中采样动作,这会导致可能采样一些OOD的动作,而ICQ则完全使用batch中的数据。
Contributions:
- we propose the Implicit Constraint Q-learning (ICQ) algorithm, which effectively alleviates the extrapolation error as no unseen pairs are involved in estimating Q-value. Motivated by an implicit constraint optimization problem
- ICQ adopts a SARSA-like approach to evaluate Q-values and then converts the policy learning into a supervised regression problem.
- By decomposing the joint-policy under the implicit constraint, we extend ICQ to the multi-agent tasks successfully. To the best of our knowledge, our work is the first study analyzing and addressing the extrapolation error in multi-agent reinforcement learning.
算法伪代码:

首先考虑标准的贝尔曼乘子:
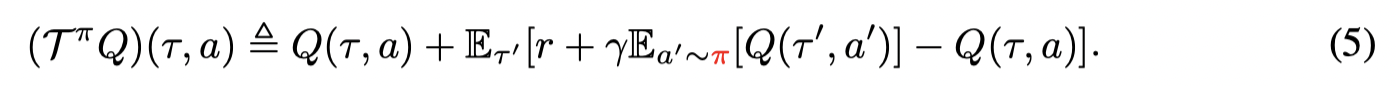
通过迭代,Q值会敛到 策略 π\piπ 对应的Q值
但在offline中,由当前策略 π\piπ 产生的动作会参与目标Q值的计算,但没有online的方式去矫正某些OOD动作的值估计,因此就会产生外推误差。其中一个解决方式是通过重要性采样:
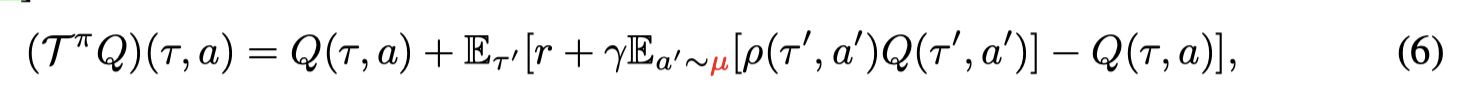
但是往往我们并不清楚行为策略 μ(a∣s)\mu(a|s)μ(a∣s) ,并且重要性采样在现实中会导致高方差,因此文章提出了另一个方式来计算重要性因子 ρ\rhoρ
Implicit Constraint Q-learning (ICQ)
首先考虑一个带着行为规范的策略优化问题:
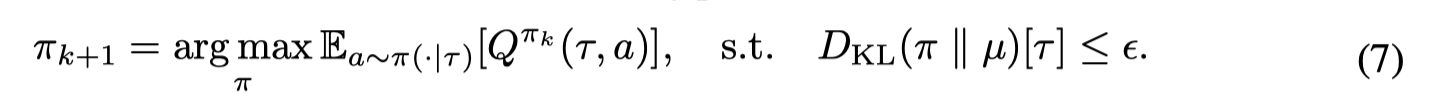
这个问题的最优解形式为:
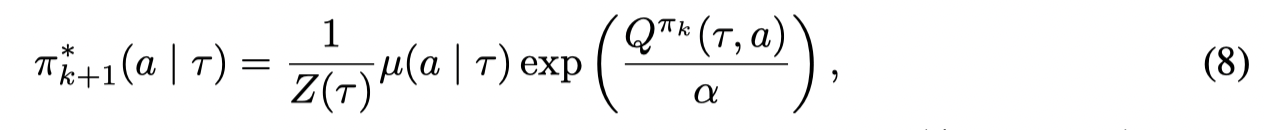
(求解过程同AWR一样,通过拉格朗日乘子法求解)
接着计算 π∗\pi^*π∗ 和 μ\muμ 之间的比例:
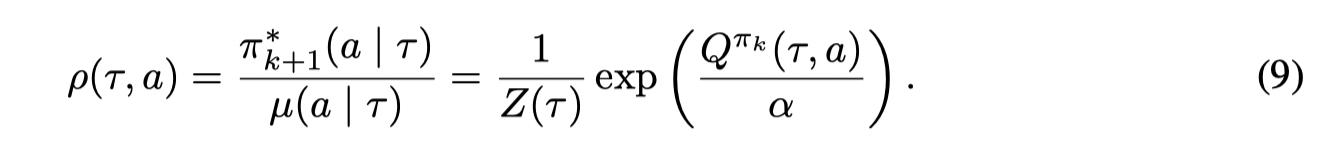
就得到了 Implicit Constraint Q-learning operator:
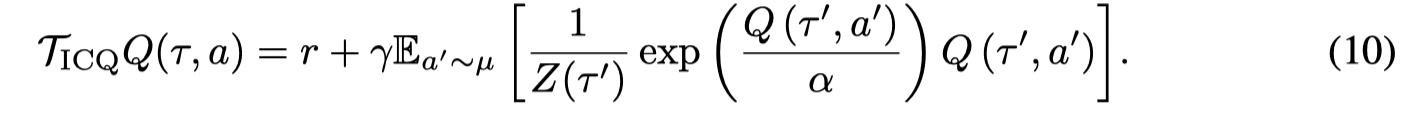
这样就得到了SARAR-like algorithm,其中不用OOD的状态和动作。
接着文章给出了一些理论分析,分析了 α\alphaα 对这个乘子的影响:
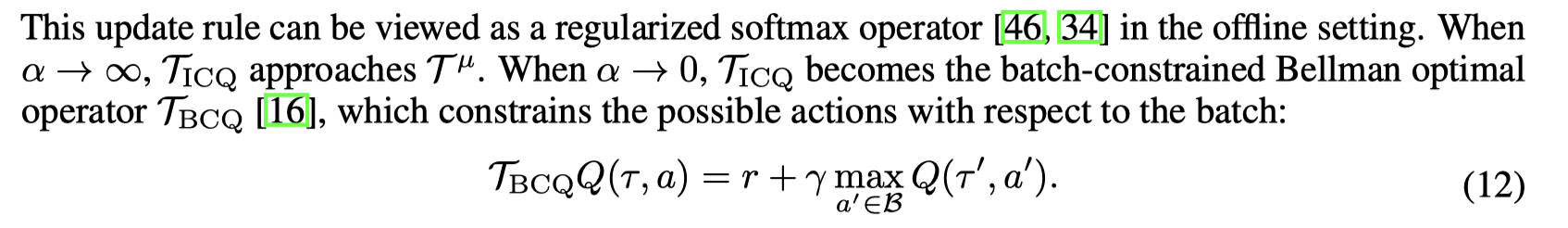

文章给出了Q值更新和策略更新的目标:
Q-value training:
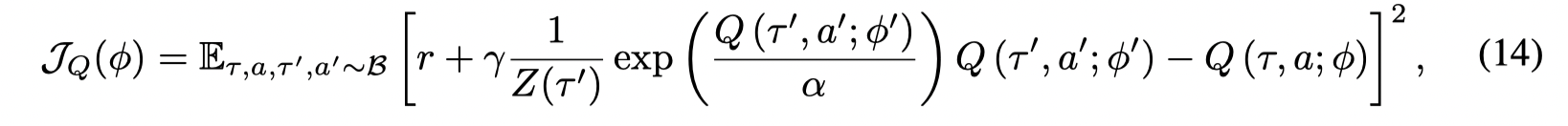
policy training 的部分和MARWIL, AWR 一样。
最后文章还将ICQ拓展到多智能体上,这里就不讨论了。
Imitation-based
基于模仿学习的方法通常寻找数据集中存在的最优策略,并且模仿这个最优策略。其中COIL针对混合数据集,提出了一个更有效学习到最优策略的方法。
*Exponentially Weighted Imitation Learning for Batched Historical Data (2018, NeurIPS)
文章提出了 MARWIL,通过offline的训练模仿一个比behavior policy 更好的策略。
算法伪代码:
![]()

首先对于一个最大化策略的提升(第一项)同时最小化新旧策略之间的距离(第二项)的问题:
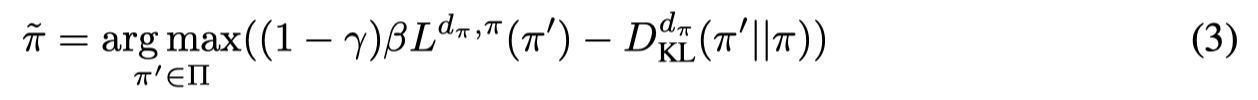
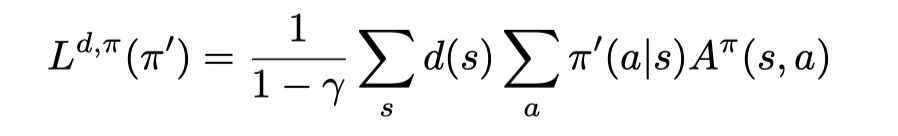
的最优解的形式为:
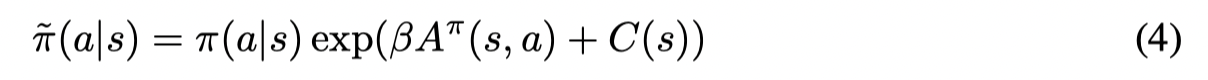
其中C(s)可以看作是一个normalizing factor,exp(C(s)) 等价于 AWR 中的 1/ Z(S)。
并且文章证明了π~\tilde \piπ~ 比 behavior poliy π\piπ 要好:
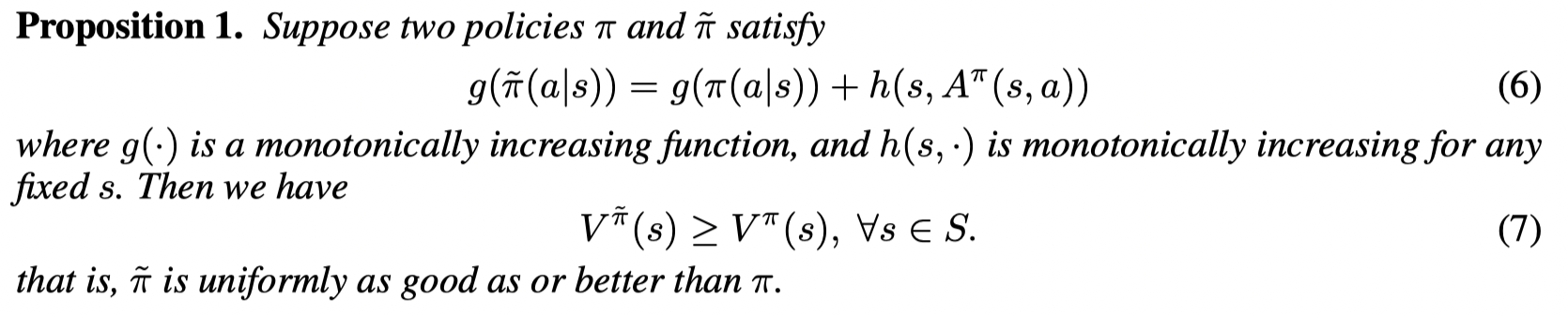
证明思路:
定义一个序列
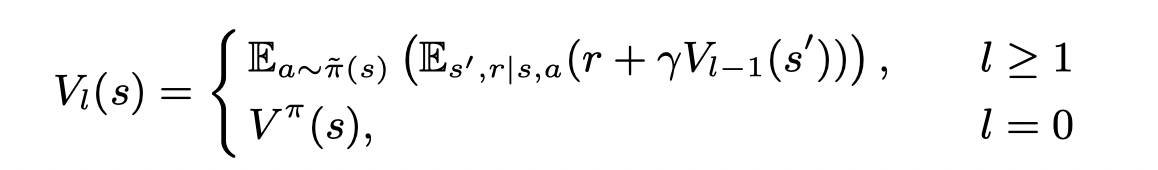
表示在状态sss,前lll步使用π~\tilde\piπ~ ,后面使用π\piπ 的值函数。
首先取两个集合:
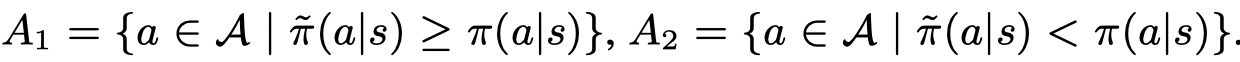
则根据g的单调性有:
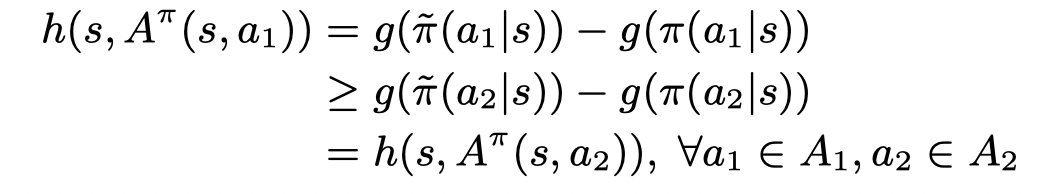
并且考虑a1 和 a2对应的优势函数只有Q不同,并且h是对于a单调的,则存在一个q(s):
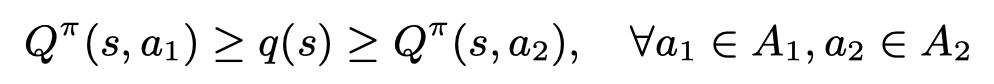
则下面的公式大于等于零,只需要把对a的求和分成a1, a2的求和,并结合上面的不等式
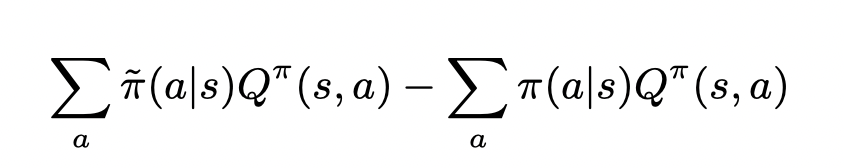
左边项为 V1(s)V_1(s)V1(s),右边项为 V0(s)V_0(s)V0(s)。则证明了 V1(s)≥V0(s)V_1(s) \geq V_0(s)V1(s)≥V0(s)
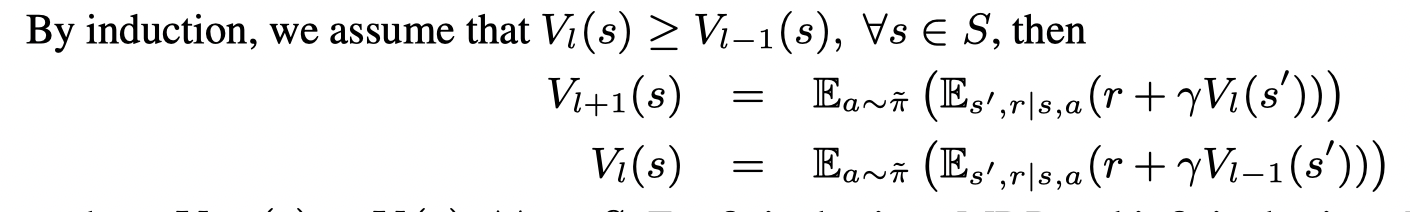
因此我们可以证明这个序列是单调不降的,对于有限MDP 和 γ<1\gamma <1γ<1 的无限MDP,都有:
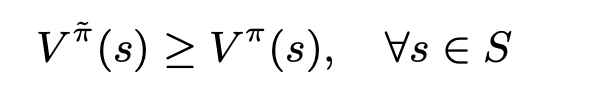
只要取 g(π)=log(π)g(π) = log(π)g(π)=log(π),h(s,Aπ(s,a))=βAπ(s,a)+C(s)h(s, A^π(s, a)) = β A ^π(s, a) + C(s)h(s,Aπ(s,a))=βAπ(s,a)+C(s) ,则公式(4)满足Proposition1。
不过有个问题是为什么优势函数可以认为是对a单调递增的?
文章证明了 π~\tilde \piπ~ 是一个比behavior的策略,因为不同于传统的模仿学习模仿behavior policy, 文章提出模仿一个比behavior policy更好的策略。将得到的策略用πθ\pi_{\theta}πθ表示
文章直接通过最小化KL divergence来模仿π~\tilde \piπ~ :
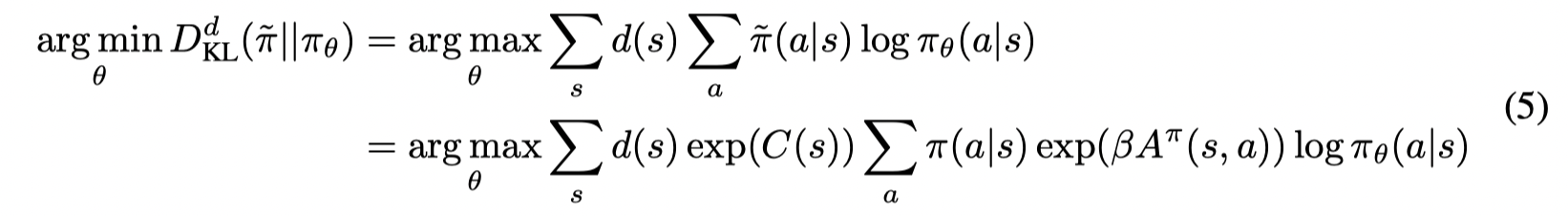
可以直接取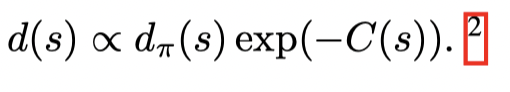
这样数据集全都由behavior policy 产生。得此得到πθ\pi_{\theta}πθ 的过程可以看作在分布 d(s)d(s)d(s) 下对π~\tilde \piπ~ 的 behavioral cloning。公式(5)等价算法(1)。
文章还给出了πθπ_θπθ 和 behavior policy之间差距的下界,保证了 πθ\pi_{\theta}πθ 是 在behavior policy 上的提升。
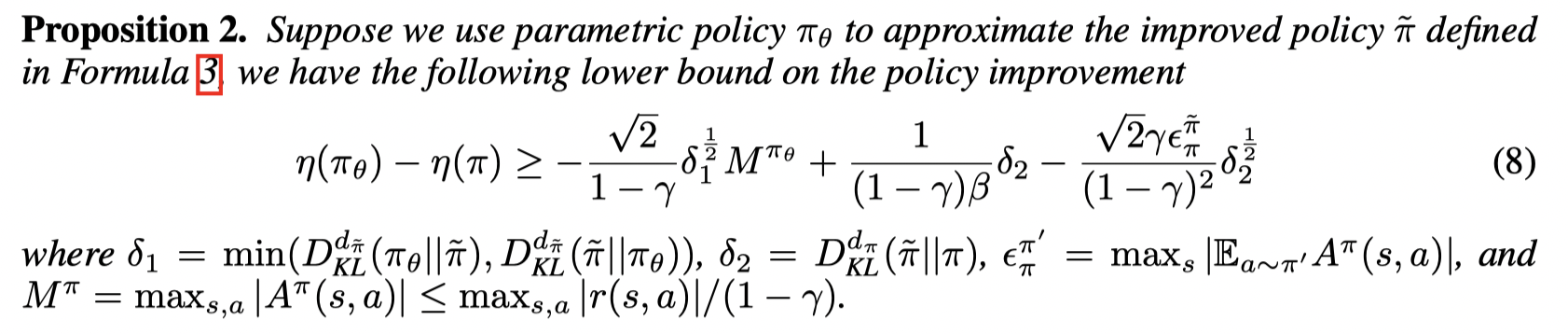
证明思路:
首先将两个policy的差异表示为各自与 π~\tilde \piπ~ 的差异:
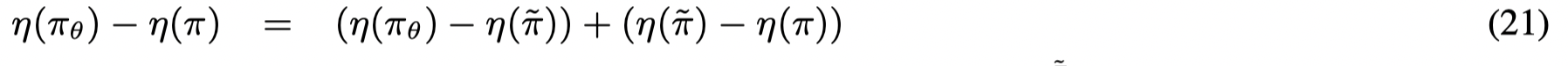
首先分析等式右边的第一个括号,根据:
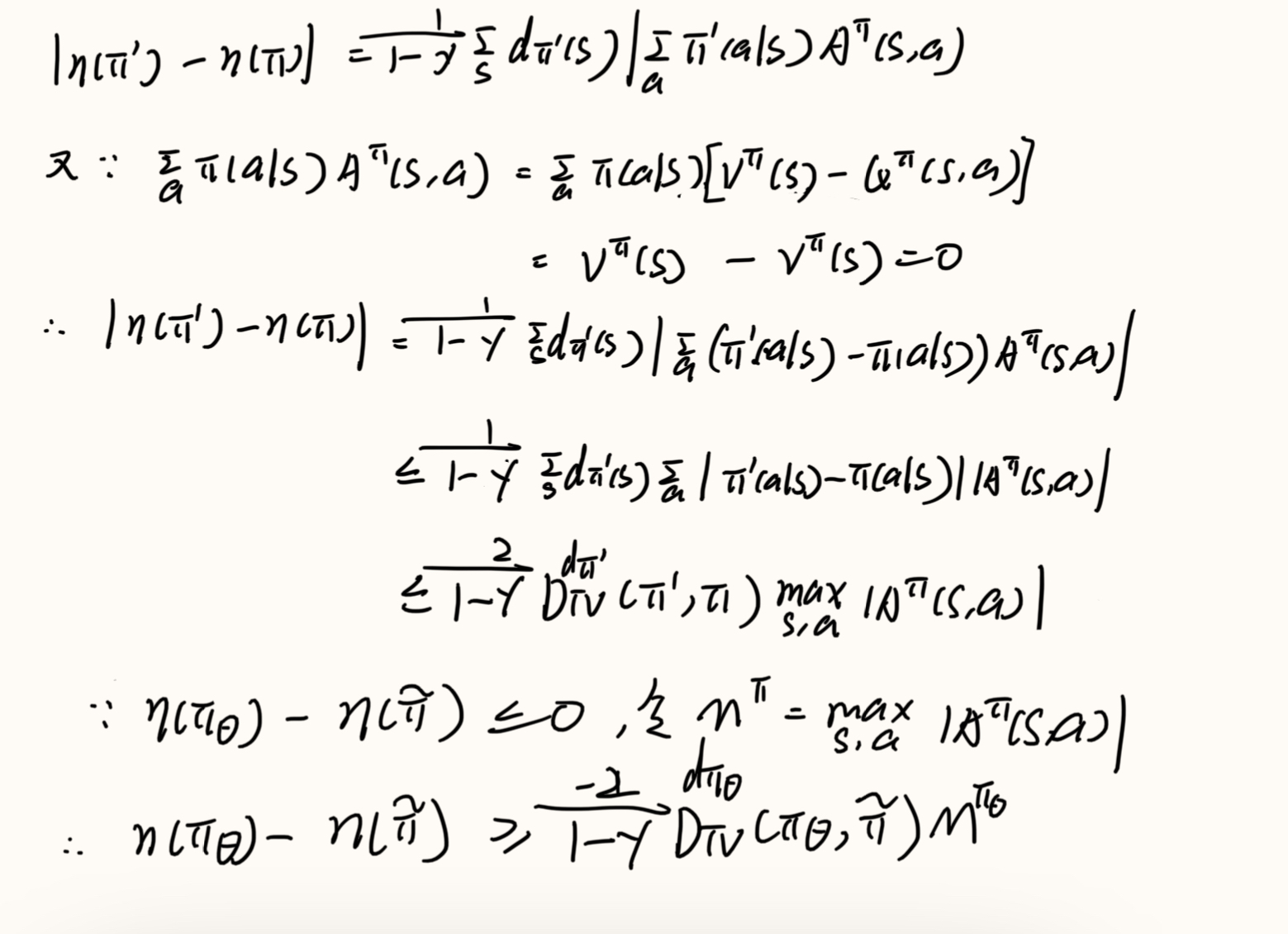
现在考虑等式右边的第二个括号,因为 π~\tilde \piπ~ 以下问题的最优解
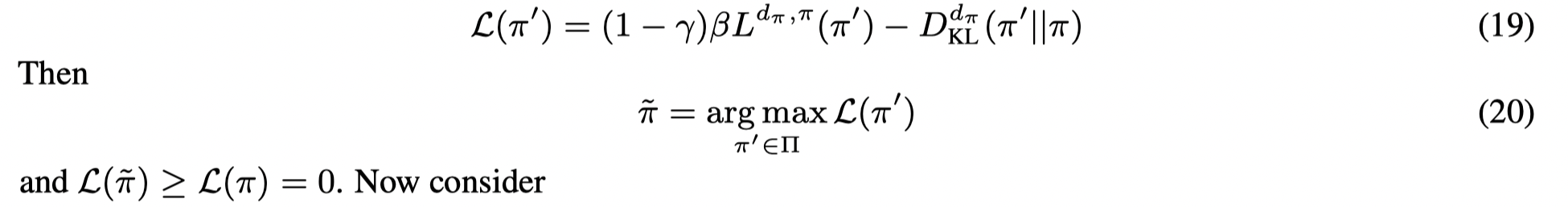
又有:
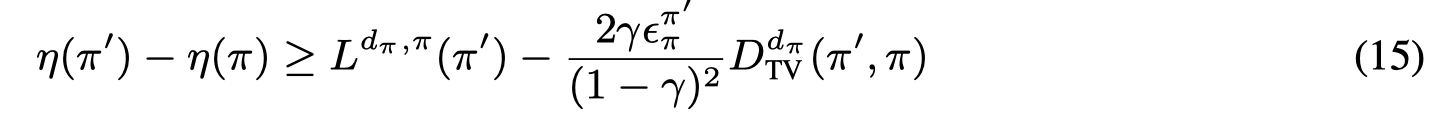
整合以后可以得到:
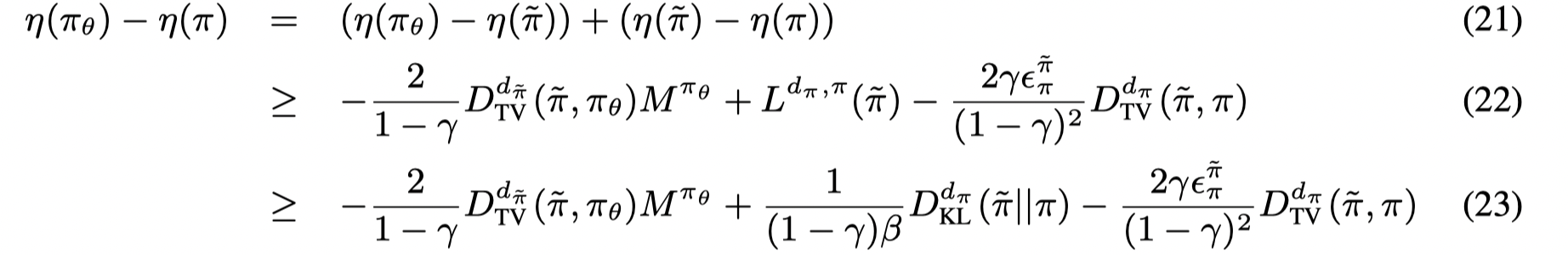

在实现中,文章估计优势函数通过:
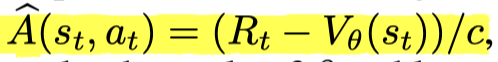
Vθ(st)V_θ(s_t)Vθ(st) 通过神经网络估计。
*Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning (2019)
文章提出了一个off-policy的策略搜索,整体思路和MARWIL相同,但不同点在于 MARWIL直接从一个数据集中学习,并没有对数据集的产生有什么要求。而AWR则利用replay buffer, 在每一个iteration 都由上一个策略采集数据加入buffer中,并从buffer中采集数据进行训练。AWR可以有online 和 offline 两个版本。
算法伪代码:

对于constrained policy search problem定义为:
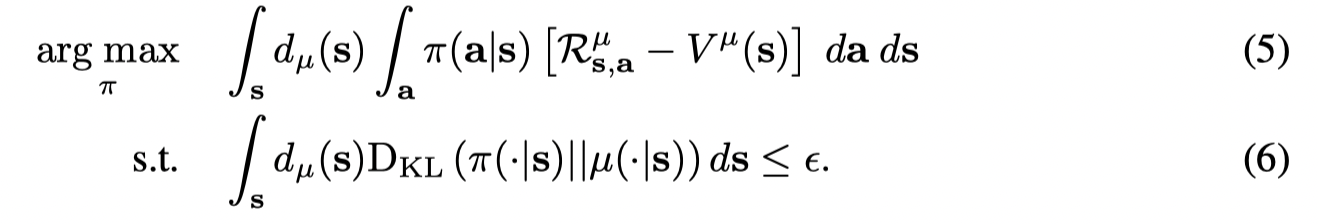
和MARWIL中的公式(3)求解问题相似。通过拉格朗日乘子法优化目标转变为:
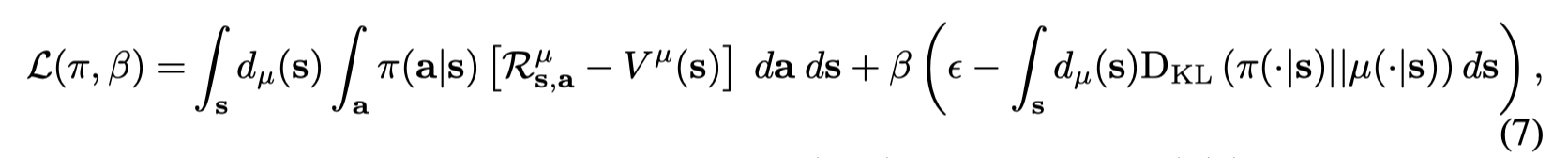
最优策略的形式为:
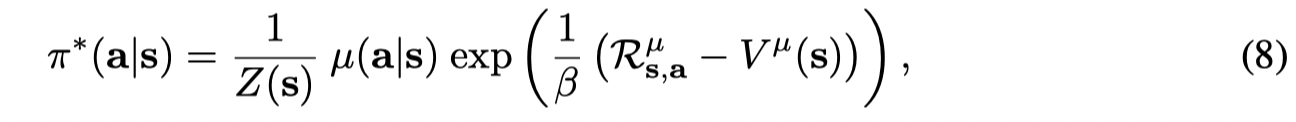
这个解的形式其实和MARWIL中的(4)一样。
求解过程如下:
首先将(6)中的硬约束转变为软约束:
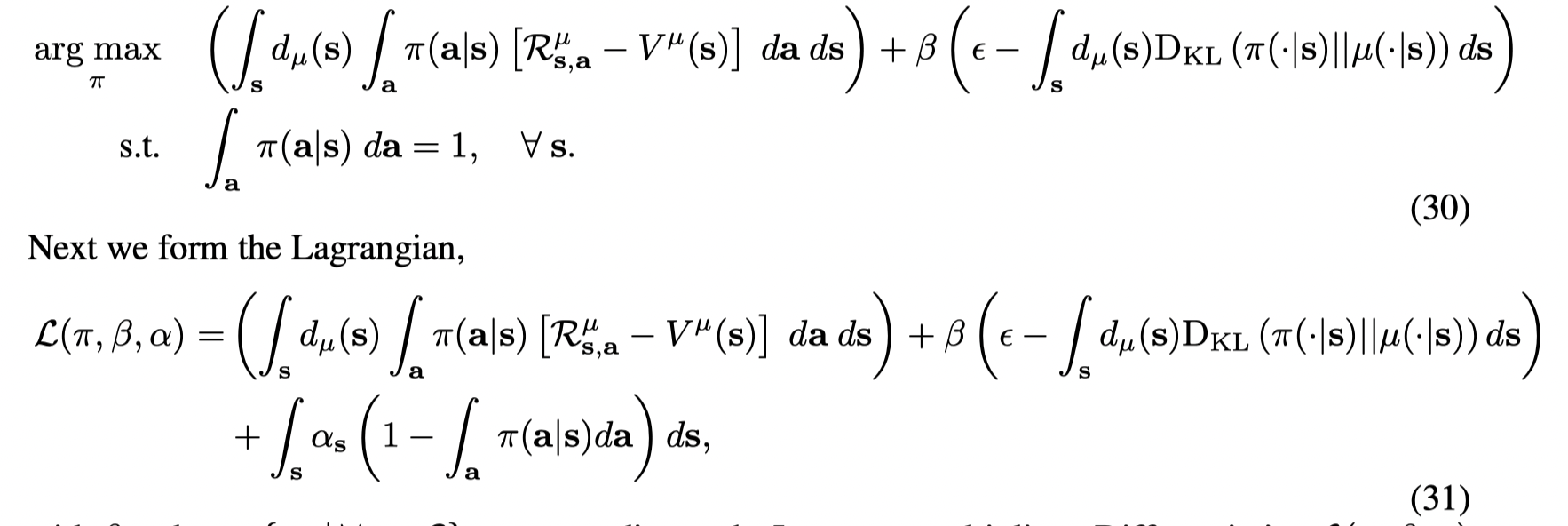
接着再对 π(a∣s)\pi(a|s)π(a∣s) 微分得到:
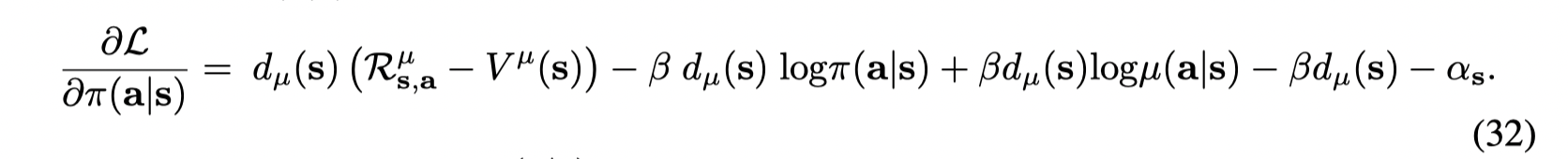
令其等于0,得到:
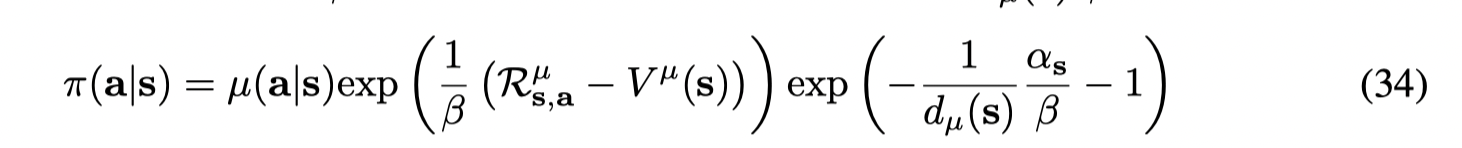
令
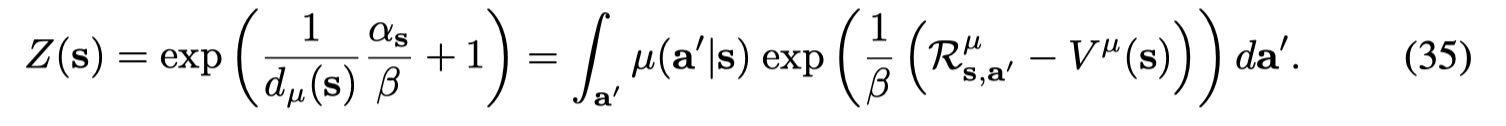
可以看出,Z(s)Z(s)Z(s) 是一个归一化的因子。
我们可以将π∗\pi ^*π∗ 投影到一个参数化的策略上,等价于MARWIL中的模仿学习。
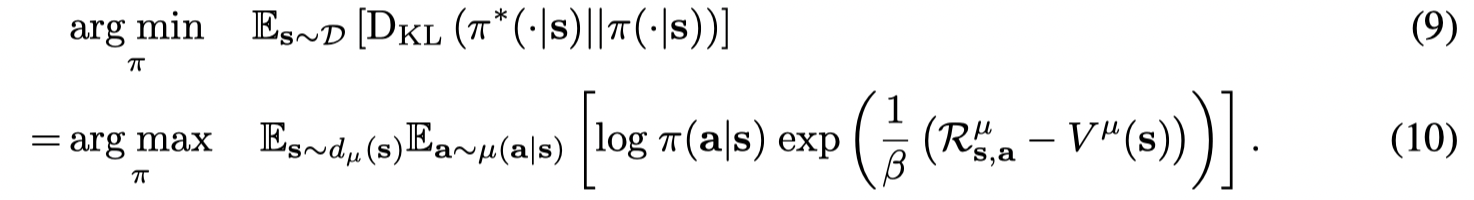
其中公式(9)中的 s∼Ds \sim Ds∼D 我认为应该改成 s∼dμ(s)Z(s)s \sim d_{\mu}(s) Z(s)s∼dμ(s)Z(s) 这样10才能成立。
接着文章讨论了如何结合experience replay buffer来进行 off-policy training。将buffer中的策略定义为 μ\muμ
首先文章将experience replay buffer 中的trajectory distribution,joint state-action distribution 和 marginal state distribution
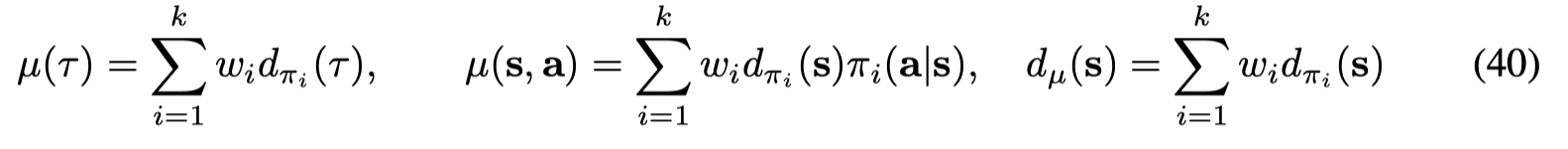
其中的权重为选择改策略的概率。conditional action distribution 为:
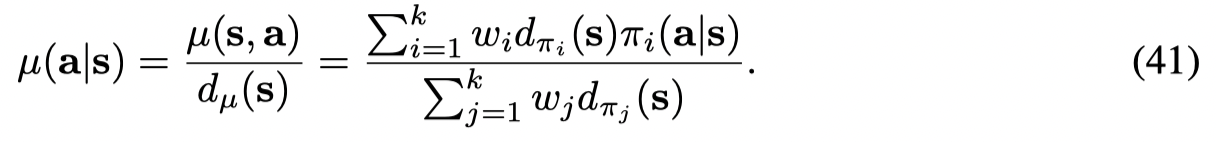
因此expected improvement 可以写成对buffer中每个策略的提升的加权和:
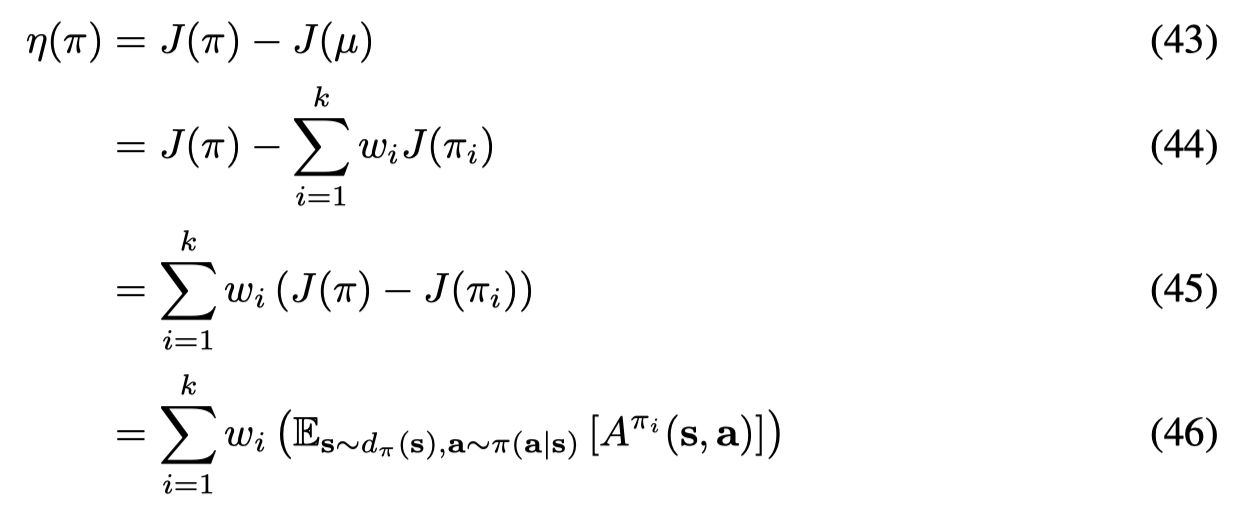
同时加上限制条件:
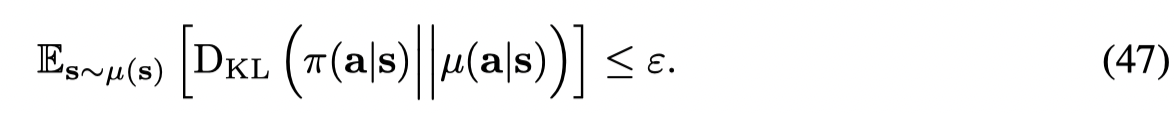
得到一下带约束的目标函数:
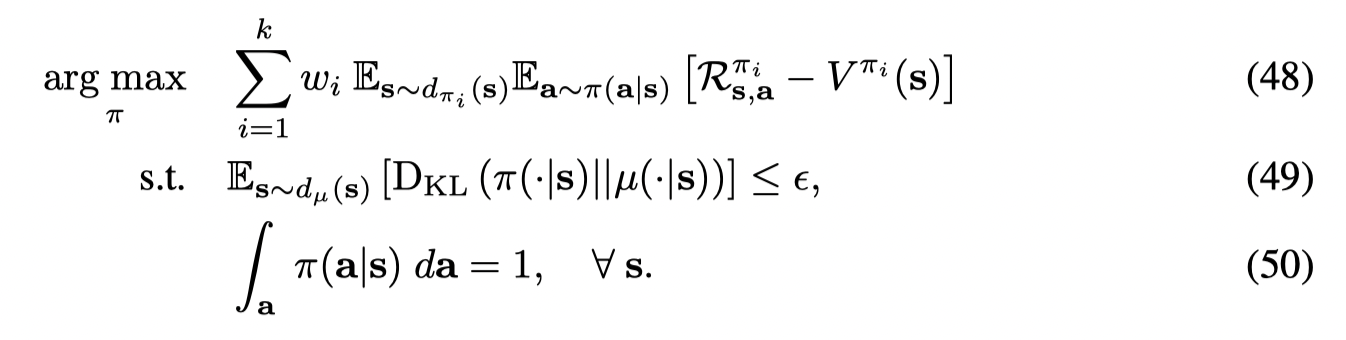
同样利用拉格朗日乘子法求解得到:
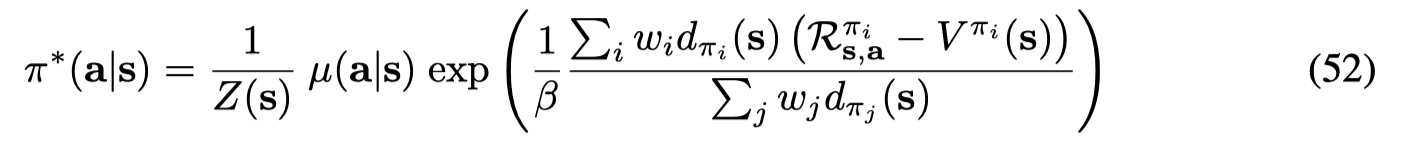
同样将 π∗\pi^*π∗ 投影到一个参数化的新策略上,求解监督学习中的回归问题
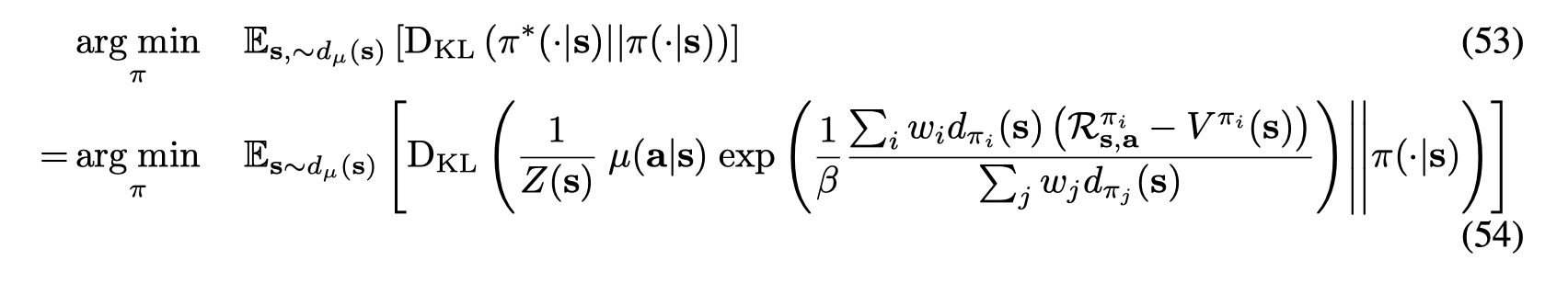
接着文章提出了两个trick来简化计算
将exptected return 的计算改为buffer 中的单次rollout:
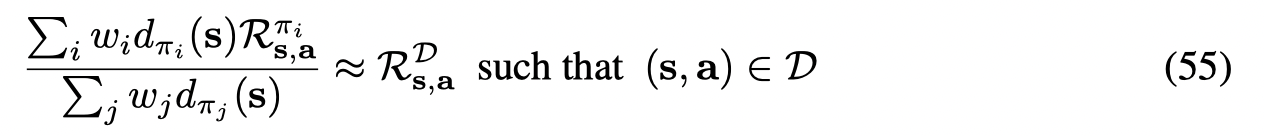
将混合的value function 改为single mean value function:
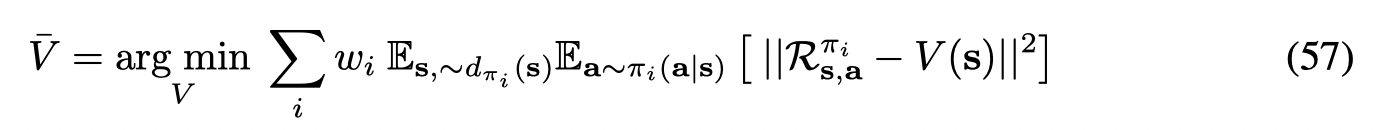
也就是可以直接从buffer 采集数据进行一个回归 (算法中的line5)。
最终(54)的求解可以由算法中的 line6 实现。
在实现中,文章利用TD(λ) 来估计Rs,aR_{s,a}Rs,a, 并且对权重进行一个最大值的clip。
*BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning (2019, NeurIPS)
文章提出了BAIL,利用batch 数据的上包络来进行值函数估计,并且根据值函数来挑选数据集中最好的状态和动作进行模仿学习训练。
Contributions:
- BAIL, a new high-performing batch DRL algorithm, along with the novel concept of “the upper envelope of data”.
- extensive, carefullydesigned experiments comparing five batch DRL algorithms over diverse datasets.

Best-Action Imitation Learning (BAIL)
首先对任意的 (s,a)(s,a)(s,a),G(s,a)G(s,a)G(s,a) 定义为从 sss 出发,做出动作 aaa 的return, V∗(s)V^∗ (s)V∗(s) 为最优的值方程,满足 G(s,a∗)=V∗(s)G(s, a^∗ ) = V^∗ (s)G(s,a∗)=V∗(s) 的动作 a∗a^*a∗ 为最优动作。因此文章的目标是构建一个算法寻找每一个状态 sss 的最优动作。
考虑到在batch中只有有限的数据,因此文章利用 batch 数据的上包络来估计值函数。给定一个未知的,episodic fashion生成的batch数据。状态 sis_isi 的蒙特卡洛回报为:Gi=∑t=iTγt−irtG_i= ∑_{t=i}^T γ^{t−i}r_tGi=∑t=iTγt−irt.
定义 Vϕ(s)V_{\phi}(s)Vϕ(s) 是一个神经网络,ϕ=(w,b)\phi = (w,b)ϕ=(w,b) , 对于一个固定的 λ>0\lambda > 0λ>0, 则 Vϕλ(s)V_{\phi^{\lambda}}(s)Vϕλ(s) 是λ-regularized upper envelope,如果 ϕλ\phi^{\lambda}ϕλ 是下面约束优化问题的最优解:
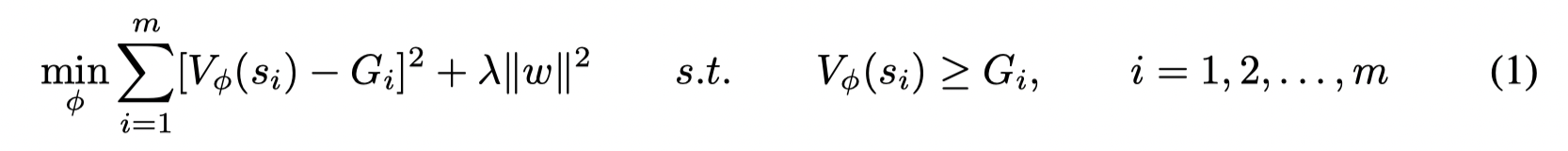
后面的 λ\lambdaλ 约束项是为了防止过拟合。
λ-regularized upper envelopes 的极限有如下性质:

证明:
(1)
对于 ϕ=(0,b)\phi = (0, b)ϕ=(0,b),我们都有V(0,b)(s)=bV_{(0,b)}(s) = bV(0,b)(s)=b,并且Jλ(0,b)=∑i=1m(b−Gi)2J^λ(0, b) = ∑_{i=1}^m(b − G_i)^2Jλ(0,b)=∑i=1m(b−Gi)2
定义 G∗:=max1≤i≤m{Gi}G^∗ := \max_{1 \le i \le m} \{ G_i \}G∗:=max1≤i≤m{Gi} , ϕ^=(0,G∗)\hat \phi = (0, G^∗ )ϕ^=(0,G∗), 则对于所有的 λ\lambdaλ 有:
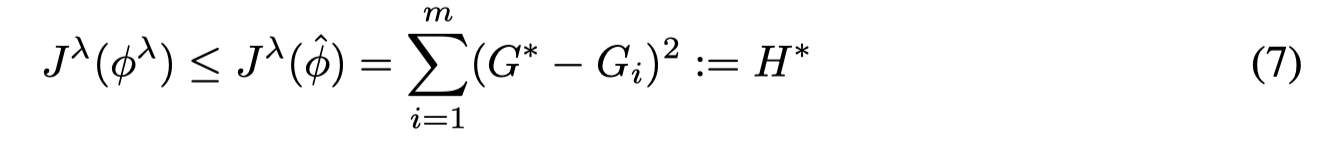
这是因为 ϕλ\phi^{\lambda}ϕλ 是优化问题的最优解,因此有最小的 JλJ^{\lambda}Jλ 值。
首先假设 limλ→∞wλ=0\lim_{\lambda \rightarrow ∞} w^λ= 0limλ→∞wλ=0 不成立,
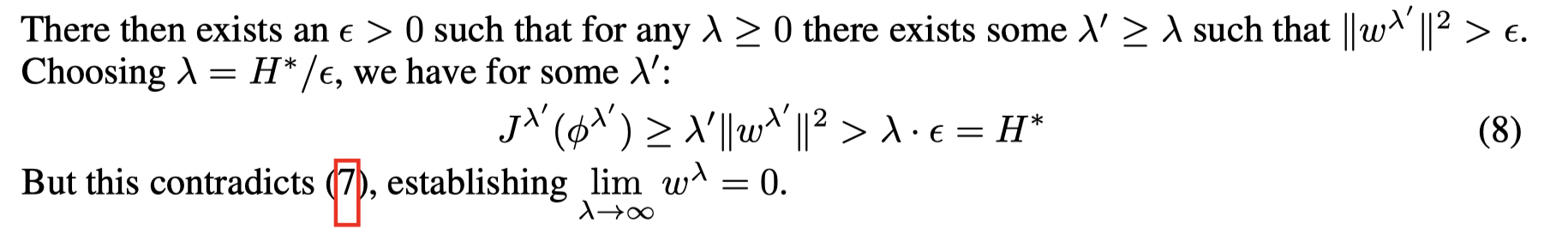
令 b~:=liminfλ→∞bλ\tilde b := \lim \inf_{λ→∞} b^λb~:=liminfλ→∞bλ,考虑一个序列 {bλn}\{ b^{λ_n} \}{bλn} 使得 limn→∞bλn=b~{\lim_{n→∞} b^{λ_n}= \tilde b}limn→∞bλn=b~, 因为 limλ→∞wλ=0\lim_{\lambda \rightarrow ∞} w^λ= 0limλ→∞wλ=0 ,有:
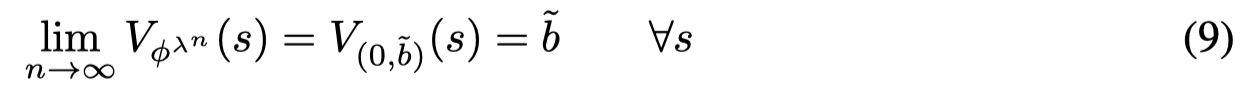
因为 ϕλn\phi^{λ_n}ϕλn 需要满足约束条件,因此有:
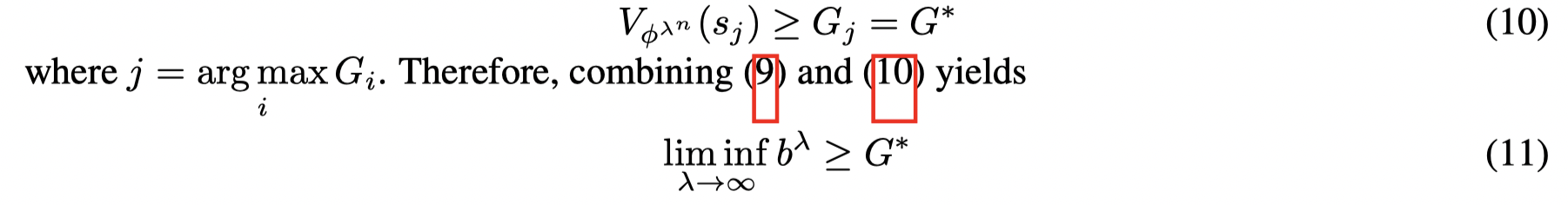
令 b‾:=limsupλ→∞bλ\overline b := \lim \sup_{λ→∞} b^λb:=limsupλ→∞bλ,考虑一个序列 {bλk}\{ b^{λ_k} \}{bλk} 使得 limk→∞bλk=b‾{\lim_{k→∞} b^{λ_k}= \overline b}limk→∞bλk=b, 则有:
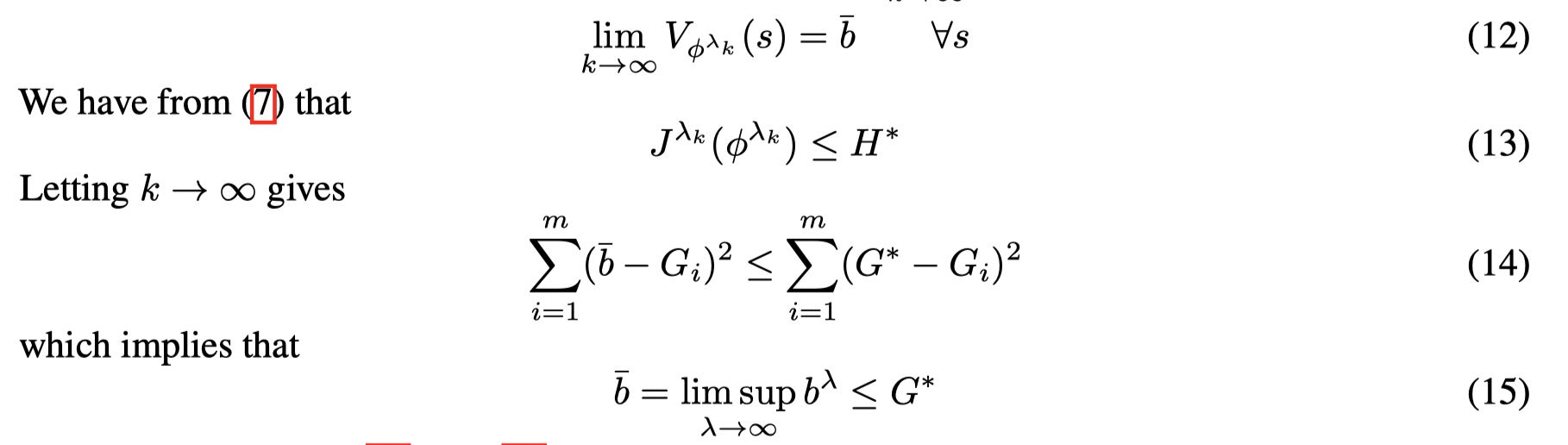
结合(11)和(15)有:
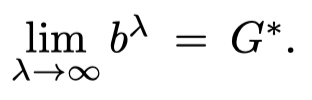
这里的 ϕλn\phi^{\lambda_n}ϕλn 和 ϕλk\phi^{\lambda_k}ϕλk 都需要是(1)的最优解。证毕。
(2)
如果 λ=0\lambda=0λ=0,那这就是一个神经网络的拟合问题,只要神经网络的表征能力够强就能拟合每一个点的值。
这个定理说明了 λ\lambdaλ 的选取会让上包络线在一条最大水平线(最大值)和插入每一个数据点的曲线之间。因此一定存在一个合适的 $\lambda $ 提供最好的泛化性。
接着通过一个惩罚项来将这个约束问题转变为一个无约束的损失函数:
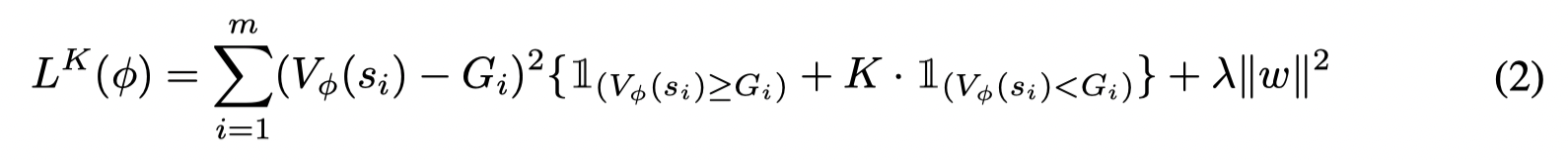
通过优化这个损失函数可以逼近真正的上包络,但是 V(si)V(s_i)V(si) 可能会在某些点小于 GiG_iGi

证明:
损失函数(2)有如下形式:
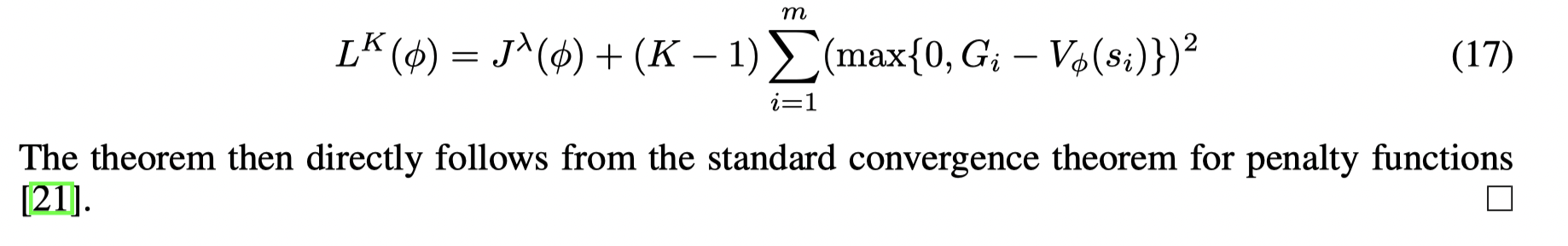
在实际中,文章利用一个验证集来检验这个损失,如果损失一直上升就停止更新网络参数。
文章提出两种方式来挑选最优的动作。
BAIL-ratio:对一个固定的 x>0x > 0x>0,选取 (si,ai)(s_i, a_i)(si,ai) 满足:

设置 xxx 使得 $p % $ 的数据点被选中
BAIL-difference:对于固定的 x>0x > 0x>0,选取(si,ai)(s_i, a_i)(si,ai) 满足:

*Keep Doing What Worked_Behavioral Modelling Priors for Offline Reinforcement Learning (2020, ICLR)
文章提出了ABM,首先从数据集中学习到一个先验策略,并且在策略提升步骤中限制当前策略和先验策略之间的差异。最后提出了两种方式,MPO和SVG进行优化。
Contributions:
- We propose a policy iteration algorithm in which the prior is learned to form an advantage-weighted model of the behavior data. This prior biases the RL policy towards previously experienced actions that also have a high chance of being successful in the current task.
- Our method enables stable learning from conflicting data sources and we show improvements on competitive baselines in a variety of RL tasks – including standard continuous control benchmarks and multi-task learning for simulated and real-world robots.
- We also find that utilizing an appropriate prior is sufficient to stabilize learning; demonstrating that the policy evaluation step is implicitly stabilized when a policy iteration algorithm is used – as long as care is taken to faithfully evaluate the value function within temporal difference calculations.
算法伪代码:

Policy Evaluation:
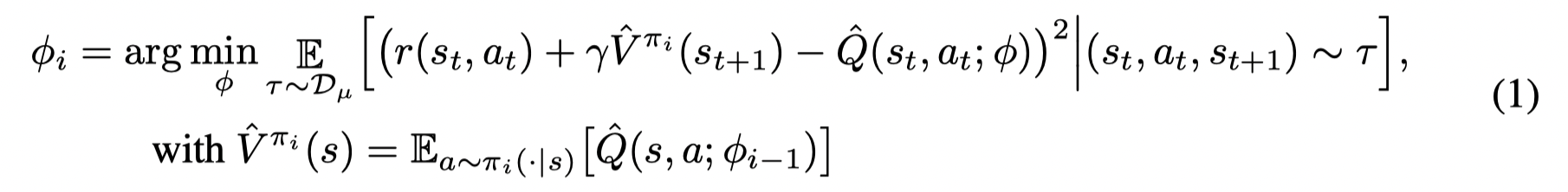
与BCQ等方法中的Q-learning 相比,文章认为通过策略评估可以使得训练更加稳定。
Policy Improvement:
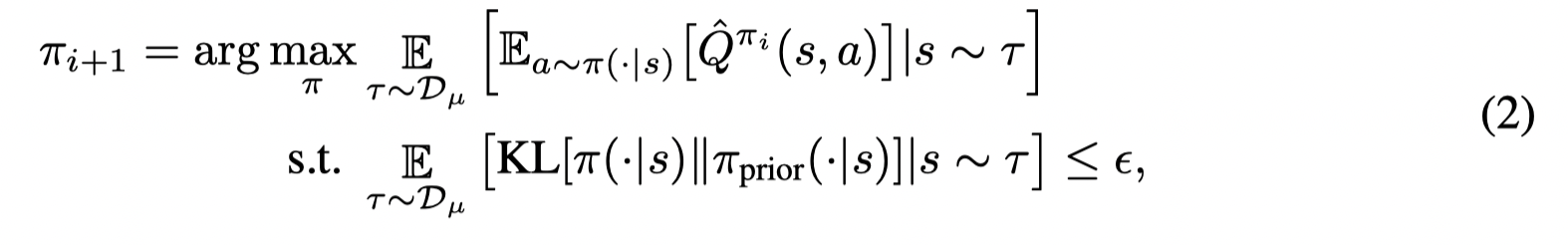
与TRPO不同,在(2)中限制当前策略与先验策略而不是限制当前策略与前一个策略的差异。
Prior Learning:
通过KL散度进行一个模仿学习:
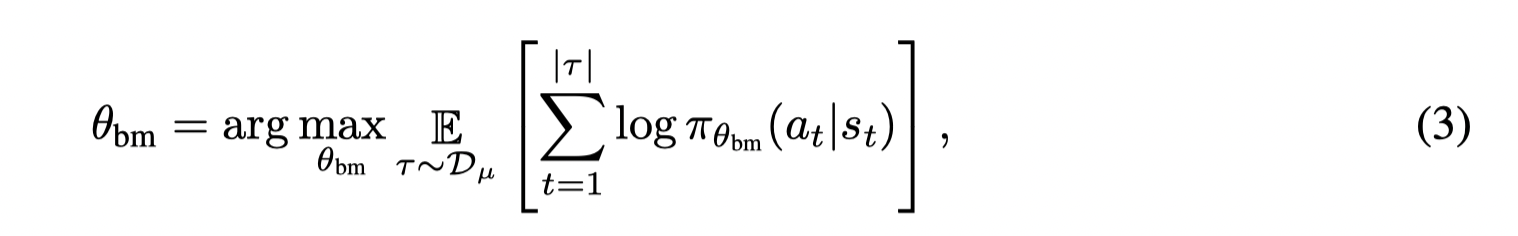
但是如果先验策略是行为策略,则可能会在(2)中限制了策略的提升。因此这种方式适用于数据集是最优策略或专家策略。
因此在一个混合的数据集(有好的轨迹也有坏的轨迹),文章考虑另一个先验策略。
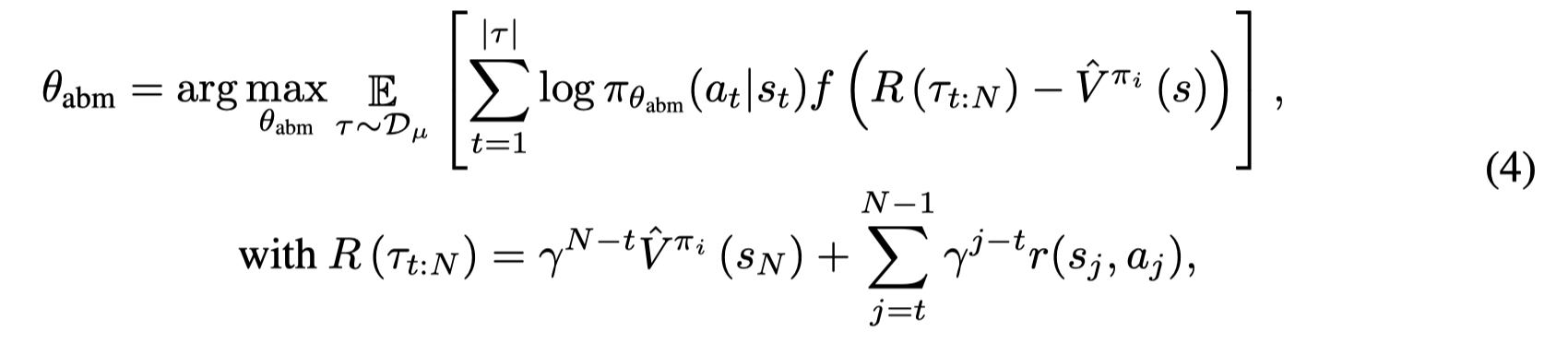
其中 fff 是一个递增非负项。通过乘上优势函数,则先验模型会更多学习到数据集中比较好的动作,并不断过滤掉数据集中那些比当前策略 (πi\pi_iπi) 表现还差的轨迹。注意到当 f(x)=xf(x) = xf(x)=x 时,(4)就是 policy gradient的形式。但是因为样本都是由buffer中产生,因此训练得到的 θabm\theta_{abm}θabm 只能收敛到buffer中的最优策略。文章采取 f=1+f = 1_+f=1+ (the unit step function with f(x) = 1 for x ≥ 0 and 0 otherwise) .
文章提出了两种优化方式:
EM-style optimization
首先方程(2)的最优解形式为:
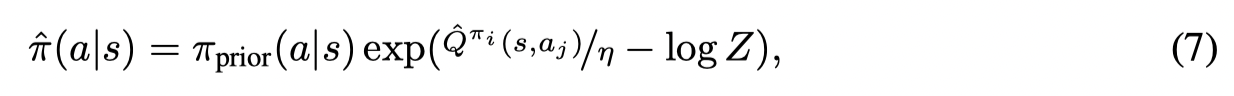
其中 ZZZ 是一个归一化项,ηηη 是取决于 ϵ\epsilonϵ 的参数。
对于优化 ηηη 的目标函数为:
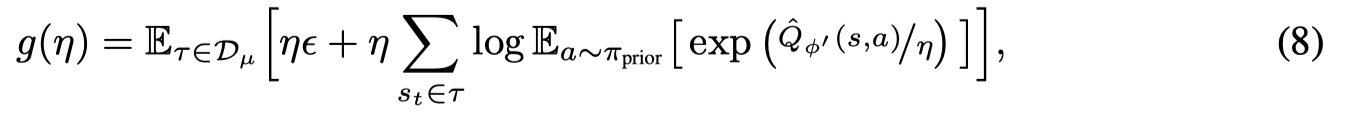
通过从buffer中采样轨迹,并根据 πprior(a∣s)π_{prior}(a | s)πprior(a∣s)采样动作得到:
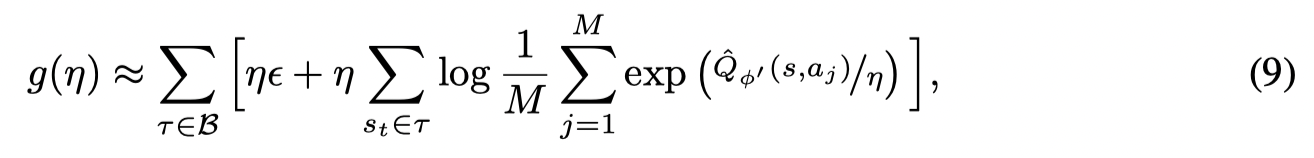
则可以通过最小化KL(π~∥πθi+1)KL(\tilde π ∥ π_{θ_i+1})KL(π~∥πθi+1) 得到 i+1i+1i+1 步的参数化策略,优化目标为:
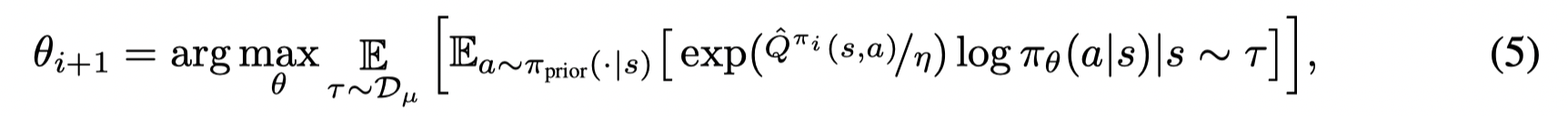
为了避免策略收敛过快,因此添加了一个置信区间约束,最终目标函数为:

可以对 θθθ 和 ααα 求导并且轮流执行梯度下降来优化(10)
Stochastic value gradient optimization
可以利用拉格朗日乘子法将(2)写成如下优化目标:
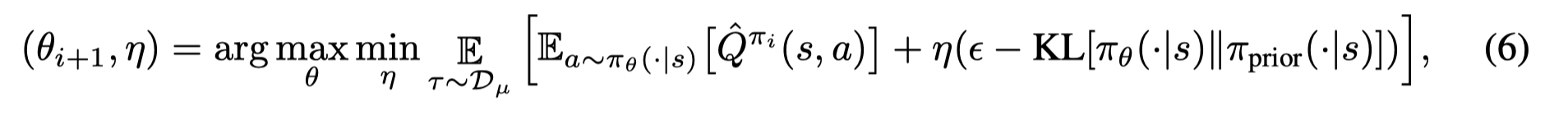
为了求解(6),文章中采用高斯分布作为策略族,πθ(a∣s)=N(a∣μθ(s),Iσθ2(s))π_θ(a | s) = N(a |\mu_θ(s), Iσ_θ^2(s))πθ(a∣s)=N(a∣μθ(s),Iσθ2(s)),并且采用一个重参数技巧,f(s,ξ;θ)=µθ(s)+σθ(s)ξf(s, ξ ; θ) = µ_θ (s) + σ_θ(s) ξf(s,ξ;θ)=µθ(s)+σθ(s)ξ , where ξ∼N(0,I)ξ ∼ N(0, I)ξ∼N(0,I).
接着文章给出了value gradient的形式:
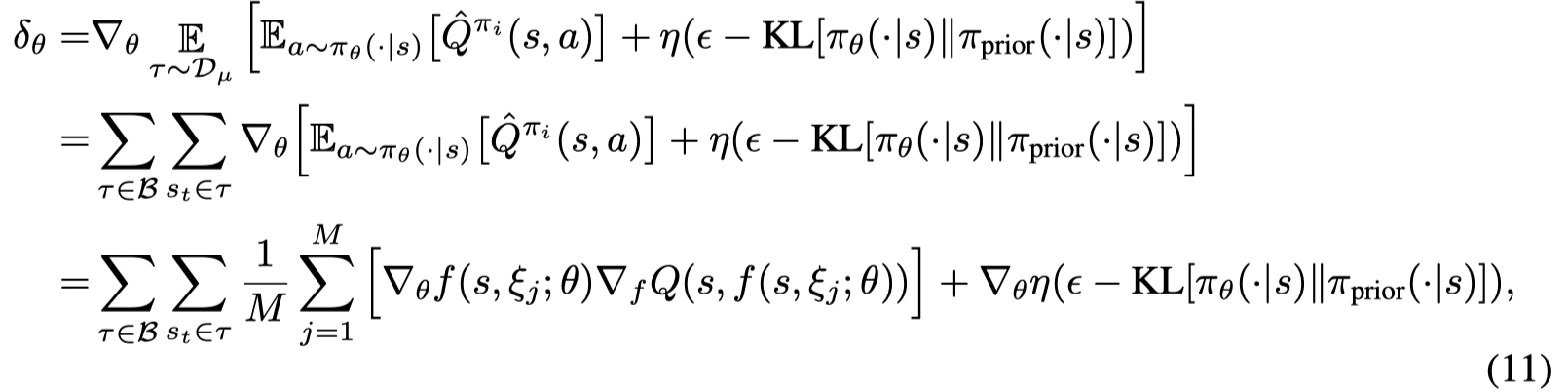
拉格朗日乘子的梯度为:
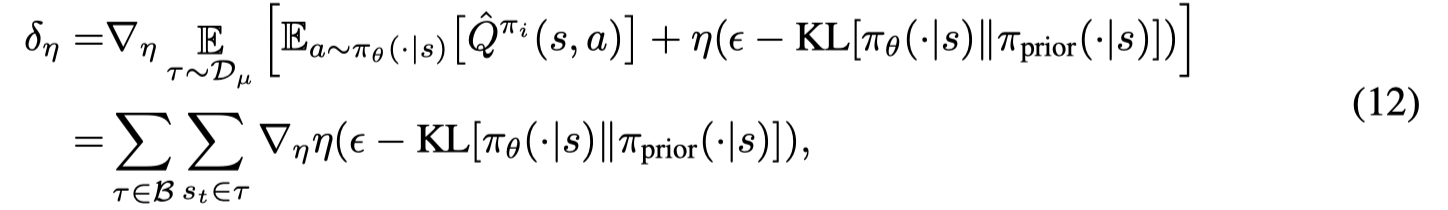
则可以对 θ\thetaθ 和 ηηη 轮流执行梯度下降来优化(6)
*Curriculum Offline Imitating Learning (2021, NeurIPS)
文章提出了 COIL,针对于一个混合的数据集,BC无法有效学习到数据集中的策略,而COIL则在每次迭代中学习和当前策略最像的N条策略,并最终学习到数据集中最好的策略。
Contributions:
- We highlight how the discrepancy between the target policy and the initialized policy affects the number of samples required by BC.
- Depending on BC, we propose a practical and effective offline RL algorithm with a practical neighboring experience picking strategy that ends with a good policy.
- We present promising comparison results with comprehensive analysis for our algorithm, which is competitive to the state-of-the-art methods.

首先文章给了两个策略比较的定义:
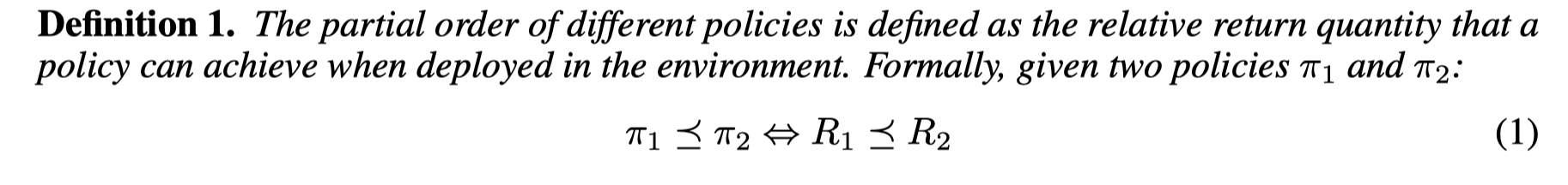
并定义了循环学习:

接着文章提出了一个观测到的现象。在传统的BC中,通常要求数据集需要高数量和高质量,小样本的专家数据也会导致学习失败。但是文章当初始策略和要模仿的策略之间的相似度增加时候,关于数量的要求可以放松。并且文章从实验和理论两个部分进行分析(实验部分在这里不写了,就是设置不同的初始策略和不同的样本数来进行模仿学习)。
接着文章分析了BC的performance bound:

证明:
首先引入一个引理:

这个证明很简单。接着我们有:
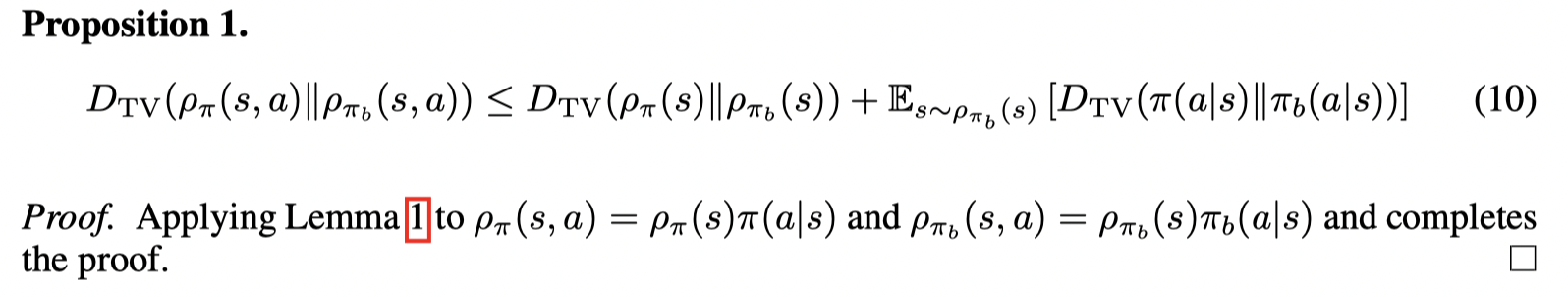
接着再引入一个引理:
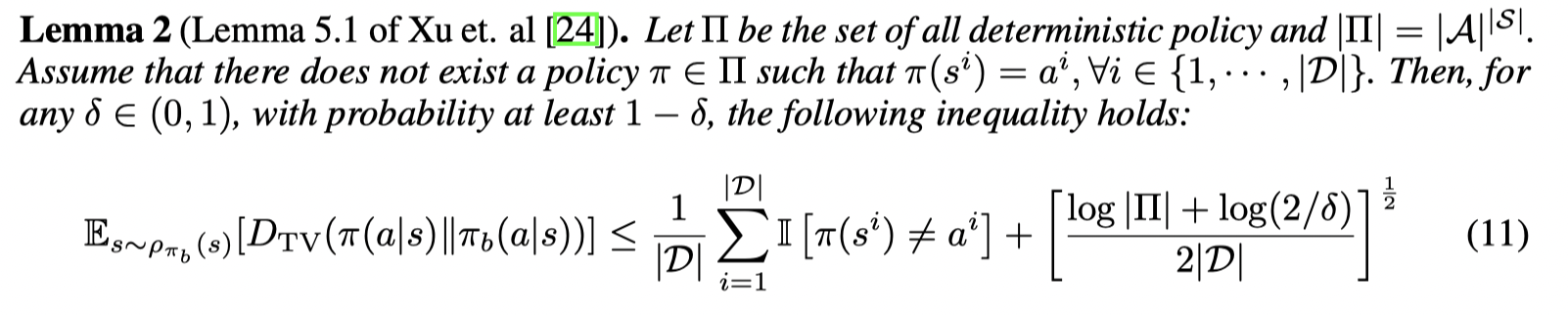
接着给出定理的证明:
根据(11),则(10)中右边的第二项可以被bound住,考虑(10)右边的第一项,引入一个新的分布 ρπ^b(s)ρ _{\hat π_b} (s)ρπ^b(s) (数据集的边缘状态分布) 有:
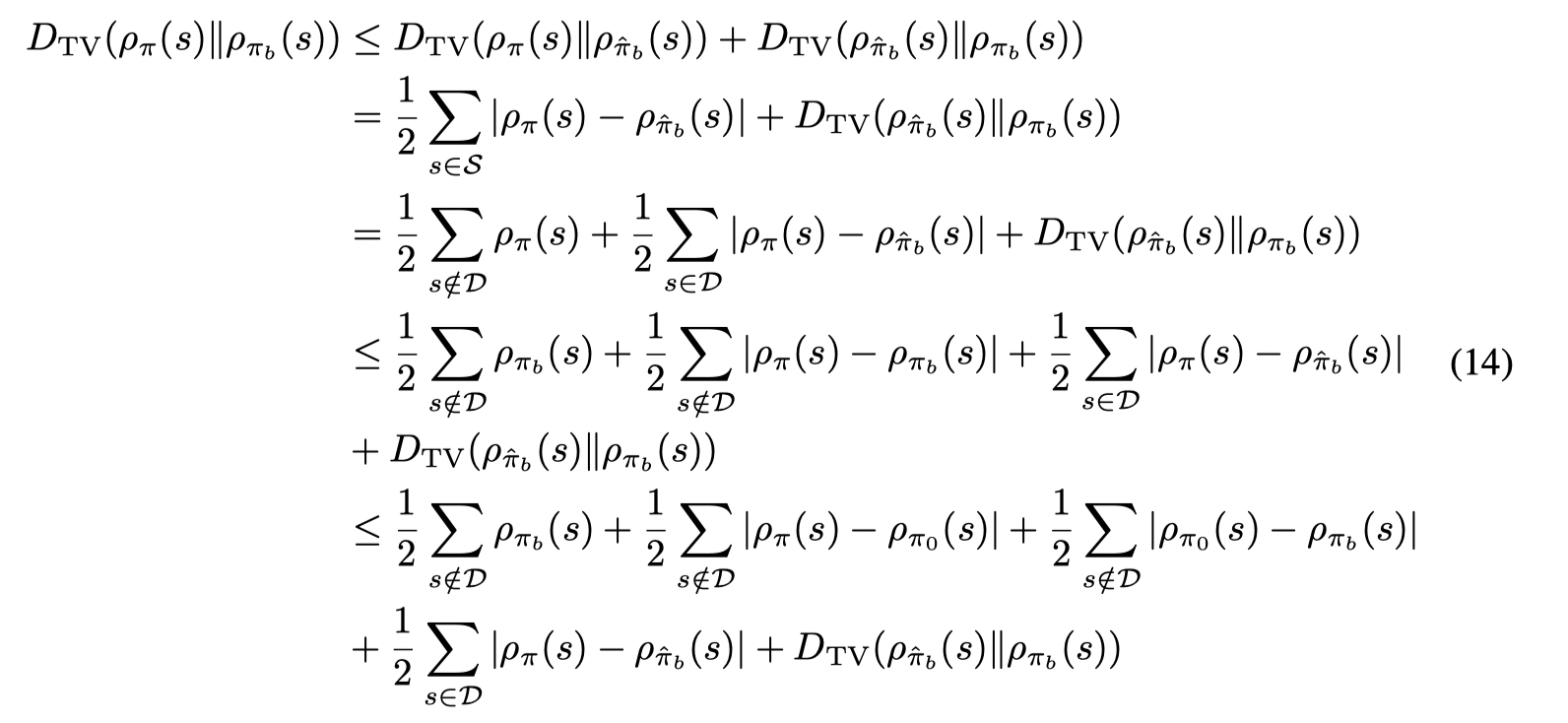
第一个不等式由三角不等式得到。第二个等式是因为对于不在数据集中的状态,ρπ^b(s)=0\rho_{\hat π_b} (s) = 0ρπ^b(s)=0。
并且有:
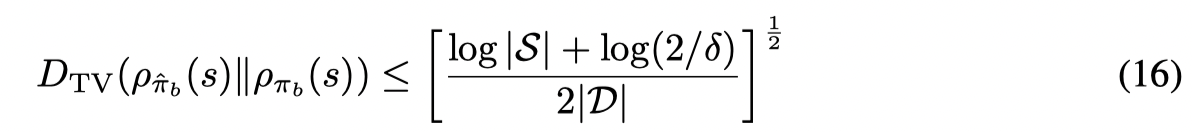
(16)如何得到我没有太看懂。
结合 (13),(14),(16),则给出了定理中的不等式。证毕。
从定理中可以看到,这个bound 包含了三个重要项目:initialization gap, BC gap 和 data gap。其中BC gap是模仿学习的误差。initialization gap是初始策略和要模仿的策略分布之间的差异。data gap和样本数量以及状态空间的复杂度有关。并且注意到不等式右边的第二项是在数据集外的状态上计算的,因此难以从理论上分析,因此文章利用empirical discrepancy来估计这一项,并且这一项会随着初始策略接近要模仿的策略而减少。
因此当初始策略接近目标策略后,即使数据集规模变小,这个bound也可以不变,所以关于样本量的要求可以放松。
Curriculum Offline Imitation Learning (COIL)
在每个训练阶段,从数据集 D={τ}1ND = \{ τ \}_1^ND={τ}1N 中挑选 τ∼π~iτ ∼ \tilde\pi^iτ∼π~i 来进行训练。
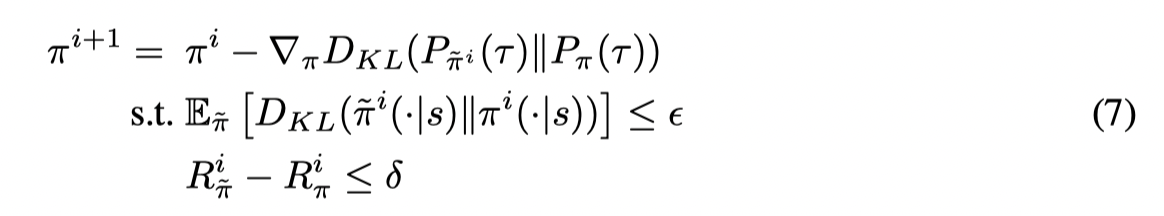
ϵ\epsilonϵ 用来约束当前策略和模仿的策略之间的差异,δ\deltaδ 用来避免学习太差的策略。
在每一迭代中 ,任务GiG_iGi 为去模仿和当前策略最相似的策略π~i\tilde π_iπ~i,损失函数为DKL(Pπ~i(τ)∥Pπ(τ))D_{KL}(P_{\tilde π_i(τ)} ∥ P_π(τ))DKL(Pπ~i(τ)∥Pπ(τ))。最终学习到数据集中的最优策略。这样就将循环学习和BC相结合起来了。
接着文章提出如何约束 $E_{\tilde π} [D_{KL} ( \tilde \pi(· | s) ∥ π(· | s))] ≤ \epsilon $。文章假设每一条轨迹 τπ~=(s0,a0,s0′,r0),⋅⋅⋅,(sh,ah,sh′,rh)τ_{\tilde π}= { (s_0, a_0, s' _0, r_0), · · · , (s_h, a_h, s'_h, r_h) }τπ~=(s0,a0,s0′,r0),⋅⋅⋅,(sh,ah,sh′,rh)都是由一个未知的确定性的策略 π~\tilde ππ~ 但加上探索噪音采集的。则有
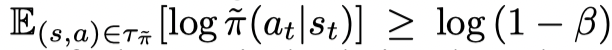
β\betaβ 对应探索噪音的部分,注意如果采集轨迹不带探索噪音,则左边一项等价于 log1\log1log1。因此文章提出了一种方法来放松KL散度的限制。

证明:
为了达到:
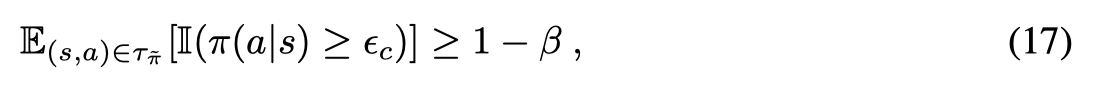
则至少有 1−β1-\beta1−β 数量的样本可以以 ϵc\epsilon_cϵc 的概率被采集到,因此可以得到一个lower-bound:
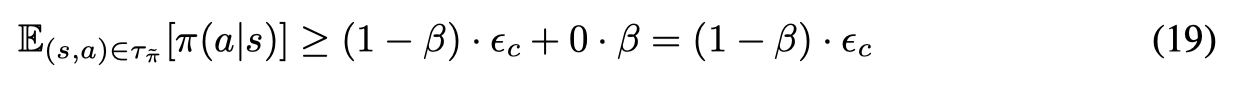
接着考虑KL散度的限制,有:
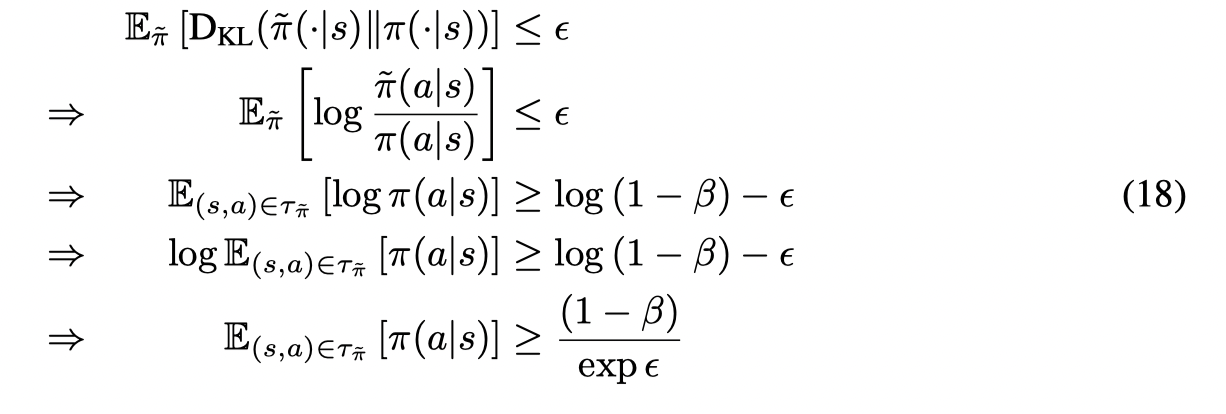
因此可以用公式(17)来代替KL散度的限制。证毕。
因此为了确定 τπ~τ_{\tilde π}τπ~ 是否是由一个相似的策略采集得到,我们计算τπ~(π)=π(a0∣s0),⋅⋅⋅,π(ah∣sh)τ_{\tilde π}(π) = { π(a_0| s_0), · · · , π(a_h| s_h) }τπ~(π)=π(a0∣s0),⋅⋅⋅,π(ah∣sh)。文章设置β=0.05β = 0.05β=0.05, 但不设置具体的 ϵc\epsilon_cϵc 值,而是寻找N个最相似的策略(N条轨迹)。
除了策略距离的约束,还有Rπ~−Rπ≤δR_{\tilde π}− R_π ≤ δRπ~−Rπ≤δ。文章采用一个Return Filter来代替这个约束。
在一开始将return filter设置为0,并且在每次循环都更新。如果在第 kkk 次迭代选择了轨迹 {τ}1n\{ τ \}_1^n{τ}1n,则 V 通过下列公式更新:
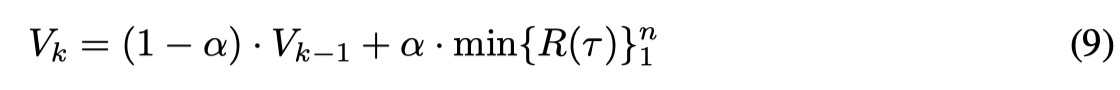
其中 R(τ)R(\tau)R(τ) 是轨迹的累积收益。并且更新数据集 D={τ∈D∣R(τ)≥V}D = \{ τ ∈ D | R(τ) ≥ V \}D={τ∈D∣R(τ)≥V},也就是去除掉那些相对于策略 πk\pi^kπk 表现不好的轨迹。
Offline RL Summary相关推荐
- 离线强化学习(Offline RL)系列3: (算法篇) IQL(Implicit Q-learning)算法详解与实现
[更新记录] 论文信息:Ilya Kostrikov, Ashvin Nair, Sergey Levine: "Offline Reinforcement Learning with Im ...
- 离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)
论文原文:[Yifan Wu, George Tucker, Ofir Nachum: "Behavior Regularized Offline Reinforcement Learnin ...
- 离线强化学习(Offline RL)系列3: (算法篇) AWAC算法详解与实现
[更新记录] 论文信息:AWAC: Accelerating Online Reinforcement Learning with Offline Datasets [Code] 本文由UC Berk ...
- 离线强化学习(Offline RL)系列3: (算法篇) Onestep 算法详解与实现
[更新记录] 论文信息: David Brandfonbrener, William F. Whitney, Rajesh Ranganath, Joan Bruna: "Offline R ...
- 离线强化学习(Offline RL)系列4:(数据集) 经验样本复杂度(Sample Complexity)对模型收敛的影响分析
[更新记录] 文章信息:Samin Yeasar Arnob, Riashat Islam, Doina Precup: "Importance of Empirical Sample Co ...
- 论文理解【Offline RL】—— 【BAIL】Best-Action Imitation Learning for Batch Deep Reinforcement Learning
标题:BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning 文章链接:BAIL: Best-Action ...
- 离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BEAR算法原理详解与实现
论文信息:Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction 本文由UC Berkeley的Sergey Levin ...
- 离线强化学习(Offline RL)系列4:(数据集)Offline数据集特征及对离线强化学习算法的影响
[更新信息] 文章信息:Kajetan Schweighofer, Markus Hofmarcher, Marius-Constantin Dinu, Philipp Renz, Angela Bi ...
- Interpretable Rl Summary
文章目录 Model Approximation Method Toward Interpretable Deep Reinforcement Learning with Linear Model U ...
最新文章
- 异常处理汇总-后端系列
- 【mysql】mysql的数据库主从(一主一从)
- ibm刀片服务器显示器切换,IBM X240 刀片 怎么连上显示屏呢
- 使用 IntraWeb (13) - 基本控件之 TIWLabel、TIWLink、TIWURL、TIWURLWindow
- iOS开发-UIScrollView原理
- impdp oracle 只导入表结构_oracle数据库怎么导入dmp,只导入数据不导入表结构?...
- el表达式里面fn的用法
- Zigbee 2006介绍+资料+源代码下载
- 利用windows 自带WiFi共享工具共享WiFi
- PostgreSQL update多张表关联查询更新
- d3中文案例_D3js初探及数据可视化案例设计实战 -web开发
- 数据库系统原理——实验四
- Udacity数据分析(入门)-探索美国共享单车数据
- java.lang.IllegalStateException: Cannot get a text value from a numeric cell
- 漏洞系列之——SQL注入
- 度小满金融大数据架构实践
- toolkit-frame之toolkit-sprider(数据采集)---笔趣阁小说
- 杰理之OTA 升级【篇】
- 在rtc ds1307的驱动中增加rtc ht1382芯片驱动
- SketchUp:解决修改不同模型背景天空颜色的问题图文教程